| БрМЭЦМі: |
ЮФеТжївЊНщЩмСЫИпПЩгУашвЊУцСйЕФГЃМћЮЪЬтЃЌдйДгММЪѕЗНУцНщЩмМИжжЬсИпЯЕЭГПЩППадЁЂПЩгУадЕФЗНЗЈЁЃ
РДздгкФћУЪдЦПЮЬУЃЌ,гЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ПЩППЕФЯЕЭГЪЧвЕЮёЮШЖЈЁЂПьЫйЗЂеЙЕФЛљЪЏЁЃ
ФЧУДЃЌШчКЮзіЕНЯЕЭГИпПЩППЁЂИпПЩгУФиЃП
ИпПЩгУЗНЗЈТл
ЯТУцЕФБэИёРяЃЌСаГіСЫИпПЩгУГЃМћЕФЮЪЬтКЭгІЖдДыЪЉЁЃ

ПЩРЉеЙ
РЉеЙЪЧзюГЃМћЕФЬсЩ§ЯЕЭГПЩППадЕФЗНЗЈЃЌЯЕЭГЕФРЉеЙПЩвдБмУтЕЅЕуЙЪеЯЃЌМДвЛИіНкЕуГіЯжСЫЮЪЬтдьГЩећИіЯЕЭГЮоЗЈе§ГЃЙЄзїЁЃ
ЛЛвЛИіНЧЖШНВЃЌвЛИіШнвзРЉеЙЕФЯЕЭГЃЌФмЙЛЭЈЙ§РЉеЙРДГЩБЖЕФЬсЩ§ЯЕЭГФмСІЃЌЧсЫЩгІЖдЯЕЭГЗУЮЪСПЕФЬсЩ§ЁЃ
вЛАуЕиЃЌРЉеЙПЩвдЗжЮЊДЙжБРЉеЙКЭЫЎЦНРЉеЙЃК
1ЁЂДЙжБРЉеЙ
дкЭЌвЛТпМЕЅдЊРяЬэМгзЪдДДгЖјТњзуЯЕЭГДІРэФмСІЩЯЩ§ЕФашЧѓЁЃ
БШШчЃЌЕБЛњЦїФкДцВЛЙЛЪБЃЌЮвУЧПЩвдАяЛњЦїдіМгФкДцЃЌЛђепЪ§ОнДцВЛЯТЪБЃЌЮвУЧЮЊЛњЦїЙвдиаТЕФДХХЬЁЃ
ДЙжБРЉеЙФмЙЛЬсЩ§ЯЕЭГДІРэФмСІЃЌЕЋВЛФмНтОіЕЅЕуЙЪеЯЮЪЬтЁЃ
гХЕуЃКРЉеЙМђЕЅЁЃ
ШБЕуЃКРЉеЙФмСІгаЯоЁЃ
2ЁЂЫЎЦНРЉеЙ
ЭЈЙ§діМгвЛИіЛђЖрИіТпМЕЅдЊЃЌВЂЪЙЕУЫќУЧЯёећЬхвЛбљЕФЙЄзїЁЃ
ЫЎЦНРЉеЙЃЌЭЈЙ§ШпгрВПЪ№НтОіСЫЕЅЕуЙЪеЯЃЌЭЌЪБгжЬсЩ§СЫЯЕЭГДІРэФмСІЁЃ
гХЕуЃКРЉеЙФмСІЧПЁЃ
ШБЕуЃКдіМгЯЕЭГИДдгЖШЃЌЮЌЛЄГЩБОИпЃЌЯЕЭГашвЊЪЧЮозДЬЌЕФЁЂПЩЗжВМЪНЕФЁЃ
ПЩРЉеЙадЯЕЪ§ scalability factor ЭЈГЃгУРДКтСПвЛИіЯЕЭГЕФРЉеЙФмСІЃЌЕБдіМг 1 ЕЅдЊЕФзЪдДЪБЃЌЯЕЭГДІРэФмСІжЛдіМгСЫ
0.95 ЕЅдЊЃЌФЧУДПЩРЉеЙадЯЕЪ§ОЭЪЧ 95%ЁЃЕБЯЕЭГдкГжајЕФРЉеЙжаЃЌПЩРЉеЙЯЕЪ§ЪМжеБЃГжВЛБфЃЌЮвУЧОЭГЦетжжРЉеЙЪЧЯпадПЩРЉеЙЁЃ
дкЪЕМЪгІгУжаЃЌЫЎЦНРЉеЙзюГЃМћЃК
1ЃЉЭЈГЃЮвУЧдкВПЪ№гІгУЗўЮёЦїЕФЪБКђЃЌЖМЛсВПЪ№ЖрЬЈЃЌШЛКѓЪЙгУ nginx РДзіИКдиОљКтЃЌnginx
ЪЙгУаФЬјЛњжЦРДМьВтЗўЮёЦїЕФе§ГЃгыЗёЃЌЮоЯьгІЕФЗўЮёОЭДгМЏШКжаЬоГ§ЁЃетбљЕФМЏШКжаУПЬЈЗўЮёЦїЕФНЧЩЋЪЧЯрЭЌЕФЃЌЭЌЪБЬсЙЉвЛбљЕФЗўЮёЁЃ
2ЃЉдкЪ§ОнПтЕФВПЪ№жаЃЌЮЊСЫЗРжЙЕЅЕуЙЪеЯЃЌвЛАуЛсЪЙгУвЛжїЖрДгЃЌЭЈГЃаДВйзїжЛЗЂЩњдкжїПтЁЃВЛЭЌЪ§ОнПтжЎМфНЧЩЋВЛЭЌЁЃЕБжїЛњхДЛњЪБЃЌвЛЬЈДгПтПЩвдздЖЏЧаЛЛЮЊжїЛњЬсЙЉЗўЮёЁЃ
ПЩИєРы
ИєРыЃЌЪЧЖдЪВУДНјааИєРыФиЃПЪЧЖдЯЕЭГЁЂвЕЮёЫљеМгаЕФзЪдДНјааИєРыЃЌЯожЦФГИівЕЮёЖдзЪдДЕФеМгУЪ§СПЃЌБмУтвЛИівЕЮёеМгУећИіЯЕЭГзЪдДЃЌЖдЦфЫћвЕЮёдьГЩгАЯьЁЃ
ИєРыМЖБ№АДСЃЖШДгаЁЕНДѓЃЌПЩвдЗжЮЊЯпГЬГиИєРыЁЂНјГЬИєРыЁЂФЃПщИєРыЁЂгІгУИєРыЁЂЛњЗПИєРыЁЃдкЪ§ОнПтЕФЪЙгУжаЃЌЛЙОГЃгУЕНЖСаДЗжРыЁЃ
1ЁЂЯпГЬГиИєРы
ВЛЭЌЕФвЕЮёЪЙгУВЛЭЌЕФЯпГЬГиЃЌБмУтЕЭгХЯШМЖЕФШЮЮёзшШћИпгХЯШМЖЕФШЮЮёЁЃЛђепИпгХЯШМЖЕФШЮЮёЙ§ЖрЃЌЕМжТЕЭгХЯШМЖШЮЮёгРдЖВЛЛсжДааЁЃ
2ЁЂНјГЬИєРы
Linux жагагУгкНјГЬзЪдДИєРыЕФ Linux CGroupЃЌЭЈЙ§ЮяРэЯожЦЕФЗНЪНЮЊНјГЬМфзЪдДПижЦЬсЙЉСЫМђЕЅЕФЪЕЯжЗНЪНЃЌЮЊ
Linux Container ММЪѕЁЂащФтЛЏММЪѕЕФЗЂеЙЕьЖЈСЫММЪѕЛљДЁ
3ЁЂФЃПщИєРыЁЂгІгУИєРы
КмЖрЯпЩЯЙЪеЯЕФЗЂЩњдДгкДњТыаоИФКѓЃЌВтЪдВЛЕНЮЛЕМжТЁЃАДееДњТыЛђвЕЮёЕФвзБфГЬЖШРДЛЎЗжФЃПщЛђгІгУЃЌАбБфЛЏНЯЩйЕФЛЎЗжЕНвЛИіФЃПщЛђгІгУжаЃЌБфЛЏНЯЖрЕФЛЎЗжЕНСэвЛИіФЃПщЛђгІгУжаЁЃМѕЩйДњТыаоИФгАЯьЕФЗЖЮЇЃЌвВОЭМѕЩйСЫВтЪдЕФЙЄзїСПЃЌМѕЩйСЫЙЪеЯГіЯжЕФИХТЪЁЃ
4ЁЂЛњЗПИєРы
жївЊЪЧЮЊСЫБмУтЕЅИіЛњЗПЭјТчЮЪЬтЛђЖЯЕчАЩЁЃ
5ЁЂЖСаДЗжРы
вЛЗНУцЃЌНЋЖдЪЕЪБадвЊЧѓВЛИпЕФЖСВйзїЃЌЗХЕН DB ДгПтЩЯжДааЃЌгаРћгкМѕЧс DB жїПтЕФбЙСІЁЃ
СэвЛЗНУцЃЌНЋвЛаЉКФЪБРыЯпвЕЮё sql ЗХЕН DB ДгПтЩЯжДааЃЌФмЙЛМѕЩйТ§
sql Жд DB жїПтЕФгАЯьЃЌБЃжЄЯпЩЯвЕЮёЕФЮШЖЈПЩППЁЃ
Нтёюад
дкШэМўЙЄГЬжаЃЌЖдЯѓжЎМфЕФёюКЯЖШОЭЪЧЖдЯѓжЎМфЕФвРРЕадЁЃЖдЯѓжЎМфЕФёюКЯдНИпЃЌЮЌЛЄГЩБОдНИпЃЌвђДЫЖдЯѓЕФЩшМЦгІЪЙФЃПщжЎМфЕФёюКЯЖШОЁСПаЁЁЃ
дкШэМўМмЙЙЩшМЦжаЃЌФЃПщжЎМфЕФНтёюЛђепЫЕЫЩёюКЯгаСНжжЃЌМйЩшгаСНИіФЃПщAЁЂBЃЌAвРРЕBЃК
ЕквЛжжЪЧЃЌФЃПщAКЭФЃПщBжЛЭЈЙ§НгПкНЛЛЅЃЌжЛвЊНгПкЩшМЦВЛБфЃЌФЧУДФЃПщBФкВПЯИНкЕФБфЛЏВЛгАЯьФЃПщAЖдФЃПщBЗўЮёФмСІЕФЯћЗбЁЃ
1ЃЉУцЯђНгПкЩшМЦЯТеце§ЪЕЯжСЫНЋНгПкЦѕдМЕФЖЈвхКЭНгПкЕФЪЕЯжГЙЕзЗжРыЃЌЪЕЯжБфЛЏВЛгАЯьЕННгПкЦѕдМЃЌздШЛВЛгАЯьЕНЛљгкНгПкЕФНЛЛЅЁЃ
2ЃЉФЃПщAКЭBжЎМфЕФЫЩёюКЯЃЌжївЊЭЈЙ§КЯРэЕФФЃПщЛЎЗжЁЂНгПкЩшМЦРДЭъГЩЁЃШчЙћГіЯжбЛЗвРРЕЃЌПЩвдНЋФЃПщAЁЂBЙВЭЌвРРЕЕФВПЗжвЦГ§ЕНСэвЛИіФЃПщCжаЃЌНЋAЁЂBжЎМфЕФЯрЛЅвРРЕЃЌзЊЛЛЮЊAЁЂBЭЌЪБЖдCЕФвРРЕЁЃ
ЕкЖўжжЪЧЃЌНЋЭЌВНЕїгУзЊЛЛГЩвьВНЯћЯЂНЛЛЅЁЃ
1ЃЉБШШчдкТђЛњЦБЯЕЭГжаЃЌЛњЦБжЇИЖЭъГЩКѓашвЊЭЈжЊГіЦБЯЕЭГГіЦБЁЂДњН№ШЏЯЕЭГЗЂШЏЁЃШчЙћЪЙгУЭЌВНЕїгУЃЌФЧУДГіЦБЯЕЭГЁЂДњН№ШЏЯЕЭГхДЛњЪЧЛсгАЯьЕНЛњЦБжЇИЖЯЕЭГЃЌШчЙћСэвЛИіЯЕЭГБШШчзЈГЕЯЕЭГвВЯывЊдкЛњЦБжЇИЖЭъГЩКѓЯђгУЛЇЭЦМізЈГЕЗўЮёЃЌФЧУДЭЌВНЕїгУФЃЪНЯТЛњЦБжЇИЖЯЕЭГОЭашвЊЮЊДЫЖјИФЖЏЃЌШнвзгАЯьКЫаФжЇИЖвЕЮёЕФПЩППадЁЃ
2ЃЉШчЙћЮвУЧНЋЭЌВНЕїгУЬцЛЛГЩвьВНЯћЯЂЃЌЛњЦБжЇИЖЯЕЭГЗЂЫЭЛњЦБжЇИЖГЩЙІЕФЯћЯЂЕНЯћЯЂжаМфМўЃЌГіЦБЯЕЭГЁЂДњН№ШЏЯЕЭГДгЯћЯЂжаМфМўЖЉдФЯћЯЂЁЃетбљвЛРДЃЌГіЦБЯЕЭГЁЂДњН№ШЏЯЕЭГЕФхДЛњвВОЭВЛЛсЖдЛњЦБжЇИЖЯЕЭГдьГЩШЮКЮгАЯьСЫЁЃзЈГЕЯЕЭГЯывЊжЊЕРЛњЦБжЇИЖЭъГЩетвЛЪТМўЃЌвВжЛашвЊДгЯћЯЂжаМфМўЖЉдФЯћЯЂМДПЩЃЌЛњЦБжЇИЖЯЕЭГЭъШЋВЛашвЊзіШЮКЮИФЖЏЁЃ
3ЃЉвьВНЯћЯЂНтёюЃЌЪЪКЯФЧаЉаХЯЂСїЕЅЯђСїЖЏЃЈРрЫЦЗЂВМ-ЖЉдФетбљЕФЃЉЃЌЪЕЪБадвЊЧѓВЛИпЕФЯЕЭГЁЃГЃМћЕФПЊдДЯћЯЂЖгСаПђМмгаЃКKafkaЁЂRabbitMQЁЂRocketMQЁЃ
ЯоСї
ЮЊЪВУДвЊзіЯоСїФиЃПОйвЛИіЩњЛюжаЕФР§згЃЌДѓМвдчЩЯЩЯАрЖМвЊМЗЕиЬњАЩЃЌЕиЬњеОдкдчИпЗхЕФЪБКђОГЃвЊЯожЦПЭСїЃЌЮЊЪВУДФиЃПгаШЫЛсОѕЕУетЪЧШЫЮЊЬэЖТЁЃецЪЧетбљТ№ЃПШчЙћВЛжДааПЭСїПижЦЃЌДѓМвЯыЯыЛсЪЧЪВУДГЁОАФиЃПеОЬЈЕНДІЖММЗТњСЫГЫПЭЃЌОЭЫуФуЪЙГіКщЛФжЎСІвВВЛвЛЖЈФмЫГРћЩЯГЕЃЌЧвЗЧГЃШнвзв§ЗЂжЋЬхХізВЃЌдьГЩГхЭЛЁЃгаСЫПЭСїПижЦжЎКѓЃЌЕиЬњеОВХФмБфЕУжШађОЎШЛЃЌДѓМвВХФмАВШЋЩЯЕиЬњЁЃ
вЛИіЯЕЭГЕФДІРэФмСІЪЧгаЩЯЯоЕФЃЌЕБЗўЮёЧыЧѓСПГЌЙ§ДІРэФмСІЃЌЭЈГЃЛсв§Ц№ХХЖгЃЌдьГЩЯьгІЪБМфбИЫйЬсЩ§ЁЃ
ШчЙћЖдЗўЮёеМгУЕФзЪдДСПУЛгадМЪјЃЌЛЙПЩФмвђЮЊЯЕЭГзЪдДеМгУЙ§ЖрЖјхДЛњЁЃ
вђДЫЃЌЮЊСЫБЃжЄЯЕЭГдкдтгіЭЛЗЂСїСПЪБЃЌФмЙЛе§ГЃдЫааЃЌашвЊЮЊФуЕФЗўЮёМгЩЯЯоСїЁЃ
ГЃМћЕФЯоСїЫуЗЈгаЃКТЉЭАЁЂСюХЦЭАЁЂЛЌЖЏДАПкМЦЪ§ЁЃ
ЗжРр
АДееМЦЪ§ЗЖЮЇЃЌПЩвдЗжЮЊЃКЕЅЛњЯоСїЁЂШЋОжЯоСїЁЃЕЅЛњЯоСїЃЌвЛАуЪЧЮЊСЫгІЖдЭЛЗЂСїСПЃЌЖјШЋОжЯоСїЃЌЭЈГЃЪЧЮЊСЫИјгаЯозЪдДНјааСїСПХфЖюЁЃ
АДееМЦЪ§жмЦкЃЌПЩвдЗжЮЊЃКQPSЁЂВЂЗЂЃЈСЌНгЪ§ЃЉЁЃ
АДееуажЕЩшЖЈЗНЪНЕФВЛЭЌЃЌПЩвдЗжЮЊЃКЙЬЖЈуажЕЁЂЖЏЬЌуажЕЁЃ
ТЉЭАЫуЗЈ
ЯТУцетеХЭМЃЌЪЧТЉЭАЕФЪОвтЭМЁЃТЉЭАЫуЗЈЫМТЗКмМђЕЅЃЌЫЎЃЈЧыЧѓЃЉЯШНјШыЕНТЉЭАРяЃЌТЉЭАвдвЛЖЈЕФЫйЖШГіЫЎЃЌЕБЫЎСїШыЫйЖШЙ§ДѓЪБЃЌЛсжБНгвчГіЃЌПЩвдПДГіТЉЭАЫуЗЈФмЧПааЯожЦЪ§ОнЕФДЋЪфЫйТЪЁЃТЉЭАЫуЗЈ(Leaky
Bucket)ЪЧЭјТчЪРНчжаСїСПећаЮЃЈTraffic ShapingЃЉЛђЫйТЪЯожЦЃЈRate LimitingЃЉЪБОГЃЪЙгУЕФвЛжжЫуЗЈЃЌЫќЕФжївЊФПЕФЪЧПижЦЪ§ОнзЂШыЕНЭјТчЕФЫйТЪЃЌЦНЛЌЭјТчЩЯЕФЭЛЗЂСїСПЁЃ
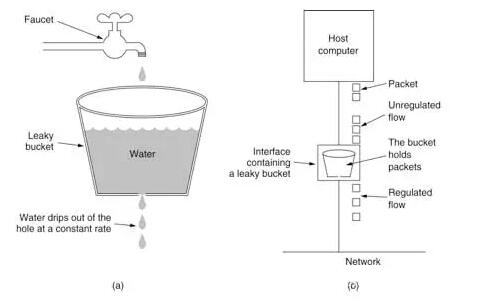
ТЉЭАЫуЗЈПЩвдЪЙгУ Redis ЖгСаРДЪЕЯжЃЌЩњВњепЗЂЫЭЯћЯЂЧАЯШМьВщЖгСаГЄЖШЪЧЗёГЌЙ§уажЕЃЌГЌЙ§уажЕдђЖЊЦњЯћЯЂЃЌЗёдђЗЂЫЭЯћЯЂЕН
Redis ЖгСажаЃЛ
ЯћЗбепвдЙЬЖЈЫйТЪДг Redis ЖгСажаШЁЯћЯЂЁЃRedis ЖгСадкетРяЦ№ЕНСЫвЛИіЛКГхГиЕФзїгУЃЌЦ№ЕНЯїЗхЬюЙШЁЂСїСПећаЮЕФзїгУЁЃ
СюХЦЭАЫуЗЈ
ЖдгкКмЖргІгУГЁОАРДЫЕЃЌГ§СЫвЊЧѓФмЙЛЯожЦЪ§ОнЕФЦНОљДЋЪфЫйТЪЭтЃЌЛЙвЊЧѓдЪаэФГжжГЬЖШЕФЭЛЗЂДЋЪфЁЃ
етЪБКђТЉЭАЫуЗЈПЩФмОЭВЛКЯЪЪСЫЃЌСюХЦЭАЫуЗЈИќЮЊЪЪКЯЁЃ
СюХЦЭАЫуЗЈЕФдРэЪЧЯЕЭГЛсвдвЛИіКуЖЈЕФЫйЖШЭљЭАРяЗХШыСюХЦЃЌЖјШчЙћЧыЧѓашвЊБЛДІРэЃЌдђашвЊЯШДгЭАРяЛёШЁвЛИіСюХЦЃЌЕБЭАРяУЛгаСюХЦПЩШЁЪБЃЌдђОмОјЗўЮёЁЃ
ЭАРяФмЙЛДцЗХСюХЦЕФзюИпЪ§СПЃЌОЭЪЧдЪаэЕФЭЛЗЂДЋЪфСПЁЃ

Guava жаЕФЯоСїЙЄОп RateLimiterЃЌЦфдРэОЭЪЧСюХЦЭАЫуЗЈЁЃ
ЛЌЖЏДАПкМЦЪ§ЗЈ
МЦЪ§ЗЈЪЧЯоСїЫуЗЈРязюШнвзРэНтЕФвЛжжЃЌИУЗНЗЈЭГМЦзюНќвЛЖЮЪБМфЕФЧыЧѓСПЃЌШчЙћГЌЙ§вЛЖЈЕФуажЕЃЌОЭПЊЪМЯоСїЁЃ
дк TCP ЭјТчавщжаЃЌвВгУЕНСЫЛЌЖЏДАПкРДЯожЦЪ§ОнДЋЪфЫйТЪЁЃ

ЛЌЖЏДАПкМЦЪ§гаСНИіЙиМќЕФвђЫиЃКДАПкЪБГЄЁЂЙіЖЏЪБМфМфИєЁЃЙіЖЏЪБМфМфИєвЛАуЕШгкЩЯЭМжаЕФвЛИіЭА
bucketЃЌДАПкЪБГЄГ§вдЙіЖЏЪБМфМфИєЃЌОЭЪЧвЛИіДАПкЫљАќКЌЕФ bucket Ъ§ФПЁЃ
ЖЏЬЌЯоСї
вЛАуЧщПіЯТЕФЯоСїЃЌЖМашвЊЮвУЧЪжЖЏЩшЖЈЯоСїуажЕЃЌВЛНіЗБЫіЃЌЖјЧвШнвзвђЯЕЭГЕФЗЂВМЩ§МЖЖјЙ§ЪБЁЃЮЊДЫЃЌЮвУЧПМТЧИљОнЯЕЭГИКдиРДЖЏЬЌОіЖЈЪЧЗёЯоСїЃЌЖЏЬЌМЦЫуЯоСїуажЕЁЃПЩвдВЮПМЕФЯЕЭГИКдиВЮЪ§гаЃКLoadЁЂCPUЁЂНгПкЯьгІЪБМфЕШЁЃ 
НЕМЖ
вЕЮёНЕМЖЃЌЪЧжИЮўЩќЗЧКЫаФЕФвЕЮёЙІФмЃЌБЃжЄКЫаФЙІФмЕФЮШЖЈдЫааЁЃМђЕЅРДЫЕЃЌвЊЪЕЯжгХбХЕФвЕЮёНЕМЖЃЌашвЊНЋЙІФмЪЕЯжВ№ЗжЕНЯрЖдЖРСЂЕФВЛЭЌДњТыЕЅдЊЃЌЗжгХЯШМЖНјааИєРыЁЃдкКѓЬЈЭЈЙ§ПЊЙиПижЦЃЌНЕМЖВПЗжЗЧжїСїГЬЕФвЕЮёЙІФмЃЌМѕЧсЯЕЭГвРРЕКЭадФмЫ№КФЃЌДгЖјЬсЩ§МЏШКЕФећЬхЭЬЭТТЪЁЃ
НЕМЖЕФжиЕуЪЧЃКвЕЮёжЎМфгагХЯШМЖжЎЗжЁЃНЕМЖЕФЕфаЭгІгУЪЧЃКЕчЩЬЛюЖЏЦкМфЙиБеЗЧКЫаФЗўЮёЃЌБЃжЄКЫаФТђТђТђвЕЮёЕФе§ГЃдЫааЁЃ
вЕЮёНЕМЖЭЈГЃашвЊЭЈЙ§ПЊЙиЙЄзїЃЌПЊЙивЛАузіГЩХфжУЗХдкзЈУХЕФХфжУЯЕЭГЃЌХфжУЕФаоИФзюКУФмЙЛЪЕЪБЩњаЇЃЌБЯОЙвЊЪЧЛЙЕУаоИФДњТыЗЂВМФЧОЭЬЋ
low СЫЁЃПЊдДЕФХфжУЯЕЭГгаАЂРяЕФdiamondЁЂаЏГЬЕФApolloЁЂАйЖШЕФdisconfЁЃ
НЕМЖЭљЭљашвЊЖЕЕзЗНАИЕФХфКЯЃЌБШШчЯЕЭГВЛПЩгУЕФЪБКђЃЌЖдгУЛЇНјааЬсЪОЃЌАВИЇгУЛЇЁЃЬсЪОЫфШЛВЛЦ№блЃЌЕЋЪЧФмЙЛгааЇЕФЬсЩ§гУЛЇЬхбщЁЃ
ШлЖЯ
ЬИЕНШлЖЯЃЌВЛЕУВЛЬсОЕфЕФЕчСІЯЕЭГжаЕФБЃЯеЫПЃЌЕБИКдиЙ§ДѓЃЌЛђепЕчТЗЗЂЩњЙЪеЯЪБЃЌЕчСїЛсВЛЖЯЩ§ИпЃЌЮЊЗРжЙЩ§ИпЕФЕчСїгаПЩФмЫ№ЛЕЕчТЗжаЕФФГаЉживЊЦїМўЛђЙѓжиЦїМўЃЌЩеЛйЕчТЗЩѕжСдьГЩЛ№джЁЃБЃЯеЫПЛсдкЕчСївьГЃЩ§ИпЕНвЛЖЈЕФИпЖШКЭШШЖШЕФЪБКђЃЌздЩэШлЖЯЧаЖЯЕчСїЃЌДгЖјЦ№ЕНБЃЛЄЕчТЗАВШЋдЫааЕФзїгУЁЃ
ЭЌбљЃЌдкЗжВМЪНЯЕЭГжаЃЌШчЙћЕїгУЕФдЖГЬЗўЮёЛђепзЪдДгЩгкФГжждвђЮоЗЈЪЙгУЪБЃЌУЛгаетжжЙ§диБЃЛЄЃЌОЭЛсЕМжТЧыЧѓзшШћдкЗўЮёЦїЩЯЕШД§ДгЖјКФОЁЗўЮёЦїзЪдДЁЃКмЖрЪБКђИеПЊЪМПЩФмжЛЪЧЯЕЭГГіЯжСЫОжВПЕФЁЂаЁЙцФЃЕФЙЪеЯЃЌШЛЖјгЩгкжжжждвђЃЌЙЪеЯгАЯьЕФЗЖЮЇдНРДдНДѓЃЌзюжеЕМжТСЫШЋОжадЕФКѓЙћЁЃЖјетжжЙ§диБЃЛЄОЭЪЧДѓМвЫзГЦЕФШлЖЯЦї(Circuit
Breaker)ЁЃ
ЯТУцетеХЭМЃЌОЭЪЧШлЖЯЦїЕФЛљБОдРэЃЌАќКЌШ§ИізДЬЌЃК
1ЃЉЗўЮёе§ГЃдЫааЪБЕФ Closed зДЬЌЃЌЕБЗўЮёЕїгУЪЇАмСПЛђЪЇАмТЪДяЕНуажЕЪБЃЌШлЖЯЦїНјШы Open
зДЬЌ
2ЃЉдк Open зДЬЌЃЌЗўЮёЕїгУВЛЛсеце§ШЅЧыЧѓЭтВПзЪдДЃЌЛсПьЫйЪЇАмЁЃ
3ЃЉЕБНјШы Open зДЬЌвЛЖЮЪБМфКѓЃЌНјШы Half-OpenзДЬЌЃЌашвЊШЅГЂЪдЕїгУМИДЮЗўЮёЃЌМьВщЙЪеЯЕФЗўЮёЪЧЗёЛжИДЁЃШчЙћГЩЙІдђШлЖЯЦїЙиБеЃЌШчЙћЪЇАмЃЌдђдйДЮНјШы
Open зДЬЌЁЃ

ФПЧАБШНЯСїааЕФНЕМЖШлЖЯПђМмЃЌЪЧгЩ Netflix ПЊдДЕФ Hystrix
ПђМм
ЗЂВМЯрЙи
ФЃПщМЖздЖЏЛЏВтЪд
жкЫљжмжЊЃЌвЛИіЯюФПЩЯЯпЧАашвЊОРњбЯИёЕФВтЪдЙ§ГЬЃЌЕЋЪЧЫцзХвЕЮёВЛЖЯЕќДњЁЂЯЕЭГШевцИДдгЃЌбаЗЂЙЄГЬЪІЁЂВњЦЗОРэЁЂВтЪдЙЄГЬЪІЕШЖМдкВтЪдЙ§ГЬжаЭЖШыСЫДѓСПОЋСІЃЌЖјвЛИіИіЯпЩЯЙЪеЯШДБэУїВтЪдаЇЙћВЂВЛЪЧФЧУДЭъУРЁЃОПЦфдвђЃЌФПЧАЕФВтЪдЙЄзїжївЊДцдкСНЗНУцЮЪЬтЃК
1ЃЉВтЪдЗЖЮЇФбвдНчЖЈ
ЫцзХвЕЮёТпМЕФВЛЖЯЕќДњЁЂЯЕЭГЕФВЛЖЯВ№ЗжгыЯИЛЏЃЌОЋШЗЦРЙРЯюФПИФЖЏЕФгАЯьЗЖЮЇБфЕУдНРДдНРЇФбЃЌДгЖјКмФбЪсРэГіИВИЧШЋУцЕФВтЪдЕуЁЃ
2ЃЉcaseбщжЄГЩБОЙ§Ип
бщжЄвЛИіcaseашвЊЙЙдьВтЪдГЁОАЃЌАќРЈЪ§ОнЕФзМБИКЭдЫааЛЗОГЕФзМБИЃЌЕБcaseСПНЯДѓЛђепДцдквЛаЉЩцМАЖрИіЯЕЭГФЃПщЧвДЅЗЂЬѕМўИДдгЕФcaseЪБЃЌетвЛЙ§ГЬвВНЋЛЈЗбДѓСПЕФЪБМфЁЃ
НтОіЩЯЪіЮЪЬтПЩвдЪЙгУФЃПщМЖздЖЏЛЏВтЪдЁЃОпЬхЗНАИЪЧЃКеыЖдФГвЛФЃПщЃЌЪеМЏФЃПщЯпЩЯЕФЪфШыЁЂЪфГіЁЂдЫааЪБЛЗОГЕШаХЯЂЃЌдкРыЯпВтЪдЛЗОГЭЈЙ§Ъ§ОнmockФЃПщЯпЩЯГЁОАЃЌЛиЗХЪеМЏЕФЯпЩЯЪфШыЃЌЯрЭЌЕФЪфШыБШНЯВтЪдГЁОАгыЯпЩЯЪеМЏЕФЪфГізїЮЊВтЪдНсЙћЁЃ
ФЃПщМЖздЖЏЛЏВтЪдЭЈЙ§МђЛЏИДдгЯЕЭГжаЕФВЛБфвђЫиЃЈmockЃЉЃЌНЋЯЕЭГЕФВтЪдБпНчЪеТЃЕНИФЖЏФЃПщЃЌНЋИДдгЯЕЭГЕФећЬхВтЪдзЊЛЏЮЊИФЖЏФЃПщЕФЕЅдЊВтЪдЁЃжївЊЪЪгУгкЯЕЭГвЕЮёЛиЙщЃЌЖдЯЕЭГФкВПжиЙЙГЁОАгШЦфЪЪгУЁЃ
ОпЬхШчКЮЪеМЏЯпЩЯЪ§ОнФиЃПгаСНжжЗНЗЈЃК
1ЃЉAOPЃКУцЯђЧаУцБрГЬЃЌЖЏЬЌЕижЏШыДњТыЃЌЖддгаДњТыЕФЧжШыадНЯаЁЁЃ
2ЃЉТёЕуЃККмЖрЙЋЫОЖМПЊЗЂСЫвЛЯТЛљДЁзщМўЃЌПЩвддкетаЉЛљДЁзщМўжаЧЖШыЪ§ОнЪеМЏЕФДњТыЁЃ
ИќЖрЯИНкЃЌПЩвдВщПДЯТУцВЮПМЮФЯзжаЕФЮФеТЃКQunar здЖЏЛЏВтЪдПђМм
ARESЁЃ
ЛвЖШЗЂВМ & ЛиЙі
ЕЅЕуКЭЗЂВМЪЧЯЕЭГИпПЩгУзюДѓЕФЕаШЫЁЃвЛАудкЯпЩЯГіЯжЙЪеЯКѓЃЌЕквЛИівЊПМТЧЕФОЭЪЧИеИегаУЛгаДњТыЗЂВМЁЂХфжУЗЂВМЃЌШчЙћгаЕФЛАОЭЯШЛиЙіЁЃЯпЩЯЙЪеЯзюживЊЕФЪЧПьЫйЛжИДЃЌШчЙћЕШФуЯИЯИПДДњТыевЕНЮЪЬтЃЌУЛзМЖљАыЬьОЭЙ§ШЅСЫЁЃ
ЮЊСЫМѕЩйЗЂВМв§Ц№ЮЪЬтЕФбЯжиГЬЖШЃЌЭЈГЃЛсЪЙгУЛвЖШЗЂВМВпТдЁЃЛвЖШЗЂВМЪЧЫйЖШгыАВШЋадзїЮЊЭзаЁЃЫћЪЧЗЂВМжкЖрБЃЯеЕФзюКѓвЛЕРЃЌЖјВЛЪЧЮЈвЛЕФвЛЕРЁЃ
зіЛвЖШЗЂВМЃЌШчЙћЪЧдШЫйЕФЃЌЫЕУїУЛгаРэНтЛвЖШЗЂВМЕФвтвхЁЃвЛАуРДЫЕНзЖЮбЁдёЩЯДг 1% -> 10%
-> 100% ЕФжИЪ§аЭдіГЄЁЃетИіНзЖЮЃЌЪЧИљОнОпЬхвЕЮёВЛЭЌАДЮЌЖШШЅЯИЗжЕФЁЃ
етРяУцЕФжиЕудкгк 1% ВЂВЛШЋЪЧЫцЛњбЁдёЕФЃЌЖјЪЧИљОнвЕЮёЬиЕуЁЂЪ§ОнЬиЕубЁдёЕФвЛХњгаМЋЧПЕФДњБэадЕФЪЕР§ЃЌШЅзіЛвЖШЗЂВМЕФаЁАзЪѓЁЃЩѕжСгкУПДЮЗЂВМЕФ
ЕквЛНзЖЮгУЛЇ(ЮвУЧНа Canary/Н№ЫПШИ)ЃЌИљОнУПДЮЗЂВМЕФЬиЕуВЛЭЌЃЌЪЧШЫЮЊЬєбЁЕФЁЃ
ЗЂВМжЎЧАБиаыжЦЖЈЯъЯИЕФЛиЙіВНжшЃЌЛиЙіЪЧНтОіЗЂВМв§Ц№ЕФЙЪеЯЕФзюПьЕФЗНЗЈЁЃ
ЙЪеЯбнСЗ
ЮЊЪВУДвЊзіЙЪеЯбнСЗФиЃПОЭИњдкВтЪдвЕЮёЙІФмЪБЃЌВЛНівЊВтЪде§ГЃЕФЧыЧѓФмЗёе§ШЗДІРэЃЌвВвЊВтЪдвьГЃЕФЧыЧѓФмЗёЕУЕНЪЪЕБЕФДІРэвЛбљЁЃеОдкШЋОжЕФНЧЖШПДЃЌЮвУЧвВЯЃЭћБЃжЄФГИіЛњЦїЛђФГИіЗўЮёЙвЕєЪБЃЌОЁСПВЛгАЯьЯЕЭГећЬхЕФПЩгУадЃЌММЪѕЩЯвЊППЮозДЬЌЗўЮёЁЂШпгрВПЪ№ЁЂНЕМЖЕШЁЃЪЕМЪжаШчКЮВтЪдетбљЕФвьГЃЧщПіФиЃП
Netflix ПЊдДСЫвЛИіЙЄОп Chaos MonkeyЃЌетЪЧвЛЬзгУРДЙЪвтАбЗўЮёЦїИуЯТЯпЕФШэМўЃЌПЩвдгУРДВтЪдЯЕЭГЕФНЁзГадКЭЛжИДФмСІЁЃ
здЖЏЛЏдЫЮЌ-ЙЪеЯздгњ
дкЮФеТАЂРяШчКЮзіЕНАйЭђСПМЖгВМўЙЪеЯздгњРяЃЌНщЩмСЫШчКЮЪЕЯжгВМўЙЪеЯдЄВтЁЂЗўЮёЦїздЖЏЯТЯпЁЂЗўЮёздгњвдМАМЏШКЕФздЦНКтжиНЈЃЌеце§дкгАЯьвЕЮёжЎЧАЪЕЯжгВМўЙЪеЯздЖЏБеЛЗВпТдЃЌЖдгкГЃМћЕФгВМўЙЪеЯЮоашШЫЙЄИЩдЄМДПЩздЖЏБеЛЗНтОіЁЃ
ЪТМўЯЕЭГ
AWS гавЛИі CloudTrail ЯЕЭГЃЌзЈУХМЧТМжиДѓЛюЖЏЪТМўЃЌПЩвдМђЛЏАВШЋадЗжЮіЁЂзЪдДИќИФИњзйКЭЮЪЬтХХВщЙЄзїЁЃЯЕЭГЗЂВМЁЂХфжУБфИќЪЧв§ЗЂЙЪеЯЕФвЛДѓвђЫиЃЌЮЂЗўЮёЛЏЕФЯЕЭГМмЙЙРяЃЌгаЪБФГИіЕзВуЯЕЭГЕФБфИќЃЌв§Ц№ЗДгГЁЂГіЯжЙЪеЯЕФЭљЭљЪЧЩЯВужБНгУцЖдгУЛЇЕФЯЕЭГЁЃгаСЫЪТМўЯЕЭГЃЌГіЯжЙЪеЯКѓЃЌПЩвдПьЫйВщПДдкЙЪеЯЪБМфЕуЃЌЯрЙиСЊЯЕЭГЪЧЗёгаБфИќЃЌЪЧЗёЪЧв§Ц№ЙЪеЯЕФИљБОдвђЃП
ЪТМўЯЕЭГЕФГіЯжЃЌПЩвдАяжњгІгУПЊЗЂепПьЫйЖЈЮЛЁАЕзВуЯЕЭГБфИќв§ЗЂЩЯВуЯЕЭГвьГЃЁБетвЛРрЙЪеЯЕФИљБОдвђЁЃ
ЦфЫћЩшМЦПМТЧ
1ЃЉЩшжУГЌЪБ
ЧыЧѓЖдЭтНгПкЕФЪБКђЃЌашвЊЩшжУКЯРэЕФГЌЪБЪБМфЃЌБмУтЭтВПНгПкЙвЕєЪБЃЌзшШћећИіЯЕЭГЁЃ
2ЃЉЪЇАмжиЪд
ЪЇАмжиЪдФмЙЛЬсИпГЩЙІТЪЃЌЕЋЪЧвВЛсдьГЩЯьгІЪБМфБфТ§ЃЌЗўЮёЬсЙЉЗНбЙСІБЖдіЁЃОпЬхвЊВЛвЊжиЪдвЊИљОнОпЬхЧщПіОіЖЈЃКЖдЯьгІЪБМфгавЊЧѓТ№ЃПНгПкЪЇАмТЪШчКЮЃПжиЪдЛсВЛЛсдьГЩбЉБРЃП
змНс

|








