| БрМЭЦМі: |
жївЊНВНтСЫФкШнМмЙЙзмЭМ,ЩшМЦгыЪЕЯжАќРЈЃКФкШнв§ШыФЃаЭЕФЩшМЦгыЕќДњЃЌФкШнДцДЂМмЙЙЩшМЦЃЌИіадЛЏФкШнЯТЗЂЕШЯрЙиФкШнЁЃ
РДздгкМђЪщЃЌ,гЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
ЧАбд
ЁАfeedСїЁБЭЈГЃЪЧжИгУЛЇЭЈЙ§жїЖЏРЛђепБЛЖЏЭЦЕФЗНЪНЛёШЁЖЉдФаХЯЂСїЁЃГЃМћЕФЃЌБШШчЮЂВЉЩЯЕФГЌЛАЃЌаТАцБОЕФЮЂаХЙЋжкКХЖЉдФЯћЯЂЃЌЖЖвєРяЕФЪгЦЕСїЕШЕШЁЃФПЧАЪаУцЩЯжїСїЕФappЪзЦСЛљБОЖМЪЧfeedСїЩшМЦЁЃБОЮФжївЊЪЧДгвЕЮёЬиеїГіЗЂЃЌЩюШыЧГГіЕФНщЩмfeedСїЕФМмЙЙЩшМЦЪЧШчКЮНсКЯЙЋПЊПЮЕФвЕЮёЬиеїзіЕНИпаЇТфЕиЕФЁЃ
ДгвЕЮёМмЙЙПДЃЌЁАfeedСїЁБдкзнЯђЩЯПЩвдВ№НтГЩШ§ИіВПЗжЃК
дДФкШнв§Шы
дДФкШнЕНfeedФкШнЙ§ЖЩ
feedФкШнЭЖЗХ
ашЧѓКЭЬєеН
дкИљОнвЕЮёМмЙЙзіММЪѕГщЯѓЕФЪБКђЃЌећИіМмЙЙПЩвдЙщФЩЪеСВЕНвдЯТМИИіММЪѕЕуЃК
ШчКЮзіКУФкШнв§ШыЕФЙ§ТЫВпТд
ШчКЮБЃжЄФкШнДцДЂМмЙЙЕФИпПЩгУ
ШчКЮзіЕНФкШнИіадЛЏОЋзМЗжЗЂ
ФкШнМмЙЙзмЭМ

ЩшМЦгыЪЕЯж
ЃЈвЛЃЉФкШнв§ШыФЃаЭЕФЩшМЦгыЕќДњ
ФкШнв§ШыФЃаЭv1.0ШчЭМ2ЫљЪО 
ЭјвзЙЋПЊПЮЕФФкШнРДдДгаСНжжЃК
зддЫгЊЕФОЋЦЗФкШн
ЧЉдМЕФЕкШ§ЗНpgcгУЛЇ
зддЫгЊЕФОЋЦЗФкШнвдМАpgcЧЉдМгУЛЇЩњВњЕФФкШнОЙ§ЁАЛњЦїЩѓКЫЁБЁЂЁАШЫЙЄГѕЩѓЁБЁЂЁАШЫЙЄИДЩѓЁБЁЂЁАГщМьЁБЁЂЁАбВВщЁБЕШЛљБОЩѓКЫСїГЬЃЌдйЙ§ТЫЩцЛЦЁЂЩцеўЕШУєИааХЯЂШЛКѓСїШыФкШнГиЁЃЖдгкГѕЦкЕФЙЋПЊПЮРДЫЕЃЌетжжФЃаЭЫфШЛМђЕЅДжБЉЃЌЕЋЪЧШЗЪЕвВзуЙЛжЇГХвЕЮёЁЃВЛЙ§ЫцзХвЕЮёЬхСПЕФдіМгЃЌгШЦфЪЧгУЛЇСПЕФБЉдіЃЌетИіФЃаЭЕФШБЕувВБЉТЖГіРДЁЊЁЊМДФЃаЭВњГіФкШнЕФЫйЖШдЖЕЭгкгУЛЇЯћЗбЕФЫйЖШЁЃжБАзЕФЫЕЃЌетИіФЃаЭЕФФкШнВњГіТЪЪЧВЛзувджЇГХЯжгаЕФгУЛЇЙцФЃЯћЗбЕФЁЃ
ФкШнв§ШыФЃаЭv2.0ШчЭМ3ЫљЪО 
дк2.0РяЃЌКЫаФЪЧв§ШыСЫЁАЧЉдМШызЄздУНЬхЁБЃЌзХжиНтОіСЫФкШнВњСПЮЪЬтЁЃРрЫЦАйЖШЕФЁААйМвКХЁБЃЌЭЗЬѕЕФЁАЭЗЬѕКХЁБЃЌЮЂаХЕФЁАЙЋжкКХЁБЃЌЭјвзаТЮХУХЛЇУцЯђЦеЭЈгУЛЇЭЦГіЕФЗЂВМФкШнЕФЦНЬЈЃЌЙуЗКв§ШыгУЛЇЕФФкШнЙрШыЕНЧЉдМздУНЬхРяЁЃШЛКѓвЕЮёздМКдйЭЈЙ§ЁАТЉЖЗФЃаЭЁБМгШЈЬѕМўЯожЦЃЌЙ§ТЫЕєВЛЗћКЯЙЋПЊПЮвЕЮёЬиеїЕФФкШнЁЃОйИіМђЕЅЕФР§згЃЌБШШчЮвУЧдкв§ШыбЇЯАвєРжЕФЪгЦЕЪБЃЌЭЈЙ§жЦЖЈЕФЙ§ТЫЙцдђЃК
ЕудоЪ§ГЌЙ§1wЕФ
БъЬтАќКЌвєРжЕШЙиМќДЪЕФ
гааЇЛиИДЪ§ГЌЙ§вЛЖЈСПЕФ
дкЪЕМЪЩњВњЛЗОГРяЃЌЭЈЙ§етвЛЯЕСаЕФЙ§ТЫЙцдђОЭФмЙ§ТЫЕєДѓВПЗжЕФдгжЪФкШнЃЌШЛЖјЛњЦїЩѓКЫПЯЖЈЛсгаТЉЩБЁЂЮѓЩБЕФbad
caseЁЃЛљгкетИіПМТЧЃЌЮвУЧаТв§ШыСЫвЛИіЁАЕШМЖГиЁБЕФИХФюЃЌШчЭМ4ЁЃ 
зддЫгЊФкШн --> ОЋбЁГи
ЧЉдМpgcФкШн --> гХжЪГи
ЧЉдМШызЄздУНЬхФкШн --> ЦеЭЈГи
ЁАЕШМЖГиЁБИХФюЕФв§ШыжївЊЪЧдкЪзвГИіадЛЏЭЦМіЫуЗЈвдМАЗўЮёНЕМЖЖЕЕзЕФЪБКђгУЕНЃЌжївЊЪЧБЃжЄЗўЮёЬхбщвдМАБЃжЄЗўЮёЮШЖЈадЕФЁЃ
ЃЈЖўЃЉФкШнДцДЂМмЙЙЩшМЦ

ИљОнгУЛЇааЮЊЬиеївдМАЙЋПЊПЮЕФФкШнЪєадЃЌдкШ§ИіЛљБОФкШнГиЛљДЁЩЯЃЌдйГщЯѓГіШєИЩИіЪєадЗжРрГиbucketЃЌШчЭМ6ЁЃ 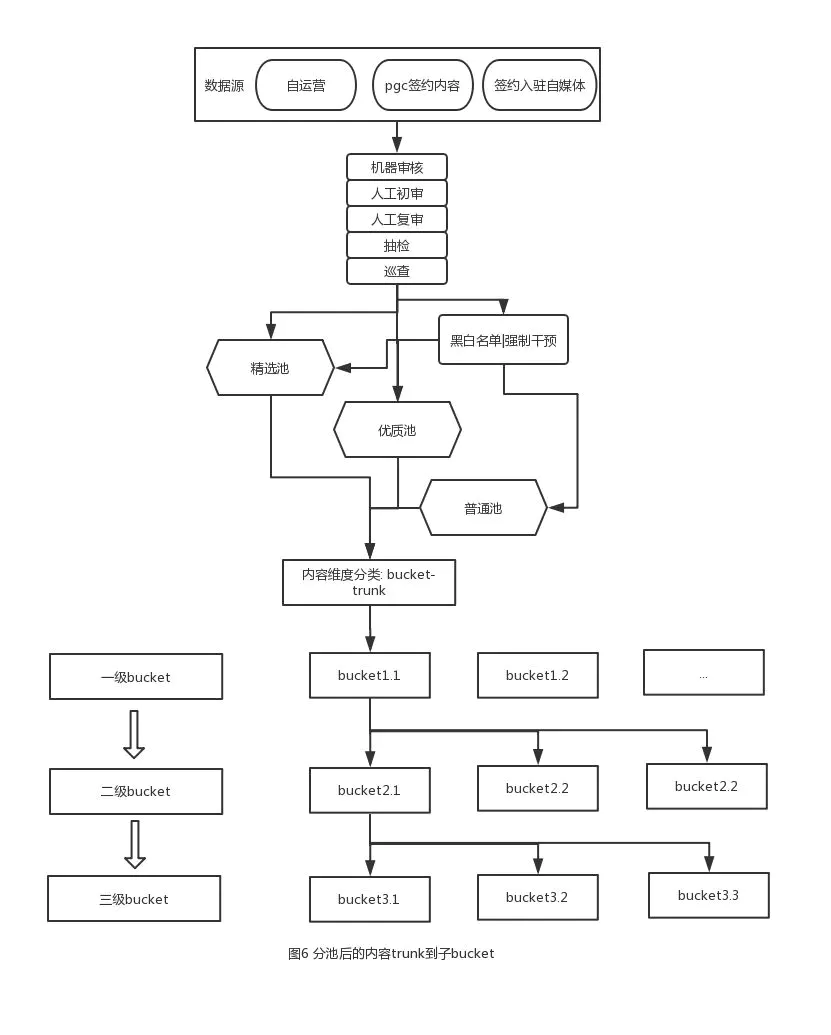
ИљОнФкШнжїЬхеЫКХЕФЪєадздЖЏmapЕНОпЬхЕФЪєадЗжРрГиЃЌгаЕуРрЫЦгкbucketЕФИХФюЃЌжївЊЪЧАбФкШнchunkЕНИїИізгbucketРяЁЃЮвУЧЯИЛЏетУДЖрФкШнГиЦфЪЕКЫаФФПЕФОЭЪЧФмИќКУЕФЬсШЁгУЛЇЕФааЮЊЬиеїЁЃФмИќОЋШЗЕФЛёШЁЕНгУЛЇЕФааЮЊЃЌОЭФмзіГіИќзМШЗЕФгУЛЇЛЯёЃЌЖјетРяЩшМЦЕФ
ЁАеЫКХЁА ЁБФкШнЁАЕФгГЩфЙиЯЕЃЌЛсаДШыЕНгУЛЇПЬЛ&ФкШнЭЦМіЫуЗЈЯЕЭГРяЁЃгУЛЇдкappЩЯЕФааЮЊЛсЩЯБЈЕНгУЛЇПЬЛ&ФкШнЭЦМіЫуЗЈЯЕЭГзібЕСЗЁЃ
ОЙ§дЄДІРэКѓЃЌПЊЪМЙЙНЈЕзВуЪ§ОнГжОУЛЏЕФДцДЂМмЙЙЃЌШчЭМ7 
2.1Ъ§ОнДЙжБВ№Зж
МйЩшУПвЛЬѕЪ§ОнЖМгаШ§ИіЛљБОЪєадЃК
ПЮГЬЛљБОФкШнЃЈБъЬтЃЌМђНщЕШЃЉ
гУЛЇЖЏзїааЮЊЃЈЕудоЃЌЪеВиЕШЃЉ
ФкШнИіадЛЏЃЈЗжГиЁЂЗжРрЕШЃЉ
дкДцДЂЕФЪБКђЃЌУПЬѕЪ§ОнБЛДЙжБВ№ЗжГЩ3ПщЃЌДЙжБВ№ЗжЃЌИїздЖРСЂДцДЂЃЌЭЈЙ§вЕЮёЬиеїФкСЊЃЌШчЭМ8 
жСгкЮЊЪВУДвЊДЙжБВ№ЗжЖјВЛзіШпгрЃПжївЊЛљгквдЯТПМТЧЃК
Ъ§ОнПщЕФдіСПЁЂЗУЮЪСПКЭИќаТСПВюОрКмДѓЃЌqpsВЛОљКтЃЌгаДѓзжЖЮЕФИќаТВщбЏЮЪЬт
ЛљгкФЃПщКЭЗўЮёЖРСЂЕФЫМПМЃЌДгЪ§ОнЮЌЖШзіИєРы
ЛљгкЪ§ОнЬиеїПМТЧЃЌЖРСЂЕФЪ§ОнВжПтИќЗНБузіЪ§ОнЬдЬЃЌРфШШЗжРы
2.2Ъ§ОнЫЎЦНВ№Зж
ЫЎЦНВ№ЗжЦфЪЕОЭЪЧКмГЃМћЕФЗжПтЗжБэЃЌЙЋПЊПЮЕФгУЛЇааЮЊЪ§ОнгаКмЖрЃЌЯёГЃМћЕФЪеВиЁЂЕудоЁЂЙлПДРњЪЗЕШЕШЁЃетаЉЪєадгааЉЪЧЪ§ВжЭГМЦашвЊЪЙгУЕФЃЌгааЉЪЧЭЦМіЕФЫуЗЈФЃаЭашвЊгУЕНЕФЃЌЛЙгааЉдђЪЧДПгУЛЇааЮЊЕФЪ§ОнЁЃЫљвддквЕЮёЕМЯђЩЯЃЌЫЎЦНЧаИюГЩЖрИігУЛЇааЮЊЪ§ОнБэЁЃ
2.3ЙЙНЈESЫїв§ЃЌШчЭМ9 
в§ШыESЪЧвЕЮёЩЯЕФЧПашЧѓЁЃЙЋПЊПЮESЩшМЦЗжЮЊЧАКѓЬЈESЃЌЧАЖЫESжївЊЪЧУцЯђCЖЫЃЌТњзугУЛЇЕФЛљБОЕФЫбЫїашЧѓЁЃКѓЖЫESжївЊЪЧУцЯђBЖЫЃЌТњзудЫгЊШЫШеГЃашЧѓЃЌБШШчfeedСїГЁОАжаОГЃГіЯжЕФвЛИіcaseЃЌЯыДгЧЇЭђЕФЪ§ОнжаИљОнБъЬтВщГіРДЫљгаДјгаЁАЭѕепШйвЋЁБЕФФкШнВЂЯТЯпЁЃЮФБОЫбЫїЕФжЇГжЩЯЃЌmysqlгаЕуСІВЛДгаФ
2.4ЙЙНЈвЕЮёЛКДц
ЙЋПЊПЮВЩгУЕФЪЧЫЋВуЛКДцЃЌЩшМЦЫМТЗВЮПМmysqlЕФЛиБэЃЌШчЭМ 
вЛМЖЛКДцЪЧвЕЮёЬиеїЛКДцЃЌБШШчЗжРрЙиЯЕЁЃЖўМЖЛКДцЪЧЛљДЁЪ§ОнЕФЛКДцЃЌБШШчПЮГЬЯъЧщЁЃ ОйИіР§згЃЌШШЯњПЮГЬБэAЖдгІЕФЪ§ОнгаaЃЌbЃЌcЁЃдђШШЯњПЮГЬБэAдкЛљДЁЛКДцРяОЭДцзХaЃЌbЃЌcЁЃОпЬхЦиЙтвГЛђепЛиСївГЕФЪБдйИљОнaЃЌbЃЌcШЅЕзВуЛКДцШЁЁЃетбљзіЕФКУДІЃК1.БмУтЪ§ОнВуМфЯрЛЅШпгрДцДЂЃЌЯёШШЯњПЮГЬБэAЕФДцДЂЕБШЛвВПЩвджБНгАбФкШнДцЯТРДЃЌЕЋЪЧШпгрСПЬЋДѓЃЌДцДЂРћгУТЪЬЋЕЭЃЛ2.ШпгрдкЪ§ОнЭЌВНЕФЪБКђЪЧКмЭДПрЕФЃЌЪзЯШШчКЮБЃжЄmysqlКЭredisЕФвЛжТадЃЌЦфДЮЛЙвЊБЃжЄЖрИіЛКДцВуЕФЪ§ОнвЛжТЁЃБШШчвЛИіПЮГЬДгAИФГЩBЃЌдђжЛашвЊИФЕзВуЪ§ОнВуЛКДц
СэЭтЃЌЙЋПЊПЮЕФdbКЭredisЭЌВНГЁОАгаСНжжЃК
update db + del redis + redisМгЙ§ЦкЬдЬВпТд + query ЛиаДЛКДц
update db + ЯћЯЂЖгСа + вьВНЬдЬ|ИќаТ
ДгТпМЩЯетСНИіГЁОАЖМгаbad caseЃЌВЂЗЧНтОіdb-redisвЛжТадЕФзюМбЗНАИЁЃЕЋЪЧеыЖдвЛжТадЕФЬжТлЪЧвЊНсКЯвЛжТадЕФвЕЮёЪБМфжсШЅЬжТлЕФЃЌБШШчгаОјЖдвЛжТЁЂЗжжгМЖБ№вЛжТЃЌаЁЪБМЖБ№вЛжТЃЌЬьМЖБ№вЛжТЕШЕШЁЃЯёвјааШШЕуеЫЛЇЮЪЬтЃЌПЯЖЈвЊЪЧвЊЧѓЭъШЋвЛжТЃЌЖјгУЛЇааЮЊЪ§ОнЕШОЭЪЧШѕвЛжТСЫЁЃЙЋПЊПЮЕФвЕЮёГЁОАЖдгквЛжТадЕФвЊЧѓУЛгаФЧУДИпЁЃБШШчвЛИіpgcзїепдкЦфеЫЛЇЯТаТЗЂВМСЫвЛЬѕЪ§ОнЃЌФЧУДдкappПЩМћетЬѕЪ§ОнЕФЪБМфВюЪЧЗжжгМЖБ№ЕФЖјЗЧУыЩѕжСКСУыМЖБ№вЛжТЭЌВНЕФЁЃдйБШШчвЛИіеЫКХЮЌЖШЕФЭГМЦЃЌБШШчЙизЂШЫЪ§ЃЌФкШнЪ§ЩѕжСдЪаэЕНаЁЪБМЖБ№ЁЃЖјдкЩшМЦЛКДцkeyЙ§ЦкЪБМфЕФЪБКђЃЌЛсПМТЧЕНетвЛЕуЃЌБШШчеЫКХЮЌЖШЕФkeyвЛИіаЁЪБПЩФмОЭЛсЬдЬЕє
2.5ДцДЂЗўЮёбЁаЭ
mongo
жЛinsertЁЂselectЃЌПЩНЕМЖЃЌПЩЪЇАмЃЌПЩЖЊЪЇ
ddb ДцДЂДѓБэЁЂОодіСПЪ§ОнЃЌвдМАДЙжБВ№ЗжЕФДѓзжЖЮЃЌБШШчЮФеТЮФБО
mysql ЛљБОЙиЯЕаЭвЕЮёЪ§Он redis ЫЋВуЛКДцЩшМЦЃЌДцДЂКЫаФЦиЙтЪ§ОнЃЌtopЃЌhotЪ§Он ES
вЕЮёЬиеїЮФБОЪ§Он
2.6ЗўЮёЛЏВ№ЗжКЭИКдиОљКт
ШчЭМ1ЃЌЭМ5ЫљЪОЃЌЙЋПЊПЮећЬхФкШнМмЙЙЕїгУСДТЗЗЧГЃГЄЃЌЖјЧвДгФкШнв§ШыЃЌЕНЪ§ОнГжОУЛЏЃЌЕНЛКДцжжжВЃЌзюКѓЕНЭЦМіФЃаЭЃЌФЃПщЙІФмЯрЖдЖРСЂЃЌЫљвддкЩшМЦЩЯИљОнИїЙІФмЖРСЂГЩзгЯЕЭГЃЌЭЈЙ§жаМфМўЯрЛЅГадиЩЯЯТгЮЗўЮёЁЃСэЭтЃЌгЩгкИїзгЯЕЭГФкВПгаКмЖрЫВМфСїСПГхЛїЕФвЕЮёГЁОАЁЃБШШчЃЌдкЬиЪтЪБЦкЙњМвЙуЕчзмОжвЊЧѓвЊЯТМмЫљгаАќЩцеўФкШнЁЃМйЩш100ИіеЫКХЃЌУПИіеЫКХЯТга1000ЬѕФкШнЁЃФЧОЭвЊЧѓ10wЕФЪ§ОнСПвЊзіЕНЛКДцЯТЯпЁЂdbЯТЯпЁЂesЯТЯпЁЂЫбЫїЫїв§ЯТЯпЁЂЭЦМіФЃаЭЯТЯпЁЂCЖЫгУЛЇааЮЊЪ§ОнЯТЯпЁЂеЫКХФкШнЭЈЕРЯТЯпЕШЃЌвЛЬѕЪ§ОнЕФЯТЯпПЩФмЩцМАЕН10БэЃЌ10wЕФЪ§ОнСПвђЮЊЙібЉЧђаЇгІЛсв§Ц№ЯТгЮqpsБЉдіЃЌеце§ТфдкdbЩЯЕФqpsбЙСІЛсБЛЗХДѓМИБЖЩѕжСМИЪЎБЖЃЌдьГЩСїСПМтЗхЁЃЫљвдЃЌЩшМЦЩЯдкзіКУЗўЮёВ№ЗжЕФЭЌЪБЃЌвВвЊПМТЧЕНвђЮЊЗжВМЪНЯЕЭГв§ШыЕФЯТгЮСїСПБЉдіЖјГхПхdbЕФЗчЯеЃЌФПЧАЙЋПЊПЮеыЖдетжжвЕЮёГЁОАгаСНжжЫМТЗЃК
dbСїСПЖбЛ§ЃЌЯТгЮвджїЖЏРЕФФЃЪНзіжмЦкадВпТдЯћЗбЃЌетбљdbгаЁАДЯЂЁБЕФЪБМфЃЌВЛжСгкДђЫРЁЃШБЕуОЭЪЧгаЕуТ§ЃЌdbСїСПЯћЛЏЪБМфОУ
РЉШнЁЂдіМгdbЪЕР§ШЅгВПИdbСїСП
ЃЈШ§ЃЉИіадЛЏФкШнЯТЗЂ
ЧАУцМИВНЦфЪЕЪЧАбдДЪ§ОнОЙ§ИїжжДІРэЃЌзюКѓЗХЕНФГИіbucketРяЁЃЕЋЪЧдкAPPРяЃЌШчКЮзіКУгУЛЇЮЌЖШЕФИіадЛЏЭЦМіФиЃПЛЛОфЛАЫЕЃЌШчКЮАбгУЛЇОЋзМЕФЭЖЗХЕНФГИіbucketФиЃП
ЙЋПЊПЮВЩгУЕФЪЧpullФЃаЭЁЃШчЭМ11 
ЭЌЪБЙЋПЊПЮетБпеыЖдетИіФЃаЭИњвЕЮёзіСЫвЛаЉЬљКЯЁЃ
ФкШнЮЌЖШЩЯДђЩЂЕФИќЯИЃЌБШШчЧАЮФЬсЕНЕФbucketзуЙЛЖрЃЌВЩМЏЯюИќЯИЃЌФЃаЭЗжЮіЕФзМШЗЖШЛсИќИп
в§ШыЁАЕШМЖГиЁБЕФИХФюЃЌБЃжЄИіадЛЏЭЦМіФЃаЭЕФРфЦєЖЏЪБЃЈМДЮогУЛЇааЮЊЪ§ОнЃЉКЭЭЦМіЗўЮёЙЪеЯЪБЃЈЭМ11жагХЛЏЭЦМіФЃаЭЭЃЗўЪБЃЉЃЌжБНгШЁзюгХЪ§ОнЃЌзіКУЗўЮёЖЕЕз
в§ШыгУЛЇжїЖЏЗДРЁЙІФмЁЃвЛАуЖјбдappЖМЛсгагУЛЇааЮЊВЩМЏЙІФмЃЌЭЈЙ§appТёЕуЕШБЛЖЏЩЯДЋЕНгУЛЇааЮЊЗўЮёРяЁЃЙЋПЊПЮетБпГ§СЫБЛЖЏЕФЩЯДЋЗДРЁЃЌЛЙв§ШыСЫгУЛЇжїЖЏЗДРЁЃЌБШШчдкФГвЛЦСРяЫЂЕНСЫвЛИіbad
caseЃЌгУЛЇПЩвддкappЩЯбЁдёжїЖЏЗДРЁ
МмЙЙЭДЕу
ФкШнЭЌВНЕФЭДЕуЁЃДгМмЙЙЭМЩЯФмЙЛПДЕНЙЋПЊПЮЕФЪ§ОнСїзЊТЗОЖЪЧБШНЯГЄЕФЃЌЖјФкШндкУПвЛИіСїзЊНкЕуЖМгаПЩФмБЛаоИФзДЬЌЃЌгШЦфЪЧФкШнИќаТЛђепЩОГ§ЯћЯЂШчЙћдкФГИіНкЕуЖЊСЫЃЌдйевЛиРДБШНЯТщЗГ
ДгФкШнДцДЂНсЙЙЩЯЃЌФмЙЛПДЕНЙЋПЊПЮЕФЕзВуЪ§ОнДцДЂЪЧБШНЯРыЩЂЕФЁЃетжжРыЩЂЕФЩшМЦБОвтЪЧОЁСПМѕЩйЕзВуЪ§ОнЕФШпгрЃЌЕЋЪЧШБЕувВКмУїЯдЃЌЯывЊвЛЬѕЭъећЕФФкШнЪ§ОнашвЊСЊЖреХБэВщбЏЃЌгШЦфЕБЪ§ОнСПЩЯШЅКѓЃЌВщбЏадФмЛсж№ВНЯТНЕЁЃгШЦфЪЧЩцМАИпИДдгЖШЕФХХађЗжвГЪБЃЌетИіШБЕугШЦфУїЯд
вЕЮёЬхСПЩЯШЅКѓЃЌвЛАуЖМЛсПМТЧЕНЮЂЗўЮёЕФВ№ЗжЁЃЖјЮвУЧвЛАуВ№ЖРСЂЗўЮёЕФЪБКђЃЌвВЪЧАбвЛРрвЕЮёЪеСВЕНвЛЦ№ЁЃАДееФПЧАЕФМмЙЙВ№ЗўЮёЃЌгаЬЋЖрЖРСЂЕФserviceЁЃServiceЙ§ЖрЪЦБиЛсЕМжТЕїгУСДТЗЙ§ГЄЃЌв§Ц№КмИпЕФдЫЮЌКЭЮЌЛЄГЩБОЁЃ
змНс
ЛљДЁвЕЮёМмЙЙЕФдЫЮЌЪЧвЛИіГжајбнНјЕФЙ§ГЬЃЌАбвЛИіГЩЪьЕФММЪѕМмЙЙИњвЕЮёзіЬљКЯЃЌВЛФмЩњАсгВЬзЃЌашвЊЖдвЕЮёЬиеїгаБШНЯЩюЕФРэНтЁЃИќживЊЕФЪЧвЕЮёМмЙЙВЂЗЧвЛѕэЖјОЭЃЌАцБОдкВЛЖЯЕќДњЃЌММЪѕдкВЛЖЯИќаТЃЌММЪѕеЛгывЕЮёЬхЯЕЕФНсКЯЕувВвЊВЛЖЯЕїећЁЃгРдЖУЛгазюКУЕФМмЙЙЃЌжЛгазюЪЪКЯвЕЮёЕФМмЙЙ
|








