| БрМЭЦМі: |
БОЮФНЋЯђДѓМвНщЩмЪВУДЪЧЗДгІЪНЃЌвдМАЮЊЪВУДвЊВЩгУЗДгІЪНМмЙЙЃЌВЂЧвЭЈЙ§вЛИіБрГЬЪОР§ЃЌЩюШыЗжЮіДЋЭГЕФБрГЬЗНЪНЛсДјРДФФаЉЮЪЬтКЭЬєеНЃЌвдМАШчКЮзівьВНЛЏИФдьЃЌЫГРћТѕГіЗДгІЪНМмЙЙбнНјЕФЕквЛВНЁЃ
БОЮФРДздгкВЉПЭдАЃЌгЩЛ№СњЙћШэМўDeloresБрМЁЂЭЦМіЁЃ |
|
ЬдБІДг2018ФъПЊЪМЖдећЬхМмЙЙНјааЗДгІЪНЩ§МЖЃЌ ШЁЕУСЫЗЧГЃКУЕФГЩМЈЁЃЦфжаЁКВТФуЯВЛЖЁЛгІгУЩЯЯо QPS ЬсЩ§СЫ 96%ЃЌЭЌЪБЛњЦїЪ§СПЫѕМѕСЫвЛАыЃЛСэвЛКЫаФгІгУЁКЮвЕФЬдБІЁЛЪЕМЪЯпЩЯЯьгІЪБМфЯТНЕСЫ 40% вдЩЯЁЃPayPalЦОНшЦфЛљгкAkkaЙЙНЈЕФЗДгІЪНЦНЬЈsqubsЃЌНіЪЙгУ8ЬЈ2vCPUащФтЛњЃЌУПЬьПЩвдДІРэГЌЙ§10вкБЪНЛвзЃЌгыЛљгкSpringЪЕЯжЕФРЯЯЕЭГЯрБШЃЌДњТыСПНЕЕЭСЫ80%ЃЌЖјадФмШДЬсЩ§СЫ10БЖЁЃФмЙЛШЁЕУШчДЫКУЕФГЩМЈЃЌШЫУЧВЛНћвЊЮЪЗДгІЪНЕНЕзЪЧЪВУДЃП ЦфЪЕЗДгІЪНВЂВЛЪЧвЛИіаТЯЪЕФИХФюЃЌЫќЕФСщИаРДдДзюдчПЩвдзЗЫнЕН90ФъДњЃЌЕЋЪЧжБЕН2013ФъЃЌRoland KuhnЕШШЫЗЂВМСЫЁЖЗДгІЪНаћбдЁЗКѓВХТ§Т§БЛШЫЪьжЊЃЌМЬЖјдк2014ФъгРДБЌЗЂЪНдіГЄЃЌБШНЯгавтЫМЕФЪЧЃЌЭЌЪБгРДБЌЗЂЪНдіГЄЕФЛЙгаСьгђЧ§ЖЏЩшМЦ(DDD)ЃЌдвђЪЧ2014Фъ3дТ25ШеЃЌMartin FowlerКЭJames LewisЯђДѓжкНщЩмСЫЮЂЗўЮёМмЙЙЃЌЖјЗДгІЪНКЭСьгђЧ§ЖЏЪЧЮЂЗўЮёМмЙЙЕУвдТфЕиЕФгаСІБЃеЯЁЃНєНгзХИїжжЗДгІЪНБрГЬПђМмЯрМЬНјШыДѓМвЪгвАЃЌШчRxJavaЁЂAkkaЁЂSpring Reactor/WebFluxЁЂPlay FrameworkКЭЮДРДЕФDubbo3ЕШЃЌАЂРяФкВПдкзіЗДгІЪНИФдьЪБвВЗѕЛЏСЫвЛаЉЗДгІЪНЯюФПЃЌАќРЈAliRxObjCЁЂRxAOPКЭAliRxUtilЕШЁЃ ДгФПЧАЕФЧїЪЦПДРДЃЌЗДгІЪНИХФюНЋЛсж№НЅЩюШыШЫаФЃЌ ВЂЧвНЋв§СьЯТвЛДњММЪѕБфИяЁЃ
1 ЪВУДЪЧЗДгІЪНЃП
1.1 ЗДгІЪННщЩм
ЮЊСЫжБЙлЕиСЫНтЪВУДЪЧЗДгІЪНЃЌЮвУЧЯШДгвЛИіДѓМвЖМБШНЯЪьЯЄЕФРрБШПЊЪМЁЃЪзЯШДђПЊExcelЃЌдкBЁЂCЁЂDШ§СаЪфШыШчЯТЙЋЪНЃК

BЁЂCКЭDШ§СаУПИіЕЅдЊИёЕФжЕОљвРРЕЦфзѓВрЕФЕЅдЊИёЃЌЕБЮвУЧдкAСавРДЮЪфШы1ЁЂ2КЭ3ЪБЃЌБфЛЏЛсздЖЏДЋЕнЕНСЫBЁЂCКЭDШ§СаЃЌВЂДЅЗЂЯргІзДЬЌБфИќЃЌШчЯТЭМЃК
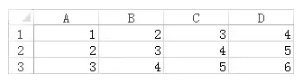
ЮвУЧПЩвдАбAСаДгЩЯЕНЯТЯыЯѓГЩвЛИіЪ§ОнСїЃЌУПвЛИіЪ§ОнЕНДяЪБЖМЛсДЅЗЂвЛИіЪТМўЃЌИУЪТМўЛсБЛДЋВЅЕНгвВрЕЅдЊИёЃЌКѓепдђЛсДІРэЪТМўВЂИФБфздЩэЕФзДЬЌЁЃетвЛЯЕСаСїГЬЦфЪЕОЭЪЧЗДгІЪНЕФКЫаФЫМЯыЁЃ
ЭЈЙ§етИіР§згЃЌФугІИУФмИаЪмЕНЗДгІЪНЕФКЫаФЪЧЪ§ОнСї(data stream)ЃЌ ЯТУцЮвУЧдйРДПДвЛИіР§згЁЃЮвУЧКмЖрШЫУПЬьЖМЛсзјЕиЬњЩЯЯТАрЃЌЕиЬњУПСНЗжжгвЛАрЃЌВЂЧвЭЌвЛЬѕЙьЕРЛсБЛКмЖрЕиЬњЙВЯэЃЌФуЛсВЛЛсвђЮЊЕЃаФзЗЮВЃЌЖјВЛИвзјЪзЮВСННкГЕЯсФиЃП ЦфЪЕШчЙћВЩгУЗДгІЪНМмЙЙЙЙНЈЕиЬњЯЕЭГЃЌОЭЮоашЕЃаФзЗЮВЮЪЬтЁЃдкЗДгІЪНЯЕЭГжаЃЌУПСОЕиЬњЖМЛсЪЕЪБНЋздМКЕФЫйЖШКЭЮЛжУЕШзДЬЌаХЯЂЭЈжЊИјЩЯЯТгЮЕФЦфЫћЕиЬњЃЌЭЌЪБвВЛсЪЕЪБЕФНгЪеЦфЫћЕиЬњЕФзДЬЌаХЯЂЃЌВЂЪЕЪБзіГіЗДРЁЁЃР§ШчЕБЗЂЯжЯТгЮЕиЬњЭЛШЛвтЭтМѕЫйЃЌдђСЂМДЕїећздЩэЫйЖШЃЌВЂНЋМѕЫйЪТМўЭЈжЊЕНЩЯгЮЕиЬњЃЌШчДЫЃЌећЬѕЙьЕРЩЯЕФЫљгаЕиЬњаЮГЩвЛжжЛибЙЛњжЦ(back pressure)ЃЌИљОнЩЯЯТгЮзДЬЌздЖЏЕїећздЩэЫйЖШЁЃ ЯТУцЮвУЧРДПДЯТЮЌЛљАйПЦЙигкЗДгІЪНБрГЬЕФЖЈвхЃК
ЗДгІЪНБрГЬ (reactive programming) ЪЧвЛжжЛљгкЪ§ОнСї (data stream) КЭ БфЛЏДЋЕн (propagation of change) ЕФЩљУїЪН (declarative) ЕФБрГЬЗЖЪНЁЃ
ДгЩЯУцЕФЖЈвхжаЃЌЮвУЧПЩвдПДГіЗДгІЪНБрГЬЕФКЫаФЪЧЪ§ОнСївдМАБфЛЏДЋЕнЁЃЮЌЛљАйПЦИјГіЕФЖЈвхБШНЯЭЈгУЃЌОпгаЦеЪЪадЃЌУЛгаЧјЗжЪ§ОнСїЕФЭЌВНКЭвьВНФЃЪНЃЌ ИќзМШЗЕиЫЕЃЌвьВНЪ§ОнСї(asynchronous data stream)ЛђепЫЕЗДгІЪНСї(reactive stream)ВХЪЧЗДгІЪНБрГЬЕФзюМбЪЕМљЁЃЯИаФЕФЖСепЛсЗЂЯжЃЌНВСЫетУДЖрЃЌетВЛОЭЪЧЙлВьепФЃЪН(Observer Pattern)ТяЃЁ ЦфЪЕетИіЫЕЗЈВЂВЛзМШЗЃЌЦфЪЕЗДгІЪНВЂВЛЪЧжИОпЬхЕФММЪѕЃЌЖјЪЧжИвЛаЉМмЙЙЩшМЦддђЃЌ ЙлВьепФЃЪНЪЧЪЕЯжЗДгІЪНЕФвЛжжЪжЖЮЃЌдкНгЯТРДЕФЗДгІЪНСї(Reactive Stream)вЛНкЃЌЮвУЧЛсЗЂЯжЗДгІЪНСїЛљгкЙлВьепФЃЪНРЉеЙСЫИќЖрЕФЙІФмЃЌИќЧПДѓвВИќвзгУЁЃ
1.2 ЗДгІЪНРњЪЗ
дчдк1985ФъЃЌDavid Harel КЭ Amir Pnueli ОЭЗЂБэСЫЁЖЗДгІЪНЯЕЭГЕФПЊЗЂЁЗТлЮФЃЌдкТлЮФжаЃЌЫћУЧВЩгУЖўЗжЗЈЖдИДдгЕФМЦЫуЙ§ГЬНјааЙщФЩЃЌЬсГіСЫзЊЛЛЪН(transformative)гыЗДгІЪН(reactive)ЯЕЭГЁЃЦфжаЗДгІЪНЯЕЭГОЭЪЧжИФмЙЛГжајЕигыЛЗОГНјааНЛЛЅЃЌВЂЧвМАЪБЕиНјааЯьгІЁЃР§ШчЪгЦЕМрПиЯЕЭГЛсГжајМрВтЃЌ ВЂЕБгаФАЩњШЫДГШыЪБСЂПЬДЅЗЂОЏБЈЁЃ
Бэ1 ЗДгІЪНРњЪЗ

ЭМ1 ЙШИшЫбЫїЧїЪЦ
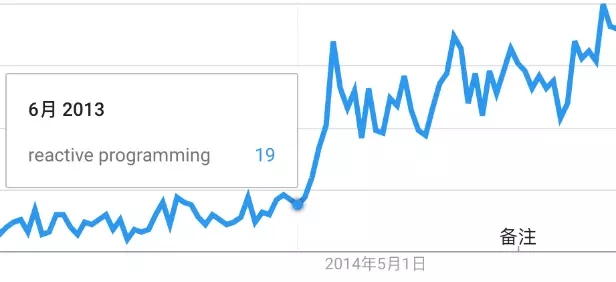
ДгGoogleЫбЫїЧїЪЦЩЯПЩвдПДГіЃЌДг2013Фъ6дТЗнПЊЪМЃЌЗДгІЪНБрГЬЕФЫбЫиЧїЪЦГіЯжСЫБЌЗЂЪНдіГЄЃЌдвђЪЧ2013Фъ6дТЗДгІЪНаћбдЗЂВМСЫЕквЛИіАцБОЁЃ
1.3 ReactiveX НщЩм
ReactiveXЪЧReactive ExtensionsЕФЫѕаДЃЌвЛАуМђаДЮЊRxЃЌзюГѕЪЧLINQЕФвЛИіРЉеЙЃЌгЩЮЂШэЕФМмЙЙЪІErik MeijerСьЕМЕФЭХЖгПЊЗЂЃЌдк2012Фъ11дТПЊдДЁЃRxЪЧвЛИіБрГЬФЃаЭЃЌФПБъЪЧЬсЙЉвЛжТЕФБрГЬНгПкЃЌАяжњПЊЗЂепИќЗНБуЕФДІРэвьВНЪ§ОнСїЁЃRxжЇГжМИКѕШЋВПЕФСїааБрГЬгябдЃЌДѓВПЗжгябдПтгЩReactiveXетИізщжЏИКд№ЮЌЛЄЃЌБШНЯСїааЕФгаRxJava/RxJS/Rx.NET/Rx.Scala/ Rx.SwiftЃЌЩчЧјЭјеОЪЧhttp://reactivex.io/ЁЃ
1.4 ЗДгІЪНаћбд
2013Фъ6дТЃЌRoland KuhnЕШШЫЗЂВМСЫЁЖЗДгІЪНаћбдЁЗЃЌ ИУаћбдЖЈвхСЫЗДгІЪНЯЕЭГгІИУОпБИЕФвЛаЉМмЙЙЩшМЦддђЁЃЗћКЯЗДгІЪНЩшМЦддђЕФЯЕЭГГЦЮЊЗДгІЪНЯЕЭГЁЃИљОнЗДгІЪНаћбдЃЌ ЗДгІЪНЯЕЭГашвЊОпБИМДЪБЯьгІад(Responsive)ЁЂЛиЕЏад(Resilient)ЁЂЕЏад(Elastic)КЭЯћЯЂЧ§ЖЏ(Message Driven)ЫФИіЬижЪЃЌвдЯТФкШнеЊздЗДгІЪНаћбдЙйЭјЃЌ УшЪіБШНЯГщЯѓЃЌДѓМвВЛБиОРНсЯИНкЃЌСЫНтМДПЩЁЃ
МДЪБЯьгІад(Responsive)ЁЃЯЕЭГгІИУЖдгУЛЇЕФЧыЧѓМДЪБзіГіЯьгІЁЃМДЪБЯьгІЪЧПЩгУадКЭЪЕгУадЕФЛљЪЏЃЌ ЖјИќМгживЊЕФЪЧЃЌМДЪБЯьгІвтЮЖзХПЩвдПьЫйЕиМьВтЕНЮЪЬтВЂЧвгааЇЕиЖдЦфНјааДІРэЁЃ
ЛиЕЏад(Resilient)ЁЃ ЯЕЭГдкГіЯжЪЇАмЪБвРШЛФмБЃГжМДЪБЯьгІадЃЌ УПИізщМўЕФЛжИДЖМБЛЮЏЭаИјСЫСэвЛИіЭтВПЕФзщМўЃЌ ДЫЭтЃЌдкБивЊЪБПЩвдЭЈЙ§ИДжЦРДБЃжЄИпПЩгУадЁЃ вђДЫзщМўЕФПЭЛЇЖЫВЛдйГаЕЃзщМўЪЇАмЕФДІРэЁЃ
ЕЏад(Elastic)ЁЃ ЯЕЭГдкВЛЖЯБфЛЏЕФЙЄзїИКдижЎЯТвРШЛБЃГжМДЪБЯьгІадЁЃ ЗДгІЪНЯЕЭГПЩвдЖдЪфШыИКдиЕФЫйТЪБфЛЏзіГіЗДгІЃЌБШШчЭЈЙ§КсЯђЕиЩьЫѕЕзВуМЦЫузЪдДЁЃ етвтЮЖзХЩшМЦЩЯВЛФмгажабыЦПОБЃЌ ЪЙЕУИїИізщМўПЩвдНјааЗжЦЌЛђепИДжЦЃЌ ВЂдкЫќУЧжЎМфНјааИКдиОљКтЁЃ
ЯћЯЂЧ§ЖЏ(Message Driven)ЁЃЗДгІЪНЯЕЭГвРРЕвьВНЕФЯћЯЂДЋЕнЃЌДгЖјШЗБЃСЫЫЩёюКЯЁЂИєРыЁЂЮЛжУЭИУїЕФзщМўжЎМфгазХУїШЗБпНчЁЃ етвЛБпНчЛЙЬсЙЉСЫНЋЪЇАмзїЮЊЯћЯЂЮЏЭаГіШЅЕФЪжЖЮЁЃ ЪЙгУЯдЪНЕФЯћЯЂДЋЕнЃЌПЩвдЭЈЙ§дкЯЕЭГжаЫмдьВЂМрЪгЯћЯЂСїЖгСаЃЌ ВЂдкБивЊЪБгІгУЛибЙЃЌ ДгЖјЪЕЯжИКдиЙмРэЁЂ ЕЏадвдМАСїСППижЦЁЃ ЪЙгУЮЛжУЭИУїЕФЯћЯЂДЋЕнзїЮЊЭЈаХЕФЪжЖЮЃЌ ЪЙЕУПчМЏШКЛђепдкЕЅИіжїЛњжаЪЙгУЯрЭЌЕФНсЙЙГЩЗжКЭгявхРДЙмРэЪЇАмГЩЮЊСЫПЩФмЁЃ ЗЧзшШћЕФЭЈаХЪЙЕУНгЪеепПЩвджЛдкЛюЖЏЪБВХЯћКФзЪдДЃЌ ДгЖјМѕЩйЯЕЭГПЊЯњЁЃ
1.5 Reactive Streams
ЗДгІЪНаћбдНіВћЪіСЫЩшМЦддђЃЌВЂУЛгаИјГіОпЬхЕФЪЕЯжЙцЗЖЃЌЕМжТУПИіЗДгІЪНПђМмЖМИїздЪЕЯжСЫвЛЬзздМКЕФAPIЙцЗЖЃЌЧвЯрЛЅжЎМфЮоЗЈЛЅЭЈЁЃЮЊСЫНтОіетИіЮЪЬтЃЌReactive StreamsЙцЗЖгІдЫЖјЩњЁЃ
Reactive StreamsЕФФПБъЪЧЖЈвхвЛзщзюаЁЛЏЕФвьВНСїДІРэНгПкЃЌЪЙЕУдкВЛЭЌПђМмжЎМфЃЌЩѕжСВЛЭЌгябджЎМфЪЕЯжНЛЛЅадЁЃReactive StreamsЙцЗЖАќКЌСЫ4ИіНгПкЃЌ7ИіЗНЗЈЃЌ43ЬѕЙцдђвдМАвЛЬзгУгкМцШнадВтЪдЕФБъзМЬзМўTCK(The Technology Compatibility Kit)ЁЃИУЙцЗЖвбОГЩЮЊСЫвЕНчБъзМЃЌ ВЂЧвдкJava 9жавбОЪЕЯжЃЌЖдгІЕФЪЕЯжНгПкЮЊjava.util.concurrent.FlowЁЃ гавЛЕуашвЊЬсабЕФЪЧЃЌЫфШЛJava 9вбОЪЕЯжСЫReactive StreamsЃЌЕЋетВЂВЛвтЮЖзХЯёRxJavaЁЂReactorЁЂAkka StreamsетаЉСїДІРэПђМмОЭУЛгавтвхСЫЃЌЪТЪЕЩЯЧЁЧЁЯрЗДЁЃReactive StreamsЕФФПЕФдкгкдіЧПВЛЭЌПђМмжЎМфЕФНЛЛЅадЃЌЬсЙЉЕФЪЧвЛзщзюаЁЙІФмМЏКЯЃЌЮоЗЈТњзуЮвУЧШеГЃЕФСїДІРэашЧѓЃЌР§ШчзщКЯЁЂЙ§ТЫЁЂЛКДцЁЂЯоСїЕШЙІФмЖМашвЊЖюЭтЪЕЯжЁЃСїДІРэПђМмЕФФПЕФОЭдкгкЬсЙЉетаЉЖюЭтЕФЙІФмЪЕЯжЃЌВЂЭЈЙ§Reactive StreamsЙцЗЖЪЕЯжПчПђМмЕФНЛЛЅадЁЃ
ОйИіР§згРДЫЕЃЌMongoDBЕФJavaЧ§ЖЏЪЕЯжСЫReactive StreamsЙцЗЖЃЌ ПЊЗЂепЪЙгУШЮКЮвЛИіСїДІРэПђМмЃЌНіашвЊМИааДњТыМДПЩЪЕЪБМрЬ§Ъ§ОнПтЕФБфЛЏЁЃР§ШчЯТУцЪЧЛљгкAkka StreamЕФЪЕЯжДњТыЃК
mongo
.collection("users")
.watch()
.toSource
.groupedWithin(10, 1.second)
.throttle(1, 1.second)
.runForeach { docs =>
// ДІРэдіСПЪ§Он
} |
ЩЯУцЕФМИааДњТыЪЕЯжСЫШчЯТЙІФмЃК
НЋНгЪеЕНЕФСїЪ§ОнНјааЛКГхвдЗНБуХњДІРэЃЌТњзувдЯТШЮвЛЬѕМўБуНсЪјЛКГхВЂЯђКѓДЋЕн
ЛКГхТњ10ИідЊЫи
ЛКГхЪБМфГЌЙ§СЫ1000КСУы
ЖдЛКГхКѓЕФдЊЫиНјааСїПиЃЌУПУыжЛдЪаэЭЈЙ§1ИідЊЫи
1.6 аЁНс
БОеТЪзЯШЭЈЙ§аЮЯѓЕФР§згШУДѓМвЖдЗДгІЪНЯЕЭГгавЛИіжБЙлЕФШЯжЊЃЌШЛКѓДјСьДѓМввЛЦ№ЛиЙЫСЫЗДгІЪНЕФЗЂеЙРњЪЗЃЌзюКѓЯђДѓМвНщЩмСЫШ§ИіЗДгІЪНЯюФПЃЌАќРЈReactiveXЁЂЗДгІЪНаћбдКЭReactive StreamsЁЃ ReactiveXЪЧЗДгІЪНРЉеЙЃЌжМдкЮЊИїИіБрГЬгябдЬсЙЉЗДгІЪНБрГЬЙЄОпЁЃЗДгІЪНаћбдеОдквЛИіИќИпЕФНЧЖШЃЌЪЙгУГщЯѓгябдЯђДѓМвУшЪіЪВУДЪЧЗДгІЪНЯЕЭГЃЌвдМАЪЕЯжЗДгІЪНЯЕЭГгІИУзёбЕФвЛаЉЩшМЦддђЁЃReactive StreamsЙцЗЖЕФФПЕФдкгкЬсИпИїИіЗДгІЪНПђМмжЎМфЕФНЛЛЅадЃЌБОЩэВЂВЛЪЪКЯзїЮЊПЊЗЂПђМмжБНгЪЙгУЃЌПЊЗЂепгІИУбЁдёвЛИіГЩЪьЕФЗДгІЪНПђМмЃЌВЂЭЈЙ§Reactive StreamsЙцЗЖгыЦфЫќПђМмЪЕЯжНЛЛЅЁЃ
2 ЮЊЪВУДашвЊЗДгІЪНЃП
2.1 УќСюЪНБрГЬ VS ЩљУїЪНБрГЬ
ЪЕМЪЩЯЮвУЧОјДѓЖрЪ§ГЬађдБЖМдкЪЙгУДЋЭГЕФУќСюЪНБрГЬЃЌетвВЪЧМЦЫуЛњЕФЙЄзїЗНЪНЁЃУќСюЪНБрГЬОЭЪЧЖдгВМўВйзїЕФГщЯѓЃЌ ГЬађдБашвЊЭЈЙ§жИСюЃЌОЋШЗЕФИцЫпМЦЫуЛњИЩЪВУДЪТЧщЁЃетвВЪЧБрГЬЙЄзїжазюПндяЕФЕиЗНЃЌГЬађдБашвЊКФОЁФджЃЌНЋИДдгЁЂвзБфЕФвЕЮёашЧѓЗвыГЩОЋШЗЕФМЦЫуЛњжИСюЁЃ
ЩљУїЪНБрГЬЪЧНтОіГЬађдБЕФРћЦїЃЌЩљУїЪНБрГЬИќЙизЂЮвЯывЊЪВУД(What)ЖјВЛЪЧдѕУДШЅзі(How)ЁЃSQLЪЧзюЕфаЭЕФЩљУїЪНгябдЃЌЮвУЧЭЈЙ§SQLУшЪіЯывЊЪВУДЃЌзюжегЩЪ§ОнПтв§ЧцжДааSQLгяОфВЂНЋНсЙћЗЕЛиИјЮвУЧЁЃ
SELECT COUNT(*)
FROM
USER u WHERE u.age > 30 |
1.5НкЪЙгУAkka StreamЪЕЯжМрЬ§MongoDBЕФДњТывВЪЧЕфаЭЕФЩљУїЪНБрГЬЃЌШчЙћВЩгУУќСюЪНЗНЪНжиаДЃЌ ВЛНіЗбЪБЗбСІЃЌЖјЧвЛЙЛсЕМжТДњТыСПБЉдіЃЌзюживЊЕФЪЧвЊЭЈЙ§ИќЖрЕФЕЅдЊВтЪдБЃжЄЪЕЯжЕФе§ШЗадЁЃ
ЗДгІЪНМмЙЙЭЦМіЪЙгУЩљУїЪНБрГЬЃЌ ЪЙгУИќНгНќздШЛгябдЕФЗНЪНУшЪівЕЮёТпМЃЌ ДњТыЧхЮњвзЖЎВЂЧвИЛгаБэДяСІЃЌ зюживЊЕФЪЧДѓДѓНЕЕЭСЫКѓЦкЮЌЛЄГЩБОЁЃ
2.2 ЭЌВНБрГЬ VS вьВНБрГЬ
ЕБЬИЕНЭЌВНгывьВНЪБЃЌОЭВЛЕУВЛЬсвЛЯТзшШћгыЗЧзшШћЕФИХФюЃЌвђЮЊетСНзщИХФюКмШнвзЛьЯ§ЁЃЕМжТЛьЯ§ЕФдвђЪЧЫќУЧдкУшЪіЭЌвЛИіЖЋЮїЃЌЕЋЪЧЙизЂЕуВЛЭЌЁЃ зшШћгыЗЧзшШћЙизЂЗНЗЈжДааЪБЕБЧАЯпГЬЕФзДЬЌЃЌЖјЭЌВНгывьВНдђЙизЂЗНЗЈЕїгУНсЙћЕФЭЈжЊЛњжЦЁЃвђЮЊЪЧДгВЛЭЌНЧЖШУшЪіЗНЗЈЕФЕїгУЙ§ГЬЃЌЫљвдетСНзщИХФювВПЩвдЯрЛЅзщКЯЃЌМДНЋЯпГЬзДЬЌКЭЭЈжЊЛњжЦНјаазщКЯЁЃР§ШчJDK1.3МАвдЧАЕФBIOЪЧЭЌВНзшШћФЃЪНЃЌJDK1.4ЗЂВМЕФNIOЪЧЭЌВНЗЧзшШћФЃЪНЃЌJDK1.7ЗЂВМЕФNIO.2ЪЧвьВНЗЧзшШћФЃЪНЁЃ
ИњУќСюЪНБрГЬвЛбљЃЌЭЌВНБрГЬвВЪЧФПЧАБЛЙуЗКВЩгУЕФДЋЭГБрГЬЗНЪНЁЃЭЌВНБрГЬЕФгХЕуЪЧДњТыМђЕЅВЂЧвШнвзРэНтЃЌДњТыАДееЯШКѓЫГађвРДЮжДааЃЛШБЕуЪЧCPUРћгУТЪЗЧГЃЕЭЃЌДѓВПЗжЪБМфЖМАзАзРЫЗбдкСЫIOЕШД§ЩЯЁЃ
вьВНБрГЬЭЈЙ§ГфЗжРћгУCPUзЪдДВЂаажДааШЮЮёЃЌ дкжДааЪБМфКЭзЪдДРћгУТЪЩЯдЖдЖИпгкЭЌВНЗНЪНЁЃОйИіР§згРДЫЕЃЌЖдгквЛИі10КЫЗўЮёЦїЃЌЪЙгУЭЌВНЗНЪНзЅШЁ10ИіЭјвГЃЌУПИіЭјвГКФЪБ1УыЃЌдђзмКФЪБЮЊ10УыЃЛШчЙћВЩгУвьВНЗНЪНЃЌ10ИізЅШЁШЮЮёЗжБ№дкИїздЕФЯпГЬЩЯжДааЃЌзмКФЪБжЛга1УыЁЃ ЙЙНЈЗДгІЪНЯЕЭГВЂЗЧвзЪТЃЌгШЦфЪЧеыЖдвХСєЯЕЭГНјааИФдьЃЌетНЋЛсЪЧвЛИіНЯЮЊТўГЄЕФЙ§ГЬЁЃЗДгІЪНМмЙЙЕФКЫаФЫМЯыЪЧвьВНЗЧзшШћЕФЗДгІЪНСїЃЌзїЮЊЙ§ЖЩНзЖЮЃЌЮвУЧПЩвдбЁдёЯШЖдЯЕЭГНјааЭъШЋвьВНЛЏжиЙЙЃЌЮЊНјвЛВНЯђЗДгІЪНМмЙЙбнНјЕьЖЈЛљДЁЁЃНгЯТРДЃЌЮвУЧНЋЯШЗжЮівЛИіДЋЭГЕФЭЌВНЪОР§ЃЌШЛКѓеыЖдИУЪОР§НјаавьВНЛЏжиЙЙЁЃ
2.3 ЭЌВНБрГЬЪОР§
МйЩшЮвУЧвЊЪЕЯжвЛИіВщбЏЪжЛњЬзВЭгрЖюЕФЗНЗЈЃЌ ИУЗНЗЈНгЪмвЛИіЪжЛњКХВЮЪ§ЃЌЗЕЛиИУЪжЛњКХЕФЬзВЭгрЖюаХЯЂЃЌ АќРЈЪЃгрЭЈЛАЪБМфЁЂЪЃгрЖЬаХЪ§СПКЭЪЃгрЭјТчСїСПЁЃ гЩгкВщбЏЬзВЭгрЖюашвЊСЌајЗЂЦ№Ш§ДЮЭЌВНзшШћЕФЪ§ОнПтВщбЏЧыЧѓЃЌЫљвддкЪЕЯжжаашвЊРћгУЛКДцЬсИпЖСШЁадФмЃЌ ДњТыШчЯТЃК
private PhonePlanCache
cache;
public PhonePlan retrievePhonePlan
(String phoneNo)
{
PhonePlan plan = cache.get(phoneNo);
if (plan != null) {
return plan;
}
Long leftTalk = readLeftTalk(phoneNo);
Long leftText = readLeftText(phoneNo);
Long leftData = readLeftData(phoneNo);
return new PhonePlan
(leftTalk, leftText, leftData);
} |
ЪзЯШЮвУЧМьВщЪЧЗёПЩвджБНгДгЛКДцжаЖСШЁЬзВЭгрЖюаХЯЂЃЌШчЙћПЩвддђжБНгЗЕЛиЃЌ ЗёдђСЌајЗЂЦ№Ш§ДЮЭЌВНзшШћЕФдЖГЬЕїгУЃЌ ДгЪ§ОнПтжавРДЮЖСШЁЭЈЛАгрЖюЁЂЖЬаХгрЖюКЭСїСПгрЖюЁЃДњТыТпМЗЧГЃМђЕЅЃЌЕЋЪЧгЩгкЭЌВНзшШћДњТыЖдЯпГЬГивРРЕЗЧГЃбЯжиЃЌНгЯТРДЮвУЧЛЙашвЊИљОнSLAЙРЫуЯпГЬГиКЭСЌНгГиДѓаЁЁЃЙРЫуЕФЙ§ГЬВЂВЛШнвзЃЌКУдкЮвУЧгаРћЬиЖћЗЈдђЁЃ
1954ФъЃЌ John LittleЛљгкЕШКђРэТлЬсГіСЫРћЬиЖћЗЈдђ(Little's law)ЃК дквЛИіЮШЖЈЕФЯЕЭГжаЃЌЯЕЭГПЩвдЭЌЪБДІРэЕФЧыЧѓЪ§СПLЃЌ ЕШгкЧыЧѓЕНДяЕФЦНОљЫйЖШ ІЫ ГЫвдЧыЧѓЕФЦНОљДІРэЪБМфWЃЌ МДЃК
L = ІЫ * W
етИіЗЈдђЭЌбљПЩвдгУРДМЦЫуЯпГЬГиКЭСЌНгГиДѓаЁЁЃ Р§ШчЯЕЭГУПУыНгЪе1000ИіЧыЧѓЃЌУПИіЧыЧѓЕФЦНОљДІРэЪБМфЪЧ10msЃЌ дђКЯЪЪЕФЪ§ОнПтСЌНгГиДѓаЁгІИУЮЊ10ЁЃ вВОЭЪЧЫЕЯЕЭГПЩвдЭЌЪБДІРэ10ИіЧыЧѓЁЃ ДгГЄЪБМфРДПДЃЌЯЕЭГЦНОљЛсга10ИіЯпГЬдкЕШД§Ъ§ОнПтСЌНгЩЯЕФЯьгІЁЃ ЕЋЪЧашвЊзЂвтЕФЪЧЃЌРћЬиЖћЗЈдђжЛЪЪгУгквЛИіЮШЖЈЯЕЭГЃЌ ЮоЗЈДІРэЗхжЕЧщПіЃЌ ЖјЭЈГЃЯЕЭГЧыЧѓЪ§СПЕФЗхжЕЛсБШЦНОљжЕИпКмЖрЁЃМйЩшЮЊСЫгІИЖЗхжЕЧщПіЃЌЮвУЧНЋЯпГЬГиДѓаЁЕїећЮЊ50ЃЌ гЩгкСЌНгГиДѓаЁШдЮЊ10ЃЌЫљвдЛсЕМжТДѓСПЯпГЬдкЕШД§ПЩгУСЌНгЃЌ ЮвУЧашвЊдйДЮдіДѓСЌНгГиДѓаЁвдИФЩЦЯЕЭГадФмЁЃЭЈГЃОЙ§ШчДЫЗДИДЕїећКѓЕФВЮЪ§вбОбЯжиЦЋРыСЫРћЬиЖћЗЈдђЃЌ ЕМжТЯЕЭГадФмбЯжиЯТНЕЃЌдкИпВЂЗЂГЁОАЯТЃЌШчЙћЭјТчЩдгаЖЖЖЏЛђЪ§ОнПтЩдгабгГйЃЌдђЛсЕМжТЫВМфЛ§бЙДѓСПЧыЧѓЃЌ ШчЙћУЛгагааЇЕФгІЖдДыЪЉЃЌЯЕЭГНЋУцСйЬБЛОЗчЯеЁЃ
2.4 ЭЌВНБрГЬУцСйЕФЬєеН
ДЋЭГгІгУЭЈГЃЛљгкServletШнЦїНјааВПЪ№ЃЌЖјServletЪЧЛљгкЯпГЬЕФЧыЧѓДІРэФЃаЭЁЃДгЩЯЮФЕФЬжТлжаЮвУЧЗЂЯжЃЌЭЈГЃашвЊЩшжУвЛИіНЯДѓЕФЯпГЬГивдЛёЕУНЯКУЕФадФмЃЌНЯДѓЕФЯпГЬГиЛсЕМжТвдЯТШ§ИіЮЪЬтЃК
ЖюЭтЕФФкДцПЊЯњЁЃ дкJavaжаЃЌУПИіЯпГЬЖМгаздМКЕФеЛПеМфЃЌФЌШЯЪЧ1MBЁЃШчЙћЩшжУЯпГЬГиДѓаЁЮЊ200ЃЌдђгІгУдкЦєЖЏЪБжСЩйашвЊ200MФкДцЃЌвЛЗНУцдьГЩСЫФкДцРЫЗбЃЌСэвЛЗНУцвВЕМжТгІгУЦєЖЏБфТ§ЁЃЪдЯывЛЯТЃЌШчЙћЭЌЪБВПЪ№1000ИіНкЕуЃЌетаЉЮЪЬтНЋЛсБЛЗХДѓ1000БЖЁЃ
CPUРћгУТЪЕЭЁЃ гаСНИіЗНУцдвђЛсЕМжТМЋЕЭЕФCPUРћгУТЪЁЃвЛЗНУцЪЧдкOracle JDK 1.2АцБОжЎКѓЃЌЫљгаЦНЬЈЕФJVMЪЕЯжЖМЪЙгУ1:1ЯпГЬФЃаЭ(SolarisЪЧИіЬиР§)ЃЌетвтЮЖзХвЛИіJavaЯпГЬЛсБЛгГЩфЕНвЛИіЧсСПМЖНјГЬЩЯЃЌЖјгааЇЕФЧсСПМЖНјГЬЪ§СПШЁОігкCPUЕФИіЪ§вдМАКЫЪ§ЁЃШчЙћJavaЕФЯпГЬЪ§СПдЖДѓгкгааЇЕФЧсСПМЖНјГЬЪ§СПЃЌдђЦЕЗБЕФЯпГЬЩЯЯоЮФЧаЛЛЛсРЫЗбДѓСПCPUЪБМфЃЛ СэвЛЗНУцЃЌгЩгкДЋЭГЕФдЖГЬВйзїЛђIOВйзїОљЮЊзшШћВйзїЃЌЛсЕМжТжДааЯпГЬБЛЙвЦ№ДгЖјЮоЗЈжДааЦфЫћШЮЮёЃЌДѓДѓНЕЕЭСЫCPUЕФРћгУТЪЁЃ
зЪдДОКељМЄСвЁЃ ЕБдіДѓЯпГЬГиКѓЃЌЦфЫћЕФЙВЯэзЪдДБуЛсГЩЮЊадФмЦПОБЃЌШчЪ§ОнПтСЌНгГизЪдДЁЃШчЙћДцдкЙВЯэзЪдДЦПОБЃЌМДЪЙЩшжУдйДѓЕФЯпГЬГиЃЌвВЮоЗЈгааЇЕиЬсЩ§адФмЁЃДЫЪБЛсЕМжТЖрИіЯпГЬОКељЪ§ОнПтСЌНгЃЌ ЪЙЕУЪ§ОнПтСЌНгГЩЮЊЯЕЭГЦПОБЁЃ
Г§СЫЩЯУцетаЉЮЪЬтЃЌЭЌВНБрГЬЛЙЛсЩюПЬЕигАЯьЕНЮвУЧЕФМмЙЙЁЃ
МйЩшЮвУЧзМБИПЊЗЂвЛИіЕЅЕуЕЧТМЮЂЗўЮёЃЌЮЂЗўЮёПђМмЪЙгУ Dubbo 2.xЃЌИУАцБОЩаЮДжЇГжЗДгІЪНБрГЬЃЌЮЂЗўЮёНгПкжЎМфЕїгУШдШЛЪЧЭЌВНзшШћЗНЪНЁЃ МйЩшЮвУЧашвЊЪЕЯжШчЯТСНИіНгПкЃК
гУЛЇЕЧТМНгПк
СюХЦбщжЄНгПк
ЖдгкгУЛЇЕЧТМНгПкЃЌгЩгкашвЊЖрДЮЗУЮЪЪ§ОнПтЛђЛКДцЃЌВЂЧвашвЊЪЙгУArgon2ЕШТ§ЙўЯЃЫуЗЈНјааУмТыаЃбщЃЌЕМжТЦНОљЯьгІЪБМфНЯГЄЃЌдМЮЊ500КСУыЁЃЖјЖдгкСюХЦбщжЄНгПкЃЌгЩгкжЛашвЊзіМђЕЅЕФЧЉУћаЃбщЃЌЫљвдЦНОљЯьгІЪБМфНЯЖЬЃЌдМЮЊ5КСУыЁЃ МйЩшгЩгквЕЮёашвЊЃЌгУЛЇЕЧТМНгПкЕФадФмжИБъжЛашвЊДяЕН1000tpsМДПЩЃЌЖјСюХЦбщжЄНгПкЕФадФмжИБъдђашвЊДяЕН100,000tpsЁЃ
ЭЈГЃРДЫЕЃЌетСНИіНгПкЛсдкЭЌвЛИіЮЂЗўЮёРржаЪЕЯжЃЌвВЭЈГЃЛсБЛЗЂВМЕНЭЌвЛИіШнЦїжаЖдЭтЬсЙЉЗўЮёЁЃЮЊСЫТњзувЕЮёашвЊЃЌЮвУЧЯШРДЫувЛЯТашвЊЖрЩйгВМўГЩБОЃП ЮЊСЫМђЛЏЬжТлЃЌЮвУЧШЯЮЊСюХЦбщжЄНгПкЮоашгВМўГЩБОЃЌжЛЙизЂгУЛЇЕЧТМНгПкМДПЩЁЃИљОнРћЬиЖћЗЈдђЃЌ змЯпГЬЪ§СП(L) = TPS(ІЫ)*ЦНОљЯьгІЪБМф(W)ЃЌ МДЃК
змЯпГЬЪ§СП(L) = (1000*0.5) = 500
МйЩшУПИіМЦЫуНкЕуХфжУЮЊ4C8GЃЌ ФЧУДвЛЙВашвЊ (500/4)=125ЬЈМЦЫуНкЕуЁЃ ЧјЧјЕФ1000tpsОЙШЛашвЊ125ЬЈМЦЫуНкЕуЃЁФувдЮЊетОЭЭъСЫТ№ЃП 1000tpsжЛЪЧШеГЃЕФЧыЧѓбЙСІЃЌШчЙћПМТЧЗхжЕЧщПіФиЃПМйЩшЗхжЕЧыЧѓЪЧ10, 000tpsЃЌВЂЧвЛсГжај10УыЃЌ ФЧУДдкет10УыФкЯЕЭГвВПЩвдПДзіЪЧЮШЖЈзДЬЌЃЌ ФЧУДИљОнРћЬиЖћЗЈдђЃЌОЭашвЊВПЪ№1250ЬЈМЦЫуНкЕуЁЃ ЛЙгаИќЛЕЕФЧщПіЃЌШчЙћФГИіНкЕугЩгкЪ§ОнПтбгГйЛђЭјТчЖЖЖЏЕШЧщПіЃЌЕМжТгУЛЇЕЧТМЧыЧѓЛ§бЙЃЌдђгУЛЇЕЧТМЧыЧѓЛсКФОЁЫљгаЧыЧѓДІРэЯпГЬЃЌЕМжТдБОПЩвдПьЫйЯьгІЕФСюХЦбщжЄЧыЧѓЮоЗЈБЛМАЪБДІРэЃЌЖјСюХЦбщжЄНгПкЕФtpsЪЧ100,000ЃЌетвтЮЖзХ1УыжгОЭЛсЛ§бЙ100,000ИіСюХЦбщжЄЧыЧѓЃЌ ЯЕЭГвбОДІдкЮЃЯеБпдЕЃЌЫцЪБЖМЛсБРРЃЁЃ
ЮЊСЫНтОіСюХЦбщжЄНгПкЕФПьЫйЯьгІЮЪЬтЃЌЮвУЧжЛФмЕїећМмЙЙЃЌНЋЕЧТНКЭбщжЄВ№ЗжГЩСНИіЕЅЖРЕФЮЂЗўЮёЃЌВЂЧвИїздВПЪ№ЕНЖРСЂЕФШнЦїжаЁЃетбљЪЧВЛЪЧОЭЭђЪТДѓМЊСЫФиЃПКмВЛавЃЌЕЅЕуЕЧТМгРДСЫвЛИіаТашЧѓЃЌеыЖддБЙЄеЫЛЇашвЊдЖГЬЕїгУLDAPНјааШЯжЄЃЌ ЖјдЖГЬЕїгУLDAPвВЪЧвЛИіЭЌВНзшШћВйзїЃЌетвтЮЖзХУПвЛИіLDAPдЖГЬЕїгУЖМЛсЙвЦ№вЛИіЯпГЬЃЌДѓСПЕФдЖГЬЕїгУвВЛсКФОЁЫљгаЯпГЬЃЌетаЉБЛЙвЦ№ЕФЯпГЬЩЖЖМВЛзіЃЌОЭдкФЧЩЕЩЕЕФЕШД§дЖГЬЯьгІЁЃетЦфЪЕОЭЪЧЮЂЗўЮёЕїгУСДбЉБРЕФзяП§ЛіЪзЁЃСНИіЮЂЗўЮёжЎМфЕїгУвбОШчДЫМЌЪжСЫЃЌФЧШчЙћЕїгУСДЩЯга10ИіЩѕжСИќЖрЕФЮЂЗўЮёЕїгУФиЃП ФЧНЋЪЧвЛГЁиЌУЮЃЁ
ЦфЪЕЫљгаЮЪЬтЕФИљдДЖМПЩвдЙщНсЮЊДЋЭГЕФЭЌВНзшШћБрГЬЗНЪНЁЃгШЦфЪЧдкЮЂЗўЮёГЁОАЯТЃЌЫцзХЕїгУСДГЄЖШЕФВЛЖЯдіГЄЃЌЗчЯевВНЋдНРДдНИпЃЌ ЦфжаШЮКЮвЛИіНкЕуЭЌВНзшШћВйзїЖМЛсЕМжТЦфЯТгЮЫљгаНкЕуЯпГЬБЛзшШћЃЌШчЙћЮЪЬтНкЕуЕФЧыЧѓВњЩњЛ§бЙЃЌдђЛсЕМжТЫљгаЯТгЮНкЕуЯпГЬБЛКФОЁЃЌетОЭЪЧПЩХТЕФбЉБРЁЃ
2.5 вьВНБрГЬЪОР§
ЮвУЧЫЕвьВНБрГЬЭЈГЃЪЧжИвьВНЗЧзшШћЕФБрГЬЗНЪНЃЌМДвЊЧѓЯЕЭГжаВЛФмгаШЮКЮзшШћЯпГЬЕФДњТыЁЃдкЯжЪЕЧщПіЯТЃЌЯыЪЕЯжЭъШЋЕФвьВНЗЧзшШћЗЧГЃРЇФбЃЌ вђЮЊЛЙгаКмЖрЕкШ§ЗНЕФПтЛђЧ§ЖЏШдШЛВЩгУЭЌВНзшШћЕФБрГЬЗНЪНЁЃЮвУЧашвЊЮЊетаЉПтЛђЧ§ЖЏжИЖЈЖРСЂЕФЯпГЬГиЃЌвдУтгАЯьЕНЦфЫћЗўЮёНгПкЁЃ
РћгУJava 8ЬсЙЉЕФCompletableFutureКЭLambdaСНИіЬиадЃЌЮвУЧЖд2.2НкЕФЪОР§НјаавьВНЛЏИФдьЃЌИФдьКѓДњТыШчЯТЃК
private PhonePlanCache
cache;
public CompletableFuture<PhonePlan> retrievePhonePlan(String
phoneNo) {
PhonePlan cachedPlan
= cache.get(phoneNo);
if (cachedPlan != null) {
return CompletableFuture.
completedFuture(cachedPlan);
}
CompletableFuture<Long> leftTalkFuture =
readLeftTalk(phoneNo);
CompletableFuture<Long> leftTextFuture =
readLeftText(phoneNo);
CompletableFuture<Long> leftDataFuture =
readLeftData(phoneNo);
CompletableFuture<PhonePlan> planFuture
=
leftTalkFuture.thenCombine
(leftTextFuture, (leftTalk, leftText) ->{
PhonePlan plan = new PhonePlan();
plan.setLeftTalk(leftTalk);
plan.setLeftText(leftText);
return plan;
}).thenCombine(leftDataFuture,
www.xinyiylzc.cn
(plan, leftData) -> {
plan.setLeftData(leftData);
return plan;
});
return planFuture;
} |
ЮвУЧЗЂЯжЫфШЛвьВНБрГЬПЩвдЛёЕУадФмЩЯЕФЬсЩ§ЃЌЕЋЪЧБрТыИДдгЖШШДЬсЩ§СЫКмЖрЃЌВЂЧвШчЙћвьВНЕїгУСДЬЋГЄЃЌЛЙШнвзЕМжТЛиЕїЕигќЁЃ
ES2017 дкБрГЬгябдМЖБ№ЬсЙЉСЫasync/awaitЙиМќзжгУгкМђЛЏвьВНБрГЬЃЌШУПЊЗЂепвдЭЌВНЕФЗНЪНБраДвьВНДњТыЃЌР§ШчЃК
const leftTalk
= await readLeftTalkPromise
(www.ping2yl.com phoneNo);
const leftText = await readLeftTextPromise
(www.huanhua2zhuc.cn
phoneNo);
const leftData = await readLeftDataPromise
(www.hdptzc.cn
phoneNo);
const phonePlan = new PhonePlan
(leftTalk, leftText,
www.yunzeyle.cn leftData); |
дкScalaжаЪЙгУ for гяОфвВПЩвдМђЛЏвьВНБрГЬЃЌР§ШчЃК
for {
leftTalk <- leftTalkFuture
leftText <- leftTextFuture
leftData <- leftDataFuture
} yield new PhonePlan
(leftTalk, leftText, leftData) |
ПДЕНдкЦфЫќгябджавьВНБрГЬШчДЫМђЕЅЃЌЪЧВЛЪЧКмЯлФНЃП Б№МБЃЌ дкЯТвЛЦЊЮФеТжаЃЌЮвУЧНЋЛсПДЕНШчКЮРћгУЗДгІЪНБрГЬМђЛЏвьВНЕїгУЮЪЬтЁЃ
3 змНс
БОЮФЭЈЙ§СНВПЗжФкШнЮЊДѓМвНщЩмСЫЗДгІЪНЕФЛљБОИХФюЁЃЕквЛВПЗжНщЩмЪВУДЪЧЗДгІЪНЃЌАќРЈЗДгІЪНЕФЗЂеЙРњЪЗКЭвЛаЉЯрЙиЯюФПЁЃЕкЖўВПЗжНщЩмЮЊЪВУДвЊЗДгІЪНЃЌЭЈЙ§вЛИіДЋЭГЕФБрГЬЪОР§ЯђДѓМвВћЪіЭЌВНБрГЬЫљУцСйЕФЮЪЬтКЭЬєеНЃЌгШЦфдкЮЂЗўЮёГЁОАЯТЃЌУцЖдГЩЧЇЩЯЭђЕФЮЂЗўЮёНгПквдДэзлИДдгЕФЕїгУСДЃЌЮЊСЫЙцБмПЩФмЕМжТЕФбЉБРЗчЯеЃЌЮвУЧВЛЕУВЛЖдвбгаЕФМмЙЙНјааЮовтвхИФдьЃЌВЛНідіМгПЊЗЂГЩБОЃЌЖјЧвЕМжТВПЪ№КЭдЫЮЌФбЖШдіМгЃЌЭЌВНБрГЬЗНЪНвбОЩюПЬЕигАЯьЕНСЫЮвУЧЕФМмЙЙЁЃЕЋЪЧВЛЙмдѕУДЫЕЃЌЗДгІЪНИФдьЪЧвЛИіГЄЦкЕФЙ§ГЬЃЌ дкетИіЙ§ГЬжаЃЌЮвУЧашвЊВЛЖЯЕиЭъЩЦЛљДЁЩшЪЉЃЌЭЌЪБвВвЊзЂжиЖдПЊЗЂШЫдБЕФХрбјЃЌ вђЮЊЗДгІЪНБрГЬЪЧЖдДЋЭГЗНЪНЕФвЛДЮБфИяЃЌБрГЬФЃЪНКЭЫМЮЌЖМашвЊНјаазЊЛЛЃЌетЖдгкПЊЗЂШЫдБРДЫЕЭЌбљЪЧвЛДЮЬєеНЁЃзЊаЭЫфШЛЭДПрЃЌЕЋЪЧГЩЙІЭЩБфжЎКѓБуЛсгРДаТЩњЁЃ
|








