| БрМЭЦМі: |
БОЮФРДздгкaliyunЃЌЮФеТRocketMQЕФЬиЕуЁЂЭјТчВПЪ№ЁЂЙиМќЬиадЃЌвдМАConsumerзюМбЪЕМљЕШЯрЙиФкШнЁЃ |
|
RocketMQЪЧвЛПюЗжВМЪНЁЂЖгСаФЃаЭЕФЯћЯЂжаМфМўЃЌОпгавдЯТЬиЕуЃК
ФмЙЛБЃжЄбЯИёЕФЯћЯЂЫГађ
ЬсЙЉЗсИЛЕФЯћЯЂРШЁФЃЪН
ИпаЇЕФЖЉдФепЫЎЦНРЉеЙФмСІ
ЪЕЪБЕФЯћЯЂЖЉдФЛњжЦ
вкМЖЯћЯЂЖбЛ§ФмСІ
RocketMQЭјТчВПЪ№Ьи
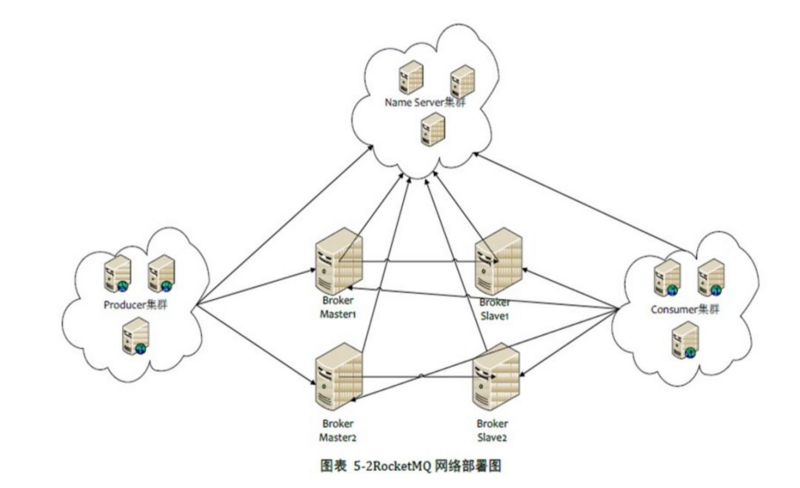
ЃЈ1ЃЉNameServerЪЧвЛИіМИКѕЮозДЬЌЕФНкЕуЃЌПЩМЏШКВПЪ№ЃЌНкЕужЎМфЮоШЮКЮаХЯЂЭЌВН
ЃЈ2ЃЉBrokerВПЪ№ЯрЖдИДдгЃЌBrokerЗеЮЇMasterгыSlaveЃЌвЛИіMasterПЩвдЖдгІЖрИіSlaverЃЌЕЋЪЧвЛИіSlaverжЛФмЖдгІвЛИіMasterЃЌMasterгыSlaverЕФЖдгІЙиЯЕЭЈЙ§жИЖЈЯрЭЌЕФBrokerNameЃЌВЛЭЌЕФBrokerIdРДЖЈвхЃЌBrokerIdЮЊ0БэЪОMasterЃЌЗЧ0БэЪОSlaverЁЃMasterПЩвдВПЪ№ЖрИіЁЃУПИіBrokerгыNameServerМЏШКжаЕФЫљгаНкЕуНЈСЂГЄСЌНгЃЌЖЈЪБзЂВсTopicаХЯЂЕНЫљгаЕФNameServer
ЃЈ3ЃЉProducerгыNameServerМЏШКжаЕФЦфжавЛИіНкЕуЃЈЫцЛњбЁдёЃЉНЈСЂГЄСЌНгЃЌЖЈЦкДгNameServerШЁTopicТЗгЩаХЯЂЃЌВЂЯђЬсЙЉTopicЗўЮёЕФMasterНЈСЂГЄСЌНгЃЌЧвЖЈЪБЯђMasterЗЂЫЭаФЬјЁЃProduceЭъШЋЮозДЬЌЃЌПЩМЏШКВПЪ№
ЃЈ4ЃЉConsumerгыNameServerМЏШКжаЕФЦфжавЛИіНкЕуЃЈЫцЛњбЁдёЃЉНЈСЂГЄСЌНгЃЌЖЈЦкДгNameServerШЁTopicТЗгЩаХЯЂЃЌВЂЯђЬсЙЉTopicЗўЮёЕФMasterЁЂSlaverНЈСЂГЄСЌНгЃЌЧвЖЈЪБЯђMasterЁЂSlaverЗЂЫЭаФЬјЁЃConsumerМДПЩДгMasterЖЉдФЯћЯЂЃЌвВПЩвдДгSlaveЖЉдФЯћЯЂЃЌЖЉдФЙцдђгЩBrokerХфжУОіЖЈ
RocketMQДЂДцЬиЕу
ЃЈ1ЃЉСуПНБДдРэЃКConsumerЯћЗбЯћЯЂЙ§ГЬЃЌЪЙгУСЫСуПНБДЃЌСуПНБДАќРЈвЛЯТ2жаЗНЪНЃЌRocketMQЪЙгУЕквЛжжЗНЪНЃЌвђаЁПщЪ§ОнДЋЪфЕФвЊЧѓаЇЙћБШsendfileЗНЪНКУ
a )ЪЙгУmmap+writeЗНЪН
гХЕуЃКМДЪЙЦЕЗБЕїгУЃЌЪЙгУаЁЮФМўПщДЋЪфЃЌаЇТЪвВКмИп
ШБЕуЃКВЛФмКмКУЕФРћгУDMAЗНЪНЃЌЛсБШsendfileЖрЯћКФCPUзЪдДЃЌФкДцАВШЋадПижЦИДдгЃЌашвЊБмУтJVM
CrashЮЪЬт
bЃЉЪЙгУsendfileЗНЪН
гХЕуЃКПЩвдРћгУDMAЗНЪНЃЌЯћКФCPUзЪдДЩйЃЌДѓПщЮФМўДЋЪфаЇТЪИпЃЌЮоФкДцАВШЋаТЮЪЬт
ШБЕуЃКаЁПщЮФМўаЇТЪЕЭгкmmapЗНЪНЃЌжЛФмЪЧBIOЗНЪНДЋЪфЃЌВЛФмЪЙгУNIO
ЃЈ2ЃЉЪ§ОнДцДЂНсЙЙ
RocketMQЙиМќЬиад
1.ЕЅЛњжЇГж1WвдЩЯЕФГжОУЛЏЖг
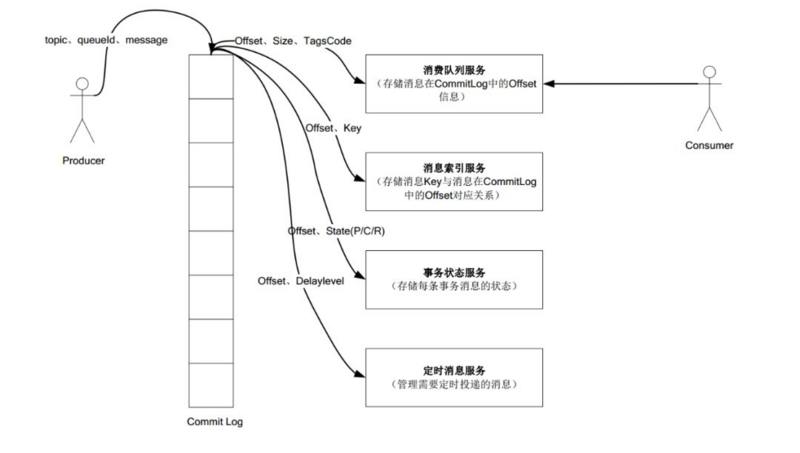
ЃЈ1ЃЉЫљгаЪ§ОнЕЅЖРДЂДцЕНcommit Log ЃЌЭъШЋЫГађаДЃЌЫцЛњЖС
ЃЈ2ЃЉЖдзюжегУЛЇеЙЯжЕФЖгСаЪЕМЪжЛДЂДцЯћЯЂдкCommit Log ЕФЮЛжУаХЯЂЃЌВЂЧвДЎааЗНЪНЫЂХЬ
етбљзіЕФКУДІЃК
ЃЈ1ЃЉЖгСаЧсСПЛЏЃЌЕЅИіЖгСаЪ§ОнСПЗЧГЃЩй
ЃЈ2ЃЉЖдДХХЬЕФЗУЮЪДЎааЛАЃЌБмУтДХХЬОКељЃЌВЛЛсвђЮЊЖгСадіМгЕМжТIOWaitдіИп
УПИіЗНАИЖМгагХШБЕуЃЌЫћЕФШБЕуЪЧЃК
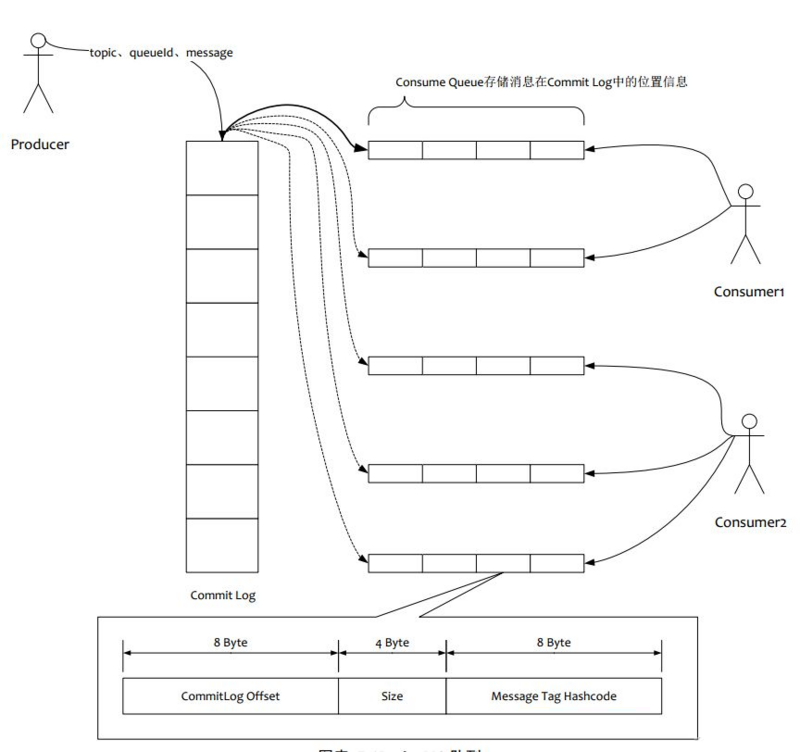
ЃЈ1ЃЉаДЫфШЛЪЧЫГађаДЃЌЕЋЪЧЖСШДБфГЩСЫЫцЛњЖС
ЃЈ2ЃЉЖСвЛЬѕЯћЯЂЃЌЛсЯШЖСConsume QueueЃЌдйЖСCommit LogЃЌдіМгСЫПЊЯњ
ЃЈ3ЃЉвЊБЃжЄCommit Log гы Consume QueueЭъШЋЕФвЛжТЃЌдіМгСЫБрГЬЕФИДдгЖШ
вдЩЯШБЕуШчКЮПЭЗўЃК
ЃЈ1ЃЉЫцЛњЖСЃЌОЁПЩФмШУЖСУќжаpagecacheЃЌМѕЩйIOВйзїЃЌЫљвдФкДцдНДѓдНКУЁЃШчЙћЯЕЭГжаЖбЛ§ЕФЯћЯЂЙ§ЖрЃЌЖСЪ§ОнвЊЗУЮЪгВХЬЛсВЛЛсгЩгкЫцЛњЖСЕМжТЯЕЭГадФмМБОчЯТНЕЃЌД№АИЪЧЗёЖЈЕФЁЃ
aЃЉЗУЮЪpagecacheЪБЃЌМДЪЙжЛЗУЮЪ1KЕФЯћЯЂЃЌЯЕЭГвВЛсЬсЧАдЄЖСГіИќЖрЕФЪ§ОнЃЌдкЯТДЮЖСЪБОЭПЩФмУќжаpagecache
bЃЉЫцЛњЗУЮЪCommit Log ДХХЬЪ§ОнЃЌЯЕЭГIOЕїЖШЫуЗЈЩшжУЮЊNOOPЗНЪНЃЌЛсдквЛЖЈГЬЖШЩЯНЋЭъШЋЕФЫцЛњЖСБфГЩЫГађЬјдОЗНЪНЃЌЖјЫГађЬјдОЗНЪНЖСНЯЭъШЋЕФЫцЛњЖСадФмИп5БЖ
ЃЈ2ЃЉгЩгкConsume QueueДцДЂЪ§СПМЋЩйЃЌЖјЧвЫГађЖСЃЌдкpagecacheЕФгыЖСШЁЧщПіЯТЃЌConsume
QueueЕФЖСадФмгыФкДцМИКѕвЛжБЃЌМДЪЙЖбЛ§ЧщПіЯТЁЃЫљвдПЩвдШЯЮЊConsume QueueЭъШЋВЛЛсзшАЖСадФм
ЃЈ3ЃЉCommit LogжаДцДЂСЫЫљгаЕФдЊаХЯЂЃЌАќКЌЯћЯЂЬхЃЌРрЫЦгкMySQlЁЂOracleЕФredologЃЌЫљвджЛвЊгаCommit
LogДцдкЃЌ Consume QueueМДЪЙЖЊЪЇЪ§ОнЃЌШдПЩвдЛжИДГіРД
2.ЫЂХЬВпТд
rocketmqжаЕФЫљгаЯћЯЂЖМЪЧГжОУЛЏЕФЃЌЯШаДШыЯЕЭГpagecacheЃЌШЛКѓЫЂХЬЃЌПЩвдБЃжЄФкДцгыДХХЬЖМгавЛЗнЪ§ОнЃЌЗУЮЪЪБЃЌПЩвджБНгДгФкДцЖСШЁ
2.1вьВНЫЂХЬ
дкга RAID ПЈЃЌ SAS 15000 зЊДХХЬВтЪдЫГађаДЮФМўЃЌЫйЖШПЩвдДяЕН 300M УПУызѓгвЃЌЖјЯпЩЯЕФЭјПЈвЛАуЖМЮЊЧЇезЭјПЈЃЌаДДХХЬЫйЖШУїЯдПьгкЪ§ОнЭјТчШыПкЫйЖШЃЌФЧУДЪЧЗёПЩвдзіЕНаДЭъ
ФкДцОЭЯђгУЛЇЗЕЛиЃЌгЩКѓЬЈЯпГЬЫЂХЬФиЃП
(1). гЩгкДХХЬЫйЖШДѓгкЭјПЈЫйЖШЃЌФЧУДЫЂХЬЕФНјЖШПЯЖЈПЩвдИњЩЯЯћЯЂЕФаДШыЫйЖШЁЃ
(2). ЭђвЛгЩгкДЫЪБЯЕЭГбЙСІЙ§ДѓЃЌПЩФмЖбЛ§ЯћЯЂЃЌГ§СЫаДШы IOЃЌЛЙгаЖСШЁ IOЃЌЭђвЛГіЯжДХХЬЖСШЁТфКѓЧщПіЃЌЛсВЛЛсЕМжТЯЕЭГФкДцвчГіЃЌД№АИЪЧЗёЖЈЕФЃЌдвђШчЯТЃК
a) аДШыЯћЯЂЕН PAGECACHE ЪБЃЌШчЙћФкДцВЛзуЃЌдђГЂЪдЖЊЦњИЩОЛЕФ PAGEЃЌЬкГіФкДцЙЉаТЯћЯЂЪЙгУЃЌВпТдЪЧ
LRU ЗНЪНЁЃ
b) ШчЙћИЩОЛвГВЛзуЃЌДЫЪБаДШы PAGECACHE ЛсБЛзшШћЃЌЯЕЭГГЂЪдЫЂХЬВПЗжЪ§ОнЃЌДѓдМУПДЮГЂЪд
32 Иі PAGEЃЌРДевГіИќЖрИЩОЛ PAGEЁЃ
злЩЯЃЌФкДцвчГіЕФЧщПіВЛЛсГіЯж
2.2ЭЌВНЫЂХЬЃК
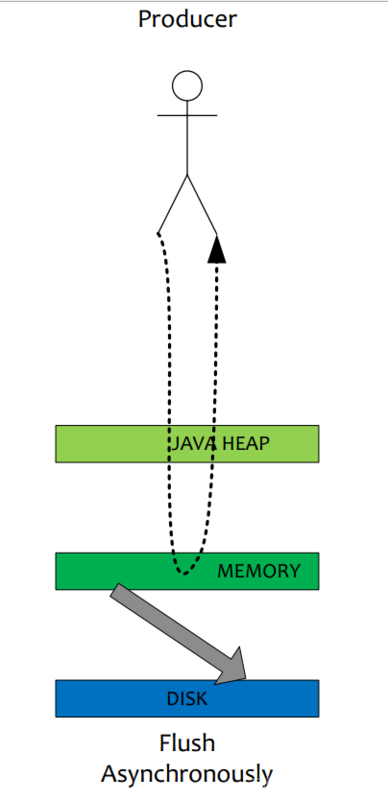
ЭЌВНЫЂХЬгывьВНЫЂХЬЕФЮЈвЛЧјБ№ЪЧвьВНЫЂХЬаДЭъ PAGECACHE жБНгЗЕЛиЃЌЖјЭЌВНЫЂХЬашвЊЕШД§ЫЂХЬЭъГЩВХЗЕЛиЃЌЭЌВНЫЂХЬСїГЬШчЯТЃК
ЃЈ1ЃЉаДШы PAGECACHE КѓЃЌЯпГЬЕШД§ЃЌЭЈжЊЫЂХЬЯпГЬЫЂХЬЁЃ
ЃЈ2ЃЉЫЂХЬЯпГЬЫЂХЬКѓЃЌЛНабЧАЖЫЕШД§ЯпГЬЃЌПЩФмЪЧвЛХњЯпГЬЁЃ
ЃЈ3ЃЉЧАЖЫЕШД§ЯпГЬЯђгУЛЇЗЕЛиГЩЙІЁЃ
3.ЯћЯЂВщбЏ
3.1АДееMessageIdВщбЏЯћЯЂ
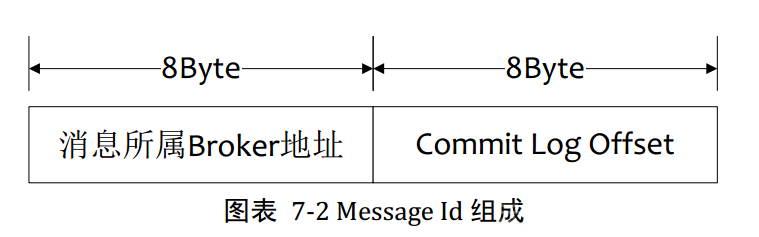
MsgIdзмЙВ16ИізжНкЃЌАќКЌЯћЯЂДЂДцжїЛњЕижЗЃЌЯћЯЂCommit Log OffsetЁЃДгMsgIdжаНтЮіГіBrokerЕФЕижЗКЭCommit
Log ЦЋвЦЕижЗЃЌШЛКѓАДееДцДЂИёЪНЫљдкЮЛжУЯћЯЂbufferНтЮіГЩвЛИіЭъећЯћЯЂ
3.2АДееMessage KeyВщбЏЯћЯЂ
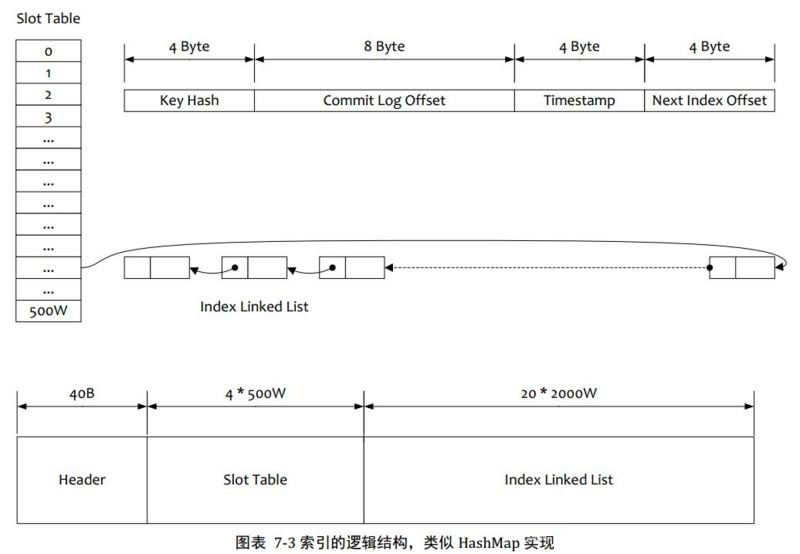
1.ИљОнВщбЏЕФkeyЕФhashcode%slotNumЕУЕНОпЬхЕФВлЮЛжУ ЃЈslotNumЪЧвЛИіЫїв§ЮФМўРяУцАќКЌЕФзюДѓВлФПЪ§ФПЃЌР§ШчЭМжаЫљЪОslotNum=500WЃЉ
2.ИљОнslotValueЃЈslotЖдгІЮЛжУЕФжЕЃЉВщевЕНЫїв§ЯюСаБэЕФзюКѓвЛЯюЃЈЕЙађХХСаЃЌslotValueзмЪЧжИЯђзюаТЕФвЛИіЫїв§ЯюЃЉ
3.БщРњЫїв§ЯюСаБэЗЕЛиВщбЏЪБМфЗЖЮЇФкЕФНсЙћМЏЃЈФЌШЯвЛДЮзюДѓЗЕЛиЕФ32ЬѕМЧТМЃЉ
4.HashГхЭЛЃЌбАевkeyЕФslotЮЛжУЪБЯрЕБгкжДааСЫСНДЮЩЂСаКЏЪ§ЃЌвЛДЮkeyЕФhashЃЌвЛДЮkeyЕФhashШЁжЕФЃЃЌвђДЫетРяДцдкСНДЮГхЭЛЕФЧщПіЃЛЕквЛжжЃЌkeyЕФhashжЕВЛЭЌЕЋФЃЪ§ЯрЭЌЃЌДЫЪБВщбЏЕФЪБКђЛсдкБШНЯЕквЛДЮkeyЕФhashжЕЃЈУПИіЫїв§ЯюБЃДцСЫkeyЕФhashжЕЃЉЃЌЙ§ТЫЕєhashжЕВЛЯыЕШЕФЧщПіЁЃЕкЖўжжЃЌhashжЕЯрЕШkeyВЛЯыЕШЃЌГігкадФмЕФПМТЧГхЭЛЕФМьВтЗХЕНПЭЛЇЖЫДІРэЃЈkeyЕФдЪМжЕЪЧДцДЂдкЯћЯЂЮФМўжаЕФЃЌБмУтЖдЪ§ОнЮФМўЕФНтЮіЃЉЃЌПЭЛЇЖЫБШНЯвЛДЮЯћЯЂЬхЕФkeyЪЧЗёЯрЭЌ
5.ДцДЂЃЌЮЊСЫНкЪЁПеМфЫїв§ЯюжаДцДЂЕФЪБМфЪЧЪБМфВюжЕЃЈДцДЂЪБМфЁЊЁЊПЊЪМЪБМфЃЌПЊЪМЪБМфДцДЂдкЫїв§ЮФМўЭЗжаЃЉЃЌећИіЫїв§ЮФМўЪЧЖЈГЄЕФЃЌНсЙЙвВЪЧЙЬЖЈЕФ
4.ЗўЮёЦїЯћЯЂЙ§ТЫ
RocketMQЕФЯћЯЂЙ§ТЫЗНЪНгаБ№гкЦфЫћЕФЯћЯЂжаМфМўЃЌЪЧдкЖЉдФЪБЃЌдйзіЙ§ТЫЃЌЯШРДПДЯТConsume
QueueДцДЂНсЙЙ
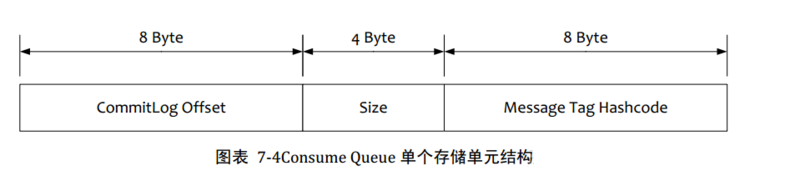
1.дкBrokerЖЫНјааMessage TagБШНЯЃЌЯШБщРњConsume QueueЃЌШчЙћДцДЂЕФMessage
TagгыЖЉдФЕФMessage TagВЛЗћКЯЃЌдђЬјЙ§ЃЌМЬајБШЖдЯТвЛИіЃЌЗћКЯдђДЋЪфИјConsumerЁЃзЂвтMessage
TagЪЧзжЗћДЎаЮЪНЃЌConsume QueueжаДцДЂЕФЪЧЦфЖдгІЕФhashcodeЃЌБШЖдЪБвВЪЧБШЖдhashcode
2.ConsumerЪеЕНЙ§ТЫЯћЯЂКѓЃЌЭЌбљвВвЊжДаадкbrokerЖЫЕФВйзїЃЌЕЋЪЧБШЖдЕФЪЧецЪЕЕФMessage
TagзжЗћДЎЃЌЖјВЛЪЧhashcode
ЮЊЪВУДЙ§ТЫвЊетУДзіЃП
1.Message TagДцДЂhashcodeЃЌЪЧЮЊСЫдкConsume QueueЖЈГЄЗНЪНДцДЂЃЌНкдМПеМф
2.Й§ТЫЙ§ГЬжаВЛЛсЗУЮЪCommit Log Ъ§ОнЃЌПЩвдБЃжЄЖбЛ§ЧщПіЯТвВФмИпаЇЙ§ТЫ
3.МДЪЙДцдкhashГхЭЛЃЌвВПЩвддкConsumerЖЫНјаааое§ЃЌБЃжЄЭђЮовЛЪЇ
5.ЕЅИіJVMНјГЬвВФмРћгУЛњЦїГЌДѓФкДц
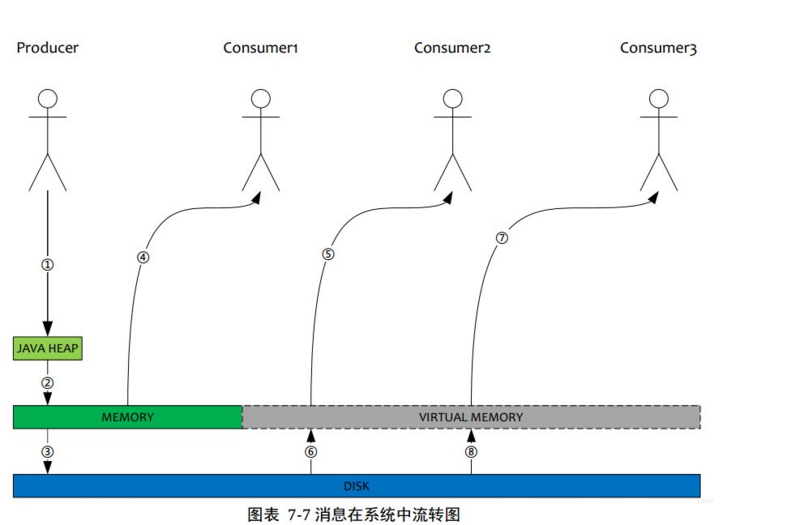
1.ProducerЗЂЫЭЯћЯЂЃЌЯћЯЂДгsocketНјШыjava Жб
2.ProducerЗЂЫЭЯћЯЂЃЌЯћЯЂДгjavaЖбНјШыpagecacheЃЌЮяРэФкДц
3.ProducerЗЂЫЭЯћЯЂЃЌгЩвьВНЯпГЬЫЂХЬЃЌЯћЯЂДгpagecacheЫЂШыДХХЬ
4.ConsumerРЯћЯЂЃЈе§ГЃЯћЗбЃЉЃЌЯћЯЂжБНгДгpagecacheЃЈЪ§ОндкЮяРэФкДцЃЉзЊШыsocketЃЌЕНДяConsumerЃЌВЛОЙ§javaЖбЁЃетжжЯћЗбГЁОАзюЖрЃЌЯпЩЯ96GЮяРэФкДцЃЌАДее1KЯћЯЂЫуЃЌПЩвдЮяРэЛКДц1вкЬѕЯћЯЂ
5.ConsumerРЯћЯЂЃЈвьГЃЯћЗбЃЉЃЌЯћЯЂжБНгДгpagecacheзЊШыsocket
6.ConsumerРЯћЯЂЃЈвьГЃЯћЗбЃЉЃЌгЩгкsocketЗУЮЪСЫащФтФкДцЃЌВњЩњШБвГжаЖЯЃЌДЫЪБЛсВњЩњДХХЬIOЃЌДгДХХЬLoadЯћЯЂЕНpagecacheЃЌШЛКѓжБНгДгsocketЗЂГіШЅ
7.ЭЌ5
8.ЭЌ6
6.ЯћЯЂЖбЛ§ЮЪЬтНтОіАьЗЈ
1 ЯћЯЂЕФЖбЛ§ШнСПЁЂвРРЕДХХЬДѓаЁ
2 ЗЂЯћЯЂЕФЭЬЭТСПДѓаЁЪмгАЯьГЬЖШЁЂЮоSlaveЧщПіЃЌЛсЪмвЛЖЈгАЯьЁЂгаSlaveЧщПіЃЌВЛЪмгАЯь
3 е§ГЃЯћЗбЕФConsumerЪЧЗёЛсЪмгАЯьЁЂЮоSlaveЧщПіЃЌЛсЪмвЛЖЈгАЯьЁЂгаSlaveЧщПіЃЌВЛЪмгАЯь
4 ЗУЮЪЖбЛ§дкДХХЬЕФЯћЯЂЪБЃЌЭЬЭТСПгаЖрДѓЁЂгыЗУЮЪЕФВЂЗЂгаЙиЃЌзюжеЛсНЕЕН5000зѓгв
дкгаSlaveЧщПіЯТЃЌMasterвЛЕЉЗЂЯжConsumerЗУЮЪЖбЛ§дкДХХЬЕФЪ§ОнЪБЃЌЛиЯыConsumerЯТДявЛИіжиЖЈЯђжИСюЃЌСюConsumerДгSlaveРШЁЪ§ОнЃЌетбље§ГЃЕФЗЂЯћЯЂгые§ГЃЕФЯћЗбВЛЛсвђЮЊЖбЛ§ЪмгАЯьЃЌвђЮЊЯЕЭГНЋЖбЛ§ГЁОАгыЗЧЖбЛ§ГЁОАЗжИюдкСЫСНИіВЛЭЌЕФНкЕуДІРэЁЃетРяЛсВњЩњвЛИіЮЪЬтЃЌSlaveЛсВЛЛсаДадФмЯТНЕЃЌД№АИЪЧЗёЖЈЕФЁЃвђЮЊSlaveЕФЯћЯЂаДШыжЛзЗЧѓЭЬЭТСПЃЌВЛзЗЧѓЪЕЪБадЃЌжЛвЊећЬхЕФЭЬЭТСПИпОЭааСЫЃЌЖјSlaveУПДЮЖМЪЧДгMasterРШЁвЛХњЪ§ОнЃЌШч1MЃЌетжжХњСПЫГађаДШыЗНЪНЪЙЖбЛ§ЧщПіЃЌећЬхЭЬЭТСПгАЯьЯрЖдНЯаЁЃЌжЛЪЧаДШыRTЛсБфГЄЁЃ
ЗўЮёЖЫАВзАВПЪ№
ЮвЪЧдкащФтЛњжаЕФCentOS6.5жаНјааВПЪ№ЁЃ
1.ЯТдиГЬађ
2.tar -xvf alibaba-rocketmq-3.0.7.tar.gz НтбЙЕНЪЪЕБЕФФПТМШч/opt/ФПТМ
3.ЦєЖЏRocketMQЃКНјШыrocketmq/bin ФПТМ жДаа

4.ЦєЖЏBrokerЃЌЩшжУЖдгІЕФNameServer

БраДПЭЛЇЖЫ
ПЩвдВщПДsamepleжаЕФquickstartдДТы 1.Consumer ЯћЯЂЯћЗбеп
2.ProducerЯћЯЂЩњВњеп
3.ЪзЯШдЫааConsumerГЬађЃЌвЛжБдкдЫаазДЬЌНгЪеЗўЮёЦїЖЫЭЦЫЭЙ§РДЕФЯћЯЂ
4.дйДЮдЫааProducerГЬађЃЌЩњГЩЯћЯЂВЂЗЂЫЭЕНBrokerЃЌProducerЕФШежОГхУЛСЫЃЌЕЋЪЧПЩвдПДЕНBrokerЭЦЫЭЕНConsumerЕФвЛЬѕЯћЯЂ

ConsumerзюМбЪЕМљ
1.ЯћЗбЙ§ГЬвЊзіЕНУнЕШЃЈМДЯћЗбЖЫШЅжиЃЉ
RocketMQЮоЗЈзіЕНЯћЯЂжиИДЃЌЫљвдШчЙћвЕЮёЖдЯћЯЂжиИДЗЧГЃУєИаЃЌЮёБивЊдквЕЮёВуУцШЅжиЃЌгавдЯТвЛаЉЗНЪНЃК
ЃЈ1ЃЉ.НЋЯћЯЂЕФЮЈвЛМќЃЌПЩвдЪЧMsgIdЃЌвВПЩвдЪЧЯћЯЂФкШнжаЕФЮЈвЛБъЪЖзжЖЮЃЌР§ШчЖЉЕЅIDЃЌЯћЗбжЎЧАХаЖЯЪЧЗёдкDBЛђTairЃЈШЋОжKVДцДЂЃЉжаДцдкЃЌШчЙћВЛДцдкдђВхШыЃЌВЂЯћЗбЃЌЗёдђЬјЙ§ЁЃЃЈЪЕМљЙ§ГЬвЊПМТЧдзгадЮЪЬтЃЌХаЖЯЪЧЗёДцдкПЩвдГЂЪдВхШыЃЌШчЙћБЈжїМќГхЭЛЃЌдђВхШыЪЇАмЃЌжБНгЬјЙ§ЃЉ
msgidвЛЖЈЪЧШЋОжЮЈвЛЕФБъЪЖЗћЃЌЕЋЪЧПЩФмЛсДцдкЭЌбљЕФЯћЯЂгаСНИіВЛЭЌЕФmsgidЕФЧщПіЃЈгаЖржждвђЃЉЃЌетжжЧщПіПЩФмЛсЪЙвЕЮёЩЯжиИДЃЌНЈвщзюКУЪЙгУЯћЯЂЬхжаЕФЮЈвЛБъЪЖзжЖЮШЅжи
ЃЈ2ЃЉ.ЪЙвЕЮёВуУцЕФзДЬЌЛњШЅжи
2.ХњСПЗНЪНЯћЗб
ШчЙћвЕЮёСїГЬжЇГжХњСПЗНЪНЯћЗбЃЌдђПЩвдКмДѓГЬЖШЩЯЕФЬсИпЭЬЭТСПЃЌПЩвдЭЈЙ§ЩшжУConsumerЕФconsumerMessageBatchMaxSizeВЮЪ§ЃЌФЌШЯЪЧ1ЃЌМДвЛДЮЯћЗбвЛЬѕВЮЪ§
3.ЬјЙ§ЗЧживЊЕФЯћЯЂ
ЗЂЩњЯћЯЂЖбЛ§ЪБЃЌШчЙћЯћЗбЫйЖШвЛжБИњВЛЩЯЗЂЫЭЫйЖШЃЌПЩвдбЁдёЖЊЦњВЛживЊЕФЯћЯЂ

ШчвдЩЯДњТыЫљЪОЃЌЕБФГИіЖгСаЕФЯћЯЂЪ§ЖбЛ§ЕН 100000 ЬѕвдЩЯЃЌдђГЂЪдЖЊЦњВПЗжЛђШЋВПЯћЯЂЃЌетбљОЭПЩвдПьЫйзЗЩЯЗЂЫЭЯћЯЂЕФЫйЖШ
4.гХЛЏУЛЬѕЯћЯЂЯћЗбЙ§ГЬ
ОйР§ШчЯТЃЌФГЬѕЯћЯЂЕФЯћЗбЙ§ГЬШчЯТ
1ЁЂИљОнЯћЯЂДг DB ВщбЏЪ§Он 1
2ЁЂИљОнЯћЯЂДг DB ВщбЏЪ§Он2
3ЁЂИДдгЕФвЕЮёМЦЫу
4ЁЂЯђ DB ВхШыЪ§Он3
5ЁЂЯђ DB ВхШыЪ§Он 4
етЬѕЯћЯЂЕФЯћЗбЙ§ГЬгы DB НЛЛЅСЫ 4 ДЮЃЌШчЙћАДееУПДЮ 5ms МЦЫуЃЌФЧУДзмЙВКФЪБ 20msЃЌМйЩшвЕЮёМЦЫуКФЪБ
5msЃЌФЧУДзмЙ§КФЪБ 25msЃЌШчЙћФмАб 4 ДЮ DB НЛЛЅгХЛЏЮЊ 2 ДЮЃЌФЧУДзмКФЪБОЭПЩвдгХЛЏЕН
15msЃЌвВОЭЪЧЫЕзмЬхадФмЬсИпСЫ 40%ЁЃ
Ждгк Mysql ЕШ DBЃЌШчЙћВПЪ№дкДХХЬЃЌФЧУДгы DB НјааНЛЛЅЃЌШчЙћЪ§ОнУЛгаУќжа cacheЃЌУПДЮНЛЛЅЕФ
RT ЛсжБЯпЩЯЩ§ЃЌ ШчЙћВЩгУ SSDЃЌдђ RT ЩЯЩ§ЧїЪЦвЊУїЯдКУгкДХХЬЁЃ
ИіБ№гІгУПЩФмЛсгіЕНетжжЧщПіЃКдкЯпЯТбЙВтЯћЗбЙ§ГЬжаЃЌdb БэЯжЗЧГЃКУЃЌУПДЮ RT ЖМКмЖЬЃЌЕЋЪЧЩЯЯпдЫаавЛЖЮЪБМфЃЌRT
ОЭЛсБфГЄЃЌЯћЗбЭЬЭТСПжБЯпЯТНЕ
жївЊдвђЪЧЯпЯТбЙВтЪБМфЙ§ЖЬЃЌЯпЩЯдЫаавЛЖЮЪБМфКѓЃЌcache УќжаТЪЯТНЕЃЌФЧУД RT ОЭЛсдіМгЁЃНЈвщдкЯпЯТбЙВтЪБЃЌвЊВтЪдзуЙЛГЄЪБМфЃЌОЁПЩФмФЃФтЯпЩЯЛЗОГЃЌбЙВтЙ§ГЬжаЃЌЪ§ОнЕФЗжВМвВКмживЊЃЌЪ§ОнВЛЭЌЃЌПЩФм
cache ЕФУќжаТЪвВЛсЭъШЋВЛЭЌ
ProducerзюМбЪЕМљ
1.ЗЂЫЭЯћЯЂзЂвтЪТЯю
ЃЈ1ЃЉ вЛИігІгУОЁПЩФмгУвЛИі TopicЃЌЯћЯЂзгРраЭгУ tags РДБъЪЖЃЌtags ПЩвдгЩгІгУздгЩЩшжУЁЃжЛгаЗЂЫЭЯћЯЂЩшжУСЫtagsЃЌЯћЗбЗНдкЖЉдФЯћЯЂЪБЃЌВХПЩвдРћгУ
tags дк broker зіЯћЯЂЙ§ТЫЁЃ
ЃЈ2ЃЉУПИіЯћЯЂдквЕЮёВуУцЕФЮЈвЛБъЪЖТыЃЌвЊЩшжУЕН keys зжЖЮЃЌЗНБуНЋРДЖЈЮЛЯћЯЂЖЊЪЇЮЪЬтЁЃЗўЮёЦїЛсЮЊУПИіЯћЯЂДДНЈЫїв§ЃЈЙўЯЃЫїв§ЃЉЃЌгІгУПЩвдЭЈЙ§
topicЃЌkey РДВщбЏетЬѕЯћЯЂФкШнЃЌвдМАЯћЯЂБЛЫЯћЗбЁЃгЩгкЪЧЙўЯЃЫїв§ЃЌЧыЮёБиБЃжЄ key ОЁПЩФмЮЈвЛЃЌетбљПЩвдБмУтЧБдкЕФЙўЯЃГхЭЛЁЃ
ЃЈ3ЃЉЯћЯЂЗЂЫЭГЩЙІЛђепЪЇАмЃЌвЊДђгЁЯћЯЂШежОЃЌЮёБивЊДђгЁ sendresult КЭ key зжЖЮ
ЃЈ4ЃЉsend ЯћЯЂЗНЗЈЃЌжЛвЊВЛХзвьГЃЃЌОЭДњБэЗЂЫЭГЩЙІЁЃЕЋЪЧЗЂЫЭГЩЙІЛсгаЖрИізДЬЌЃЌдк sendResult
РяЖЈвх
SEND_OKЃКЯћЯЂЗЂЫЭГЩЙІ
FLUSH_DISK_TIMEOUTЃКЯћЯЂЗЂЫЭГЩЙІЃЌЕЋЪЧЗўЮёЦїЫЂХЬГЌЪБЃЌЯћЯЂвбОНјШыЗўЮёЦїЖгСаЃЌжЛгаДЫЪБЗўЮёЦїхДЛњЃЌЯћЯЂВХЛсЖЊЪЇ
FLUSH_SLAVE_TIMEOUTЃКЯћЯЂЗЂЫЭГЩЙІЃЌЕЋЪЧЗўЮёЦїЭЌВНЕН Slave ЪБГЌЪБЃЌЯћЯЂвбОНјШыЗўЮёЦїЖгСаЃЌжЛгаДЫЪБЗўЮёЦїхДЛњЃЌЯћЯЂВХЛсЖЊЪЇ
SLAVE_NOT_AVAILABLEЃКЯћЯЂЗЂЫЭГЩЙІЃЌЕЋЪЧДЫЪБ slave ВЛПЩгУЃЌЯћЯЂвбОНјШыЗўЮёЦїЖгСаЃЌжЛгаДЫЪБЗўЮёЦїхДЛњЃЌЯћЯЂВХЛсЖЊЪЇЁЃЖдгкОЋШЗЗЂЫЭЫГађЯћЯЂЕФгІгУЃЌгЩгкЫГађЯћЯЂЕФОжЯоадЃЌПЩФмЛсЩцМАЕНжїБИздЖЏЧаЛЛЮЪЬтЃЌЫљвдШчЙћsendresult
жаЕФ status зжЖЮВЛЕШгк SEND_OKЃЌОЭгІИУГЂЪджиЪдЁЃЖдгкЦфЫћгІгУЃЌдђУЛгаБивЊетбљ
ЃЈ5ЃЉЖдгкЯћЯЂВЛПЩЖЊЪЇгІгУЃЌЮёБивЊгаЯћЯЂжиЗЂЛњжЦ
2.ЯћЯЂЗЂЫЭЪЇАмДІРэ
Producer ЕФ send ЗНЗЈБОЩэжЇГжФкВПжиЪдЃЌжиЪдТпМШчЯТЃК
ЃЈ1ЃЉ жСЖржиЪд 3 ДЮ
ЃЈ2ЃЉ ШчЙћЗЂЫЭЪЇАмЃЌдђТжзЊЕНЯТвЛИі Broker
ЃЈ3ЃЉ етИіЗНЗЈЕФзмКФЪБЪБМфВЛГЌЙ§ sendMsgTimeout ЩшжУЕФжЕЃЌФЌШЯ 10sЫљвдЃЌШчЙћБОЩэЯђ
broker ЗЂЫЭЯћЯЂВњЩњГЌЪБвьГЃЃЌОЭВЛЛсдйзіжиЪд
ШчЃК
ШчЙћЕїгУ send ЭЌВНЗНЗЈЗЂЫЭЪЇАмЃЌдђГЂЪдНЋЯћЯЂДцДЂЕН dbЃЌгЩКѓЬЈЯпГЬЖЈЪБжиЪдЃЌБЃжЄЯћЯЂвЛЖЈЕНДя
BrokerЁЃ
ЩЯЪі db жиЪдЗНЪНЮЊЪВУДУЛгаМЏГЩЕН MQ ПЭЛЇЖЫФкВПзіЃЌЖјЪЧвЊЧѓгІгУздМКШЅЭъГЩЃЌЛљгквдЯТМИЕуПМТЧЃК
ЃЈ1ЃЉMQ ЕФПЭЛЇЖЫЩшМЦЮЊЮозДЬЌФЃЪНЃЌЗНБуШЮвтЕФЫЎЦНРЉеЙЃЌЧвЖдЛњЦїзЪдДЕФЯћКФНіНіЪЧ cpuЁЂФкДцЁЂЭјТч
ЃЈ2ЃЉШчЙћ MQ ПЭЛЇЖЫФкВПМЏГЩвЛИі KV ДцДЂФЃПщЃЌФЧУДЪ§ОнжЛгаЭЌВНТфХЬВХФмНЯПЩППЃЌЖјЭЌВНТфХЬБОЩэадФмПЊЯњНЯДѓЃЌЫљвдЭЈГЃЛсВЩгУвьВНТфХЬЃЌгжгЩгкгІгУЙиБеЙ§ГЬВЛЪм
MQ дЫЮЌШЫдБПижЦЃЌПЩФмОГЃЛсЗЂЩњ kill -9 етбљБЉСІЗНЪНЙиБеЃЌдьГЩЪ§ОнУЛгаМАЪБТфХЬЖјЖЊЪЇ
ЃЈ3ЃЉProducer ЫљдкЛњЦїЕФПЩППадНЯЕЭЃЌвЛАуЮЊащФтЛњЃЌВЛЪЪКЯДцДЂживЊЪ§ОнЁЃ злЩЯЃЌНЈвщжиЪдЙ§ГЬНЛгЩгІгУРДПижЦЁЃ
3.бЁдё oneway аЮЪНЗЂЫЭ
вЛИі RPC ЕїгУЃЌЭЈГЃЪЧетбљвЛИіЙ§ГЬ
ЃЈ1ЃЉПЭЛЇЖЫЗЂЫЭЧыЧѓЕНЗўЮёЦї
ЃЈ2ЃЉЗўЮёЦїДІРэИУЧыЧѓ
ЃЈ3ЃЉЗўЮёЦїЯђПЭЛЇЖЫЗЕЛигІД№
ЫљвдвЛИі RPC ЕФКФЪБЪБМфЪЧЩЯЪіШ§ИіВНжшЕФзмКЭЃЌЖјФГаЉГЁОАвЊЧѓКФЪБЗЧГЃЖЬЃЌЕЋЪЧЖдПЩППадвЊЧѓВЂВЛИпЃЌР§ШчШежОЪеМЏРргІгУЃЌДЫРргІгУПЩвдВЩгУ
oneway аЮЪНЕїгУЃЌoneway аЮЪНжЛЗЂЫЭЧыЧѓВЛЕШД§гІД№ЃЌЖјЗЂЫЭЧыЧѓдкПЭЛЇЖЫЪЕЯжВуУцНіНіЪЧвЛИі
os ЯЕЭГЕїгУЕФПЊЯњЃЌМДНЋЪ§ОнаДШыПЭЛЇЖЫЕФ socket ЛКГхЧјЃЌДЫЙ§ГЬКФЪБЭЈГЃдкЮЂУыМЖЁЃ
RocketMQВЛжЙПЩвджБНгЭЦЫЭЯћЯЂЃЌдкЯћЗбЖЫзЂВсМрЬ§ЦїНјааМрЬ§ЃЌЛЙПЩвдгЩЯћЗбЖЫОіЖЈздМКШЅРШЁЪ§Он
ИеПЊЪМЕФУЛгаЯИПДPullResultЖдЯѓЃЌвдЮЊРШЁЕНЕФНсЙћУЛгаMessageExtЖдЯѓЛЙХмЕНШКРяУцЮЪБ№ШЫЃЌЗИ2СЫ
ЬиБ№вЊзЂвт ОВЬЌБфСПoffsetTableЕФзїгУЃЌРШЁЕФЪЧАДееДгoffsetЃЈРэНтЮЊЯТБъЃЉЮЛжУПЊЪМРШЁЃЌРШЁNЬѕЃЌoffsetTableМЧТМЯТДЮРШЁЕФoffsetЮЛжУЁЃ
|








