| БрМЭЦМі: |
ЮФеТжївЊНщЩмСЫЪВУДЪЧЗжВМЪНЯЕЭГМмЙЙЃЌгыДЋЭГЕЅЬхгІгУБШНЯгаЪВУДгХШБЕуЁЃвЛаЉФбЕуНщЩмЃЌЫцКѓгжНщЩмСЫЗжВМЪНЯЕЭГЕФММЪѕеЛвдМАШЋеЛМрПиЁЃ
РДздгкbilibiliзЈРИЃЌ,гЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
жегкЕНСЫЪБЯТЬжТлзюШШУХЕФЗжВМЪНЯЕЭГМмЙЙСЫЃЌЯждкИїДѓЙЋЫОЮоТлЪЧДѓЙЋЫОЛЙЪЧаЁЙЋЫОЖМЛсЬсМАЪЙгУЗжВМЪНЯЕЭГМмЙЙРДЙЙНЈxxxЯЕЭГЃЌЛЙгаPasSЦНЬЈетаЉИХФюЕФГіЯжЃЌПЩвдЫЕЗжВМЪНЯЕЭГМмЙЙЪЧЯждкзюШШУХЕФММЪѕЛАЬтСЫЁЃЮвНгДЅЗжВМЪНЯЕЭГМмЙЙзюГѕЪЧдк2016ФъЮЊжЎЧАЙЋЫОЕФЩчНЛВњЦЗЁАЖЃШЄЁБЃЌДгСуЕНвЛЙЙНЈСЫвЛЬзЗжВМЪНЯЕЭГМмЙЙКѓЖЫЗўЮёЃЌЕБШЛФЧЪБКђздМКвВЪЧБпбЇБпзіЃЌУўзХЪЏЭЗЙ§КгЃЌКмЖрЖЋЮїЖМВЛЭъЩЦЃЌБШШчЗўЮёжЎМфёюКЯГЬЖШБШНЯИпЃЌвВУЛгаРрЫЦDevOpsетбљЕФздЖЏЛЏдЫЮЌЗНАИЃЌЗжВМЪНЪТЮёЮЪЬтУЛгаГЙЕзНтОіЃЌжЛФмЫуИіДЋЭГЕЅЬхгІгУКЭЗжВМЪНЯЕЭГЯрНсКЯЕФАыГЩЦЗЁЃ
1.ЗжВМЪНЯЕЭГМмЙЙЕФЖЈвх
ЪВУДНаЗжВМЪНЯЕЭГМмЙЙЃП
НЋЕЅЬхгІгУВ№ЗжГЩЖрИізгЯЕЭГЃЌУПИізгЯЕЭГдЫаадкИїздЕФНјГЬжаЃЌзгЯЕЭГМфЯрЛЅЭЈбЖЃЌДгЖјЪЙећИіЯЕЭГдЫзЊЦ№РДЃЌетОЭЪЧЗжВМЪНЯЕЭГМмЙЙЁЃ
2.ДЋЭГЕЅЬхгІгУгыЗжВМЪНЯЕЭГМмЙЙЕФгХШБЕу
ЗжВМЪНЯЕЭГЯрБШНЯгкЕЅЬхгІгУгазХКмЖрЕФгХЪЦЃЌБШШчФмдіМгЯЕЭГЭЬЭТСПЃЌМгЧПЯЕЭГИпПЩгУадЕШЁЃВЛЙ§ЪРНчЩЯВЛДцдкЭъУРЕФММЪѕЗНАИЃЌЗжВМЪНЯЕЭГМмЙЙвВгаКмЖрШБЯнЃЌЯТУцетеХЭМБэЖдБШСЫСНепЕФгХШБЕуЁЃ

3.ЗжВМЪНЯЕЭГМмЙЙЕФЗЂеЙЪЗ
ПЊЗЂЁЂЮЌЛЄКЭЪЙгУ SOA вЊзёбвдЯТМИЬѕЛљБОддђЁЃ
ПЩжигУЃЌСЃЖШКЯЪЪЃЌФЃПщЛЏЃЌПЩзщКЯЃЌЙЙМўЛЏвдМАгаЛЅВйзїадЁЃ
ЗћКЯПЊЗХБъзМЃЈЭЈгУЕФЛђаавЕЕФЃЉЁЃ
ЗўЮёЕФЪЖБ№КЭЗжРрЃЌЬсЙЉКЭЗЂВМЃЌМрПиКЭИњзйЁЃ
ЗжВМЪНЯЕЭГМмЙЙЕФбнБфЪЗЃК

ЮвУЧПЩвдПДЕНЃЌУцЯђЗўЮёЕФМмЙЙгавдЯТШ§ИіНзЖЮЁЃ
l 20 ЪРМЭ 90 ФъДњЧАЃЌЪЧЕЅЬхМмЙЙЃЌШэМўФЃПщИпЖШёюКЯЁЃЕБШЛЃЌетеХЭМЭЌбљвВЫЕУїСЫгаЕФ SOA
МмЙЙЦфЪЕКЭЕЅЬхМмЙЙУЛЪВУДСНбљЃЌвђЮЊЖМЪЧИпЖШёюКЯдквЛЦ№ЕФЁЃОЭЯёЭМжаЕФГнТжвЛбљЃЌЕБФуЕїгУвЛИіЗўЮёЪБЃЌетИіЗўЮёЛсЕїгУСэвЛИіЗўЮёЃЌШЛКѓгжЕїгУСэЭтЕФЗўЮёЁЁгкЪЧећИіЯЕЭГОЭзЊЦ№РДСЫЁЃЕЋЪЧетБОжЪЪЧБШНЯёюКЯЕФзіЗЈЁЃ
l Жј 2000 ФъзѓгвГіЯжСЫБШНЯЫЩёюКЯЕФ SOA МмЙЙЃЌетИіМмЙЙашвЊвЛИіБъзМЕФавщЛђЪЧжаМфМўРДСЊЖЏЦфЫќЯрЙиСЊЕФЗўЮёЃЈШч
ESBЃЉЁЃетбљвЛРДЃЌЗўЮёМфВЂВЛжБНгвРРЕЃЌЖјЪЧЭЈЙ§жаМфМўЕФБъзМавщЛђЪЧЭЈбЖПђМмЯрЛЅвРРЕЁЃетЦфЪЕОЭЪЧ IoCЃЈПижЦЗДзЊЃЉКЭ
DIPЃЈвРРЕЕЙжУддђЃЉЩшМЦЫМЯыдкМмЙЙжаЕФЪЕМљЁЃЫќУЧЖМвРРЕгквЛИіБъзМЕФавщЛђЪЧвЛИіБъзМЭГвЛЕФНЛЛЅЗНЪНЃЌЖјВЛЪЧжБНгЕїгУЁЃ
l Жј 2010 ФъКѓЃЌГіЯжСЫЮЂЗўЮёМмЙЙЃЌетИіМмЙЙИќЮЊЫЩёюКЯЁЃУПвЛИіЮЂЗўЮёЖМФмЖРСЂЭъећЕидЫааЃЈЫљЮНЕФздАќКЌЃЉЃЌКѓЖЫЕЅЬхЕФЪ§ОнПтвВБЛЮЂЗўЮёетбљЕФМмЙЙЗжЩЂЕНВЛЭЌЕФЗўЮёжаЁЃЖјЫќКЭДЋЭГ
SOA ЕФВюБ№дкгкЃЌЗўЮёМфЕФећКЯашвЊвЛИіЗўЮёБрХХЛђЪЧЗўЮёећКЯЕФв§ЧцЁЃОЭКУЯёНЛЯьРжжаашвЊгавЛИіжИЛгРДАбЫљгаРжЦїБрХХКЭзщжЏдквЛЦ№ЁЃ
4.ЗжВМЪНЯЕЭГМмЙЙЕФФбЕу
ДгФПЧАвбОЙЋПЊЕФзЪСЯРДПДЃЌЗжВМЪНЗўЮёЛЏМмЙЙЫМЯыЪЕМљзюдчЕФЙЋЫОгІИУЪЧбЧТэбЗЁЃдк2002ФъЕФЪБКђбЧТэбЗCEOБДЫїЫЙОЭЯђЙЋЫОАфВМСЫМИЬѕМмЙЙЕФЙцЖЈ
1ЃЎЫљгаЭХЖгЕФГЬађФЃПщЖМвЊЭЈЙ§ Service Interface ЗНЪННЋЦфЪ§ОнгыЙІФмПЊЗХГіРДЁЃ
2ЃЎЭХЖгМфГЬађФЃПщЕФаХЯЂЭЈаХЃЌЖМвЊЭЈЙ§етаЉНгПкЁЃГ§ДЫжЎЭтУЛгаЦфЫќЕФЭЈаХЗНЪНЁЃ
3ЃЎЦфЫћаЮЪНвЛИХВЛдЪаэЃКВЛФмжБНгСДНсБ№ЕФГЬађЃЈАбЦфЫћЭХЖгЕФГЬађЕБзіЖЏЬЌСДНгПтРДСДНгЃЉЃЌВЛФмжБНгЖСШЁЦфЫћЭХЖгЕФЪ§ОнПтЃЌВЛФмЪЙгУЙВЯэФкДцФЃЪНЃЌВЛФмЪЙгУБ№ШЫФЃПщЕФКѓУХЃЌЕШЕШЁЃЮЈвЛдЪаэЕФЭЈаХЗНЪНЪЧЕїгУ
Service InterfaceЁЃ
4ЃЎШЮКЮММЪѕЖМПЩвдЪЙгУЁЃБШШчЃКHTTPЁЂCORBAЁЂPub/SubЁЂздЖЈвхЕФЭјТчавщЕШЁЃ
5ЃЎЫљгаЕФ Service InterfaceЃЌКСЮоР§ЭтЃЌЖМБиаыДгЙЧзгРяЕНБэУцЩЯЩшМЦГЩФмЖдЭтНчПЊЗХЕФЁЃвВОЭЪЧЫЕЃЌЭХЖгБиаызіКУЙцЛЎгыЩшМЦЃЌвдБуЮДРДАбНгПкПЊЗХИјШЋЪРНчЕФГЬађдБЃЌУЛгаШЮКЮР§ЭтЁЃ
6ЃЎВЛетбљзіЕФШЫЛсБЛГДіЯгуЁЃ
бЧТэбЗЙмРэЗжВМЪНЯЕЭГМмЙЙЕФвЊЕу
еыЖдЗжВМЪНЯЕЭГМмЙЙдЫЮЌКЭЙмРэЕФФбЕуЃЌбЧТэбЗжївЊДгвдЯТМИЗНУцРДЙмРэЁЃ
l ЗжВМЪНЗўЮёЕФМмЙЙашвЊЗжВМЪНЕФЭХЖгМмЙЙ
l ЗжВМЪНЗўЮёВщДэВЛШнвз
l УЛгазЈжАЕФВтЪдШЫдБЃЌвВУЛгазЈжАЕФдЫЮЌШЫдБЃЌПЊЗЂШЫдБзіЫљгаЕФЪТЧщ
l дЫЮЌгХЯШЃЌГчЩаМђЛЏКЭздЖЏЛЏ
l ФкВПЗўЮёКЭЭтВПЗўЮёвЛжТ
ЗжВМЪНЯЕЭГМмЙЙЕФФбЕу
ЮЪЬтвЛЃКвьЙЙЯЕЭГЕФВЛБъзМЮЪЬт
ЮЪЬтЖўЃКЯЕЭГМмЙЙжаЕФЗўЮёвРРЕадЮЪЬт
ЮЪЬтШ§ЃКЙЪеЯЗЂЩњЕФИХТЪИќДѓ
ЮЪЬтЫФЃКЖрВуМмЙЙЕФдЫЮЌИДдгЖШИќДѓ
ЪзЯШПДЕквЛИіЮЪЬтЃЌетжївЊЬхЯждкШэМўКЭгІгУВЛБъзМЁЂЭЈбЖавщВЛБъзМЁЂЪ§ОнИёЪНВЛБъзМЁЂПЊЗЂКЭдЫЮЌЕФЙ§ГЬКЭЗНЗЈВЛБъзМЁЃетаЉЮЪЬтЖМЛсЬсЩ§ЮвУЧЙЙНЈЗжВМЪНЯЕЭГМмЙЙЕФИДдгЖШЁЃ
ЕкЖўЪЧЗўЮёвРРЕадЕФЮЪЬтЃЌдкЗжВМЪНЯЕЭГМмЙЙжаЃЌЗўЮёжЎМфЪЧЛсгавРРЕЕФЃЌвЛИіЗўЮёЙвСЫПЩФмЛсв§ЗЂЁАЖрУзХЕЙЧХЦЁБаЇгІЃЌЕМжТећИіЯЕЭГЬБЛОЁЃ
гЩгкЯЕЭГБЛВ№ЗжГЩЖрИіЗўЮёЃЌУПИіЗўЮёВПЪ№дкВЛЭЌЕФЛњЦїЩЯЃЌУПИіЗўЮёЖдгІЕФЪ§ОнПтвВдкВЛЭЌЕФЛњЦїЩЯЃЌетОЭЪЙЕУЯЕЭГГіЯжЙЪеЯЕФИХТЪдіМгЃЌБЯОЙЗжВМЕУдНЩЂОЭдНШнвзЗИДэЁЃ
ЗжВМЪНЯЕЭГМмЙЙжївЊЗжЮЊЫФВуЃКЛљДЁВуЁЂЦНЬЈВуЁЂгІгУВуКЭНгШыВуЁЃ
ЛљДЁВуОЭЪЧЮвУЧЕФЛњЦїЁЂЭјТчКЭДцДЂЩшБИЕШЁЃ
ЦНЬЈВуОЭЪЧЮвУЧЕФжаМфМўВуЃЌTomcatЁЂMySQLЁЂRedisЁЂKafka жЎРрЕФШэМўЁЃ
гІгУВуОЭЪЧЮвУЧЕФвЕЮёШэМўЃЌБШШчЃЌИїжжЙІФмЕФЗўЮёЁЃ
НгШыВуОЭЪЧНгШыгУЛЇЧыЧѓЕФЭјЙиЁЂИКдиОљКтЛђЪЧ CDNЁЂDNS етбљЕФЖЋЮїЁЃ
етЫФВужаЕФШЮКЮвЛВуГіЯжЮЪЬтЖМгаПЩФмЕМжТећИіЯЕЭГЬБЛОЁЃ
вдЩЯОЭЪЧЗжВМЪНЯЕЭГжаЕФФбЕуЃЌдкЗжВМЪНЯЕЭГжаЃЌУПИізгЯЕЭГЖМгаЖдгІЕФЗжЙЄЃЌЗжЙЄВЛЪЧЮЪЬтЃЌЮЪЬтЪЧЗжЙЄКѓЕФазїЪЧЗёЭГвЛКЭЙцЗЖЁЃ
5.ЗжВМЪНЯЕЭГЕФММЪѕеЛ
ЙЙНЈЗжВМЪНЯЕЭГМмЙЙЕФФПЕФЪЧЮЊСЫдіМгЯЕЭГЭЬЭТСПЃЌЬсИпЯЕЭГЕФПЩгУадЁЃдкММЪѕЗНУцЪЕМЪЩЯОЭЪЧЭЈЙ§МЏШКММЪѕНЋВЂЗЂЧыЧѓИКдиЗжЩЂЕНВЛЭЌЕФЛњЦїЩЯЃЌЬсИпЯЕЭГПЩгУадЃЌНЋЗўЮёЙЪеЯИєРыЗРжЙГіЯжЁАЖрУзХЕЙЧХЦЁБаЇгІЁЃ
ЬсИпЯЕЭГЕФадФм

ЛКДцЯЕЭГ
МгШыЛКДцЯЕЭГПЩвдгааЇЕиЬсИпЯЕЭГЕФадФмЃЌДгЧАЖЫЕФфЏРРЦїЃЌЕНЭјТчЃЌдйЕНКѓЖЫЕФЗўЮёЃЌЕзВуЕФЪ§ОнПтЁЂЮФМўЯЕЭГЁЂгВХЬКЭ
CPUЃЌШЋЖМгаЛКДцЃЌетЪЧЬсИпПьЫйЗУЮЪФмСІзюгааЇЕФЪжЖЮЁЃдкЗжВМЪНЯЕЭГМмЙЙжаашвЊвЛИіЛКДцМЏШКЁЃ
ИКдиОљКтЯЕЭГ
ИКдиОљКтЯЕЭГЪЧЫЎЦНРЉеЙЕФЙиМќММЪѕЃЌЫќПЩвдЪЙгУЖрЬЈЛњЦїРДЙВЭЌЗжЕЃвЛВПЗжСїСПЧыЧѓЁЃ
вьВНЕїгУ
вьВНЯЕЭГжївЊЭЈЙ§ЯћЯЂЖгСаРДЖдЧыЧѓзіХХЖгДІРэЃЌетбљПЩвдАбЧАЖЫЕФЧыЧѓЕФЗхжЕИјЁАЯїЦНЁБСЫЃЌЖјКѓЖЫЭЈЙ§здМКФмЙЛДІРэЕФЫйЖШРДДІРэЧыЧѓЁЃетбљПЩвддіМгЯЕЭГЕФЭЬЭТСПЃЌЕЋЪЧЪЕЪБадОЭВюКмЖрСЫЁЃЭЌЪБЃЌЛЙЛсв§ШыЯћЯЂЖЊЪЇЕФЮЪЬтЃЌЫљвдвЊЖдЯћЯЂзіГжОУЛЏЃЌетЛсдьГЩЁАгазДЬЌЁБЕФНсЕуЃЌДгЖјдіМгСЫЗўЮёЕїЖШЕФФбЖШЁЃ
Ъ§ОнЗжЧјКЭЪ§ОнОЕЯё
Ъ§ОнЗжЧјЪЧАбЪ§ОнАДвЛЖЈЕФЗНЪНЗжГЩЖрИіЧјЃЈБШШчЭЈЙ§ЕиРэЮЛжУЃЉЃЌВЛЭЌЕФЪ§ОнЧјРДЗжЕЃВЛЭЌЧјЕФСїСПЁЃеташвЊвЛИіЪ§ОнТЗгЩЕФжаМфМўЃЌЛсЕМжТПчПтЕФ
Join КЭПчПтЕФЪТЮёЗЧГЃИДдгЁЃЖјЪ§ОнОЕЯёЪЧАбвЛИіЪ§ОнПтОЕЯёГЩЖрЗнвЛбљЕФЪ§ОнЃЌетбљОЭВЛашвЊЪ§ОнТЗгЩЕФжаМфМўСЫЁЃФуПЩвддкШЮвтНсЕуЩЯНјааЖСаДЃЌФкВПЛсздааЭЌВНЪ§ОнЁЃШЛЖјЃЌЪ§ОнОЕЯёжазюДѓЕФЮЪЬтОЭЪЧЪ§ОнЕФвЛжТадЮЪЬтЁЃ
ЬсИпМмЙЙЕФЮШЖЈад

ЗўЮёВ№Зж
ЗўЮёВ№ЗжжївЊгаСНИіФПЕФЃКвЛЪЧЮЊСЫИєРыЙЪеЯЃЌЖўЪЧЮЊСЫжигУЗўЮёФЃПщЁЃЕЋЗўЮёВ№ЗжЭъжЎКѓЃЌЛсв§ШыЗўЮёЕїгУМфЕФвРРЕЮЪЬтЁЃ
ЗўЮёШпгр
ЗўЮёШпгрЪЧЮЊСЫШЅГ§ЕЅЕуЙЪеЯЃЌВЂПЩвджЇГжЗўЮёЕФЕЏадЩьЫѕЃЌвдМАЙЪеЯЧЈвЦЁЃШЛЖјЃЌЖдгквЛаЉгазДЬЌЕФЗўЮёРДЫЕЃЌШпгретаЉгазДЬЌЕФЗўЮёДјРДСЫИќИпЕФИДдгадЁЃЦфжавЛИіЪЧЕЏадЩьЫѕЪБЃЌашвЊПМТЧЪ§ОнЕФИДжЦЛђЪЧжиаТЗжЦЌЃЌЧЈвЦЕФЪБКђЛЙвЊЧЈвЦЪ§ОнЕНЦфЫќЛњЦїЩЯЁЃ
ЯоСїНЕМЖ
ЕБЯЕЭГЪЕдкПИВЛзЁбЙСІЪБЃЌжЛФмЭЈЙ§ЯоСїЛђепЙІФмНЕМЖЕФЗНЪНРДЭЃЕєвЛВПЗжЗўЮёЃЌЛђЪЧОмОјвЛВПЗжгУЛЇЃЌвдШЗБЃећИіМмЙЙВЛЛсЙвЕєЁЃетаЉММЪѕЪєгкБЃЛЄДыЪЉЁЃ
ИпПЩгУМмЙЙ
ЭЈГЃРДЫЕИпПЩгУМмЙЙЪЧДгШпгрМмЙЙЕФНЧЖШРДБЃеЯПЩгУадЁЃБШШчЃЌЖрзтЛЇИєРыЃЌджБИЖрЛюЃЌЛђЪЧЪ§ОнПЩвддкЦфжаИДжЦБЃГжвЛжТадЕФМЏШКЁЃзмжЎЃЌОЭЪЧЮЊСЫВЛГіЕЅЕуЙЪеЯЁЃ
ИпПЩгУдЫЮЌ
ИпПЩгУдЫЮЌжИЕФЪЧ DevOps жаЕФ CI/CDЃЈГжајМЏГЩ / ГжајВПЪ№ЃЉЁЃвЛИіСМКУЕФдЫЮЌгІИУЪЧвЛЬѕКмСїГЉЕФШэМўЗЂВМЙмЯпЃЌЦфжазіСЫзуЙЛЕФздЖЏЛЏВтЪдЃЌЛЙПЩвдзіЯргІЕФЛвЖШЗЂВМЃЌвдМАЖдЯпЩЯЯЕЭГЕФздЖЏЛЏПижЦЁЃетбљЃЌПЩвдзіЕНЁАМЦЛЎФкЁБЛђЪЧЁАЗЧМЦЛЎФкЁБЕФхДЛњЪТМўЕФЪБГЄзюЖЬЁЃ
ЗжВМЪНЯЕЭГЕФЙиМќММЪѕ
ЗўЮёжЮРэ
ЗўЮёВ№ЗжЁЂЗўЮёЕїгУЁЂЗўЮёЗЂЯжЁЂЗўЮёвРРЕЁЂЗўЮёЕФЙиМќЖШЖЈвхЁЁЗўЮёжЮРэЕФзюДѓвтвхЪЧашвЊАбЗўЮёМфЕФвРРЕЙиЯЕЁЂЗўЮёЕїгУСДЃЌвдМАЙиМќЕФЗўЮёИјЪсРэГіРДЃЌВЂЖдетаЉЗўЮёНјааадФмКЭПЩгУадЗНУцЕФЙмРэЁЃ
МмЙЙШэМўЙмРэ
ЗўЮёжЎМфгавРРЕЃЌЖјЧвгаМцШнадЮЪЬтЃЌЫљвдЃЌећЬхЗўЮёЫљаЮГЩЕФМмЙЙашвЊгаМмЙЙАцБОЙмРэЁЂећЬхМмЙЙЕФЩњУќжмЦкЙмРэЃЌвдМАЖдЗўЮёЕФБрХХЁЂОлКЯЁЂЪТЮёДІРэЕШЗўЮёЕїЖШЙІФмЁЃ
DevOps
ЗжВМЪНЯЕЭГПЩвдИќЮЊПьЫйЕиИќаТЗўЮёЃЌЕЋЪЧЖдгкЗўЮёЕФВтЪдКЭВПЪ№ЖМЛсЪЧЬєеНЁЃЫљвдЃЌЛЙашвЊ DevOps
ЕФШЋСїГЬЃЌЦфжаАќРЈЛЗОГЙЙНЈЁЂГжајМЏГЩЁЂГжајВПЪ№ЕШЁЃ
здЖЏЛЏдЫЮЌ
гаСЫ DevOps КѓЃЌЮвУЧОЭПЩвдЖдЗўЮёНјааздЖЏЩьЫѕЁЂЙЪеЯЧЈвЦЁЂХфжУЙмРэЁЂзДЬЌЙмРэЕШвЛЯЕСаЕФздЖЏЛЏдЫЮЌММЪѕСЫЁЃ
зЪдДЕїЖШЙмРэ
гІгУВуЕФздЖЏЛЏдЫЮЌашвЊЛљДЁВуЕФЕїЖШжЇГжЃЌвВОЭЪЧдЦМЦЫу IaaS ВуЕФМЦЫуЁЂДцДЂЁЂЭјТчЕШзЪдДЕїЖШЁЂИєРыКЭЙмРэЁЃ
ећЬхМмЙЙМрПи
ШчЙћУЛгавЛИіКУЕФМрПиЯЕЭГЃЌФЧУДздЖЏЛЏдЫЮЌКЭзЪдДЕїЖШЙмРэжЛПЩФмГЩЮЊвЛИіХнгАЃЌвђЮЊМрПиЯЕЭГЪЧФуЕФблОІЁЃУЛгаблОІЃЌУЛгаЪ§ОнЃЌОЭЮоЗЈНјааИпаЇЕФдЫЮЌЁЃЫљвдЫЕЃЌМрПиЪЧЗЧГЃживЊЕФВПЗжЁЃетРяЕФМрПиашвЊЖдШ§ВуЯЕЭГЃЈгІгУВуЁЂжаМфМўВуЁЂЛљДЁВуЃЉНјааМрПиЁЃ
СїСППижЦ
зюКѓЪЧЮвУЧЕФСїСППижЦЃЌИКдиОљКтЁЂЗўЮёТЗгЩЁЂШлЖЯЁЂНЕМЖЁЂЯоСїЕШКЭСїСПЯрЙиЕФЕїЖШЖМЛсдкетРяЃЌАќРЈЛвЖШЗЂВМжЎРрЕФЙІФмвВдкетРяЁЃ
ЗжВМЪНЯЕЭГЕФЁАИйЁБ
ЗжВМЪНЯЕЭГЕФЙиМќММЪѕЦфЪЕОЭЪЧЮхДѓЗНУцЃК
ШЋеЛЯЕЭГМрПиЃЛ
ЗўЮё / зЪдДЕїЖШЃЛ
СїСПЕїЖШЃЛ
зДЬЌ / Ъ§ОнЕїЖШЃЛ
ПЊЗЂКЭдЫЮЌЕФздЖЏЛЏЁЃ
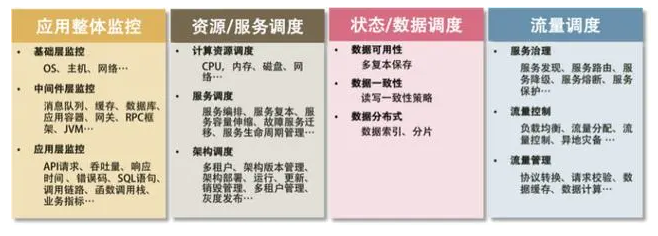
6.ЗжВМЪНЯЕЭГЙиМќММЪѕЃКШЋеЛМрПи
гЩгкгІгУБЛВ№ЗжГЩЖрИіЗўЮёзгЯЕЭГЃЌвђДЫашвЊЖдећИіЯЕЭГНјааШЋеЛЕФМрПиЃЌвЛБщЮвУЧИќКУЕФЗЂЯжКЭЖЈЮЛЯЕЭГЙЪеЯЮЪЬтЁЃ
ШЋеЛМрПиашвЊМрПиФФаЉФкШнФиЃП
ЛљДЁВу
МрПижїЛњКЭЕзВузЪдДЁЃБШШчЃКCPUЁЂФкДцЁЂЭјТчЭЬЭТЁЂгВХЬ I/OЁЂгВХЬЪЙгУЕШ
жаМфВу
ОЭЪЧжаМфМўВуЕФМрПиЁЃБШШчЃКNginxЁЂRedisЁЂActiveMQЁЂKafkaЁЂMySQLЁЂTomcat
ЕШ
гІгУВу
МрПигІгУВуЕФЪЙгУЁЃБШШчЃКHTTP ЗУЮЪЕФЭЬЭТСПЁЂЯьгІЪБМфЁЂЗЕЛиТыЁЂЕїгУСДТЗЗжЮіЁЂадФмЦПОБЃЌЛЙАќРЈгУЛЇЖЫЕФМрПи

ЪВУДЪЧКУЕФМрПиЯЕЭГЃП
ЙизЂгкећЬхгІгУЕФ SLA
жївЊДгЮЊгУЛЇЗўЮёЕФ API РДМрПиећИіЯЕЭГ
ЙиСЊжИБъОлКЯ
АбгаЙиСЊЕФЯЕЭГМАЦфжИБъОлКЯеЙЪОЁЃжївЊЪЧШ§ВуЯЕЭГЪ§ОнЃКЛљДЁВуЁЂЦНЬЈжаМфМўВуКЭгІгУВуЁЃЦфжаЃЌзюживЊЕФЪЧАбЗўЮёКЭЯрЙиЕФжаМфМўвдМАжїЛњЙиСЊдквЛЦ№ЃЌЗўЮёгаПЩФмдЫаадк
Docker жаЃЌвВгаПЩФмдЫаадкЮЂЗўЮёЦНЬЈЩЯЕФЖрИі JVM жаЃЌвВгаПЩФмдЫаадк Tomcat жаЁЃзмжЎЃЌЮоТлдЫаадкФФРяЃЌЮвУЧЖМашвЊАбЗўЮёЕФОпЬхЪЕР§КЭжїЛњЙиСЊдквЛЦ№ЃЌЗёдђЃЌЖдгквЛИіЗжВМЪНЯЕЭГРДЫЕЃЌЖЈЮЛЮЪЬтгЬШчДѓКЃРЬеыЁЃ
ФмПьЫйЙЪеЯЖЈЮЛ
ЖдгкЯжгаЕФЯЕЭГРДЫЕЃЌЙЪеЯзмЪЧЛсЗЂЩњЕФЃЌЖјЧвЛЙЛсЦЕЗБЗЂЩњЁЃЙЪеЯЗЂЩњВЛПЩХТЃЌПЩХТЕФЪЧЙЪеЯЕФЛжИДЪБМфЙ§ГЄЁЃЫљвдЃЌПьЫйЕиЖЈЮЛЙЪеЯОЭЯрЕБЙиМќЁЃПьЫйЖЈЮЛЮЪЬташвЊЖдећИіЗжВМЪНЯЕЭГзівЛИігУЛЇЧыЧѓИњзйЕФ
trace МрПиЃЌЮвУЧашвЊМрПиЕНЫљгаЕФЧыЧѓдкЗжВМЪНЯЕЭГжаЕФЕїгУСДЃЌетИіЪТзюКУЪЧзіГЩУЛгаЧжШыадЕФЁЃ
ШчКЮзіГівЛИіКУЕФМрПиЯЕЭГЃП
ЗўЮёЕїгУСДИњзй
ЖдгІПЊдДЪЕЯжЃКZipkinЃЌSkyWalking

ЗўЮёЕїгУЪБГЄЗжВМ
Zipkin

ЗўЮёЕФ TOP N ЪгЭМ

Ъ§ОнПтВйзїЙиСЊ
Ждгк Java гІгУЃЌЮвУЧПЩвдКмЗНБуЕиЭЈЙ§ JavaAgent зжНкТызЂШыММЪѕФУЕН JDBC жДааЪ§ОнПтВйзїЕФжДааЪБМфЁЃЖдДЫЃЌЮвУЧПЩвдКЭЯрЙиЕФЧыЧѓЖдгІЦ№РДЁЃ

ЗўЮёзЪдДИњзй
ЮвУЧЕФЗўЮёПЩФмдЫаадкЮяРэЛњЩЯЃЌвВПЩФмдЫаадкащФтЛњРяЃЌЛЙПЩФмдЫаадквЛИі Docker ЕФШнЦїРяЃЌDocker
ШнЦїгждЫаадкЮяРэЛњЛђЪЧащФтЛњЩЯЁЃЮвУЧашвЊАбЗўЮёдЫааЕФЛњЦїНкЕуЩЯЕФЪ§ОнЃЈШч CPUЁЂMEMЁЂI/OЁЂDISKЁЂNETWORKЃЉЙиСЊЦ№РДЁЃ
вЛИіЗжВМЪНЯЕЭГЙЪеЯЕФЪОР§ЭМЃК

7.ЗжВМЪНЯЕЭГЙиМќММЪѕЃКЗўЮёЕїЖШ
ЗўЮёЙиМќГЬЖШКЭЗўЮёЕФвРРЕЙиЯЕ
1.ЪсРэГіЖЈвхЗўЮёЕФЙиМќГЬЖШ
ЗўЮёЕФЙиМќГЬЖШЪЧИљОнвЕЮёРДЖЈвхЕФЃЌашвЊФуЖдЯЕЭГЕФвЕЮёгаНЯКУЕФРэНтЃЌВХФмИќКУЖЈвхГіЯЕЭГМмЙЙжаИїИіЗўЮёЕФЙиМќГЬађЁЃ
2.ЪсРэГіЗўЮёжЎМфЕФвРРЕЙиЯЕ
дкЗжВМЪНЯЕЭГжавЊзіЕНЗўЮёжЎМфУЛгавРРЕЪЧВЛПЩФмЕФЪТЧщЃЌвђДЫашвЊЪсРэГіЗўЮёМфЕФвРРЕЙиЯЕЁЃЮЂЗўЮёЪЧЗўЮёвРРЕзюгХНтЕФЩЯЯоЃЌЖјЗўЮёвРРЕЕФЯТЯоЪЧЧЇЭђВЛвЊгавРРЕЛЗЁЃШчЙћЯЕЭГМмЙЙжагаЗўЮёвРРЕЛЗЃЌФЧУДБэУїФуЕФМмЙЙЩшМЦЪЧДэЮѓЕФЁЃ
ЗўЮёЕФвРРЕЙиЯЕЪЧПЩвдЭЈЙ§ММЪѕЕФЪжЖЮРДЗЂЯжЕФЃЌетЦфжаЃЌZipkinЪЧвЛИіКмВЛДэЕФЗўЮёЕїгУИњзйЯЕЭГЁЃ
ЗўЮёзДЬЌКЭЩњУќжмЦкЕФЙмРэ
ашвЊвЛИіЗўЮёЗЂЯжЕФжаМфМўРДЙмРэЃЌвВОЭЪЧЗўЮёзЂВсжааФЃЌР§ШчЃКZookeeperЁЂNacosЕШЁЃ
ЮвУЧашвЊжЊЕРетаЉЗўЮёЕФзДЬЌКЭЩњУќжмЦкЃЌБШШчЃКгаЕФЗўЮёЛсаТМгНјРДЃЌгаЕФЗўЮёЛсЯТЯпЃЌЗўЮёЖдгІЕФЪЕР§гаЖрЩйИіЃЌетаЉЪЕР§ЕФзДЬЌЪЧдѕбљЕФЃПетаЉЖМашвЊБЛЙмРэЦ№РДЁЃ
ЗўЮёЕФЩњУќжмЦкЭЈГЃЛсгавдЯТМИИізДЬЌЃК
ProvisionЃЌДњБэдкЙЉгІвЛИіаТЕФЗўЮёЃЛ
ReadyЃЌБэЪОЦєЖЏГЩЙІСЫЃЛ
RunЃЌБэЪОЭЈЙ§СЫЗўЮёНЁПЕМьВщЃЛ
UpdateЃЌБэЪОдкЩ§МЖжаЃЛ
RollbackЃЌБэЪОдкЛиЙіжаЃЛ
ScaleЃЌБэЪОе§дкЩьЫѕжаЃЈПЩвдга Scale-in КЭ Scale-out СНжжЃЉЃЛ
DestroyЃЌБэЪОдкЯњЛйжаЃЛ
FailedЃЌБэЪОЪЇАмзДЬЌЁЃ
ећИіМмЙЙЕФАцБОЙмРэ
дкЗжВМЪНМмЙЙжаЃЌЮвУЧвВашвЊвЛИіМмЙЙЕФАцБОЃЌгУРДПижЦЦфжаИїИіЗўЮёЕФАцБОМцШнЁЃБШШчЃЌA ЗўЮёЕФ 1.2
АцБОжЛФмКЭ B ЗўЮёЕФ 2.2 АцБОвЛЦ№ЙЄзїЃЌA ЗўЮёЕФЩЯИіАцБО 1.1 жЛФмКЭ B ЗўЮёЕФ 2.0
вЛЦ№ЙЄзїЁЃетОЭЪЧАцБОМцШнадЁЃ
ШчЙћМмЙЙжагаетбљЕФЮЪЬтЃЌФЧУДЮвУЧОЭашвЊвЛИіЩЯВуМмЙЙЕФАцБОЙмРэЁЃетбљЃЌШчЙћЮвУЧвЊЛиЙівЛИіЗўЮёЕФАцБОЃЌОЭПЩвдАбгыжЎгаАцБОвРРЕЕФЗўЮёвВвЛЦ№ЛиЙіЕєЁЃ
ЕБШЛЃЌвЛАуРДЫЕЃЌдкЩшМЦЙ§ГЬжаЃЌЮвУЧЯЃЭћУЛгаАцБОЕФвРРЕадЮЪЬтЁЃЕЋПЩФмгааЉЪБКђЃЌЮвУЧЛсгаетбљЕФЮЪЬтЃЌФЧУДОЭашвЊдкМмЙЙАцБОжаМЧТМЯТетИіЪТЃЌвдБуПЩвдЛиЙіЕНЩЯвЛДЮЯрЛЅМцШнЕФАцБОЁЃ
вЊзіЕНетИіЪТЃЌФуашвЊвЛИіМмЙЙЕФ manifestЃЌвЛИіЗўЮёЧхЕЅЃЌетИіЗўЮёЧхЕЅЖЈвхСЫЫљгаЗўЮёЕФАцБОдЫааЛЗОГЃЌЦфжаАќРЈЕЋВЛЯогкЃК
ЗўЮёЕФШэМўАцБОЃЛ
ЗўЮёЕФдЫааЛЗОГЁЊЁЊЛЗОГБфСПЁЂCPUЁЂФкДцЁЂПЩвддЫааЕФНсЕуЁЂЮФМўЯЕЭГЕШЃЛ
ЗўЮёдЫааЕФзюДѓзюаЁЪЕР§Ъ§ЁЃ
УПвЛДЮЖдетИіЧхЕЅЕФБфИќЖМашвЊБЛМЧТМЯТРДЃЌЫуЪЧвЛИіМмЙЙЕФАцБОЙмРэЁЃЖјЮвУЧЩЯУцЫљЫЕЕФФЧИіМЏШКПижЦЯЕЭГашвЊФмЙЛНтЖСВЂжДааетИіЧхЕЅжаЕФБфИќЃЌвдВйзїКЭЙмРэећИіМЏШКжаЕФЯрЙиБфИќЁЃ
8.ЗжВМЪНЯЕЭГЙиМќММЪѕЃКСїСПгыЪ§ОнЕїЖШ
СїСПЕїЖШЃК
СїСПЕїЖШашвЊТњзуЕФашЧѓгавдЯТСНИіЗНУцЃК
1.вРОнЯЕЭГдЫааЕФЧщПіЃЌздЖЏЕиНјааСїСПЕїЖШЃЌдкЮоашШЫЙЄИЩдЄЕФЧщПіЯТЃЌЬсЩ§ећИіЯЕЭГЕФЮШЖЈад
2.ШУЯЕЭГгІЖдБЌЦЗЕШЭЛЗЂЪТМўЪБЃЌдкЕЏадМЦЫуРЉЫѕШнЕФНЯГЄЪБМфДАПкФкЛђЕзВузЪдДЯћКФДљОЁЕФЧщПіЯТЃЌБЃЛЄЯЕЭГЦНЮШдЫаа
3.ЗўЮёСїПиЁЃЗўЮёЗЂЯжЁЂЗўЮёТЗгЩЁЂЗўЮёНЕМЖЁЂЗўЮёШлЖЯЁЂЗўЮёБЃЛЄЕШЁЃ
4.СїСППижЦЁЃИКдиОљКтЁЂСїСПЗжХфЁЂСїСППижЦЁЂвьЕиджБИЃЈЖрЛюЃЉЕШ
5.СїСПЙмРэЁЃавщзЊЛЛЁЂЧыЧѓаЃбщЁЂЪ§ОнЛКДцЁЂЪ§ОнМЦЫуЕШ
вдЩЯетаЉвЊЧѓЖМЪЧвЛИіAPI GatewayашвЊзіЕФЪТЧщЁЃвЛИіКУЕФAPI GatewayгІОпБИвдЯТЙиМќММЪѕЃК
ИпадФм
ПИСїСП
вЊФмПИСїСПЃЌОЭашвЊЪЙгУМЏШКММЪѕЁЃМЏШКММЪѕЕФЙиМќЕуЪЧдкМЏШКФкЕФИїИіНсЕужаЙВЯэЪ§ОнЁЃетОЭашвЊЪЙгУЯё PaxosЁЂRaftЁЂGossip
етбљЕФЭЈбЖавщЁЃвђЮЊ Gateway ашвЊВПЪ№дкЙугђЭјЩЯЃЌЫљвдЛЙашвЊМЏШКЕФЗжзщММЪѕ
вЕЮёТпМ
API Gateway ашвЊгаМђЕЅЕФвЕЮёТпМЃЌЫљвдЃЌзюКУЪЧЯё AWS ЕФ Lambda ЗўЮёвЛбљЃЌПЩвдШУШЫзЂШыВЛЭЌгябдЕФМђЕЅвЕЮёТпМЁЃ
ЗўЮёЛЏ
вЛИіКУЕФ API Gateway ашвЊФмЙЛЭЈЙ§ Admin API РДВЛЭЃЛњЕиЙмРэХфжУБфИќЃЌЖјВЛЪЧЭЈЙ§вЛИі.conf
ЮФМўРДШЫШтЕиаоИФХфжУЁЃ
зДЬЌЪ§ОнЕїЖШ
1.ЖдгкгІгУВуЩЯЕФЗжВМЪНЪТЮёвЛжТадЃЌжЛгаСННзЖЮЬсНЛетбљЕФЗНЪН
2.ЖјЕзВуДцДЂПЩвдНтОіетИіЮЪЬтЕФЗНЪНЪЧЭЈЙ§вЛаЉЯё PaxosЁЂRaft ЛђЪЧ NWR етбљЕФЫуЗЈКЭФЃаЭРДНтОі
3.зДЬЌЪ§ОнЕїЖШгІИУЪЧгЩЗжВМЪНДцДЂЯЕЭГРДНтОіЕФЃЌетбљЛсИќЮЊЭъУРЁЃЕЋЪЧвђЮЊЪ§ОнДцДЂЕФ Scheme
ЬЋЖрЃЌЫљвдЃЌЕМжТЮвУЧгаИїЪНИїбљЕФЗжВМЪНДцДЂЯЕЭГЃЌгаЮФМўЖдЯѓЕФЃЌгаЙиЯЕаЭЪ§ОнПтЕФЃЌга NoSQL ЕФЃЌгаЪБађЪ§ОнЕФЃЌгаЫбЫїЪ§ОнЕФЃЌгаЖгСаЕФЁЁ
9.PasSЦНЬЈЕФБОжЪ
ЕквЛЃЌЬсИпЗўЮёЕФ SLA
ЕкЖўЃЌФмСІКЭзЪдДжигУЛђИДгУ
ЕкШ§ЃЌЙ§ГЬЕФздЖЏЛЏЃЈАќРЈздЖЏЛЏдЫЮЌвдМАЩњВњЛЗОГе§дкдЫааЕФШэМўЕФздЖЏЛЏЃЉ
PasSЦНЬЈЕФБОжЪЪЧЃК
ЗўЮёЛЏ
ЗжВМЪН
здЖЏЛЏ

PaaS ЦНЬЈЕФзмЬхМмЙЙ
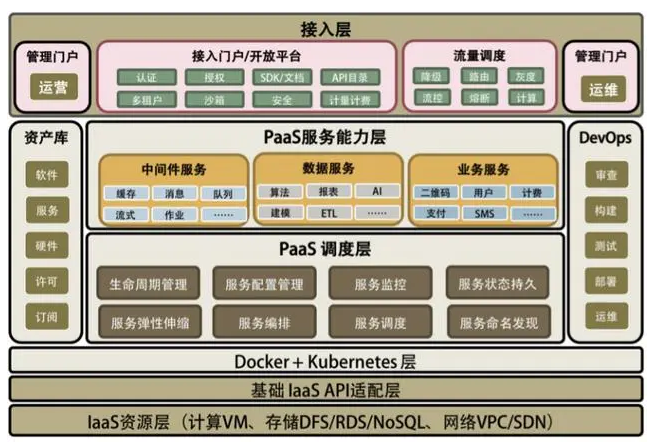
вЛИіЭъећЕФ PaaS ЦНЬЈЛсАќРЈвдЯТМИВПЗжЁЃ
PaaS ЕїЖШВу ЈC жївЊЪЧ PaaS ЕФздЖЏЛЏКЭЗжВМЪНЖдгкИпПЩгУИпадФмЕФЙмРэЁЃ
PaaS ФмСІЗўЮёВу ЈC жївЊЪЧ PaaS еце§ЬсЙЉИјгУЛЇЕФЗўЮёКЭФмСІЁЃ
PaaS ЕФСїСПЕїЖШ ЈC жївЊЪЧгыСїСПЕїЖШЯрЙиЕФЖЋЮїЃЌАќРЈЖдИпВЂЗЂЕФЙмРэЁЃ
PaaS ЕФдЫгЊЙмРэ ЈC ШэМўзЪдДПтЁЂШэМўНгШыЁЂШЯжЄКЭПЊЗХЦНЬЈУХЛЇЁЃ
PaaS ЕФдЫЮЌЙмРэ ЈC жївЊЪЧ DevOps ЯрЙиЕФЖЋЮїЁЃ
PaaS ЦНЬЈЕФЩњВњКЭдЫЮЌЯТУцЕФЭМЮвИјГіСЫвЛИіДѓИХЕФШэМўЩњВњЁЂдЫЮЌКЭЗўЮёНгШыЕФСїГЬЃЌЫќАбжЎЧАЕФЖЋЮїЖМДЎЦ№РДСЫЁЃ

ДгзѓЩЯПЊЪМШэМўЙЙНЈЃЌНјШыШэМўзЪВњПтЃЈDocker Registry+ вЛаЉШэМўЕФЖЈвхЃЉЃЌШЛКѓзп DevOps
ЕФСїГЬЃЌЭЈЙ§ећЬхМмЙЙПижЦЦїНјШыЩњВњЛЗОГЃЌЩњВњЛЗОГЭЈЙ§ПижЦЦїВйзї Docker+Kubernetes
МЏШКНјааШэМўВПЪ№КЭЩњВњБфИќЁЃ
ЦфжаЃЌЭЌВНЗўЮёЕФдЫаазДЬЌЃЌВЂЭЈЙ§ЩњУќжмЦкЙмРэРДФтКЯзДЬЌЃЌШчЭМгвВрВПЗжЫљЪОЁЃЗўЮёдЫааЪБЕФЪ§ОнЛсНјШыЕНЯрЙигІгУМрПиЃЌгІгУМрПижаЕФвЛаЉМрПиЪТМўЛсЭЌВНЕНЩњУќжмЦкЙмРэжаЃЌдйгЩЩњУќжмЦкЙмРэЦїРДзіГіОіЖЈЃЌЭЈЙ§ПижЦЦїРДЕїЖШЗўЮёдЫааЁЃЕБгІгУМрПижааФЗЂЯжСїСПБфЛЏЃЌвЊНјааЧПжЦадЩьЫѕЪБЃЌЫќЭЈЙ§ЩњУќжмЦкЙмРэРДЭЈжЊПижЦЯЕЭГНјааЩьЫѕЁЃ
зѓЯТЪЧЗўЮёНгШыЕФЯрЙизщМўЃЌжївЊЪЧЭјЙиЗўЮёЃЌвдМА API ОлКЯБрХХКЭСїГЬДІРэЁЃетЖдгІгкжЎЧАЫЕЙ§ЕФСїСПЕїЖШКЭ
API Gateway ЕФЯрЙиЙІФмЁЃ
|








