| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫFeedСїЯЕЭГЕФећЬхПђМмЃЌжївЊЪЧВњЦЗЖЈвхЁЂЭЌВНЁЂДцДЂЁЂдЊЪ§ОнЁЂЦРТлЁЂдоЁЂХХађКЭЫбЫїЕШФкШнЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
РДздгкВЉПЭдА,гЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
МђНщ
ВюВЛЖрЪЎФъЧАЃЌЫцзХЙІФмЛњЕФЬдЬКЭжЧФмЛњЕФЦеМАЃЌЛЅСЊЭјПЊЪМНјШывЦЖЏЛЅСЊЭјЪБДњЃЌзюОпДњБэадЕФВњЦЗОЭЪЧЮЂВЉЁЂЮЂаХЃЌвдМАКѓРДЕФНёШеЭЗЬѕЁЂПьЪжЕШЁЃетаЉвЦЖЏЛЏСЊЭјЪБДњЕФаТВњЦЗдкЙ§ШЅМИФъМфНшзХжЧФмЪжЛњЕФЗчИпЫйГЩГЄЁЃ
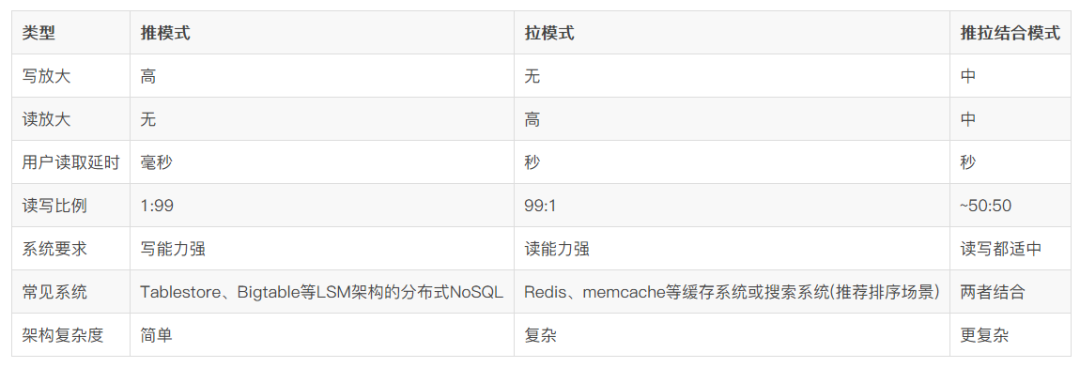
етаЉВњЦЗЖМЪЧFeedСїРраЭВњЦЗЃЌгЩгкFeedСївЛАуЪЧАДееЪБМфЁАДгЩЯЭљЯТСїЖЏЁБЃЌЗЧГЃЪЪКЯдквЦЖЏЩшБИЖЫфЏРРЃЌзюжеетвЛРргІгУОЭЭбгБЖјГіЃЌбИЫйЧРеМСЫЩЯвЛДњВњЦЗЕФЪаГЁПеМфЁЃ
FeedСїЪЧFeed + СїЃЌFeedЕФБОвтЪЧЫЧСЯЃЌFeedСїЕФБОвтОЭЪЧгаШЫвЛжБдкЭљвЛИіЕиЗНЭЖЕнаТЯЪЕФЫЧСЯЃЌШчЙћашвЊЫЧСЯЃЌжЛашвЊЖЂзХЭЖЕнЕуОЭПЩвдСЫЃЌетбљОЭФмдДдДВЛЖЯЛёШЁЕНаТЯЪЕФЫЧСЯЁЃдкаХЯЂбЇРяУцЃЌFeedЦфЪЕЪЧвЛИіаХЯЂЕЅдЊЃЌБШШчвЛЬѕХѓгбШІзДЬЌЁЂвЛЬѕЮЂВЉЁЂвЛЬѕзЩбЏЛђвЛЬѕЖЬЪгЦЕЕШЃЌЫљвдFeedСїОЭЪЧВЛЭЃИќаТЕФаХЯЂЕЅдЊЃЌжЛвЊЙизЂФГаЉЗЂВМепОЭФмЛёШЁЕНдДдДВЛЖЯЕФаТЯЪаХЯЂЃЌЮвУЧЕФгУЛЇвВОЭПЩвддквЦЖЏЩшБИЩЯж№ЬѕШЅфЏРРетаЉаХЯЂЕЅдЊЁЃ
ЕБЧАзюСїааЕФFeedСїВњЦЗгаЮЂВЉЁЂЮЂаХХѓгбШІЁЂЭЗЬѕЕФзЪбЖЭЦМіЁЂПьЪжЖЖвєЕФЪгЦЕЭЦМіЕШЃЌЛЙгавЛаЉБфжжЃЌБШШчЫНаХЁЂЭЈжЊЕШЃЌетаЉЯЕЭГЖМЪЧFeedСїЯЕЭГЃЌНгЯТРДЮвУЧЛсНщЩмШчКЮЩшМЦвЛИіFeedСїЯЕЭГМмЙЙЁЃ
FeedСїЯЕЭГЬиЕу
FeedСїБОжЪЩЯЪЧвЛИіЪ§ОнСїЃЌЪЧНЋ ЁАNИіЗЂВМепЕФаХЯЂЕЅдЊЁБ ЭЈЙ§ ЁАЙизЂЙиЯЕЁБ ДЋЫЭИј ЁАMИіНгЪеепЁБЁЃ
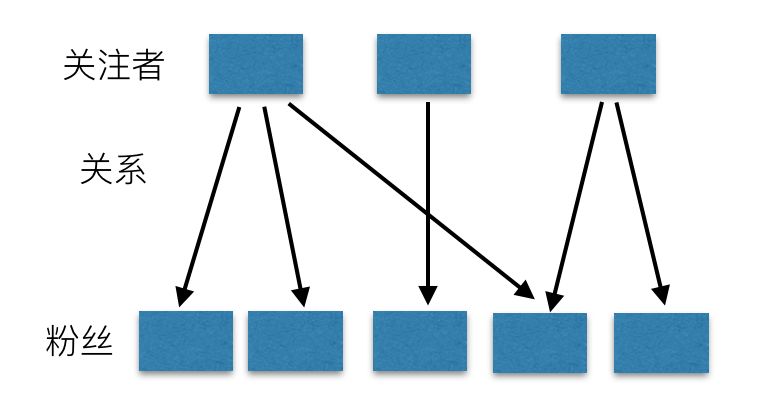
FeedСїЯЕЭГЪЧвЛИіЪ§ОнСїЯЕЭГЃЌЫљвдЮвУЧКЫаФвЊПДЪ§ОнЁЃДгЪ§ОнВуУцПДЃЌЪ§ОнЗжЮЊШ§РрЃЌЗжБ№ЪЧЃК
ЗЂВМепЕФЪ§ОнЃКЗЂВМепВњЩњЪ§ОнЃЌШЛКѓЪ§ОнашвЊАДееЗЂВМепзщжЏЃЌашвЊИљОнЗЂВМепВщЕНЫљгаЪ§ОнЃЌБШШчЮЂВЉЕФИіШЫвГУцЁЂХѓгбШІЕФИіШЫЯрВсЕШЁЃ
ЙизЂЙиЯЕЃКЯЕЭГжаИіЬхМфЕФЙиЯЕЃЌЮЂВЉжаЪЧЙизЂЃЌЪЧЕЅЯђСїЃЌХѓгбШІЪЧКУгбЃЌЪЧЫЋЯђСїЁЃВЛЙмЪЧЕЅЯђЛЙЪЧЫЋЯђЃЌЕБЗЂВМепЗЂВМвЛЬѕаХЯЂЪБЃЌИУЬѕаХЯЂЕФСїЖЏгРдЖЪЧЕЅЯђЕФЁЃ
НгЪеепЕФЪ§ОнЃКДгВЛЭЌЗЂВМепФЧРяЛёШЁЕНЕФЪ§ОнЃЌШЛКѓЭЈЙ§ФГжжЫГађЃЈвЛАуЮЊЪБМфЃЉзщжЏдквЛЦ№ЃЌБШШчЮЂВЉЕФЪзвГЁЂХѓгбШІЪзвГЕШЁЃетаЉЪ§ОнОпгаЪБМфШШЖШЪєадЃЌдНаТЕФЪ§ОндНгаМлжЕЃЌдНаТЕФЪ§ОнОЭвЊХХдкзюЧАУцЁЃ
еыЖдетШ§РрЪ§ОнЃЌЮвУЧПЩвдгаШчЯТЖЈвхЃК
ДцДЂПтЃКДцДЂЗЂВМепЕФЪ§ОнЃЌгРОУБЃДцЁЃ
ЙизЂБэЃКгУЛЇЙиЯЕБэЃЌгРОУБЃДцЁЃ
ЭЌВНПтЃКДцДЂНгЪеепЕФЪБМфШШЖШЪ§ОнЃЌжЛашвЊБЃСєзюНќвЛЖЮЪБМфЕФЪ§ОнМДПЩЁЃ
ЩшМЦFeedСїЯЕЭГЪБзюКЫаФЕФЪЧШЗЖЈЧхГўВњЦЗВуУцЕФЖЈвхЃЌашвЊПМТЧЕФвђЫиАќРЈЃК
ВњЦЗгУЛЇЙцФЃЃКгУЛЇЙцФЃдкЪЎЭђЁЂЧЇЭђЁЂЪЎвкМЖЪБЃЌЩшМЦФбЖШКЭВржиЕуЛсВЛЭЌЁЃ
ЙизЂЙиЯЕЃЈЕЅЯђЁЂЫЋаДЃЉЃКШчЙћЪЧЫЋЯђЃЌФЧУДОЭВЛЛсгаДѓVЃЌЗёдђЛсгаДѓVДцдкЁЃ
ЩЯЪіЪЧбЁдёЪ§ОнДцДЂЯЕЭГзюКЫаФЕФМИИіПМТЧЕуЃЌГ§ДЫжЎЭтЃЌЛЙгавЛаЉашвЊПМТЧЕФЃК
ШчКЮЪЕЯжMetaКЭFeedФкШнЫбЫїЃП
ЫфШЛFeedСїЯЕЭГБОЩэПЩвдВЛашвЊЫбЫїЃЌЕЋЪЧвЛИіFeedСїВњЦЗБиаывЊгаЫбЫїЃЌЗёдђаХЯЂЗЂЯжФбЖШЛсМгДѓЃЌгУЛЇСєДцТЪЛсДѓЗљЯТНЕЁЃ
FeedСїЕФЫГађЪЧЪБМфЛЙЪЧЦфЫћЗжЪ§ЃЌБШШчИіШЫЕФЯВКУГЬЖШЃП
ЫЋЯђЙиЯЕЪБгЩгкЙиЯЕКмНєУмЃЌвЛЖЈЪЧАДЪБМфХХађЃЌОЭЫувЛИіЙиЯЕКмНєУмЕФШЫЗЂСЫвЛЬѕПеЯћЯЂЛђепЕЭМлжЕЯћЯЂЃЌФЧЮвУЧвВЛсашвЊЙизЂСЫНтЕФЁЃ
ЕЅЯђЙиЯЕЪБЃЌФЧУДПЩФмОЭЛсДцдкДѓVЃЌДѓVЕФЗлЫПЪ§СПРэТлМЋЯоОЭЪЧећИіЯЕЭГЕФгУЛЇЪ§ЃЌгавЛаЉВњЦЗЛсШУЫљгагУЛЇЖМФЌШЯЙизЂВњЦЗИКд№ШЫЃЌетжжВњЦЗжаЃЌИУИКд№ШЫОЭЪЧзюДѓЕФДѓVЃЌЗлЫПЪ§ОЭЪЧгУЛЇЙцФЃЁЃ
НгЯТРДЃЌЮвУЧПДПДећИіFeedСїЯЕЭГШчКЮЩшМЦЁЃ
FeedСїЯЕЭГЩшМЦ
ЩЯвЛНкЃЌЮвУЧЬсЧАЫМПМСЫFeedСїЯЕЭГЕФМИИіЙиМќЕуЃЌНгЯТРДЃЌдкетвЛНкЃЌЮвУЧздЖЅЯђЯТРДЩшМЦвЛИіFeedСїЯЕЭГЁЃ
1. ВњЦЗЖЈвх
ЕквЛВНЃЌЮвУЧЪзЯШашвЊЖЈвхВњЦЗЃЌЮвУЧвЊзіЕФВњЦЗЪЧФФвЛжжРраЭЃЌГЃМћЕФРраЭгаЃК
ЮЂВЉРр
ХѓгбШІРр
ЖЖвєРр
ЫНаХРр
НгзХЃЌдйЯъЯИПДвЛЯТетМИРрВњЦЗЕФвьЭЌЃК

ЩЯЪіЖдБШжаЃЌжЛЖдБШИїРрВњЦЗзюКЫаФЁЂЛђепзюИљБОЬиЕуЃЌЦфЫћДЮвЊЕФВЛПМТЧЁЃБШШчЮЂВЉжаЛЅЯрЙизЂКѓОЭЪЧЫЋЯђЙизЂСЫЃЌЕЋЪЧетИіВЛЪЧЮЂВЉЕФСЂУќжЎБОЃЌжЛЪЧВЙГфЃЌЮоЗЈКГЖЏИљБОЁЃ
ДгЩЯУцБэИёПЩвдПДГіРДЃЌжївЊЗжЮЊСНжжЧјЗжЃК
ЙизЂЙиЯЕЪЧЕЅЯђЛЙЪЧЫЋЯђЃК
ШчЙћЪЧЕЅЯђЃЌФЧУДПЩФмОЭЛсДцдкДѓVаЇгІЃЌЭЌЪБЪБаЇадПЩвдЕЭвЛаЉЃЌБШШчЕНЗжжгМЖБ№ЃЛ
ШчЙћЪЧЫЋЯђЃЌФЧОЭЪЧКУгбЃЌКУгбЕФЪ§СПгаЯоЃЌФЧУДОЭВЛЛсгаДѓVЃЌвђЮЊУПИіШЫЕФОЋСІгаЯоЃЌЫћВЛПЩФмжїЖЏМгМИЧЇЭђЕФКУгбЃЌетЪБКђвђЮЊЙиЯЕИќОЋУмЃЌЪБаЇадвЊЧѓЛсИќИпЃЌашвЊЖМУыМЖБ№ЁЃ
ХХађЪЧЪБМфЛЙЪЧЭЦМіЃК
гУЛЇЖдfeedСїзюШнвзНгЪмЕФОЭЪЧЪБМфЃЌФПЧАДѓВПЗжЖМЪЧЪБМфЁЃ
ЕЋЪЧгавЛаЉГЁОАЃЌЪЧДгШЋЭјЪ§ОнРяУцИљОнгУЛЇЕФЯВКУИјгУЛЇЭЦМіКЭгУЛЇЯВКУЖШзюЦЅХфЕФФкШнЃЌетИіЪБКђОЭашвЊгУЭЦМіСЫЃЌетжжЧщПівЛАувВЛсЪЁТдЕєЙизЂСЫЃЌЯрЖдгкЙизЂСЫШЋЭјЫљгагУЛЇЃЌБШШчЖЖвєЁЂЭЗЬѕЕШЁЃ
ШЗЖЈСЫВњЦЗРраЭКѓЃЌЛЙашвЊМЬајШЗЖЈЕФЪЧЯЕЭГЩшМЦФПБъЃКашвЊжЇГжЕФзюДѓгУЛЇЪ§ЪЧЖрЩйЃПЪЎЭђЁЂАйЭђЁЂЧЇЭђЛЙЪЧвкЃП
гУЛЇЪ§КмЩйЕФЪБКђЃЌОЭБШНЯМђЕЅЃЌетРяЮвУЧжївЊПМТЧ вкМЖгУЛЇ ЕФЧщПіЃЌвђЮЊШчЙћЯЕЭГФмжЇГжвкМЖЃЌФЧУДЦфЫћСПМЖвВФмжЇГжЁЃЮЊСЫжЇГжвкМЖЙцФЃЕФгУЛЇЃЌжївЊзгЯЕЭГбЁаЭЪБашвЊПМТЧЫЎЦНРЉеЙФмСІвдМАвЛаЉзгЯЕЭГЕФПЩгУадКЭПЩППадСЫЃЌвђЮЊЯЕЭГДѓСЫКѓЃЌШЮКЮвЛИізгЯЕЭГЕФВЛЮШЖЈЖМКмШнвзВЈМАећИіЯЕЭГЁЃ
2. ДцДЂ
ЮвУЧЯШРДПДПДзюживЊЕФДцДЂЃЌВЛЙмЪЧФФжжЭЌВНФЃЪНЃЌдкДцДЂЩЯЖМЪЧвЛбљЕФЃЌЮвУЧЖЈвхгУЛЇЯћЯЂЕФДцДЂЮЊДцДЂПтЁЃДцДЂПтжївЊТњзуШ§ИіашЧѓЃК
ПЩППДцДЂгУЛЇЗЂЫЭЕФЯћЯЂЃЌВЛФмЖЊЪЇЁЃЗёдђОЭевВЛЕНздМКдјОЗЂВМЕНХѓгбШІзДЬЌСЫЁЃ
ЖСШЁФГИіШЫЗЂВМЙ§ЕФЫљгаЯћЯЂЃЌБШШчИіШЫжївГЕШЁЃ
Ъ§ОнгРОУБЃДцЁЃ
ЫљвдЃЌДцДЂПтзюживЊЕФЬиеїОЭЪЧСНЕуЃК
Ъ§ОнПЩППЁЂВЛЖЊЪЇЁЃ
гЩгкЪ§ОнвЊгРОУБЃДцЃЌЪ§ОнЛсвЛжБдіГЄЃЌЫљвдвЊвзгкЫЎЦНРЉеЙЁЃ
злЩЯЃЌПЩвдбЁЮЊДцДЂПтЕФЯЕЭГДѓИХгаСНРрЃК
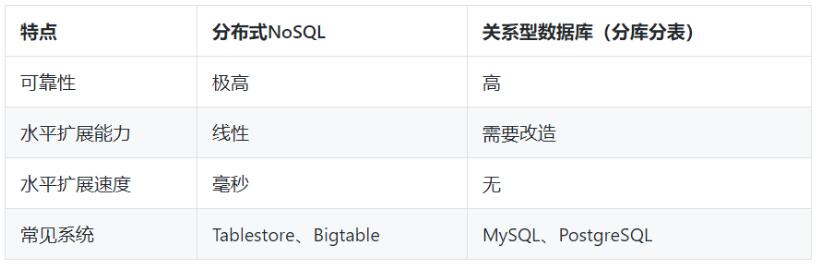
ЖдгкПЩППадЃЌЗжВМЪНNoSQLЕФПЩППадвЊИпгкЙиЯЕаЭЪ§ОнПтЃЌетИіПЩФмгаЮЅКмЖрШЫЕФШЯжЊЁЃжївЊЪЧЙиЯЕаЭЪ§ОнПтЗЂеЙКмГЄЪБМфСЫЃЌЧвКмГЩЪьСЫЃЌЪ§ОнЗХдкЩЯУцДѓМвЗХаФЃЌЖјЗжВМЪНNoSQLЪ§ОнПтЗЂеЙЭэЃЌЪЙгУЕФВЂВЛЖрЃЌВЛЬЋаХШЮЁЃЕЋЪЧЃЌЗжВМЪНNoSQLашвЊДцДЂЕФЪ§ОнСПИќЖрЃЌЖдЪ§ОнПЩППадЕФвЊЧѓвВМгбЯИёЃЌЫљвдвЛАуЖМЪЧДцДЂШ§ЗнЃЌПЩППадЛсИќИпЁЃФПЧАдквЛаЉдЦГЇЩЬжаЕФЙиЯЕаЭЪ§ОнПтвђЮЊВЩгУСЫКЭЗжВМЪНNoSQLРрЫЦЕФЗНЪНЃЌЫљвдПЩППадвВЕУЕНСЫДѓЗљЬсИпЁЃ
ЫЎЦНРЉеЙФмСІЃКЖдгкЗжВМЪНNoSQLЪ§ОнПтЃЌЪ§ОнЬьШЛЪЧЗжВМдкЖрЬЈЛњЦїЩЯЃЌЕБвЛЬЈЛњЦїЩЯЕФЪ§ОнСПдіДѓКѓЃЌПЩвдЭЈЙ§здЖЏЗжСбСНВПЗжЃЌШЛКѓНЋЦфжавЛАыЕФЪ§ОнЧЈвЦЕНСэвЛЬЈЛњЦїЩЯШЅЃЌетбљОЭзіЕНСЫЯпадРЉеЙЁЃЖјЙиЯЕаЭЪ§ОнПташвЊдкРЉШнЪБдйДЮЗжПтЗжБэЁЃ
ЫљвдЃЌНсТлЪЧЃК
ШчЙћЪЧздНЈЯЕЭГЃЌЧвВЛОпБИЗжВМЪНNoSQLЪ§ОнПтдЫЮЌФмСІЃЌЧвЪ§ОнЙцФЃВЛДѓЃЌФЧУДПЩвдЪЙгУMySQLЃЌетбљПЩвдГХвЛЖЮЪБМфЁЃ
ШчЙћЪЧЛљгкдЦЗўЮёЃЌФЧУДОЭгУЗжВМЪНNoSQLЃЌБШШчTablestoreЛђBigtableЁЃ
ШчЙћЪ§ОнЙцФЃКмДѓЃЌФЧУДвВвЊгУЗжВМЪНNoSQLЃЌЗёдђОЭЪЧзпЩЯвЛЬѕВЛЙщТЗЁЃ
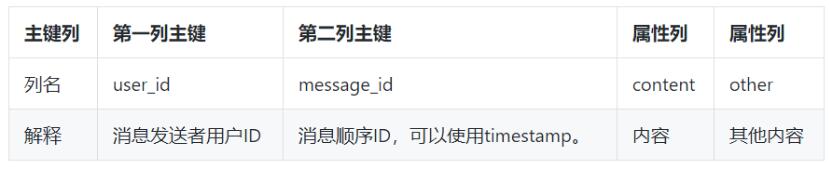
ШчЙћЪЙгУTablestoreЃЌФЧУДДцДЂПтБэЩшМЦНсЙЙШчЯТЃК
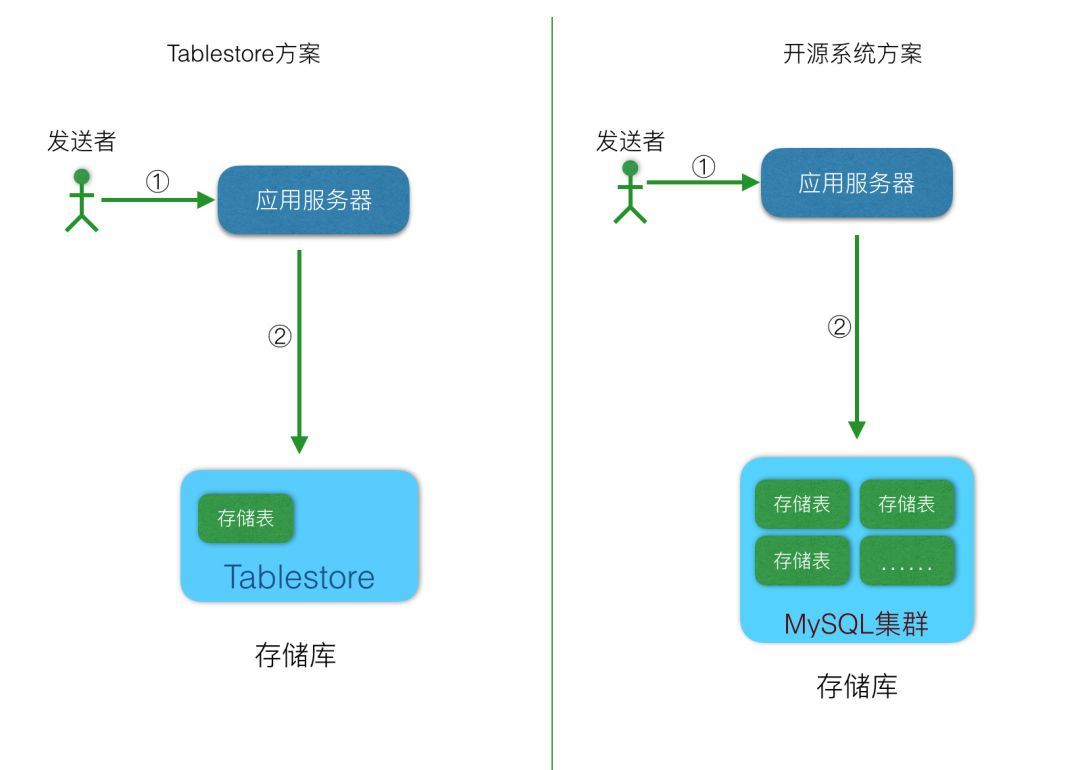
ЕНДЫЃЌЮвУЧШЗЖЈСЫДцДЂПтЕФбЁаЭЃЌФЧУДЯЕЭГМмЙЙЕФТжРЊгаСЫЃК
3. ЭЌВН
ЯЕЭГЙцФЃКЭВњЦЗРраЭЃЌвдМАДцДЂЯЕЭГШЗЖЈКѓЃЌЮвУЧПЩвдШЗЖЈЭЌВНЗНЪНЃЌГЃМћЕФЗНЪНгаШ§жжЃК
ЭЦФЃЪНЃЈвВНааДРЉЩЂЃЉЃККЭУћзжвЛбљЃЌОЭЪЧвЛжжЭЦЕФЗНЪНЃЌЗЂЫЭепЗЂЫЭСЫвЛИіЯћЯЂКѓЃЌСЂМДНЋетИіЯћЯЂЭЦЫЭИјНгЪеепЃЌЕЋЪЧНгЪеепДЫЪБВЛвЛЖЈдкЯпЃЌФЧУДОЭашвЊгавЛИіЕиЗНДцДЂетИіЪ§ОнЃЌетИіДцДЂЕФЕиЗНЮвУЧГЦЮЊЃКЭЌВНПтЁЃЭЦФЃЪНвВНааДРЉЩЂЕФдвђЪЧЃЌвЛИіЯћЯЂашвЊЗЂЫЭИіЖрИіЗлЫПЃЌФЧУДетЬѕЯћЯЂОЭЛсИДжЦЖрЗнЃЌаДЗХДѓЃЌЫљвдвВНааДРЉЩЂЁЃетжжФЃЪНЯТЃЌЖдЭЌВНПтЕФвЊЧѓОЭЪЧаДШыФмСІМЋЧПКЭЮШЖЈЁЃЖСШЁЕФЪБКђвђЮЊЯћЯЂвбОЗЂЕННгЪеепЕФЪеМўЯфСЫЃЌжЛашвЊЖСвЛДЮздМКЕФЪеМўЯфМДПЩЃЌЖСЧыЧѓЕФСПМЋаЁЃЌЫљвдЖдЖСЕФQPSашЧѓВЛДѓЁЃЙщФЩЯТЃЌЭЦФЃЪНжаЖдЭЌВНПтЕФвЊЧѓжЛгавЛИіЃКаДШыФмСІЧПЁЃ
РФЃЪНЃЈвВНаЖСРЉЩЂЃЉЃКетжжЪЧвЛжжРЕФЗНЪНЃЌЗЂЫЭепЗЂЫЭСЫвЛЬѕЯћЯЂКѓЃЌетЬѕЯћЯЂВЛЛсСЂМДЭЦЫЭИјЗлЫПЃЌЖјЪЧаДШыздМКЕФЗЂМўЯфЃЌЕБЗлЫПЩЯЯпКѓдйШЅздМКЙизЂепЕФЗЂМўЯфРяУцШЅЖСШЁЃЌвЛЬѕЯћЯЂЕФаДШыжЛгавЛДЮЃЌЕЋЪЧЖСШЁзюЖрЛсКЭЗлЫПЪ§вЛбљЃЌЖСЛсЗХДѓЃЌЫљвдвВНаЖСРЉЩЂЁЃРФЃЪНЕФЖСаДБШР§ИеКУКЭаДРЉЩЂЯрЗДЃЌФЧУДЖдЯЕЭГЕФвЊЧѓЪЧЃКЖСШЁФмСІЧПЁЃСэЭтетРяЛЙгавЛИіЮѓЧјЃЌКмЖрШЫдкзюПЊЪМЩшМЦfeedСїЯЕЭГЪБЃЌЪзЯШЯыЕНЕФЪЧРФЃЪНЃЌвђЮЊетжжКЭгУЛЇЕФЪЙгУЬхИаЪЧвЛбљЕФЃЌЕЋЪЧдкЯЕЭГЩшМЦЩЯетжжЗНЪНгаВЛЩйЭДЕуЃЌзюДѓЕФЪЧУПИіЗлЫПашвЊМЧТМздМКЩЯДЮЖСЕНСЫЙизЂепЕФФФЬѕЯћЯЂЃЌШчЙћга1000ИіЙизЂепЃЌФЧУДетИіШЫашвЊМЧТМ1000ИіЮЛжУаХЯЂЃЌетИіСПКЭЙизЂСПГЩе§БШЕФЃЌдЖБШгУЛЇЪ§вЊДѓЕФЖрЃЌетРявЊЬиБ№зЂвтЃЌЫфШЛдкВњЦЗЧАЦкЪ§ОнСПЩйЕФЪБКђетжжЗНЪНПЩвдгІИЖЃЌЕЋЪЧСПДѓСЫКѓОЭЛсЪТБЖЙІАыЃЌЕУВЛГЅЪЇЃЌЧаМЧЧаМЧЁЃ
ЭЦРНсКЯФЃЪНЃКЭЦФЃЪНдкЕЅЯђЙиЯЕжаЃЌвђЮЊДцдкДѓVЃЌФЧУДвЛЬѕЯћЯЂПЩФмЛсРЉЩЂМИАйЭђДЮЃЌЕЋЪЧетаЉгУЛЇжаПЩФмгавЛАыЖрЪЧНЉЪЌЃЌгРдЖВЛЛсЩЯЯпЃЌФЧУДОЭДцдкзЪдДРЫЗбЁЃЖјРФЃЪНЯТЃЌдкЯЕЭГМмЙЙЩЯЛсКмИДдгЃЌЭЌЪБашвЊМЧТМЕФЮЛжУаХЯЂЪЧЬьСПЃЌВЛКУНтОіЃЌгШЦфЪЧгУЛЇСПЖрСЫКѓЛсГЩЮЊЕквЛИіЙЪеЯЕуЁЃЛљгкДЫЃЌЫљвдгаСЫЭЦРНсКЯФЃЪНЃЌДѓВПЗжгУЛЇЕФЯћЯЂЖМЪЧаДРЉЩЂЃЌжЛгаДѓVЪЧЖСРЉЩЂЃЌетбљМШПижЦСЫзЪдДРЫЗбЃЌгжМѕЩйСЫЯЕЭГЩшМЦИДдгЖШЁЃЕЋЪЧећЬхЩшМЦИДдгЖШЛЙЪЧвЊБШЭЦФЃЪНИДдгЁЃ
гУЭМБэЖдБШЃК
НщЩмЭъЭЌВНФЃЪНжаЫљгаГЁОАКЭФЃЪНКѓЃЌЮвУЧЙщФЩЯТЃК
ШчЙћВњЦЗжаЪЧЫЋЯђЙиЯЕЃЌФЧУДОЭВЩгУЭЦФЃЪНЁЃ
ШчЙћВњЦЗжаЪЧЕЅЯђЙиЯЕЃЌЧвгУЛЇЪ§Щйгк1000ЭђЃЌФЧУДвВВЩгУЭЦФЃЪНЃЌзуЙЛСЫЁЃ
ШчЙћВњЦЗЪЧЕЅЯђЙиЯЕЃЌЕЅгУЛЇЪ§Дѓгк1000ЭђЃЌФЧУДВЩгУЭЦРНсКЯФЃЪНЃЌетЪБКђПЩвдДгЭЦФЃЪНбнНјЙ§РДЃЌВЛашвЊЖюЭтжиаТЭЦЗжизіЁЃ
гРдЖВЛвЊжЛгУРФЃЪНЁЃ
ШчЙћЪЧвЛИіГѕДДЦѓвЕЃЌЯШгУЭЦФЃЪНЃЌПьЫйАбЯЕЭГЩшМЦГіРДЃЌШЛКѓШУВњЦЗШЅбщжЄЁЂЕќДњЃЌЕШПЭЛЇЪ§ДѓЗљЩЯеЧЕН1000ЭђКѓЃЌдйПМТЧЩ§МЖЮЊЭЦРМЏКЯФЃЪНЁЃ
ШчЙћЪЧАДЭЦМіХХађЃЌФЧУДЪЧСэЭтЕФПМТЧСЫЃЌМмЙЙЛсЭъШЋВЛвЛбљЃЌетИіКѓУцзЈУХЮФеТНщЩмЁЃ
ШчЙћбЁдёСЫTablestoreЃЌФЧУДЭЌВНПтБэЩшМЦНсЙЙШчЯТЃК

ШЗЖЈСЫЭЌВНПтЕФМмЙЙШчЯТЃК
4. дЊЪ§Он
ЧАУцНщЩмСЫЭЌВНКЭДцДЂКѓЃЌећИіFeedСїЯЕЭГЕФЛљДЁЙІФмЭъГЩСЫЃЌЕЋЪЧЖдгквЛИіЭъећFeedСїВњЦЗЖјбдЃЌЛЙШБдЊЪ§ОнВПЗжЃЌНгЯТРДЃЌЮвУЧПДдЊЪ§ОнШчКЮДІРэЃК
FeedСїЯЕЭГжаЕФдЊЪ§ОнжївЊАќРЈЃК
гУЛЇЯъЧщКЭСаБэЁЃ
ЙизЂЛђКУгбЙиЯЕЁЃ
ЭЦЫЭsessionГиЁЃ
ЮвУЧНгЯТРДж№вЛРДПДЁЃ
4.1 гУЛЇЯъЧщКЭСаБэ
жївЊЪЧгУЛЇЕФЯъЧщЃЌАќРЈгУЛЇЕФИїжжздЖЈвхЪєадКЭЯЕЭГИНМгЕФЪєадЃЌетВПЗжЕФвЊЧѓжЛашвЊИљОнгУЛЇIDВщбЏЕНОЭПЩвдСЫЁЃ
ПЩвдВЩгУЕФЗжВМЪНNoSQLЯЕЭГЛђепЙиЯЕаЭЪ§ОнПтЖМПЩвдЁЃ
ШчЙћЪЙгУNoSQLЪ§ОнПтTablestoreЃЌФЧУДгУЛЇЯъЧщБэЩшМЦНсЙЙШчЯТЃК

4.2 ЙизЂЛђКУгбЙиЯЕ
етВПЗжЪЧДцДЂЙиЯЕЃЌВщбЏЕФЪБКђашвЊжЇГжВщбЏЙизЂСаБэЛђепЗлЫПСаБэЃЌЛђепжБНгКУгбСаБэЃЌетРяОЭашвЊИљОнЖрИіЪєадСаВщбЏашвЊЫїв§ФмСІЃЌетРяЃЌДцДЂЯЕЭГвВПЩвдВЩгУСНРрЃЌЙиЯЕаЭЁЂЗжВМЪНNoSQLЪ§ОнПтЁЃ
ШчЙћвбОгаСЫЙиЯЕаЭЪ§ОнПтСЫЃЌЧвЪ§ОнСПНЯЩйЃЌдђбЁдёЙиЯЕаЭЪ§ОнПтЃЌБШШчMySQLЕШЁЃ
ШчЙћЪ§ОнСПБШНЯДѓЃЌетИіЪБКђОЭгаСНжжбЁдёЃК
ЪЙгУОпгаЫїв§ЕФЯЕЭГЃЌБШШчдЦЩЯЕФTablestoreЃЌИќМђЕЅЃЌЭЬЭТИќИпЃЌРЉШнФмСІвВвЛВЂНтОіСЫЁЃ
ашвЊЗжВМЪНЪТЮёЃЌПЩвдВЩгУжЇГжЗжВМЪНЪТЮёЕФЯЕЭГЃЌБШШчЗжВМЪНЙиЯЕаЭЪ§ОнПтЁЃ
ШчЙћЪЙгУTablestoreЃЌФЧУДЙизЂЙиЯЕБэЩшМЦНсЙЙШчЯТЃК
TableЃКuser_relation_table
ЖрдЊЫїв§ЕФЫїв§НсЙЙЃК
ВщбЏЕФЪБКђЃК
ШчЙћашвЊВщбЏФГИіШЫЕФЗлЫПСаБэЃКЪЙгУTermQueryВщбЏЙЬЖЈuser_idЃЌЧвАДееtimestampХХађЁЃ
ШчЙћашвЊВщбЏФГИіШЫЕФЙизЂСаБэЃКЪЙгУTermQueryВщбЏЙЬЖЈfollow_user_idЃЌЧвАДееtimestampХХађЁЃ
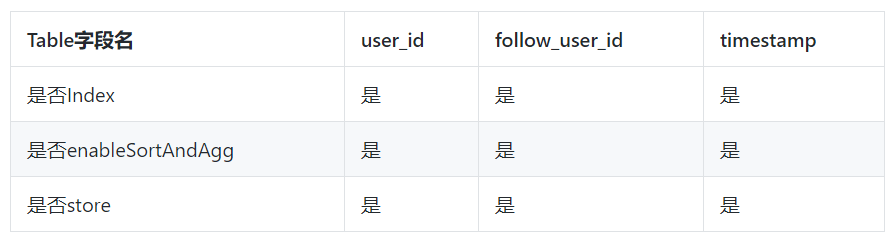
ЕБЧАЪ§ОнаДШыTableКѓЃЌашвЊ5~10УыжгбгГйКѓЛсдкЖрдЊЫїв§жаВщбЏЕНЃЌЮДРДЛсгХЛЏЕН2УывдФкЁЃ
Г§СЫЪЙгУЖрдЊЫїв§ЭтЃЌЛЙПЩвдЪЙгУGlobalIndexЁЃ
4.3 ЭЦЫЭsessionГи
ЫМПМвЛИіЮЪЬтЃЌЗЂЫЭепНЋЯћЯЂЗЂЫЭКѓЃЌНгЪеепШчКЮжЊЕРздМКгааТЯћЯЂРДСЫЃППЭЛЇЖЫжмЦкадШЅЫЂаТЃПШчЙћЪЧетбљзгЃЌФЧУДЯЕЭГЕФЖСЧыЧѓбЙСІЛсЫцзХПЭЛЇЖЫдіГЄЖјдіГЄЃЌетЪБКђОЭЛсгавЛИіЗчЯеЃЌБШШчЦНЪБЕФЩшБИдкЯпТЪЪЧ20%~30%ЃЌЭЛШЛФГЬьЦНЬЈБЌЗЂСЫвЛИіШШЕуЯћЯЂЃЌДѓСПанУпЩшБИЕЧТНЃЌетИіЪБКђОЭЛсГіЯжЁАВщбЏЗчБЉЁБЃЌвЛЯТзгОЭАбЯЕЭГДђПхСЫЃЌЫљгаЕФгУЛЇЖМВЛФмгУСЫЁЃ
НтОіетИіЮЪЬтЕФвЛИіЫМТЗЪЧЃЌдкЗўЮёЖЫЮЌЛЄвЛИіЭЦЫЭsessionГиЃЌетИіРяУцМЧТМФФаЉгУЛЇдкЯпЃЌШЛКѓЕБгУЛЇAЗЂЫЭСЫвЛЬѕЯћЯЂИјгУЛЇBКѓЃЌЗўЮёЖЫдкаДШыДцДЂПтКЭЭЌВНПтКѓЃЌдйЭЈжЊвЛЯТsessionГижаЕФгУЛЇBЕФsessionЃЌИцЫпЫћЃКФугааТЯћЯЂСЫЁЃШЛКѓsession-BдйШЅЖСЯћЯЂЃЌШЛКѓгаЯћЯЂКѓНЋЯћЯЂЭЦЫЭИјПЭЛЇЖЫЁЃЛђепгаЯћЯЂКѓИјПЭЛЇЖЫЭЦЫЭвЛЯТгаЯћЯЂСЫЃЌПЭЛЇЖЫдйШЅРЁЃ
етИіsessionГиЪЙгУдкЭЌВНжаЃЌЕЋЪЧБОжЪЛЙЪЧвЛИідЊЪ§ОнЃЌвЛАужЛашвЊДцдкгкФкДцжаМДПЩЃЌЕЋЪЧПМТЧЕНfailoverЧщПіЃЌФЧОЭашвЊГжОУЛЏЃЌетВПЗжЪ§ОнгЩгкжЛашвЊжИЖЈЕЅKeyВщбЏЃЌгУЗжВМЪНNoSQLЛђЙиЯЕаЭЪ§ОнПтЖМПЩвдЃЌвЛАуИДгУЕБЧАЕФЯЕЭГМДПЩЁЃ
ШчЙћЪЙгУTablestoreЃЌФЧУДsessionБэЩшМЦНсЙЙШчЯТЃК

5. ЦРТл
Г§СЫЫНаХРраЭЭтЃЌЦфЫћЕФfeedСїРраЭжаЃЌЖМгаЦРТлЙІФмЃЌЦРТлЕФЪєадКЭДцДЂПтВюВЛЖрЃЌЕЋЪЧЖрСЫвЛВуЙиЯЕЃКБЛЦРТлЕФЯћЯЂЃЌЫљвджЛвЊНЋЦРТлАДееБЛБЛЦРТлЯћЯЂЗжзщзщжЏМДПЩЃЌШЛКѓВщбЏЪБвВЪЧвЛИіЗЖЮЇВщбЏОЭааЁЃетжжВщбЏЗНЪНКмМђЕЅЃЌгУВЛЕНЙиЯЕаЭЪ§ОнПтжаИДдгЕФЪТЮёЁЂjoinЕШЙІФмЃЌКмЪЪКЯгУЗжВМЪНNoSQLЪ§ОнПтРДДцДЂЁЃ
ЫљвдЃЌвЛАуЕФбЁдёЗНЪНОЭЪЧЃК
ШчЙћЯЕЭГжавбОгаСЫЗжВМЪНNoSQLЪ§ОнПтЃЌБШШчTablestoreЁЂBigtableЕШЃЌФЧУДжБНггУетаЉМДПЩЁЃ
ШчЙћУЛгаЩЯЪіЯЕЭГЃЌФЧУДШчЙћгаMySQLЕШЙиЯЕаЭЪ§ОнПтЃЌФЧОЭбЁЙиЯЕаЭЪ§ОнПтМДПЩЁЃ
ШчЙћбЁдёСЫTablestoreЃЌФЧУДЁАЦРТлБэЁБЩшМЦНсЙЙШчЯТЃК

ШчЙћашвЊЫбЫїЦРТлФкШнЃЌФЧУДЖдетеХБэНЈСЂЖрдЊЫїв§МДПЩЁЃ
6. до
зюНќМИФъЃЌЁАдоЁБЛђЁАlikeЁБЙІФмКмСїааЃЌдоЙІФмЕФЪЕЯжКЭЦРТлРрЫЦЃЌжЛЪЧБШЦРТлЩйСЫвЛИіФкШнЃЌЫљвдбЁдёЗНЪНКЭЦРТлвЛбљЁЃ
ШчЙћбЁдёСЫTablestoreЃЌФЧУДЁАдоБэЁБЩшМЦНсЙЙЭЌЦРТлБэЃЌетРяОЭВЛдйзИЪіСЫ
ЯЕЭГМмЙЙжаМгСЫдЊЪ§ОнЯЕЭГКѓЕФМмЙЙШчЯТЃК
7. ЫбЫї
ЕНДЫЃЌЮвУЧвбОНщЩмЭъСЫFeedСїЯЕЭГЕФжїЬтМмЙЙЃЌFeedСїЯЕЭГЫуЪЧЭъГЩСЫЁЃЕЋЪЧFeedСїВњЦЗЩЯЛЙЮДНсЪјЃЌЖдгкЫљгаЕФfeedСїВњЦЗЖМашвЊгаЫбЫїФмСІЃЌБШШчЯТУцГЁОАЃК
ЮЂВЉжаЕФЫбЫїгУЛЇЁЃ
ЫбЫїЮЂВЉФкШнЁЃ
ЮЂаХжаЫбЫїКУгбЕШЁЃ
етаЉФкШнЫбЫїжЛашвЊзжЗћЦЅХфЕНМДПЩЃЌВЛашвЊЗЧГЃИДдгЕФЯрЙиадЫуЗЈЃЌЫљвджЛашвЊгаФмжЇГжЗжДЪЕФМьЫїЙІФмМДПЩЃЌЫљвдвЛАугаСНжжзіЗЈЃК
ЪЙгУЫбЫїв§ЧцЃЌНЋДцДЂПтЕФФкШнКЭгУЛЇаХЯЂБэФкШнЭЦЫЭИјЫбЫїЯЕЭГЃЌЫбЫїЕФЪБКђжБНгЗУЮЪЫбЫїЯЕЭГЁЃ
ЪЙгУОпБИШЋЮФМьЫїФмСІЕФЪ§ОнПтЃЌБШШчзюаТАцЕФMySQLЁЂMongoDBЛђепTablestoreЁЃ
ЫљвдЃЌбЁдёЕФддђШчЯТЃК
ШчЙћДцДЂПтЪЙгУСЫMySQLЛђепTablestoreЃЌФЧУДжБНгбЁдёетСНИіЯЕЭГОЭПЩвдСЫЁЃ
ШчЙћећИіЯЕЭГЖМУЛЪЙгУMySQLЁЂTablestoreЃЌЧввбОЪЙгУСЫЫбЫїЯЕЭГЃЌФЧУДПЩвджБНгИДгУЫбЫїЯЕЭГЃЌЦфЫћГЁОАЖМВЛгІИУдйЖюЭтМгвЛИіЫбЫїЯЕЭГНјРДЃЌЭНЬэИДдгЖШЁЃ
ШчЙћЪЙгУTablestoreЃЌФЧУДжЛашвЊдкЯргІБэЩЯНЈСЂЖрдЊЫїв§МДПЩЃК
ШчЙћашвЊЖдгУЛЇУћжЇГжЫбЫїЃЌФЧУДашвЊЖдuser_tableНЈСЂЖрдЊЫїв§ЃЌЦфжаЕФnick_nameашвЊЪЧTextРраЭЃЌЧвЕЅзжЗжДЪЁЃ
ШчЙћашвЊЖдFeedСїФкШнжЇГжЫбЫїЃЌФЧУДашвЊЖдДцДЂПтБэЃКstore_tableНЈСЂЖрдЊЫїв§ЃЌетбљОЭФмжБНгЖдFeedСїФкШнНјааИїжжИДдгВщбЏСЫЃЌАќРЈЖрЬѕМўЩИбЁЁЂШЋЮФМьЫїЕШЁЃ
ЯЕЭГМмЙЙжаМгСЫЫбЫїЙІФмКѓЕФМмЙЙШчЯТЃК
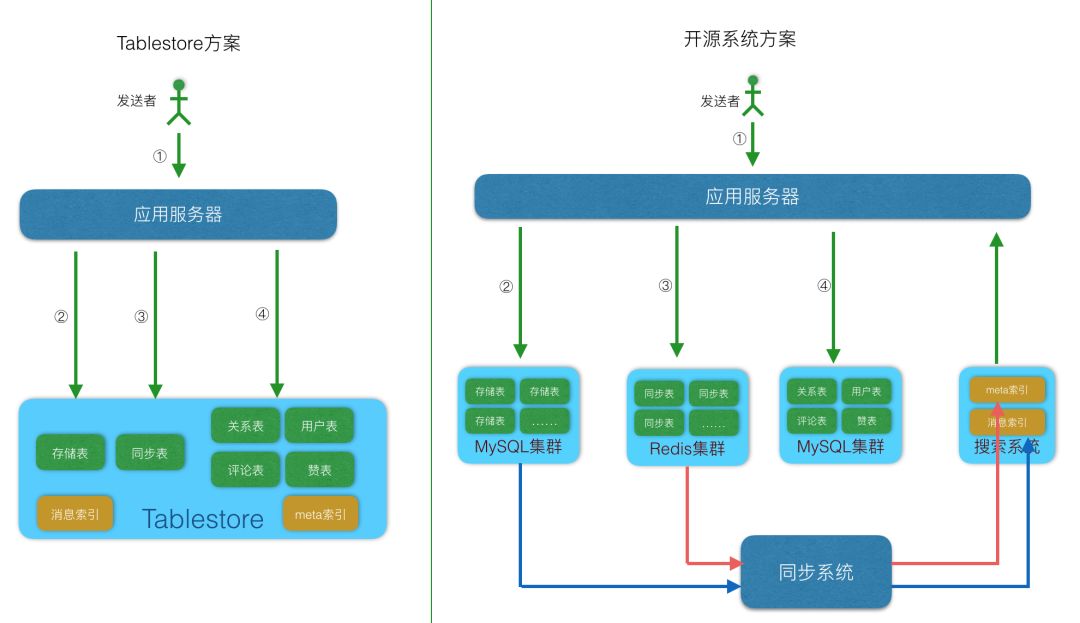
8. ХХађ
ФПЧАЕФFeedСїЯЕЭГжаЕФХХађЗНЪНгаСНжжЃЌвЛжжЪЧЪБМфЃЌвЛжжЪЧЗжЪ§ЁЃ
ЮвУЧГЃгУЕФЮЂВЉЁЂХѓгбШІЁЂЫНаХетаЉЖМЪЧЪБМфЯпРраЭЕФЃЌвђЮЊетаЉВњЦЗЖЈвхжаЃЌашвЊЮвУЧжїЖЏЙизЂФГаЉШЫКѓВХЛсПДЕНетаЉШЫЗЂБэЕФФкШнЃЌетИіЪБКђЃЌзюживЊЕФЪЧЪЕЪБадЃЌЖјВЛЪЧЗЂВМжЪСПЃЌОЭЫуЙизЂШЫЗЂВМСЫвЛЬѕРЌЛјаХЯЂЃЌЮвУЧвВЛсБЛЖЏПДЕНЁЃетжжРраЭЕФВњЦЗЪЪгУгкАДееЪБМфЯпХХађЁЃетвЛЦЊЮвУЧНщЩмЕФМмЙЙЖМЪЧЛљгкЪБМфРраЭЕФЁЃ
СэЭтвЛжжЪЧВЛашвЊЙизЂШЮКЮШЫЃЌЮвУЧФмПДЕНЕФЖМЪЧЯЕЭГЯЃЭћЮвУЧПДЕНЕФЃЌЯЕЭГдкКѓЬЈЛсЗжЮіЮвУЧЕФУПИіШЫЕФАЎКУЃЌШЛКѓИјУПИіШЫЭЦЫЭВювьЛЏЕФЁЂИїздЯВЛЖЕФФкШнЃЌетвЛжжЕФМмЙЙКЭЛљгкЪБМфЕФЭъШЋВЛвЛбљЃЌЮвУЧдкКѓајЕФЭЦМіРраЭжазЈУХНщЩмЁЃ
9. ЩОГ§FeedФкШн
дкFeedСїгІгУжагавЛИіЮЪЬтЃЌОЭЪЧШчЙћгУЛЇЩОГ§СЫжЎЧАЗЂБэЕФФкШнЃЌЯЕЭГИУШчКЮДІРэЃПвђЮЊЯЕЭГРяУцгааДРЉЩЂЃЌФЧУДЩОГ§ЕФЪБКђЪЧВЛЪЧвВвЊаДРЉЩЂвЛБщЃПетбљЕФЛАЃЌЩОГ§ОЭВЛМАЪБСЫЃЌКмФбгІЖдЗЈТЩЗЈЙцвЊЧѓЕФПьЫйЩОГ§ЁЃ
еыЖдетИіЮЪЬтЃЌЮвУЧдкжЎЧАЩшМЦЕФЪБКђЃЌЭЌВНБэжажЛгаЯћЯЂIDЃЌУЛгаЯћЯЂФкШнЃЌдкгУЛЇЖСШЁЕФЪБКђашвЊЕНДцДЂПтжаШЅЖСЯћЯЂФкШнЃЌФЧУДЮвУЧПЩвджБНгЩОГ§ДцДЂПтжаЕФетвЛЬѕЯћЯЂЃЌетбљгУЛЇЖСШЁЕФЪБКђЪЙгУЯћЯЂIDЪЧЖСВЛЕНЪ§ОнЕФЃЌвВОЭЯрЕБгкЩОГ§ЕФФкШнЃЌЖјЧвЩОГ§ЫйЖШЛсКмПьЁЃГ§СЫжБНгЩОГ§ЭтЃЌСэЭтвЛжжАьЗЈЪЧТпМЩОГ§ЃЌЖдгкЩОГ§ЕФfeedФкШнЃЌжЛзіБъМЧЃЌЕБВщбЏЕНДјгаБъМЧЕФЪ§ОнЪБОЭШЯЮЊЩОГ§СЫЁЃ
10. ИќаТFeedФкШн
ИќаТКЭЩОГ§FeedДІРэТпМвЛбљЃЌШчЙћЪЙгУСЫжЇГжЖрАцБОЕФДцДЂЯЕЭГЃЌБШШчTablestoreЃЌФЧУДвВПЩвджЇГжБрМАцБОЃЌКЭЯждкЕФЮЂВЉвЛбљЁЃ
11. змНс
ЩЯУцНщЩмСЫВЛЭЌзгЙІФмЕФЬиЕуКЭЯЕЭГвЊЧѓЃЌФмТњзуашЧѓЕФЯЕЭГжївЊгаСНРрЃЌвЛРрЪЧАЂРядЦЕФTablestoreЕЅЯЕЭГЃЌвЛРрЪЧПЊдДзщМўзщГЩЕФзщКЯЯЕЭГЁЃ
ПЊдДзщМўзщГЩЕФзщКЯЯЕЭГЃКАќРЈMySQLЁЂRedisЁЂHBaseЕШЃЌетаЉЯЕЭГЕЅИіЖМВЛФмНтОіFeedСїЯЕЭГжагіЕНЕФЮЪЬтЃЌашвЊзщКЯдквЛЦ№ЃЌИїЫОЦфжАВХФмЭъГЩвЛИіFeedСїЯЕЭГЃЌЪЪгУгкШШждПЊдДЯЕЭГЃЌШЫЖрЧвЯВЛЖдЫЮЌВйзїЕФЭХЖгЁЃ
TablestoreЕЅЯЕЭГЃКжЛЪЙгУTablestoreЕЅИіЯЕЭГОЭФмНтОіЩЯЪіЕФЫљгаЮЪЬтЃЌетЪБКђПЯЖЈгаШЫвЊЮЪЃПФуЪЧВЛЪЧдкДЕХЃЃПетРяВЛЪЧДЕХЃЃЌTablestoreдкШ§ФъЧАОЭвбОПЊЪМжиЪгFeedСїРраЭвЕЮёЃЌжЎЧАвВЗЂБэЙ§ЖрЦЊЮФеТНщЩмЃЌЙІФмЩЯвВдкзЈУХЮЊFeedСїЯЕЭГЬиБ№ЖЈжЦЩшМЦЃЌЫљвдЕННёЬьЃЌжЛЪЙгУTablestoreвЛПюВњЦЗЃЌЪЧПЩвдТњзуЩЯЪіашЧѓЕФЁЃбЁдёTablestoreзіFeedСїЯЕЭГЕФгУЛЇОпгавдЯТвЛаЉЬиеїЃК
ВњЦЗЩшМЦФПБъЙцФЃДѓЃЌЧЇЭђМЖЛђвкМЖЁЃ
ВЛЯВЛЖдЫЮЌЃЌЯВЛЖзЈзЂгкПЊЗЂЁЃ
ИпаЇТЪЭХЖгЃЌЯЃЭћОЁПьНЋВњЦЗЪЕЯжТфЕиЁЃ
ЯЃЭћвЛРЭгРвнЃЌЮДРДЯЕЭГЫцзХгУЛЇЙцФЃдіГЄПЩвдздЖЏРЉШнЁЃ
ЯЃЭћФмАДСПИЖЗбЃЌгУЛЇЩйЕФЪБКђЗбгУЕЭЃЌЕШгУЛЇдіГЄЦ№РДКѓЗбгУдкИњЫцгУЛЇЪ§діГЄЁЃ
ШчЙћОпгаЩЯЪіЫФИіЬиеїЕФШЮКЮвЛИіЃЌФЧУДЖМЪЧЪЪКЯгкгУTablestoreЁЃ
МмЙЙЪЕМљ
ЩЯУцЮвУЧНщЩмСЫFeedСїЯЕЭГЕФЩшМЦРэТлЃЌОпЬхЕНВЛЭЌЕФРраЭжаЃЌЛсгаВЛЭЌЕФВржиЕуЃЌЯТУцЛсж№вЛНщЩмЁЃ
ХѓгбШІ
ХѓгбШІЪЧвЛжжЕфаЭЕФFeedСїЯЕЭГЃЌЙиЯЕЪЧЫЋаДЙиЯЕЃЌЙиЯЕгаЩЯЯоЃЌХХађАДееЪБМфЃЌШчЙћгаИіШЫГжајВњЩњРЌЛјФкШнЃЌФЧОЭжЛФмЦСБЮЕєTAЃЌетвЛжжРраЭОЭЪЧЕфаЭЕФаДРЉЩЂФЃаЭЁЃ
ЮвУЧНгЯТРДЛсдкЮФеТЁЖХѓгбШІРрЯЕЭГМмЙЙЩшМЦЁЗжаЯъЯИНщЩмХѓгбШІРраЭFeedСїЯЕЭГЕФЩшМЦЁЃ
ЮЂВЉ
ЮЂВЉвВЪЧвЛжжЗЧГЃЕфаЭЕФFeedСїЯЕЭГЃЌЕЋВЛЭЌгкХѓгбШІЃЌЙиЯЕЪЧЕЅЯђЕФЃЌФЧУДвВОЭЛсВњЩњДѓVЃЌетИіЪБКђОЭашвЊЖСаДРЉЩЂФЃЪНЃЌгУЖСРЉЩЂНтОіДѓVЮЪЬтЁЃЭЌЪБЃЌЮЂВЉвВЪЧжїЖЏЙизЂРраЭЕФВњЦЗЃЌЫљвдХХађвВжЛФмЪЧЪБМфЃЌШчЙћАДееЭЦМіХХађЃЌФЧУДаЇЙћОЭЛсБШНЯВюЁЃ
НгЯТРяЛсдкЮФеТЁЖЮЂВЉРрЯЕЭГМмЙЙЩшМЦЁЗжаЯъЯИНщЩмЮЂВЉРраЭFeedСїЯЕЭГЕФЩшМЦЁЃ
ЭЗЬѕ
ЭЗЬѕЪЧзюНќМИФъПьЫйсШЦ№ЕФвЛПюгІгУЃЌдкдгаЮЂВЉЕФFeedСїЯЕЭГЩЯВњЩњСЫНјЛЏЃЌгУЛЇВЛашвЊжїЖЏЙизЂЦфЫћШЫЃЌжЛвЊГѕЪМфЏРРвЛаЉФкШнКѓЃЌЯЕЭГОЭЛсздЖЏХаЖЯГіФуЕФЯВКУЃЌШЛКѓКѓУцдйИљОнФуЕФЯВКУИјФуЭЦМіФуПЩФмЛсЯВКУЕФФкШнЃЌбЕСЗЪБМфГЄСЫКѓЃЌЭЦЫЭЕФФкШнЖМЛсЪЧФузюЯВЛЖПДЕФЁЃ
КѓУцЃЌЮвУЧЛсдкЮФеТЁЖЭЗЬѕРрЯЕЭГМмЙЙЩшМЦЁЗжаЯъЯИНщЩмЭЗЬѕРраЭFeedСїЯЕЭГЕФЩшМЦЁЃ
ЫНаХ
ЫНаХвВЫуЪЧвЛжжМђЕЅЕФFeedСїЯЕЭГЃЌЛђепвВПЩвдШЯЮЊЪЧвЛжжБфЯрЕФIMЃЌЖМЪЧЕЅЖдЕЅЕФЃЌУЛгаШКЁЃЮвУЧКѓУцвВЛсгавЛЦЊЮФеТЁЖЫНаХРрЯЕЭГМмЙЙЩшМЦЁЗжазіЯъЯИНщЩмЁЃ
змНс
ЖСепШчЙћЖдФГвЛВПЗжПДЭъКѓШдШЛгавЩЮЪЃЌПЩвдМЬајдйЮФКѓЬсЮЪЃЌЮвЛсМЬајШЅЭъЩЦетЦЊЮФеТЃЌЯЃЭћЮДРДЖСепПДЭъетЦЊЮФеТКѓЃЌОЭПЩвдЧсЧсЫЩЫЩЩшМЦГівЛИівкМЖЙцФЃЕФFeedСїЯЕЭГЁЃ
|








