| БрМЭЦМі: |
БОЮФжївЊНВНтСЫЪ§ОнПтЗжВМЪНИФдьЕФЭООЖЁЂЗжВМЪНЪ§ОнПтзмЬхМмЙЙЁЂCAPгыBASEЕФОёдёМАЗжВМЪНЪ§ОнПтШчКЮЪЕЯжPITRЕШЃЌЯЃЭћЖдФуЕФбЇЯАгаАяжњЁЃ
РДздгк51CTOЃЌ,гЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
вјаавЕДгзюГѕЕФЪжЙЄМЧеЫЕНЛсМЦЕчЫуЛЏЃЌЕНН№ШкЕчзгЛЏЃЌдйЕНЯждкЕФН№ШкПЦММЃЌПЩвдПДЕНН№ШкгыПЦММЕФНсКЯдНРДдННєУмЃЌШЫЙЄжЧФмЁЂДѓЪ§ОнЁЂЮяСЊЭјЁЂЧјПщСДЕШаТаЫММЪѕИФБфСЫН№ШкЕФНЛвзЗНЪНЃЌЮЊН№ШкаавЕЕФДДаТЧАааЬсЙЉСЫдДдДВЛЖЯЕФЖЏСІЁЃЭЌЪБЛЅСЊЭјН№ШкЕФаЫЦ№ЪЧвЛАбЫЋШаНЃЃЌДјРДСЫЛњгіЕФЭЌЪБвВДјРДСЫЬєеНЁЃ
ЦеЛнН№ШкЪЙЕУН№ШкЕФУХМїНЕЕЭЃЌИќЖрЕФЦеЭЈДѓжкВЮгыЕНН№ШкЛюЖЏжаЃЌетШУН№ШкаХЯЂЯЕЭГГаЪмСЫдНРДдНДѓЕФбЙСІЁЃгкЪЧЮвУЧПЩвдПДЕНДѓаЭЩЬвЕвјааЁЂБЃЯеЙЋЫОЁЂжЄШЏЙЋЫОЁЂНЛвзЫљЕШКЫаФНЛвзЯЕЭГЖМдкЗзЗзНјааЗжВМЪНИФдьЃЌЦфжаЪ§ОнПтзїЮЊгазДЬЌЕФгІгУЃЌГЩЮЊСЫаХЯЂЯЕЭГжаЮЈвЛЕФЕЅЕуЃЌГаЕЃСЫЫљгаРДздЩЯВугІгУЕФбЙСІЁЃЫцзХЪ§ОнПтЦПОБЕФЭЙЯдЃЌНјааЗжВМЪНИФдьЦШдкУМНоЁЃ
Ъ§ОнПтЗжВМЪНИФдьЕФЭООЖ
Ъ§ОнПтНјааЗжВМЪНИФдьжївЊгаШ§жжЭООЖЃКЗжВМЪНЗУЮЪПЭЛЇЖЫЁЂЗжВМЪНЗУЮЪжаМфМўЁЂЗжВМЪНЪ§ОнПтЁЃгЩгкЦфЗжВМЪНФмСІЪЕЯждкВЛЭЌЕФВуДЮ(гІгУВуЁЂжаМфВуЁЂЪ§ОнПтВу)ЃЌЖдгІгУГЬађгаВЛЭЌЕФЧжШыГЬЖШЃЌЦфжаЗжВМЪНЗУЮЪПЭЛЇЖЫЖдгІгУЧжШыадзюДѓЃЌИФдьФбЖШзюДѓЃЌЖјЗжВМЪНЪ§ОнПтЗНАИЖдгІгУЧжШыадзюаЁЃЌЕЋЪЧМмЙЙЩшМЦМАбаЗЂФбЖШзюДѓЁЃ
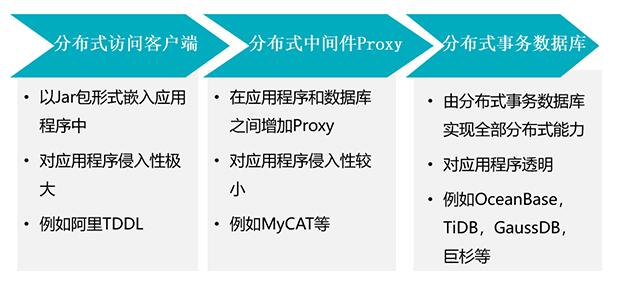
ЗжВМЪНЪ§ОнПтзмЬхМмЙЙ
ЦфЪЕЕБЧАЪаУцЩЯЕФЗжВМЪНЪ§ОнПтзмЬхМмЙЙЖМЪЧРрЫЦЕФЃЌгЩБиВЛПЩЩйЕФШ§ИізщМўзщГЩЃКНгШыНкЕуЁЂЪ§ОнНкЕуЁЂШЋОжЪТЮёЙмРэЦїЁЃзмЬхМмЙЙШчЯТЃЌНгШыНкЕуИКд№sqlНтЮіЃЌЩњГЩЗжВМЪНжДааМЦЛЎЃЌsqlзЊЗЂЃЌЪ§ОнЛузмЕШ;Ъ§ОнНкЕуИКд№Ъ§ОнДцДЂгыдЫЫу;ШЋОжЪТЮёЙмРэЦїИКд№ШЋОжЪТЮёКХЕФЩњГЩЃЌБЃжЄЪТЮёЕФШЋОжвЛжТадЁЃетИіМмЙЙЛђЖрЛђЩйЖМЪмЕНСЫGoogle
Spanner F1ТлЮФЕФгАЯьЃЌетЦЊЮФеТжївЊЗжЮіСЫетМИИізщМўдкЪЕЯжЩЯгаЪВУДФбЕуЃЌИУШчКЮНјааМмЙЙЩшМЦЁЃ

СННзЖЮЬсНЛЕФЮЪЬт
ЮвУЧжЊЕРСННзЖЮЬсНЛЪЧзшШћадавщЃЌетвВЪЧЫќзюДѓЕФЮЪЬтЁЃЯТЭМвдpgxcМмЙЙЯТЕФСННзЖЮЬсНЛЮЊР§ЃЌжївЊЗжЮЊМИИіНзЖЮЃК
ЂйЃКCN prepare ->ЂкЃКЫљгаDN prepare ->ЂлЃКCN commit->ЂмЃКЫљгаDN
commit
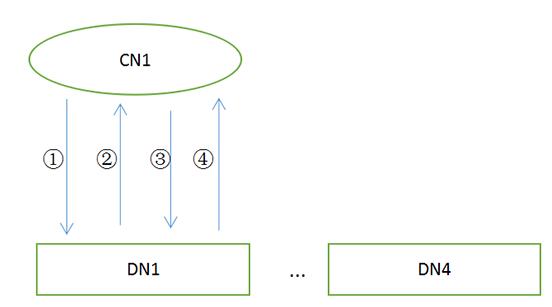
ЪдЯывЛЯТШчЙћдкcn commitНзЖЮЗЂЩњcn/dnхДЛњЛсЗЂЩњЪВУД?
ШчЙћдкcnЯТЗЂЭъcn commitУќСюКѓхДЛњЃЌетЪБdnЪеЕНcommitУќСюКѓЛсНјааЬсНЛЃЌЕЋЪЧЗЕЛиcommit
okЪБЗЂЩњcnхДЛњЃЌЪТЮёНјШызшШћзДЬЌЁЃШчЙћcnЯТЗЂcommitжЎКѓФГИіdnЗЂЩњхДЛњЃЌдђЛсдьГЩФГаЉdn
commitГЩЙІЃЌФГаЉdn commitЪЇАмЃЌдьГЩВЛвЛжТЃЌЕЋЪЧШчЙћdnжиаТЦєЖЏКѓЛсМЬајШЅcnЩЯФУЪТЮёЬсНЛаХЯЂЃЌЗЂЯжЪЧcommitзДЬЌЃЌдђЛсМЬајжДааcommitВйзїЃЌЬсНЛжЎЧАЕФЪТЮёЁЃ
дкетИіЕиЗНЮвУЧПЩвдЬНЬжвЛИіИќМЋЖЫЕФЧщПіЃЌШчЙћДЫЪБcnвВхДЛњСЫЃЌФЧУДЪЇАмЕФdnжиЦєКѓШЅcnФУзДЬЌЗЂЯжФУВЛЕНЃЌетЪБетИіЪЇАмdnЩЯЕФЪТЮёОЭДІгквЛИіЮДОіЬЌЃЌВЛжЊЕРЪЧгІИУЬсНЛЛЙЪЧЛиЙіЃЌетЪБКђгІИУгавЛИіНјГЬФмЙЛДгЦфЫћdnЩЯЗЂЯжИУзДЬЌВЂБЈИцИјЙЪеЯdnЃЌЭЈжЊЫќНјааЬсНЛЁЃетИіНЧЩЋОЭЪЧpgxc_cleanНјГЬЃЌЦфЪЕжЎЧАМИжжЧщПіЯТЕФЪТЮёЕФЛиЙівВЪЧИУНјГЬЕФЙЄзїЁЃФЧЮвУЧдйЩюШывЛЯТЃЌШчЙћИУdnЪЧЪТЮёЕФЮЈвЛВЮгыепЃЌФЧУДДЫЪБpgxc_cleanОЭЮоЗЈДгЦфЫћdnвдМАcnЛёШЁзДЬЌЃЌетЪБИУdnОЭЪЧеце§ЕФЮДОіЬЌСЫЁЃ
ЮЊСЫНтОіСННзЖЮЬсНЛЕФзшШћЮЪЬтЃЌГіЯжСЫШ§НзЖЮЬсНЛЃЌШ§НзЖЮЬсНЛдкcommitжЎЧАв§ШыСЫcancommitЕФЙ§ГЬЃЌЭЌЪБМгШыГЌЪБЛњжЦЁЃвђЮЊШчЙћаЕїепЗЂЩњхДЛњЃЌВЮгыепЮоЗЈЕУжЊаЕїепЕНЕзЗЂГіЕФЪЧcommitЛЙЪЧabortЃЌШ§НзЖЮЬсНЛcancommitЙ§ГЬОЭЪЧИцжЊВЮгыепЮвЗЂЫЭЕФЪЧcommitЛђепabortУќСюЃЌетЪБШчЙћаЕїепЗЂЩњЪЇАмЃЌВЮгыепЕШД§ГЌЪБЪБМфКѓПЩвдбЁГіаТЕФаЕїепЃЌЖјИУаЕїепЪЧжЊЕРгІИУЗЂГіЪВУДУќСюЁЃ
ЫфШЛШ§НзЖЮЬсНЛНтОіСЫзшШћЮЪЬтЃЌЕЋЪЧЮоЗЈНтОіадФмЮЪЬтЃЌЗжВМЪНЯЕЭГжаЮЊСЫБЃжЄЪТЮёвЛжТадашвЊИњУПИіВЮгыепЭЈаХЃЌвЛИіЪТЮёЕФЬсНЛКЭВЮгыашвЊЗжВМЪНЯЕЭГжаУПИіНкЕуЕФВЮгыЃЌБиШЛДјРДбгЪБЃЌВЛЙ§дкЭђезЁЂinfinibandЁЂroceИпЫйЭјТчЕФжЇГжЯТвбОВЛдйЪЧЮЪЬтСЫЁЃ
CAPгыBASEЕФОёдё
ЮвУЧжЊЕРЗжВМЪНЯЕЭГЮоЗЈеНЪЄCAPЁЃФЧУДдкЩшМЦЗжВМЪНЯЕЭГЕФЪБКђИУШчКЮНјааШЁЩс?ЪзЯШP(ЗжЧјШнДэад)ЪЧБиаыБЃжЄЕФЃЌвђЮЊЗжВМЪНЯЕЭГБиШЛЪЧЖрИіНкЕу(ЗжЧј)ЭЈЙ§ЭјТчНјааЛЅСЊЃЌЖјЭјТчЪЧВЛПЩППЕФЃЌЗжВМЪНЯЕЭГЪЧЮЊСЫБмУтЕЅЕуЙЪеЯЃЌШчЙћвђЮЊЭјТчЮЪЬтЛђепФГаЉНкЕуЪЇАмдьГЩећЬхЯЕЭГВЛПЩгУЃЌФЧУДвВВЛЗћКЯЗжВМЪНЯЕЭГЕФЩшМЦГѕждЁЃШчЙћБЃжЄA(ПЩгУад)ЃЌФЧУДЕБЭјТчЪЇАмЪБЃЌЭјТчИєРыЕФВЛЭЌЧјгђОЭвЊМЬајЬсЙЉЗўЮёЃЌФЧУДОЭЛсдьГЩВЛЭЌЗжЧјЕФЪ§ОнВЛвЛжТ(ФдСб);ШчЙћБЃжЄC(вЛжТад)ЃЌФЧУДЭјТчЪЇАмЪБЃЌОЭашвЊЕШД§ВЛЭЌЭјТчЗжЧјЕФНкЕуЭЌВНЭъЪ§ОнЃЌШчЙћЭјТчвЛжБЪЇАмЃЌФЧУДЯЕЭГОЭЛсвђЮЊЮоЗЈЭЌВНЖјвЛжБВЛПЩгУЁЃ
2PCОЭЪЧЕфаЭЕФЮўЩќПЩгУадБЃжЄвЛжТадЕФР§згЃЌЖјBASE(basically availableЃЌsoft
stateЃЌeventual consistency)ОЭЪЧЮўЩќвЛжТадБЃжЄПЩгУадЕФР§згЃЌвђЮЊзіЕНЪЕЪБЕФЧПвЛжТвЊЮўЩќЕФДњМлЬЋДѓСЫЃЌЫќдЪаэЪ§ОндкФГаЉЪБМфДАПкФкЕФВЛвЛжТЃЌЭЈЙ§МЧТМДАПкФкЕФУПвЛИіСйЪБзДЬЌШежОзіЕНдкЯЕЭГЙЪеЯЪБЃЌЭЈЙ§ШежОМЬајЭъГЩЮДЭъГЩЕФЙЄзїЛђепШЁЯћвбОЭъГЩЕФЙЄзїЛиЭЫЕНГѕЪМзДЬЌЃЌетжжЗНЪНБЃжЄСЫзюжевЛжТадЁЃBASEгыДЋЭГACIDРэТлЦфЪЕЪЧБГРыЕФЃЌТњзуBASEРэТлЕФЪТЮёвВНаШсадЪТЮёЃЌдкдтгіЪЇАмЪБашвЊгаЯргІЕФВЙГЅЛњжЦЃЌгывЕЮёёюКЯадНЯИпЃЌЦфЪЕЮвВЂВЛЪЧКмдоЭЌBASEЕФзіЗЈЃЌвђЮЊЫќвбОБГРыСЫЪ§ОнПтзюЛљБОЕФЩшМЦРэФюЁЃ
raftЕФгХЪЦ
ВЛЙмЪЧЩЯУцЕФXAЛЙЪЧBASEЖМЮоЗЈГЙЕзНтОівЛжТадЮЪЬтЃЌеце§втвхЩЯЕФЧПвЛжТвЛЖЈЪЧЛљгкЧПвЛжТавщЕФЁЃpaxosКЭraftЪЧФПЧАжїСїЕФСНжжЙВЪЖЫуЗЈЁЃPaxosЕЎЩњгкбЇдКХЩЃЌЪЧЗжВМЪНЛЗОГЯТЛљгкЯћЯЂДЋЕнЕФЙВЪЖЫуЗЈЃЌЫќЩшМЦжЎГѕЪЧПМТЧвЛИіЭЈгУЕФФЃаЭЃЌВЂУЛгаЙ§ЖрЕФПМТЧЪЕМЪЕФгІгУЃЌЖјЧвpaxosПМТЧСЫЖрИіНкЕуЭЌЪБаДШыЕФЧщПіЃЌетОЭЪЙЕУpaxosЕФзДЬЌЛњвьГЃИДдгЃЌЫљвдФбвдРэНтЃЌВЛЭЌЕФШЫПЩФмРэНтГіВЛЭЌЕФвтЫМЃЌетвЛЕувЛжБдтШЫкИВЁЃЌБШШчMGRв§Шыwrite
setЕФИХФюРДДІРэЖрЕуаДШыГхЭЛЕФЮЪЬтЃЌетдкИпВЂЗЂШШЕуЪ§ОнЕФГЁОАЯТЪЧВЛПЩНгЪмЕФЁЃвђЮЊpaxosЕФФбвдРэНтЃЌЫЙЬЙИЃЕФСНУћДѓбЇЩњЩшМЦСЫraftЫуЗЈЃЌЯрБШРДЫЕЃЌraftЪЧЙЄвЕХЩЃЌЭЌвЛЪБПЬleaderжЛгавЛИіЃЌfollowerЭЈЙ§ШежОИДжЦЪЕЯжвЛжТадЃЌЯрБШpaxosРДЫЕraftЕФзДЬЌЛњИќМгМђЕЅвзЖЎЃЌЪЕЯжЦ№РДвВИќМгМђЕЅЃЌвђДЫдкЗжВМЪНЛЗОГЩЯгазХЙуЗКЕФгІгУЃЌР§ШчTiDBЁЂRadonDBЁЂetcdЁЂkubernetesЕШЁЃ
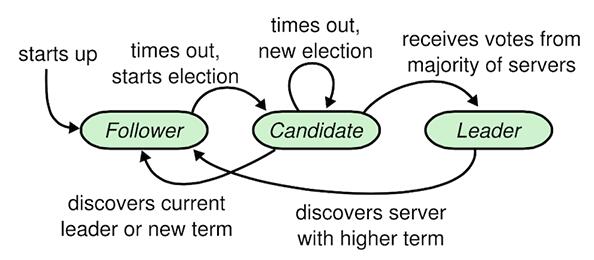
RaftавщНЋЙВЪЖЮЪЬтЗжНтЮЊШ§ИізгЮЪЬтЗжБ№НтОіЃКleaderбЁОйЁЂШежОИДжЦЁЂАВШЋадЁЃ
LeaderбЁОйЃК
ЗўЮёЦїНкЕугаШ§жжзДЬЌЃКСьЕМепЁЂИњЫцепКЭКђбЁепЁЃе§ГЃЧщПіЯТЃЌЯЕЭГжажЛгавЛИіСьЕМепЃЌЦфЫћЕФНкЕуШЋВПЖМЪЧИњЫцепЃЌСьЕМепДІРэШЋВППЭЛЇЖЫЧыЧѓЃЌИњЫцепВЛЛсжїЖЏЗЂЫЭШЮКЮЧыЧѓЃЌжЛЪЧМђЕЅЕФЯьгІРДздСьЕМепЛђепКђбЁепЕФЧыЧѓЁЃШчЙћИњЫцепНгЪеВЛЕНЯћЯЂ(бЁОйГЌЪБ)ЃЌФЧУДЫћОЭЛсБфГЩКђбЁепВЂЗЂЦ№вЛДЮбЁОйЁЃЛёЕУМЏШКжаДѓЖрЪ§бЁЦБЕФКђбЁепНЋГЩЮЊСьЕМепЃЌСьЕМепвЛжБЖМЛсЪЧСьЕМепжБЕНздМКхДЛњСЫЁЃ
Raft ЫуЗЈАбЪБМфЗжИюГЩШЮвтГЄЖШЕФШЮЦк(term)ЃЌУПвЛЖЮШЮЦкДгвЛДЮбЁОйПЊЪМЃЌвЛИіЛђепЖрИіКђбЁепГЂЪдГЩЮЊСьЕМепЁЃШчЙћвЛИіКђбЁепгЎЕУбЁОйЃЌШЛКѓЫћОЭдкетИіЕФШЮЦкФкГфЕБСьЕМепЁЃвЊПЊЪМвЛДЮбЁОйЙ§ГЬЃЌИњЫцепЯШвЊдіМгздМКЕФЕБЧАШЮЦкКХВЂЧвзЊЛЛЕНКђбЁепзДЬЌЃЌШЛКѓЫћЛсВЂааЕФЯђМЏШКжаЕФЦфЫћЗўЮёЦїНкЕуЗЂЫЭЧыЧѓЭЖЦБЕФ
RPCs РДИјздМКЭЖЦБЃЌКђбЁепЛсМЬајБЃГжзХЕБЧАзДЬЌжБЕНвдЯТШ§МўЪТЧщжЎвЛЗЂЩњЃК(a) ЫћгЎЕУСЫетДЮЕФбЁОйЃЌ(b)
ЦфЫћЗўЮёЦїГЩЮЊСьЕМепЃЌ(c) УЛгаШЮКЮвЛИіКђбЁепгЎЕУбЁОйЁЃЕБвЛИіКђбЁепЛёЕУСЫМЏШКДѓЖрЪ§НкЕуеыЖдЭЌвЛИіШЮЦкКХЕФбЁЦБЃЌФЧУДЫћОЭгЎЕУСЫбЁОйВЂГЩЮЊСьЕМепЁЃШЛКѓЫћЛсЯђЦфЫћЕФЗўЮёЦїЗЂЫЭаФЬјЯћЯЂРДНЈСЂздМКЕФШЈЭўВЂЧвзшжЙаТЕФСьЕМШЫЕФВњЩњЁЃЯТЭМЮЊШ§жжНЧЩЋЕФзЊЛЛзДЬЌЛњЁЃ
ШежОИДжЦЃК
ЕБleaderБЛбЁОйГіРДЃЌЫћОЭзїЮЊЗўЮёЦїДІРэПЭЛЇЖЫЧыЧѓЁЃПЭЛЇЖЫЕФУПвЛИіЧыЧѓЖМБЛПДГЩИДжЦзДЬЌЛњЫљашвЊжДааЕФжИСюЁЃСьЕМепАбетЬѕжИСюзїЮЊвЛЬѕаТЕФШежОЬѕФПИНМгЕНШежОжаШЅЃЌШЛКѓВЂааЕФЗЂЦ№ИНМгЬѕФП
RPCs ИјЦфЫћЕФЗўЮёЦїЃЌШУЫћУЧИДжЦетЬѕШежОЬѕФПЁЃЕБетЬѕШежОЬѕФПБЛАВШЋЕФИДжЦЃЌСьЕМепЛсгІгУетЬѕШежОЬѕФПЕНЫќЕФзДЬЌЛњжаШЛКѓАбжДааЕФНсЙћЗЕЛиИјПЭЛЇЖЫЁЃШчЙћИњЫцепБРРЃЛђепЭјТчЖЊАќЃЌСьЕМепЛсВЛЖЯЕФжиИДГЂЪдИНМгШежОЬѕФП
RPCs (ОЁЙмвбОЛиИДСЫПЭЛЇЖЫ)жБЕНЫљгаЕФИњЫцепЖМзюжеДцДЂСЫЫљгаЕФШежОЬѕФПЁЃЯТЭМЮЊИДжЦзДЬЌЛњФЃаЭЁЃ
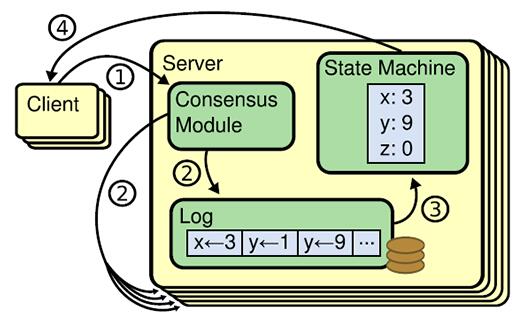
АВШЋадЃК
АВШЋаджИЕФЪЧУПЬЈИДжЦзДЬЌЛњЖМашвЊАДееЭЌбљЕФЫГађжДааЯрЭЌЕФжИСюЃЌвдБЃжЄУПЬЈЗўЮёЦїЪ§ОнЕФвЛжТадЁЃМйЯывЛЬЈИњЫцепдкФГЖЮЪБМфДІгкВЛПЩгУзДЬЌЃЌКѓРДПЩФмБЛбЁЮЊСьЕМепЃЌетЪБОЭЛсдьГЩжЎЧАЕФШежОБЛИВИЧЁЃRaftЫуЗЈЭЈЙ§дкleaderбЁОйЪБдіМгвЛаЉЯожЦРДБмУтетИіЮЪЬтЃЌетвЛЯожЦБЃжЄЫљгаСьЕМепЖдгкИјЖЈЕФШЮЦкКХЃЌЖМгЕгаСЫжЎЧАШЮЦкЕФЫљгаБЛЬсНЛЕФШежОЬѕФПЁЃШежОЬѕФПжЛЛсДгСьЕМепДЋИјИњЫцепЃЌВЛЛсГіЯжвђЮЊаТСьЕМепШБШежОЖјашвЊИњЫцепЯђСьЕМепДЋШежОЕФЧщПіЃЌВЂЧвСьЕМепДгВЛЛсИВИЧБОЕиШежОжавбОДцдкЕФЬѕФПЁЃRaft
ЫуЗЈЪЙЕУдкЭЖЦБЪБЭЖЦБепОмОјЕєФЧаЉШежОУЛгаздМКаТЕФЭЖЦБЧыЧѓЃЌДгЖјзшжЙИУКђбЁепгЎЕУбЁЦБЁЃ
CNЕФЩшМЦ
НгШыНкЕуЕФЩшМЦПЩФмПДЦ№РДКмМђЕЅЃЌЕЋЪЧРяУцгааЉЕиЗНФкШнЛЙЪЧгааЉаўЛњЕФЁЃЩшМЦcnашвЊжиЕуПМСПЕФЕиЗНжївЊЪЧcnЕНЕзЪЧзіжиЛЙЪЧзіЧсЁЃетЪЧАбЫЋШаНЃЃЌжївЊгаЯТУцСНЗНУцЮЪЬтЁЃ
1.ШчКЮзіЕНsqlгяЗЈМцШнад?
НгШыНкЕужївЊИКд№sqlЕФНтЮіЁЂжДааМЦЛЎЕФЩњГЩгыЯТЗЂЃЌетаЉЖЋЮїЦфЪЕЪЧsqlНтЮіЦїзіЕФЪТЧщЃЌЮвУЧПЩвджБНгНЋMySQLЛђепpgЕФНтЮіЦїЩѕжСserverВуФУЙ§РДзіsqlНтЮіКЭжДааМЦЛЎЩњГЩЃЌЖјЧвОЭЬьШЛЕФМцШнСЫMySQLЛђепpgЕФгяЗЈЁЃ
2.ШчКЮДІРэдЊЪ§ОнЕФЮЪЬт?
ЩЯУцЕФЗНАИПДЫЦКмЭъУРЕФЪТЧщЃЌЕЋЪЧгаИіЮЪЬтЃКШчЙћжБНгНЋMySQLЛђепpgЕФserverВуАсЙ§РДЕФЛАЃЌдЊЪ§ОндѕУДАь?cnЩЯЕНЕзЗХВЛЗХдЊЪ§Он?ШчЙћВЛЗХдЊЪ§ОнЃЌФЧУДОЭашвЊвЛИіЭГвЛЕФДцЗХКЭЙмРэдЊЪ§ОнЕФЕиЗНЃЌЮвдкcnЩЯНЈЕФБэашвЊЕНФГИіЙЬЖЈЕиЗНИќаТдЊЪ§ОнаХЯЂЃЌВщбЏвВЪЧвЛбљЁЃШчЙћcnЩЯДцЗХдЊЪ§ОнЃЌФЧУДдЊЪ§ОнЕФИќаТОЭашвЊдкИїИіcnжЎМфНјааЭЌВНЃЌШчЙћЗЂЩњФГИіcnхДЛњЃЌдђШЮКЮddlВйзїЖМЛсhangзЁЃЌетЪБОЭашвЊгавЛИіЛњжЦЃКдкcnГЌЪБЮоЯьгІКѓНЋcnЬоçó̏ШКЁЃ
DNЕФЩшМЦ
Ъ§ОнНкЕуЕФЩшМЦжївЊПМТЧЯТУцМИИіЗНУцЮЪЬтЁЃ
1.Ъ§ОнНкЕуШчКЮзіИпПЩгУ?
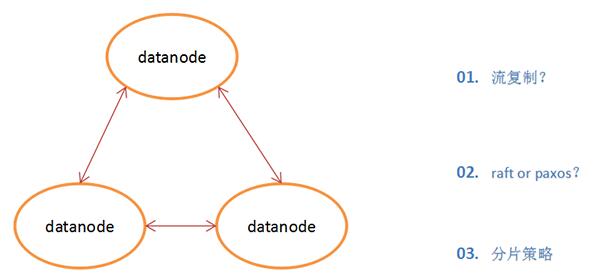
Ъ§ОнПтЕФЪ§ОнЕБШЛЪЧзюБІЙѓЕФЃЌШЮКЮЪ§ОнПтЖМвЊгаЪ§ОнШпгрЗНАИЃЌЪ§ОнНкЕувЛЖЈвЊгаИпПЩгУЃЌдкБЃжЄrpo=0ЕФЛљДЁЩЯОЁСПЫѕЖЬrtoЁЃЯИЯывЛЯТЃЌЦфЪЕУПИіdnЖМЪЧвЛИіЪ§ОнПтЪЕР§ЃЌетРявдMySQLЛђепpgЮЊР§ЃЌMySQLКЭpgБОЩэЪЧгаИпПЩгУЗНАИЕФЃЌВЛЙмЪЧЛљгкжїДгАыЭЌВНЛЙЪЧСїИДжЦЃЌЖМПЩвддкdnВуУцзїЮЊЪ§ОнЕФШпгрКЭЧаЛЛЗНАИЁЃЕБШЛЛЙгааЉЪ§ОнПтдкdnВуУцв§ШыСЫpaxosЁЂraftЁЂquorumЕШЕФЧПвЛжТЗНАИЃЌетвВЪЧдкЗжВМЪНЪ§ОнПтжаКмГЃМћЕФЩшМЦЁЃ
2.ШчКЮзіЕНдкЯпРЉШн?
дкЯпРЉШнЪЧЗжВМЪНЪ§ОнПтЕФвЛЯюОоДѓгХЕуЃЌЖјРЉШнЪ§ОнНкЕуБиШЛЩцМАЕНЪ§ОнЯђаТНкЕуЕФЧЈвЦЃЌФПЧАЪаУцЩЯЕФЗжВМЪНЪ§ОнПтЛљБОЩЯЖМзіЕНСЫздЖЏЕФЪ§ОнжиЗжВМЁЃЕЋЪЧзіЕНЪ§ОнПтздЖЏжиЗжВМЛЙВЛЙЛЃЌШчКЮзіЕНжЛЧЈвЦЩйВПЗжЪ§ОнвдНЕЕЭЗўЮёЦїIOбЙСІГЩЮЊЙиМќЮЪЬтЁЃ
ДЋЭГЕФЩЂСаЗНЪНЪЧИљОнЗжЧјМќЙўЯЃжЕЖдЗжЧјЪ§СПНјааШЁФЃВйзїЃЌЕУЕНЕФНсЙћОЭЪЧЪ§ОнгІИУТфШыЕФЗжЧјЃЌЕЋЪЧетжжЗжВМЗНЗЈдкдіМгЩОГ§НкЕуЪБЛсдьГЩДѓСПЕФЪ§ОнжиЗжВМЃЌЖјвЛжТадЙўЯЃЕФКЫаФЫМЯыЪЧУПИіЗжЧјВЛдйЪЧЖдгІвЛИіЪ§зжЃЌЖјЪЧЖдгІвЛИіЗЖЮЇЃЌЖдМЦЫуЕФЩЂСажЕНјааЗЖЮЇЕФЦЅХфЃЌДѓЬхЫМТЗЪЧНЋЪ§ОнНкЕуКЭМќЕФhashжЕЖМгГЩфЕН0~2^32ЕФдВЛЗЩЯЃЌШЛКѓДггГЩфжЕЕФЮЛжУПЊЪМЫГЪБеыВщевЃЌНЋЪ§ОнБЃДцЕНевЕНЕФЕквЛИіНкЕуЩЯЁЃШчЙћГЌЙ§2^32ШдШЛевВЛЕНЗўЮёНкЕуЃЌОЭЛсБЃДцЕНЕквЛИіНкЕуЩЯЁЃвЛжТадЙўЯЃзюДѓГЬЖШНтОіСЫЪ§ОнжиЗжВМЮЪЬтЃЌЕЋЪЧПЩФмЛсдьГЩНкЕуЪ§ОнЗжВМВЛОљдШЕФЮЪЬтЃЌЕБШЛеыЖдетИіЮЪЬтЛЙгавЛаЉИФНјЃЌБШШчдіМгащФтНкЕуЁЃ
GTMЕФЩшМЦ
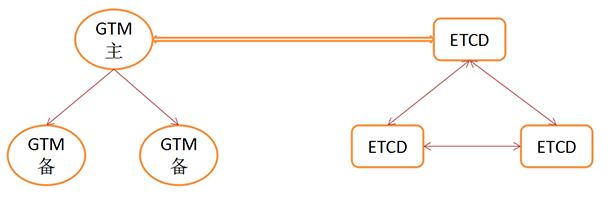
GTMЙЫУћЫМвхЪЧвЛИіШЋОжИХФюЃЌЗжВМЪНЪ§ОнПтБОРДОЭЪЧЮЊСЫПЩРЉеЙЁЂЬсЩ§адФмЁЂНЕЕЭШЋОжЗчЯеЃЌШЛЖјGTMетИіЖЋЮїДђЦЦСЫетвЛЧаЁЃ
1.ЮЊЪВУДашвЊGTM?
МђЕЅвЛОфЛАзмНсОЭЪЧЃКGTMЪЧЮЊСЫБЃжЄШЋОжЖСвЛжТадЃЌЖјСННзЖЮЬсНЛЪЧЮЊСЫБЃжЄаДвЛжТадЁЃетРяЮвУЧПЩФмгаИіЮѓЧјЃЌШчЙћУЛгаGTMФЧУДЛсВЛЛсдьГЩЪ§ОнВЛвЛжТ?ЛсЃЌЕЋЪЧжЛЪЧФГИіЪБМфЕуЖСЕФВЛвЛжТЃЌетИіВЛвЛжТвВЪЧднЪБЕФЃЌЕЋЪЧВЛЛсдьГЩЪ§ОнаДЕФВЛвЛжТЃЌаДЕФвЛжТадЭЈЙ§СННзЖЮЬсНЛРДБЃжЄЁЃ
ЮвУЧжЊЕРpostgresqlЭЈЙ§Пьее(snapshot)РДЪЕЯжMVCCгыЪТЮёПЩМћадХаЖЯЁЃЖдгкread
commitИєРыМЖБ№ЃЌвЊЧѓУПИіЪТЮёжаЕФВщбЏНіФмПДЕНдкИУЪТЮёЦєЖЏЧАвбОЬсНЛЕФИќИФЃЌвдМАЕБЧАЪТЮёжаИУВщбЏжЎЧАЫљзіЕФИќИФЃЌетЖМвЊЭЈЙ§ПьееРДЪЕЯжЁЃПьееЕФЪ§ОнНсЙЙжаЛсАќКЌЪТЮёЕФxmin(ВхШыtupleЕФЪТЮёКХ)ЁЂxmax(ИќаТЛђепЩОГ§ЪТЮёЕФЪТЮёКХ)ЁЂе§дкдЫааЕФЪТЮёСаБэЕШЯрЙиаХЯЂЁЃpgЕФУПЬѕдЊзщ(tuple)ЭЗаХЯЂжавВЛсМЧТМЪТЮёЕФxminКЭxmaxаХЯЂЁЃPgШЁЕУsnapshotКѓЛсНјааЪТЮёПЩМћадХаЖЯЃЌЖдгкЫљгаidаЁгкxminЕФtupleЖдЕБЧАПьееПЩМћЃЌЭЌЪБidДѓгкxmaxЕФtupleЖдЕБЧАЪТЮёПЩМћЁЃЕБЧАРЉеЙЕНЗжВМЪНМЏШККѓЃЌУПЬЈЛњЦїЩЯЖМДцдкpgЕФЪЕР§ЃЌЮЊСЫБЃжЄШЋОжЕФЖСвЛжТадЃЌашвЊвЛИіШЋОжЕФзщМўРДИКд№snapshotЕФЗжХфЃЌЪЙЕУПьееаХЯЂдкИїИіНкЕужЎМфЙВЯэЃЌетОЭЪЧGTMЕФЙЄзїЁЃ
2.GTMИпПЩгУЕФЮЪЬт?
GTMзїЮЊЗжХфШЋОжПьееКЭЪТЮёidЕФЮЈвЛзщМўЃЌжЛФмгавЛИіЃЌЕБШЛGTMПЩвдзіжїБИИпПЩгУЃЌЕЋЪЧЭЌвЛЪБПЬжЛФмгавЛИіGTMдкЙЄзїЃЌgxidаХЯЂдкжїБИжЎМфНјааЭЌВНЃЌетбљОЭдьГЩвЛИіЮЪЬтЃЌЫфШЛЦфЫћНкЕуЖМЗжВМЪНСЫЃЌЕЋЪЧGTMЪМжеЪЧвЛИіЕЅЕуЃЌЕЅЕуЙЪеЯЪБОЭЛсЩцМАЕНЧаЛЛЃЌЧаЛЛЙ§ГЬЪЧгАЯьШЋОжЕФЃЌЖјЧвЮЊСЫБЃжЄЧаЛЛКѓgxidаХЯЂВЛЖЊЪЇЃЌGTMжЎМфБиаызіЕНgxidЕФЭЌВНЁЃ
еыЖдИпПЩгУетПщЮЪЬтЃЌПЩвдНЋGTMЕФЪТЮёКХДцДЂаХЯЂАўРыЃЌНЋЪТЮёКХаХЯЂДцдкЕкШ§ЗНДцДЂжаЃЌР§ШчetcdОЭЪЧИіКмКУЕФбЁдёЃЌetcdЪЧИіЧПвЛжТИпПЩгУЕФЗжВМЪНДцДЂМЏШКЃЌetcdБШНЯЧсСПЃЌЪЪКЯгУРДДцДЂЪТЮёКХаХЯЂЃЌЭЌЪБЫќздЩэБЃжЄСЫИпПЩгУгыЧПвЛжТЃЌетЪБGTMОЭВЛашвЊдкжїБИжЎМфЭЌВНgxidЃЌШчЙћЗЂЩњжїБИЧаЛЛЃЌаТжїGTMжЛашвЊдйШЅДгetcdжаШЁЕУзюаТЪТЮёКХЃЌаДЪТЮёКХвВЭЌРэЃЌжїGTMЛсЯђжїetcdНкЕуаДШыЪТЮёКХаХЯЂЃЌЭЈЙ§etcdздЩэЕФraftИДжЦавщБЃжЄвЛжТадЁЃетбљЕФЩшМЦЪЙЕУGTMЕФбЙСІМѕЧсКмЖрЁЃ
3.GTMадФмЕФЮЪЬт?
GTMЪЧДѓВПЗжЗжВМЪНЪ§ОнПтЕФадФмЦПОБЃЌЫќЪЙЕУвЛЬзМЏШКЕФећЬхадФмЩѕжСВЛШчвЛЬЈЕЅЛњЁЃвВКмКУРэНтЃЌШЮКЮвЛИіЪТЮёПЊЦєЖМвЊЯШЭЈЙ§cnЕНGTMШЁЪТЮёКХКЭПьееаХЯЂЃЌШЛКѓНсЙћНтЮіКѓЯТЗЂЕНdnжДааЃЌШЛКѓcnНјааЛузмдйЗЕЛиИјгІгУЃЌТЗОЖКмУїЯдБфГЄСЫЃЌФЧУДаЇТЪПЯЖЈБфЕЭЃЌФПЧАгХЪЦдкгкПЩвдРћгУЖрЬЈЛњЦїЕФзщКЯФмСІНјааМЦЫуЃЌМЦЫузЪдДЕУЕНСЫРЉеЙЁЃ
еыЖдGTMЕФЦПОБЮЪЬтЕБШЛвВгаНтОіЗНАИЃЌБШШчЛЊЮЊGaussDBОЭЬсГіGTM-FreeКЭGTM-LiteЃЌgtm-freeЪЧдкФЧжжЧПвЛжТЖСвЊЧѓВЛИпЕФГЁОАЯТЙиБеGTMЕФЙІФмЃЌЫљгаЪТЮяЖМВЛзпGTMЃЌетжжЧщПіЯТадФмЛљБОФмЙЛЕУЕНЯпадЬсЩ§ЃЌИУЙІФмвбОЪЕЯж;gtm-liteЪЧНЋЪТЮёЗжРрЃЌШЋОжЪТЮёОЭзпGTMЃЌБОЕиЪТЮёОЭжБНгЯТЗЂЃЌвђЮЊДѓЖрЪ§ЧщПіЯТЖМЪЧБОЕиЪТЮёЃЌЫљгаадФмЬсЩ§вВКмУїЯдЃЌИУЙІФмЛЙдкбаЗЂНзЖЮЁЃ
ЗжВМЪНЪ§ОнПтШчКЮЪЕЯжPITR
Ъ§ОнПтЕФPITRвЛАуЖМЪЧЭЈЙ§вЛИіЛљДЁБИЗнМгЩЯГжајВЛМфЖЯЕФwalЙщЕЕРДзіЕНЕФЃЌетИіЛљДЁБИЗнПЩвдЪЧдкЯпЕФЃЌвђЮЊЫќВЂВЛашвЊЪ§ОнПтЕБЪБДІгквЛжТадзДЬЌЃЌвЛжТадПЩвдЭЈЙ§replay
redoРДЪЕЯжЃЌЫљвдЛљДЁБИЗнПЩвдЪЧЮФМўЯЕЭГtarУќСюЖјВЛашвЊЮФМўЯЕЭГМЖБ№ЕФПьееЁЃ
PITRЪЧЭЈЙ§ЛљДЁБИЗнМгЩЯredoШежОФмЙЛЛжИДЕНШЮвтЪБМфЕуЃЌетИіШЮвтЪБМфЕуВЛЭЌЪ§ОнПтгаВЛЭЌЖЈвхЃЌПЩФмЪЧФГИіlsnЃЌПЩФмЪЧФГИіsnapshotЃЌПЩФмЪЧФГИіtimestampЁЃPostgresqlЪ§ОнПтжаФмЙЛЛљгкredoЛжИДЕНШЮвтЕФtimestampЁЃ
ЗжВМЪНЪ§ОнПтЕФPITRРэТлЩЯКЭЕЅЛњЧјБ№ВЛДѓЃЌУПИіНкЕуБИЗнздМКЕФЛљДЁЪ§ОнЃЌетИіЪ§ОнВЛашвЊвЛжТадЃЌЕЋЪЧвЊПМТЧЕНЗжВМЪНЪТЮёЕФЮЪЬтЃЌдкзіЛљДЁБИЗнЕФЪБКђБиаыБЃжЄжЎЧАЕФЗжВМЪНЪТЮё(ШчЙћДцдк)вбОШЋВПЭъГЩЃЌвђЮЊЗжВМЪНЪТЮёЪЧзпСННзЖЮЬсНЛавщЃЌ2PCдкЬсНЛНзЖЮВЛЭЌЕФЛњЦїcommitПЯЖЈгаЪБМфВюЃЌШчЙћдкетИіЪБМфВюзіСЫБИЗнЃЌЛсЗЂЯжзюКѓвЛЬЈЛњЦїгаетИіЪТЮёЕФredoЃЌСэвЛЬЈУЛгаЃЌетбљЛжИДЕФЛАОЭЛсдьГЩЪ§ОнВЛвЛжТЁЃетИіЮЪЬтПЩвдЭЈЙ§pgжавЛИіbarriesЕФИХФюЪЕЯжЃЌдкЗжВМЪНЪТЮёНсЪјКѓДђвЛИіbarrierЃЌЛёЕУвЛжТадЕуЃЌШЛКѓдйНјааЛљДЁБИЗнЁЃЖдгкredoЕФЧАЙіРДЫЕЃЌжЛашвЊНЋЫљгаНкЕуЕФredoЧАЙіЕНвЛИівЛжТадЮЛЕуМДПЩЁЃ |








