| 编辑推荐: |
本文来自于51cto,随着新浪微博业务的不断推进,对数据处理的实时性要求越来越高。例如,大家所熟悉的微博热词,需要在很短的时间内完成数据处理以供在线系统使用。 |
|
本文将按照如下四个阶段分享微博实时流计算平台的搭建历程,以及在创建过程中的一些问题和解决方案:
初入实时流计算
实时流计算平台初建
实时流计算平台发展
总结 DQRA 设计模式
初入实时流计算
首先介绍一下我们实时流计算平台开发历程:
2015 年,我进入新浪微博。当年,我们利用实时流计算做出了物料池系统。
2016 年,我们进行了用户实时兴趣反馈系统的开发。
2017 年,我们接入了一些与多媒体相关的,如人脸识别系统的建设。同年,我们也开始进行实时流计算平台的初建。
2018 年,我们开启了 WAIC 实时流计算平台。

上图是实时流计算的技术背景,常用的计算引擎有:Spark、Streaming、Flink、Storm、Flume
和 Kafka 等一些中间件。

我们 WAIC 实时流计算平台中,主要用到的计算引擎是:Storm、Kafka、Flume 和 Flink。

上图是实时流计算的第一阶段。这是一个经典的架构,它通过利用 Flume,将业务系统里的实时流日志数据写入
Kafka。
然后再利用 Storm 去读取 Kafka 里的数据,最后将数据进行相应的业务逻辑处理。

在该阶段,我们主要完成了如下两项工作:
让微博“接入”实时流计算功能。
当数据处理出现失败时,使用 Kafka 来执行必要的数据回滚,从而解决问题。

上图是第一阶段相应的数据成果。彼时的数据量和集群个数都比较少,因此主要存在的问题包括:
人工工作量比较多,即:面对需求时,全靠人编码。
代码重复率比较高,异常排查的方式较为简陋,全靠登录到服务器上,去 Grep 日志。
监控的方式则全靠脚本。

上图是第一阶段所遗留的一些问题。
实时流计算平台初建
那么随着实时流计算的频繁使用、业务场景的增多、以及监控需求的提升,我们意识到需要搭建一个实时流的计算平台。

我们当时所提出的平台目标主要包括:
研发一个工作量可以沉淀,并且可配置的开发框架。
统一所有的监控,打造一个统一的监控平台。

这是第二阶段实时流的初步架构图。在此,我们的接入日志方式丰富了许多。如图,我们既通过 Scribe
进行收集、又从 Kafka 以及 Mcq 里面读取数据。
然后通过 Scribe、或者其他的数据同步服务,将它们接入到实时队列之中,最后在不同的业务场景下,利用不同的实时集群进行处理。
自研 WeiPig 框架

为了降低开发人员上手实时任务开发的门槛,我们自行研发了一个 WeiPig 框架。
它具有如下四个主要特点:
配置化开发。对于一些简单的开发需求,我们只需编写 WeiPig 开发文件,便可实现。
插件式编程。它提供一个插件式编程的编码规范。对于初期的一些功能需求,我们按照相应的规范进行编码,即我们通过编写
WeiPig 文件,来满足各种需求。
通用解决方案。因为 WeiPig 是一个针对实时流而开发的应用框架,所以它需要满足供应链上所有不同类型的实时流需求。
统一贡献机制。使不同的业务团队,能够按照同一套规范来进行相应的插件开发,并提供相应的插件功能。同时,他们也可以按照同样的规范和机制,来使用其他团队所提供的功能插件。
同时,我们需要通过该 WeiPig 框架,让所有开发人员的工作模式“沉淀”下去,实现公司内各个部门的共享与协作。
统一监控平台
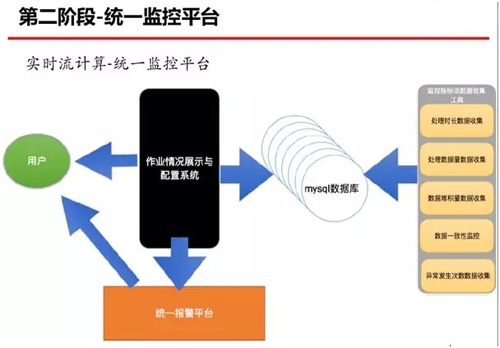
如前所述,在第一阶段,我们的监控实现方式基本上是:靠那些运行在不同服务器上的脚本,进行日志数据的采集,然后再发送报警邮件。
而进入第二阶段之后,我们利用如上图所示的实时流统一计算与监控平台,对作业情况予以了展示与配置。
即:该系统既可以展示相应的数据监控指标,又可以对数据监控指标进行相应的报警配置。
而这些监控指标数据都是通过不同的搜集工具进行采集,然后录入到 MySQL 数据库之中。

上图是第二阶段相应的成果。虽然此时已经有了 WeiPig 开发框架,但是我们的人工工作量依然不少。
由于 WeiPig 的插件主要是由平台方的几名开发人员来实现,因此插件数量不但较少,而且他们的工作量也达到了
80%。
另外,代码的重复率则仅占 50% 左右,这直接导致了异常排查的效率仍处于较低的水平。
同时,在监控配置上,我们仍需要手动配置,以及通过编写脚本,来搜集相关的指标数据。

在第二阶段之后,我们遗留下了不少问题,包括:
权限机制的欠缺
缺乏统一的资源调度
问题排查相对较慢
碎片资源相对较多(主要是因为我们使用的都是些小集群,这导致产生了大量遗留的冗余资源,闲置在系统中)
缺乏高可靠的保障
开发效率较低
实时流计算平台发展

在步入实时流计算平台的第三阶段之后,我们提高了相应的宏观目标,即:
提高公司的开发生产效率,节省重复建设的成本。
可视化各项操作。

上图是当前实时流计算平台的架构图。数据流逻辑如下:
用户通过 UI 交互客户端、以及 Weiclient 等交互模块,将作业提交给控制中心。
控制中心进行初步的权限校验和资源审核之后,将资源提交给任务调度。
任务调度将相应的作业提交给对应的集群 Weibox。
如果作业提交成功,Weibox 会把相应的作业信息重新返回给控制中心。
控制中心将作业通过用户交互客户端返回给用户结果。同时,它会将作业信息同步给管理服务后台。
用户通过管理服务后台的客户端,去操作自己在集群上面的功能。控制中心既能减少已占用的资源,又能为每一个团队实现资源控制。
控制中心初现

由于前期各种作业(如 Storm)在向集群提交的时候,许多开发人员会自行配置一个本地环境,以实现直接提交,这就造成了平台方很难对集群进行有效的管控。
因此对于我们第三阶段的控制中心而言,其主要目标是:
解决作业随意提交,治理集群上作业混乱的现象。
对集群资源进行统一管理,从而避免过多的资源浪费。

上图是实时流计算平台的控制中心架构图。其流程如下:
“基础模块”通过权限校验和资源审核,将作业提交给“作业上线流程”服务。
“作业上线流程”调用后置的检查模块,检查该作业是否在集群上运行成功,以及判断该作业所占用的资源、是否为它在提交时指定了资源量。
如果“作业上线流程”服务提交作业成功,那么“资源决策服务”调用动态资源调节模块,在集群上定时(如:每小时或每天)检查该作业所使用和处理的数据量,以及每条数据的处理时长。籍此,该模块运用简单的公式,来判断该作业是否需要占这么多资源。
上述提到过,一些开发人员可能会通过在自己的本机上配置相应的作业提交环境,以实现将作业提交到集群之中。
那么为了管控对应的业务组在集群上占用的资源量,我们在“资源决策服务”里,调用到了作业识别模块。
资源配置策略

为了提高公司的生产开发效率,我们在第三阶段实施了资源配置策略。同时,我们的核心目标点是:通过第二阶段的
WeiPig 开发框架,来鼓励各个业务团队贡献相应的插件。
其实 WeiPig 是一套规范协议,大家在贡献插件之前需要增加学习上的投入。因此,对于一些已经实施了计算能力的业务方来说,虽然有利于将旧平台迁移过来,但是他们不太愿意投入此类学习的成本。
所以我们想出了用资源去换取 WeiPig 前向发展的方法。我们将所有的平台资源按照基础资源、弹性资源、奖励资源和平台资源,四个方向进行划分。
其中基础资源仅占 1%,基本上只有一、两台机器。弹性资源有 20%,各个公司根据业务量和业务等级进行划分,当业务量多的时候,每一个业务都可以有自己的重要程度和优先级。
值得一提的是:奖励资源为 30%。它通过两方面标准:WeiPig 里贡献的 Function 数量,和这些通用
Function 会被多少业务方所使用到,来进行公式算法上的衡量。
如果你贡献的多,而且被其他业务方使用的也比较多,那么我们就会从所有平台资源的 30% 中,给你划分出更多的资源。
实时对账系统

为了满足某些高成功率场景的需求,我们在第三阶段自行设计了一个实时对账系统。
该系统的主要成绩是:满足实时计算平台完成 6 个 9 的数据成功率需求。

上图是实时对账系统的一个简单架构图。在数据处理开始时,我们会将数据写入实时对账系统,并打上开始标志。
同时,实时对账系统会将该数据的开始处理、和结束处理的标志,存放到存储服务上。
而图中下方的离线定时服务,会定时查询实时对账系统,并进行如下判断:
如果一条数据既有入账,又有根据处理结束值所求的出账,则认为该条数据已处理完成,即对账成功。
如果一条数据只有数据处理的开始,却没有处理结束的标志,则该条数据可能出现被丢掉的情况,我们需要重试。
如果一条数据只有数据处理结束,却没有数据处理成功的标志,则会发出相应的报警,我们需要查找相应的问题。
稳定性服务平台

另外,在第三阶段,我们将第二阶段的“统一监控平台”升级成了“稳定性服务平台”。
其目标有如下三点:
通用监控指标的数据统一生成。前面在第二阶段的监控统一平台中,我们必须在界面上去配置要监控的指标项目,通过编写相应的采集代码,然后把脚本部署到服务器上,以方便监控的采集。
但是在第三阶段的稳定性服务平台上,一个作业被提交到集群上之后,稳定性服务平台会对集群上处理的数据量、处理延迟、错误量等通用指标进行统一生成。
集群资源负载均衡的监控。其实 Storm 不像 Hadoop、Flink、Yum,它并没有资源调度的管理系统。
因此,它在自己做管理资源时,会出现在一个集群中,某个服务器的 CPU 利用率已达 90%,而其他服务器的
CPU 利用率只占有 50%~60% 的情况。所以我们自行研发了对集群资源负载均衡的监控。
监控指标采集平台,统一所有监控数据的采集。

这里展示的是实时流计算平台稳定性服务的架构图。左侧的数据采集平台包括:Storm 指标项目数据收集、Kafka
数据堆积量的数据收集、日志收集平台、监控脚本运行平台、和服务器硬件资源的收集。
这是一个比较简易的、便捷的资源负载均衡的监控服务。完成统一采集之后,系统调用数据存储服务,经由服务平台的管理服务平台、运维服务平台、和第三方服务平台,对外面开发人员提供相应的服务。

上图是第三阶段相应的成果。目前,我们的平台每天能处理大约一千多亿的数据量,TPS 大约有百万每秒,作业个数则每天约有
150~200 个。
如今无论是多媒体相关的数字计算需求,还是微博相关的处理需求,我们的人工工作量已相对较少了,主要的工作量集中在编写
WeiPig 相应的配置文件上。相应的代码重复率也比较低,同样主要集中在 WeiPig 文件上。
另外,由于我们主要是到 HDFS 上去搜集和管控相应的日志,因此异常排查的效率适中。
而对于监控方式而言,我们大部分采用的是自动生成的方式,所以只对一些特殊要求才进行监控配置。

当然,目前的实时流计算平台仍有两个遗留问题:
缺乏系统性的资源调度。我们需要有一个资源调度系统,来实时获知集群上的作业到底应该运行在哪一台服务器上。
目前我们采用的一种简易方式是:搜集各台服务器上的资源情况,然后用自己的程序进行判断和处理。如果某一台机器利用率高于其他服务器20%的话,那么我们认为其负载是不均衡的。
日志收集方案不统一。
总结 DQRA 设计模式

我们在实时流计算开发的过程中,一边搭建业务平台,一边解决了不少问题。因此我们总结出了一套 DQRA
的设计模式。
DQRA 详解

它们分别是:
Difficulty(逻辑复杂度)
Quantity(数据量)
Reliability(可靠性)
Asynchronous(异步时序性)
因此,我们认为:面对大多数的需求,我们可以把问题的实现拆解为上述四个属性中的某种。
例如:逻辑复杂度有难、中、易;数据量有大、中、小;可靠性是高、中、弱;等方面。

上述便是 DQRA 可能出现的不同组合,以及所对应的不同解决方法。
DQRA 案例分析

下面我们会介绍一个简单案例,它包含如下特性:
D 难,表示实现的复杂度,即实时流作业中需要处理的逻辑比较难。
Q 中,表示数据量可能一般,可能是从几千万到十亿之间。
R 高,表示可靠性高,即成功率要求高,如前面提到的 6 个 9 的数据处理成功率。

具体来说,它是一个图像分析与处理类系统,需要具有持续稳定的服务保证。因此,系统稳定是第一位的。
其次,它要求数据处理的成功率大于 6 个 9,从而能应对单日 5000 万的数据量。
因此,我们通过上述三个方面来实现该系统的需求:
首先,针对系统的稳定性,我们采用的是内网和阿里云的“双保险”网络部署方式。
其次,由于涉及到图片的下载,而我们在做分析时,调用的是在线模型预测方式。
因此,为了避免可能出现的图片分析失败,我们采用了实时对账系统,实现了必要的重试处理。
|








