| БрМЭЦМі: |
БОЮФМђЕЅНщЩмСЫЩшМЦРрtwitterЯЕЭГЕФЫМТЗВЂдкзюКѓИјГіСЫВЮПМЩшМЦ ЁЃ
РДздгкЮЂаХЙЋжкКХ51CTO ,гЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
TwitterЪЧШЋЧђзюДѓЕФЩчНЛЭјТчжЎвЛЃЌШчЙћШУЮвУЧДг0ПЊЪМЩшМЦtwitterЕФЯЕЭГМмЙЙЃЌИУдѕУДзіФиЃПгаФФаЉЗўЮёЪЧБиаыЕФЃПгаФФаЉЕуашвЊЬсЧАПМТЧЃПетЦЊЮФеТМђЕЅНщЩмСЫЩшМЦРрtwitterЯЕЭГЕФЫМТЗВЂдкзюКѓИјГіСЫВЮПМЩшМЦЁЃ

TwitterЪЧШЋЧђСьЯШЕФдкЯпЩчНЛЭјТчЗўЮёЃЌгУЛЇПЩвддкетРяЗЂВМКЭдФЖСБЛГЦЮЊЁАЭЦЮФЃЈtweetsЃЉЁБЕФЖЬЯћЯЂЁЃдкЯЕЭГМмЙЙЩшМЦУцЪдЙ§ГЬжаЃЌЕББЛЮЪМАШчКЮЩшМЦTwitterЪБЃЌДѓЖрЪ§КђбЁШЫЖМЛсНЋЦфЩшМЦЮЊЕЅЬхЗўЮёЁЃШЛЖјЃЌНЋTwitterетбљЕФДѓаЭЗўЮёЩшМЦЮЊЕЅЬхЃЌБэУїКђбЁШЫШБЗІЩшМЦЗжВМЪНЯЕЭГЕФОбщЁЃДгЮЂЗўЮёЩѕжСlambda(ЛђКЏЪ§)ЕФНЧЖШРДЩшМЦЗжВМЪНЯЕЭГдкНёЬьЪЧКме§ГЃЕФбЁдёЁЃФПЧАЕФЧїЪЦЪЧЃЌУЛгаШЫЛсНЋаТЗўЮёЩшМЦЮЊЕЅЬхЃЌЙЋЫОе§ж№НЅНЋЦфХгДѓЕФЕЅЬхЗўЮёзЊЛЛЮЊвЛзщЮЂЗўЮёЁЃвђДЫЃЌКђбЁШЫгІИУвдЮЂЗўЮёЕФЗНЪНЩшМЦTwitterЁЃ
ЙІФмашЧѓ
гУЛЇПЩвдЗЂВМЛђЗжЯэаТЕФЭЦЮФЃЈtweetЃЉ
УПЬѕЭЦЮФзюЖрВЛГЌЙ§140ИізжЗћ
гУЛЇПЩвдЩОГ§ЭЦЮФЃЌЕЋВЛФмИќаТ/БрМЗЂВМЕФЭЦЮФ(аДВйзї)
ЛЇПЩвдБъМЧЯВЛЖЕФЭЦЮФ(аДВйзї)
гУЛЇПЩвдЙизЂЛђШЁЯћЙизЂСэвЛИігУЛЇ(аДВйзї)ЃЌЙизЂвЛИігУЛЇвтЮЖзХгУЛЇПЩвдПДЕНЦфЫћгУЛЇдкЫћЕФЪБМфЯпЩЯЕФЭЦЮФ
ПЩвдЩњГЩСНжжРраЭЕФЪБМфЯп(ЖСВйзї)ЃЌгУЛЇЪБМфЯпгЩЫћзюКѓNИіЭЦЮФзщГЩЃЌжївГЪБМфЯпгЩЫће§дкЙизЂЕФгУЛЇЕФШШУХЭЦЮФАДееЪБМфНЕађЩњГЩ
гУЛЇПЩвдИљОнЙиМќзжЫбЫїЭЦЮФ(ЖСВйзї)
гУЛЇашвЊгавЛИіеЪЛЇРДЗЂВМЛђЖСШЁЭЦЮФ(днЪБЪЙгУЭтВПЩэЗнЗўЮё)
гУЛЇПЩвдзЂВсКЭЩОГ§еЪЛЇ
TwitterжЇГжАќКЌЮФзжКЭЭМЦЌ/ЪгЦЕЕФЭЦЮФЃЌЕЋдкЮвУЧЕБЧАЕФЩшМЦжаЃЌНЋжЛжЇГжЮФБО
ЗжЮі/МрЪгЗўЮёЃЌвдШЗЖЈЦфИКдиЁЂдЫаазДПіКЭЙІФм
ЗжЮіЛЙПЩЮЊгУЛЇЬсЙЉЙигкЙизЂЫЁЂЭЦЮФЭЈжЊЁЂШШУХЛАЬтЁЂЭЦЫЭЭЈжЊКЭЗжЯэЭЦЮФЕФвтМћЛђНЈвщ

ЗЧЙІФмашЧѓ
ЗўЮёЕФИпПЩгУЪЧзюживЊЕФашЧѓЃЌетвтЮЖзХгУЛЇПЩвддкздМКЕФжївГЪБМфЯпЩЯдФЖСЭЦЮФЃЌЖјИаЪмВЛЕНШЮКЮЭЃЖй
ЩњГЩЪБМфЯпЕФЪБМфзюГЄВЛЕУГЌЙ§АыУы
ВЛашвЊЧПвЛжТадЃЌжЛашвЊзюжевЛжТадЃЌПЩвдЪЙгУЙиМќДЪЪ§ОнПтгУгкЫбЫїЛљгкЙиМќДЪЕФЭЦЮФ
ЫцзХгУЛЇКЭЭЦЮФЕФдіМгЃЌЯЕЭГИКдивВдкдіМгЃЌвђДЫЯЕЭГгІИУОпгаПЩЩьЫѕад
ГжОУЛЏгУЛЇЪ§Он
ЯждкЮвУЧРДзівЛаЉМЦЫуЁЃ
ШеЛюдОгУЛЇЦНОљЧыЧѓ/Ьь = 150M*60/86400 = 100k /Уы
ЗхжЕгУЛЇ = ЦНОљВЂЗЂгУЛЇ* 3 = 300k
Ш§дТФкзюДѓЗхжЕгУЛЇЪ§ = ЗхжЕгУЛЇЪ§*2 = 600k
ЖСQPS = 300k
аДQPS = 5k

twitterЗўЮёЕФИХвЊЩшМЦ
гЩгкЯЕЭГЕФИДдгадЃЌПЩвдНЋЦфЛЎЗжЮЊШєИЩИіЗўЮёЃЌЦфжаАќРЈШєИЩИіЮЂЗўЮёЁЃ
ЭЦЮФЗўЮёЃЈTweet serviceЃЉ
гУЛЇЪБМфЯпЗўЮёЃЈUser timeline serviceЃЉ
ЩШГіЗўЮёЃЈFanout ServiceЃЉ
жївГЪБМфЯпЗўЮёЃЈHome timeline serviceЃЉ
ЩчНЛЭјТчЗўЮёЃЈSocial graph serviceЃЉ
ЫбЫїЗўЮёЃЈSearch serviceЃЉ
ЯТУцЪЧtwitterЗўЮёжаВЛЭЌТпМзщМўЛђЮЂЗўЮёМмЙЙЁЃ

twitterЗўЮёЕФЯъЯИЩшМЦ
ЫљгаЮЂЗўЮёЖМПЩвдБЛГЦЮЊФЃПщЁЃ
1. ЭЦЮФЗўЮёЃЈTweet serviceЃЉ
НгЪегУЛЇЭЦЮФЃЌзЊЗЂгУЛЇЭЦЮФЕНЙизЂепЪБМфЯпКЭЫбЫїЗўЮё
ДцДЂгУЛЇаХЯЂЃЌЭЦЮФаХЯЂЃЌАќРЈгУЛЇЕФЭЦЮФЪ§СПвдМАгУЛЇЯВЛЖЕФзДЬЌ
АќРЈгІгУЗўЮёЦїЁЂЗжВМЪНЕФФкДцЛКДцвдМАКѓЖЫЕФЗжВМЪНЪ§ОнПтЃЌЛђепЪЙгУжБНггЩЪ§ОнПт(Р§ШчRedis)жЇГжЕФФкДцЛКДц

ШЛКѓЮвУЧПДвЛЯТtweetЗўЮёЕФЪ§ОнПтБэНсЙЙЁЃ

гУЛЇЃЈUsersЃЉБэАќКЌгУЛЇЕФЫљгааХЯЂЃЌЭЦЮФЃЈTweetЃЉБэДцДЂЫљгаЭЦЮФЃЌFavorite_tweetБэДцДЂСЫЯВЛЖЕФЭЦЮФМЧТМЃЌвВОЭЪЧЫЕЃЌУПЕБгУЛЇЯВЛЖвЛЬѕЭЦЮФЪБЃЌОЭЛсдкFavorite_tweetБэжаВхШывЛЬѕМЧТМЁЃ
2. ЩњГЩЮЈвЛЕФЭЦЮФId

ЕБгУЛЇЕїгУpostTweet()ЪБЃЌЕїгУЛсЗЂЫЭИјгІгУЗўЮёЦїЁЃгІгУЗўЮёЦїЮЊИУЭЦЮФЩњГЩвЛИіЮЈвЛЕФidЃЌЭЌбљЕФЛњжЦвВПЩвдгУРДЮЊЭЦЮФЩњГЩЖЬURLЁЃСэвЛИіЗНЪНЪЧЛљгкгІгУЗўЮёЦїЕФUUIDЃЈUniversally
unique identifierЃЉЁЃЭЦЮФIDЩњГЩКѓЃЌгІгУЗўЮёЦїНЋИУЭЦЮФВхШыЗжВМЪНЛКДцКЭЪ§ОнПтЕФtweetБэжаЁЃгЩгкашвЊдкжДааЭЦЮФЕФДДНЈ/ИќаТ/ЩОГ§ВйзїЕФЭЌЪБИќаТЛКДцКЭЪ§ОнПтЃЌЫљвдЮвУЧЪЙгУЛКДцЭИаДЛњжЦЁЃ
3. ПЩРЉеЙадЩшМЦ
ЮвУЧПЩвдНЋЗжВМЪНЛКДцКЭЪ§ОнПтЛЎЗжЮЊЖрИіЗжЧјКЭИББОЁЃ
ЛљгкгУЛЇIDЗжЦЌ
ЛљгкЭЦЮФIDЗжЦЌ
ЛљгкгУЛЇIDКЭЭЦЮФIDНјааСНВу/МЖБ№ЗжЦЌ

4. ЩчНЛЭјТчЗўЮёЃЈSocial graph serviceЃЉ
ЪЕЯжFollowing APIЃЌИњзйгУЛЇжЎМфЕФЙизЂЙиЯЕ
АќРЈгІгУЗўЮёЦїЁЂЗжВМЪНЛКДцКЭЪ§ОнПт
гУгкДцДЂгУЛЇЙиЯЕЕФЪ§ОнПтБэНсЙЙ

Following API
НЋБЛЙизЂгУЛЇЕФЪБМфЯпвьВНКЯВЂЕНЙизЂепЕФаХЯЂЪТМўСїжа
ШЁЯћЙизЂвЛИігУЛЇКѓЃЌДгЙизЂепЕФЪТМўСїжавьВНЩОГ§ЫћЕФЭЦЮФ
вьВНЕФДгаХЯЂЪТМўСїжаЬєбЁЭЦЮФ
жЎЫљвдашвЊвьВНВйзїЃЌЪЧвђЮЊетИіЙ§ГЬБШНЯТ§ЃЌЖјгУЛЇдкЙизЂКЭШЁЯћЙизЂЦфЫћгУЛЇЪБЃЌЯЃЭћКмПьЕУЕНЗДРЁ
вьВНЕФШБЕуЪЧгУЛЇдкШЁЯћЙизЂКѓЃЌШчЙћЫЂаТаХЯЂЪТМўСїЃЌЛсЗЂЯжетаЉаХЯЂШдШЛДцдкЃЌЕЋзюжеЫќУЧЛсБЛЩОГ§
5. гУЛЇЪБМфЯпЗўЮёЃЈUser timeline serviceЃЉ
ЗЕЛигУЛЇЕФЪБМфЯпЃЌвдНЕађХХСаЕФЗНЪНАќКЌгУЛЇЫљгаЭЦЮФЁЃДЫЗўЮёПЩгУгкжївГЪБМфЯпЛђЦфЫћгУЛЇЕФЪБМфЯпЁЃ
ИУЗўЮёАќРЈгІгУЗўЮёЦїКЭЗжВМЪНФкДцЛКДцЃЌЕЋУЛгаЩцМАИУЗўЮёЕФЪ§ОнПтЁЃ
гУЛЇЪБМфЯпЪЧЪЙгУАќКЌгУЛЇЭЦЮФСДНгСаБэЕФЪ§ОнНсЙЙЩшМЦЕФ

ЕБгУЛЇЗЂВМвЛЬѕЭЦЮФЪБЃЌtweetЗўЮёЕїгУгУЛЇЪБМфЯпЗўЮёЃЌНЋИУЭЦЮФВхШыЕНгУЛЇЪБМфЯпЕФЭЦЮФСаБэЖЅВПЃЌдЫЫуИДдгЖШЮЊO(1)ЁЃ
ДЫЭтЃЌЗжЮівЧБэАхПЩвдХфжУВЮЪ§KЃЌБэЪОПЩвдБЃСєЕФЭЦЮФИіЪ§ЃЌKФЌШЯЮЊ1000ЃЌБэЪОБЃСєгУЛЇЪБМфЯпжсжаЕФзюКѓKЬѕЭЦЮФЁЃ
дкгУЛЇЪБМфЯпСаБэжаЃЌЭЦЮФАДcreationTimeЃЈДДНЈЪБМфЃЉНЕађДцДЂЁЃЕБгУЛЇЪБМфЯпСаБэДяЕНзюДѓKЬѕЭЦЮФЪБЃЌзюРЯЕФЬѕФПНЋБЛЩОГ§ЁЃ
6. ЩШГіЗўЮёЃЈFanout ServiceЃЉ
НЋаТЭЦЮФзЊЗЂЕНЫбЫїКЭжївГЪБМфЯпЗўЮёЃЌвдМАЦфЫћзщМў/ЮЂЗўЮёЃЌБШШчЧїЪЦЗўЮёЛђЭЈжЊЗўЮё
гЩЖрИіЗжВМЪНЖгСазщГЩ
ЕБгУЛЇЗЂЫЭвЛЬѕЭЦЮФЯћЯЂЪБЃЌИУЗўЮёАбЯћЯЂЗХШыЭЦЮФЖгСаЃЌЩчНЛЭјТчЗўЮёБиаыЛёЕУгУЛЇЕФЙизЂепСаБэЃЌВЂдкЕкЖўзщЖгСажаВхШыОЁПЩФмЖрЕФЯћЯЂЁЃЖдгкУћШЫгУЛЇРДЫЕЃЌЫћУЧгЕгаЗЧГЃЖрЕФЗлЫПЃЌЦфЗлЫПЪ§ЩѕжСГЌЙ§СЫУПДЮЭЦЫЭЕФуажЕЁЃФЧУДЃЌШчКЮДІРэетИіЮЪЬтФи?
ИУЗўЮёЪЧвЛИіЯШНјЯШГіЕФШЮЮёЖгСаСаБэЃЌДІРэЙВЯэЯрЭЌСаБэЕФШЮЮёЃЌВЂдкЭъГЩКѓЗДРЁИјЖгСаЗўЮёЦїЁЃЖгСаЗўЮёЦїЪЧвьВНШЮЮёЕФживЊзщГЩВПЗжЃЌЦфжДааЕФШЮЮёПЩФмВЛЛсСЂМДЪеЕНЯьгІЃЌЕЋШДФмЙЛБЃжЄзюжевЛжТадЁЃ
7. жївГЪБМфЯпЗўЮёЃЈHome timeline serviceЃЉ
ЯдЪОгУЛЇЕФжївГЪБМфЯп
АќРЈРДздЦфЫћЙизЂЕФгУЛЇЕФЭЦЮФЃЌАДееЭЦЮФЕФcreationTimeЃЈДДНЈЪБМфЃЉНЕађЯдЪОЁЃ
ЦфЩшМЦРрЫЦгкгУЛЇЪБМфЯпЗўЮёЁЃ
ЕЋЪЧБШгУЛЇЪБМфЯпЗўЮёЩдЮЂИДдгвЛЕуЃЌвђЮЊгУЛЇНЋВхШызюаТЕФЭЦЮФЃЌВЂЧвЕБЭЦЮФЪ§СПГЌЙ§KжЕЪБашвЊЩОГ§зюРЯЕФЭЦЮФЃЌШчЙћгУЛЇЙизЂСЫКмЖрЦфЫћгУЛЇЃЌЗўЮёЛЙашвЊвЛаЉЛњжЦРДИјВЛЭЌЙизЂгУЛЇЕФЭЦЮФИГгшВЛЭЌЕФШЈжиЁЃ
8. ЫбЫїЗўЮёЃЈSearch serviceЃЉ
ЮЊгУЛЇЬсЙЉЫбЫїВщбЏЗўЮё
ЩШГіЗўЮёНЋЭЦЮФДЋЕнИјЫбЫїЗўЮё
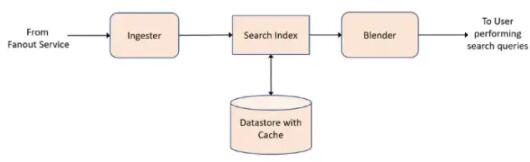
Ingester(Лђingestion engine)ЃКИјЭЦЮФБъМЧЩЯаэЖрБъЧЉЁЂЪѕгяЛђЙиМќзжЁЃР§ШчетЬѕЭЦЮФ:ЁАЮвЯыГЩЮЊЯёбЧТэбЗЕФНмЗђЁЄБДЫїЫЙвЛбљЗЧГЃИЛгаЕФШЫЁБЃЌЫќЛсЙ§ТЫЕєФЧаЉдкЫбЫїжаУЛгагУЕФДЪЁЃГ§СЫНмЗђЁЄБДЫїЫЙ(Jeff
Bezos)КЭбЧТэбЗ(Amazon)ЃЌЫљгаЦфЫћДЪЖМНЋБЛЖЊЦњЁЃIngesterПЩвдЭЈЙ§ХфжУЛђЪ§ОнПтЛёЕУДЪЛуБэЁЃ
вЛИіНазіЁАДЪИљЬсШЁЃЈstemmingЃЉЁБЕФЙ§ГЬЖдЪЃЯТЕФЕЅДЪНјааЗжЮіЃЌвдШЗЖЈЫќУЧЕФДЪИљЁЃStemmingЪЧДІРэДЪИЩЁЂДЪИљЛђДЪИљЕФДЪаЮБфЛЏ(ЛђХЩЩњ)ЕФЙ§ГЬЁЃвђДЫЃЌЛсдкЪ§ОнПтжаБЃДцвЛИіВщевБэЁЃетжжЗНЗЈЕФгХЕуЪЧПЩвдМђЕЅЁЂПьЫйЁЂЧсЫЩЕФДІРэвьГЃЁЃШБЕуЪЧаТЕФЛђВЛЪьЯЄЕФЕЅДЪМДЪЙЪЧЭъШЋЗћКЯЙцдђЕФЃЌвВВЛЛсБЛДІРэЁЃ
ДЋЕнЕНЫбЫїЫїв§
ЫбЫїЫїв§ЮЂЗўЮёНЋДДНЈЗДЯђЫїв§ЃЌВЂДцДЂДгФкШн(ШчЕЅДЪ)ЕНЦфЫљдкЮФЕЕЛђвЛзщЮФЕЕжаЕФЮЛжУЕФЪѕгягГЩфЫїв§ЃЌдкЮвУЧЕФР§згжаЃЌетЪЧвЛИіЛђвЛзщЭЦЮФЁЃ
BlenderЗўЮёЃКдкtwitterЦНЬЈЩЯЮЊгУЛЇЬсЙЉЫбЫїВщбЏЁЃЕБЧыЧѓЫбЫїВщбЏЪБЃЌЪзЯШШЗЖЈЫбЫїЬѕМўЃЌШЛКѓНјааДЪИЩЗжЮіЃЌзюКѓЪЙгУДЪИљдкЪѕгяЕФЕЙХХЫїв§ЩЯдЫааЫбЫїВщбЏЁЃ
9. ееЦЌКЭЪгЦЕ
ЪЙгУNoSQLЪ§ОнПт
УНЬхЮФМў(ЪЙгУЮФМўЯЕЭГ)
Ъ§ОнБэИёЪН

twitterЕФЭјТч

twitterЕФзюжеЯъЯИЩшМЦ
ЯЕЭГЩшМЦ

Ъ§ОнМмЙЙ

|








