| БрМЭЦМі: |
БОЮФРДздгкinfoqЃЌЮФеТЗжЯэСЫ
ЭЈаХВуЕФПЩППадЩшМЦЁЂвьВНЛЏдРэвдМАRPC ЕїгУВуЕФПЩППадЩшМЦЕШФкШнЁЃ
|
|
1. БГОА
1.1 ЗжВМЪНЕїгУв§ШыЕФЙЪеЯ
дкДЋЭГЕФЕЅЬхМмЙЙжаЃЌвЕЮёЗўЮёЕїгУЖМЪЧБОЕиЗНЗЈЕїгУЃЌВЛЛсЩцМАЕНЭјТчЭЈаХЁЂавщеЛЁЂЯћЯЂађСаЛЏКЭЗДађСаЛЏЕШЃЌЕБЪЙгУ
RPC ПђМмНЋвЕЮёгЩЕЅЬхМмЙЙИФдьГЩЗжВМЪНЯЕЭГжЎКѓЃЌБОЕиЗНЗЈЕїгУНЋбнБфГЩПчНјГЬЕФдЖГЬЕїгУЃЌЛсв§ШывЛаЉаТЕФЙЪеЯЕуЃЌШчЯТЫљЪОЃК
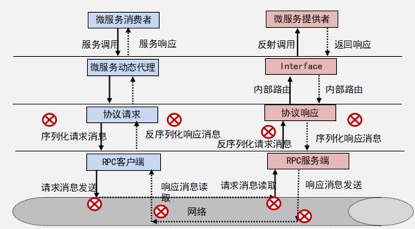
ЭМ 1 RPC ЕїгУв§ШыЕФЧБдкЙЪеЯЕу
аТв§ШыЕФЧБдкЙЪеЯЕуАќРЈЃК
1ЃЎЯћЯЂЕФађСаЛЏКЭЗДађСаЛЏЙЪеЯЃЌР§ШчЃЌВЛжЇГжЕФЪ§ОнРраЭЁЃ
2ЃЎТЗгЩЙЪеЯЃКАќРЈЗўЮёЕФЖЉдФЁЂЗЂВМЙЪеЯЃЌЗўЮёЪЕР§ЙЪеЯжЎКѓУЛгаМАЪБЫЂаТТЗгЩБэЃЌЕМжТ RPC ЕїгУШдШЛТЗгЩЕНЙЪеЯНкЕуЁЃ
3ЃЎЭјТчЭЈаХЙЪеЯЃЌАќРЈЭјТчЩСЖЯЁЂЭјТчЕЅЭЈЁЂЖЊАќЁЂПЭЛЇЖЫРЫгПНгШыЕШЁЃ
1.2 ЕкШ§ЗНЗўЮёвРРЕ
RPC ЗўЮёЭЈГЃЛсвРРЕЕкШ§ЗНЗўЮёЃЌАќРЈЪ§ОнПтЗўЮёЁЂЮФМўДцДЂЗўЮёЁЂЛКДцЗўЮёЁЂЯћЯЂЖгСаЗўЮёЕШЃЌетжжЕкШ§ЗНвРРЕЭЌЪБвВв§ШыСЫЧБдкЕФЙЪеЯЃК
1ЃЎЭјТчЭЈаХРрЙЪеЯ, ШчЙћВЩгУ BIO ЕїгУЕкШ§ЗНЗўЮёЃЌКмгаПЩФмБЛзшШћЁЃ
2ЃЎЁАбЉБРаЇгУЁБЕМжТЕФМЖСЊЙЪеЯЃЌР§ШчЗўЮёЖЫДІРэТ§ЕМжТПЭЛЇЖЫЯпГЬБЛзшШћЁЃ
3ЃЎЕкШ§ЗНВЛПЩгУЕМжТ RPC ЕїгУЪЇАмЁЃ
ЕфаЭЕФЕкШ§ЗНвРРЕЪОР§ШчЯТЃК
ЭМ 2 RPC ЗўЮёЖЫЕФЕкШ§ЗНвРРЕ
2. ЭЈаХВуЕФПЩППадЩшМЦ
2.1 СДТЗгааЇадМьВт
ЕБЭјТчЗЂЩњЕЅЭЈЁЂСЌНгБЛЗРЛ№ЧН Hang зЁЁЂГЄЪБМф GC ЛђепЭЈаХЯпГЬЗЂЩњЗЧдЄЦквьГЃЪБЃЌЛсЕМжТСДТЗВЛПЩгУЧвВЛвзБЛМАЪБЗЂЯжЁЃЬиБ№ЪЧвьГЃЗЂЩњдкСшГПвЕЮёЕЭЙШЦкМфЃЌЕБдчГПвЕЮёИпЗхЦкЕНРДЪБЃЌгЩгкСДТЗВЛПЩгУЛсЕМжТЫВМфЕФДѓХњСПвЕЮёЪЇАмЛђепГЌЪБЃЌетНЋЖдЯЕЭГЕФПЩППадВњЩњжиДѓЕФЭўаВЁЃ
ДгММЪѕВуУцПДЃЌвЊНтОіСДТЗЕФПЩППадЮЪЬтЃЌБиаыжмЦкадЕФЖдСДТЗНјаагааЇадМьВтЁЃФПЧАзюСїааКЭЭЈгУЕФзіЗЈОЭЪЧаФЬјМьВтЁЃ
аФЬјМьВтЛњжЦЗжЮЊШ§ИіВуУцЃК
1.TCP ВуУцЕФаФЬјМьВтЃЌМД TCP ЕФ Keep-Alive ЛњжЦЃЌЫќЕФзїгУгђЪЧећИі TCP
авщеЛЁЃ
2. авщВуЕФаФЬјМьВтЃЌжївЊДцдкгкГЄСЌНгавщжаЁЃР§Шч MQTT авщЁЃ
3. гІгУВуЕФаФЬјМьВтЃЌЫќжївЊгЩИївЕЮёВњЦЗЭЈЙ§дМЖЈЗНЪНЖЈЪБИјЖдЗНЗЂЫЭаФЬјЯћЯЂЪЕЯжЁЃ
аФЬјМьВтЕФФПЕФОЭЪЧШЗШЯЕБЧАСДТЗПЩгУЃЌЖдЗНЛюзХВЂЧвФмЙЛе§ГЃНгЪеКЭЗЂЫЭЯћЯЂЁЃзіЮЊИпПЩППЕФ NIO ПђМмЃЌNetty
вВЬсЙЉСЫаФЬјМьВтЛњжЦЃЌЯТУцЮвУЧвЛЦ№ЪьЯЄЯТаФЬјЕФМьВтдРэЁЃ
аФЬјМьВтЕФдРэЪОвтЭМШчЯТЃК
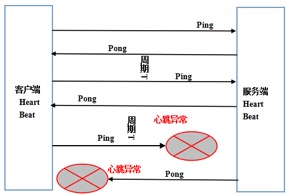
ЭМ 3 СДТЗаФЬјМьВт
ВЛЭЌЕФавщЃЌаФЬјМьВтЛњжЦвВДцдкВювьЃЌЙщФЩЦ№РДжївЊЗжЮЊСНРрЃК
1ЃЎPing-Pong аЭаФЬјЃКгЩЭЈаХвЛЗНЖЈЪБЗЂЫЭ Ping ЯћЯЂЃЌЖдЗННгЪеЕН Ping ЯћЯЂжЎКѓЃЌСЂМДЗЕЛи
Pong гІД№ЯћЯЂИјЖдЗНЃЌЪєгкЧыЧѓ - ЯьгІаЭаФЬјЁЃ
2ЃЎPing-Ping аЭаФЬјЃКВЛЧјЗжаФЬјЧыЧѓКЭгІД№ЃЌгЩЭЈаХЫЋЗНАДеедМЖЈЖЈЪБЯђЖдЗНЗЂЫЭаФЬј Ping
ЯћЯЂЃЌЫќЪєгкЫЋЯђаФЬјЁЃ
аФЬјМьВтВпТдШчЯТЃК
1ЃЎСЌај N ДЮаФЬјМьВтЖМУЛгаЪеЕНЖдЗНЕФ Pong гІД№ЯћЯЂЛђеп Ping ЧыЧѓЯћЯЂЃЌдђШЯЮЊСДТЗвбОЗЂЩњТпМЪЇаЇЃЌетБЛГЦзїаФЬјГЌЪБЁЃ
2ЃЎЖСШЁКЭЗЂЫЭаФЬјЯћЯЂЕФЪБКђШчКЮжБНгЗЂЩњСЫ IO вьГЃЃЌЫЕУїСДТЗвбОЪЇаЇЃЌетБЛГЦЮЊаФЬјЪЇАмЁЃ
ЮоТлЗЂЩњаФЬјГЌЪБЛЙЪЧаФЬјЪЇАмЃЌЖМашвЊЙиБеСДТЗЃЌгЩПЭЛЇЖЫЗЂЦ№жиСЌВйзїЃЌБЃжЄСДТЗФмЙЛЛжИДе§ГЃЁЃ
Netty ЕФаФЬјМьВтЪЕМЪЩЯЪЧРћгУСЫСДТЗПеЯаМьВтЛњжЦЪЕЯжЕФЃЌЫќЕФПеЯаМьВтЛњжЦЗжЮЊШ§жжЃК
1ЃЎЖСПеЯаЃЌСДТЗГжајЪБМф t УЛгаЖСШЁЕНШЮКЮЯћЯЂЁЃ
2ЃЎаДПеЯаЃЌСДТЗГжајЪБМф t УЛгаЗЂЫЭШЮКЮЯћЯЂЁЃ
3ЃЎЖСаДПеЯаЃЌСДТЗГжајЪБМф t УЛгаНгЪеЛђепЗЂЫЭШЮКЮЯћЯЂЁЃ
Netty ЕФФЌШЯЖСаДПеЯаЛњжЦЪЧЗЂЩњГЌЪБвьГЃЃЌЙиБеСЌНгЃЌЕЋЪЧЃЌЮвУЧПЩвдЖЈжЦЫќЕФГЌЪБЪЕЯжЛњжЦЃЌвдБужЇГжВЛЭЌЕФгУЛЇГЁОАЃЌСДТЗПеЯаНгПкЖЈвхШчЯТЃК
protected void
channelIdle(ChannelHandlerContext ctx, IdleStateEvent
evt) throws Exception {
ctx.fireUserEventTriggered(evt);
} |
СДТЗПеЯаЕФЪБКђВЂУЛгаЙиБеСДТЗЃЌЖјЪЧДЅЗЂ IdleStateEvent ЪТМўЃЌгУЛЇЖЉдФ IdleStateEvent
ЪТМўЃЌгУгкздЖЈвхТпМДІРэЃЌР§ШчЙиБеСДТЗЁЂПЭЛЇЖЫЗЂЦ№жиаТСЌНгЁЂИцОЏКЭДђгЁШежОЕШЁЃРћгУ Netty ЬсЙЉЕФСДТЗПеЯаМьВтЛњжЦЃЌПЩвдЗЧГЃСщЛюЕФЪЕЯжСДТЗПеЯаЪБЕФгааЇадМьВтЁЃ
2.2 ПЭЛЇЖЫЖЯСЌжиСЌ
ЕБЗЂЩњШчЯТвьГЃЪБЃЌПЭЛЇЖЫашвЊЪЭЗХзЪдДЃЌжиаТЗЂЦ№СЌНгЃК
1ЃЎЗўЮёЖЫвђЮЊФГжждвђЃЌжїЖЏЙиБеСЌНгЃЌПЭЛЇЖЫМьВтЕНСДТЗБЛе§ГЃЙиБеЁЃ
2ЃЎЗўЮёЖЫвђЮЊхДЛњЕШЙЪеЯЃЌЧПжЦЙиБеСЌНгЃЌПЭЛЇЖЫМьВтЕНСДТЗБЛ Rest ЕєЁЃ
3ЃЎаФЬјМьВтГЌЪБЃЌПЭЛЇЖЫжїЖЏЙиБеСЌНгЁЃ
4ЃЎПЭЛЇЖЫвђЮЊЦфЫќдвђЃЈР§ШчНтТыЪЇАмЃЉЃЌЧПжЦЙиБеСЌНгЁЃ
5ЃЎЭјТчРрЙЪеЯЃЌР§ШчЭјТчЖЊАќЁЂГЌЪБЁЂЕЅЭЈЕШЃЌЕМжТСДТЗжаЖЯЁЃ
ПЭЛЇЖЫМьВтЕНСДТЗжаЖЯКѓЃЌЕШД§ INTERVAL ЪБМфЃЌгЩПЭЛЇЖЫЗЂЦ№жиСЌВйзїЃЌШчЙћжиСЌЪЇАмЃЌМфИєжмЦк
INTERVAL КѓдйДЮЗЂЦ№жиСЌЃЌжБЕНжиСЌГЩЙІЁЃ
ЮЊСЫБЃжЄЗўЮёЖЫФмЙЛгаГфзуЕФЪБМфЪЭЗХОфБњзЪдДЃЌдкЪзДЮЖЯСЌЪБПЭЛЇЖЫашвЊЕШД§ INTERVAL ЪБМфжЎКѓдйЗЂЦ№жиСЌЃЌЖјВЛЪЧЪЇАмКѓОЭСЂМДжиСЌЁЃ
ЮЊСЫБЃжЄОфБњзЪдДФмЙЛМАЪБЪЭЗХЃЌЮоТлЪВУДГЁОАЯТЕФжиСЌЪЇАмЃЌПЭЛЇЖЫЖМБиаыБЃжЄздЩэЕФзЪдДБЛМАЪБЪЭЗХЃЌАќРЈЕЋВЛЯогк
SocketChannelЁЂSocket ЕШЁЃжиСЌЪЇАмКѓЃЌашвЊДђгЁвьГЃЖбеЛаХЯЂЃЌЗНБуКѓајЕФЮЪЬтЖЈЮЛЁЃ
РћгУ Netty Channel ЬсЙЉЕФ CloseFutureЃЌПЩвдЗЧГЃЗНБуЕФМьВтСДТЗзДЬЌЃЌвЛЕЉСДТЗЙиБеЃЌЯрЙиЪТМўМДБЛДЅЗЂЃЌПЩвджиаТЗЂЦ№СЌНгВйзїЃЌДњТыЪОР§ШчЯТЃК
future.channel().closeFuture().sync();
} finally {
// ЫљгазЪдДЪЭЗХЭъГЩжЎКѓЃЌЧхПезЪдДЃЌдйДЮЗЂЦ№жиСЌВйзї
executor.execute(new Runnable() {
public void run() {
try {
TimeUnit.SECONDS.sleep(3);//3 УыжЎКѓЗЂЦ№жиСЌЃЌЕШД§ОфБњЪЭЗХ
try {
// ЗЂЦ№жиСЌВйзї
connect(NettyConstant.PORT, NettyConstant.REMOTEIP);
} catch (Exception e) {
...... вьГЃДІРэЯрЙиДњТыЪЁТд
}
}); |
2.3 ЛКДцжиЗЂ
ЕБЮвУЧЕїгУЯћЯЂЗЂЫЭНгПкЕФЪБКђЃЌЯћЯЂВЂУЛгаеце§БЛаДШыЕН Socket жаЃЌЖјЪЧЯШЗХШы NIO ЭЈаХПђМмЕФЯћЯЂЗЂЫЭЖгСажаЃЌгЩ
Reactor ЯпГЬЩЈУшД§ЗЂЫЭЕФЯћЯЂЖгСаЃЌвьВНЕФЗЂЫЭИјЭЈаХЖдЖЫЁЃМйШчКмВЛавЃЌЯћЯЂЖгСажаЛ§бЙСЫВПЗжЯћЯЂЃЌДЫЪБСДТЗжаЖЯЃЌетЛсЕМжТВПЗжЯћЯЂВЂУЛгаеце§ЗЂЫЭИјЭЈаХЖдЖЫЃЌЪОР§ШчЯТЃК

ЭМ 4 СДТЗжаЖЯЕМжТЛ§бЙЯћЯЂУЛгаЗЂЫЭ
ЗЂЩњДЫЙЪеЯЪБЃЌЮвУЧЯЃЭћ NIO ПђМмФмЙЛздЖЏЪЕЯжЯћЯЂЛКДцКЭжиаТЗЂЫЭЃЌвХКЖЕФЪЧзїЮЊЛљДЁЕФ NIO ЭЈаХПђМмЃЌЮоТлЪЧ
Mina ЛЙЪЧ NettyЃЌЖМУЛгаЬсЙЉИУЙІФмЃЌашвЊЭЈаХПђМмздМКЗтзАЪЕЯжЃЌЛљгк Netty ЕФЪЕЯжВпТдШчЯТЃК
1ЃЎЕїгУ Netty ChannelHandlerContext ЕФ write ЗНЗЈЪБЃЌЗЕЛи ChannelFuture
ЖдЯѓЃЌЮвУЧдк ChannelFuture жазЂВсЗЂЫЭНсЙћМрЬ§ ListenerЁЃ
2ЃЎдк Listener ЕФ operationComplete ЗНЗЈжаХаЖЯВйзїНсЙћЃЌШчЙћВйзїВЛГЩЙІЃЌНЋжЎЧАЗЂЫЭЕФЯћЯЂЖдЯѓЬэМгЕНжиЗЂЖгСажаЁЃ
3ЃЎСДТЗжиСЌГЩЙІжЎКѓЃЌИљОнВпТдЃЌНЋЛКДцЖгСажаЕФЯћЯЂжиаТЗЂЫЭИјЭЈаХЖдЖЫЁЃ
ашвЊжИГіЕФЪЧЃЌВЂЗЧЫљгаГЁОАЖМашвЊЭЈаХПђМмзіжиЗЂЃЌР§ШчЗўЮёПђМмЕФПЭЛЇЖЫЃЌШчЙћФГИіЗўЮёЬсЙЉепВЛПЩгУЃЌЛсздЖЏЧаЛЛЕНЯТвЛИіПЩгУЕФЗўЮёЬсЙЉепжЎЩЯЁЃМйЖЈЪЧСДТЗжаЖЯЕМжТЕФЗўЮёЬсЙЉепВЛПЩгУЃЌМДБуСДТЗжиаТЛжИДЃЌвВУЛгаБивЊНЋжЎЧАЛ§бЙЕФЯћЯЂжиаТЗЂЫЭЃЌвђЮЊЯћЯЂвбОЭЈЙ§
FailOver ЛњжЦЧаЛЛЕНСэвЛИіЗўЮёЬсЙЉепДІРэЁЃЫљвдЃЌЯћЯЂЛКДцжиЗЂжЛЪЧвЛжжВпТдЃЌЭЈаХПђМмгІИУжЇГжСДТЗМЖжиЗЂВпТдЁЃ
2.4 ПЭЛЇЖЫГЌЪББЃЛЄ
дкДЋЭГЕФЭЌВНзшШћБрГЬФЃЪНЯТЃЌПЭЛЇЖЫ Socket ЗЂЦ№ЭјТчСЌНгЃЌЭљЭљашвЊжИЖЈСЌНгГЌЪБЪБМфЃЌетбљзіЕФФПЕФжївЊгаСНИіЃК
1ЃЎдкЭЌВНзшШћ I/O ФЃаЭжаЃЌСЌНгВйзїЪЧЭЌВНзшШћЕФЃЌШчЙћВЛЩшжУГЌЪБЪБМфЃЌПЭЛЇЖЫ I/O ЯпГЬПЩФмЛсБЛГЄЪБМфзшШћЃЌетЛсЕМжТЯЕЭГПЩгУ
I/O ЯпГЬЪ§ЕФМѕЩйЁЃ
2ЃЎвЕЮёВуашвЊЃКДѓЖрЪ§ЯЕЭГЖМЛсЖдвЕЮёСїГЬжДааЪБМфгаЯожЦЃЌР§Шч WEB НЛЛЅРрЕФЯьгІЪБМфвЊаЁгк 3SЁЃПЭЛЇЖЫЩшжУСЌНгГЌЪБЪБМфЪЧЮЊСЫЪЕЯжвЕЮёВуЕФГЌЪБЁЃ
Ждгк NIO ЕФ SocketChannelЃЌдкЗЧзшШћФЃЪНЯТЃЌЫќЛсжБНгЗЕЛиСЌНгНсЙћЃЌШчЙћУЛгаСЌНгГЩЙІЃЌвВУЛгаЗЂЩњ
I/O вьГЃЃЌдђашвЊНЋ SocketChannel зЂВсЕН Selector ЩЯМрЬ§СЌНгНсЙћЁЃЫљвдЃЌвьВНСЌНгЕФГЌЪБЮоЗЈдк
API ВуУцжБНгЩшжУЃЌЖјЪЧашвЊЭЈЙ§гУЛЇздЖЈвхЖЈЪБЦїРДжїЖЏМрВтЁЃ
Netty дкДДНЈ NIO ПЭЛЇЖЫЪБЃЌжЇГжЩшжУСЌНгГЌЪБВЮЪ§ЁЃNetty ЕФПЭЛЇЖЫСЌНгГЌЪБВЮЪ§гыЦфЫќГЃгУЕФ
TCP ВЮЪ§вЛЦ№ХфжУЃЌЪЙгУЦ№РДЗЧГЃЗНБуЃЌЩЯВугУЛЇВЛгУЙиаФЕзВуЕФГЌЪБЪЕЯжЛњжЦЁЃетМШТњзуСЫгУЛЇЕФИіадЛЏашЧѓЃЌгжЪЕЯжСЫЙЪеЯЕФЗжВуИєРыЁЃ
2.5 еыЖдПЭЛЇЖЫЕФВЂЗЂСЌНгЪ§СїПи
вд Netty ЕФ HTTPS ЗўЮёЖЫЮЊР§ЃЌеыЖдПЭЛЇЖЫЕФВЂЗЂСЌНгЪ§СїПидРэШчЯТЫљЪОЃК
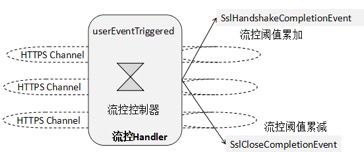
ЭМ 5 ЗўЮёЖЫ HTTS СЌНгЪ§СїПи
Лљгк Netty ЕФ Pipeline ЛњжЦЃЌПЩвдЖд SSL ЮеЪжГЩЙІЁЂSSL СЌНгЙиБезіЧаУцРЙНиЃЈРрЫЦгк
Spring ЕФ AOP ЛњжЦЃЌЕЋЪЧУЛВЩгУЗДЩфЛњжЦЃЌадФмИќИпЃЉЃЌЭЈЙ§СїПиЧаУцНгПкЃЌЖд HTTPS СЌНгзіМЦЪ§ЃЌИљОнМЦЪ§ЦїзіСїПиЃЌЗўЮёЖЫЕФСїПиЫуЗЈШчЯТЃК
1ЃЎЛёШЁСїПиуажЕЁЃ
2ЃЎДгШЋОжЩЯЯТЮФжаЛёШЁЕБЧАЕФВЂЗЂСЌНгЪ§ЃЌгыСїПиуажЕЖдБШЃЌШчЙћаЁгкСїПиуажЕЃЌдђЖдЕБЧАЕФМЦЪ§ЦїзідзгзддіЃЌдЪаэПЭЛЇЖЫСЌНгНгШыЁЃ
3ЃЎШчЙћЕШгкЛђепДѓгкСїПиуажЕЃЌдђХзГіСїПивьГЃИјПЭЛЇЖЫЁЃ
4ЃЎSSL СЌНгЙиБеЪБЃЌЛёШЁЩЯЯТЮФжаЕФВЂЗЂСЌНгЪ§ЃЌзідзгздМѕЁЃ
дкЪЕЯжЗўЮёЖЫСїПиЪБЃЌашвЊзЂвтШчЯТМИЕуЃК
1ЃЎСїПиЕФ ChannelHandler ЩљУїЮЊ @ChannelHandler.SharableЃЌетбљШЋОжДДНЈвЛИіСїПиЪЕР§ЃЌОЭПЩвддкЫљгаЕФ
SSL СЌНгжаЙВЯэЁЃ
2ЃЎЭЈЙ§ userEventTriggered ЗНЗЈРЙНи SslHandshakeCompletionEvent
КЭ SslCloseCompletionEvent ЪТМўЃЌдк SSL ЮеЪжГЩЙІКЭ SSL СЌНгЙиБеЪБИќаТСїПиМЦЪ§ЦїЁЃ
3ЃЎСїПиВЂВЛЪЧЕЅеыЖд ESTABLISHED зДЬЌЕФ HTTP СЌНгЃЌЖјЪЧеыЖдЫљгазДЬЌЕФСЌНгЃЌвђЮЊПЭЛЇЖЫЙиБеСЌНгЃЌВЂВЛвтЮЖзХЗўЮёЖЫвВЭЌЪБЙиБеСЫСЌНгЃЌжЛга
SslCloseCompletionEvent ЪТМўДЅЗЂЪБЃЌЗўЮёЖЫВХеце§ЕФЙиБеСЫ NioSocketChannelЃЌGC
ВХЛсЛиЪеСЌНгЙиСЊЕФФкДцЁЃ
4ЃЎСїПи ChannelHandler ЛсБЛЖрИі NioEventLoop ЯпГЬЕїгУЃЌвђДЫЖдгкЯрЙиЕФМЦЪ§ЦїИќаТЕШВйзїЃЌвЊБЃжЄВЂЗЂАВШЋадЃЌБмУтЪЙгУШЋОжЫјЃЌПЩвдЭЈЙ§дзгРрЕШЬсЩ§адФмЁЃ
2.6 ФкДцБЃЛЄ
NIO ЭЈаХЕФФкДцБЃЛЄжївЊМЏжадкШчЯТМИЕуЃК
1. СДТЗзмЪ§ЕФПижЦЃКУПЬѕСДТЗЖМАќКЌНгЪеКЭЗЂЫЭЛКГхЧјЃЌСДТЗИіЪ§ЬЋЖрШнвзЕМжТФкДцвчГіЁЃ
2. ЕЅИіЛКГхЧјЕФЩЯЯоПижЦЃКЗРжЙЗЧЗЈГЄЖШЛђепЯћЯЂЙ§ДѓЕМжТФкДцвчГіЁЃ
3. ЛКГхЧјФкДцЪЭЗХЃКЗРжЙвђЮЊЛКГхЧјЪЙгУВЛЕБЕМжТЕФФкДцаЙТЖЁЃ
4.NIO ЯћЯЂЗЂЫЭЖгСаЕФГЄЖШЩЯЯоПижЦЁЃ
ЕБЮвУЧЖдЯћЯЂНјааНтТыЕФЪБКђЃЌашвЊДДНЈЛКГхЧјЁЃЛКГхЧјЕФДДНЈЗНЪНЭЈГЃгаСНжжЃК
1. ШнСПдЄЗжХфЃЌдкЪЕМЪЖСаДЙ§ГЬжаШчЙћВЛЙЛдйРЉеЙЁЃ
2. ИљОнавщЯћЯЂГЄЖШДДНЈЛКГхЧјЁЃ
дкЪЕМЪЕФЩЬгУЛЗОГжаЃЌШчЙћгіЕНЛћаЮТыСїЙЅЛїЁЂавщЯћЯЂБрТывьГЃЁЂЯћЯЂЖЊАќЕШЮЪЬтЪБЃЌПЩФмЛсНтЮіЕНвЛИіГЌГЄЕФГЄЖШзжЖЮЁЃБЪепдјОгіЕНЙ§РрЫЦЮЪЬтЃЌБЈЮФГЄЖШзжЖЮжЕОЙШЛЪЧ
2G ЖрЃЌгЩгкДњТыЕФвЛИіЗжжЇУЛгаЖдГЄЖШЩЯЯозігааЇБЃЛЄЃЌНсЙћЕМжТФкДцвчГіЁЃЯЕЭГжиЦєКѓМИУыФкдйДЮФкДцвчГіЃЌавКУМАЪБЖЈЮЛГіЮЪЬтИљвђЃЌЯеаЉФ№ГЩбЯжиЕФЪТЙЪЁЃ
Netty ЬсЙЉСЫБрНтТыПђМмЃЌвђДЫЖдгкНтТыЛКГхЧјЕФЩЯЯоБЃЛЄОЭЯдЕУЗЧГЃживЊЁЃЯТУцЃЌЮвУЧПДЯТ Netty
ЪЧШчКЮЖдЛКГхЧјНјааЩЯЯоБЃЛЄЕФЃК
ЪзЯШЃЌдкФкДцЗжХфЕФЪБКђжИЖЈЛКГхЧјГЄЖШЩЯЯоЃК
/**
* Allocate a {@link ByteBuf} with the given initial
capacity and the given
* maximal capacity. If it is a direct or heap
buffer depends on the actual
* implementation.
*/
ByteBuf buffer(int initialCapacity, int maxCapacity); |
ЦфДЮЃЌдкЖдЛКГхЧјНјаааДШыВйзїЕФЪБКђЃЌШчЙћЛКГхЧјШнСПВЛзуашвЊРЉеЙЃЌЪзЯШЖдзюДѓШнСПНјааХаЖЯЃЌШчЙћРЉеЙКѓЕФШнСПГЌЙ§ЩЯЯоЃЌдђОмОјРЉеЙЃК
@Override
public ByteBuf capacity(int newCapacity) {
ensureAccessible();
if (newCapacity < 0 || newCapacity > maxCapacity())
{
throw new IllegalArgumentException("newCapacity:
" + newCapacity);
} |
дкЯћЯЂНтТыЕФЪБКђЃЌЖдЯћЯЂГЄЖШНјааХаЖЯЃЌШчЙћГЌЙ§зюДѓШнСПЩЯЯоЃЌдђХзГіНтТывьГЃЃЌОмОјЗжХфФкДцЃЌвд
LengthFieldBasedFrameDecoder ЕФ decode ЗНЗЈЮЊР§НјааЫЕУїЃК
if (frameLength
> maxFrameLength) {
long discard = frameLength - in.readableBytes();
tooLongFrameLength = frameLength;
if (discard < 0) {
in.skipBytes((int) frameLength);
} else {
discardingTooLongFrame = true;
bytesToDiscard = discard;
in.skipBytes(in.readableBytes());
}
failIfNecessary(true);
return null;
} |
3. RPC ЕїгУВуЕФПЩППадЩшМЦ
3.1 RPC ЕїгУвьГЃГЁОА
RPC ЕїгУЙ§ГЬжаГ§СЫЭЈаХВуЕФвьГЃЃЌЭЈГЃвВЛсгіЕНШчЯТМИжжЙЪеЯЃК
ЗўЮёТЗгЩЪЇАмЁЃ
ЗўЮёЖЫГЌЪБЁЃ
ЗўЮёЖЫЕїгУЪЇАмЁЃ
RPC ПђМмашвЊФмЙЛеыЖдЩЯЪіГЃМћЕФвьГЃзіШнДэДІРэЃЌвдЬсЩ§вЕЮёЕїгУЕФПЩППадЁЃ
3.1.1 ЗўЮёТЗгЩЪЇАм
RPC ПЭЛЇЖЫЭЈГЃЛсЛљгкЖЉдФ / ЗЂВМЕФЛњжЦЛёШЁЗўЮёЖЫЕФЕижЗСаБэЃЌВЂНЋЦфЛКДцЕНБОЕиЃЌRPC ЕїгУЪБЃЌИљОнИКдиОљКтВпТдДгБОЕиЛКДцЕФТЗгЩБэжаЛёШЁЕНвЛИіЮЈвЛЕФЗўЮёЖЫНкЕуЗЂЦ№ЕїгУЃЌдРэШчЯТЫљЪОЃК

ЭМ 6 ЛљгкЖЉдФЗЂВМЛњжЦЕФ RPC ЕїгУ
ЭЈЙ§ЛКДцЕФЛњжЦФмЙЛЬсЩ§ RPC ЕїгУЕФадФмЃЌRPC ПЭЛЇЖЫВЛашвЊУПДЮЕїгУЖМЯђзЂВсжааФВщбЏФПБъЗўЮёЕФЕижЗаХЯЂЃЌЕЋЪЧвВПЩФмЛсЗЂЩњШчЯТСНРрЧБдкЙЪеЯЃК
1ЃЎФГИі RPC ЗўЮёЖЫЗЂЩњЙЪеЯЃЌЛђепЯТЯпЃЌПЭЛЇЖЫУЛгаМАЪБЫЂаТБОЕиЛКДцЕФЗўЮёЕижЗСаБэЃЌОЭЛсЕМжТ RPC
ЕїгУЪЇАмЁЃ
2ЃЎRPC ПЭЛЇЖЫКЭЗўЮёЖЫЖМЙЄзїе§ГЃЃЌЕЋЪЧ RPC ПЭЛЇЖЫКЭЗўЮёЖЫЕФСЌНгЛђепЭјТчЗЂЩњСЫЙЪеЯЃЌШчЙћУЛгаСДТЗЕФПЩППадМьВтЛњжЦЃЌОЭЛсЕМжТ
RPC ЕїгУЪЇАмЁЃ
3.1.2 ЗўЮёЖЫГЌЪБ
ЕБЗўЮёЖЫЮоЗЈдкжИЖЈЕФЪБМфФкЗЕЛигІД№ИјПЭЛЇЖЫЃЌОЭЛсЗЂЩњГЌЪБЃЌЕМжТГЌЪБЕФдвђжївЊгаЃК
1ЃЎЗўЮёЖЫЕФ I/O ЯпГЬУЛгаМАЪБДгЭјТчжаЖСШЁПЭЛЇЖЫЧыЧѓЯћЯЂЃЌЕМжТИУЮЪЬтЕФдвђЭЈГЃЪЧ I/O ЯпГЬБЛвтЭтзшШћЛђепжДааГЄжмЦкВйзїЁЃ
2ЃЎЗўЮёЖЫвЕЮёДІРэЛКТ§ЃЌЛђепБЛГЄЪБМфзшШћЃЌР§ШчВщбЏЪ§ОнПтЃЌгЩгкУЛгаЫїв§ЕМжТШЋБэВщбЏЃЌКФЪБНЯГЄЁЃ
3ЃЎЗўЮёЖЫЗЂЩњГЄЪБМф Full GCЃЌЕМжТЫљгавЕЮёЯпГЬднЭЃдЫааЃЌЮоЗЈМАЪБЗЕЛигІД№ИјПЭЛЇЖЫЁЃ
3.1.3 ЗўЮёЖЫЕїгУЪЇАм
гаЪБЛсЗЂЩњЗўЮёЖЫЕїгУЪЇАмЃЌЕМжТЗўЮёЖЫЕїгУЪЇАмЕФдвђжївЊгаШчЯТМИжжЃК
1ЃЎЗўЮёЖЫНтТыЪЇАмЃЌЛсЗЕЛиЯћЯЂНтТыЪЇАмвьГЃЁЃ
2ЃЎЗўЮёЖЫЗЂЩњЖЏЬЌСїПиЃЌЗЕЛиСїПивьГЃЁЃ
3ЃЎЗўЮёЖЫЯћЯЂЖгСаЛ§бЙТЪГЌЙ§зюДѓуажЕЃЌЗЕЛиЯЕЭГгЕШћвьГЃЁЃ
4ЃЎЗУЮЪШЈЯоаЃбщЪЇАмЃЌЗЕЛиШЈЯоЯрЙивьГЃЁЃ
5ЃЎЮЅЗД SLA ВпТдЃЌЗЕЛи SLA ПижЦЯрЙивьГЃЁЃ
6ЃЎЦфЫћЯЕЭГвьГЃЁЃ
ашвЊжИГіЕФЪЧЃЌЗўЮёЕїгУвьГЃВЛАќРЈвЕЮёВуУцЕФДІРэвьГЃЃЌР§ШчЪ§ОнПтВйзївьГЃЁЂгУЛЇМЧТМВЛДцдквьГЃЕШЁЃ
3.2 RPC ЕїгУПЩППадЗНАИ
3.2.1 зЂВсжааФгыСДТЗМьВтЫЋБЃЯеЛњжЦ
вђЮЊзЂВсжааФгаМЏШКФкЫљга RPC ПЭЛЇЖЫКЭЗўЮёЖЫЕФЪЕР§аХЯЂЃЌвђДЫЭЈЙ§зЂВсжааФЯђУПИіЗўЮёЖЫКЭПЭЛЇЖЫЗЂЫЭаФЬјЯћЯЂЃЌМьВтЖдЗНЪЧЗёдкЯпЃЌШчЙћСЌај
N ДЮаФЬјГЌЪБЃЌЛђепаФЬјЗЂЫЭЪЇАмЃЌдђХаЖЯЖдЗНвбОЗЂЩњЙЪеЯЛђепЯТЯпЃЈЯТЯпПЩвдЭЈЙ§гХбХЭЃЛњЕФЗНЪНжїЖЏИцжЊзЂВсжааФЃЌЪЕЪБадЛсИќКУЃЉЁЃзЂВсжааФНЋЙЪеЯНкЕуЕФЗўЮёЪЕР§аХЯЂЭЈЙ§аФЬјЯћЯЂЗЂЫЭИјПЭЛЇЖЫЃЌгЩПЭЛЇЖЫНЋЙЪеЯЕФЗўЮёЪЕР§аХЯЂДгБОЕиЛКДцЕФТЗгЩБэжаЩОГ§ЃЌКѓајЯћЯЂЕїгУВЛдйТЗгЩЕНИУНкЕуЁЃ
дквЛаЉЬиЪтГЁОАЯТЃЌОЁЙмзЂВсжааФгыЗўЮёЖЫЁЂПЭЛЇЖЫЕФСЌНгЖМУЛгаЮЪЬтЃЌЕЋЪЧЗўЮёЖЫКЭПЭЛЇЖЫжЎМфЕФСДТЗЗЂЩњСЫвьГЃЃЌгЩгкЗЂЩњСДТЗвьГЃЕФЗўЮёЖЫШдШЛдкЛКДцБэжаЃЌвђДЫЯћЯЂЛЙЛсМЬајЕїЖШЕНЙЪеЯНкЕуЩЯЃЌЫљвдЃЌРћгУ
RPC ПЭЛЇЖЫКЭЗўЮёЖЫжЎМфЕФЫЋЯђаФЬјМьВтЃЌПЩвдМАЪБЗЂЯжЫЋЗНжЎМфЕФСДТЗЮЪЬтЃЌРћгУжиСЌЕШЛњжЦПЩвдПьЫйЕФЛжИДСЌНгЃЌШчЙћжиСЌ
N ДЮЖМЪЇАмЃЌдђЗўЮёТЗгЩЪБВЛдйНЋЯћЯЂЗЂЫЭЕНСЌНгЙЪеЯЕФЗўЮёНкЕуЩЯЁЃ
РћгУзЂВсжааФЖдЗўЮёЖЫЕФаФЬјМьВтКЭЭЈжЊЛњжЦЁЂвдМАЗўЮёЖЫКЭПЭЛЇЖЫеыЖдСДТЗВуЕФЫЋЯђаФЬјМьВтЛњжЦЃЌПЩвдгааЇМьВтГіЙЪеЯНкЕуЃЌЬсЩ§
RPC ЕїгУЕФПЩППадЃЌЫќЕФдРэШчЯТЫљЪОЃК
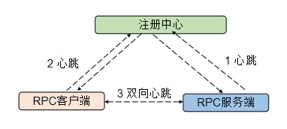
ЭМ 7 зЂВсжааФгыСДТЗЫЋЯђаФЬјМьВтЛњжЦдРэ
3.2.2 МЏШКШнДэВпТд
ГЃгУЕФМЏШКШнДэВпТдАќРЈЃК
1ЃЎЪЇАмздЖЏЧаЛЛ (Failover)ЁЃ
2ЃЎЪЇАмЭЈжЊЃЈFailbackЃЉЁЃ
3ЃЎЪЇАмЛКДцЃЈFailcacheЃЉЁЃ
4ЃЎПьЫйЪЇАмЃЈFailfastЃЉЁЃ
ЪЇАмздЖЏЧаЛЛВпТдЃКЗўЮёЕїгУЪЇАмздЖЏЧаЛЛВпТджИЕФЪЧЕБЗЂЩњ RPC ЕїгУвьГЃЪБЃЌжиаТбЁТЗЃЌВщевЯТвЛИіПЩгУЕФЗўЮёЬсЙЉепЁЃ
ЗўЮёЗЂВМЕФЪБКђЃЌПЩвджИЖЈЗўЮёЕФМЏШКШнДэВпТдЁЃЯћЗбепПЩвдИВИЧЗўЮёЬсЙЉепЕФЭЈгУХфжУЃЌЪЕЯжИіадЛЏЕФШнДэВпТдЁЃ
Failover ВпТдЕФЩшМЦЫМТЗШчЯТЃКЯћЗбепТЗгЩВйзїЭъГЩжЎКѓЃЌЛёЕУФПБъЕижЗЃЌЕїгУЭЈаХПђМмЕФЯћЯЂЗЂЫЭНгПкЗЂЫЭЧыЧѓЃЌМрЬ§ЗўЮёЖЫгІД№ЁЃШчЙћЗЕЛиЕФНсЙћЪЧ
RPC ЕїгУвьГЃЃЈГЌЪБЁЂСїПиЁЂНтТыЪЇАмЕШЯЕЭГвьГЃЃЉЃЌИљОнЯћЗбепМЏШКШнДэЕФВпТдНјааШнДэТЗгЩЃЌШчЙћЪЧ FailoverЃЌдђжиаТЗЕЛиЕНТЗгЩ
Handler ЕФШыПкЃЌДгТЗгЩНкЕуМЬајжДааЁЃбЁТЗЭъГЩжЎКѓЃЌЖдФПБъЕижЗНјааБШЖдЃЌЗРжЙжиаТТЗгЩЕНЙЪеЯЗўЮёНкЕуЃЌЙ§ТЫЕєЩЯДЮЕФЙЪеЯЗўЮёЬсЙЉепжЎКѓЃЌЕїгУЭЈаХПђМмЕФЯћЯЂЗЂЫЭНгПкЗЂЫЭЧыЧѓЯћЯЂЁЃ
RPC ПђМмЬсЙЉ Failover ШнДэВпТдЃЌЕЋЪЧгУЛЇдкЪЙгУЪБашвЊздМКБЃжЄгУЖдЕиЗНЃЌЯТУцЖд Failover
ВпТдЕФгІгУГЁОАНјаазмНсЃК
1ЃЎЖСВйзїЃЌвђЮЊЭЈГЃЫќЪЧУнЕШЕФЁЃ
2ЃЎУнЕШадЗўЮёЃЌБЃжЄЕїгУ 1 ДЮгы N ДЮаЇЙћЯрЭЌЁЃ
ашвЊЬиБ№жИГіЕФЪЧЃЌЪЇАмжиЪдЛсдіМгЗўЮёЕїгУЪБбгЃЌвђДЫПђМмБиаыЖдЪЇАмжиЪдЕФзюДѓДЮЪ§зіЯожЦЃЌЭЈГЃФЌШЯЮЊ
3ЃЌЗРжЙЮоЯожЦжиЪдЕМжТЗўЮёЕїгУЪБбгВЛПЩПиЁЃ
ЪЇАмЭЈжЊЃЈFailbackЃЉЃКдкКмЖрвЕЮёГЁОАжаЃЌПЭЛЇЖЫашвЊФмЙЛЛёШЁЕНЗўЮёЕїгУЪЇАмЕФОпЬхаХЯЂЃЌЭЈЙ§ЖдЪЇАмДэЮѓТыЕШвьГЃаХЯЂЕФХаЖЯЃЌОіЖЈКѓајЕФжДааВпТдЃЌР§ШчЗЧУнЕШадЕФЗўЮёЕїгУЁЃ
Failback ЕФЩшМЦЗНАИШчЯТЃКRPC ПђМмЛёШЁЕНЗўЮёЬсЙЉепЗЕЛиЕФ RPC вьГЃЯьгІжЎКѓЃЌИљОнВпТдНјааШнДэЁЃШчЙћЪЧ
Failback ФЃЪНЃЌдђВЛдйжиЪдЦфЫќЗўЮёЬсЙЉепЃЌЖјЪЧНЋ RPC вьГЃЭЈжЊИјПЭЛЇЖЫЃЌгЩПЭЛЇЖЫВЖЛёвьГЃНјааКѓајДІРэЁЃ
ЪЇАмЛКДцЃЈFailcacheЃЉЃКFailcache ВпТдЪЧЪЇАмздЖЏЛжИДЕФвЛжжЃЌдкЪЕМЪЯюФПжаЫќЕФгІгУГЁОАШчЯТЃК
1ЃЎЗўЮёгазДЬЌТЗгЩЃЌБиаыЖЈЕуЗЂЫЭЕНжИЖЈЕФЗўЮёЬсЙЉепЁЃЕБЗЂЩњСДТЗжаЖЯЁЂСїПиЕШЗўЮёднЪБВЛПЩгУЪБЃЌRPC
ПђМмНЋЯћЯЂСйЪБЛКДцЦ№РДЃЌЕШД§жмЦк TЃЌжиаТЗЂЫЭЃЌжБЕНЗўЮёЬсЙЉепФмЙЛе§ГЃДІРэИУЯћЯЂЁЃ
2ЃЎЖдЪБбгвЊЧѓВЛУєИаЕФЗўЮёЁЃЯЕЭГЗўЮёЕїгУЪЇАмЃЌЭЈГЃЪЧСДТЗднЪБВЛПЩгУЁЂЗўЮёСїПиЁЂGC ЙвзЁЗўЮёЬсЙЉепНјГЬЕШЃЌетжжЪЇАмВЛЪЧгРОУадЕФЪЇАмЃЌЫќЕФЛжИДЪЧПЩдЄЦкЕФЁЃШчЙћПЭЛЇЖЫЖдЗўЮёЕїгУЪБбгВЛУєИаЃЌПЩвдПМТЧВЩгУздЖЏЛжИДФЃЪНЃЌМДЯШЛКДцЃЌдйЕШД§ЃЌзюКѓжиЪдЁЃ
3ЃЎЭЈжЊРрЗўЮёЁЃР§ШчЭЈжЊЗлЫПЛ§ЗждіГЄЁЂМЧТМНгПкШежОЕШЃЌЖдЗўЮёЕїгУЕФЪЕЪБадвЊЧѓВЛИпЃЌПЩвдШнШЬздЖЏЛжИДДјРДЕФЪБбгдіМгЁЃ
ЮЊСЫБЃжЄПЩППадЃЌFailcache ВпТддкЩшМЦЕФЪБКђашвЊПМТЧШчЯТМИИівЊЫиЃК
1ЃЎЛКДцЪБМфЁЂЛКДцЖдЯѓЩЯЯоЪ§ЕШашвЊзіГіЯожЦЃЌЗРжЙФкДцвчГіЁЃ
2ЃЎЛКДцЬдЬЫуЗЈЕФбЁдёЃЌЪЧЗёжЇГжгУЛЇХфжУЁЃ
3ЃЎЖЈЪБжиЪдЕФжмЦк TЁЂжиЪдЕФзюДѓДЮЪ§ЕШашвЊзіГіЯожЦВЂжЇГжгУЛЇжИЖЈЁЃ
4ЃЎжиЪдДяЕНзюДѓЩЯЯоШдЪЇАмЃЌашвЊЖЊЦњЯћЯЂЃЌМЧТМвьГЃШежОЁЃ
ПьЫйЪЇАмЃЈFailfastЃЉЃКдквЕЮёИпЗхЦкЃЌЖдгквЛаЉЗЧКЫаФЕФЗўЮёЃЌЯЃЭћжЛЕїгУвЛДЮЃЌЪЇАмвВВЛдйжиЪдЃЌЮЊживЊЕФКЫаФЗўЮёНкдМБІЙѓЕФдЫаазЪдДЁЃДЫЪБЃЌПьЫйЪЇАмЪЧИіВЛДэЕФбЁдёЁЃПьЫйЪЇАмВпТдЕФЩшМЦБШНЯМђЕЅЃЌЛёШЁЕНЗўЮёЕїгУвьГЃжЎКѓЃЌжБНгКіТдвьГЃЃЌМЧТМвьГЃШежОЁЃ
4. ЕкШ§ЗНЗўЮёвРРЕЙЪеЯИєРы
4.1 змЬхВпТд
ОЁЙмКмЖрЕкШ§ЗНЗўЮёЛсЬсЙЉ SLAЃЌЕЋЪЧ RPC ЗўЮёБОЩэВЂВЛФмЭъШЋвРРЕЕкШ§ЗНЗўЮёздЩэЕФПЩППадРДБЃеЯздМКЕФИпПЩППЃЌЕкШ§ЗНЗўЮёвРРЕИєРыЕФзмЬхВпТдШчЯТЃК
1ЃЎЕкШ§ЗНвРРЕИєРыПЩвдВЩгУЯпГЬГи + ЯьгІЪНБрГЬЃЈР§Шч RxJavaЃЉЕФЗНЪНЪЕЯжЁЃ
2ЃЎЖдЕкШ§ЗНвРРЕНјааЗжРрЃЌУПжжвРРЕЖдгІвЛИіЖРСЂЕФЯпГЬ / ЯпГЬГиЁЃ
3ЃЎЗўЮёВЛжБНгЕїгУЕкШ§ЗНвРРЕЕФ APIЃЌЖјЪЧЪЙгУвьВНЗтзАжЎКѓЕФ API НгПкЁЃ
4ЃЎвьВНЕїгУЕкШ§ЗНвРРЕ API жЎКѓЃЌЛёШЁ Future ЖдЯѓЁЃРћгУЯьгІЪНБрГЬПђМмЃЌ
ПЩвдЖЉдФКѓајЕФЪТМўЃЌНгЪеЯьгІЃЌеыЖдЯьгІНјааБрГЬЁЃ
4.2 вьВНЛЏ
ШчЙћЕкШ§ЗНЗўЮёЬсЙЉЕФЪЧБъзМЕФ HTTP/Restful ЗўЮёЃЌдђРћгУвьВН HTTP ПЭЛЇЖЫЃЌР§Шч NettyЁЂVert.xЁЂвьВН
RestTemplate ЕШЗЂЦ№вьВНЗўЮёЕїгУЃЌетбљЮоТлЪЧЗўЮёЖЫздЩэДІРэТ§ЛЙЪЧЭјТчТ§ЃЌЖМВЛЛсЕМжТЕїгУЗНБЛзшШћЁЃ
ШчЙћЖдЗНЪЧЫНгаЛђепЖЈжЦЛЏЕФавщЃЌSDK УЛгаЬсЙЉвьВННгПкЃЌдђашвЊВЩгУЯпГЬГиЛђепРћгУвЛаЉПЊдДПђМмЪЕЯжЙЪеЯИєРыЁЃ
вьВНЛЏЪОР§ЭМШчЯТЫљЪОЃК
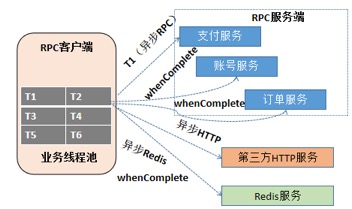
ЭМ 8 вьВНЛЏдРэЪОвтЭМ
вьВНЛЏЕФМИИіЙиМќММЪѕЕуЃК
1ЃЎвьВНОпгавРРЕКЭДЋЕнадЃЌШчЙћЯыдкФГИівЕЮёСїГЬЕФФГИіЙ§ГЬжазівьВНЛЏЃЌдђШыПкДІОЭашвЊзівьВНЁЃР§ШчШчЙћЯыАб
Redis ЗўЮёЕїгУИФдьГЩвьВНЃЌдђЕїгУ Redis ЗўЮёжЎЧАЕФСїГЬвВашвЊЭЌЪБзівьВНЛЏЃЌЗёдђвтвхВЛДѓЃЈГ§ЗЧЕїгУЗНВЛашвЊЗЕЛижЕЃЉЁЃ
2ЃЎЭЈГЃЖјбдЃЌШЋеЛвьВНЖдгквЕЮёадФмКЭПЩППадЬсЩ§ЕФвтвхИќДѓЃЌШЋеЛвьВНЛсЩцМАЕНФкВПЗўЮёЕїгУЁЂЕкШ§ЗНЗўЮёЕїгУЁЂЪ§ОнПтЁЂЛКДцЕШЦНЬЈжаМфМўЗўЮёЕФЕїгУЃЌвьВНЛЏИФдьГЩБОБШНЯИпЃЌЕЋЪЧЪевцвВБШНЯУїЯдЁЃ
3ЃЎВЛЭЌПђМмЁЂЗўЮёЕФвьВНБрГЬФЃаЭОЁСПБЃГжвЛжТЃЌР§ШчЭГвЛВЩШЁ RxJava ЗчИёЕФНгПкЁЂЛђеп JDK8
ЕФ CompletableFutureЁЃШчЙћВЛЭЌЗўЮё SDK ЕФвьВН API НгПкЗчИёВювьЙ§ДѓЃЌЛсдіМгвЕЮёЕФПЊЗЂГЩБОЃЌвВВЛРћгУЯпГЬФЃаЭЕФЙщВЂКЭећКЯЁЃ
4.3. Лљгк Hystrix ЕФЕкШ§ЗНвРРЕЙЪеЯИєРы
МЏГЩ Netflix ПЊдДЕФ Hystrix ПђМмЃЌПЩвдЗЧГЃЗНБуЕФЪЕЯжЕкШ§ЗНЗўЮёвРРЕЙЪеЯИєРыЃЌЫќЬсЙЉЕФжївЊЙІФмАќРЈ:
1ЃЎвРРЕИєРыЁЃ
2ЃЎШлЖЯЦїЁЃ
3ЃЎгХбХНЕМЖЁЃ
4ЃЎReactive БрГЬЁЃ
5ЃЎаХКХСПИєРыЁЃ
НЈвщЕФМЏГЩВпТдШчЯТЃК
1ЃЎЕкШ§ЗНвРРЕИєРыЃКЪЙгУ HystrixCommand зівЛВувьВНЗтзАЃЌЪЕЯжвЕЮёЕФ RPC ЗўЮёЕїгУЯпГЬКЭЕкШ§ЗНвРРЕЕФЯпГЬИєРыЁЃ
2ЃЎвРРЕЗжРрЙмРэЃКЖдЕкШ§ЗНвРРЕНјааЗжРрЁЂЗжзщЙмРэЃЌИљОнвРРЕЕФЬиЕуЩшжУШлЖЯВпТдЁЂгХбХНЕМЖВпТдЁЂГЌЪБВпТдЕШЃЌвдЪЕЯжВювьЛЏЕФДІРэЁЃ
змЬхМЏГЩЪгЭМШчЯТЫљЪОЃК
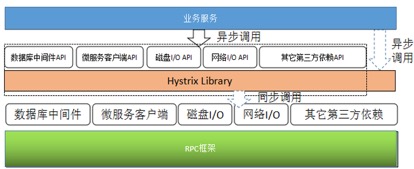
ЭМ 9 Лљгк Hystrix ЕФЕкШ§ЗНЙЪеЯИєРыПђМм
Лљгк Hystrix ПЩвдЗЧГЃЗНБуЕФЪЕЯжЕкШ§ЗНвРРЕЗўЮёЕФШлЖЯНЕМЖЃЌЫќЕФЙЄзїдРэШчЯТЃК
1ЃЎШлЖЯХаЖЯЃКЗўЮёЕїгУЪБЃЌЖдШлЖЯПЊЙизДЬЌНјааХаЖЯЃЌЕБШлЖЯЦїПЊЙиЙиБеЪБ, ЧыЧѓБЛдЪаэЭЈЙ§ШлЖЯЦїЁЃ
2ЃЎШлЖЯжДааЃКЕБШлЖЯЦїПЊЙиДђПЊЪБЃЌЗўЮёЕїгУЧыЧѓБЛНћжЙЭЈЙ§ЃЌжДааЪЇАмЛиЕїНгПкЁЃ
3ЃЎздЖЏЛжИДЃКШлЖЯжЎКѓЃЌжмЦк T жЎКѓдЪаэвЛЬѕЯћЯЂЭЈЙ§ЃЌШчЙћГЩЙІЃЌдђШЁЯћШлЖЯзДЬЌЃЌЗёдђМЬајДІгкШлЖЯзДЬЌЁЃ
СїГЬШчЯТЫљЪОЃК
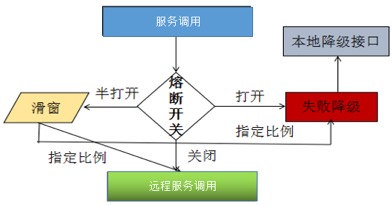
ЭМ 10 Лљгк Hystrix ЕФШлЖЯНЕМЖ
|








