| БрМЭЦМі: |
БОЮФЯЕЭГЕиНВНтСЫGPUЕФРњЪЗЁЂЗЂеЙЁЂЙЄзїСїГЬЃЌвдМАВПЗжЙ§ГЬЕФЯИЛЏЫЕУїКЭгУЕНЕФИїжжММЪѕЃЌЮвУЧДгжаПЩвдПДЕНGPUМмЙЙЕФЖЏЛњЁЂЛњжЦЁЂЦПОБЃЌвдМАЮДРДЕФЗЂеЙЁЃ
РДздгкВЉПЭдА ,гЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
вЛЁЂЕМбд
ЖдгкДѓЖрЪ§ЭМаЮфжШОПЊЗЂепЃЌGPUЪЧМШЪьЯЄгжФАЩњЕФВПМўЃЌЪьЯЄЕФЪЧУПЬьЖМашвЊИњЫќДђНЛЕРЃЌФАЩњЕФЪЧGPUОЭШчвЛИіКкКаЃЌВЛжЊЕРЦфФкВПгВМўМмЙЙЃЌИќЮоДгЬИМАЦфдЫааЛњжЦЁЃ
БОЮФвдNVIDIAзїЮЊжїЯпЃЌНЋЪдЭМШЋУцЧвЩюШыЕиЦЪЮіGPUЕФгВМўМмЙЙМАдЫааЛњжЦЃЌжївЊЩцМАPCзРУцМЖЕФGPUЃЌВЛЛсИВИЧвЦЖЏЖЫЁЂзЈвЕМЦЫуЁЂЭМаЮЙЄзїеОМЖБ№ЕФGPUЁЃ
ШєвЊЭЈЖСБОЮФЃЌвЊЧѓЖСепгавЛЖЈЭМаЮбЇЕФЛљДЁЃЌСЫНтGPUфжШОЙмЯпЃЌзюКУаДЙ§HLSLЁЂGLSLЕШshaderДњТыЁЃ
1.1 ЮЊКЮвЊСЫНтGPUЃП
СЫНтGPUгВМўМмЙЙКЭРэНтдЫааЛњжЦЃЌБЪепШЯЮЊКУДІЖрЖрЃЌзмНсГіРДгаЃК
РэНтGPUЦфЮяРэНсЙЙКЭдЫааЛњжЦЃЌGPUгЩКкКаБфАзКаЁЃ
ИќвзевГіфжШОЦПОБЃЌаДГіИпаЇТЪshaderДњТыЁЃ
НєИњЪБДњГБСїЃЌСЫНтзюЧАбифжШОММЪѕЃЁ
ММЖрВЛбЙЩэЃЁ
1.2 ФкШнвЊЕу
БОЮФЕФФкШнвЊЕуЬсСЖШчЯТЃК
GPUМђНщЁЂРњЪЗЁЂЬиадЁЃ
GPUгВМўМмЙЙЁЃ
GPUКЭCPUЕФаЕїЕїЖШЛњжЦЁЃ
GPUЛКДцНсЙЙЁЃ
GPUфжШОЙмЯпЁЃ
GPUдЫааЛњжЦЁЃ
GPUгХЛЏММЧЩЁЃ
1.3 ДјзХЮЪЬтдФЖС
ЪЪЕБДјзХЮЪЬтШЅдФЖСММЪѕЮФеТЃЌЭЈГЃФмМгЩюРэНтКЭМЧвфЃЌдФЖСБОЮФПЩДјзХвдЯТЮЪЬтЃК
1ЁЂGPUЪЧШчКЮгыCPUаЕїЙЄзїЕФЃП
2ЁЂGPUвВгаЛКДцЛњжЦТ№ЃПгаМИВуЃПЫќУЧЕФЫйЖШВювьЖрЩйЃП
3ЁЂGPUЕФфжШОСїГЬгаФФаЉНзЖЮЃПЫќУЧЕФЙІФмЗжБ№ЪЧЪВУДЃП
4ЁЂEarly-ZММЪѕЪЧЪВУДЃПЗЂЩњдкФФИіНзЖЮЃПетИіНзЖЮЛЙЛсЗЂЩњЪВУДЃПЛсВњЩњЪВУДЮЪЬтЃПШчКЮНтОіЃП
5ЁЂSIMDКЭSIMTЪЧЪВУДЃПЫќУЧЕФКУДІЪЧЪВУДЃПco-issueФиЃП
6ЁЂGPUЪЧВЂааДІРэЕФУДЃПШєЪЧЃЌгВМўВуЪЧШчКЮЩшМЦКЭЪЕЯжЕФЃП
7ЁЂGPCЁЂTPCЁЂSMЪЧЪВУДЃПWarpгжЪЧЪВУДЃПЫќУЧКЭCoreЁЂThreadжЎМфЕФЙиЯЕШчКЮЃП
8ЁЂЖЅЕузХЩЋЦїЃЈVSЃЉКЭЯёЫизХЩЋЦїЃЈPSЃЉПЩвдЪЧЭЌвЛДІРэЕЅдЊТ№ЃПЮЊЪВУДЃП
9ЁЂЯёЫизХЩЋЦїЃЈPSЃЉЕФзюаЁДІРэЕЅЮЛЪЧ1ЯёЫиТ№ЃПЮЊЪВУДЃПЛсДјРДЪВУДгАЯьЃП
10ЁЂShaderжаЕФifЁЂforЕШгяОфЛсНЕЕЭфжШОаЇТЪТ№ЃПЮЊЪВУДЃП
11ЁЂШчЯТЭМЃЌфжШОЯрЭЌУцЛ§ЕФЭМаЮЃЌШ§НЧаЮЪ§СПЩйЃЈзѓЃЉЕФЛЙЪЧЪ§СПЖрЃЈгвЃЉЕФаЇТЪИќПьЃПЮЊЪВУДЃП
12ЁЂGPU ContextЪЧЪВУДЃПгаЪВУДзїгУЃП
13ЁЂдьГЩфжШОЦПОБЕФЮЪЬтКмПЩФмгаФФаЉЃПИУШчКЮБмУтЛђгХЛЏЫќУЧЃП
ШчЙћдФЖСЭъБОЮФЃЌФмЙЛЗЧГЃЧхЮњЕиЛиД№вдЩЯЫљгаЮЪЬтЃЌФЧУДЃЌЙЇЯВФуеЦЮеЕНБОЮФЕФОЋЫшСЫЃЁ
ЖўЁЂGPUИХЪі
2.1 GPUЪЧЪВУДЃП
GPUШЋГЦЪЧGraphics Processing UnitЃЌЭМаЮДІРэЕЅдЊЁЃЫќЕФЙІФмзюГѕгыУћзжвЛжТЃЌЪЧзЈУХгУгкЛцжЦЭМЯёКЭДІРэЭМдЊЪ§ОнЕФЬиЖЈаОЦЌЃЌКѓРДНЅНЅМгШыСЫЦфЫќКмЖрЙІФмЁЃ

NVIDIA GPUаОЦЌЪЕЮяЭМЁЃ
ЮвУЧШеГЃЬжТлGPUКЭЯдПЈЪБЃЌОГЃЛьЮЊвЛЬИЃЌбЯИёРДЫЕЪЧгаЫљЧјБ№ЕФЁЃGPUЪЧЯдПЈЃЈVideo cardЁЂDisplay
cardЁЂGraphics cardЃЉзюКЫаФЕФВПМўЃЌЕЋГ§СЫGPUЃЌЯдПЈЛЙгаЩШШШЦїЁЂЭЈбЖдЊМўЁЂгыжїАхКЭЯдЪОЦїСЌНгЕФИїРрВхВлЁЃ
ЖдгкPCзРУцЃЌЩњВњGPUЕФГЇЩЬжївЊгаСНМвЃК
NVIDIAЃКгЂЮАДяЃЌЪЧЕБНёЪзЧќвЛжИЕФЭМаЮфжШОММЪѕЕФв§СьепКЭGPUЩњВњЩЬйЎйЎепЁЃNVIDIAЕФВњЦЗЫзГЦNПЈЃЌДњБэВњЦЗгаGeForceЯЕСаЁЂGTXЯЕСаЁЂRTXЯЕСаЕШЁЃ

AMDЃКМШЪЧCPUЩњВњЩЬЃЌвВЪЧGPUЩњВњЩЬЃЌЫќМвЕФЯдПЈЫзГЦAПЈЁЃДњБэВњЦЗгаRadeonЯЕСаЁЃ

ЕБШЛЃЌNVIDIAКЭAMDвВЖМЩњВњвЦЖЏЖЫЁЂЭМаЮЙЄзїеОРраЭЕФGPUЁЃДЫЭтЃЌЩњВњвЦЖЏЖЫЯдПЈЕФГЇЩЬЛЙгаARMЁЂImagination
TechnologyЁЂИпЭЈЕШЙЋЫОЁЃ
2.2 GPUРњЪЗ
GPUздДгЩЯЪРМЭ90ФъДњГіЯжГћаЮвдРДЃЌОЙ§20ЖрФъЕФЗЂеЙЃЌвбОЗЂеЙГЩВЛНіНіЪЧфжШОЭМаЮетУДМђЕЅЃЌЛЙАќКЌСЫЪ§бЇМЦЫуЁЂЮяРэФЃФтЁЂAIдЫЫуЕШЙІФмЁЃ
2.2.1 NV GPUЗЂеЙЪЗ
вдЯТЪЧGPUЗЂеЙНкЕуБэЃК
1995 ЈC NV1

NV1ЕФфжШОЛУцМАЦфЬиадЁЃ
1997 ЈC Riva 128 (NV3), DX3
1998 ЈC Riva TNT (NV4), DX5
32ЮЛбеЩЋ, 24ЮЛZЛКДц, 8ЮЛФЃАхЛКДц
ЫЋЮЦРэ, ЫЋЯпадЙ§ТЫ
УПЪБжг2ЯёЫи (2 ppc)
1999 - GeForce 256ЃЈNV10ЃЉ
ЙЬЖЈЙмЯпЃЌжЇГжDirectX 7.0
гВМўT&LЃЈTransform & lightingЃЌзјБъБфЛЛКЭЙтееЃЉ
СЂЗНЬхЛЗОГЭМЃЈCubemapsЃЉ
DOT3 ЈC bump mapping
2БЖИїЯђвьадЙ§ТЫ
Ш§ЯпадЙ§ТЫ
DXTЮЦРэбЙЫѕ
4ppc
в§ШыЁАGPUЁБЪѕгя

NV10ЕФфжШОЛУцМАЦфЬиадЁЃ
2001 - GeForce 3
DirectX 8.0
Shader Model 1.0
ПЩБрГЬфжШОЙмЯп
ЖЅЕузХЩЋЦї
ЯёЫизХЩЋЦї
3DЮЦРэ
гВМўвѕгАЭМ
8БЖИїЯђвьадЙ§ТЫ
ЖрВЩбљПЙОтГнЃЈMSAAЃЉ
4 ppc

NV20ЕФфжШОЛУцМАЦфЬиадЁЃ
2003 - GeForce FXЯЕСаЃЈNV3xЃЉ
DirectX 9.0
Shader Model 2.0
256ЖЅЕуВйзїжИСю
32ЮЦРэ + 64ЫуЪѕЯёЫиВйзїжИСю
Shader Model 2.0a
256ЖЅЕуВйзїжИСю
512ЯёЫиВйзїжИСю
зХЩЋгябд
HLSL
CGSL
GLSL

NV30ЕФфжШОЛУцМАЦфЬиадЁЃ
2004 - GeForce 6ЯЕСа (NV4x)
DirectX 9.0c
Shader Model 3.0
ЖЏЬЌСїПижЦ
ЗжжЇЁЂбЛЗЁЂЩљУїЕШ
ЖЅЕуЮЦРэЖСШЁ
ИпЖЏЬЌЗЖЮЇЃЈHDRЃЉ
64ЮЛфжШОЮЦРэЃЈRender TargetЃЉ
FP16*4 ЮЦРэЙ§ТЫКЭЛьКЯ
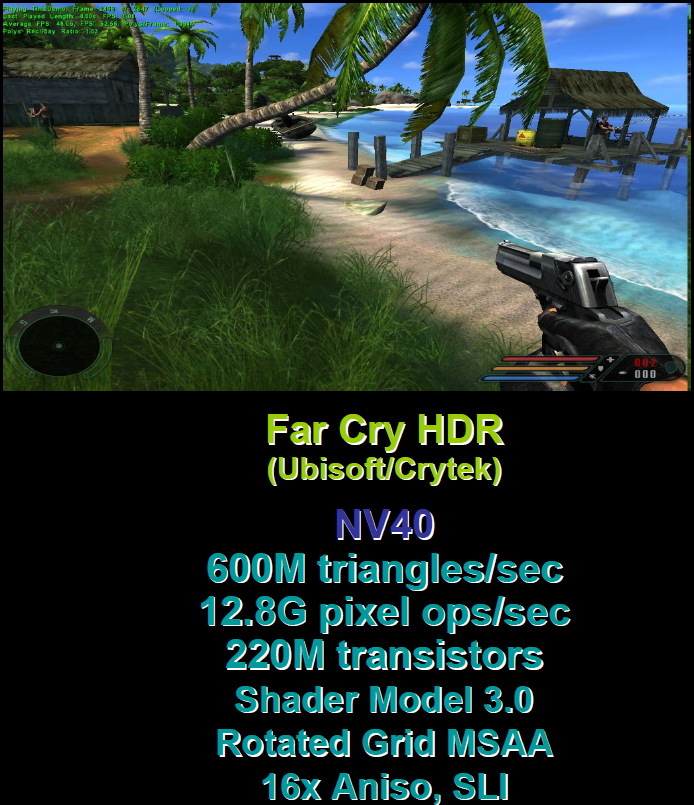
NV40ЕФфжШОЛУцМАЦфЬиадЁЃ
2006 - GeForce 8ЯЕСа (G8x)
DirectX 10.0
Shader Model 4.0
МИКЮзХЩЋЦїЃЈGeometry ShadersЃЉ
УЛгаЩЯЯоЮЛЃЈNo caps bitsЃЉ
ЭГвЛЕФзХЩЋЦїЃЈUnified ShadersЃЉ
VistaЯЕЭГШЋаТЧ§ЖЏ
ЛљгкGPUМЦЫуЕФCUDAЮЪЪР
GPUМЦЫуФмСІвдGFLOPSМЦСПЁЃ

NV G80ЕФфжШОЛУцМАЦфЬиадЁЃ
2010 - GeForce 405ЃЈGF119ЃЉ
DirectX 11.0
ЧњУцЯИЗжЃЈTessellationЃЉ
ЭтПЧзХЩЋЦїЃЈHull ShaderЃЉ
ЯтЧЖЕЅдЊЃЈtessellatorЃЉ
гђзХЩЋЦїЃЈDomain ShaderЃЉ
МЦЫузХЩЋЦїЃЈCompute ShaderЃЉ
жЇГжStream Output
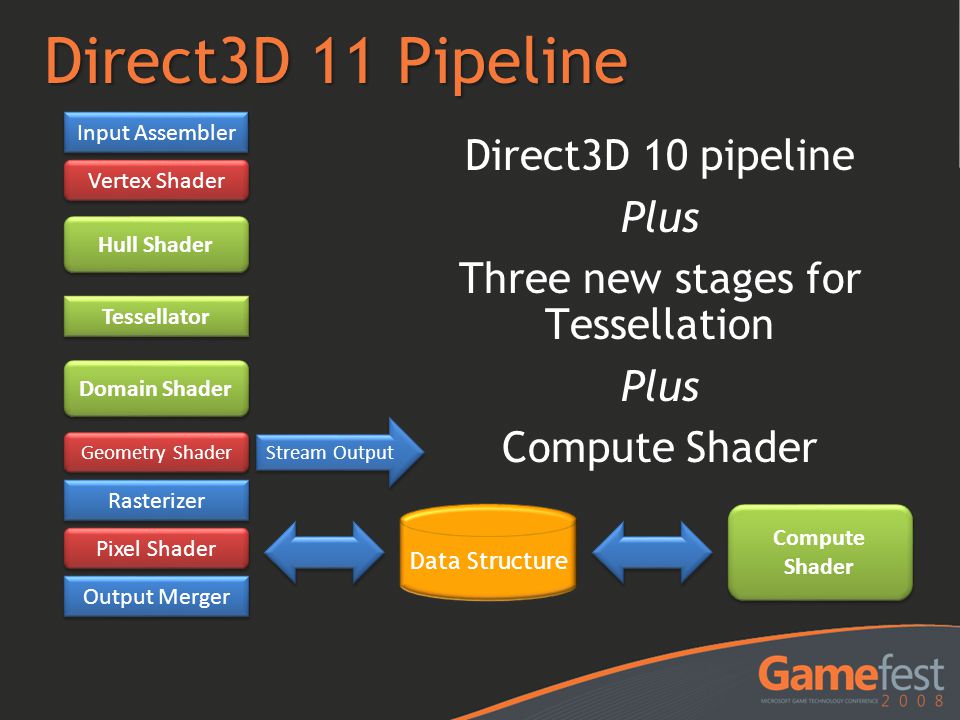
DirectX 11ЕФфжШОЙмЯпЁЃ
ЖрЯпГЬжЇГж
ИФНјЕФЮЦРэбЙЫѕ
Shader Model 5.0
ИќЖржИСюЁЂДцДЂЕЅдЊЁЂМФДцЦї
УцЯђЖдЯѓзХЩЋгябд
ЧњУцЯИЗж
МЦЫузХЩЋЦї
2014 - GeForceGT 710ЃЈGK208ЃЉ
DirectX 12.0
ЧсСПЛЏЧ§ЖЏВу
гВМўМЖЖрЯпГЬфжШОжЇГж
ИќЭъЩЦЕФгВМўзЪдДЙмРэ
2016 - GeForceGTX 1060 6GB
ЪзДЮжЇГжRTXКЭDXRММЪѕЃЌМДжЇГжЙтЯпзЗзй
в§ШыRT CoreЃЈЙтЯпзЗзйКЫаФЃЉ

жЇГжRTXЙтЯпзЗзйЕФЯдПЈСаБэЁЃ
2018 - TITAN RTXЃЈTU102ЃЉ
DirectX 12.1ЃЌOpenGL 4.5
6GPCЃЌ36TPCЃЌ72SMЃЌ72RT CoreЃЌ...
8KЗжБцТЪЃЌ1770MHzжїЦЕЃЌ24GЯдДцЃЌ384ЮЛДјПэ

ДгЩЯУцПЩвдПДГіРДЃЌGPUгВМўЪЧАщЫцзХЭМаЮAPIБъзМЁЂгЮЯЗвЛЦ№ЗЂеЙЕФЃЌВЂЧвЫќУЧаЮГЩСЫЯрЛЅЯрГЩЁЂЯрЛЅДйНјЕФСМадЙиЯЕЁЃ
2.2.2 NV GPUМмЙЙЗЂеЙЪЗ
жкЫљжмжЊЃЌCPUЕФЗЂеЙЗћКЯФІЖћЖЈТЩЃКУП18ИідТЫйЖШЗБЖЁЃ

ДІРэаОЦЌОЇЬхЙмЪ§СПЗћКЯФІЖћЖЈТЩЃЌЭМгвЪЧФІЖћБОШЫЃЌIntelЕФДДЪМШЫ
ЖјNVIDIAДДЪМШЫЛЦШЪбЋдкКмЖрФъЧАдјаХЪФЕЉЕЉЕиЫЕЃЌGPUЕФЫйЖШКЭЙІФмвЊГЌдНФІЖћЖЈТЩЃЌУП6ИідТОЭЗвЛБЖЁЃNVЕФGPUЗЂеЙЪЗжЄУїЃЌЫћШЗЪЕзіЕНСЫЃЁGPUЕФЬсЫйЗљТЪдЖГЌCPUЃК
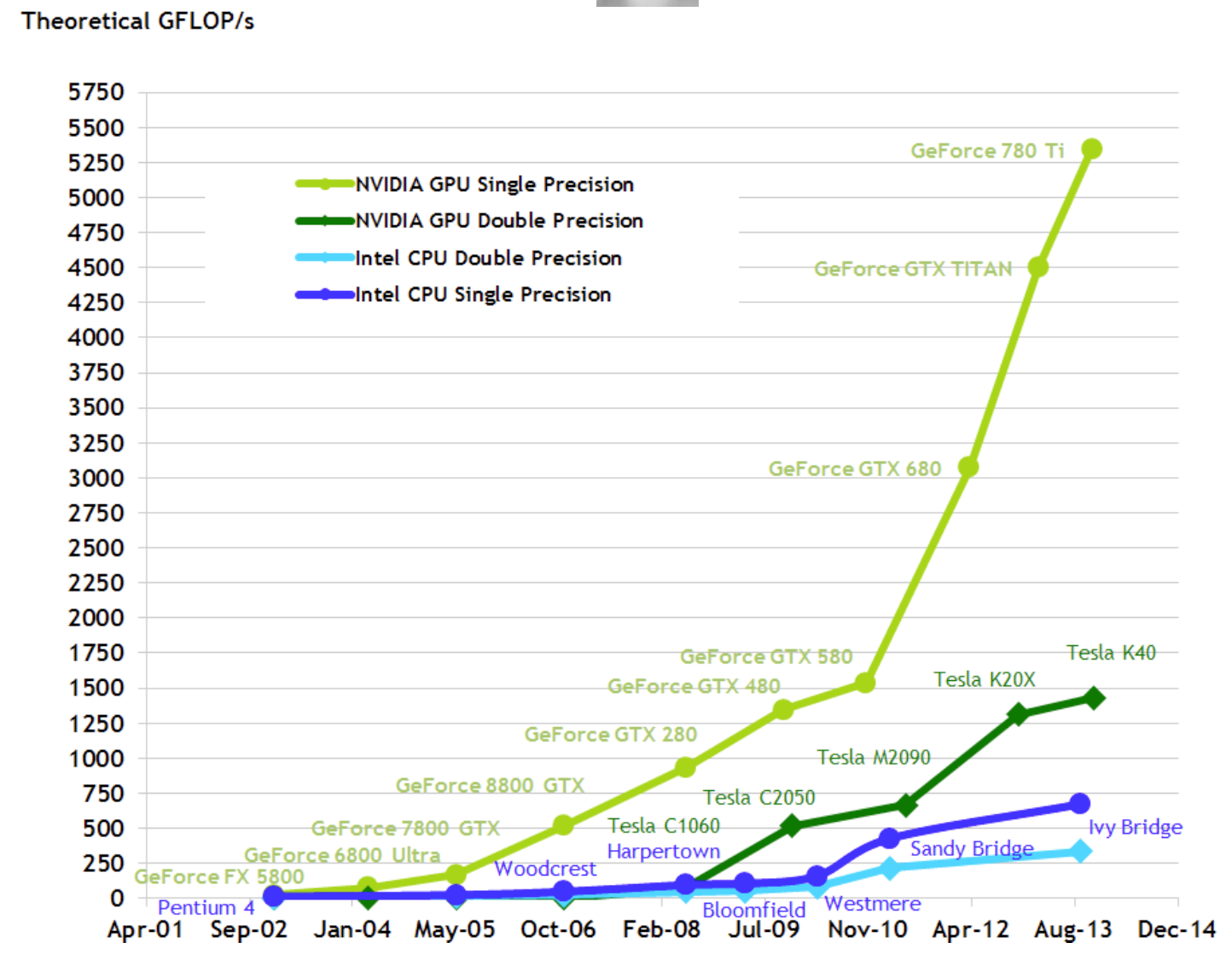
NVIDIA GPUМмЙЙРњОЖрДЮБфИяЃЌДгЦ№ГѕЕФTeslaЗЂеЙЕНзюаТЕФTuringМмЙЙЃЌЗЂеЙЪЗПЩЗжЮЊвдЯТЪБМфНкЕуЃК
2008 - Tesla
TeslaзюГѕЪЧИјМЦЫуДІРэЕЅдЊЪЙгУЕФЃЌгІгУгкдчЦкЕФCUDAЯЕСаЯдПЈаОЦЌжаЃЌВЂВЛЪЧеце§втвхЩЯЕФЦеЭЈЭМаЮДІРэаОЦЌЁЃ
2010 - Fermi
FermiЪЧЕквЛИіЭъећЕФGPUМЦЫуМмЙЙЁЃЪзПюПЩжЇГжгыЙВЯэДцДЂНсКЯДПcacheВуДЮЕФGPUМмЙЙЃЌжЇГжECCЕФGPUМмЙЙЁЃ
2012 - Kepler
KeplerЯрНЯгкFermiИќПьЃЌаЇТЪИќИпЃЌадФмИќКУЁЃ
2014 - Maxwell
ЦфШЋаТЕФСЂЬхЯёЫиШЋОжЙтее (VXGI) ММЪѕЪзДЮШУгЮЯЗ GPU ФмЙЛЬсЙЉЪЕЪБЕФЖЏЬЌШЋОжЙтееаЇЙћЁЃЛљгк
Maxwell МмЙЙЕФ GTX 980 КЭ 970 GPU ВЩгУСЫАќРЈЖржЁВЩбљПЙОтГн (MFAA)ЁЂЖЏЬЌГЌМЖЗжБцТЪ
(DSR)ЁЂVR Direct вдМАГЌНкФмЩшМЦдкФкЕФвЛЯЕСааТММЪѕЁЃ
2016 - Pascal
Pascal МмЙЙНЋДІРэЦїКЭЪ§ОнМЏГЩдкЭЌвЛИіГЬађАќФкЃЌвдЪЕЯжИќИпЕФМЦЫуаЇТЪЁЃ1080ЯЕСаЁЂ1060ЯЕСаЛљгкPascalМмЙЙ
2017 - Volta
Volta ХфБИ640 ИіTensor КЫаФЃЌУПУыПЩЬсЙЉГЌЙ§100 езДЮИЁЕудЫЫу(TFLOPS)
ЕФЩюЖШбЇЯАаЇФмЃЌБШЧАвЛДњЕФPascal МмЙЙПь5 БЖвдЩЯЁЃ
2018 - Turing
Turing МмЙЙХфБИСЫУћЮЊ RT Core ЕФзЈгУЙтЯпзЗзйДІРэЦїЃЌФмЙЛвдИпДяУПУы 10 Giga
Rays ЕФЫйЖШЖдЙтЯпКЭЩљвєдк 3D ЛЗОГжаЕФДЋВЅНјааМгЫйМЦЫуЁЃTuring МмЙЙНЋЪЕЪБЙтЯпзЗзйдЫЫуМгЫйжСЩЯвЛДњ
NVIDIA Pascal? МмЙЙЕФ 25 БЖЃЌВЂФмвдИпГі CPU 30 ЖрБЖЕФЫйЖШНјааЕчгАаЇЙћЕФзюжежЁфжШОЁЃ2060ЯЕСаЁЂ2080ЯЕСаЯдПЈвВЪЧЬјЙ§СЫVoltaжБНгбЁдёСЫTuringМмЙЙЁЃ
ЯТЭМЪЧВПЗжGPUМмЙЙЕФЗЂеЙРњГЬЃК
2.3 GPUЕФЙІФм
ЯжДњGPUГ§СЫЛцжЦЭМаЮЭтЃЌЛЙЕЃЕБСЫКмЖрЖюЭтЕФЙІФмЃЌзлКЯЦ№РДШчЯТМИЗНУцЃК
ЭМаЮЛцжЦЁЃ
етЪЧGPUзюДЋЭГЕФФУЪжКУЯЗЃЌвВЪЧзюЛљДЁЁЂзюКЫаФЕФЙІФмЁЃЮЊДѓЖрЪ§PCзРУцЁЂвЦЖЏЩшБИЁЂЭМаЮЙЄзїеОЬсЙЉЭМаЮДІРэКЭЛцжЦЙІФмЁЃ
ЮяРэФЃФтЁЃ
GPUгВМўМЏГЩЕФЮяРэв§ЧцЃЈPhysXЁЂHavokЃЉЃЌЮЊгЮЯЗЁЂЕчгАЁЂНЬг§ЁЂПЦбЇФЃФтЕШСьгђЬсЙЉСЫГЩАйЩЯЧЇБЖадФмЕФЮяРэФЃФтЃЌЪЙЕУвдЧАашвЊГЄЪБМфМЦЫуЕФЮяРэФЃФтЕУвдЪЕЪБГЪЯжЁЃ
КЃСПМЦЫуЁЃ
МЦЫузХЩЋЦїМАСїЪфГіЕФГіЯжЃЌЮЊИїжжПЩвдВЂааМЦЫуЕФКЃСПашЧѓЕУвдЪЕЯжЃЌCUDAОЭЪЧзюКУЕФР§жЄЁЃ
AIдЫЫуЁЃ
НќФъРДЃЌШЫЙЄжЧФмЕФсШЦ№ЭЦЖЏСЫGPUМЏГЩСЫAI CoreдЫЫуЕЅдЊЃЌЗДВИAIдЫЫуФмСІЕФЬсЩ§ЃЌИјИїааИївЕДјРДСЫМЦЫуФмСІЕФЬсЩ§ЁЃ
ЦфЫќМЦЫуЁЃ
вєЪгЦЕБрНтТыЁЂМгНтУмЁЂПЦбЇМЦЫуЁЂРыЯпфжШОЕШЕШЖМРыВЛПЊЯжДњGPUЕФВЂааМЦЫуФмСІКЭКЃСПЭЬЭТФмСІЁЃ
Ш§ЁЂGPUЮяРэМмЙЙ
3.1 GPUКъЙлЮяРэНсЙЙ
гЩгкФЩУзЙЄвеЕФв§ШыЃЌGPUПЩвдНЋЪ§вдвкМЧЕФОЇЬхЙмКЭЕчзгЦїМўМЏГЩдквЛИіаЁаЁЕФаОЦЌФкЁЃДгКъЙлЮяРэНсЙЙЩЯПДЃЌЯжДњДѓЖрЪ§зРУцМЖGPUЕФДѓаЁИњЪ§УЖгВБвЭЌЕШДѓаЁЃЌВПЗжЩѕжСБШвЛУЖгВБвЛЙаЁЃЈЯТЭМЃЉЁЃ

ИпЭЈцчСњ853ЯдЪОаОЦЌБШгВБвЛЙаЁ
ЕБGPUНсКЯЩЂШШЗчЩШЁЂPCIВхВлЁЂHDMIНгПкЕШВПМўжЎКѓЃЌОЭзщГЩСЫЯдПЈЃЈЯТЭМЃЉЁЃ

ЯдПЈВЛФмЖРСЂЙЄзїЃЌашвЊзАдидкжїАхЩЯЃЌНсКЯCPUЁЂФкДцЁЂЯдДцЁЂЯдЪОЦїЕШгВМўЩшБИЃЌзщГЩЭъећЕФPCЛњЁЃ

ДюдиСЫЯдПЈЕФжїАхЁЃ
3.2 GPUЮЂЙлЮяРэНсЙЙ
GPUЕФЮЂЙлНсЙЙвђВЛЭЌГЇЩЬЁЂВЛЭЌМмЙЙЖМЛсгаЫљВювьЃЌЕЋКЫаФВПМўЁЂИХФюЁЂвдМАдЫааЛњжЦДѓЭЌаЁвьЁЃЯТУцНЋеЙЪОВПЗжМмЙЙЕФGPUЮЂЙлЮяРэНсЙЙЁЃ
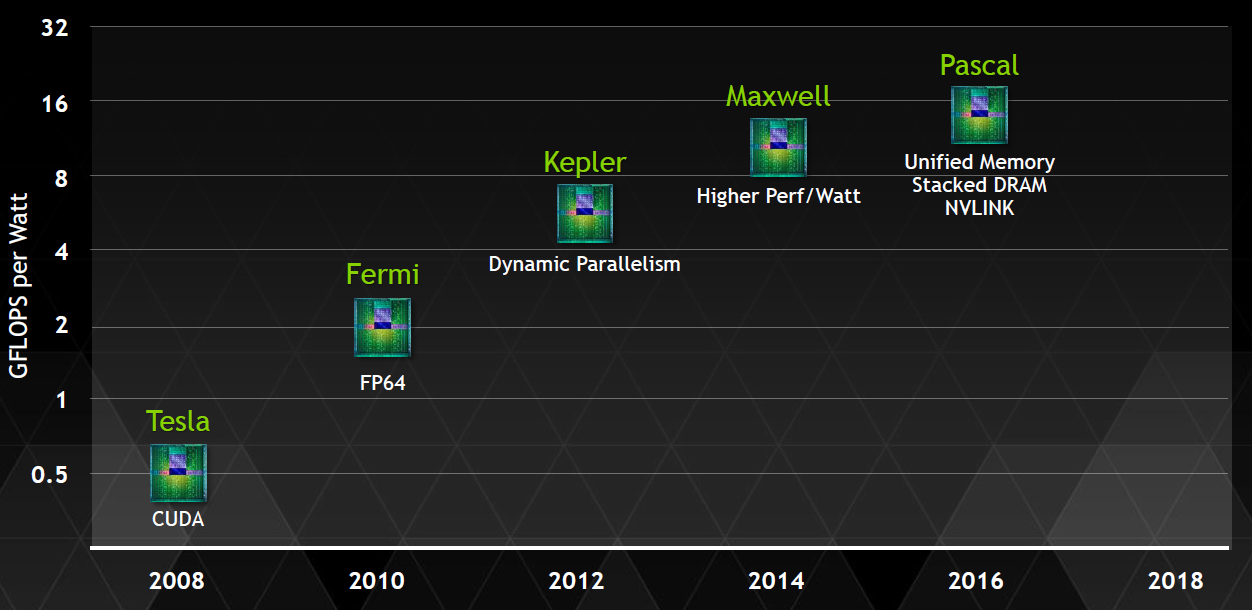
3.2.1 NVidia TeslaМмЙЙ
TeslaЮЂЙлМмЙЙзмРРЭМШчЩЯЁЃЯТУцНЋВћЪіЫќЕФЬиадКЭИХФюЃК
гЕга7зщTPCЃЈTexture/Processor ClusterЃЌЮЦРэДІРэДиЃЉ
УПИіTPCгаСНзщSMЃЈStream MultiprocessorЃЌСїЖрДІРэЦїЃЉ
УПИіSMАќКЌЃК
6ИіSPЃЈStreaming ProcessorЃЌСїДІРэЦїЃЉ
2ИіSFUЃЈSpecial Function UnitЃЌЬиЪтКЏЪ§ЕЅдЊЃЉ
L1ЛКДцЁЂMT IssueЃЈЖрЯпГЬжИСюЛёШЁЃЉЁЂC-CacheЃЈГЃСПЛКДцЃЉЁЂЙВЯэФкДц
Г§СЫTPCКЫаФЕЅдЊЃЌЛЙгагыЯдДцЁЂCPUЁЂЯЕЭГФкДцНЛЛЅЕФИїжжВПМўЁЃ
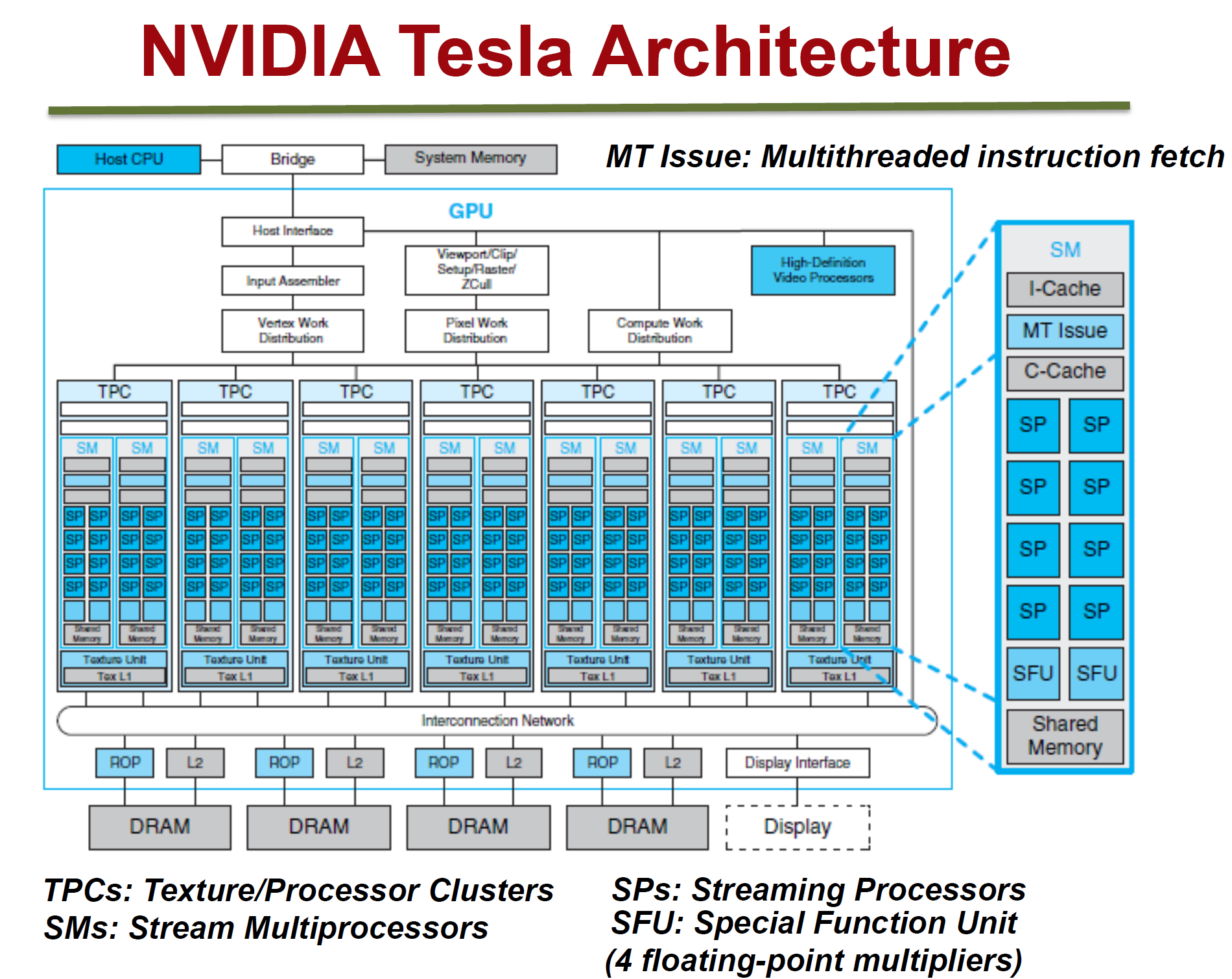
3.2.2 NVidia FermiМмЙЙ
FermiМмЙЙШчЩЯЭМЃЌЫќЕФЬиадШчЯТЃК
гЕга16ИіSM
УПИіSMЃК
2ИіWarpЃЈЯпГЬЪјЃЉ
СНзщЙВ32ИіCore
16зщМгдиДцДЂЕЅдЊЃЈLD/STЃЉ
4ИіЬиЪтКЏЪ§ЕЅдЊЃЈSFUЃЉ
УПИіWarpЃК
16ИіCore
WarpБрХХЦїЃЈWarp SchedulerЃЉ
ЗжЗЂЕЅдЊЃЈDispatch UnitЃЉ
УПИіCoreЃК
1ИіFPUЃЈИЁЕуЪ§ЕЅдЊЃЉ
1ИіALUЃЈТпМдЫЫуЕЅдЊЃЉ
3.2.3 NVidia MaxwellМмЙЙ

ВЩгУСЫMaxwellЕФGM204ЃЌгЕга4ИіGPCЃЌУПИіGPCга4ИіSMЃЌЖдБШTeslaМмЙЙРДЫЕЃЌдкДІРэЕЅдЊЩЯгаСЫКмДѓЕФЬсЩ§ЁЃ
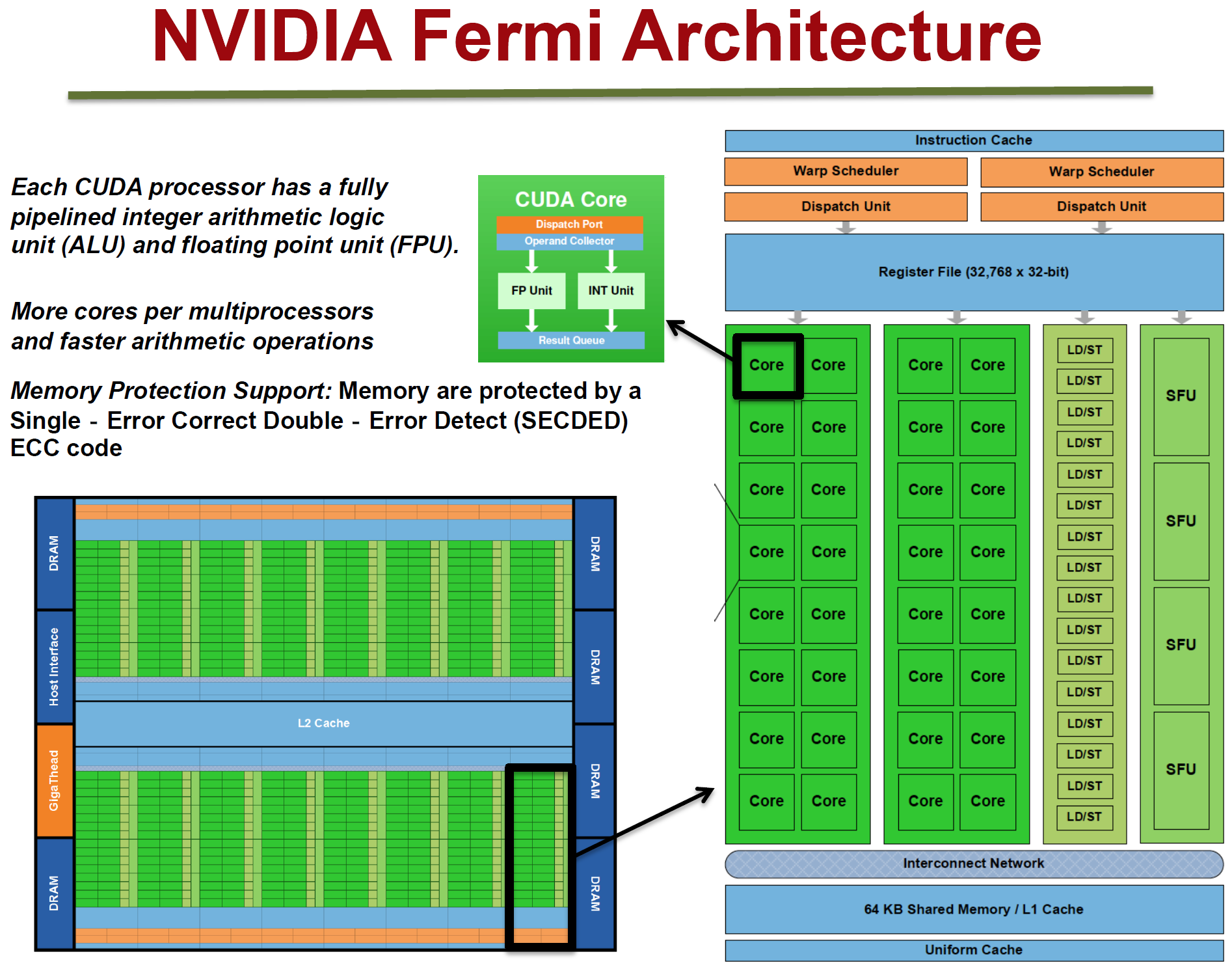
3.2.4 NVidia KeplerМмЙЙ
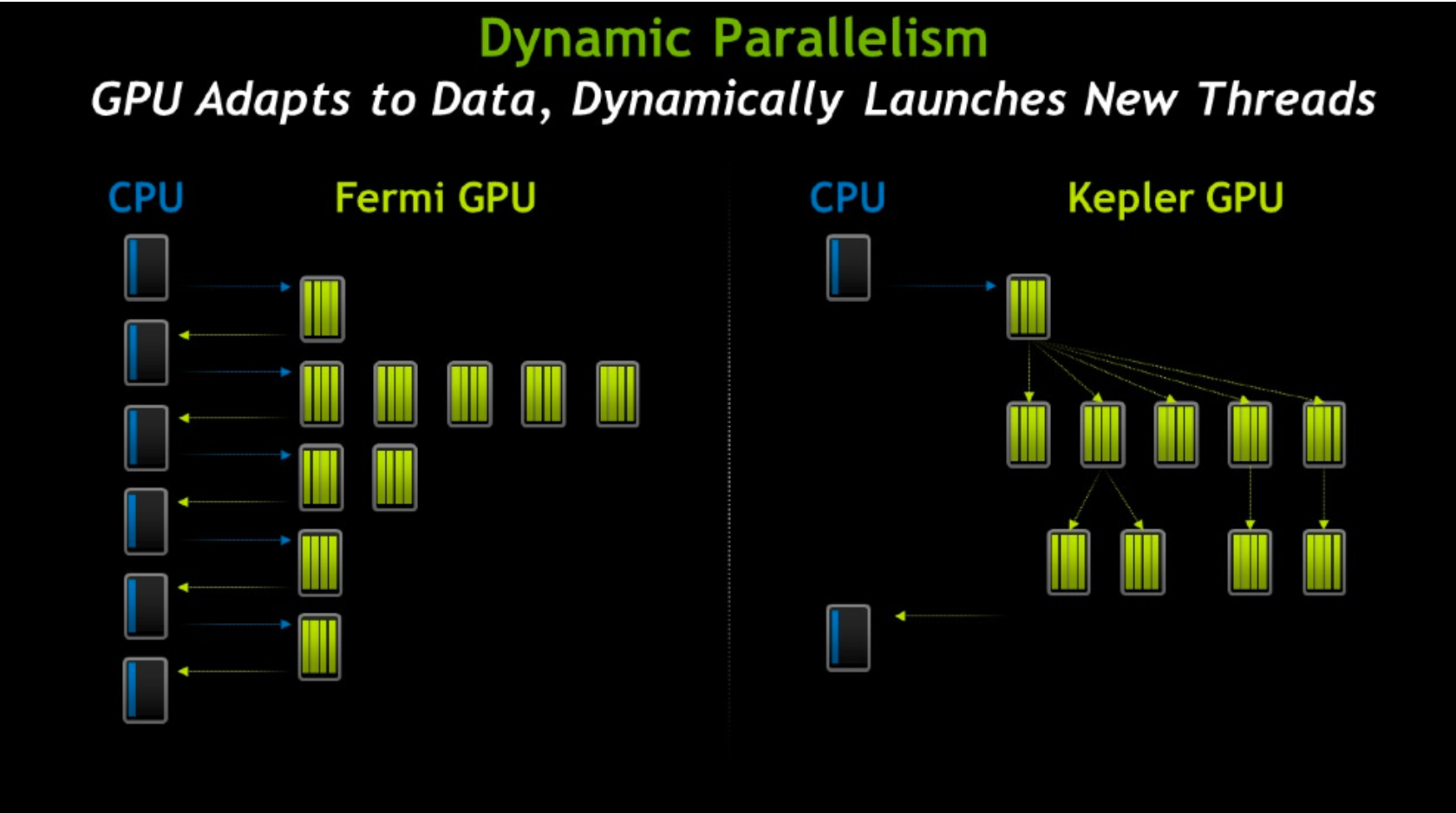
KeplerГ§СЫдкгВМўгаСЫЬсЩ§ЃЌгаСЫИќЖрДІРэЕЅдЊжЎЭтЃЌЛЙНЋSMЩ§МЖЕНСЫSMXЁЃSMXЪЧИФНјЕФМмЙЙЃЌжЇГжЖЏЬЌДДНЈфжШОЯпГЬЃЈЯТЭМЃЉЃЌвдНЕЕЭбгГйЁЃ
3.2.5 NVidia TuringМмЙЙ

ЩЯЭМЪЧВЩФЩСЫTuringМмЙЙЕФTU102 GPUЃЌЫќЕФЬиЕуШчЯТЃК
6 GPCЃЈЭМаЮДІРэДиЃЉ
36 TPCЃЈЮЦРэДІРэДиЃЉ
72 SMЃЈСїЖрДІРэЦїЃЉ
УПИіGPCга6ИіTPCЃЌУПИіTPCга2ИіSM
4,608 CUDAКЫ
72 RTКЫ
576 TensorКЫ
288 ЮЦРэЕЅдЊ
12x32ЮЛ GDDR6ФкДцПижЦЦї (ЙВ384ЮЛ)
ЕЅИіSMЕФНсЙЙЭМШчЯТЃК
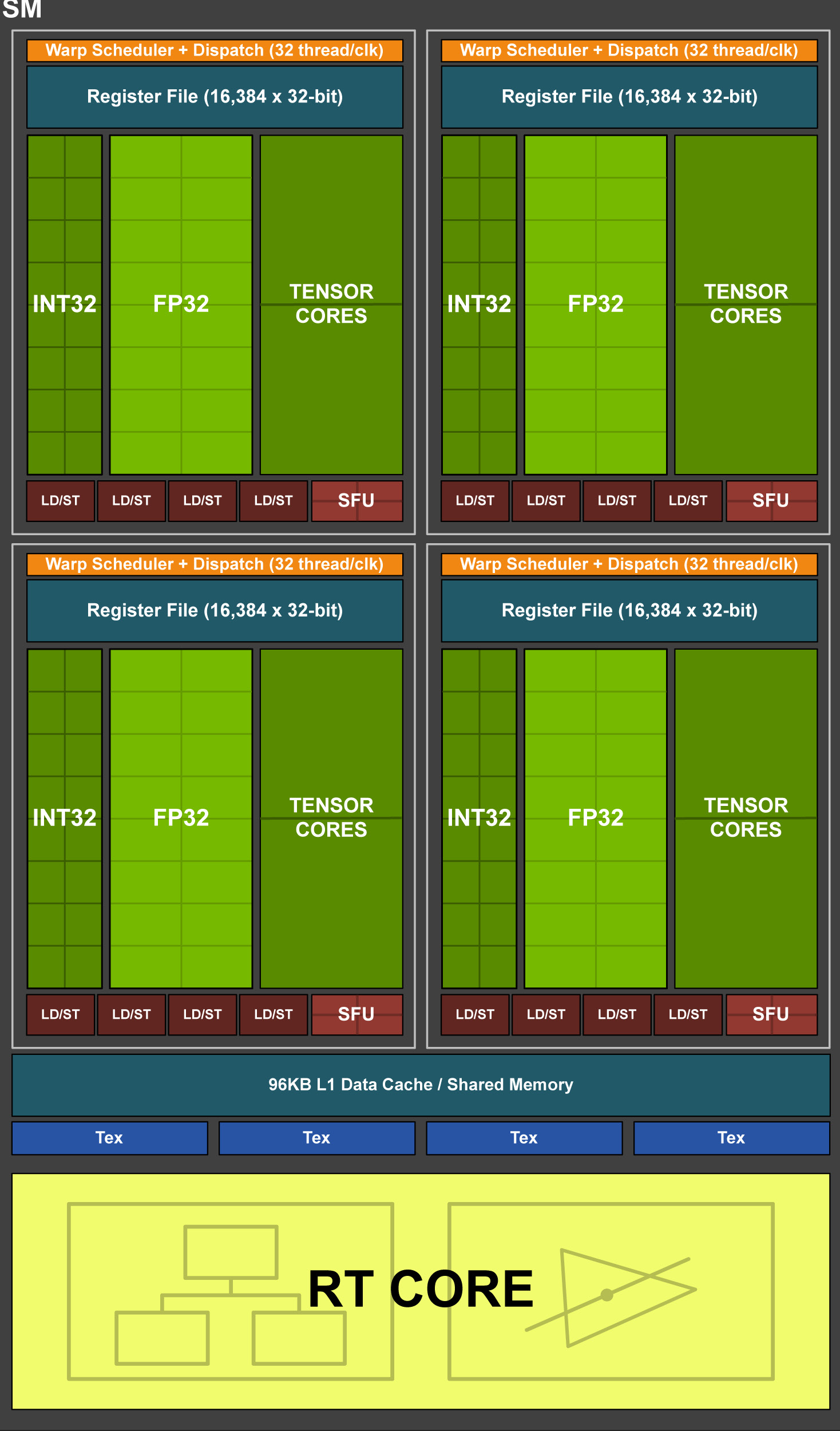
УПИіSMАќКЌЃК
64 CUDAКЫ
8 TensorКЫ
256 KBМФДцЦїЮФМў
TU102 GPUаОЦЌЪЕЮяЭМЃК

3.3 GPUМмЙЙЕФЙВад
знЙлЩЯвЛНкЕФЫљгаGPUМмЙЙЃЌПЩвдЗЂЯжЫќУЧЫфШЛгаЫљВювьЃЌЕЋДцдкзХКмЖрЯрЭЌЕФИХФюКЭВПМўЃК
GPC
TPC
Thread
SMЁЂSMXЁЂSMM
Warp
SP
Core
ALU
FPU
SFU
ROP
Load/Store Unit
L1 Cache
L2 Cache
Memory
Register File
вдЩЯИїИіВПМўЕФгУЭОНЋдкЯТвЛеТЯъЯИВћЪіЁЃ
GPUЮЊЪВУДЛсгаетУДЖрВуМЖЧвгаетУДЖрРзЭЌЕФВПМўЃПД№АИЪЧGPUЕФШЮЮёЪЧЬьШЛВЂааЕФЃЌЯжДњGPUЕФМмЙЙНдЪЧвдИпЖШВЂааФмСІЖјЩшМЦЕФЁЃ
ЫФЁЂGPUдЫааЛњжЦ
4.1 GPUфжШОзмРР
гЩЩЯвЛеТПЩЕУжЊЃЌЯжДњGPUгазХЯрЫЦЕФНсЙЙЃЌгаКмЖрЯрЭЌЕФВПМўЃЌдкдЫааЛњжЦЩЯЃЌвВгаКмЖрЙВЭЌЕуЁЃЯТУцЪЧFermiМмЙЙЕФдЫааЛњжЦзмРРЭМЃК

ДгFermiПЊЪМNVIDIAЪЙгУРрЫЦЕФдРэМмЙЙЃЌЪЙгУвЛИіGiga Thread EngineРДЙмРэЫљгае§дкНјааЕФЙЄзїЃЌGPUБЛЛЎЗжГЩЖрИіGPCs(Graphics
Processing Cluster)ЃЌУПИіGPCгЕгаЖрИіSMЃЈSMXЁЂSMMЃЉКЭвЛИіЙтеЄЛЏв§Чц(Raster
Engine)ЃЌЫќУЧЦфжагаКмЖрЕФСЌНгЃЌзюЯджјЕФЪЧCrossbarЃЌЫќПЩвдСЌНгGPCsКЭЦфЫќЙІФмадФЃПщЃЈР§ШчROPЛђЦфЫћзгЯЕЭГЃЉЁЃ
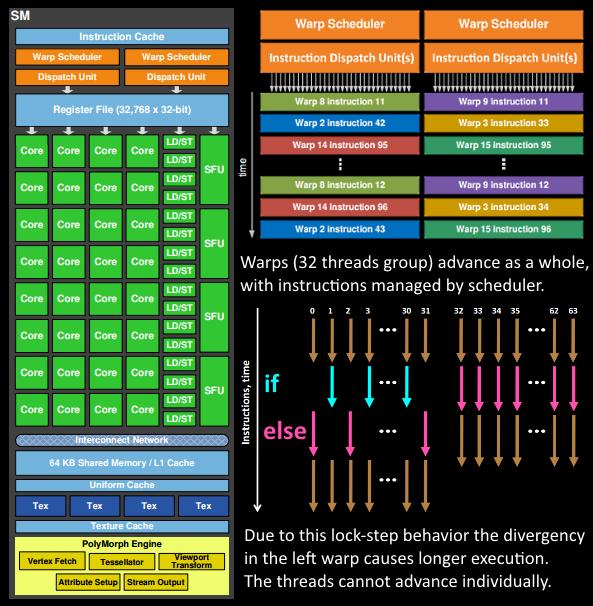
ГЬађдББраДЕФshaderЪЧдкSMЩЯЭъГЩЕФЁЃУПИіSMАќКЌаэЖрЮЊЯпГЬжДааЪ§бЇдЫЫуЕФCoreЃЈКЫаФЃЉЁЃР§ШчЃЌвЛИіЯпГЬПЩвдЪЧЖЅЕуЛђЯёЫизХЩЋЦїЕїгУЁЃетаЉCoreКЭЦфЫќЕЅдЊгЩWarp
SchedulerЧ§ЖЏЃЌWarp SchedulerЙмРэвЛзщ32ИіЯпГЬзїЮЊWarpЃЈЯпГЬЪјЃЉВЂНЋвЊжДааЕФжИСювЦНЛИјDispatch
UnitsЁЃ
GPUжаЪЕМЪгаЖрЩйетаЉЕЅдЊЃЈУПИіGPCгаЖрЩйИіSMЃЌЖрЩйИіGPC ......ЃЉШЁОігкаОЦЌХфжУБОЩэЁЃР§ШчЃЌGM204га4ИіGPCЃЌУПИіGPCга4ИіSMЃЌЕЋTegra
X1га1ИіGPCКЭ2ИіSMЃЌЫќУЧОљВЩгУMaxwellЩшМЦЁЃSMЩшМЦБОЩэЃЈФкКЫЪ§СПЃЌжИСюЕЅЮЛЃЌЕїЖШГЬађ......ЃЉвВЫцзХЪБМфЕФЭЦвЦЖјЗЂЩњБфЛЏЃЌВЂАяжњЪЙаОЦЌБфЕУШчДЫИпаЇЃЌПЩвдДгИпЖЫЬЈЪНЛњРЉеЙЕНБЪМЧБОЕчФдвЦЖЏЁЃ
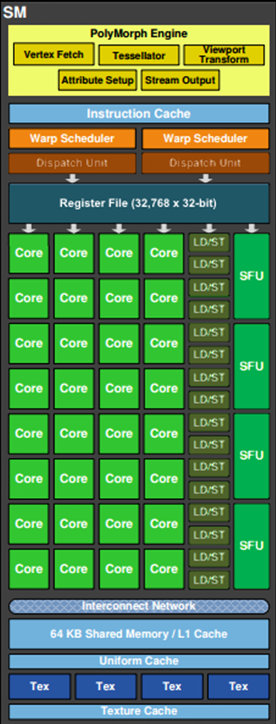
ШчЩЯЭМЃЌЖдгкФГаЉGPUЃЈШчFermiВПЗжаЭКХЃЉЕФЕЅИіSMЃЌАќКЌЃК
32ИідЫЫуКЫаФ ЃЈCoreЃЌвВНаСїДІРэЦїStream ProcessorЃЉ
16ИіLD/STЃЈload/storeЃЉФЃПщРДМгдиКЭДцДЂЪ§Он
4ИіSFUЃЈSpecial function unitsЃЉжДааЬиЪтЪ§бЇдЫЫуЃЈsinЁЂcosЁЂlogЕШЃЉ
128KBМФДцЦїЃЈRegister FileЃЉ
64KB L1ЛКДц
ШЋОжФкДцЛКДцЃЈUniform CacheЃЉ
ЮЦРэЖСШЁЕЅдЊ
ЮЦРэЛКДцЃЈTexture CacheЃЉ
PolyMorph EngineЃКЖрБпаЮв§ЧцИКд№ЪєадзАХфЃЈattribute SetupЃЉЁЂЖЅЕуРШЁ(VertexFetch)ЁЂЧњУцЯИЗжЁЂеЄИёЛЏЃЈетИіФЃПщПЩвдРэНтзЈУХДІРэЖЅЕуЯрЙиЕФЖЋЮїЃЉЁЃ
2ИіWarp SchedulersЃКетИіФЃПщИКд№warpЕїЖШЃЌвЛИіwarpгЩ32ИіЯпГЬзщГЩЃЌwarpЕїЖШЦїЕФжИСюЭЈЙ§Dispatch
UnitsЫЭЕНCoreжДааЁЃ
жИСюЛКДцЃЈInstruction CacheЃЉ
ФкВПСДНгЭјТчЃЈInterconnect NetworkЃЉ
4.2 GPUТпМЙмЯп
СЫНтЩЯвЛНкЕФВПМўКЭИХФюжЎКѓЃЌПЩвдЩюШыВћЪіGPUЕФфжШОЙ§ГЬКЭВНжшЁЃЯТУцНЋвдFermiМвзхЕФSMЮЊР§ЃЌНјааТпМЙмЯпЕФЯъЯИЫЕУїЁЃ
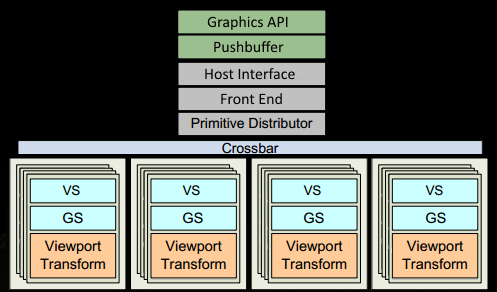
1ЁЂГЬађЭЈЙ§ЭМаЮAPI(DXЁЂGLЁЂWEBGL)ЗЂГіdrawcallжИСюЃЌжИСюЛсБЛЭЦЫЭЕНЧ§ЖЏГЬађЃЌЧ§ЖЏЛсМьВщжИСюЕФКЯЗЈадЃЌШЛКѓЛсАбжИСюЗХЕНGPUПЩвдЖСШЁЕФPushbufferжаЁЃ
2ЁЂОЙ§вЛЖЮЪБМфЛђепЯдЪНЕїгУflushжИСюКѓЃЌЧ§ЖЏГЬађАбPushbufferЕФФкШнЗЂЫЭИјGPUЃЌGPUЭЈЙ§жїЛњНгПкЃЈHost
InterfaceЃЉНгЪметаЉУќСюЃЌВЂЭЈЙ§ЧАЖЫЃЈFront EndЃЉДІРэетаЉУќСюЁЃ
3ЁЂдкЭМдЊЗжХфЦї(Primitive Distributor)жаПЊЪМЙЄзїЗжХфЃЌДІРэindexbufferжаЕФЖЅЕуВњЩњШ§НЧаЮЗжГЩХњДЮ(batches)ЃЌШЛКѓЗЂЫЭИјЖрИіPGCsЁЃетвЛВНЕФРэНтОЭЪЧЬсНЛЩЯРДnИіШ§НЧаЮЃЌЗжХфИјетМИИіPGCЭЌЪБДІРэЁЃ
4ЁЂдкGPCжаЃЌУПИіSMжаЕФPoly Morph EngineИКд№ЭЈЙ§Ш§НЧаЮЫїв§(triangle
indices)ШЁГіШ§НЧаЮЕФЪ§Он(vertex data)ЃЌМДЭМжаЕФVertex FetchФЃПщЁЃ
5ЁЂдкЛёШЁЪ§ОнжЎКѓЃЌдкSMжавд32ИіЯпГЬЮЊвЛзщЕФЯпГЬЪј(Warp)РДЕїЖШЃЌРДПЊЪМДІРэЖЅЕуЪ§ОнЁЃWarpЪЧЕфаЭЕФЕЅжИСюЖрЯпГЬЃЈSIMTЃЌSIMDЕЅжИСюЖрЪ§ОнЕФЩ§МЖЃЉЕФЪЕЯжЃЌвВОЭЪЧ32ИіЯпГЬЭЌЪБжДааЕФжИСюЪЧвЛФЃвЛбљЕФЃЌжЛЪЧЯпГЬЪ§ОнВЛвЛбљЃЌетбљЕФКУДІОЭЪЧвЛИіwarpжЛашвЊвЛИіЬзТпМЖджИСюНјааНтТыКЭжДааОЭПЩвдСЫЃЌаОЦЌПЩвдзіЕФИќаЁИќПьЃЌжЎЫљвдПЩвдетУДзіЪЧгЩгкGPUашвЊДІРэЕФШЮЮёЪЧЬьШЛВЂааЕФЁЃ
6ЁЂSMЕФwarpЕїЖШЦїЛсАДееЫГађЗжЗЂжИСюИјећИіwarpЃЌЕЅИіwarpжаЕФЯпГЬЛсЫјВН(lock-step)жДааИїздЕФжИСюЃЌШчЙћЯпГЬХіЕНВЛМЄЛюжДааЕФЧщПівВЛсБЛекбк(be
masked out)ЁЃБЛекбкЕФдвђгаКмЖрЃЌР§ШчЕБЧАЕФжИСюЪЧif(true)ЕФЗжжЇЃЌЕЋЪЧЕБЧАЯпГЬЕФЪ§ОнЕФЬѕМўЪЧfalseЃЌЛђепбЛЗЕФДЮЪ§ВЛвЛбљЃЈБШШчforбЛЗДЮЪ§nВЛЪЧГЃСПЃЌЛђБЛbreakЬсЧАжежЙСЫЕЋЪЧБ№ЕФЛЙдкзпЃЉЃЌвђДЫдкshaderжаЕФЗжжЇЛсЯджјдіМгЪБМфЯћКФЃЌдквЛИіwarpжаЕФЗжжЇГ§ЗЧ32ИіЯпГЬЖМзпЕНifЛђепelseРяУцЃЌЗёдђЯрЕБгкЫљгаЕФЗжжЇЖМзпСЫвЛБщЃЌЯпГЬВЛФмЖРСЂжДаажИСюЖјЪЧвдwarpЮЊЕЅЮЛЃЌЖјетаЉwarpжЎМфВХЪЧЖРСЂЕФЁЃ
7ЁЂwarpжаЕФжИСюПЩвдБЛвЛДЮЭъГЩЃЌвВПЩФмОЙ§ЖрДЮЕїЖШЃЌР§ШчЭЈГЃSMжаЕФLD/ST(МгдиДцШЁ)ЕЅдЊЪ§СПУїЯдЩйгкЛљДЁЪ§бЇВйзїЕЅдЊЁЃ
8ЁЂгЩгкФГаЉжИСюБШЦфЫћжИСюашвЊИќГЄЕФЪБМфВХФмЭъГЩЃЌЬиБ№ЪЧФкДцМгдиЃЌwarpЕїЖШЦїПЩФмЛсМђЕЅЕиЧаЛЛЕНСэвЛИіУЛгаФкДцЕШД§ЕФwarpЃЌетЪЧGPUШчКЮПЫЗўФкДцЖСШЁбгГйЕФЙиМќЃЌжЛЪЧМђЕЅЕиЧаЛЛЛюЖЏЯпГЬзщЁЃЮЊСЫЪЙетжжЧаЛЛЗЧГЃПьЃЌЕїЖШЦїЙмРэЕФЫљгаwarpдкМФДцЦїЮФМўжаЖМгаздМКЕФМФДцЦїЁЃетРяОЭЛсгаИіУЌЖмВњЩњЃЌshaderашвЊдНЖрЕФМФДцЦїЃЌОЭЛсИјwarpСєЯТдНЩйЕФПеМфЃЌОЭЛсВњЩњдНЩйЕФwarpЃЌетЪБКђдкХіЕНФкДцбгГйЕФЪБКђОЭЛсжЛЪЧЕШД§ЃЌЖјУЛгаПЩвддЫааЕФwarpПЩвдЧаЛЛЁЃ
9ЁЂвЛЕЉwarpЭъГЩСЫvertex-shaderЕФЫљгажИСюЃЌдЫЫуНсЙћЛсБЛViewport TransformФЃПщДІРэЃЌШ§НЧаЮЛсБЛВУМєШЛКѓзМБИеЄИёЛЏЃЌGPUЛсЪЙгУL1КЭL2ЛКДцРДНјааvertex-shaderКЭpixel-shaderЕФЪ§ОнЭЈаХЁЃ
10ЁЂНгЯТРДетаЉШ§НЧаЮНЋБЛЗжИюЃЌдйЗжХфИјЖрИіGPCЃЌШ§НЧаЮЕФЗЖЮЇОіЖЈзХЫќНЋБЛЗжХфЕНФФИіЙтеЄв§Чц(raster
engines)ЃЌУПИіraster enginesИВИЧСЫЖрИіЦСФЛЩЯЕФtileЃЌетЕШгкАбШ§НЧаЮЕФфжШОЗжХфЕНЖрИіtileЩЯУцЁЃвВОЭЪЧЯёЫиНзЖЮОЭАбАДШ§НЧаЮЛЎЗжБфГЩСЫАДЯдЪОЕФЯёЫиЛЎЗжСЫЁЃ
11ЁЂSMЩЯЕФAttribute SetupБЃжЄСЫДгvertex-shaderРДЕФЪ§ОнОЙ§ВхжЕКѓЪЧpixel-shadeЪЧПЩЖСЕФЁЃ
12ЁЂGPCЩЯЕФЙтеЄв§Чц(raster engines)дкЫќНгЪеЕНЕФШ§НЧаЮЩЯЙЄзїЃЌРДИКд№етаЉетаЉШ§НЧаЮЕФЯёЫиаХЯЂЕФЩњГЩЃЈЭЌЪБЛсДІРэВУМєClippingЁЂБГУцЬоГ§КЭEarly-ZЬоГ§ЃЉЁЃ
13ЁЂ32ИіЯёЫиЯпГЬНЋБЛЗжГЩвЛзщЃЌЛђепЫЕ8Иі2x2ЕФЯёЫиПщЃЌетЪЧдкЯёЫизХЩЋЦїЩЯУцЕФзюаЁЙЄзїЕЅдЊЃЌдкетИіЯёЫиЯпГЬФкЃЌШчЙћУЛгаБЛШ§НЧаЮИВИЧОЭЛсБЛекбкЃЌSMжаЕФwarpЕїЖШЦїЛсЙмРэЯёЫизХЩЋЦїЕФШЮЮёЁЃ
14ЁЂНгЯТРДЕФНзЖЮОЭКЭvertex-shaderжаЕФТпМВНжшЭъШЋвЛбљЃЌЕЋЪЧБфГЩСЫдкЯёЫизХЩЋЦїЯпГЬжажДааЁЃ
гЩгкВЛКФЗбШЮКЮадФмПЩвдЛёШЁвЛИіЯёЫиФкЕФжЕЃЌЕМжТЫјВНжДааЗЧГЃБуРћЃЌЫљгаЕФЯпГЬПЩвдБЃжЄЫљгаЕФжИСюПЩвддкЭЌвЛЕуЁЃ
15ЁЂзюКѓвЛВНЃЌЯждкЯёЫизХЩЋЦївбОЭъГЩСЫбеЩЋЕФМЦЫуЛЙгаЩюЖШжЕЕФМЦЫуЃЌдкетИіЕуЩЯЃЌЮвУЧБиаыПМТЧШ§НЧаЮЕФдЪМapiЫГађЃЌШЛКѓВХНЋЪ§ОнвЦНЛИјROP(render
output unitЃЌфжШОЪфШыЕЅдЊ)ЃЌвЛИіROPФкВПгаКмЖрROPЕЅдЊЃЌдкROPЕЅдЊжаДІРэЩюЖШВтЪдЃЌКЭframebufferЕФЛьКЯЃЌЩюЖШКЭбеЩЋЕФЩшжУБиаыЪЧдзгВйзїЃЌЗёдђСНИіВЛЭЌЕФШ§НЧаЮдкЭЌвЛИіЯёЫиЕуОЭЛсгаГхЭЛКЭДэЮѓЁЃ
4.3 GPUММЪѕвЊЕу
гЩгкЩЯвЛНкжївЊВћЪіGPUФкВПЕФЙЄзїСїГЬКЭЛњжЦЃЌЮЊСЫМђНрадЃЌЪЁТдСЫКмЖржЊЪЖЕуКЭЙ§ГЬЃЌБОНкНЋЖдЫќУЧзіНјвЛВНВЙГфЫЕУїЁЃ
4.3.1 SIMDКЭSIMT
SIMDЃЈSingle Instruction Multiple DataЃЉЪЧЕЅжИСюЖрЪ§ОнЃЌдкGPUЕФALUЕЅдЊФкЃЌвЛЬѕжИСюПЩвдДІРэЖрЮЌЯђСПЃЈвЛАуЪЧ4DЃЉЕФЪ§ОнЁЃБШШчЃЌгавдЯТshaderжИСюЃК
float4 c = a + b; // a, bЖМЪЧfloat4РраЭ
ЖдгкУЛгаSIMDЕФДІРэЕЅдЊЃЌашвЊ4ЬѕжИСюНЋ4ИіfloatЪ§жЕЯрМгЃЌЛуБрЮБДњТыШчЯТЃК
ADD c.x, a.x, b.x
ADD c.y, a.y, b.y
ADD c.z, a.z, b.z
ADD c.w, a.w, b.w
ЕЋгаСЫSIMDММЪѕЃЌжЛашвЛЬѕжИСюМДПЩДІРэЭъЃК
SIMD_ADD c, a, b
SIMTЃЈSingle Instruction Multiple ThreadsЃЌЕЅжИСюЖрЯпГЬЃЉЪЧSIMDЕФЩ§МЖАцЃЌПЩЖдGPUжаЕЅИіSMжаЕФЖрИіCoreЭЌЪБДІРэЭЌвЛжИСюЃЌВЂЧвУПИіCoreДцШЁЕФЪ§ОнПЩвдЪЧВЛЭЌЕФЁЃ
SIMT_ADD c, a, b
ЩЯЪіжИСюЛсБЛЭЌЪБЫЭШыдкЕЅИіSMжаБЛБрзщЕФЫљгаCoreжаЃЌЭЌЪБжДаадЫЫуЃЌЕЋaЁЂb ЁЂcЕФжЕПЩвдВЛвЛбљЃК
4.3.2 co-issue
co-issueЪЧЮЊСЫНтОіSIMDдЫЫуЕЅдЊЮоЗЈГфЗжРћгУЕФЮЪЬтЁЃР§ШчЯТЭМЃЌгЩгкfloatЪ§СПЕФВЛЭЌЃЌALUРћгУТЪДг100%вРДЮЯТНЕЮЊ75%ЁЂ50%ЁЂ25%ЁЃ
ЮЊСЫНтОізХЩЋЦїдкЕЭЮЌЯђСПЕФРћгУТЪЕЭЕФЮЪЬтЃЌПЩвдЭЈЙ§КЯВЂ1Dгы3DЛђ2Dгы2DЕФжИСюЁЃР§ШчЯТЭМЃЌDP3жИСюгУСЫ3DЪ§ОнЃЌADDжИСюжЛга1DЪ§ОнЃЌco-issueЛсздЖЏНЋЫќУЧКЯВЂЃЌдкЭЌвЛИіALUжЛашвЛИіжИСюжмЦкМДПЩжДааЭъЁЃ
ЕЋЪЧЃЌЖдгкЯђСПдЫЫуЕЅдЊЃЈVector ALUЃЉЃЌШчЙћЦфжавЛИіБфСПМШЪЧВйзїЪ§гжЪЧДцДЂЪ§ЕФЧщПіЃЌЮоЗЈЦєгУco-issueММЪѕЃК
гкЪЧБъСПжИСюзХЩЋЦїЃЈScalar Instruction ShaderЃЉгІдЫЖјЩњЃЌЫќПЩвдгааЇЕизщКЯШЮКЮЯђСПЃЌПЊЦєco-issueММЪѕЃЌГфЗжЗЂЛгSIMDЕФгХЪЦЁЃ
4.3.3 if - elseгяОф
ШчЩЯЭМЃЌSMжага8ИіALUЃЈCoreЃЉЃЌгЩгкSIMDЕФЬиадЃЌУПИіALUЕФЪ§ОнВЛвЛбљЃЌЕМжТif-elseгяОфдкФГаЉALUжажДааЕФЪЧtrueЗжжЇЃЈЛЦЩЋЃЉЃЌгааЉALUжДааЕФЪЧfalseЗжжЇЃЈЛвРЖЩЋЃЉЃЌетбљЕМжТКмЖрALUЕФжДаажмЦкБЛРЫЗбЕєСЫЃЈМДmasked
outЃЉЃЌРГЄСЫећИіжДаажмЦкЁЃзюЛЕЕФЧщПіЃЌЭЌвЛИіSMжажЛга1/8ЃЈ8ЪЧЭЌвЛИіSMЕФЯпГЬЪ§ЃЌВЛЭЌМмЙЙЕФGPUгаЫљВЛЭЌЃЉЕФРћгУТЪЁЃ
ЭЌбљЃЌforбЛЗвВЛсЕМжТРрЫЦЕФЧщаЮЃЌР§ШчвдЯТshaderДњТыЃК
void func(int count, int breakNum)
{
for(int i=0; i<count; ++i)
{
if (i == breakNum)
break;
else
// do something
}
}
гЩгкУПИіALUЕФcountВЛвЛбљЃЌМгЩЯгаbreakЗжжЇЃЌЕМжТзюПьжДааЭъshaderЕФALUПЩФмЪЧзюТ§ЕФNЗжжЎвЛЕФЪБМфЃЌЕЋгЩгкSIMDЕФЬиадЃЌзюПьЕФФЧИіALUвРШЛвЊЕШД§зюТ§ЕФALUжДааЭъБЯЃЌВХФмНгЯТвЛзщжИСюЕФЛюЃЁвВОЭАзАзРЫЗбСЫКмЖрЪБМфжмЦкЁЃ
4.3.4 Early-Z
дчЦкGPUЕФфжШОЙмЯпЕФЩюЖШВтЪдЪЧдкЯёЫизХЩЋЦїжЎКѓВХжДааЃЈЯТЭМЃЉЃЌетбљЛсдьГЩКмЖрБОВЛПЩМћЕФЯёЫижДааСЫКФадФмЕФЯёЫизХЩЋЦїМЦЫуЁЃ
КѓРДЃЌЮЊСЫМѕЩйЯёЫизХЩЋЦїЕФЖюЭтЯћКФЃЌНЋЩюЖШВтЪдЬсжСЯёЫизХЩЋЦїжЎЧАЃЈЯТЭМЃЉЃЌетОЭЪЧEarly-ZММЪѕЕФгЩРДЁЃ
Early-ZММЪѕПЩвдНЋКмЖрЮоаЇЕФЯёЫиЬсЧАЬоГ§ЃЌБмУтЫќУЧНјШыКФЪБбЯжиЕФЯёЫизХЩЋЦїЁЃEarly-ZЬоГ§ЕФзюаЁЕЅЮЛВЛЪЧ1ЯёЫиЃЌЖјЪЧЯёЫиПщЃЈpixel
quadЃЌ2x2ИіЯёЫиЃЌЯъМћ[4.3.6 ](#4.3.6 ЯёЫиПщЃЈpixel quadЃЉ)ЃЉЁЃ
ЕЋЪЧЃЌвдЯТЧщПіЛсЕМжТEarly-ZЪЇаЇЃК
ПЊЦєAlpha TestЃКгЩгкAlpha TestашвЊдкЯёЫизХЩЋЦїКѓУцЕФAlpha TestНзЖЮБШНЯЃЌЫљвдЮоЗЈдкЯёЫизХЩЋЦїжЎЧАОЭОіЖЈИУЯёЫиЪЧЗёБЛЬоГ§ЁЃ
ПЊЦєTex KillЃКМДдкshaderДњТыжагаЯёЫио№ЦњжИСюЃЈDXЕФdiscardЃЌOpenGLЕФclipЃЉЁЃ
ЙиБеЩюЖШВтЪдЁЃEarly-ZЪЧНЈСЂдкЩюЖШВтЪдПДПЊЦєЕФЬѕМўЯТЃЌШчЙћЙиБеСЫЩюЖШВтЪдЃЌвВОЭЮоЗЈЦєгУEarly-ZММЪѕЁЃ
ПЊЦєMulti-SamplingЃКЖрВЩбљЛсгАЯьжмБпЯёЫиЃЌЖјEarly-ZНзЖЮЮоЗЈЕУжЊжмБпЯёЫиЪЧЗёБЛВУМєЃЌЙЪЮоЗЈЬсЧАЬоГ§ЁЃ
вдМАЦфЫќШЮКЮЕМжТашвЊЛьКЯКѓУцбеЩЋЕФВйзїЁЃ
ДЫЭтЃЌEarly-ZММЪѕЛсЕМжТвЛИіЮЪЬтЃКЩюЖШЪ§ОнГхЭЛЃЈdepth data hazardЃЉЁЃ
Р§згвЊНсКЯЩЯЭМЃЌМйЩшЪ§жЕЩюЖШжЕ5вбООЙ§Early-ZМДНЋаДШыFrame BufferЃЌЖјЩюЖШжЕ10ИеКУДІгкEarly-ZНзЖЮЃЌЖСШЁВЂЖдБШЕБЧАЛКДцЕФЩюЖШжЕ15ЃЌНсЙћОЭЪЧ10ЭЈЙ§СЫEarly-ZВтЪдЃЌЛсИВИЧЕєБШздМКаЁЕФЩюЖШжЕ5ЃЌзюжеframe
bufferЕФЩюЖШжЕЪЧДэЮѓЕФНсЙћЁЃ
БмУтЩюЖШЪ§ОнГхЭЛЕФЗНЗЈжЎвЛЪЧдкаДШыЩюЖШжЕжЎЧАЃЌдйДЮгыframe bufferЕФжЕНјааЖдБШЃК
4.3.5 ЭГвЛзХЩЋЦїМмЙЙЃЈUnified shader ArchitectureЃЉ
дкдчЦкЕФGPUЃЌЖЅЕузХЩЋЦїКЭЯёЫизХЩЋЦїЕФгВМўНсЙЙЪЧЖРСЂЕФЃЌЫќУЧИїгаИїЕФМФДцЦїЁЂдЫЫуЕЅдЊЕШВПМўЁЃетбљКмЖрЪБКђЃЌЛсдьГЩЖЅЕузХЩЋЦїгыЯёЫизХЩЋЦїжЎМфШЮЮёЕФВЛЦНКтЁЃЖдгкЖЅЕуЪ§СПЖрЕФШЮЮёЃЌЯёЫизХЩЋЦїПеЯазДЬЌЖрЃЛЖдгкЯёЫиЖрЕФШЮЮёЃЌЖЅЕузХЩЋЦїЕФПеЯазДЬЌЖрЃЈЯТЭМЃЉЁЃ
гкЪЧЃЌЮЊСЫНтОіVSКЭPSжЎМфЕФВЛЦНКтЃЌв§ШыСЫЭГвЛзХЩЋЦїМмЙЙЃЈUnified shader ArchitectureЃЉЁЃгУСЫДЫМмЙЙЕФGPUЃЌVSКЭPSгУЕФЖМЪЧЯрЭЌЕФCoreЁЃвВОЭЪЧЃЌЭЌвЛИіCoreМШПЩвдЪЧVSгжПЩвдЪЧPSЁЃ
етбљОЭНтОіСЫВЛЭЌРраЭзХЩЋЦїжЎМфЕФВЛЦНКтЮЪЬтЃЌЛЙПЩвдМѕЩйGPUЕФгВМўЕЅдЊЃЌбЙЫѕЮяРэГпДчКЭКФЕчСПЁЃДЫЭтЃЌVSЁЂPSПЩЛЙПЩвдКЭЦфЫќзХЩЋЦїЃЈМИКЮЁЂЧњУцЁЂМЦЫуЃЉЭГвЛЮЊвЛЬхЁЃ
4.3.6 ЯёЫиПщЃЈPixel QuadЃЉ
ЩЯвЛНкВНжш13ЬсЕНЃК
32ИіЯёЫиЯпГЬНЋБЛЗжГЩвЛзщЃЌЛђепЫЕ8Иі2x2ЕФЯёЫиПщЃЌетЪЧдкЯёЫизХЩЋЦїЩЯУцЕФзюаЁЙЄзїЕЅдЊЃЌдкетИіЯёЫиЯпГЬФкЃЌШчЙћУЛгаБЛШ§НЧаЮИВИЧОЭЛсБЛекбкЃЌSMжаЕФwarpЕїЖШЦїЛсЙмРэЯёЫизХЩЋЦїЕФШЮЮёЁЃ
вВОЭЪЧЫЕЃЌдкЯёЫизХЩЋЦїжаЃЌЛсНЋЯрСкЕФЫФИіЯёЫизїЮЊВЛПЩЗжИєЕФвЛзщЃЌЫЭШыЭЌвЛИіSMФк4ИіВЛЭЌЕФCoreЁЃ
ЮЊЪВУДЯёЫизХЩЋЦїДІРэЕФзюаЁЕЅдЊЪЧ2x2ЕФЯёЫиПщЃП
БЪепЭЦВтгавдЯТдвђЃК
1ЁЂМђЛЏКЭМгЫйЯёЫиЗжХЩЕФЙЄзїЁЃ
2ЁЂОЋМђSMЕФМмЙЙЃЌМѕЩйгВМўЕЅдЊЪ§СПКЭГпДчЁЃ
3ЁЂНЕЕЭЙІКФЃЌЬсИпаЇФмБШЁЃ
4ЁЂЮоаЇЯёЫиЫфШЛВЛЛсБЛДцДЂНсЙћЃЌЕЋПЩИЈжњгааЇЯёЫиЧѓЕМКЏЪ§ЁЃЯъМћ4.6 РћгУРЉеЙР§жЄЁЃ
етжжЩшМЦЫфШЛгаЦфгХЪЦЃЌЕЋЭЌЪБЃЌвВЛсМЄЛЏЙ§ЛцжЦЃЈOver DrawЃЉЕФЧщПіЃЌЫ№КФЖюЭтЕФадФмЁЃБШШчЯТЭМжаЃЌАзЩЋЕФШ§НЧаЮжЛеМгУСЫ3ИіЯёЫиЃЈТЬЩЋЃЉЃЌАДЮвУЧЦеЭЈЕФЫМЮЌЃЌжЛашвЊ3ИіCoreЛцжЦ3ДЮОЭПЩвдСЫЁЃ
ЕЋЪЧЃЌгЩгкЩЯУцЕФ3ИіЯёЫиЗжБ№еМОнСЫВЛЭЌЕФЯёЫиПщЃЈГШЩЋЗжИєЃЉЃЌЪЕМЪЩЯашвЊеМгУ12ИіCoreЛцжЦ12ДЮЃЈЯТЭМЃЉЁЃ
етОЭЛсЖюЭтЯћКФ300%ЕФгВМўадФмЃЌЕМжТСЫИќМгбЯжиЕФЙ§ЛцжЦЧщПіЁЃ
ИќЖрЯъЧщПЩвдЙлПДащЛУЙйЗНЕФЪгЦЕНЬбЇЃКЪЕЪБфжШОЩюШыЬНОПЁЃ
4.4 GPUзЪдДЛњжЦ
БОНкНЋВћЪіGPUЕФФкДцЗУЮЪЁЂзЪдДЙмРэЕШЛњжЦЁЃ
4.4.1 ФкДцМмЙЙ
ВПЗжМмЙЙЕФGPUгыCPUРрЫЦЃЌвВгаЖрМЖЛКДцНсЙЙЃКМФДцЦїЁЂL1ЛКДцЁЂL2ЛКДцЁЂGPUЯдДцЁЂЯЕЭГЯдДцЁЃ
ЫќУЧЕФДцШЁЫйЖШДгМФДцЦїЕНЯЕЭГФкДцвРДЮБфТ§ЃК

гЩДЫПЩМћЃЌshaderжБНгЗУЮЪМФДцЦїЁЂL1ЁЂL2ЛКДцЛЙЪЧБШНЯПьЕФЃЌЕЋЗУЮЪЮЦРэЁЂГЃСПЛКДцКЭШЋОжФкДцЗЧГЃТ§ЃЌЛсдьГЩКмИпЕФбгГйЁЃ
ЩЯУцЕФЖрМЖЛКДцНсЙЙПЩБЛГЦЮЊЁАCPU-StyleЁБЃЌЛЙДцдкGPU-StyleЕФФкДцМмЙЙЃК
етжжМмЙЙЕФЬиЕуЪЧALUЖрЃЌGPUЩЯЯТЮФЃЈContextЃЉЖрЃЌЭЬЭТСПИпЃЌвРРЕИпДјПэгыЯЕЭГФкДцНЛЛЛЪ§ОнЁЃ
4.4.2 GPU ContextКЭбгГй
гЩгкSIMTММЪѕЕФв§ШыЃЌЕМжТКмЖрЭЌвЛИіSMФкЕФКмЖрCoreВЂВЛЪЧЖРСЂЕФЃЌЕБЫќУЧЕБжагаВПЗжCoreашвЊЗУЮЪЕНЮЦРэЁЂГЃСПЛКДцКЭШЋОжФкДцЪБЃЌОЭЛсЕМжТЗЧГЃДѓЕФПЈЖйЃЈStallЃЉЁЃ
Р§ШчЯТЭМжаЃЌга4зщЩЯЯТЮФЃЈContextЃЉЃЌЫќУЧЙВгУЭЌвЛзщдЫЫуЕЅдЊALUЁЃ
МйЩшЕквЛзщContextашвЊЗУЮЪЛКДцЛђФкДцЃЌЛсЕМжТ2~3ИіжмЦкЕФбгГйЃЌДЫЪБЕїЖШЦїЛсМЄЛюЕкЖўзщContextвдРћгУALUЃК
ЕБЕкЖўзщContextЗУЮЪЛКДцЛђФкДцгжПЈзЁЃЌЛсвРДЮМЄЛюЕкШ§ЁЂЕкЫФзщContextЃЌжБЕНЕквЛзщContextЛжИДдЫааЛђЫљгаЖМБЛМЄЛюЃК
бгГйЕФКѓЙћЪЧУПзщContextЕФзмЬхжДааЪБМфБЛРГЄСЫЃК
ЕЋЪЧЃЌдНЖрContextПЩгУОЭдНПЩвдЬсЩ§дЫЫуЕЅдЊЕФЭЬЭТСПЃЌБШШчЯТЭМЕФ18зщContextЕФМмЙЙПЩвдзюДѓЛЏЕиЬсЩ§ЭЬЭТСПЃК
4.4.3 CPU-GPUвьЙЙЯЕЭГ
ИљОнCPUКЭGPUЪЧЗёЙВЯэФкДцЃЌПЩЗжЮЊСНжжРраЭЕФCPU-GPUМмЙЙЃК
ЩЯЭМзѓЪЧЗжРыЪНМмЙЙЃЌCPUКЭGPUИїздгаЖРСЂЕФЛКДцКЭФкДцЃЌЫќУЧЭЈЙ§PCI-eЕШзмЯпЭЈбЖЁЃетжжНсЙЙЕФШБЕудкгк
PCI-e ЯрЖдгкСНепОпгаЕЭДјПэКЭИпбгГйЃЌЪ§ОнЕФДЋЪфГЩСЫЦфжаЕФадФмЦПОБЁЃФПЧАЪЙгУЗЧГЃЙуЗКЃЌШчPCЁЂжЧФмЪжЛњЕШЁЃ
ЩЯЭМгвЪЧёюКЯЪНМмЙЙЃЌCPU КЭ GPU ЙВЯэФкДцКЭЛКДцЁЃAMD ЕФ APU ВЩгУЕФОЭЪЧетжжНсЙЙЃЌФПЧАжївЊЪЙгУдкгЮЯЗжїЛњжаЃЌШч
PS4ЁЃ
дкДцДЂЙмРэЗНУцЃЌЗжРыЪННсЙЙжа CPU КЭ GPU ИїздгЕгаЖРСЂЕФФкДцЃЌСНепЙВЯэвЛЬзащФтЕижЗПеМфЃЌБивЊЪБЛсНјааФкДцПНБДЁЃЖдгкёюКЯЪННсЙЙЃЌGPU
УЛгаЖРСЂЕФФкДцЃЌгы GPU ЙВЯэЯЕЭГФкДцЃЌгЩ MMU НјааДцДЂЙмРэЁЃ
4.4.4 GPUзЪдДЙмРэФЃаЭ
ЯТЭМЪЧЗжРыЪНМмЙЙЕФзЪдДЙмРэФЃаЭЃК
MMIOЃЈMemory Mapped IOЃЉ
CPUгыGPUЕФНЛСїОЭЪЧЭЈЙ§MMIOНјааЕФЁЃCPU ЭЈЙ§ MMIO ЗУЮЪ GPU ЕФМФДцЦїзДЬЌЁЃ
DMAДЋЪфДѓСПЕФЪ§ОнОЭЪЧЭЈЙ§MMIOНјааУќСюПижЦЕФЁЃ
I/OЖЫПкПЩгУгкМфНгЗУЮЪMMIOЧјгђЃЌЯёNouveauЕШПЊдДШэМўДгРДВЛЗУЮЪЫќЁЃ
GPU Context
GPU ContextДњБэСЫGPUМЦЫуЕФзДЬЌЁЃ
дкGPUжагЕгаздМКЕФащФтЕижЗЁЃ
GPU жаПЩвдВЂДцЖрИіЛюдОЬЌЯТЕФContextЁЃ
GPU Channel
ШЮКЮУќСюЖМЪЧгЩCPUЗЂГіЁЃ
УќСюСїЃЈcommand streamЃЉБЛЬсНЛЕНгВМўЕЅдЊЃЌвВОЭЪЧGPU ChannelЁЃ
УПИіGPU ChannelЙиСЊвЛИіcontextЃЌЖјвЛИіGPU ContextПЩвдгаЖрИіGPU channelЁЃ
УПИіGPU Context АќКЌЯрЙиchannelЕФ GPU Channel Descriptors
ЃЌ УПИі Descriptor ЖМЪЧ GPU ФкДцжаЕФвЛИіЖдЯѓЁЃ
УПИі GPU Channel Descriptor ДцДЂСЫ Channel ЕФЩшжУЃЌЦфжаОЭАќРЈ Page
Table ЁЃ
УПИі GPU Channel дкGPUФкДцжаЗжХфСЫЮЈвЛЕФУќСюЛКДцЃЌетЭЈЙ§MMIOЖдCPUПЩМћЁЃ
GPU Context Switching КЭУќСюжДааЖМдкGPUгВМўФкВПЕїЖШЁЃ
GPU Page Table
GPU ContextдкащФтЛљЕиПеМфгЩPage TableИєРыЦфЫќЕФContext ЁЃ
GPU Page TableИєРыCPU Page TableЃЌЮЛгкGPUФкДцжаЁЃ
GPU Page TableЕФЮяРэЕижЗЮЛгк GPU Channel DescriptorжаЁЃ
GPU Page TableВЛНіНіНЋ GPUащФтЕижЗзЊЛЛГЩGPUФкДцЕФЮяРэЕижЗЃЌвВПЩвдзЊЛЛГЩCPUЕФЮяРэЕижЗЁЃвђДЫЃЌGPU
Page TableПЩвдНЋGPUащФтЕижЗКЭCPUФкДцЕижЗЭГвЛЕНGPUЭГвЛащФтЕижЗПеМфРДЁЃ
PCI-e BAR
GPU ЩшБИЭЈЙ§PCI-eзмЯпНгШыЕНжїЛњЩЯЁЃ Base Address Registers(BARs)
ЪЧ MMIOЕФДАПкЃЌдкGPUЦєЖЏЪБКђХфжУЁЃ
GPUЕФПижЦМФДцЦїКЭФкДцЖМгГЩфЕНСЫBARsжаЁЃ
GPUЩшБИФкДцЭЈЙ§гГЩфЕФMMIOДАПкШЅХфжУGPUКЭЗУЮЪGPUФкДцЁЃ
PFIFO Engine
PFIFOЪЧGPUУќСюЬсНЛЭЈЙ§ЕФвЛИіЬиЪтЕФВПМўЁЃ
PFIFOЮЌЛЄСЫвЛаЉЖРСЂУќСюЖгСаЃЌвВОЭЪЧChannelЁЃ
ДЫУќСюЖгСаЪЧRing BufferЃЌгаPUTКЭGETЕФжИеыЁЃ
ЫљгаЗУЮЪChannelПижЦЧјгђЕФжДаажИСюЖМБЛPFIFO РЙНиЯТРДЁЃ
GPUЧ§ЖЏЪЙгУChannel DescriptorРДДцДЂЯрЙиЕФChannelЩшЖЈЁЃ
PFIFOНЋЖСШЁЕФУќСюзЊНЛИјPGRAPH EngineЁЃ
BO
Buffer Object (BO)ЃЌФкДцЕФвЛПщ(Block)ЃЌФмЙЛгУгкДцДЂЮЦРэЃЈTextureЃЉЁЂфжШОФПБъЃЈRender
TargetЃЉЁЂзХЩЋДњТыЃЈshader codeЃЉЕШЕШЁЃ
NouveauКЭGdevОГЃЪЙгУBOЁЃ
NouveauЪЧвЛИіздгЩМАПЊЗХдДДњТыЯдПЈЧ§ЖЏГЬађЃЌЪЧЮЊNVidiaЕФЯдПЈЫљБраДЁЃ
GdevЪЧвЛЬзЗсИЛЕФПЊдДШэМўЃЌгУгкNVIDIAЕФGPGPUММЪѕЃЌАќРЈЩшБИЧ§ЖЏГЬађЁЃ
ИќЖрЯъЯИПЩвддФЖСТлЮФЃКData Transfer Matters for GPU ComputingЁЃ
4.4.5 CPU-GPUЪ§ОнСї
ЯТЭМЪЧЗжРыЪНМмЙЙЕФCPU-GPUЕФЪ§ОнСїГЬЭМЃК
1ЁЂНЋжїДцЕФДІРэЪ§ОнИДжЦЕНЯдДцжаЁЃ
2ЁЂCPUжИСюЧ§ЖЏGPUЁЃ
3ЁЂGPUжаЕФУПИідЫЫуЕЅдЊВЂааДІРэЁЃДЫВНЛсДгЯдДцДцШЁЪ§ОнЁЃ
4ЁЂGPUНЋЯдДцНсЙћДЋЛижїДцЁЃ
4.4.6 ЯдЯёЛњжЦ
ЫЎЦНКЭДЙжБЭЌВНаХКХ
дкдчЦкЕФCRTЯдЪОЦїЃЌЕчзгЧЙДгЩЯЕНЯТж№ааЩЈУшЃЌЩЈУшЭъГЩКѓЯдЪОЦїОЭГЪЯжвЛжЁЛУцЁЃШЛКѓЕчзгЧЙЛиЕНГѕЪМЮЛжУНјааЯТвЛДЮЩЈУшЁЃЮЊСЫЭЌВНЯдЪОЦїЕФЯдЪОЙ§ГЬКЭЯЕЭГЕФЪгЦЕПижЦЦїЃЌЯдЪОЦїЛсгУгВМўЪБжгВњЩњвЛЯЕСаЕФЖЈЪБаХКХЁЃ
ЕБЕчзгЧЙЛЛааНјааЩЈУшЪБЃЌЯдЪОЦїЛсЗЂГівЛИіЫЎЦНЭЌВНаХКХЃЈhorizonal synchronizationЃЉЃЌМђГЦ
HSync
ЕБвЛжЁЛУцЛцжЦЭъГЩКѓЃЌЕчзгЧЙЛиИДЕНдЮЛЃЌзМБИЛЯТвЛжЁЧАЃЌЯдЪОЦїЛсЗЂГівЛИіДЙжБЭЌВНаХКХЃЈvertical
synchronizationЃЉЃЌМђГЦ VSyncЁЃ
ЯдЪОЦїЭЈГЃвдЙЬЖЈЦЕТЪНјааЫЂаТЃЌетИіЫЂаТТЪОЭЪЧ VSync аХКХВњЩњЕФЦЕТЪЁЃЫфШЛЯждкЕФЯдЪОЦїЛљБОЖМЪЧвКОЇЯдЪОЦССЫЃЌЕЋЦфдРэЛљБОвЛжТЁЃ
CPUНЋМЦЫуКУЯдЪОФкШнЬсНЛжС GPUЃЌGPU фжШОЭъГЩКѓНЋфжШОНсЙћДцШыжЁЛКГхЧјЃЌЪгЦЕПижЦЦїЛсАДее
VSync аХКХж№жЁЖСШЁжЁЛКГхЧјЕФЪ§ОнЃЌОЙ§Ъ§ОнзЊЛЛКѓзюжегЩЯдЪОЦїНјааЯдЪОЁЃ
ЫЋЛКГх
дкЕЅЛКГхЯТЃЌжЁЛКГхЧјЕФЖСШЁКЭЫЂаТЖМЖМЛсгаБШНЯДѓЕФаЇТЪЮЪЬтЃЌОГЃЛсГіЯжЯрЛЅЕШД§ЕФЧщПіЃЌЕМжТжЁТЪЯТНЕЁЃ
ЮЊСЫНтОіаЇТЪЮЪЬтЃЌGPU ЭЈГЃЛсв§ШыСНИіЛКГхЧјЃЌМД ЫЋЛКГхЛњжЦЁЃдкетжжЧщПіЯТЃЌGPU ЛсдЄЯШфжШОвЛжЁЗХШывЛИіЛКГхЧјжаЃЌгУгкЪгЦЕПижЦЦїЕФЖСШЁЁЃЕБЯТвЛжЁфжШОЭъБЯКѓЃЌGPU
ЛсжБНгАбЪгЦЕПижЦЦїЕФжИеыжИЯђЕкЖўИіЛКГхЦїЁЃ
ДЙжБЭЌВН
ЫЋЛКГхЫфШЛФмНтОіаЇТЪЮЪЬтЃЌЕЋЛсв§ШывЛИіаТЕФЮЪЬтЁЃЕБЪгЦЕПижЦЦїЛЙЮДЖСШЁЭъГЩЪБЃЌМДЦСФЛФкШнИеЯдЪОвЛАыЪБЃЌGPU
НЋаТЕФвЛжЁФкШнЬсНЛЕНжЁЛКГхЧјВЂАбСНИіЛКГхЧјНјааНЛЛЛКѓЃЌЪгЦЕПижЦЦїОЭЛсАбаТЕФвЛжЁЪ§ОнЕФЯТАыЖЮЯдЪОЕНЦСФЛЩЯЃЌдьГЩЛУцЫКСбЯжЯѓЃК
ЮЊСЫНтОіетИіЮЪЬтЃЌGPU ЭЈГЃгавЛИіЛњжЦНазіДЙжБЭЌВНЃЈМђаДвВЪЧV-SyncЃЉЃЌЕБПЊЦєДЙжБЭЌВНКѓЃЌGPU
ЛсЕШД§ЯдЪОЦїЕФ VSync аХКХЗЂГіКѓЃЌВХНјаааТЕФвЛжЁфжШОКЭЛКГхЧјИќаТЁЃетбљФмНтОіЛУцЫКСбЯжЯѓЃЌвВдіМгСЫЛУцСїГЉЖШЃЌЕЋашвЊЯћЗбИќЖрЕФМЦЫузЪдДЃЌвВЛсДјРДВПЗжбгГйЁЃ
4.5 ShaderдЫааЛњжЦ
ShaderДњТывВИњДЋЭГЕФC++ЕШгябдРрЫЦЃЌашвЊНЋУцЯђШЫРрЕФИпМЖгябдЃЈGLSLЁЂHLSLЁЂCGSLЃЉЭЈЙ§БрвыЦїзЊГЩУцЯђЛњЦїЕФЖўНјжЦжИСюЃЌЖўНјжЦжИСюПЩзЊвыГЩЛуБрДњТыЃЌвдБуММЪѕШЫдБВщдФКЭЕїЪдЁЃ
гЩИпМЖгябдБрвыГЩЛуБржИСюЕФЙ§ГЬЭЈГЃЪЧдкРыЯпНзЖЮжДааЃЌвдМѕЧсдЫааЪБЕФЯћКФЁЃ
дкжДааНзЖЮЃЌCPUЖЫНЋshaderЖўНјжЦжИСюОгЩPCI-eЭЦЫЭЕНGPUЖЫЃЌGPUдкжДааДњТыЪБЃЌЛсгУContextНЋжИСюЗжГЩШєИЩChannelЭЦЫЭЕНИїИіCoreЕФДцДЂПеМфЁЃ
ЖдЯжДњGPUЖјбдЃЌПЩБрГЬЕФНзЖЮдНРДдНЖрЃЌАќКЌЕЋВЛЯогкЃКЖЅЕузХЩЋЦїЃЈVertex ShaderЃЉЁЂЧњУцЯИЗжПижЦзХЩЋЦїЃЈTessellation
Control ShaderЃЉЁЂМИКЮзХЩЋЦїЃЈGeometry ShaderЃЉЁЂЯёЫи/ЦЌдЊзХЩЋЦїЃЈFragment
ShaderЃЉЁЂМЦЫузХЩЋЦїЃЈCompute ShaderЃЉЁЂ...
етаЉзХЩЋЦїаЮГЩСїЫЎЯпЪНЕФВЂааЛЏЕФфжШОЙмЯпЁЃЯТУцНЋХфКЯОпЬхЕФР§згЫЕУїЁЃ
ЯТЖЮЪЧМЦЫуТўЗДЩфЕФОЕфДњТыЃК
sampler mySamp;
Texture2D<float3> myTex;
float3 lightDir;
float4 diffuseShader(float3 norm, float2 uv)
{
float3 kd;
kd = myTex.Sample(mySamp, uv);
kd *= clamp( dot(lightDir, norm), 0.0, 1.0);
return float4(kd, 1.0);
}
ОЙ§БрвыКѓГЩЮЊЛуБрДњТыЃК
<diffuseShader>:
sample r0, v4, t0, s0
mul r3, v0, cb0[0]
madd r3, v1, cb0[1], r3
madd r3, v2, cb0[2], r3
clmp r3, r3, l(0.0), l(1.0)
mul o0, r0, r3
mul o1, r1, r3
mul o2, r2, r3
mov o3, l(1.0)
дкжДааНзЖЮЃЌвдЩЯЛуБрДњТыЛсБЛGPUЭЦЫЭЕНжДааЩЯЯТЮФЃЈExecution ContextЃЉЃЌШЛКѓALUЛсж№ЬѕЛёШЁЃЈDetchЃЉЁЂНтТыЃЈDecodeЃЉЛуБржИСюЃЌВЂжДааЫќУЧЁЃ
вдЩЯЪОР§ЭМжЛЪЧЕЅИіALUЕФжДааЧщПіЃЌЪЕМЪЩЯЃЌGPUгаМИЪЎЩѕжСЩЯАйИіжДааЕЅдЊдкЭЌЪБжДааshaderжИСюЃК
ЖдгкSIMTМмЙЙЕФGPUЃЌЛуБржИСюгаЫљВЛЭЌЃЌБфГЩСЫSIMTЬиЖЈжИСюДњТыЃК
<VEC8_diffuseShader>:
VEC8_sample vec_r0, vec_v4, t0, vec_s0
VEC8_mul vec_r3, vec_v0, cb0[0]
VEC8_madd vec_r3, vec_v1, cb0[1], vec_r3
VEC8_madd vec_r3, vec_v2, cb0[2], vec_r3
VEC8_clmp vec_r3, vec_r3, l(0.0), l(1.0)
VEC8_mul vec_o0, vec_r0, vec_r3
VEC8_mul vec_o1, vec_r1, vec_r3
VEC8_mul vec_o2, vec_r2, vec_r3
VEC8_mov o3, l(1.0)
ВЂЧвContextвдCoreЮЊЕЅЮЛзщГЩЙВЯэЕФНсЙЙЃЌЭЌвЛИіCoreЕФЖрИіALUЙВЯэвЛзщContextЃК
ШчЙћгаЖрИіCoreЃЌОЭЛсгаИќЖрЕФALUЭЌЪБВЮгыshaderМЦЫуЃЌУПИіCoreжДааЕФЪ§ОнЪЧВЛвЛбљЕФЃЌПЩФмЪЧЖЅЕуЁЂЭМдЊЁЂЯёЫиЕШШЮКЮЪ§ОнЃК
4.6 РћгУРЉеЙР§жЄ
NV shader thread groupЬсЙЉСЫOpenGLЕФРЉеЙЃЌПЩвдВщбЏGPUЯпГЬЁЂCoreЁЂSMЁЂWarpЕШгВМўЯрЙиЕФЪєадЁЃШчЙћвЊПЊЦєДЮДЫРЉеЙЃЌашвЊТњзувдЯТЬѕМўЃК
OpenGL 4.3+ЃЛ
GLSL 4.3+ЃЛ
жЇГжOpenGL 4.3+ЕФNVЯдПЈЃЛ
ВЂЧвДЫРЉеЙжЛдкNVВПЗж5ДњзХЩЋЦїФкЦ№зїгУЃК
This extension interacts with NV_gpu_program5
This extension interacts with NV_compute_program5
This extension interacts with NV_tessellation_program5
ЯТУцЪЧОпЬхЕФзжЖЮКЭДњБэЕФвтвхЃК
// ПЊЦєРЉеЙ
#extension GL_NV_shader_thread_group : require (or
enable)
WARP_SIZE_NV // ЕЅИіЯпГЬЪјЕФЯпГЬЪ§СП
WARPS_PER_SM_NV // ЕЅИіSMЕФЯпГЬЪјЪ§СП
SM_COUNT_NV // SMЪ§СП
uniform uint gl_WarpSizeNV; // ЕЅИіЯпГЬЪјЕФЯпГЬЪ§СП
uniform uint gl_WarpsPerSMNV; // ЕЅИіSMЕФЯпГЬЪјЪ§СП
uniform uint gl_SMCountNV; // SMЪ§СП
in uint gl_WarpIDNV; // ЕБЧАЯпГЬЪјid
in uint gl_SMIDNV; // ЕБЧАЯпГЬЪјЫљдкЕФSM idЃЌШЁжЕ[0, gl_SMCountNV-1]
in uint gl_ThreadInWarpNV; // ЕБЧАЯпГЬidЃЌШЁжЕ[0, gl_WarpSizeNV-1]
in uint gl_ThreadEqMaskNV; // ЪЧЗёЕШгкЕБЧАЯпГЬidЕФЮЛгђбкТыЁЃ
in uint gl_ThreadGeMaskNV; // ЪЧЗёДѓгкЕШгкЕБЧАЯпГЬidЕФЮЛгђбкТыЁЃ
in uint gl_ThreadGtMaskNV; // ЪЧЗёДѓгкЕБЧАЯпГЬidЕФЮЛгђбкТыЁЃ
in uint gl_ThreadLeMaskNV; // ЪЧЗёаЁгкЕШгкЕБЧАЯпГЬidЕФЮЛгђбкТыЁЃ
in uint gl_ThreadLtMaskNV; // ЪЧЗёаЁгкЕБЧАЯпГЬidЕФЮЛгђбкТыЁЃ
in bool gl_HelperThreadNV; // ЕБЧАЯпГЬЪЧЗёажњаЭЯпГЬЁЃ
ЩЯЪіЫљЫЕЕФажњаЭЯпГЬgl_HelperThreadNVЪЧжИдкДІРэ2x2ЕФЯёЫиПщЪБЃЌФЧаЉЮДБЛЭМдЊИВИЧЕФЯёЫизХЩЋЦїЯпГЬНЋБЛБъМЧЮЊgl_HelperThreadNV
= trueЃЌЫќУЧЕФНсЙћНЋБЛКіТдЃЌвВВЛЛсБЛДцДЂЃЌЕЋПЩИЈжњвЛаЉМЦЫуЃЌШчЕМЪ§dFdxКЭdFdyЁЃЮЊСЫЗРжЙРэНтгаЮѓЃЌЬљГідЮФЃК
The variable gl_HelperThreadNV specifies if the current
thread is a helper thread. In implementations supporting
this extension, fragment shader invocations may be
arranged in SIMD thread groups of 2x2 fragments called
"quad". When a fragment shader instruction
is executed on a quad, it's possible that some fragments
within the quad will execute the instruction even
if they are not covered by the primitive. Those threads
are called helper threads. Their outputs will be discarded
and they will not execute global store functions,
but the intermediate values they compute can still
be used by thread group sharing functions or by fragment
derivative functions like dFdx and dFdy.
РћгУвдЩЯзжЖЮЃЌПЩвдБраДЬиЪтshaderДњТызЊГЩбеЩЋаХЯЂЃЌвдБуПЩЪгЛЏПњЬНGPUЕФЙЄзїЛњжЦКЭСїГЬЁЃ
РћгУNVРЉеЙзжЖЮЃЌПЩЪгЛЏСЫЖЅЕузХЩЋЦїЁЂЯёЫизХЩЋЦїЕФSMЁЂWarp idЃЌЮЊЮвУЧВщЬНGPUЕФЙЄзїЛњжЦКЭСїГЬЬсЙЉСЫЭООЖЁЃ
ЯТУце§ЪННјШыбщжЄНзЖЮЃЌНЋвдGeforce RTX 2060зїЮЊбщжЄЖдЯѓЃЌОпЬхаХЯЂШчЯТЃК
ВйзїЯЕЭГЃК Windows 10 Pro, 64-bit
DirectX АцБОЃК 12.0
GPU ДІРэЦїЃК GeForce RTX 2060
Ч§ЖЏГЬађАцБОЃК 417.71
Driver Type: Standard
Direct3D API АцБОЃК 12
Direct3D ЙІФмМЖБ№ЃК12_1
CUDA КЫаФЃК 1920
КЫаФЪБжгЃК 1710 MHz
ФкДцЪ§ОнЫйТЪЃК 14.00 Gbps
ФкДцНгПкЃК 192-ЮЛ
ФкДцДјПэЃК 336.05 GB/Уы
ШЋВППЩгУЕФЭМаЮФкДцЃК22494MB
зЈгУЪгЦЕФкДцЃК 6144 MB GDDR6
ЯЕЭГЪгЦЕФкДцЃК 0MB
ЙВЯэЯЕЭГФкДцЃК 16350MB
ЪгЦЕ BIOS АцБОЃК 90.06.3F.00.73
IRQЃК Not used
змЯпЃК PCI Express x16 Gen3
ЪзЯШдкгІгУГЬађДДНЈАќКЌСНИіШ§НЧаЮЕФЖЅЕуЪ§ОнЃК

фжШОВЩгУЕФЖЅЕузХЩЋЦїЗЧГЃМђЕЅЃК
#version 430 core
layout (location = 0) in vec3 aPos;
void main()
{
gl_Position = vec4(aPos, 1.0f);
}
ЦЌдЊзХЩЋЦївВЪЧСШСШЪ§ааЃК
#version 430 core
out vec4 FragColor;
void main()
{
FragColor = vec4(1.0f, 0.5f, 0.2f, 1.0f);
}
ЛцжЦГіРДЕФдЪМЛУцШчЯТЃК
НєНгзХЃЌаоИФЦЌдЊзХЩЋЦїЃЌМгШыРЉеЙЫљашЕФДњТыЃЌВЂаоИФбеЩЋМЦЫуЃК
#version 430 core
#extension GL_NV_shader_thread_group : require
uniform uint gl_WarpSizeNV; // ЕЅИіЯпГЬЪјЕФЯпГЬЪ§СП
uniform uint gl_WarpsPerSMNV; // ЕЅИіSMЕФЯпГЬЪјЪ§СП
uniform uint gl_SMCountNV; // SMЪ§СП
in uint gl_WarpIDNV; // ЕБЧАЯпГЬЪјid
in uint gl_SMIDNV; // ЕБЧАЯпГЬЫљдкЕФSM idЃЌШЁжЕ[0, gl_SMCountNV-1]
in uint gl_ThreadInWarpNV; // ЕБЧАЯпГЬidЃЌШЁжЕ[0, gl_WarpSizeNV-1]
out vec4 FragColor;
void main()
{
// SM id
float lightness = gl_SMIDNV / gl_SMCountNV;
FragColor = vec4(lightness);
}
гЩЩЯУцЕФДњТыфжШОЕФЛУцШчЯТЃК
ДгЩЯУцПЩЗжЮіГівЛаЉаХЯЂЃК
ЛУцЙВга32ИіССЖШЩЋНзЃЌвВОЭЪЧGeforce RTX 2060га32ИіSMЁЃ
ЕЅИіSMУПДЮфжШО16x16ЮЊЕЅЮЛЕФЯёЫиПщЃЌвВОЭЪЧУПИіSMга256ИіCoreЁЃ
SMжЎМфВЛЪЧЫГађЗжХфЯёЫиПщЃЌЖјЪЧЮоађЗжХфЁЃ
ВЛЭЌШ§НЧаЮЕФНгЗьДІГіЯжЖЯВуЃЌЫЕУїЭЌвЛИіЯёЫиПщШчЙћЗжЪєВЛЭЌЕФШ§НЧаЮЃЌОЭЛсЗжХфЕНВЛЭЌЕФSMНјааДІРэЁЃгЩДЫЭЦЖЯЃЌЯрЭЌУцЛ§ЕФЧјгђЃЌШчЙћЫљЪєЕФШ§НЧаЮдНЖрЃЌОЭЛсЕМжТЗжХфИјSMЕФДЮЪ§дНЖрЃЌЯћКФЕФфжШОадФмвВдНЖрЁЃ
НгзХаоИФЦЌдЊзХЩЋЦїЕФбеЩЋМЦЫуДњТывдЯдЪОWarp idЃК
// warp id
float lightness = gl_WarpIDNV / gl_WarpsPerSMNV;
FragColor = vec4(lightness);
ЕУЕНШчЯТЛУцЃК
гЩДЫПЩЕУГівЛаЉаХЯЂЛђЭЦТлЃК
ЛУцЙВга32ИіССЖШЩЋНзЃЌвВОЭЪЧУПИіSMга32ИіWarpЃЌУПИіWarpга8ИіCoreЁЃ
УПИіЩЋПщЯёЫиЪЧ4x8ЃЌгЩгкУПИіWarpга8ИіCoreЃЌгЩДЫЭЦЖЯУПИіCoreЕЅДЮвЊДІРэ2x2ЕФзюаЁЕЅдЊЯёЫиПщЁЃ
вВЪЧЮоађЗжХфЯёЫиПщЁЃ
Ш§НЧаЮНгЗьДІГіЯжЖЯВуЃЌЭЌSMЕФЭЦЖЯвЛжТЁЃ
дйаоИФЦЌдЊзХЩЋЦїЕФбеЩЋМЦЫуДњТывдЯдЪОЯпГЬidЃК
// thread id
float lightness = gl_ThreadInWarpNV / gl_WarpSizeNV;
FragColor = vec4(lightness);
ЕУЕНШчЯТЛУцЃК
ЮЊСЫЗНБуЗжЮіЃЌгУPhotoshopЖджаМфОжВПЗХДѓ10БЖЃЌЕУЕНвдЯТЛУцЃК
НсКЯЩЯУцСНЗљЭМЃЌвВПЩвдЕУГівЛаЉНсТлЃК
ЯрНЯSMЁЂЯпГЬЪјЃЌЯпГЬЗжВМЭМБШНЯЙцТЩЁЃЫЕУїЭЌвЛИіWarpЕФЯпГЬЗжВМЪЧЙцТЩЕФЁЃ
Ш§НЧаЮНгЗьДІГіЯжЮЩТвЃЌЫЕУїЪЧВЛЭЌЕФWarpдьГЩСЫВЛЭЌЕФЯпГЬЁЃ
ЛУцга32ИіЩЋНзЃЌЫЕУїЕЅИіWarpга32ИіЯпГЬЁЃ
УПИіЯёЫиЖРеМвЛИіССЖШЩЋНзЃЌгыжмБпЯрСкЯёЫиЖМВЛЭЌЃЌЫЕУїУПИіЯпГЬжЛДІРэвЛИіЯёЫиЁЃ
дйДЮЫЕУїЃЌвдЩЯЛУцКЭНсТлЪЧЛљгкGeforce RTX 2060ЃЌВЛЭЌаЭКХЕФGPUПЩФмЛсВЛвЛбљЃЌЕУЕНЕФНсЙћКЭЭЦТлвВЛсгаЫљВЛЭЌЁЃ
ИќЖрNVРЉеЙПЩВЮМћOpenGLЙйЭјЃКNV extensionsЁЃ
ЮхЁЂзмНс
5.1 CPU vs GPU
CPUКЭGPUЕФВювьПЩвдУшЪідкЯТУцБэИёжаЃК
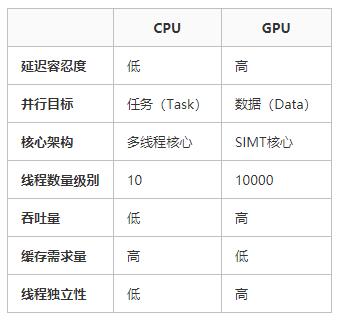
ЫќУЧжЎМфЕФВювьЃЈЛКДцЁЂКЫаФЪ§СПЁЂФкДцЁЂЯпГЬЪ§ЕШЃЉПЩгУЯТЭМеЙЪОГіРДЃК
5.2 фжШОгХЛЏНЈвщ
гЩЩЯеТЕФЗжЮіЃЌПЩвдКмШнвзИјГіфжШОгХЛЏНЈвщЃК
МѕЩйCPUКЭGPUЕФЪ§ОнНЛЛЛЃК
КЯХњЃЈBatchЃЉ
МѕЩйЖЅЕуЪ§ЁЂШ§НЧаЮЪ§
ЪгзЖВУМє
BVH
Portal
BSP
OSP
БмУтУПжЁЬсНЛBufferЪ§Он
CPUАцЕФСЃзгЁЂЖЏЛЛсУПжЁаоИФЁЂЬсНЛЪ§ОнЃЌПЩвЦжСGPUЖЫЁЃ
МѕЩйфжШОзДЬЌЩшжУКЭВщбЏ
Р§ШчЃКglGetUniformLocationЛсДгGPUФкДцВщбЏзДЬЌЃЌКФЗбКмЖрЪБМфжмЦкЁЃ
БмУтУПжЁЩшжУЁЂВщбЏфжШОзДЬЌЃЌПЩдкГѕЪМЛЏЪБЛКДцзДЬЌЁЃ
ЦєгУGPU Instance
ПЊЦєLOD
БмУтДгЯдДцЖСЪ§Он
МѕЩйЙ§ЛцжЦЃК
БмУтTex KillВйзї
БмУтAlpha Test
БмУтAlpha Blend
ПЊЦєЩюЖШВтЪд
Early-Z
ВуДЮZЛКГхЃЈHierarchical Z-BufferingЃЌHZBЃЉ
ПЊЦєВУМєЃК
БГУцВУМє
екЕВВУМє
ЪгПкВУМє
МєЧаОиаЮЃЈscissor rectangleЃЉ
ПижЦЮяЬхЪ§СП
СЃзгЪ§СПЖрЧвУцЛ§аЁЃЌгЩгкЯёЫиПщЛњжЦЃЌЛсМгОчЙ§ЛцжЦЧщПі
жВЮяЁЂЩГЪЏЁЂУЋЗЂЕШвВШчДЫ
ShaderгХЛЏЃК
БмУтifЁЂswitchЗжжЇгяОф
БмУтforбЛЗгяОфЃЌЬиБ№ЪЧбЛЗДЮЪ§ПЩБфЕФ
МѕЩйЮЦРэВЩбљДЮЪ§
НћгУclipЛђdiscardВйзї
МѕЩйИДдгЪ§бЇКЏЪ§ЕїгУ
ИќЖргХЛЏММЧЩПЩдФЖСЃК
вЦЖЏгЮЯЗадФмгХЛЏЭЈгУММЗЈЁЃ
GPU Programming GuideЁЃ
Real-Time Rendering ResourcesЁЃ
5.3 GPUЕФЮДРД
ДгеТНк[2.2 GPUРњЪЗ](#2.2 GPUРњЪЗ)ПЩвдЕУГівЛаЉНсТлЃЌвВПЩвдЭЦВтGPUЗЂеЙЕФЧїЪЦЃК
гВМўЩ§МЖЁЃИќЖрдЫЫуЕЅдЊЃЌИќЖрДцДЂПеМфЃЌИќИпВЂЗЂЃЌИќИпДјПэЃЌИќЕЭбгЪБЁЃЁЃЁЃ
Tile-Based RenderingЕФМЏГЩЁЃЛљгкЭпЦЌЕФфжШОПЩвдвЛЖЈГЬЖШНЕЕЭДјПэКЭЬсЩ§ЙтееМЦЫуаЇТЪЃЌФПЧАВПЗжвЦЖЏЖЫМАзРУцЕФGPUвбОв§ШыетИіММЪѕЃЌЮДРДНЋгаЭћГЩЮЊГЃЬЌЁЃ
3DФкДцММЪѕЁЃФПЧАДѓЖрЪ§ДЋЭГЕФФкДцЪЧ2DЕФЃЌ3DФкДцдђВЛЭЌЃЌдкЮяРэНсЙЙЩЯЪЧ3DЕФЃЌРрЫЦСЂЗНЬхНсЙЙЃЌМЏГЩгкаОЦЌФкЁЃПЩЛёЕУМИБЖЕФЗУЮЪЫйЖШКЭаЇФмБШЁЃ
GPUгњМгПЩБрГЬЛЏЁЃGPUЬьЩњЪЧВЂааЧвЯрЖдЙЬЖЈЕФЃЌЮДРДНЋЛсПЊЗХдНРДдНЖрЕФshaderПЩЙЉБрГЬЃЌЖјCPUИеКУЯрЗДЃЌНЋЭљВЂааЛЏЗЂеЙЁЃвВОЭЪЧЫЕЃЌЮДРДЕФGPUдНРДдНЯёCPUЃЌЖјCPUдНРДдНЯёGPUЁЃФбЕРЫќУЧгІбщСЫЙХгяЃККЯОУБиЗжЃЌЗжОУБиКЯУДЃП
ЪЕЪБЙтеезЗзйЕФЦеМАЁЃЛљгкTuringМмЙЙЕФGPUвбОМгШыДѓСПRT CoreЁЂHVBЁЂAIНЕдыЕШММЪѕЃЌHybrid
Rendering PipelineОЭЪЧДЫМмЙЙЕФЙтЯпзЗзйфжШОЙмЯпЃЌФмЙЛЭЌЪБНсКЯЙтеЄЛЏЦїЁЂRT CoreЁЂCompute
CoreжДааЛьКЯфжШОЃК
Hybrid Rendering PipelineЯрЕБгкЙтЯпзЗзйфжШОЙмЯпКЭЙтеЄЛЏфжШОЙмЯпЕФКЯЬхЃК
Ъ§ОнВЂЗЂЬсЩ§ЁЂЩюЖШЩёОЭјТчЁЂGPUМЦЫуЕЅдЊЕШЦеМАМАЬсЩ§ЁЃ
AIНЕдыКЭAIПЙОтГнЁЃAIНЕдывбОдкВПЗжRTXЯЕСаЕФЙтЯпзЗзйАцБОЕУЕНгІгУЃЌЖјAIПЙОтГнЃЈSuper
ResЃЉПЩгУгкГЌИпЗжБцТЪЕФЪгЦЕЭМЯёПЙОтГнЃК
ЛљгкШЮЮёКЭЭјИёзХЩЋЦїЕФфжШОЙмЯпЁЃЛљгкШЮЮёКЭЭјИёзХЩЋЦїЕФфжШОЙмЯпЃЈGraphics Pipeline
with Task and Mesh ShadersЃЉгыДЋЭГЕФЙтеЄЛЏфжШОЙтЯпгазХКмДѓЕФВювьЃЌЫќвдЯпГЬзщЃЈThread
GroupЃЉЁЂШЮЮёзХЩЋЦїЃЈTask shaderЃЉКЭЭјИёзХЩЋЦїЃЈMesh shaderЃЉЮЊЛљДЁЃЌаЮГЩвЛжжШЋаТЕФфжШОЙмЯпЃК
ЙигкДЫММЪѕЕФИќЖрЯъЧщПЩдФЖСЃКNVIDIA Turing Architecture WhitepaperЁЃ
ПЩБфЫйТЪзХЩЋЃЈVariable Rate ShadingЃЉЁЃПЩБфРћТЪзХЩЋММЪѕПЩХаЖЯЛУцЧјгђЕФживЊадЃЈЛђгЩгІгУГЬађжИЖЈЃЉЃЌШЛКѓИљОнЛУцЧјгђЕФживЊадГЬЖШВЩгУВЛЭЌЕФзХЩЋЗжБцТЪОЋЖШЃЌПЩвдЯджјНЕЕЭЙІКФЃЌЬсИпзХЩЋаЇТЪЁЃ
5.4 Нсгя
БОЮФЯЕЭГЕиНВНтСЫGPUЕФРњЪЗЁЂЗЂеЙЁЂЙЄзїСїГЬЃЌвдМАВПЗжЙ§ГЬЕФЯИЛЏЫЕУїКЭгУЕНЕФИїжжММЪѕЃЌЮвУЧДгжаПЩвдПДЕНGPUМмЙЙЕФЖЏЛњЁЂЛњжЦЁЂЦПОБЃЌвдМАЮДРДЕФЗЂеЙЁЃ
ЯЃЭћПДЭъБОЮФЃЌДѓМвФмКмКУЕиЛиД№ЕМбдЬсГіЕФЮЪЬтЃК1.3 ДјзХЮЪЬтдФЖСЁЃШчЙћВЛФмШЋВПЛиД№ЃЌвВУЛЙиЯЕЃЌЛиЭЗПДЯрЙиеТНкЃЌзмФмевЕНД№АИЁЃ
ШчЙћЯыИќЩюШыЕиСЫНтGPUЕФЩшМЦЯИНкЁЂЪЕЯжЯИНкЃЌПЩдФЖСGPUГЇЩЬЖЈЦкЗЂВМЕФАзЦЄЪщКЭИїДѓИпаЃЁЂЛњЙЙЗЂВМЕФТлЮФЁЃЭЦМівЛИіGPUНтЫЕЪгЦЕЃКA
trip through the Graphics Pipeline 2011: IndexЃЌЫфШЛЪЧЖрФъЧАЕФЪгЦЕЃЌЕЋБШНЯЯЕЭГЁЂШЋУцЕиНВНтСЫGPUЕФЛњжЦКЭММЪѕЁЃ
|






