| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫBitcask ЪЧЪВУД?Bitcask НтОіФФаЉЕФЮЪЬт?Bitcask
МмЙЙЩшМЦМАЯюФПЪЕЯжЁЃ
РДздгк51CTO,гЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
Bitcask ЪЧЪВУД?
Bitcask ЪЧвЛжжКмгаШЄЕФДцДЂФЃаЭЕФЩшМЦЃЌетЪЧвЛжжЕзВуИёЪНЮЊШежОФЃбљЕФ kv ДцДЂЁЃBitcask
Ц№дДгк Riak ЗжВМЪНЪ§ОнПтЃЌBitcask ТлЮФ ЯъЯИНщЩмСЫЫќЕФгЩРДЁЃ
Bitcask НтОіФФаЉЕФЮЪЬт?
МђЕЅЪсРэСЫЯТ Bitcask ТлЮФжаЬсЕНЕФМмЙЙЩшМЦФПБъЃК
ЖСаДЕФЕЭЪБбг;
ИпЭЬЭТЃЌдкЫцЛњаДШыЕФГЁОА;
Ъ§ОнСПМЖвЊБШ RAM Дѓ;
ГжОУЛЏКѓЕФДцДЂЃЌЙЪеЯЛжИДвВвЊЗНБу;
вВвЊЗНБуБИЗнЃЌЗНБуЛжИД;
ЗћКЯетаЉФПБъЕФЛсЪЧФФаЉГЁОАФи?ЯТУцвЛВНВНПДвЛЯТЁЃ
Bitcask МмЙЙЩшМЦ
1 СФСФећЬхЩшМЦ
вЊЕувЛЃКЛљгкЮФМўЯЕЭГЃЌЖјЗЧТуХЬ
етбљЙмРэПеМфОЭЗНБуСЫЃЌЖјЧвПЩвдАбвЛаЉЙІФмНЛИјФкКЫЮФМўЯЕЭГЃЌБШШчЖС cacheЃЌаД buffer ЕШЁЃ
вЊЕуЖўЃКвЛИіДХХЬжЛгавЛИіаДШыЕу
ЛЛОфЛАЫЕжЛгавЛИіПЩаДЕФЮФМўЁЃетИіЮФМўНазі active data fileЃЌЦфЫћЕФЮЊжЛЖСЮФМўЁЃactive
data file аДЕНвЛИідЄЖЈЕФуажЕДѓаЁжЎКѓЃЌОЭПЩвдТжзЊГЩжЛЖСЕФЮФМўЁЃ
БШШчЃЌactive data file аДЕН 10 G ДѓаЁОЭВЛаДСЫЃЌЧаГЩжЛЖСФЃЪНЃЌаТНЈвЛИіЮФМўРДаДЁЃетИіаТЮФМўОЭБфГЩ
active data file ЁЃ
вЊЕуШ§ЃКactive data file жЛга append аДШы
ШежОЮФМўЕФБъХфТяЃЌгРдЖ append ЃЌетбљВХФмБЃжЄзюДѓГЬЖШЕФЫГађ IO ЃЌбЙеЅГіЛњаЕгВХЬЕФЫГађадФмЁЃ
вЊЕуЫФЃКЩОГ§вВЪЧаДШы
етИіЦфЪЕГаНгЩЯУцЕФЁЃвВЪЧШежОРраЭЮФМўВЩгУЕФЪжЖЮЃЌЭтУцПДРДЕФдгаЖдЯѓЕФИќаТЦфЪЕЪЧВйзїШежОЕФМЧТМЃЌетбљВХФмзюДѓЯоЖШЕФБЃГжЫГађ
IO ЁЃ
вЊЕуЮхЃКШежОЪНЮФМўБОжЪЪЧЮоађЮФМўЃЌвРППФкДцЫїв§
дк LSM ЕФМмЙЙжавВЬсЙЉЃЌШежОЮФМўжЛзі append ЃЌДггУЛЇФкШнРДПДЪЧЮоађЕФ(аДШыЪБМфЩЯПДЪЧгаађЕФ)ЃЌЫљвдЮЊСЫНтОіЖСЕФЮЪЬтЃЌБиаывЊППИїжжЫїв§НсЙЙРДНтОіЃЌдк
LSM РяОЭЪЧЭЈЙ§ЙЙНЈФкДцЕФЬјБэРДНтОіЫїв§ЕФЮЪЬтЁЃ
дк Bitcask вВЪЧШчДЫЃЌBitcask дкФкДцжаЙЙНЈЫљга key ЕФ hash БэНтОіетИіЮЪЬтЁЃ
вЊЕуСљЃКПеМфЕФЛиЪеНазі merge ЃЌЦфЪЕОЭЪЧ compact
Bitcask ФкВПЕФЛиЪеСїГЬНазі merge ЃЌЦфЪЕОЭЪЧ compact ЃЌдРэКмМђЕЅЃКБщРњЮФМўЃЌЖСОЩаДаТЃЌгіЕНБъМЧЩОГ§СЫЕФФкШнЖЊЕєМДПЩЁЃ
вЊЕуЦпЃКЮФМў merge жЎКѓЃЌЫГДјЩњГЩвЛЗн ЁАhint fileЁБ
Bitcask ЕФЫїв§ШЋЙЙНЈдкФкДцЃЌЛЛОфЛАЫЕЃЌОЭЪЧдкНјГЬЦєЖЏЕФЪБКђвЊНтЮіЫљгаЕФЕзВуШежОЮФМўЁЃФЧетЪБКђЕзВуЮФМўЕФДѓаЁЁЂФкВПЖдЯѓЪ§СПЕФЖрЩйОЭОіЖЈСЫФуЙЙНЈЕФПьТ§ЃЌBitcask
ЮЊСЫМгЫйЙЙНЈЃЌЫљвдЬсЧААбвЛаЉдЊЪ§ОнаХЯЂЗХЕНЮВЖЫЁЃетбљНјГЬЦєЖЏЕФЪБКђЃЌОЭФмжБНгЖС ЁАhint fileЁБ
РДЛёШЁдЊЪ§ОнСЫЁЃ
2 ПДПДМмЙЙЭМ
Bitcask ЪЧЛљгкЮФМўЯЕЭГЕФЃК

Bitcask жЛгавЛИіПЩаДЕФЮФМўЁЃПЩаДЕФЮФМўНазі active fileЃЌжЛЖСЕФНазіЗЧ activeЃК
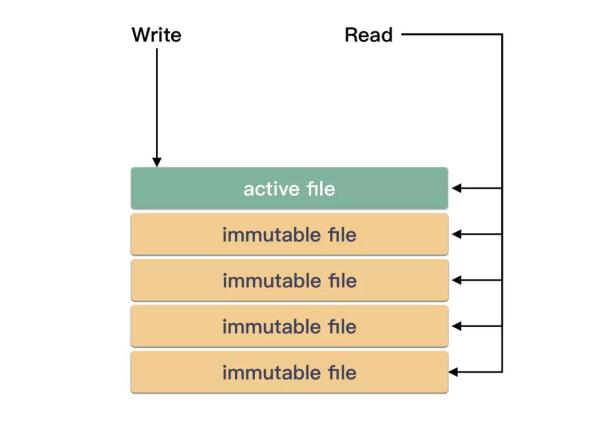
Bitcask ЫќЕФЮФМўЪЧгаИёЪНЕФЃК
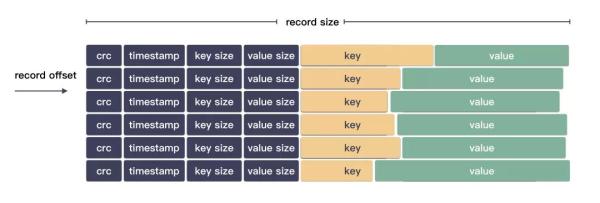
Bitcask ЫќФкДцЕФЫїв§ДѓИХЪЧетбљЕФЃК

3 аДШы
аДШыЕФЙ§ГЬКмМђЕЅЃЌBitcask ЯШаДЮФМўЃЌГжОУЛЏТфХЬжЎКѓИќаТФкДц hash БэЁЃ
змНсЯТаДЕФСїГЬ
аДШежОЮФМўЃЌЗЕЛи file_id, offset, length ЕШЙиМќаХЯЂ;
ИќаТФкДц hash БэФкШнЃЌАбгУЛЇ key КЭЩЯУцЕФЮЛжУаХЯЂЙиСЊЦ№РД;
ЫМПМСНЕуЃК
Дг IO ДЮЪ§РДПДЃЌДХХЬ IO жЛашвЊећЬхТфвЛДЮОЭЙЛСЫЃЌВЛашвЊЕЅЖРаДЫїв§;
Дг IO ФЃаЭРДПДЃЌаДгРдЖЖМЪЧЫГађ IOЃЌЖдЛњаЕХЬРДНВЃЌадФмзюгХ;
4 ЖСШЁ
ЖСШЁЕФЙ§ГЬКмМђЕЅЃЌЯШдкФкДц hash БэжаВщевгУЛЇ key ЃЌДгЖјЛёШЁЕНгУЛЇ value дкШежОЮФМўЕФЮЛжУЁЃ
file_id: БъЪОдкФФИіЮФМўЃЛ
offset: БъЪОдкЮФМўЕФПЊЪМЮЛжУЃЛ
length: БъЪОжЕЕФГЄЖЬЃЈНсЪјЮЛжУЃЉЃЛ
ЭЈЙ§вдЩЯШ§ИіаХЯЂЃЌОЭФмевЕНЖдгІЕФЮФМўШЁЛиЪ§ОнСЫЁЃ
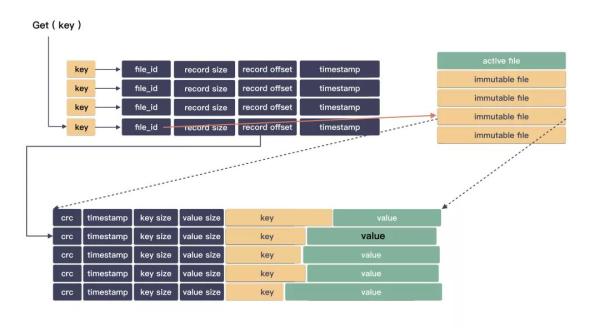
змНсЯТЖСЕФСїГЬЃК
дкФкДц hash БэжаевЕН key ЕФжЕЕФЮФМўЮЛжУ;
ЯТХЬЖСЪ§Он;
ЫМПМСНЕуЃК
Дг IO ДЮЪ§РДПДЃЌетРяадФмгІИУЛЙЪЧВЛДэЕФЃЌвђЮЊжЛгаЖСЪ§ОнЕФЪБКђВХашвЊДХХЬ IO ;
Дг IO ФЃаЭРДПМТЧЃЌЖСЪЧЗЧГЃДѓИХТЪЕМжТЫцЛњ IO ЕФЃЌЕЋетИіПЩвдвРРЕгкЮФМўЯЕЭГЕФЛКДцЃЌЖСЙ§ЕФЪ§ОнНЋПЩвдМгЫйЗУЮЪ;
5 ЛиЪе
Bitcask ЛиЪеЕФСїГЬНазі mergeЃЌЦфЪЕКмМђЕЅЃЌдкШежОЮФМўжаЩОГ§ЕФБъМЧвбОДђЩЯСЫЃЌФкДцРягжгаШЋВПЫїв§ЃЌФЧжЛашвЊАбгааЇЕФЪ§ОнЖСГіРДаДЕНаТЮФМўЃЌШЛКѓАбОЩЮФМўвЛЩОЃЌОЭЭъГЩСЫПеМфЕФЪЭЗХЁЃ
ЕЋМђЕЅЕФЖЋЮїЭљЭљгаФкКЃЌдкЧАУцЮвУЧЬсЕНЃЌгУЛЇЕФаДШыЮЊСЫЫГађЛЏВЩгУСЫШежОЕФИёЪНЃЌЕЋЪЧ merge етИіЪЧКѓЖЫГЬађгаЪБКђЛсКЭЧАЖЮЕФаДШыВЂЗЂжДааЕФЃЌЕЋЕзЯТДХХЬжЛгавЛПщЃЌСНИіЖМЪЧЫГађ
IO ЃЌЕЋВЂЗЂЦ№РДОЭГЩЫцЛњ IO СЫЁЃЫљвдЫќЕФОЋЯИжЎДІОЭдкгк merge ЕФЪБЛњбЁдёКЭЫйТЪЃЌетИівВЪЧЫќЕФКЌН№СПжЎвЛЁЃ
ЧАУцЬсЕНЃЌBitcask ЮЊСЫЫїв§ key/value ЕФЮЛжУЃЌдкФкДцжаЙЙНЈСЫШЋВПЕФЫїв§ЙиЯЕЁЃетИіЙЙНЈдкГѕЪМЛЏЕФЪБКђПЩФмЛсЗЧГЃКФЪБЃЌвђЮЊвЊБщРњШЋВПЕФШежОЮФМўЁЃдѕУДНтОіетИіЮЪЬтФи?
ИЩДржБНгАбетИіЫїв§ЙиЯЕдкКЯЪЪЕФЪБЛњзМБИКУЃЌНјГЬЦєЖЏМгдиЕФЪБКђЃЌжБНгЖСетВПЗжЪ§ОнОЭааСЫЁЃ
зюКЯЪЪЕФЪБЛњВЛОЭЪЧ merge Й§ГЬТяЁЃmerge Й§ГЬЮоТлдѕбљЖМвЊБщРњСЫвЛДЮЮФМўЃЌЩњГЩвЛЗнЫїв§ЙиЯЕЙщЕЕЦ№РДОЭЪЧЫГЪжЕФЪТЧщЁЃетЗнЙщЕЕЕФЫїв§ЙиЯЕдк
Bitcask РяНазі ЁАhint fileЁБ ЁЃ
ЛЎжиЕуЃКФкДцЕФЫїв§ФкШнКЭЮФМўЕФ ЁАhint fileЁБ ЪЧЖдгІЕФЁЃ
ВЛвЛбљЕФЫМПМ
УПвЛжжЩшМЦЖМгаЫќеыЖдЕФГЁОАЃЌЭЈгУЕФЖЋЮїЭљЭљЪЧЦНгЙЕФЁЃBitcask ЫќвВЪЧШчДЫЃЌЫќВЛЪЪгУгкЫљгаГЁОАЃЌФЧЫќЪЪгУФФаЉГЁОАФи?
Bitcask жївЊЪЧГжОУЛЏШежОаЭЮФМўМгЩЯвзЪЇЕФФкДц hash БэзщГЩЁЃ
етРягаКмЖрПЩвдЫМПМЕФЙиМќЕуЃК
ФкДц hash БэЕНЕзгаЖрДѓ?
Bitcask ЫќЪЪКЯДцДЂЖрДѓЕФЪ§Он?
Bitcask ЫќЪЪКЯДцДЂДѓЖдЯѓЛЙЪЧаЁЖдЯѓ?
ЮЊСЫЛиД№ЩЯУцМИИіЮЪЬтЃЌашвЊМйЖЈвЛаЉЪ§ОнНсЙЙЃК
ШежОНсЙЙЃК
|crc|timestamp|key size|value size|key|value|
ЮвУЧМйЩшЧАУцЭЗВПдЊЪ§ОнгУ 4+4+4+4 ИізжНкЁЃ
hash БэЕФНсЙЙЃК
key -> |file_id| record size | record offset |
timestamp |
МйЖЈЪЧ 4+4+4+4 ИізжНк(зЂвтЃЌгЩгкетРягУ offset гУ 4 ИізжНкБэЪОЃЌЫљвдШежОЮФМўбАжЗЗЖЮЇдк
0-4G жЎМф)ЁЃ
НјвЛВНМйЩшгУЛЇ key ЕФЦНОљДѓаЁЮЊ 32 зжНкЁЃ
1 ФкДц hash БэЕНЕзгаЖрДѓ?
вЛИі key/value дкФкДцжазюЩйеМгУ 32+16 зжНкЃЌМйЩш 32 GiB ЕФФкДцЃЌФЧУДПЩвдДцДЂ
32 GiB/ 48 Byte = 715,827,882 ИіЫїв§ЁЃ
7 вкИіНЁжЕЖд?
УВЫЦЛЙЭІЖрЃЌЕЋвВВЛвЛЖЈЁЃКмЖрШЫЖдетИіУЛЪВУДИХФюЃЌЮвУЧдйЭЦНјвЛИіМйЩшЃЌМйЩшгУЛЇ value ЦНОљДѓаЁЪЧ
8 KiBЃЌФЧУДОЭФмЫуЕУЕФзмПеМфЪЧ ( 715,827,882 * 8 * 1024 ) / ( 1024
* 1024 * 1024 * 1024 ) = 5.3 TiB ЁЃ
5.3 TiB ?
ЪЕЛАЪЕЫЕЃЌУВЫЦВЛЬЋДѓЁЃЯждквЛИіЛњаЕХЬ 16 TiB ЕФЖМКмЦеБщСЫЁЃ
ЯждкЗДЙ§РДЭЦЫуЯТЃЌМйЩшЯждкгавЛИі 16 TiB ЕФХЬЃЌгУЛЇ key ЦНОљ 32 зжНкЃЌvalue
ЦНОљ 8 KiBЃЌШчЙћаДТњЕФЛАЃЌашвЊЖрЩйФкДц?
ЫувЛЯТЃЌ( 16 TiB / (16+32+8KiB) ) * 48 Byte = 95 GiB
ЃЌвЛИі 16 TiB ЕФХЬаДТњЕФЛАашвЊ 95 GiB ФкДцРДДцДЂЫќЕФЫїв§ЁЃетЦфЪЕЪЧКмДѓЕФПЊЯњЃЌвђЮЊвЛЬЈЛњЦїПЩФм
64 ПщХЬЁЃЁЃЁЃЁЃ
95 GiB * N ЕФФкДцЯћКФФмПЙЕФзЁТ№?
ВЛвЛЖЈЃЌПДФуЙЋЫОЕФЛњаЭрЖЁЃетЖМЪЧЧЎТяЃЌБЯОЙФкДцЪЧКмЙѓЕФЁЃ
Ыїв§ШЋФкДцЙЙНЈЃЌетИіЙЙНЈЪБМфФуФмНгЪмТ№?
ВЛвЛЖЈЃЌШчЙћЫЕТњдиЕФЪ§ОнЙЙНЈвЊ 1 ИіаЁЪБЃЌФуЛЙЛсНгЪмТ№?ЕБШЛВЛЁЃ
2 Bitcask ЫќЪЪКЯДцДЂЖрДѓЕФЪ§Он?
ФЧЕНЕз Bitcask ЪЪКЯДцДЂЖрЩйЪ§ОнФи?
етИіУЛгаБъзМД№АИЃЌЛЙЪЧвЊПДГЁОАЗжЮіЁЃОЭФУЮвЩЯУцОйЕФР§згРДНВЃЌЖдгк 60 ХЬ( ЕЅХЬ 16 TiB
)ЕФГЁОАРДНВЃЌдЩњЕФBitcask ПЩФмОЭВЛДѓЪЪКЯЁЃ
ЖдгкФГаЉЖЏщќОЭЫЕ Bitcask ЪЪКЯДцДЂКЃСПаЁЖдЯѓЖјВЛМгШЮКЮЧАЬсЕФЫЕЗЈЃЌЦциѓОѕЕУЛЙЪЧВЛЙЛбЯНїЁЃ
дк етЦЊBitcask ТлЮФ[1] жаЦфЪЕгаетУДвЛЖЮЛА
The tests mentioned above used a dataset of more
than 10ЁСRAM on the system in question, and showed
no sign of changed behavior at that point. This is
consistent with our expectations given the design
of Bitcask.
ЫќетРяЕФЛљБОФПБъКУЯёЪЧ 10 БЖЕФ RAM ?
МйЩшФкДц 32 GiBЃЌФЧЛЛЫуЯТОЭЪЧ 320 GiB ЕФДХХЬПеМфЁЃетЃЌЫЦКѕЪЧФкДц+ SSD ХЬИќЪЪКЯ
Bitcask ЕФГЁОАЃЌЖјВЛЪЧеце§ГЌДѓШнСП HDD ДХХЬДцДЂЕФГЁОАЁЃ
3 Bitcask ЫќЪЪКЯДцДЂДѓЖдЯѓЛЙЪЧаЁЖдЯѓ?
етИіОЭКмгавтЫМСЫЃЌBitcask ФмВЛФмДцДЂКЃСПЪ§ОнЯраХЭЈЙ§ЕФМЦЫуЖСепвбОгаЪ§СЫЁЃЕЋЪЧЫќЪЪКЯЕФЪЧДѓЖдЯѓЛЙЪЧаЁЖдЯѓФи?
етИіЦфЪЕЛЙЪЧБШНЯУїЯдЕФЃЌBitcask ЮовЩЪЧЪЪКЯаЁЖдЯѓЕФЁЃРэгЩКмМђЕЅЃЌЫќДгЩшМЦЩЯОЭЙцЖЈСЫжЛгавЛИіаДШыЕу(
active file )ЃЌвВОЭЪЧЫЕгУЛЇЕФаДШыЪЧДЎааЕФЃЌФЧУДШчЙћЫЕгУЛЇЕФ value ЬиБ№ДѓЃЌБШШч
100 MЃЌФЧУДЯЕЭГЭЬЭТЛсЗЧГЃВю(БШШчЫЕЃЌетИіЪБКђРДСЫИі 1K ЕФЖдЯѓЃЌШДжЛФмХХЖг)ЁЃЖјШчЙћЖМЪЧаЉаЁЖдЯѓЃЌФЧУДЭъШЋПЩвдОлКЯКмЖр
key/value ЃЌвЛДЮадТфХЬЁЃетбљМШТњзуСЫЫГађ IO ЃЌгжЬсЙЉСЫКмКУЕФЯЕЭГЕФЭЬЭТФмСІЁЃ
ЫљвдетРяКмживЊЕФвЛЕуЪЧЃКЖдЯѓЕФДѓаЁЁЃМмЙЙЕФЩшМЦЪмДЫгАЯьЦФЩюЁЃ
ХзГівЛИіЫМПМЕФЮЪЬтЃКФуШЯЮЊЪВУДбљЕФВХЪЧаЁЖдЯѓ?
ЦциѓШЯЮЊЃЌДѓаЁВЛЙЛвЛБЪ IO ЕФЖМПЩвдШЯЮЊЪЧаЁЖдЯѓЁЃБШШчЫЕФГЯЕЭГ IO ТфХЬвд 1M ЮЊЕЅЮЛЃЌФЧУД
1M вдФкЕФЖМПЩШЯЮЊЪЧаЁЕФЖдЯѓЃЌетбљОЭПЩвдКмКУЕФзіЕН IO ЕФОлКЯЃЌетвВЪЧ Bitcask ЗЧГЃЪЪКЯЕФГЁОАЁЃетбљОЭФмзіЕНЃКМДЪЙЕзЯТЪЧДЎааЕФаДШывВФмЬсЙЉгУЛЇВЂЗЂЕФадФмЁЃЕБШЛетИіВЂВЛбЯНїЃЌЪЕМЪЧщПівЊОпЬхЗжЮіЁЃ
ЯюФПЪЕЯж
Riak ЪЧвд Erlang БраДЕФвЛИіИпЖШПЩРЉеЙЕФЗжВМЪНЪ§ОнДцДЂЃЌЪЧвЛИіКмГіУћЕФ nosql ЕФЪ§ОнПт
, Bitcask ЕФЕЎЩњКЭЫќЙиЯЕУмЧа ЁЃ
змНс
Bitcask еЙЪОСЫвЛИіМЋИЛЫМПМЕФДцДЂМмЙЙЃЌЫќМђЕЅгааЇЃЌВЂЧвПЩвдгаКмЖрБфаЮ;
Bitcask ВЂВЛЪЧвЛИізюПьЕФДцДЂЯЕЭГЃЌЕЋЪЧЫќадФмзуЙЛЃЌВЂЧвМђЕЅЁЂЮШЖЈ;
ЙРЫуЕФФмСІКмживЊЃЌНсКЯздМКЕФГЁОАЃЌЙРЫуЕФЪ§ОнФмжИЕММмЙЙЩшМЦ;
Bitcask ЮовЩЪЧЪЪКЯаЁЖдЯѓЕФЁЃаЁЖдЯѓЕФЖЈвх?ЦциѓЧГЯдЕФШЯЮЊвЛДЮ IO ФмзАЕФЯТЕФЖМПЩвдШЯЮЊЪЧаЁЖдЯѓ;
Bitcask ЫфШЛжЛгавЛИіПЩаДЮФМўЃЌВЂЧвЪЧ append ДЎаааДЃЌЕЋЭЈЙ§ОлКЯаЁЖдЯѓЁЂХњСПТфХЬЖдЭтПЩвдЬхЯжГіВЛДэЕФВЂЗЂФмСІХЖ;
Bitcask ЪЪКЯаЁЖдЯѓЃЌЕЋЪЧВЛЪЪКЯКЃСПЖдЯѓЁЃжївЊЪЧФкДцЫїв§ЕФЯожЦЁЃЕБШЛвВВЛОјЖдЕФЁЃдЩњТлЮФжЛЪЧЬсЙЉСЫвЛИіЩшМЦЫМТЗЃЌЮвУЧПЩвддкДЫЛљДЁЩЯгаКмЖрБфаЮЩшМЦ;
ВЮПМзЪСЯ
[1]Bitcask ТлЮФ: https://riak.com/assets/bitcask-intro.pdf
КѓМЧ
Bitcask дкЩшМЦЩЯКЭ LSM гавьЧњЭЌЙЄжЎДІЃЌЖМЪЧЭЈЙ§ШежОЕФаЮЪНРДГаНгаДЃЌЬсЙЉзюгХЕФаДЕФадФмЁЃЫфШЛЙІФмВЛШч
LSM ЗсИЛЃЌЕЋЫќМђЕЅЮШЖЈЃЌЗЧГЃжЕЕУбЇЯАЁЃ
|








