| БрМЭЦМі: |
БОЮФзмНсСЫFeedСїЕФвЕЮёГЁОАКЭжїСїМмЙЙЃЌЗжЮіСЫВЛЭЌГЁОАЁЂЬхСПЯТММЪѕЕФФбЕугыЦПОБЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
РДздгкдЦЦмЩчЧј,гЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
БГОА
FeedСїЃКПЩвдРэНтЮЊаХЯЂСїЃЌНтОіЕФЪЧаХЯЂЩњВњепгыаХЯЂЯћЗбепжЎМфЕФаХЯЂДЋЕнЮЪЬтЁЃ
ЮвУЧГЃМћЕФFeedСїГЁОАгаЃК
1 ЪжЬдЃЌЮЂЬдЬсЙЉИјЯћЗбепЕФЪзвГЩЬЦЗаХЯЂЃЌгУЛЇЙизЂЕъЦЬЕФаТЯћЯЂЕШ
2 ЮЂаХХѓгбШІЃЌМАЪБЛёШЁХѓгбЗжЯэЕФаХЯЂ
3 ЮЂВЉЃЌЗлЫПЛёШЁЙизЂУїаЧЁЂДѓVЕФаХЯЂ
4 ЭЗЬѕЃЌгУЛЇЛёШЁЯЕЭГЭЦМіЕФаТЮХЁЂЦРТлЁЂАЫид
ЙигкFeedСїЕФМмЙЙЩшМЦЃЌАќРЈвдЩЯГЁОАжаЕФКмЖрвЕФкзЈМвИјГіСЫЯргІЕФЫМПМЁЂЩшМЦКЭЪЕМљЁЃБОШЫЪЧДѓЪ§ОнЗНЯђГіЩэЕФММЪѕШЫЃЌЫљдкЕФЭХЖгВЮгыСЫАЂРяЪжЬдЁЂЮЂЬдFeedСїЕФДцДЂВуЯрЙиЗўЮёЃЌЮвУЧЕФHBase/LindormЪ§ОнДцДЂВњЦЗдкЙЋгадЦЩЯвВжЇГжзХSoulЁЂШЄЭЗЬѕЁЂЛнЭЗЬѕЕШвЛаЉЪмЛЖгЕФаТУНЬхЁЂЩчНЛРрВњЦЗЁЃЮвУЧдкЪ§ОнДцДЂВњЦЗЕФЙІФмЁЂадФмЁЂПЩгУадЩЯЕФвЛаЉРэНтЃЌЯЃЭћЖдецЪЕТфЕивЛИіFeedСїМмЙЙПЩвдгавЛаЉАяжњЃЌвдМАвЛЦ№ЬНЬжFeedСїЕФЮДРДвдМАЪ§ОнВњЦЗШчКЮАяжњFeedСїНјвЛВНЕќДњЁЃ
БОЮФЯЃЭћПЩвдЬсЙЉСНЕуМлжЕЃК
1 FeedСїЕБЧАЕФжїСїМмЙЙвдМАТфЕиЗНАИ
2 вЛИіГѕДДЙЋЫОШчКЮбЁдёFeedСїЕФМмЙЙбнНјТЗОЖ
вЕЮёЗжЮі
FeedСїВЮгыепЕФМлжЕ
аХЯЂЩњВњеп
ЯЃЭћаХЯЂжЇГжИёЪНЗсИЛЃЈЮФзжЁЂЭМЦЌЁЂЪгЦЕЃЉЃЌЗЂВМСїГЉЃЈЩњВњаХЯЂЕФПЩгУадЃЉЃЌЖЉдФепМАЪБЪеЕНЯћЯЂЃЈЪБаЇадЃЉЃЌЖЉдФепВЛТЉЯћЯЂЃЈДЋЕнЕФПЩППадЃЉ
аХЯЂЯћЗбеп
ЯЃЭћМАЪБЪеЕНЙизЂЕФЯћЯЂЃЈЪБаЇадЃЉЃЌЯЃЭћВЛДэЙ§ХѓгбЁЂХМЯёЕФЯћЯЂЃЈДЋЕнЕФПЩППадЃЉЃЌЯЃЭћЛёЕУгаМлжЕЕФЯћЯЂЃЈНтОіаХЯЂЙ§диЃЉ
ЦНЬЈ
ЯЃЭћЮќв§ИќЖрЕФЩњВњепКЭЯћЗбепЃЈPVЁЂUVЃЉЃЌгУЛЇИќГЄЕФЭЃСєЪБМфЃЌЙуИцЁЂЩЬЦЗИќИпЕФзЊЛЏТЪ
FeedаХЯЂДЋЕнЗНЪН
вЛжжЪЧЛљгкЙиЯЕЕФЯћЯЂДЋЕнЃЌЙиЯЕЭЈЙ§МгКУгбЁЂЙизЂЁЂЖЉдФЕШЗНЪННЈСЂЃЌПЩФмЪЧЫЋЯђЕФвВПЩФмЪЧЕЅЯђЕФЁЃвЛжжЪЧЛљгкЭЦМіЫуЗЈЕФЃЌЯЕЭГИљОнгУЛЇЛЯёЁЂЯћЯЂЛЯёРћгУБъЧЉЗжРрЛђепаЭЌЙ§ТЫЕШЫуЗЈЯђгУЛЇЭЦЫЭЯћЯЂЁЃЮЂаХКЭЮЂВЉЦЋЯђгкЛљгкЙиЯЕЃЌЭЗЬѕЁЂЖЖвєЦЋЯђгкЛљгкЭЦМіЁЃ
FeedСїЕФММЪѕФбЕу
ЛЅСЊЭјГЁОАзмЪЧашвЊвЛЖЈЙцФЃВХФмЬхЯжГіММЪѕЕФЦПОБЃЌЯТУцЮвУЧЯШПДСНзщЙЋПЊЪ§ОнЃК
аТРЫЮЂВЉЮЊР§ЃЌзїЮЊвЦЖЏЩчНЛЪБДњЕФжиСПМЖЩчНЛЗжЯэЦНЬЈЃЌ2017ФъГѕШеЛюдОгУЛЇ1.6вкЃЌдТЛюдОгУЛЇНќ3.3вкЃЌУПЬьаТдіЪ§вкЬѕЪ§ОнЃЌзмЪ§ОнСПДяЧЇвкМЖЃЌКЫаФЕЅИівЕЮёЕФКѓЖЫЪ§ОнЗУЮЪQPSИпДяАйЭђМЖ
ЃЈРДзд FeedЯЕЭГМмЙЙгыFeedЛКДцФЃаЭЃЉ
НижЙ2016Фъ12дТЕзЃЌЭЗЬѕШеЛюдОгУЛЇ7800WЃЌдТЛюдОгУЛЇ1.75вкЃЌЕЅгУЛЇЦНОљЪЙгУЪБГЄ76ЗжжгЃЌгУЛЇааЮЊЗхжЕ150w+msg/sЃЌУПЬьбЕСЗЪ§Он300T+ЃЈбЙЫѕКѓЃЉЃЌЛњЦїЙцФЃЭђМЖБ№
ЃЈРДзд НёШеЭЗЬѕЭЦМіЯЕЭГМмЙЙЩшМЦЪЕМљЃЉ
ЩЯУцЛЙЪЧСНДѓОоЭЗЕФРњЪЗжИБъЃЌМйЩшвЛЬѕЯћЯЂ1KBФЧУДЧЇвкЯћЯЂдМ93TBЕФЪ§ОнСПЃЌШедіСПдкМИАйGBЙцФЃЧвQPSИпДяАйЭђЃЌвђДЫашвЊвЛИіОпБИИпЖСаДЭЬЭТЃЌРЉеЙадСМКУЕФЗжВМЪНДцДЂЯЕЭГЁЃгУЛЇфЏРРаТЯћЯЂЦкЭћАйКСУыЯьгІЃЌЯЃЭћаТЯћЯЂдкУыМЖЛђепжСЩй1ЗжжгзѓгвПЩМћЃЌЖдЯЕЭГЕФЪЕЪБадвЊЧѓКмИпЃЌетРяашвЊЖрМЖЕФЛКДцМмЙЙЁЃЯЕЭГБиаыОпБИИпПЩгУЃЌСМКУЕФШнДэадЁЃзюКѓетИіЯЕЭГзюКУВЛвЊЬЋЙѓЁЃ
вђДЫЮвУЧашвЊвЛИіИпЭЬЭТЁЂвзРЉеЙЁЂЕЭбгГйЁЂИпПЩгУЁЂЕЭГЩБОЕФFeedСїМмЙЙ
жїСїМмЙЙ
ЭМ1ЪЧЖдFeedСїЕФзюМђЕЅГщЯѓЃЌЭъГЩвЛИіДгЩњВњепЯђЯћЗбепДЋЕнЯћЯЂЕФЙ§ГЬЁЃ

ЭМ1 FeedСїМђЕЅГщЯѓ
ЯћЯЂКЭЙиЯЕ
ЪзЯШЃЌгУЛЇдкAPPВрЛёЕУЕФЪЧвЛИіFeed IDСаБэЃЌетИіСаБэВЛвЛЖЈАќКЌСЫЫљгаЕФаТЯћЯЂЃЌгУЛЇвВВЛвЛЖЈУПвЛИіЖМДђПЊфЏРРЃЌШчЙћДЋЕнећИіЯћЯЂЗЧГЃРЫЗбзЪдДЃЌвђДЫВњЩњГіРДЕФЯћЯЂЪзЯШЩњГЩжїЬхКЭЫїв§СНИіВПЗжЃЌЦфжаЫїв§АќКЌСЫЯћЯЂIDКЭдЊЪ§ОнЁЃЦфДЮвЛИігІгУзмЪЧДцдкЙиЯЕЃЌЛљгкЙиЯЕЕФДЋЕнЪЧБиВЛПЩЩйЕФЃЌвВвђДЫвЛЖЈгавЛИіЙиЯЕЕФДцДЂКЭВщбЏЗўЮёЁЃ

ЭМ2 FeedСїЯћЯЂЁЂЙиЯЕЕФДцДЂ
ЯћЯЂБОЩэгІИУЫуЪЧвЛжжАыНсЙЙЛЏЪ§ОнЃЈАќКЌЮФзжЃЌЭМЦЌЃЌЖЬЪгЦЕЃЌвєЦЕЃЌдЊЪ§ОнЕШЃЉЁЃЦфЖСаДЭЬЭТСПвЊЧѓИпЃЌЖСаДБШР§ашвЊПДОпЬхГЁОАЁЃзмЕФДцДЂПеМфДѓЃЌашвЊКмКУЕФРЉеЙадРДжЇГХвЕЮёдіГЄЁЃЯћЯЂПЩФмЛсгаЖрДЮИќаТЃЌБШШчФкШнаоИФЃЌфЏРРЪ§ЃЌЕудоЪ§ЃЌзЊЗЂЪ§ЃЈГЩЪьЕФЯЕЭГЛсЖРСЂвЛИіcounterФЃПщРДЗўЮёетаЉдЊЪ§ОнЃЉвдМАБъМЧЩОГ§ЁЃЯћЯЂвЛАуВЛЛсгРОУБЃДцЃЌПЩФмвЊдк1ФъЛђеп3ФъКѓЩОГ§ЁЃ
злЩЯЃЌИіШЫЭЦМіЪЙгУHBaseДцДЂ
HBaseжЇГжНсЙЙЛЏКЭАыНсЙЙЛЏЪ§ОнЃЛ
ОпгаЗЧГЃКУЕФаДШыадФмЃЌЬиБ№ЖдгкFeedСїГЁОАПЩвдРћгУХњСПаДНгПкЕЅЛњЃЈ32КЫ64GBЃЉДяЕНМИЪЎЭђЕФаДШыаЇТЪЃЛ
HBaseОпБИЗЧГЃЦНЛЌЕФЫЎЦНРЉеЙФмСІЃЌздЖЏНјааShardingКЭBalanceЃЛ
HBaseФкжУЕФBlockCacheМгЩЯSSDХЬПЩвдЬсЙЉmsМЖЕФИпВЂЗЂЖСЃЛ
HBaseЕФTTLЬиадПЩвдздЖЏЕФЬдЬЙ§ЦкЪ§ОнЃЛ
РћгУЪ§ОнИДжЦДюНЈвЛИіРфШШЗжРыЯЕЭГЃЌаТЯћЯЂДцДЂдкгЕгаSSDДХХЬКЭДѓЙцИёЛКДцЕФШШПтЃЌОЩЪ§ОнДцДЂдкРфПтЁЃ
дЫгУБрТыбЙЫѕгааЇЕФПижЦДцДЂГЩБОЃЌМћHBaseгХЛЏжЎТЗ-КЯРэЕФЪЙгУБрТыбЙЫѕ

ЭМ3 ЪЙгУHBaseДцДЂFeedСїЯћЯЂ
ЖдгкЙиЯЕЗўЮёЃЌЦфаДШыВйзїЪЧНЈСЂЙиЯЕКЭЩОГ§ЙиЯЕЃЌЖСШЁВйзїЪЧЛёШЁЙиЯЕСаБэЃЌТпМЩЯНіашвЊвЛИіKVЯЕЭГЁЃШчЙћЪ§ОнСПНЯЩйПЩвдЪЙгУRDSЃЌШчЙћЪ§ОнСПНЯДѓЭЦМіЪЙгУHBaseЁЃШчЙћЖдЙиЯЕЕФQPSбЙСІДѓПЩвдПМТЧгУRedisзіЛКДцЁЃ
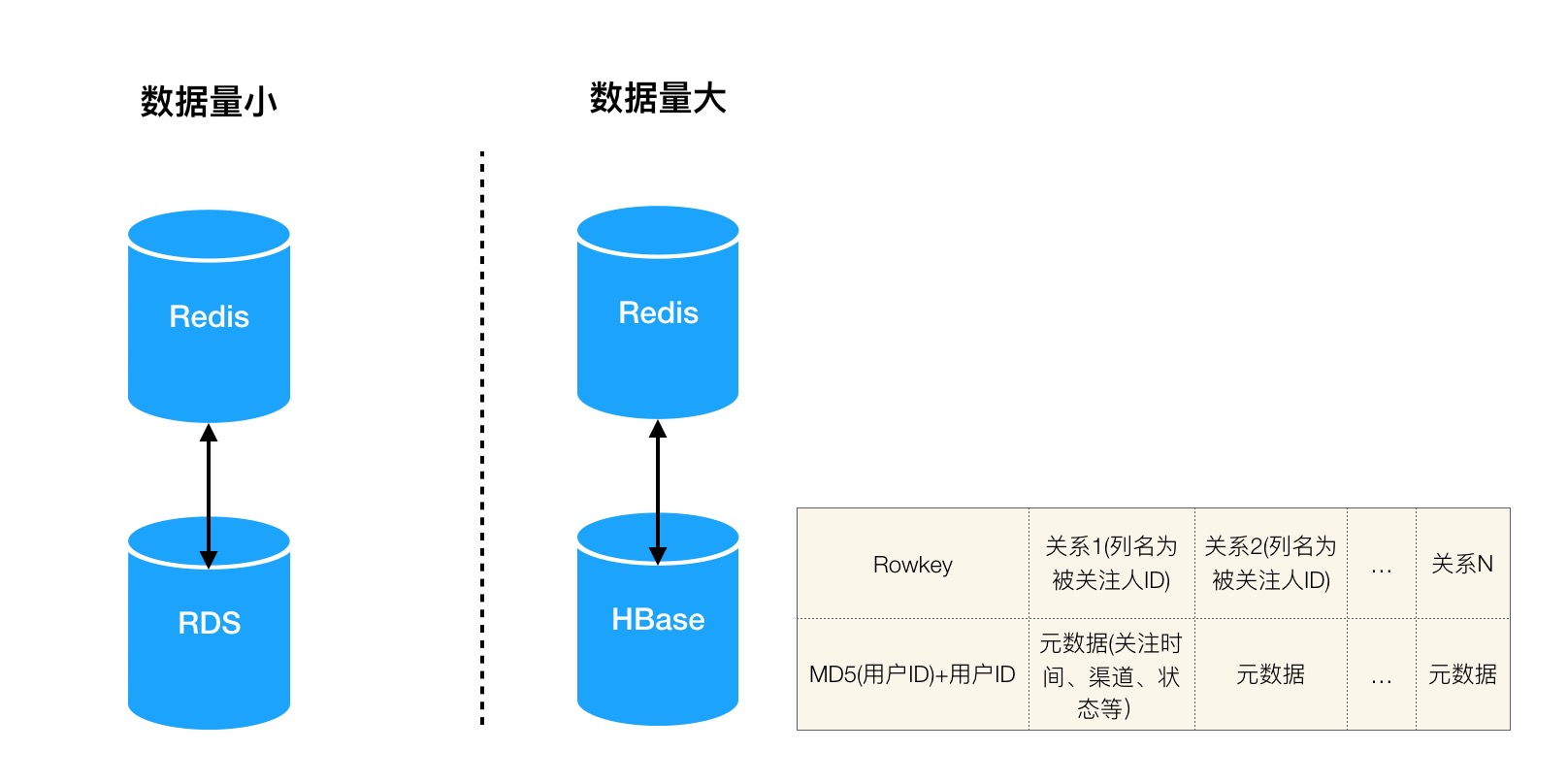
ЭМ4 гУЛЇЙиЯЕДцДЂ
ЯћЯЂДЋЕн
НВЕНFeedСївЛЖЈЛсгаЙигкЭЦФЃЪНКЭРФЃЪНЕФЬжТлЃЌЭЦФЃЪНЪЧАбЯћЯЂИДжЦNДЮЗЂЫЭЕНNИігУЛЇЕФЪеаХЯфЃЌгУЛЇЯыПДЯћЯЂЪБДгздМКЕФЪеаХЯфжБНгЛёШЁЁЃРФЃЪНЯрЗДЃЌЩњВњепЕФЯћЯЂаДШыздМКЕФЗЂаХЯфЃЌгУЛЇЯыПДЯћЯЂЪБДгЙизЂЕФMИіЗЂаХЯфжаЪеМЏЯћЯЂЁЃ

ЭМ5 ЯћЯЂДЋЕнЕФЭЦФЃЪНКЭРФЃЪН
ЭЦФЃЪНЪЕЯжЯрЖдМђЕЅЃЌЪБаЇадвВБШНЯКУЁЃРФЃЪНвЊЯыЛёЕУКУЕФадФмашвЊЖрМЖЕФЛКДцМмЙЙЁЃЭЦФЃЪНжиаДЃЌРФЃЪНжиЖСЃЌFeedСїГЁОАЯТаДЕФОлКЯаЇЙћвЊгХгкЖСЃЌаДПЩвдДѓХњСПОлКЯЁЃNдНДѓЃЌаДШыдьГЩЕФЪ§ОнШпгрОЭдНДѓЁЃMдНДѓЃЌЖСЯћКФЕФзЪдДдНДѓЁЃ
ЫцзХвЕЮёЕФдіГЄЃЌЭЦФЃЪНзЪдДРЫЗбЛсдНЗЂбЯжиЁЃдвђдкгкСНЕуЃКЕквЛДцдкзХДѓСПЕФНЉЪЌеЫКХЃЌвдМАДѓБШР§ЕФЗЧЛюдОгУЛЇМИЬьЛђепАыИідТВХЕЧТНвЛДЮЃЛЕкЖўаХЯЂЙ§диЃЌаХЯЂЬЋЖрЃЌжиИДаХЯЂЬЋЖрЃЌРЌЛјаХЯЂЬЋЖрЃЌгУЛЇИаОѕгагУЕФаХЯЂЩйЃЌЯћЯЂЕФдФЖСБШР§ЕЭЁЃетжжЧщПіЯТЭЦФЃЪНЯрЕБвЛВПЗждкзіЮогУЙІЃЌАзАзРЫЗбЯЕЭГзЪдДЁЃ
ЪЧЭЦЃПЪЧРЃПЛЙЪЧЛьКЯЃПУЛгазюКУЕФМмЙЙЃЌжЛгаЪЪКЯЕФГЁОА~
ЛљгкЙиЯЕЕФДЋЕн
ЭМ6ЪЧДПЭЦФЃЪНЕФМмЙЙЃЌИУМмЙЙга3ИіЙиМќЕФВПЗж
вьВНЛЏЁЃЩњВњепЬсНЛЯћЯЂЪзЯШаДШывЛИіЖгСаЃЌГЩЙІдђБэЪОЗЂВМГЩЙІЃЌDispatcherФЃПщЛсвьВНЕФДІРэЯћЯЂЁЃетвЛЕуЗЧГЃЙиМќЃЌЪзЯШЩњВњепЕФЯћЯЂЗЂВМЬхбщЗЧГЃКУЃЌВЛашвЊЕШД§ЯћЯЂЭЌВНЕНЗлЫПЕФЪеаХЯфЃЌЗЂВМбгГйЕЭГЩЙІТЪИпЃЛЦфДЮDispatcherПЩвдПижЦЖгСаЕФДІРэЫйЖШЃЌПЩвдгааЇЕФПижЦДѓVеЫКХдьГЩЕФТіГхбЙСІЁЃ
ЖрМЖЖгСаЁЃDispatcherПЩвдИљОнЯћЗбепЕФзДЬЌЃЌаХЯЂЕФЗжРрЕШЛЎЗжВЛЭЌЕФДІРэЗНЪНЃЌЗжХфВЛЭЌЕФзЪдДЁЃБШШчЖдгкДѓVеЫКХЕФЯћЯЂЃЌЕБЧАЛюдОгУЛЇбЁдёжБНгЗЂЫЭЃЌБЃеЯЯћЯЂЕФЪБаЇадЃЌЗЧЛюдОгУЛЇЗХШыЖгСабгГйЗЂЫЭЁЃБШШчзЊЗЂЖрЕФЯћЯЂПЩвдгХЯШДІРэЕШЁЃЖгСаРяЕФЯћЯЂПЩвдВЩгУХњСПОлКЯаДЕФЗНЪНЬсИпЭЬЭТЁЃ
ЪеаХЯфЁЃМйШчгаСНвкгУЛЇЃЌУПИігУЛЇБЃСєзюаТ2000ЬѕЭЦЫЭЯћЯЂЁЃМДБуДцДЂЕФЪЧЫїв§вВЪЧЧЇвкЕФЙцФЃЁЃЪеаХЯфвЛАуЕФБэНсЙЙЮЊгУЛЇID+ЯћЯЂађСа
+ ЯћЯЂID + ЯћЯЂдЊЪ§ОнЃЌЯћЯЂађСаЪЧвЛИіЕндіЕФIDЃЌашвЊДцДЂвЛИіЦЋвЦСПБэЪОЩЯДЮЖСЕНЕФЯћЯЂађСаIDЁЃгУЛЇЖСШЁзюаТЯћЯЂ
select * from inbox where ЯћЯЂађСа > offsetЁЃ

ЭМ6 ЛљгкЙиЯЕДЋЕнЕФДПЭЦФЃЪН
ЭЦМіЪЙгУHBaseЪЕЯжЪеаХЯф
HBaseЕЅЛњХњСПаДФмСІдкМИЪЎЭђВЂЧвПЩвдЫЎЦНРЉеЙЁЃ
HBaseЕФИпаЇЧАзКЩЈУшЗЧГЃЪЪКЯЖСШЁзюаТЕФЯћЯЂЁЃ
HBaseЕФTTLЙІФмПЩвдЖдЪ§ОнЖЈвхЩњУќжмЦкЃЌИпаЇЕФЬдЬЙ§ЦкЪ§ОнЁЃ
HBaseЕФFilterЙ§ТЫЦїКЭЖўМЖЫїв§ПЩвдгааЇЕФЪЕЯжInboxЕФЫбЫїФмСІЁЃ
ЯћЗбепЪеаХЯфhbaseБэЩшМЦШчЯТЃЌЦфжаађСаКХвЊБЃжЄЕндіЃЌвЛАугУЪБМфДСМДПЩЃЌЬиБ№ИпЦЕЧщПіЯТПЩвдгУвЛИіRDSРДжЦдьађСаКХ

ЭМ7ЪЧЭЦРНсКЯЕФФЃЪН
діМгЗЂаХЯфЃЌДѓVЕФЗЂВМНјШыЦфЖРСЂЕФЗЂаХЯфЁЃЗЧДѓVЕФЗЂВМжБНгЗЂЫЭЕНгУЛЇЕФЪеаХЯфЁЃЦфКУДІЪЧНтОіДѓСПЕФНЉЪЌеЫКХКЭЗЧЛюдОеЫКХЕФЮЪЬтЁЃгУЛЇжЛгадкЧыЧѓаТЯћЯЂЕФЪБКђЃЈБШШчЕЧТНЁЂЯТРЯћЯЂПђЃЉВХЛсШЅЯћКФЯЕЭГзЪдДЁЃ
ЗЂаХЯфЕФЖрМЖЛКДцМмЙЙЁЃвЛИіДѓVПЩФмгаАйЭђЗлЫПЃЌвЛЬѕШШЕуЯћЯЂЕФДЋВЅДАПквВЛсЗЧГЃЖЬЃЌМДЖЬЪБМфФкЛсЖдЗЂаХЯфжаЕФЭЌвЛЬѕЯћЯЂДѓСПжиИДЖСШЁЃЌЖдЯЕЭГЬєеНКмДѓЁЃжеЬЌЯТЮвУЧПЩФмЛсбЁдёСНМЖЛКДцЃЌЪеаХЯфЪ§ОнЛЙЪЧвЊГжОУЛЏЕФЃЌЗёдђЩ§МЖЛђепхДЛњЪБЪ§ОнОЭЖЊЪЇСЫЃЌЫљвдЕквЛВуЪЧвЛИіЗжВМЪНЪ§ОнДцДЂЃЌетИіДцДЂЭЦМіЪЙгУHBaseЃЌдвђКЭInboxРрЫЦЁЃЕкЖўВуЪЙгУredisЛКДцМгЫйЃЌЕЋЪЧДѓVЙ§ДѓПЩФмдьГЩШШЕуЮЪЬтЛЙашвЊЕкШ§ВуБОЕиЛКДцЁЃЛКДцВуЕФгХЛЏжївЊАќРЈСНИіЗНЯђЃКЕквЛЬсИпЛКДцУќжаТЪЃЌГЃгУЕФЗНЪНЪЧЖдЪ§ОнНјааБрТыбЙЫѕЃЌЕкЖўБЃеЯЛКДцЕФПЩгУадЃЌетРяЩцМАЕНЖдЛКДцЕФШпгрЁЃ

ЭМ7 ЛљгкЙиЯЕДЋЕнЕФЭЦРЛьКЯФЃЪН
ЛљгкЭЦМіЕФДЋЕн
ЭМ8ЪЧЛљгкЭЦМіЕФФЃаЭЃЌПЩвдПДГіЫќЪЧдкЭЦРНсКЯЕФФЃЪНЩЯШкКЯСЫЭЦМіЯЕЭГЁЃ
в§ШыЛЯёЯЕЭГЃЌБЃДцгУЛЇЛЯёЁЂЯћЯЂЛЯёЃЈМђЕЅЧщПіЯТЯћЯЂЛЯёПЩвдЗХдкЯћЯЂдЊЪ§ОнжаЃЉЁЃЛЯёгУгкЭЦМіЯЕЭГЫуЗЈЕФЪфШыЁЃ
в§ШыСЫСйЪБЪеаХЯфЃЌдкаХЯЂЙ§диЕФГЁОАжаЃЌЗЧДѓVЕФЯћЯЂвВЪЧзмСПКмДѓЃЌЦфжаВЛУтГфГтзХРЌЛјЁЂШпгрЯћЯЂЃЌЫљвджБНгНјШыгУЛЇЪеаХЯфВЛЬЋКЯЪЪЁЃ
ЪеаХЯфКЭЗЂаХЯфЖМашвЊгаСМКУЕФЫбЫїФмСІЃЌетЪЧЭЦМіЯЕЭГИпаЇдЫааЕФЙиМќЁЃOutboxгаЛКДцВуЃЌЫїв§ПЩвдзіЕНЛКДцРяУцЃЛInboxвЛАуЧщПіЯТЖўМЖЫїв§ПЩвдТњзуДѓВПЗжашЧѓЃЌЕЋШчЙћгУЛЇЯЃЭћгаШЋЮФЫїв§ЛђепШЮвтЮЌЖШЕФМьЫїФмСІЃЌЛЙашвЊв§ШыЫбЫїЯЕЭГШчSolr/ES

ЭМ8 ЛљгкЭЦМіЕФFeedСїМмЙЙ
гУЛЇЛЯёЪЙгУHBaseДцДЂ
ЛЯёвЛАуЪЧЯЁЪшБэЃЌЛЯёзмЮЌЖШПЩФмдк200+ЩѕжСИќЖрЃЌЕЋЕЅИігУЛЇЕФЮЌЖШПЩФмдкМИЪЎЃЌВЂЧвЮЌЖШПЩФмЫцвЕЮёВЛЖЯБфЛЏЁЃФЧУДHBaseЕФSchema
freeКЭЯЁЪшБэЕФФмСІЗЧГЃЪЪКЯетИіГЁОАЃЌвзгУЧвНкЪЁДѓСПДцДЂПеМфЁЃ
ЖдЛЯёЕФЗУЮЪвЛАуЪЧЕЅааЖСЃЌhbaseБОЩэЕЅааGetЕФадФмОЭЗЧГЃКУЁЃАЂРядЦHBaseдкетИіЗНЯђЩЯзіСЫЗЧГЃЖрЕФгХЛЏЃЌАќРЈCCSMAPЁЂSharedBucketCacheЁЂMemstoreBloomFilterЁЂIndex
EncodingЕШЃЌПЩвдДяЕНЦНОљRT=1-2msЃЌЕЅПт99.9% <100msЁЃАЂРяФкВПРћгУЫЋМЏШКDual
ServiceПЩвдзіЕН 99.9% < 30msЃЌетвЛФмСІЮвУЧвВдкХЌСІЭЦЕНЙЋгадЦЁЃhbaseЕФЖСЭЬЭТЫцЛњЦїЪ§СПЫЎЦНРЉеЙЁЃ
СйЪБЪеаХЯфЪЙгУдЦHBase
HBaseЕФЖСаДИпЭЬЭТЁЂЕЭбгГйФмСІЃЌетРяВЛдйжиИДЁЃ
HBaseЬсЙЉFilterКЭШЋОжЖўМЖЫїв§ЃЌТњзуВЛЭЌСПМЖЕФЫбЫїашЧѓЁЃ
АЂРядЦHBaseШкКЯHBaseгыSolrФмСІЃЌЬсЙЉЕЭГЩБОЕФШЋЮФЫїв§ЁЂЖрЮЌЫїв§ФмСІЁЃ
ГѕДДЙЋЫОЕФЕќДњТЗОЖ
дквЕЮёЗЂеЙЕФГѕЦкЃЌгУЛЇСПКЭзЪдДЖМУЛгаФЧУДЖрЃЌЭХЖгЕФШЫСІЭЖШывВЪЧгаЯоЕФЃЌВЛПЩФмвЛЩЯРДОЭИувЛИіЬиБ№ИДдгЕФМмЙЙЃЌЁАЙЛгУЁБОЭааСЫЃЌживЊЕФЪЧ
1.ПЩвдПьЫйЕФНЛИЖ
2.ЯЕЭГвЊЮШЖЈ
3.ЮДРДПЩвдДгШнЕФЕќДњЃЌБмУтЭЦЕЙжиРД
БОШЫЫЎЦНгаЯоЃЌИљОнздЩэЕФОбщЯђДѓМвЭЦМівЛжжЕќДњТЗОЖвдЙЉВЮПМЃЌШчгаВЛЭЌвтМћЛЖгНЛСї
Ц№ВНМмЙЙШчЭМ9ЃЌЪЙгУдЦKafka+дЦHBaseЁЃШчЙћЖдInboxгаМьЫїашЧѓЃЌНЈвщЪЙгУHBaseЕФscan+filterМДПЩЁЃ
1.ЯћЯЂЗжЮЊжїЬхКЭЫїв§
2.ВЩгУДПЭЦЕФФЃЪН
3.ВЩгУвьВНЛЏ

ЭМ9 Ц№ВНМмЙЙ
Ъ§ОнСПж№НЅдіДѓКѓЃЌЖдЭЦФЃЪННјвЛВНЕќДњЃЌжївЊашЧѓЪЧ
1.ПижЦДѓVдьГЩЕФаДШыТіГхИпЗх
2.ПижЦДцДЂГЩБО
3.ЬсЩ§ЖСаДадФм
4.ЬсЩ§вЛЖЈЕФInboxЫбЫїФмСІ
НјвЛВНЕФЕќДњМмЙЙШчЭМ10
1.ЯћЯЂЗжЮЊжїЬхКЭЫїв§
2.ВЩгУДПЭЦЕФФЃЪН
3.ВЩгУвьВНЛЏ
4.ВЩгУЖрМЖЖгСаНтОіДѓVЮЪЬт
5.ВЩгУРфШШЗжРыНЕЕЭДцДЂГЩБО
6.ДЫЪБInboxжаЕФЯћЯЂвВКмЖрЃЌЖдЫбЫїЕФашЧѓдіЧПЃЌНіНіScan+FilterВЛЙЛЃЌПЩФмашвЊЖўМЖЫїв§

ЭМ10 ДПЭЦФЃЪНЕФбнНј
вЕЮёбИУЭЗЂеЙЃЌЯћЯЂКЭгУЛЇдіГЄбИЫйЃЌНЉЪЌеЫКХЁЂЗЧЛюдОеЫКХНЯЖрЃЌаХЯЂЙ§дибЯжи
1.ЯћЯЂЗжЮЊжїЬхКЭЫїв§
2.ВЩгУЭЦРНсКЯФЃЪН
3.ВЩгУвьВНЛЏ
4.в§ШыЭЦМіЯЕЭГ
5.ВЩгУРфШШЗжРыНЕЕЭДцДЂГЩБО
6.OutboxВЩгУЖрМЖЛКДцЬсИпЖСШЁадФм
7.InboxдіМгЖўМЖЫїв§ЬсЩ§ЫбЫїФмСІ
ЪЙгУдЦKafka+дЦHBase+дЦRedis

ЭМ11 ЛљгкЭЦМіЕФЭЦРЛьКЯМмЙЙ
змНс
FeedаХЯЂСїЪЧЛЅСЊЭјГЁОАжаЗЧГЃЦеБщЕФГЁОАЃЌБщВМгкЕчЩЬЁЂЩчНЛЁЂаТУНЬхЕШAPPЃЌвђДЫбаОПFeedСїЪЧЗЧГЃгаМлжЕЕФвЛМўЪТЧщЁЃБОЮФзмНсСЫFeedСїЕФвЕЮёГЁОАКЭжїСїМмЙЙЃЌЗжЮіСЫВЛЭЌГЁОАЁЂЬхСПЯТММЪѕЕФФбЕугыЦПОБЁЃЖдDispatcherЁЂInboxЁЂOutoutМИИізщМўНјааСЫЯъЯИЕФбнНјНщЩмЃЌЬсЙЉСЫЛљгкдЦЛЗОГЕФТфЕиЗНАИЁЃБОШЫЫЎЦНгаЯоЃЌЯЃЭћПЩвдХззЉв§гёЃЌЛЖгДѓМввЛЦ№ЬНЬжЁЃFeedСїЕФМмЙЙбнНјЛЙдкГжајЃЌВЛЭЌвЕЮёГЁОАЯТЛЙгаФФаЉШБЯнКЭЭДЕуЃПЪ§ОнВњЦЗШчКЮДгЙІФмКЭадФмЩЯбнНјРДжЇГХFeedСїЕФГжајЗЂеЙЃПдкетаЉЮЪЬтЕФЧ§ЖЏЯТЃЌдЦHBaseЮДРДНЋЛсДѓСІЭЖШыЕНFeedСїГЁОАЕФГжајгХЛЏКЭИГФмЃЁ
|








