| 编辑推荐: |
本篇文章主要介绍
了腾 讯 计 费 、腾讯计费场景下的跨城挑战、Pulsar 跨城能力、腾讯计费在跨城上的优化等相关内容。
来自于微信公众号ApachePulsar,由火龙果软件Anna编辑、推荐。 |
|
腾 讯 计 费 介 绍
腾讯计费(米大师)是孵化于支撑腾讯内部业务千亿级营收的互联网计费平台,汇集国内外主流支付渠道,提供账户管理、精准营销、安全风控、稽核分账、计费分析等多维度服务。
平台承载了公司每天数亿收入大盘,为 180+ 个国家(地区)、万级业务代码、100W+ 结算商户提供服务,托管账户总量
300 多亿,是一个全方位、一站式计费平台。

作为一个千亿级在线支付平台,腾讯计费(米大师)需要在以下方面进行重点优化和升级。
1. 数据一致性
计费场景要求不能丢掉任何数据,这是最基本的诉求。毕竟属于金融资产类,虽然有的是虚拟账户,但还是用真金白银进行交易的。通过提取
SQL 来保证数据层面高可靠性、高一致性。
2. 流畅性、可用性
平台的操作流程跟一些电商平台的支付流程有些相似,即加入购物车、下单、发货。不同的是,大多数电商平台需要用户自己手动参与这些流程,而腾讯计费则是用户在后台点击便可自动完成。
尤其是对于一些免付费的项目,对整体可用性会有更高的要求。需具备容灾能力,在异常情况下能够自动修复。
3. 性能层面
在逻辑层面,因为整个系统覆盖 300 多个不同的业务产品,在面临海量增长的数据时,对性能的稳定性就有着极高的需求。
对于腾讯业务的量级情况,在容灾的效果期望上至少是城市级别的。在腾讯内部有上万个业务,这些业务部署在各地,计费平台的服务基本是部署在深圳和上海两个地方。在这里就需要提供「异地多活」的服务。
当然在多数情况下,我们会保持在同城部署服务。在进行业务请求时,选择就近的网关,可以减少不必要的情况。当然异地情况下,也要保证快速切换的状态。
腾讯计费场景下的跨城挑战

在容灾层面,按照地域可以分为「同城多活」和「异地多活」。在逻辑层面,两种状态下都比较容易操作,比较困难地是在数据层面。
同城多活状态下,在数据层会有多个副本构成,采用跨机房或 IDC 部署。如果出现问题,可以立即切换到其他机房/IDC
进行部署,达到无损切换。虽然这种方式操作比较简单,但是它避免不了跨城市之间、一些极端情况的出现。
异地多活情况下,在部署方面就需要跨城多地进行。当一个城市的服务器宕机时,另一个城市可以继续支撑产品,来减少损失。
但是想要做到完全无损是非常困难的,除非是每一步操作后都同步到异地并操作成功,才能保证任何时刻数据都是一致的。但是这样性能方面,效率就大大下降了。
在整体性的表现上,异地多活更适用于腾讯计费的产品模式。
异地单活与异地多活
在之前,腾讯计费采用的是异地单活的模式。当时的业务没有现在这么多元复杂,大部分请求都在主城市/主数据库完成。对于数据库的读取,可以根据不同产品的不同需求,在主城或备城读取。

这种架构的好处是,数据是强一致性的,不会出错,因为所有的数据都是集成在同一地方去写入。缺点就是一旦出现城市级网络灾难,就没有设备进行写入操作。
随着腾讯业务的扩展和丰富,异地多活成为必然的选择,用来提供高质量、高稳定的服务。这就涉及到两个数据中心的同步问题。
目前业界主流的是 CDC 异步模式,可以通过消息队列来应用到消息层面。不仅可以利用 MQ 的海量堆积能力来存放操作流水,还可以利用多消费处理能力来支撑数据复制的效率。
对于 MQ 的部署,同样也可以采用同城或者跨城的部署。
同城:在 DB 中心单独部署一个 MQ 集群。生产时,在同城的 MQ 进行,消费时,则交叉地进行数据读取。这样做的好处是生产效率高,缺点是消费时需要进行跨省访问,本身不具备「跨省」的能力。
跨城:MQ 采用同城部署,具备跨省能力,能够进一步减少数据丢失。缺点是生产配置时,需要进行跨城市的数据调用,以及消费副本需要绑定在多地。
日常使用中多采用第二种方式,因为需要尽可能减少数据丢失的风险。
所以腾讯计费系统对分布式消息队列的要求如下:
- 一致性要求:计费场景要求数据一条不能丢,这是最基本的诉求。
- 高可用要求:需具备容灾能力,在异常情况下能够自动修复。
- 海量存储需求:在移动互联网时代,产生大量的交易数据,需要具备海量堆积能力。
- 快速响应要求:在亿级支付场景下,要求 MQ 能提供平滑的响应时间,尽可能控制在 10ms 内。
Pulsar 跨城能力
所以在调研和尝试后,选择了 Pulsar 作为腾讯计费平台的消息队列选择。
相比业界使用比较多的 Kafka 而言,它的主要场景是大数据日志处理,较少用于金融场景。RocketMQ
对 Topic 运营不太友好,特别是不支持按 Topic 删除失效消息,以及不具备宕机 Failover
能力。
而 Pulsar 具有原生的高一致性,基于 BookKeeper 提供高可用存储服务,采用了存储和服务分离架构方便扩容,同时还支持多种消费模式和多域部署模式。
在消息复制层面,Pulsar 提供了两种复制方式。一种是跨地域异步复制,免去了需要额外部署异步复制的操作。非常适用于腾讯内部的一些数据统计场景,尤其是那种跨省甚至跨国场景下的业务。

第二种是同步复制,本身就是跨城市级别的业务,副本存储在多地。Pulsar 的读写架构模式,我们在之前的
TGIP-CN 系列中也跟大家讲解了许多,大家可以点击文章开头部分的「专辑」去查看哦。

更多关于 Pulsar 高效数据复制模式的讲解,可以查看视频回放的 25:00-34:20 时间段。
腾讯计费在跨城上的优化
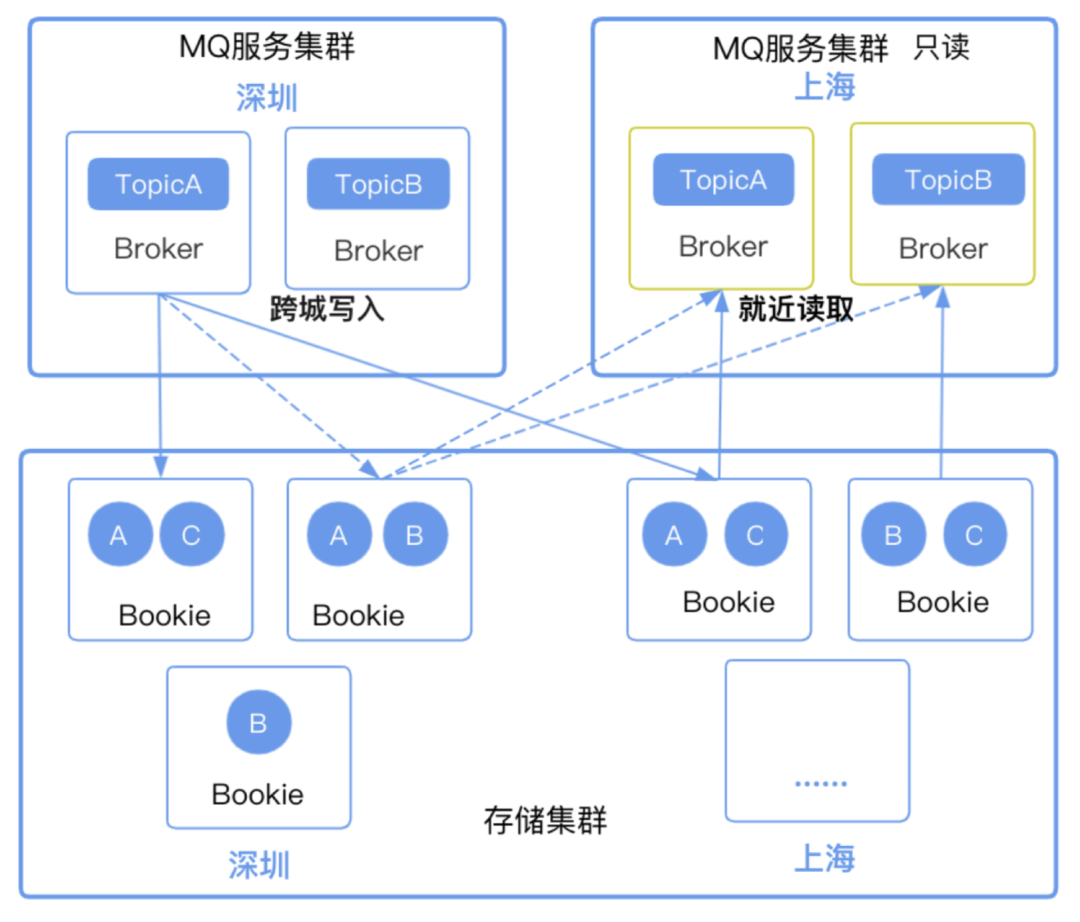
在跨城生产消费时,会存在一个问题。消费是不是一定要去主城拉取消息,因为上边提到了一个 topic
控制权只归属在一个 broker 上。
其实对于归属 broker 的说法只是在「写」层面,对于读取层面则可以采用其他 broker 进行操作。为了避免上万个消费者订阅同一个
topic,我们可以按照「就近原则」去部署一个只读 broker。

只读 broker 对于腾讯计费这种大流水量的平台是非常有帮助的。在部署上,跨城之间的存储是公用的。由
BookKeeper 提供了一些 ledger 层面的存储对象,可以创造只读类的数据。
这里就涉及到两个问题:
1. 如何知道要读取哪些数据?
因为只读 broker 和 broker 是采用隔离部署的,需要去把 topic 元数据从写入的 broker
上同步过来,这样就知道 topic 对应的 ledger 集合有哪些,就可以分辨数据读取了。
2. 如何读取最近的数据?
Topic 是由一组有序的 ledger 流组成的,每组只有一个 ledger 是处于 open
状态,其余均为关闭状态并无法进行改变。
如果只读 broker 在读取关闭状态的 ledger,可以轻松进行。如果读取 open 状态的
ledger,需要通过 LastConfirm id 来确认是否有新的消息。
消息正确读取后,就需要解决消费者偏移量同步的问题。如果不考虑消息删除的问题,则可以不用设置。
因为在 Pulsar 系统内,消息消费完后默认是会被删除的,同时没有消费者的也会被删除。这样生产集群只负责生产,没有消费。
这样在切分 ledger 时,可能会把之前未消费的 ledger 删除。这样只需要把只读的消费者偏移量同步到要写的
broker 上。这就是一个完整的只读 broker 设计思路。
Q&A
Q:Bookkeeper 是异地跨城一个大集群,broker 是每个城市一个独立集群吗?
A:是的,因为要确保跨城容灾能力,所以 BookKeeper 要做异地大集群。Broker 每个城市单独一个集群会更方便消费和读取。
Q:数据保存几个副本一般?
A:一般数据保存 3 个副本。
Q:只读 broker 的 message 读取是不是每次都要从 BookKeeper 读取,无法利用
broker 的 cache?
A:是的,因为只读 broker 与写 broker 是隔离开的,这个状态下没有用到写 broker
,所以就无法利用 broker cache。但是可以利用 BookKeeper 的缓存来加快过程。
Q:BookKeeper 的 read cache 是同步加载的,如果 ledger 盘是 HDD
的话,会不会效率不太高,对于 SSD 可能会好一些?
A:是的,机械硬盘的话可能相对慢一些,这种情况下 SSD 的状况确实会好一些。
Q:上海的 broker 如果全部挂掉,会怎么处理呢?
A:这种情况下,上海地区是无法进行消费 broker 的,那就可以切换到深圳这边的 broker 去消费。
总 结
此次分享给大家带来了关于腾讯计费内部是如何使用 Pulsar 作为 MQ 部件进行应用的,希望大家可以通过此次分享,对于
Pulsar 作为消息中间件的应用类型有了更深刻的了解。
|






 订阅
订阅