| 编辑推荐: |
本文来自于infoq,本文主要介绍SCF
框架作为 58 分布式架构的基础组件,支撑了 58 集团内部万级别节点的网络调用的基本调用和监控相关内容。
|
|
前 言
RPC 是远程过程调用(Remote Procedure Call)的缩写,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。举例来说,部署在
A 节点上的应用调用部署在 B 节点上的应用提供的接口,A 节点需要将调用的数据信息通过网络传递到
B 节点,B 节点根据接收到的数据信息找到具体的接口执行,并将执行的结果通过网络返回给节点 A。
RPC 框架封装网络传输、序列化、负载均衡、故障剔除等通用能力,使得 A 节点可以像调用本地方法一样简单地调用远程接口。
SCF 是 58 自主研发的 RPC 框架,致力于在分布式环境下提供高性能、高可靠和透明化的 RPC
远程调用方案。
服务管理平台是基于 SCF 框架的服务治理平台,具有服务节点自动注册与发现、负载均衡、服务鉴权、全方位监控、完善的告警等特点。
整体架构

SCF 服务方: 指使用 SCF 框架服务端能力,提供可以被远程调用的接口的应用。
SCF 调用方: 指使用 SCF 框架客户端能力,调用服务方提供接口的应用。
控制中心: 核心是维护 SCF 服务方和 SCF 调用方之间的调用关系,生成调用方需要使用的服务配置信息,支持当调用关系调整时,实时向调用方推送新的配置信息。
监控中心: 统一收集服务方和调用方的流量数据,并提供实时告警功能,可以提高业务人员对服务的整体把控能力,帮助服务负责人提高服务稳定性。
可视化管理平台: 提供给业务的管理界面,可以查看服务方和调用方的流量监控数据、配置服务方和调用方的调用信息、设置丰富的告警等。
SCF 服务方和 SCF 调用方构成了 SCF 框架的主要组成部分,可以实现基本的 RPC 远程调用。
控制中心、监控中心和可视化管理平台三个部分属于服务管理平台,是对 SCF 框架基本能力的补充,对服务的治理提供了有效的手段。
SCF 框架
SCF 调用模式

RPC 框架最基本的能力是提供远程调用,SCF 提供了同步调用和回调调用两种调用模式。
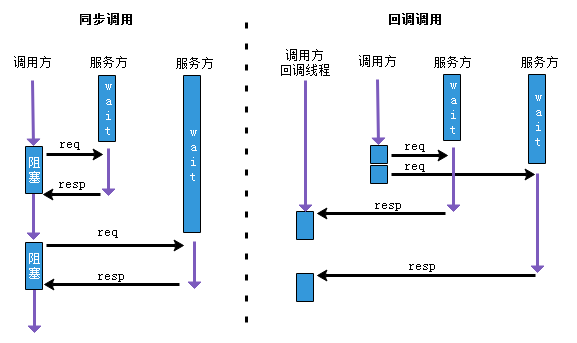
同步调用
同步调用是业务使用最多的一种方式,也是框架默认的调用方式。调用方在调用服务的接口时,执行调用的线程会被阻塞,等待调用完成。如果服务方返回了结果或等待时间超过设置的超时时间,线程被唤醒,获取返回结果或捕获超时的异常。
回调调用
回调调用是指调用服务接口之后,接口立即返回,调用接口的线程不需要等待服务端的返回结果,因此不存在阻塞的情况。如果服务端有返回结果或等待超过设置的超时时间,由框架中单独的回调线程处理返回的结果或超时异常。因此在调用前必须设置接口的回调实现类。
超时处理
在实际生产环境中,服务端方健康状况不可控、网络情况复杂可能出现各种异常情况。因此,上述同步或回调调用中,不是所有的调用都一定能得到服务方返回的结果,为了避免调用方无限制的等待,必须设置调用的超时时间。在超过设置的时间内没有得到返回结果,就通过超时异常的方式通知调用方。
SCF 中使用经典的 TimeWheel 算法实现调用任务的过期。

内部使用数组模拟类似时钟的环形数据结构,每一个格子代表一个时间间隔,每个格子对应一个任务的链表,在添加过期任务时,通过过期时间和当前时间计算出任务应该在第几个格子里并计算应该是走到第几圈时触发超时。
假设图中每个格子表示 100ms,则一圈代表 800ms,当前是走到第 1 圈的第 2 个格子。如果任务
500ms 后超时,(500+200)% 800=7,因此将任务放到第 7 个格子对应的链表中,并标记第
1 圈超时。如果任务 1000ms 后超时,(1000+200)% 800=4,(1000+200)/800=1,因此将任务放入第
4 个格子对应的链表中,并标记第 2 圈超时。
上述过期算法存在有两个关键点需要注意:
1.过期时间存在误差,误差范围是每个格子代表的时间。
2.扫描任务过期的线程应该和执行过期操作的线程独立,避免执行过期操作影响到后续任务的过期扫描。
序列化
在网络中传输的数据只能是 0 和 1 组成的二进制数据,而通常我们请求的数据信息是面向对象中具体类的对象,序列化就是实现对象的状态信息转换为可以存储或传输的形式的过程,反序列化是序列化的逆过程。
SCF 框架采用了自定义的序列化实现方式,下面主要介绍序列化是如何实现非对称序列化和泛型序列化。
非对称序列化
互联网是一个变化非常快的行业,在发布一个接口之后,随着业务的发展必然会产生对接口传输对象进行调整的情况,因此就有了增加或删除类中的成员变量的需求。如果不能支持服务方和调用方的类存在非对称的成员,业务升级将会非常麻烦。
SCF 序列化对非对称类处理的思想是对类的成员变量进行编号,在写数据流的过程中,成员变量根据编号
(id)+ 数据长度 (length)+ 数据 (value) 的方式依次写入二进制流,反序列化则从流中先读取
id,判断需要赋值的类是否存在该 id 的成员,如果存在继续读取长度和数据部分,如果不存在该 id,则根据读取的长度跳过二进制流中该
id 成员对应的数据部分,从而实现忽略不存在成员的目的。

针对以上两个版本的实体,左边是编号 1、2、3 的成员,右边是 1、4 的成员。序列化和反序列化过程如下:

使用基本的 id + length + value 的方式可以实现非对称序列化,但是对所有的成员都需要写入
id 和 length 两个特殊的标识,增加了二进制数据的大小。而对于基本类型,其实长度是已知的。通过对数据类型按下面
type 进行划分:

只需要 3bit 就可以表示说要的数据类型,因此采用 tag = (id << 3)|type
的方式,将 type 嵌入到 tag 字段中,实现基本类型的数据只需要写入 tag 数据,不需要写入
length 字段,有效减少二进制数据大小。
泛型序列化
泛型序列化是指在类中存在非具体类型成员变量(Java 中的基类 Object)的对象序列化。
SCF 中使用全限定类名 hash 的方式,为每一个类生成唯一 typeId,在写入泛型成员时,先写入类的
typeId,再写入 value 数据。读取时一样通过先读取 typeId,查找具体类型,再根据类型读取
value 数据。
服务注册与发现
调用方通过网络调用服务方,必须要知道服务方节点的 IP 列表,才能发起调用。最原始的方式是通过在调用方使用配置文件的方式指定,但是这种方式在实际使用中不能动态感知服务方节点的变化,不够灵活也无法时间服务的自动化扩缩容。
服务注册与发现即自动发现服务的节点信息,并且调用方能及时感知服务方节点的变化情况,自动调整流量切换到新的节点。

SCF 使用 ETCD 集群管理服务节点,每一个服务节点对应 ETCD 中的一个 key,并且为
key 设置一个 TTL 过期时间。通过心跳刷新 TTL 的方式维持服务节点在线状态。为隔离 ETCD
集群与业务部署环境,避免服务节点的增加造成 ETCD 集群的连接数过高等问题,封装了一层服务管理节点做代理,转发服务心跳并维护服务方和调用方的状态信息。

当服务节点下线,ETCD 集群通知服务管理节点对应的 key,服务管理节点实时推送最新的服务节点列表信息给调用方,调用方动态更新并切换流量。同时为了兼容推送失败的异常情况,增加了调用方定时根据时间戳校验拉取的策略,保证服务节点信息的最终一致。
监控数据采集与存储
服务在生产环境运行是否正常?当前服务流量是多少?有没有出现调用异常或超时的情况?这些都是服务的负责人需要关注的问题。
数据采集
对于服务方来说,一个服务有多个方法,同时部署在多个节点上,同时会被不同的调用方调用不同的方法。同样一个调用方也会同时调用多个服务的不同的方法。导致整体的收集维度是服务方和调用方的乘积量级,应该如何有效采集数据呢?
下面给大家介绍一下针对 58RPC 框架的调用数据的采集方案。

从总的架构图中可以看到,为了避免流量数据收集的压力,尽可能充分利用各层的计算能力分摊统一汇总的压力。
收集插件充分利用服务节点的计算能力,先进行本地数据聚合,以分钟为单位进行数据上报。
插件上报根据服务名 hash,尽可能保证相同服务不同节点的数据发送到同一个收集服务器,收集服务器再进行一次聚合,进一步减少
Cache 统一计数的压力。
数据存储
首先针对服务的调用信息,我们来看一下针对一个调用需要存储的数据情况。

对于同一个维度的监控数据,以上字段中只有时间戳、次数和耗时数据是和实际的流量相关的,服务名 + 服务节点
+ 函数名称 + 调用者 + 类型标识对同一个维度是相同的,因此为了减少数据的存储,我们定义一个映射的规则(S[demo]SN[10.0.0.1]SF[Service.get()]C[callerdemo]
表示服务方 demo 的 10.0.0.1 机器上的 Service.get() 方法被调用方 callerdemo
调用),将以上 5 个收集元信息映射成唯一的维度字符串,再把所有的维度字符串分别生成一个唯一的 cid,实际存储的监控数据中使用
cid 替换以上 5 个收集元信息。

在实际的应用中,最开始版本只存储调用的元数据,在展示的时候根据展示的维度进行数据查询聚合导致监控数据展示特别慢,因为需要经过大量的数据查询和合并,为了调高监控数据的查询速度,使用了写扩散的方式,针对一个调用元数据,做如下图所示的扩散:

从上图可以看出,实际存储的时候将未来经常需要展示的数据先计算好直接存入库中,展示的时候只需要直接根据维度的
cid 直接查询结果即可,有效提高了查询速度。
总 结
SCF 框架作为 58 分布式架构的基础组件,支撑了 58 集团内部万级别节点的网络调用。SCF
框架经过多次的迭代,从最初的最简单的远程调用到现在服务治理周边功能的完善,后续也将不断优化,欢迎感兴趣的同学一起沟通交流。
|








