| БрМЭЦМі: |
БОЮФРДздгкcnblogsЃЌНщЩмСЫЮяСїЯЕЭГЕФЯЕЭГПЩгУТЪЃЌDBЮяРэИєРыЃЌЗўЮёЗжзщИєРыЃЌТЉЖЗФЃаЭЕШЯрЙижЊЪЖЁЃ |
|

ЯЕЭГПЩгУТЪ 

ЖрМЖЛКДц 
ЖЏЬЌЗжзщЧаЛЛ

DBЮяРэИєРы 
ЗўЮёЗжзщИєРы 
ПчЛњЗПИєРы 
ТЉЖЗФЃаЭ 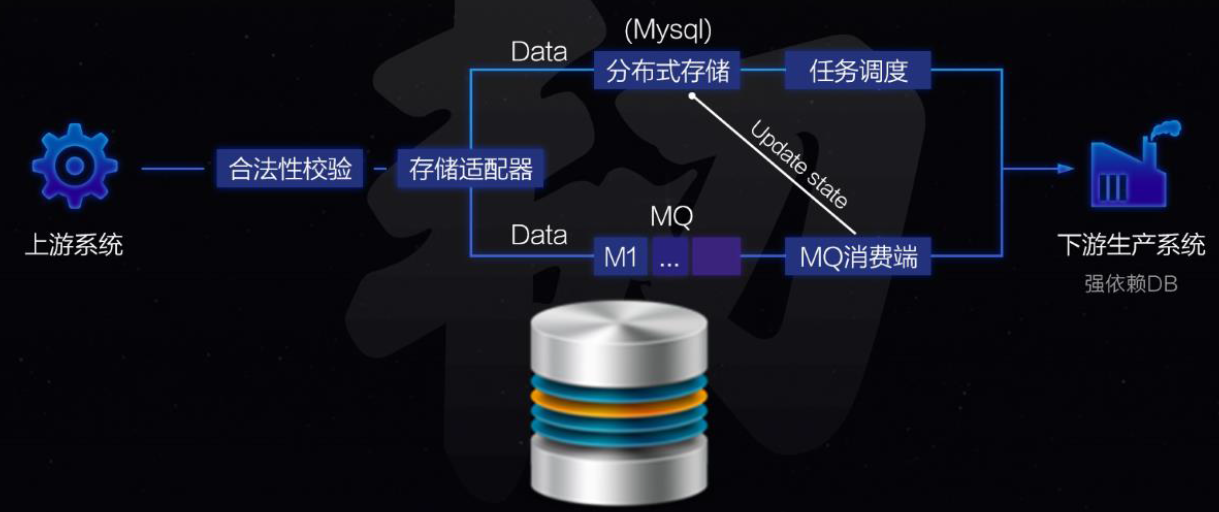

DBЯоСї 



ЯЕЭГвЛАуПЩвдЗжЮЊЧАЖЫгІгУЯЕЭГКЭКѓЖЫЪ§ОнПтЯЕЭГЃЌЧАЖЫгІгУЯЕЭГЪЕЪЉЗжВМЪНМЏШКВПЪ№ММЪѕЩЯЪЧБШНЯГЩЪьЕФЃЌКѓЖЫЪ§ОнПтЯЕЭГЪЕЯжвьЕиЖрЛюММЪѕФбЖШКмДѓЃЌФПЧАвВжЛгаАЂРяЃЌОЉЖЋетбљЕФЙЋЫОВХеце§ЪЕЯжЁЃвђДЫЃЌЖдгкДѓЖрЪ§гІгУЃЌЧАЖЫгІгУЫЋЛњЗПМЏШКВПЪ№ЃЌКѓЖЫЪ§ОнПтЯЕЭГВЩШЁГЩЪьЕФжїБИДгЕФФЃЪНЃЌвВОЭЪЧЕЅИіЛњЗПзїЮЊаДШыЃЌБИПтдкСэЭтЛњЗПЃЌПЩвдПьЫйНјааЧаЛЛЃЌЖСПтЫЋЛњЗПВПЪ№ЃЌЪЧгХбЁЕФЗНАИЁЃЖдгкетИіМмЙЙЗНАИЃЌДцдкПчЛњЗПаДбгГЄЕФЮЪЬтЃЌПЩвдИљОнГЁОАРћгУвьВНЕФЗНЪННјааНтОіЃЌвЛАувВЪЧУЛгаЮЪЬтЕФЁЃЖдгкЯЕЭГРДНВЃЌвВгааЉЬиБ№ЃЌРћгУЗжМ№жааФЕФБОЕиЗўЮёЦїКЭВйзїШЫдБЕФЩшБИЃЌЪЕЯжРыЯпЩњВњЃЌНјвЛВНЬсИпПЩгУадЁЃ
ДѓЯЕЭГаЁзіЃЌЗўЮёВ№ЗжЃЌЪЧЛЅСЊЭјгІгУЕФЬиЕуЃЌвВЗћКЯУєНнНЛИЖЕФРэФюЁЃЖдгкДЋЭГШэМўЃЌШчWindowsЃЌOfficeЕШЃЌЖМвЊОЙ§вЛИіТўГЄЕФашЧѓЃЌбаЗЂЃЌВтЪдЃЌЗЂВМжмЦкЃЌдкЁАЮЈПьВЛЦЦЁБЕФЛЅСЊЭјЪБДњЃЌетЯдШЛЪЧЮоЗЈТњзувЕЮёвЊЧѓЕФЃЌМДЪЙзюКѓЩЯЯпЃЌвВПЩФмвђЮЊжмЦкЬЋГЄЖјВЛдйЪЪгУСЫЁЃвђДЫЃЌЖдвЛИіЛЅСЊЭјЗўЮёЃЌвЛАуЛсЪзЯШЭъГЩзюКЫаФЕФЙІФмЃЌПьЫйНјааЩЯЯпЃЌВЛЖЯНјааЕќДњЃЌКѓајдйНјааИЈжњЙІФмИњНјЁЃЖдгкКЫаФЙІФмЃЌЫцзХгУЛЇЪ§ЕФдіМгЃЌЛсВЛЖЯНјааЗўЮёВ№ЗжЃЌШчКЮНјааВ№ЗжЃЌВ№ЗжЕНЪВУДбљЕФСЃЖШЃЌЪЧВЛЪЧЮЂЗўЮёЪЧНтОіЮЪЬтЕФвјЕЏЃПетаЉЖМвЊИљОнЪЕМЪЕФгІгУГЁОАРДЦРЙРЃЌОјВЛЪЧдНЯИдНКУЃЌЖјЪЧвЊДяЕНвЛИігХбХЕФЦНКтЁЃ
ВЂЗЂПижЦЃЌЗўЮёИєРыЁЃВЂЗЂПижЦЃЌЯждквбОГЩЮЊЛЅСЊЭјЗўЮёЛљБОвЊЧѓЃЌдкгІгУГЬађЖЫКЭЪ§ОнПтЖЫЃЌвВЖМгаГЩЪьЕФЗНАИЃЌШчЙћКіТдЃЌПЩФмдьГЩджФбадЕФКѓЙћЁЃЖдгкживЊЕФЗўЮёЃЌЛЙвЊНјааИєРыЃЌР§ШчЭЌвЛИіЗўЮёЃЌвЊЬсЙЉИјФкВПЕїгУЃЌЙЋЫОМЖЕїгУКЭЙЋЫОЭтПЊЗХЗўЮёЕїгУЃЌПЊЗХЗўЮёЕїгУепЮвУЧвЛАуШЯЮЊЪЧВЛПЩППЕФЃЌЩѕжСгаПЩФмЪЧЖёвтЕФЃЌШчЙћВЛНјааИєРыЃЌПЊЗХЗўЮёЕїгУгаПЩФмЪЙЕУЗўЮёзЪдДеМТњЃЌЖдФквВЮоЗЈЬсЙЉЗўЮёЁЃДгММЪѕЩЯЃЌПЩвдЪЧгВМўМЖИєРыЃЌШЋВПИєРыЃЌвВПЩвдЪЧЧАЖЫгІгУЕФИєРыЁЃ
ЛвЖШЗЂВМвВЪЧЛЅСЊЭјЗўЮёЕФвЛДѓРћЦїЃЌгаСЫЛвЖШЗЂВМЃЌВХЪЙЕУПьЫйЕќДњГЩЮЊПЩФмЃЌВЂЧвЃЌКмЖрЗўЮёвђЮЊИїжждвђЯпЯТвВЪЧКмФбВтЪдЕФЃЌжЛФмдкЯпЩЯВтЪдЁЃШчЙћУЛгаЛвЖШЗЂВМЃЌжЛФмШЋСПЗЂВМЃЌОЭДцдкНЯГЄВтЪджмЦкЮЪЬтЃЌШчЙћУЛгажиИДУуЧПЩЯЯпЃЌОЭДцдкКмДѓЕФЯЕЭГБРРЃЕФЗчЯеЁЃАДеегУЛЇЃЌЧјгђНјааЛвЖШЗЂВМЪЧБШНЯГЃгУЕФЗНЗЈЁЃ
ШЋЗНЮЛМрПиБЈОЏЃЌПЩвдЗжЮЊММЪѕВуУцКЭвЕЮёВуУцЃЌММЪѕВуУцАќРЈЖдCPUЃЌФкДцЃЌДХХЬЃЌЭјТчЕШЕФМрПиЃЌвЕЮёВуУцЃЌАќРЈЖдДІРэЛ§бЙСПЃЌе§ГЃЕФвЕЮёСПЕШЁЃзіЕНШЋЗНЮЛМрПиЃЌВХгаПЩФмдкгАЯьгУЛЇжЎЧАЃЌЬсЧАНтОіЮЪЬтЃЌЬсЩ§ЯЕЭГПЩгУадЁЃЗёдђЃЌЕШгУЛЇЗЂЯжЮЪЬтЃЌдкКмДѓЕФбЙСІЯТЃЌММЪѕЭХЖгИќФбДІРэЃЌЕМжТЯЕЭГВЛПЩгУЪБМфМгГЄЁЃ
КЫаФЗўЮёЃЌЦНЛЌНЕМЖЁЃШЮКЮММЪѕЪжЖЮЃЌЖМВЛПЩФмБЃеЯ100%ПЩгУЃЌВЂЧвЃЌМДЪЙФмЙЛзіЕНЃЌЦфДњМлвВЪЧОоДѓЃЌВЛОМУЕФЃЌвђДЫЃЌЖдгкКЫаФЗўЮёРДНВЃЌФмЙЛЦНЛЌНјааНЕМЖЃЌЬсЙЉЛљДЁЕФЗўЮёЃЌвВЪЧЗЧГЃживЊЕФЁЃЖдгкЯЕЭГРДНВЃЌОЭРћгУЗжМ№жааФБОЕиЗўЮёЦїКЭВйзїШЫдБЕФЩшБИЃЌбаЗЂСЫРыЯпЩњВњЯЕЭГЃЌРДгІЖдМЏжаЗўЮёЭђвЛВЛПЩгУЕФЧщПіЁЃ
ДѓаЭЛЅСЊЭјЗўЮёЃЌвЛАуЖМЮЂЗўЮёЛЏСЫЃЌетбљвтЮЖзХвЛИігУЛЇВйзїЃЌЖМЪЧгЩЖрИіЗўЮёНгПкжЇГжЃЌШчЙћАДееДЋЭГЕФЭЌВННгПкЩшМЦЃЌФЧУДЃЌВЛНіУцСйадФмЮЪЬтЃЌЖјЧвЃЌQPSвВЪЧЮоЗЈТњзуЕФЃЌвђДЫЃЌашвЊНЋЭЌВННгПкЕїгУвьВНЛЏЁЃдк2012ФъзѓгвЃЌeBayОЭЬсГіЫљгаЯЕЭГЕїгУвьВНЛЏЃЌКѓУцЃЌМИКѕЫљгаДѓаЭЛЅСЊЭјЙЋЫОЃЌЖМЖдздЩэЯЕЭГНјааСЫвьВНЛЏИФдьЃЌВЂЧвЃЌШЁЕУСЫКмКУЕФаЇЙћЃЌдкКЭЬкбЖCTO
TonyНЛСїжаЃЌЫћОЭЬсГіМДЪЙжЇИЖетжжЗўЮёЃЌвВЪЧгаАьЗЈНјаавьВНЛЏЩшМЦЕФЁЃЭЌВННгПквьВНЛЏЃЌвВЪЧашвЊЯЕЭГЙЄОпжЇГжЕФЁЃ
Ъ§ОнвЛжТад
ЮвУЧОЭФмЗжЮЊЫФИіЛљБОЕФГЁОАЃКИпЪЕЪБад/ИпвЛжТадЃЌИпЪЕЪБад/ЕЭвЛжТадЃЌЕЭЪЕЪБад/ИпвЛжТадЃЌЕЭЪЕЪБад/ЕЭвЛжТадЁЃеыЖдОпЬхЕФвЕЮёЃЌЮвУЧПЩвдЦЅХфЕНОпЬхЕФЪ§ОнГЁОАЃЌетбљЃЌЮвУЧОЭФмевЕНЖдгІЕФНтОіЗНАИ
ЪЕЪБ&ЧПвЛжТГЁОАЃКетИідкДѓЪ§ОнММЪѕГЩЪьжЎЧАЃЌЪЧЗЧГЃМЌЪжЕФЃЌЕЋЪЧЃЌЯждкНтОіЗНАИвбОБШНЯГЩЪьСЫЁЃЕфаЭгІгУЪЧЩњВњЯЕЭГЕФЪЕЪБМрПиЃЌР§ШчЪЕЪБЩњВњСПЃЌИїИіЩњВњЛЗНкВювьСПЕШЃЌЦфЪЕЪЧзїЮЊЩњВњЯЕЭГЕФвЛВПЗжЁЃРћгУЕБЧАжїСїЕФДѓЪ§ОнДІРэМмЙЙЪЧПЩвдНтОіЕФЃЌР§ШчЯпЩЯЩњВњПтbinlogЪЕЪБЖСШЁЃЌKafakaНјааЪ§ОнДЋЪфЃЌSparkНјааСїЪНМЦЫуЃЌESНјааЪ§ОнДцДЂЕШЁЃШчЙћРћгУДЋЭГЕФETLГщШЁЗНАИРДНтОіЃЌЦЕЗБЖдЩњВњЪ§ОнПтНјааГщШЁЃЌВЂВЛЪЧПЩааЕФЗНАИЃЌвђЮЊЃЌетбљЛсМЋДѓЕФгАЯьЯпЩЯOLTPЯЕЭГЕФадФмЁЃЛЙПЩвдОйвЛИіЩњВњЯЕЭГЪЕЪБМрПиАИР§ЃЌМмЙЙЗНАИЪЧгІгУЯЕЭГЭъГЩаДЪ§ОнПтЕФЭЌЪБЃЌАбФкШнЭЈЙ§ЯћЯЂЗЂЫЭЃЌКѓУцЕФДѓЪ§ОнДІРэЯЕЭГНгЪеЯћЯЂРДНјааДІРэЃЌетИіМмЙЙЗНАИЃЌЖдгкЪЕЪБадФГжжГЬЖШЩЯПЩвдБЃеЯЃЌЕЋЪЧЃЌвВДцдкаЇТЪЮЪЬтЃЌЕЋЪЧЃЌЖдгкЧПвЛжТадОЭЗЧГЃВЛКЯЪЪСЫЃЌвђЮЊЯћЯЂЯЕЭГШчActiveMQЕШВЛНіЮоЗЈБЃеЯЯћЯЂЪ§ОнВЛФмЖЊЪЇЃЌЖјЧвЖдгІЯћЯЂЫГађвВЪЧЮоЗЈБЃеЯЃЌЯюФПЪЕЪЉКѓЃЌЫфШЛВЩШЁСЫКмЖрВЙОШДыЪЉЃЌвВЮоЗЈТњзуЧПвЛжТадашЧѓЃЌВЛЕУВЛжиЦ№ТЏдюЁЃ
ЪЕЪБ&ШѕвЛжТадГЁОАЃКЕфаЭЕФгІгУГЁОАЪЧЯћЯЂЭЈжЊЃЌР§ШчЕчЩЬЕФШЋГЬИњзйЯћЯЂЃЌШчЙћИіБ№Ъ§ОнГіЯжЖЊЪЇЃЌЖдгкгУЛЇЕФгАЯьВЂВЛДѓЃЌвВЪЧПЩвдНгЪмЕФЃЌвђДЫЃЌПЩвдВЩгУИќМгСЎМлЕФНтОіЗНАИЃЌгІгУЭъГЩЖдгІЕФЖЏзїКѓЃЌНЋЯћЯЂЗЂГіМДПЩЃЌЪЙгУЗНЖЉдФЖдгІЕФЯћЯЂЃЌАДеежїМќЃЌШчЖЉЕЅКХЃЌДцДЂМДПЩЁЃ
РыЯп&ЧПвЛжТГЁОАЃКетЪЧЕфаЭЕФДѓЪ§ОнЗжЮіГЁОАЃЌвВОЭЪЧжкЖрЕФРыЯпБЈБэФЃЪНЁЃДгММЪѕЩЯЃЌДЋЭГЕФETLГщШЁММЪѕвВФмТњзувЊЧѓЃЌЪ§ОнВжПтЖдгІЕФММЪѕвВФмЙЛНтОіЁЃ
РыЯп&ШѕвЛжТГЁОАЃКЖдгкзЅШЁЛЅСЊЭјЪ§ОнЃЌШежОЗжЮіЕШНјааЭГМЦЯЕЭГЃЌгУгкЭГМЦЧїЪЦРрЕФгІгУЃЌПЩвдЙщЮЊДЫРрЃЌетРргІгУжївЊЪЧПДФмЙЛгазуЙЛСЎМлЕФЗНАИРДНтОіЃЌЪЧВЛЪЧПЩвдЧЩУюЕФРћгУПеЯаЕФМЦЫузЪдДЁЃетИідкКмЖрЙЋЫОЃЌРћгУЭэЩЯПеЯаЕФМЦЫузЪдДЃЌРДДІРэДЫРрЕФашЧѓЁЃ
дкЖдвЕЮёФмЪзЯШЪЧвЕЮёЪ§ОнЛЏЃЌВЂЧвОпгаЪ§ОнжЪСПБЃеЯЁЃЯЕЭГЕФжЇГХЯТЃЌЪЕЯжСЫЫљгаЮяСїВйзїЕФЯпЩЯЛЏЃЌвВОЭЪЧЪ§ОнЛЏЃЌВЂЧвЃЌЖдУПИіВйзїЛЗНкЖМЪЧПЩвдНјааЪЕЪБЗжЮіЃЌетОЭЕьЖЈСЫКмКУЕФЛљДЁЁЃШчЙћвЕЮёЖМЪЧЯпЯТВйзїЃЌЛђепЯЕЭГЮоЗЈзМШЗМАЪБЪеМЏЪ§ОнЃЌФЧУДЃЌМДЪБЪ§ОнСПЙЛДѓЃЌШБЗІЙиМќЪ§ОнКЭЪ§ОнВЛзМШЗЃЌвВЛсИјДѓЪ§ОнДІРэДјРДКмДѓЕФРЇФбЁЃЕкЖўЛљДЁОЭЪЧДѓЪ§ОнДІРэММЪѕЃЌАќРЈЪеМЏЃЌДЋЪфЃЌДцДЂЃЌМЦЫуЃЌеЙЪОЕШвЛЯЕСаММЪѕЁЃЙЛНјааЪЕЪБМрПиКЭзМШЗЦРЙРКѓЃЌвВОЭЪЧРћгУДѓЪ§ОнЖдвЕЮёНјаадЄВтЁЃдЄВтвЛжБЪЧДѓЪ§ОнгІгУЕФКЫаФЃЌвВЪЧзюгаМлжЕЕФЕиЗНЁЃЖдгкЮяСїаавЕЃЌШчЙћФмЙЛЬсЧАНјаавЕЮёСПдЄВтЃЌФЧУДЃЌЖдгкзЪдДЕїЖШЕШЗЧГЃгавтвхЃЌВЛНіФмЙЛЪЕЯжИќКУЕФЪБаЇЃЌЖјЧвФмЙЛБмУтРЫЗбЁЃОйвЛИіЕФР§згЃЌОЭЪЧЕЅСПдЄВтЃЌИљОнгУЛЇЯТЕЅСПЃЌВжДЂЩњВњФмСІЃЌТЗгЩЧщПіЕШЃЌПЩвдНјааНЈФЃдЄВтЁЃ
жЧЛлЮяСїЃЌвдДѓЪ§ОнДІРэММЪѕзїЮЊЛљДЁЃЌРћгУШэМўЯЕЭГАбШЫКЭЩшБИИќКУЕФНсКЯЦ№РДЃЌШУШЫКЭЩшБИФмЙЛЗЂЛгИїздЕФгХЪЦЃЌДяЕНЯЕЭГзюМбЕФзДЬЌЁЃ |








