| 编辑推荐: |
本文来自于infoq,本文从去哪儿网使用消息队列所碰到的各种问题出发探讨去哪儿网消息队列的设计与实现。
|
|
背景
2012 年,随着公司业务的快速增长,公司当时的单体应用架构很难满足业务快速增长的要求,和其他很多公司一样,去哪儿网也开始了服务化改造,按照业务等要素将原来庞大的单体应用拆分成不同的服务。那么在进行服务化改造之前首先就是面临是服务化基础设施的技术选型,其中最重要的就是服务之间的通信中间件。一般来讲服务之间的通信可以分为同步方式和异步方式。同步的方式的代表就是
RPC,我们选择了当时还在活跃开发的 Alibaba Dubbo(在之后 Dubbo 官方停止了开发,但是最近
Dubbo 项目又重新启动了)。
异步方式的代表就是消息队列 (Message Queue),MQ 在当时也有很多开源的选择:RabbitMQ,
ActiveMQ, Kafka, MetaQ(RocketMQ 的前身)。首先因为技术栈我们排除了
erlang 开发的 RabbitMQ,而 Kafka 以及 Java 版 Kafka 的 MetaQ
在当时还并不成熟和稳定。而 ActiveMQ 在去哪儿网已经有很多应用在使用了,但是使用过程中并不一帆风顺:宕机,消息丢失,消息堵塞等问题屡见不鲜,而且
ActiveMQ 发展多年,代码也非常复杂,想要完全把控也不容易,所以我们决定自己造一个轮子。
问题
如果我们要在服务化拆分中使用消息队列,那么我们需要解决哪些问题呢?首先去哪儿网提供了旅游产品在线预订服务,那么就涉及电商交易,在电商交易中我们认为数据的一致性是非常关键的要素。那么我们的
MQ 必须提供一致性保证。
MQ 提供一致性保证又分为两个方面:发消息时我们如何确保业务操作和发消息是一致的,也就是不能出现业务操作成功消息未发出或者消息发出了但是业务并没有成功的情况。举例来说,支付服务使用消息通知出票服务,那么不能出现支付成功,但是消息没有发出,这会引起用户投诉;但是也不能出现支付未成功,但是消息发出最后出票了,这会导致公司损失。总结一下就是发消息和业务需要有事务保证。一致性的另一端是消费者,比如消费者临时出错或网络故障,我们如何确保消息最终被处理了。那么我们通过消费
ACK 和重试来达到最终一致性。
而服务端设计,在当时我们考虑的并不多,我们原计划只在交易环节中使用自己开发的 MQ,经过对未来数据的预估我们选择数据库作为
MQ Server 的消息存储,但是随着 MQ 在各系统中的大量应用,就不仅限于交易场景了,而且大家都期望所有场景中只使用一套
API,所以后来消息量迅速增长,迫使我们对存储模型进行了重新设计。再加上旅游产品预定的特征,大部分预定都是未来某个时间点的,这个时间可长可短,短的话可能是几个小时,长的话可能是半年以上,那么我们对延时消息的需求也很强烈。那么这种延时时间不固定的方式也对服务端设计提出了挑战。
接下来本文会从客户端一致性设计和服务端存储模型两方面进行讨论。
客户端一致性
提到一致性,大家肯定就想到事务,而一提到事务,肯定就想到关系型数据库,那么我们是不是可以借助关系型
DB 里久经考验的事务来实现这个一致性呢。我们以 MySQL 为例,对于 MySQL 中同一个实例里面的
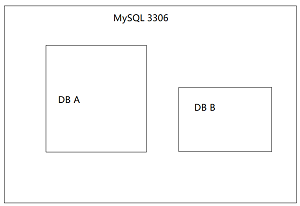
db,如果共享相同的 Connection 的话是可以在同一个事务里的。以下图为例,我们有一个 MySQL
实例监听在 3306 端口上,然后该实例上有 A,B 两个 DB,那么下面的伪代码是可以跑在同一个事务里的:
| begin
transaction
insert into A.tbl1(name, age) values('admin',
18);
insert into B.tbl2(num) values(20);
end transaction |
有了这层保证,我们就可以透明的实现业务操作和消息发送在同一个事务里了,首先我们在公司所有 MySQL
实例里初始化出一个 message db,这个可以放到自动化流程中,对应用透明。然后我们只要将发消息与业务操作放到同一个
DB 事务里即可。
我们来看一个实际的场景:在支付场景中,支付成功后我们需要插入一条支付流水,并且发送一条支付完成的消息通知其他系统。那么这里插入支付流水和发送消息就需要是一致的,任何一步没有成功最后都会导致问题。那么就有下面的代码:
| @Transactional
public void pay(Order order){
PayTransaction t = buildPayTransaction(order);
payDao.append(t);
producer.sendMessage(buildMessage(t));
} |
上面的代码可以用下面的伪代码解释:
| @Transactional
public void pay(Order order){
PayTransaction t = buildPayTransaction(order);
payDao.append(t);
//producer.sendMessage(buildMessage(t));
final Message message = buildMessage(t);
messageDao.insert(message);
// 在事务提交后执行
triggerAfterTransactionCommit(()->{
messageClient.send(message);
messageDao.delete(message);
});
} |
实际上在 producer.sendMessage 执行的时候,消息并没有通过网络发送出去,而仅仅是往业务
DB 同一个实例上的消息库插入了一条记录,然后注册事务的回调,在这个事务真正提交后消息才从网络发送出去,这个时候如果发送到
server 成功的话消息会被立即删除掉。而如果消息发送失败则消息就留在消息库里,这个时候我们会有一个补偿任务会将这些消息从消息库里捞出然后重新发送,直到发送成功。整个流程就如下图所示:

1.begin tx 开启本地事务
2.do work 执行业务操作
3.insert message 向同实例消息库插入消息
4.end tx 事务提交
5.send message 网络向 server 发送消息
6.reponse server 回应消息
7.delete message 如果 server 回复成功则删除消息
8.scan messages 补偿任务扫描未发送消息
9.send message 补偿任务补偿消息
10.delete messages 补偿任务删除补偿成功的消息
服务端存储模型
分析了客户端为了一致性所作的设计后,我们再来看看服务端的存储设计。我会从两个方面来介绍:类似 Kafka
之类的基于 partition 存储模型有什么问题,以及我们是如何解决的。
基于 partition 存储模型的问题
我们都知道 Kafka 和 RocketMQ 都是基于 partition 的存储模型,也就是每个
subject 分为一个或多个 partition,而 Server 收到消息后将其分发到某个 partition
上,而 Consumer 消费的时候是与 partition 对应的。比如,我们某个 subject
a 分配了 3 个 partition(p1, p2, p3),有 3 个消费者 (c1, c2,
c3)消费该消息,则会建立 c1 - p1, c2 - p2, c3 - p3 这样的消费关系。
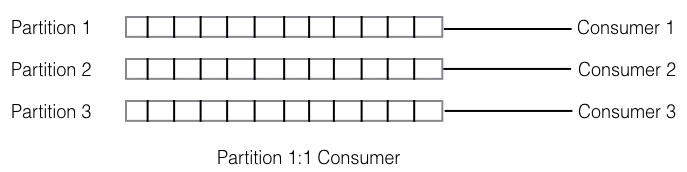
那么如果我们的 consumer 个数比 partition 个数多呢?则有的 consumer
会是空闲的。
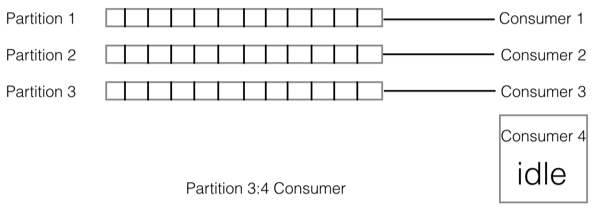
而如果 partition 个数比 consumer 个数多呢?则可能存在有的 consumer
消费的 partition 个数会比其他的 consumer 多的情况。
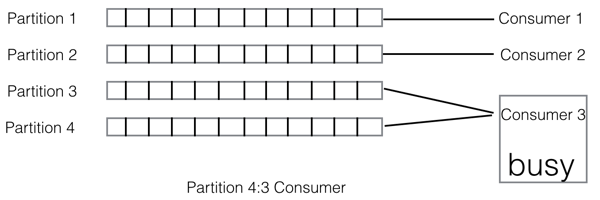
那么合理的分配策略只有是 partition 个数与 consumer 个数成倍数关系。
以上都是基于 partition 的 MQ 所带来的负载均衡问题。因为这种静态的绑定的关系,还会导致
Consumer 扩容缩容麻烦。也就是使用 Kafka 或者 RocketMQ 这种基于 partition
的消息队列时,如果遇到处理速度跟不上时,光简单的增加 Consumer 并不能马上提高处理能力,需要对应的增加
partition 个数,而特别在 Kafka 里 partition 是一个比较重的资源,增加太多
parition 还需要考虑整个集群的处理能力;当高峰期过了之后,如果想缩容 Consumer 也比较麻烦,因为
partition 只能增加,不能减少。
跟扩容相关的另外一个问题是,已经堆积的消息是不能快速消费的。比如开始的时候我们分配了 2 个 partition,由
2 个 Consumer 来消费,但是突然发送方大量发送消息 (这个在日常运维中经常遇到),导致消息快速的堆积,这个时候我们如何能快速扩容消费这些消息呢?其实增加
partition 和 Consumer 都是没有用的,增加的 Consumer 爱莫能助, 因为堆积的那
3 个 partition 只能由 2 个 Consumer 来消费,这个时候你只能纵向扩展,而不能横向扩展,而我们都知道纵向扩展很多时候是不现实的,或者执行比较重的再均衡操作。

去哪儿消息队列存储模型
上面已经介绍了基于 partition 的存储模型存在的问题,那么这些问题对于我们是问题吗?或者我们的场景是否能克服这些问题呢?
现在去哪儿网的系统架构基本上都是消息驱动的,也就是绝大多数业务流程都是靠消息来驱动,那么这样的架构有什么特征呢:
1.消息主题特别多 现在生产上已有 4W+ 消息主题。这是业务中使用的消息与数据流处理中使用的最大的不同,数据流中一般消息主题少,但是每个消息主题的吞吐量都极大。而业务中的消息是主题极多,但是有很多主题他的量是极小的。
2.消息消费的扇出大 也就是一个消息主题有几十个甚至上百个不同的应用订阅是非常常见的。以去哪儿酒店订单状态变更的消息为例,目前有将近
70 多个不同的系统来订阅这个消息。
结合前面对基于 partition 的存储模型的讨论,我们觉得这种存储模型不太容易符合我们的需求。
虽然我们并不想采用基于 partition 的存储模型,但是 Kafka 和 RocketMQ 里很多设计我们还是可以学习的:
1.顺序 append 文件,提供很好的性能
2.顺序消费文件,使用 offset 表示消费进度,不用给每个消息记录消费状态,成本极低
3.将所有 subject 的消息合并在一起,减少 parition
数量,单一集群可以支撑更多的 subject(RocketMQ)
在设计 QMQ 的存储模型时,觉得这几点是非常重要的。那如何在不使用基于 partition 的情况下,又能得到这些特性呢?正所谓有前辈大师说:计算机中所有问题都可以通过添加一个中间层来解决,一个中间层解决不了那就添加两个。
我们通过添加一层拉取的 log(pull log) 来动态映射 consumer 与 partition
的逻辑关系,这样不仅解决了 consumer 的动态扩容缩容问题,还可以继续使用一个 offset
表示消费进度。而 pull log 与 consumer 一一对应。
下图是 QMQ 的存储模型
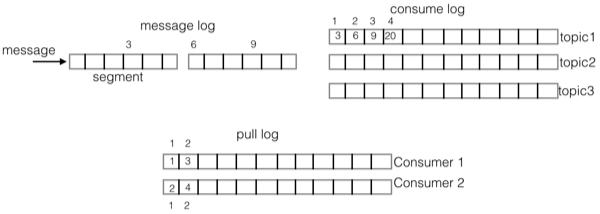
先解释一下上图中的数字的意义。上图中方框上方的数字,表示该方框在自己 log 中的偏移,而方框内的数字是该项的内容。比如
message log 方框上方的数字:3,6,9 表示这几条消息在 message log 中的偏移。而
consume log 中方框内的数字 3,6,9,20 正对应着 messzge log 的偏移,表示这几个位置上的消息都是
topic1 的消息,consume log 方框上方的 1,2,3,4 表示这几个方框在 consume
log 中的逻辑偏移。下面的 pull log 方框内的内容对应着 consume log 的逻辑偏移,而
pull log 方框外的数字表示 pull log 的逻辑偏移。
这样存储中有三种重要的 log:
1.message log 所有 subject 的消息进入该 log,消息的主存储
2.consume log consume log 存储的是 message
log 的索引信息
3.pull log 每个 consumer 拉取消息的时候会产生
pull log,pull log 记录的是拉取的消息在 consume log 中的 sequence
那么消费者就可以使用 pull log 上的 sequence 来表示消费进度,这样一来我们就解耦了
consumer 与 partition 之间的耦合关系,两者可以任意的扩展。
延迟消息队列存储模型
除了对实时消息的支持,QMQ 还支持了任意时间的延时消息, 在开源版本的 RocektMQ 里提供了多种固定延迟
level 的延时消息支持,也就是你可以发送几个固定的延时时间的延时消息,比如延时 10s, 30s…,但是基于我们现有的业务特征,我们觉得这种不同延时
level 的延时消息并不能满足我们的需要,我们更多的是需要任意时间延时。在 OTA 场景中,客人经常是预订未来某个时刻的酒店或者机票,这个时间是不固定的,我们无法使用几个固定的延时
level 来实现这个场景。
我们的延时 / 定时消息使用的是两层 hash wheel timer 来实现的。第一层位于磁盘上,每个小时为一个刻度,每个刻度会生成一个日志文件,根据业务特征,我们觉得支持两年内任意时间延时就够了,那么最多会生成
2 * 366 * 24 = 17568 个文件。第二层在内存中,当消息的投递时间即将到来的时候,会将这个小时的消息索引
(偏移量,投递时间等) 从磁盘文件加载到内存中的 hash wheel timer 上。
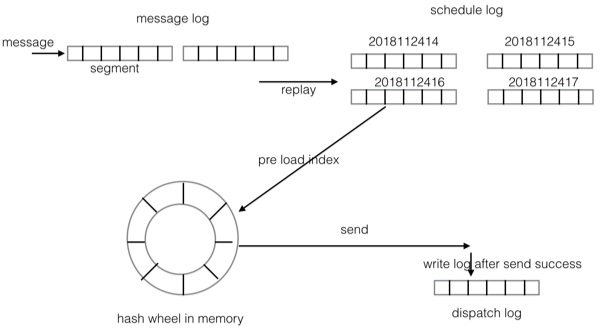
在延时 / 定时消息里也存在三种 log:
1.message log 和实时消息里的 message log
类似,收到消息后 append 到该 log,append 成功后就立即返回
2.schedule log 按照投递时间组织,每个小时一个。该
log 是回放 message log 后根据延时时间放置对应的 log 上,这是上面描述的两层 hash
wheel timer 的第一层,位于磁盘上
3.dispatch log 延时 / 定时消息投递后写入,主要用于在应用重启后能够确定哪些消息已经投递
总结
消息队列是构建微服务架构很关键的基础设施,本文根据我们自己的实际使用场景,并且对目前市面上一些活跃的开源产品进行对比,提出去哪儿网的消息队列的设计与实现。本文只是从宏观架构上做出一些探讨,具体的实现细节也有很多有趣的地方,目前去哪儿网的消息队列
QMQ 也已经在GitHub上开源,欢迎大家试用,欢迎 PR,谢谢。
|








