| БрМЭЦМі: |
БОЮФЪзЯШНщЩмGPUЕФЕФНсЙЙЃЌЦфДЮНщЩмGPUЕФЯпГЬКЭБрвыКЏЪ§ЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
РДздгкМђЪщ
,гЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ЧАбд
дкЪЕМЪCUDAБрГЬжЎЧА, ЯШРДСЫНтЯТGPUЕФНсЙЙ. КЭCPUЯрБШЯдЕУДжБЉгжЧПДѓ(ЪжЖЏЛЌЛќ).
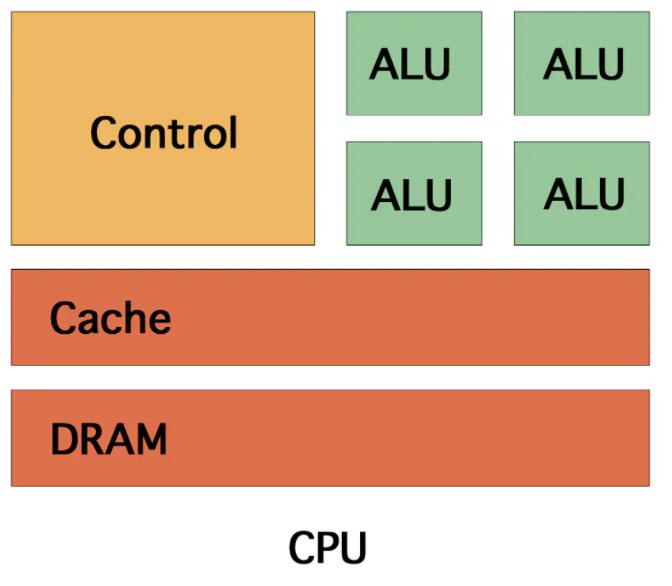
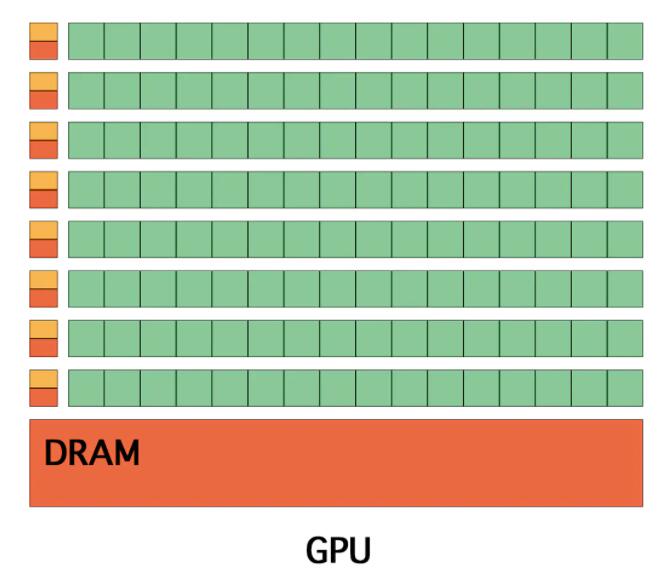
GPUМмЙЙ
GPUДІРэЕЅдЊ
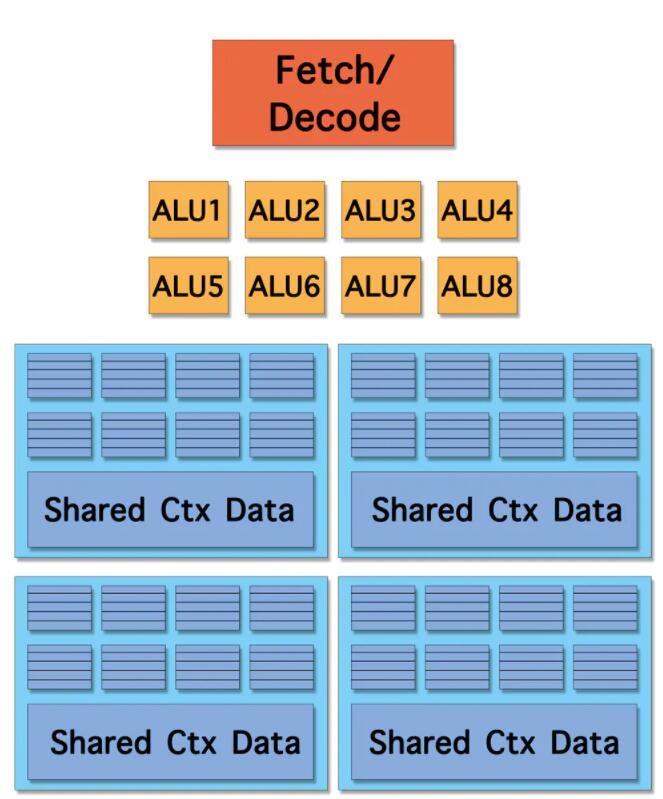
ДгетеХGPUИХФюФкКЫЭМПЊЪМНВЦ№, ЛсЗЂЯжКЭCPUФкКЫЪЧВЛЭЌЕФ, ЩйСЫ Ш§МЖЛКДц , ЗжжЇдЄВт ЕШЕШ. ЕЋЪЧдіМгСЫ ALU ЕФЪ§СП, РЉДѓСЫ ЩЯЯТЮФДцДЂГи(Pool of context storge) . ЦфЪЕетРяЕФALUОЭЪЧЪЕМЪЕФCUDAКЫ, ЩЯЯТЮФЛсЖдгІЪЕМЪЕФwarp.
ПЩвдПДЕН, ЩЯЯТЮФДцДЂГиЗжГЩ4Зн, вВОЭЪЧЫЕ, ПЩвджДаа4ЬѕжИСюСї, БШЗНЫЕжИСю1зшШћ, СЂТэЧаЛЛжИСю2, жИСю2зшШћЧаЛЛжИСю3, етОЭЦ№ЕНСЫвўВибгГйЕФаЇЙћ. ЕБШЛЪ§СПЕНЕзЪЧЖрЩйЪЧКмНВОПЕФ, ВЛЪЧдНЖрдНКУ.
змЕФРДПД, ФкКЫКЌ8ИіALU, 4зщ жДааЛЗОГ(Execution context) , УПзщга8ИіCtx. етбљ, вЛИіетбљЕФФкКЫПЩвдВЂЗЂ(concurrent but interleaved)жДаа4Ьѕ жИСюСї(instruction streams) , 32ИіВЂЗЂ ГЬађЦЌдЊ(fragment) .
ИХФюGPU
ИДжЦ16ИіЩЯЪіЕФДІРэЕЅдЊ, ЕУЕНвЛИіGPU. ЪЕМЪПЯЖЈУЛгаетУДМђЕЅЕФ, ЫљвдЫЕЪЧИХФюGPU.

ИХФюGPU
етИіGPUКЌ16ИіДІРэЕЅдЊ, 128ИіALU, 64зщжДааЛЗОГ(Execution context), 512ИіВЂЗЂГЬађЦЌдЊ(fragment).
МРГіnЖрФъЧАЕФПЈЛЪGTX 480, га480ИіCUDAКЫ(вВОЭЪЧALU), ФкДцДјПэ177.4GB/s. Жј GTX 980 Ti га2816ИіCUDAКЫ, ФкДцДјПэ336.5GB/s.
ЕЋЪЧДјПэвРОЩЪЧЦПОБ, ЫфШЛБШCPUДјПэИпСЫвЛИіЪ§СПМЖ, ЕЋЪЧПЩвдПДЕН, GTX 980 TiЕФДјПэвВОЭЪЧЖрФъЧАGTX 480ЕФСНБЖзѓгв. ЖјЧв, 336.5GB/sПДЦ№РДКмЫЌАЩ, ПЩЪЧФудкЫЎЦНВЛааЕФЧщПіЯТ, ПЩФмСЌ1%ЕФадФмЖМЗЂЛгВЛГіРД, вВОЭЪЧЫЕ, ВЛЖЎCUDAБрГЬ, жБНгвЦжВcДњТы, ЛЙВЛШчгУCPUжБНгХм.
GPUЯпГЬгыSM
гЩгкФПЧАЛЙУЛгаЭъШЋвРППGPUдЫааЕУЛњЦї, вЛАуРДЫЕ, ЖМЪЧвьЙЙЕФ, CPU+GPU. етвЛЕуЪЧвЊЬиБ№зЂвтЕФ, вВОЭЪЧHostгыDevice. ЖјЭЈГЃЃЌЮвУЧНЋдк CPUЩЯжДааЕФДњТыГЦЮЊжїЛњДњТы, ЖјНЋдкGPUЩЯдЫааЕФДњТыГЦЮЊЩшБИДњТы.
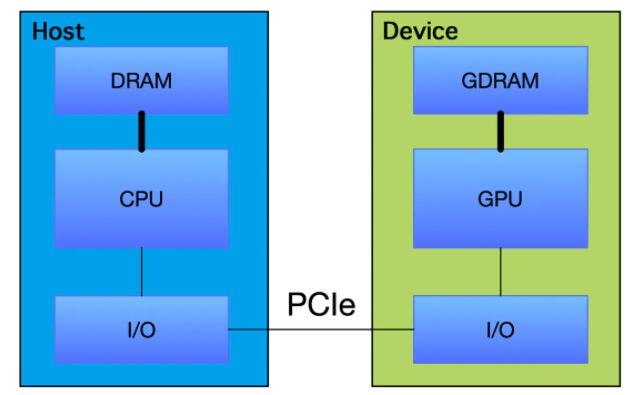
HOST-DEVICE
GPUЯпГЬ
дкCUDAМмЙЙЯТ, ЯдЪОаОЦЌжДааЪБЕФзюаЁЕЅЮЛЪЧthread. Ъ§ИіthreadПЩвдзщГЩвЛИіblock. вЛИіblockжаЕФthreadФмДцШЁЭЌвЛПщ ЙВЯэЕФФкДц(shared memory) , ЖјЧвПЩвдПьЫйНјааЭЌВНЕФЖЏзї, ЬиБ№вЊзЂвт, етЪЧПщ(block)ЭЌВН. ВЛЭЌblockжаЕФthreadЮоЗЈДцШЁЭЌвЛИіЙВЯэЕФФкДц, вђДЫЮоЗЈжБНгЛЅЭЈЛђНјааЭЌВН. вђДЫ, ВЛЭЌblockжаЕФthreadФмКЯзїЕФГЬЖШЪЧБШНЯЕЭЕФ.
ШЛКѓвРОнthread, blockКЭgrid, газХВЛЭЌЕФДцДЂ. КЫаФОЭЪЧthread. ПЩвдНсКЯЯТЭМНјааРэНт:
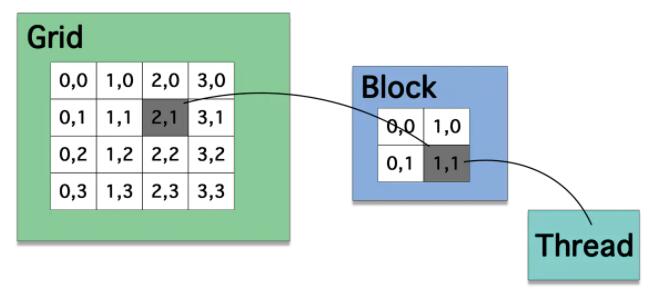
ЯпГЬНсЙЙ1
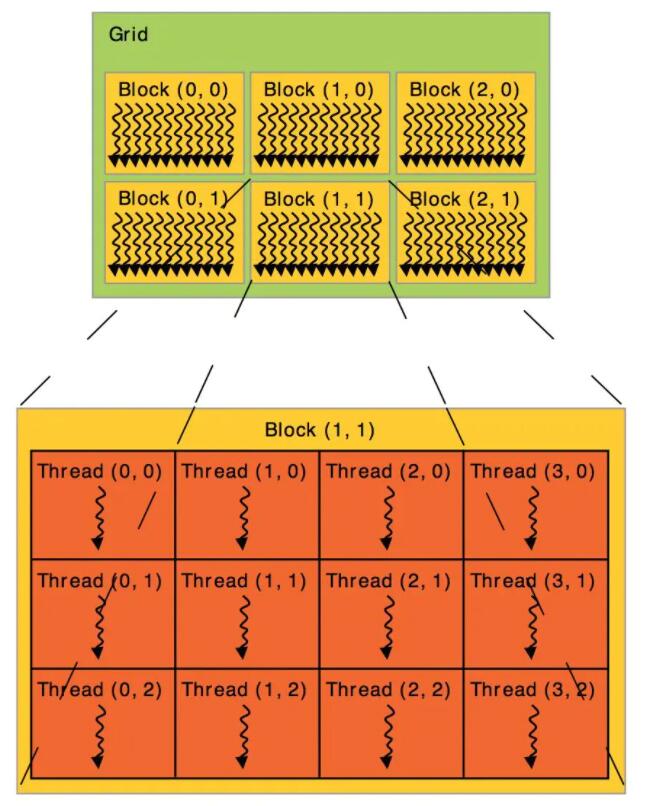
ЯпГЬНсЙЙ2
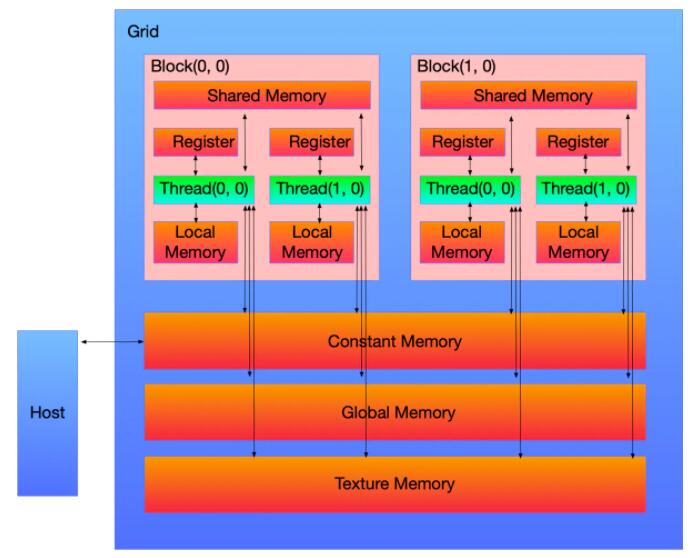
HOST-DEVICE
- УПИіДІРэЦїЩЯгавЛзщ БОЕи32ЮЛМФДцЦї(Registers) ;
- ВЂааЪ§ОнЛКДцЛђ ЙВЯэДцДЂЦї(Shared Memory) , гЩЫљгаБъСПДІРэЦїКЫаФЙВЯэ, ЙВЯэДцДЂЦїПеМфОЭЮЛгкДЫДІ;
- жЛЖСЙЬЖЈЛКДц(Constant Cache) , гЩЫљгаБъСПДІРэЦїКЫаФЙВЯэ, ПЩМгЫйДгЙЬЖЈДцДЂЦїПеМфНјааЕФЖСШЁВйзї(етЪЧЩшБИДцДЂЦїЕФвЛИіжЛЖСЧјгђ);
- вЛИі жЛЖСЮЦРэЛКДц(Texture Cache) , гЩЫљгаБъСПДІРэЦїКЫаФЙВЯэ, МгЫйДгЮЦРэДцДЂЦїПеМфНјааЕФЖСШЁВйзї(етЪЧЩшБИДцДЂЦїЕФвЛИіжЛЖСЧјгђ), УПИіЖрДІРэЦїЖМЛсЭЈЙ§ЪЕЯжВЛЭЌбАжЗФЃаЭКЭЪ§ОнЙ§ТЫЕФЮЦРэЕЅдЊЗУЮЪЮЦРэЛКДц.
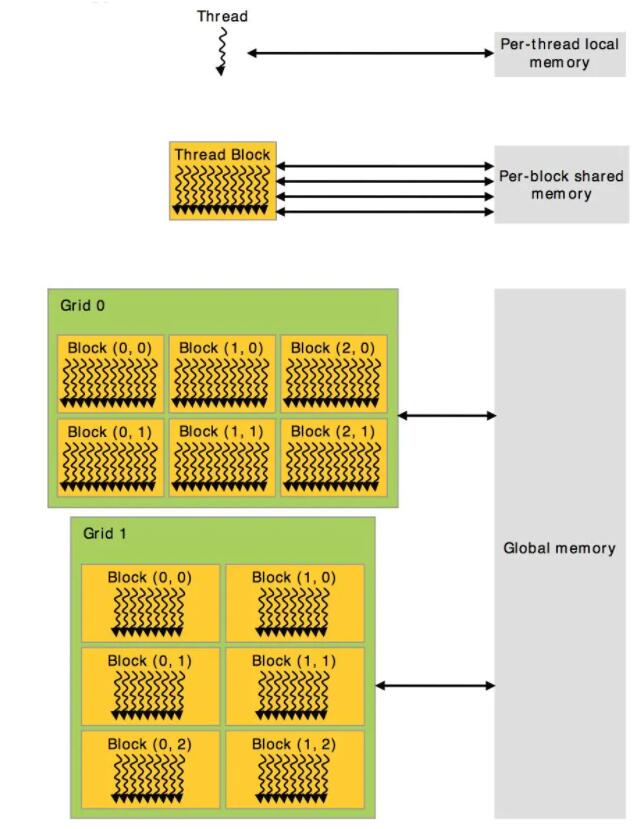
GPUЯпГЬ
SM

SM
ШчЭМ, GPUгВМўЕФвЛИіКЫаФзщМўЪЧSM, SMЪЧгЂЮФУћЪЧStreaming Multiprocessor, ЗвыЙ§РДОЭЪЧСїЪНЖрДІРэЦї. SMЕФКЫаФзщМўАќРЈCUDAКЫаФ(ЦфЪЕОЭЪЧALU, ШчЩЯЭМТЬЩЋаЁПщОЭЪЧвЛИіCUDAКЫаФ), ЙВЯэФкДц, МФДцЦїЕШ, SMПЩвдВЂЗЂЕижДааЪ§АйИіЯпГЬ, ВЂЗЂФмСІОЭШЁОігкSMЫљгЕгаЕФзЪдДЪ§. ЕБвЛИіkernelБЛжДааЪБ, ЫќЕФgirdжаЕФЯпГЬПщБЛЗжХфЕНSMЩЯ, вЛИіЯпГЬПщжЛФмдквЛИіSMЩЯБЛЕїЖШ. SMвЛАуПЩвдЕїЖШЖрИіЯпГЬПщ, етвЊПДSMБОЩэЕФФмСІ. ФЧУДгаПЩФмвЛИіkernelЕФИїИіЯпГЬПщБЛЗжХфЖрИіSM, ЫљвдgridжЛЪЧТпМВу, ЖјSMВХЪЧжДааЕФЮяРэВу.
ЭЈГЃ, ЕБЕїгУвЊдкGPUЩЯдЫааЕФКЏЪ§ЪБ, ЮвУЧНЋДЫжжКЏЪ§ГЦЮЊвбЦєЖЏЕФКЫ(kernel)КЏЪ§вЊВЙГфЕФЪЧ, КЫКЏЪ§ЦєЖЏЗНЪНЮЊвьВН: CPUДњТыНЋМЬајжДааЖјЮоашЕШД§КЫКЏЪ§ЭъГЩЦєЖЏ. ЕїгУCUDAдЫааЪБЬсЙЉЕФКЏЪ§ cudaDeviceSynchronize НЋЕМжТжїЛњ(CPU)ДњТыднзїЕШД§, жБжСЩшБИ (GPU)ДњТыжДааЭъГЩ, ВХФмдкCPUЩЯЛжИДжДаа. ЗёдђCPUЭъЪТСЫ, GPUЛЙдкЫу, ЕНФФРяШЅевМЦЫуЗЕЛиЕФНсЙћ?
ЯТЭМЪЧЮвGT 750MЕФЯдПЈаХЯЂ:
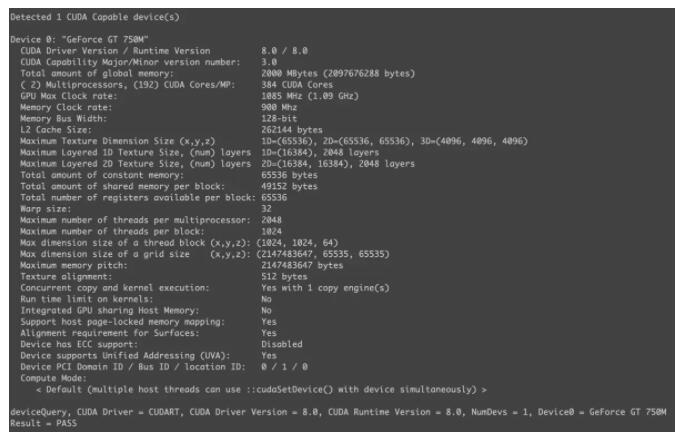
GT 750MЯдПЈаХЯЂ
SMВЩгУЕФЪЧ SIMT (Single-Instruction, Multiple-Thread, ЕЅжИСюЖрЯпГЬ)МмЙЙ, ЛљБОЕФжДааЕЅдЊЪЧЯпГЬЪј(warp), ЯпГЬЪјАќКЌ32ИіЯпГЬ(жСЩйФПЧАЖМЪЧ32), етаЉЯпГЬЭЌЪБжДааЯрЭЌЕФжИСю, ЕЋЪЧУПИіЯпГЬЖМАќКЌздМКЕФжИСюЕижЗМЦЪ§ЦїКЭМФДцЦїзДЬЌ,вВгаздМКЖРСЂЕФжДааТЗОЖ.
етИіwarpвдКѓЛЙЛсЫЕЕН.
МгЗЈ
ЪдзХгУCUDAБрГЬзівЛИіОиеѓМгЗЈ:
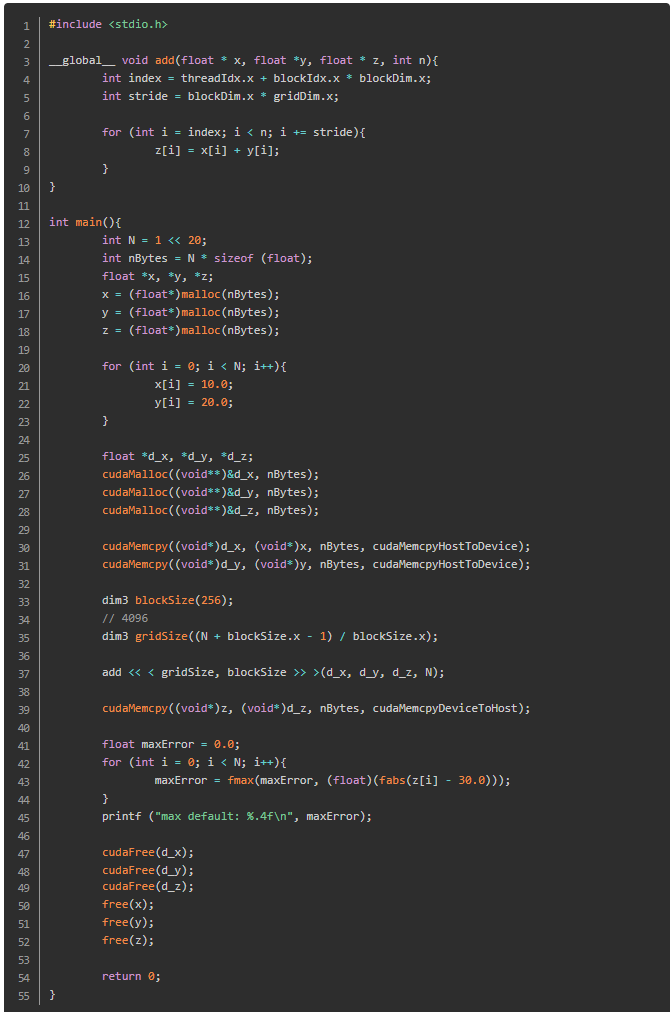
ОиеѓМгЗЈ
ЫЕЯТДњТыФкШн:
- ТпМВПЗж:
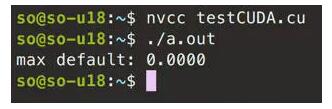
ЩъЧы1MЕФfloat, ЗХШы10.0. ЩъЧы1MЕФfloat, ЗХШы20.0, ШЛКѓМгЦ№РД. ЕЋЪЧЮвУЧВЛДцдкжБНгПДНсЙћЕФ, Ъ§СПЬЋЖрСЫ, ПЩвдПМТЧЭЗДђгЁ5ИіжЕ, ЮВДђгЁ5ИіжЕ. етРяОЭбЛЗМЦЫуЮѓВюжЕ, ЪфГізюДѓЕФФЧИіЮѓВюжЕ. зюКѓПДЕНЪЧ0ОЭДњБэШЋВПМЦЫуе§ШЗСЫ.
- CUDAВПЗж:
cudaMalloc((void**)&d_x, nBytes); ЪЧКмЧРблЕФ, втЫМвВКмМђЕЅ, дкGPUжаЩъЧыПеМф, ЖјВЛЪЧCPU.
гУ cudaMemcpy((void*)d_x, (void*)x, nBytes, cudaMemcpyHostToDevice); НЋCPUжаЕФЪ§ОнЗХШыЕНGPU, зЂвтЕкЖўИіЪЧдДЪ§Он, ЕкШ§ИіЪЧЗНЯђ.
dim3 blockSize(256); ВТВТвВжЊЕРСЫ, ОЭЪЧЩъЧы256Иіblock. dim3 gridSize() ЭЌРэ.
зюКѓ cudaMemcpy((void*)z, (void*)d_z, nBytes, cudaMemcpyDeviceToHost); ДгGPUжаАбНсЙћПНБДЛиCPU, зЂвтЕкШ§ИіВЮЪ§КЭжЎЧАЕФВЛЭЌ.
МЧЕУЪЭЗХЩъЧыЕФПеМф.
ШЛКѓПДЕНКЫКЏЪ§, _ global_ ЙиМќзжБэУївдЯТКЏЪ§НЋдкGPUЩЯдЫааВЂПЩШЋОжЕїгУ, ЖјдкДЫжжЧщПіЯТ, дђжИгЩCPUЛђGPUЕїгУ.
int index = threadIdx.x + blockIdx.x * blockDim.x; ЪЧЛёШЁЯпГЬЮЛжУ. ЦфЪЕВЛЙмЪЧЖрЩйЮЌЖШЕФОиеѓ, дкМЦЫуЛњФкДцжаЖМЪЧЯпадДцДЂЕФ, ЫљвдвЊРДвЛИівЛЮЌеЙПЊ. вРОнжЎЧАЫЕЕФНсЙЙ, CUDAКЫКЏЪ§ПЩвдЗУЮЪФмЙЛЪЖБ№ШчЯТСНжжЫїв§ЕФЬиЪтБфСП: е§дкжДааКЫКЏЪ§ЕФЯпГЬ(ЮЛгкЯпГЬПщФк)Ыїв§КЭЯпГЬЫљдкЕФЯпГЬПщ(ЮЛгкЭјИёФк)Ыїв§. етСНжжБфСПЗжБ№ЮЊthreadIdx.xКЭblockIdx.x. CUDAКЫКЏЪ§ПЩвдЗУЮЪИјГіПщжаЯпГЬЪ§ЕФЬиЪтБфСП: blockDim.x.
int stride = blockDim.x * gridDim.x; ЪЧМЦЫуЭјИёжаЕФзмЯпГЬЪ§ЃЌМДЭјИёжаЕФЯпГЬПщЪ§ГЫвдУПИіЯпГЬПщжаЕФЯпГЬЪ§ЃКgridDim.x * blockDim.x. етРяЕФВйзївВЪЧгХЛЏЪжЖЮ, вдКѓЛсдйЫЕЕН.
ЭГвЛФкДц
ЪБВЛЮвД§. CUDAЕФзюаТАцБО(АцБО6КЭИќИпАцБО)вбФмЧсЫЩЗжХфПЩгУгкCPUжїЛњКЭШЮвтЪ§СПGPUЩшБИЕФФкДц. CUDA 6.xв§Шы ЭГвЛФкДц(Unified Memory) . ОпЬхФкШнНЈвщВщдФЮвИјГіЕФСДНг, ЫЕЕФЗЧГЃЯИжТ. МђЕЅРДЫЕ, ОЭЪЧЩъЧывЛДЮОЭКУ, ВЛгУЯШCPUКѓGPU, дйПНБДРДПНБДШЅ, ЬЋЩЕ. ЕЋЪЧзЂвт, жЎКѓЛЙЪЧЛсЫЕАбHostЪ§ОнЭљDeviceЧЈвЦЕФВйзї, ЮЊСЫЬсЩ§адФм.
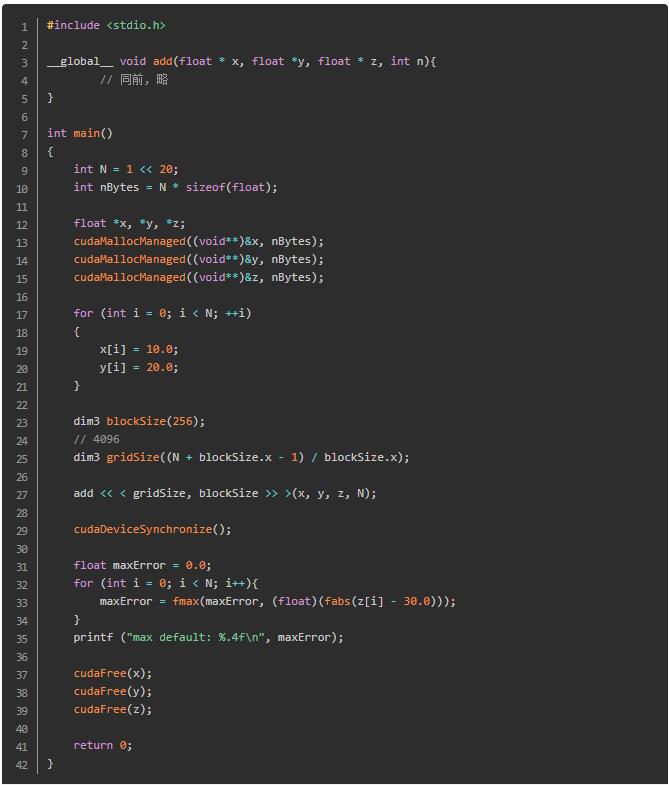
ОиеѓМгЗЈ
жЎЧАЕФШЗЪЕУЛгаетИіМђНр, ЕЋЪЧаЇТЪЛсИќИп, вдКѓдйЫЕ. зЂвтЕН cudaMallocManaged((void**)&x, nBytes); ОЭЪЧЭГвЛФкДцВйзї.
cudaDeviceSynchronize(); жЎЧАвВЫЕЙ§СЫ, жївЊЪЧгЩгкКЫКЏЪ§ЪЧвьВНЦєЖЏ, ашвЊCPUЕШД§GPUДњТыжДааЭъГЩ.
Ъ§ОнЧЈвЦ
дкжїЛњЕНЩшБИКЭЩшБИЕНжїЛњЕФФкДцДЋЪфЙ§ГЬжа, ПЩвдЪЙгУвЛжжММЪѕРДМѕЩйвГДэЮѓКЭАДашФкДцЧЈвЦГЩБО, ДЫММЪѕГЦЮЊ вьВНФкДцдЄШЁ . етдкКѓБпЕФадФмЬсЩ§ВПЗжЛсЫЕ, етРяЯШМђЕЅбнЪОЯТгУЗЈ:
ГЫЗЈ
ШЛКѓОиеѓЕуГЫМЦЫуДњТыВЮПМ етЦЊЮФеТ . ДѓЬхЯрЫЦ, ВЛЖрЫЕ, жЎКѓЛсЗжЮіОпЬхАИР§.
зюКѓ
змЖјбджЎ, GPUБрГЬЕФзюДѓФбЕудкгкадФмЬсЩ§, ЯывЊбЇКУGPU, МмЙЙвЛЖЈвЊМЧЧхГў.
|





