| 编辑推荐: |
本文主要介绍了GPU图形流水线基础相关内容。希望对你的学习有帮助。
本文来自于微信公众号TrustZone ,由火龙果软件Linda编辑、推荐。 |
|
一、前言
不小心算是邂逅了龚大的视频,看了一遍视频之后,仿佛记得,但是很多的东西又仿佛记不住。于是乎想着写一篇笔记记录一下,我自身最近也在学习做媒体相关的东西,那必须学习一下GPU啊。
图形和视频 ~~~ 某种程度上图形连续起来视频。
嗯,又牛又拽太爱了。
二、前言-显示器
显示器是如何显示画面的?
基本单元像素如下!!!

每个像素都包含红绿蓝,也就是RGB三个分量,通过组合形成各种各样的颜色。

每个分量可以用数字表示,最常见的是用8个进制位来表示,数字越大亮度越高。这样的话三个分量组合之后,就能表示256256256=16777216种颜色。
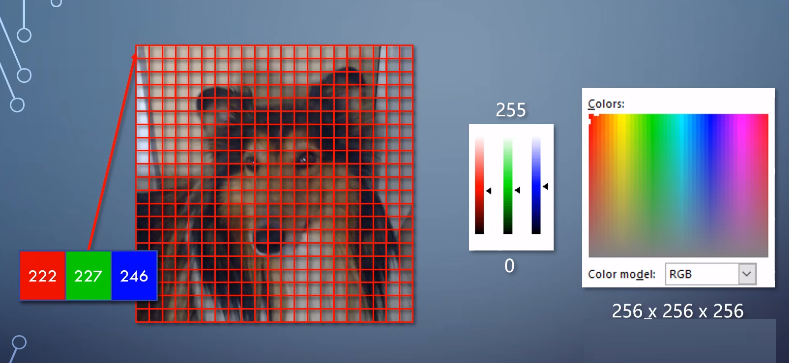
随着内容和显示技术的发展,这几年也出现了。每个分量用10位、12位、16位等更高的位数来表示。他们可以表达更多的细节,或者更大的范围。它们的原理其实没有多少区别,简化起见,我们在这里主要讲8位的情况。
那么作为一台电脑如果要把内容输出到显示器,要做什么呢?在这里之前看看一些基本概念。
三、图形基本概念
这里的一个概念叫帧缓存,frame buffer,这是内存的一块区域。
这块区域里的内容和显示器上显示的每个像素是一一对应的。
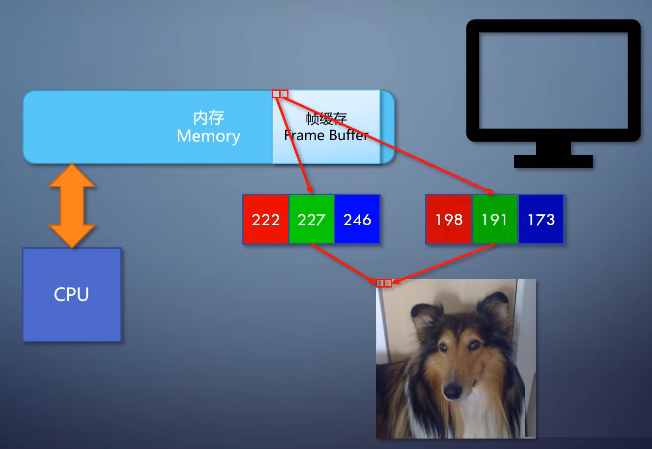
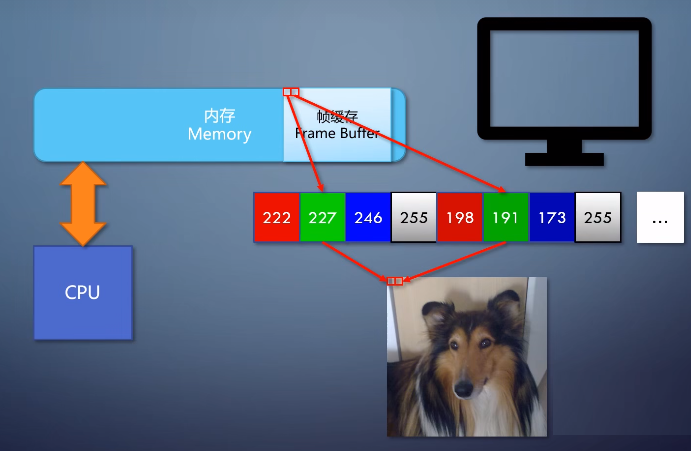
8位是一个字节,所以帧缓存里每一个字节。(每个分量可以用数字表示,最常见的是用8个进制位来表示)
表示一个像素的一个分量,连续排列下去,当然现代的电脑更适合32位对齐的处理方式。所以在帧缓存里,每32位,也就是4个字节来表示一个像素。除了RGB占用的24位,后面还跟了一个表示透明度的Alpha。虽然输出到显示器的时候,这个信息会被忽略。
有了帧缓存之后,我们需要有一个设备,把帧缓存的内容输出到显示器上。这个就得看显卡了。显卡上有个显示输出端口,通过显示器。
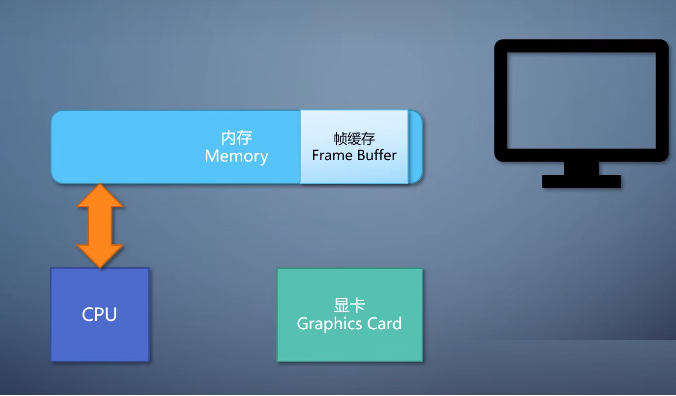

还有个显示电路,把帧缓存转成显示输出的信号,
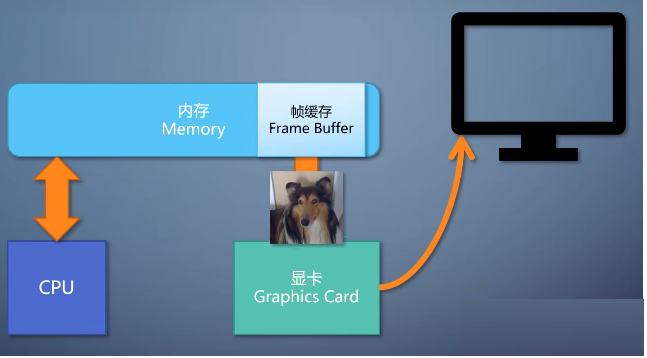
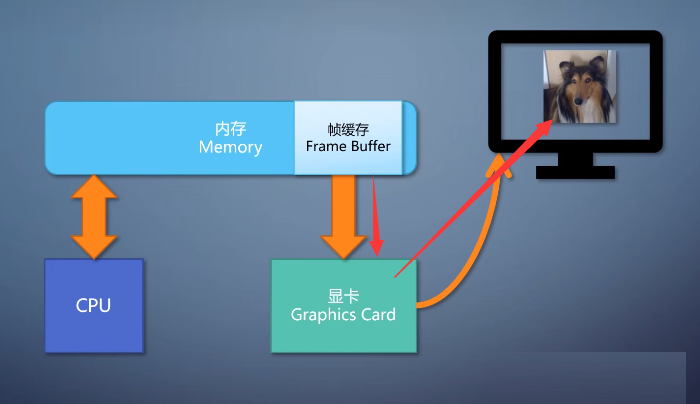
注意,这只是个显卡,上面没有计算能力,只是图像的搬运工。
现在需求增加了,我们想把显示的图像亮度翻倍,也就是RGB每个分量都乘2。我们可以在CPU上做这个事情,在每个数字在写入帧缓存之前,先乘个2。这样必然要占用大量的CPU资源。
一个更好的方法,是加入一个处理器(PU),能在大量数据上执行同样的操作。比如这里就是把每个像素的都*2,但有大量像素要处理。如果操作的算法固定,那就只需要设置不同的参数就能达到目的。
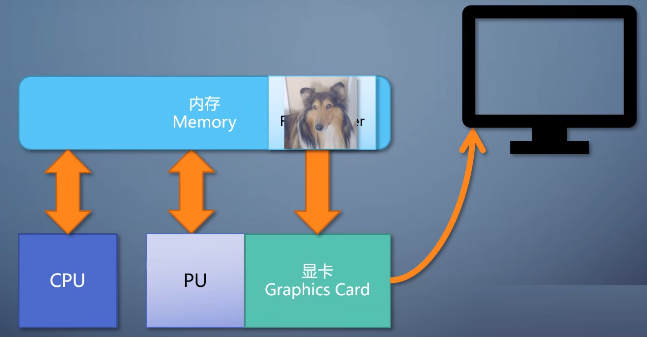
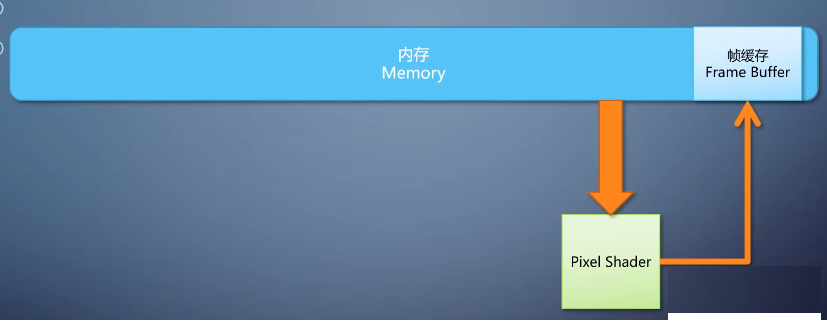
但如果操作需要灵活多变,就得挂上一个程序才行。我们把这样的程序叫做shader,又因为它处理的对象是像素。所以这里的shader是pixel
shader,这种可以绑上shader的单元叫做可编程流水线单元(Programmable Pipeline
Uint),每个pixel shader仅仅处理一个像素,单入单出。
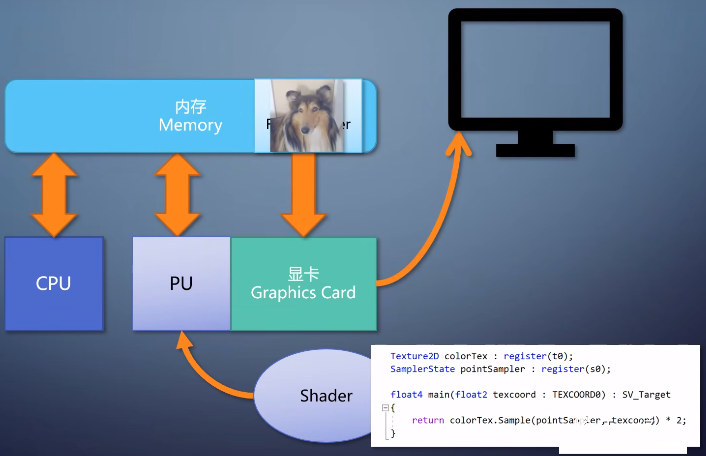
在这里,pixel shader的输入是一个坐标。
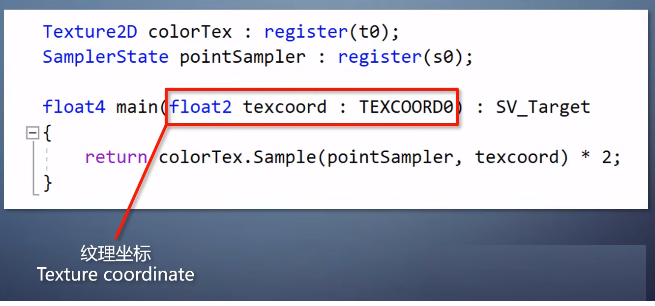
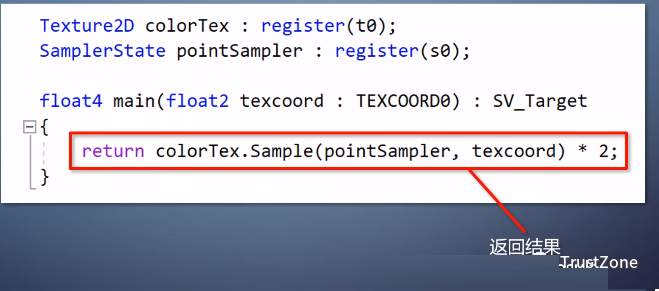
(纹理坐标:它根据坐标从图像上采到颜色,执行操作后返回结果。)
我们管输入的图像叫做纹理,texture。而如何从坐标到纹理里面采集数据,以及如何写入帧缓存。
并不需要shader来管,有专门的硬件负责。
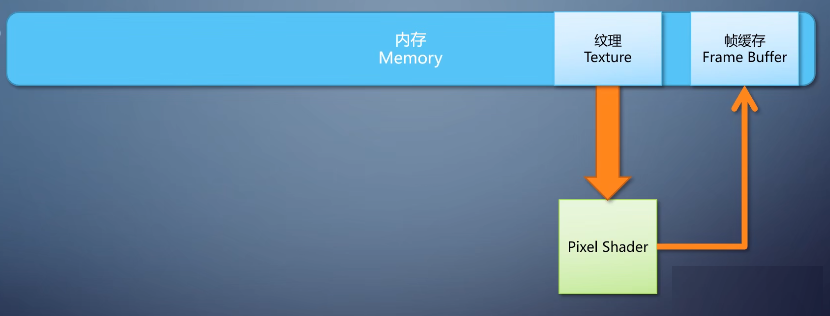
到这里我们已经能看到了一个最初级的针对图像的处理器,它只能运行pixel shader,只能把一张图像的每个像素处理之后输出。

(我以前也有一个,后来被放不见了。)
在任天堂红白机上有这么一个处理器,称为PPU。负责图块移动等操作。

光处理图片不够,更进一步。
1-图元—Primitive
如果输入不是简单的一张图,而是一个几何网格,该怎么办呢?
这样的几何由一系列简单形状组成。比如点、线三角形、四边形等。这些简单形状称为图元—Primitive。
简化来说,我们这里只看三角形,这一堆三角形怎么和像素搭上关系呢?
2-光栅化—rasterize
在到达pixel shader之前,需要一个环节,把三角形所覆盖区域的像素填上。这个环节叫做光栅化—rasterize

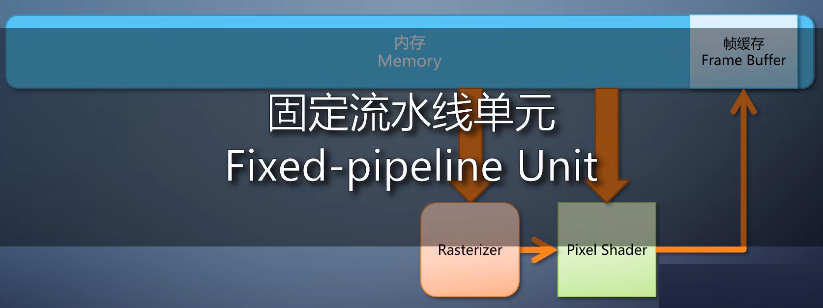
这个是一个算法固定的操作,为了效率一般用硬件直接构成,不可编程。我们称其为固定流水线的单元。
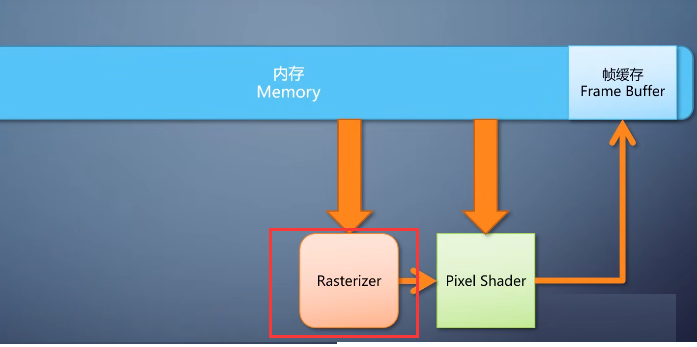
3-output merger(深度判断)
除此之外,几何存在前后遮挡关系,如何确定哪个像素显示,哪个不显示呢?这就需要在pixel shader之后加一个环节,

叫做output merger,里面会做深度判断。

根据规则来决定哪个像素最后能存活下来,这也是固定流水线的单元。

4-图元组装单元(Primitive Assembler)
还没完,几何是怎么存储的呢?
首先是有一堆的点,分布于空间里,这些点叫做顶点vertex。

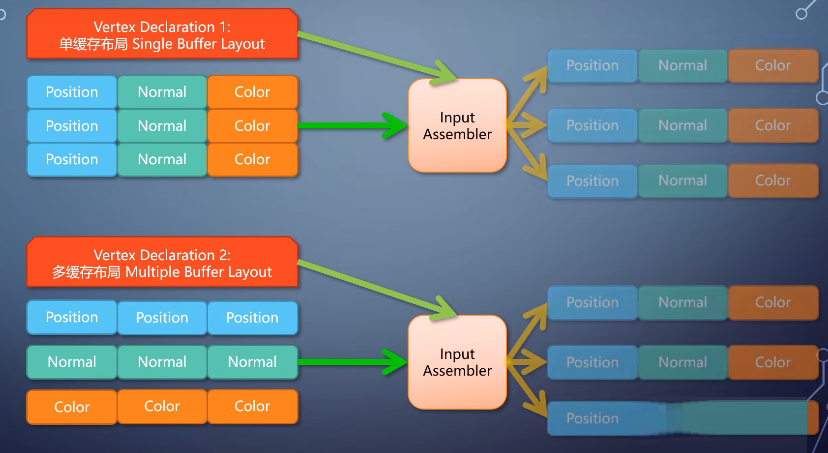
每个顶点一般有表示位置的<x, y, z>坐标。以及方向、颜色、纹理坐标等信息。
存放顶点的buffer叫做vertex buffer。
然后有一堆线,把它们连起来。所以我们需要一个buffer。

里面的每一个单元是一个整数,表示vertex的索引。这样的buffer称为index buffer。有了这两个,就可以表示出一个几何形状。
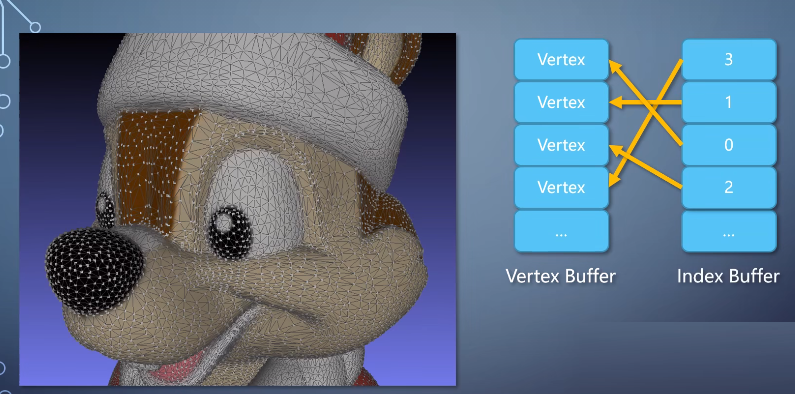
在开始光栅化处理之前,需要把vertex们组装成一个个三角形。把屏幕之外的裁剪掉,计算三条边的方程等。然后才送入rasterize。
这里的图元组装单元,这也是固定流水线单元。
5-硬件变换和光照(T&L)
新的需求又来了。同一个几何体。我可以把它摆放在不同位置、从不同角度看它、或者调整摄像机的焦距。它在屏幕上就该看起来不一样。

这时候,index buffer是一样的。因为几何本身拓扑关系不变。
但vertex buffer里的每个顶点,都需要做一个变换。把它从几何自己的空间变换到屏幕的空间。
这里需要三个不同的变换,每个变换用一个4x4的矩阵来表示。
顶点的坐标<x, y, z>,加上第四个维度1,乘上这三个矩阵,能得到一个在屏幕空间的坐标<x',
y', z', w'>。
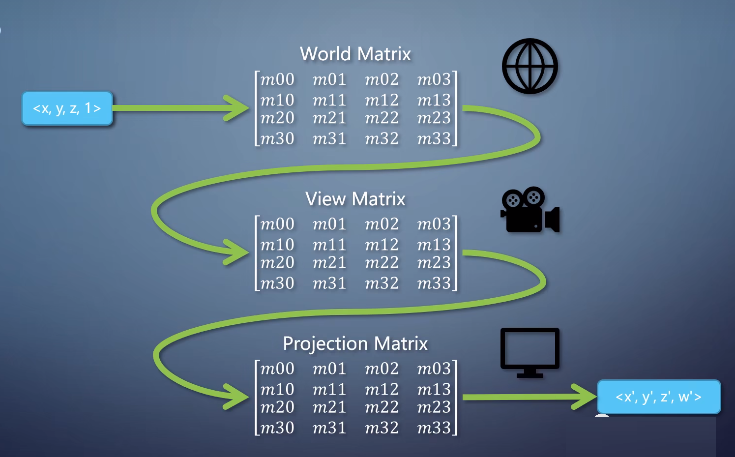
这三个变换里,
• 第一个用来决定这个物体在空间中的:位置、朝向、放缩等,叫做world matrix。经过这个矩阵,物体就摆放到一个全局的世界里。

• 第二个用来决定摄像机的位置,叫做view matrix。经过这个矩阵,物体就在以摄像机为原点的坐标系里。表示从摄像机能看到的一个空间。

• 第三个用来调整摄像机的参数,比如视野宽窄,视域远近范围,叫做projection matrix。经过过个矩阵,物体就在屏幕范围这个空间里了,并带有近大远小的效果。

同样,如果只要固定不变的算法操作,那确实可以用固定的硬件和可设置的参数来完成。
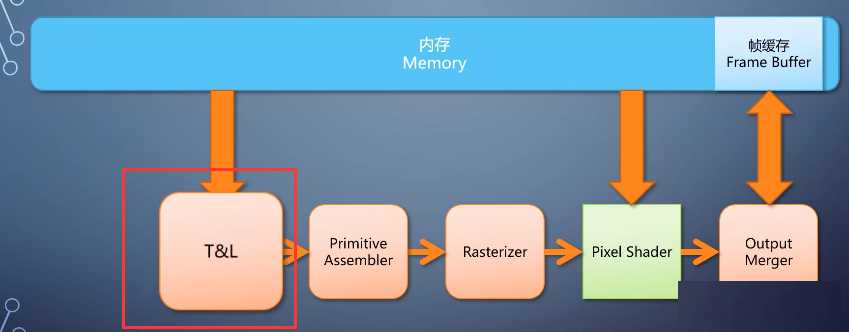
早起的GPU确实也是这么做的,比如2000年的GeForce 256。

这一步被称为硬件变换和光照(T&L),但为了灵活性的需求,很快就进化到可编程的方式,但为了灵活性的需求,很快就进化到可编程的方式。用一个shader对每个顶点过一遍,这个就是vertex
shader。
(T&L 进化为vertex shader)
而顶点的信息,可以根据需要不同格式来保存。
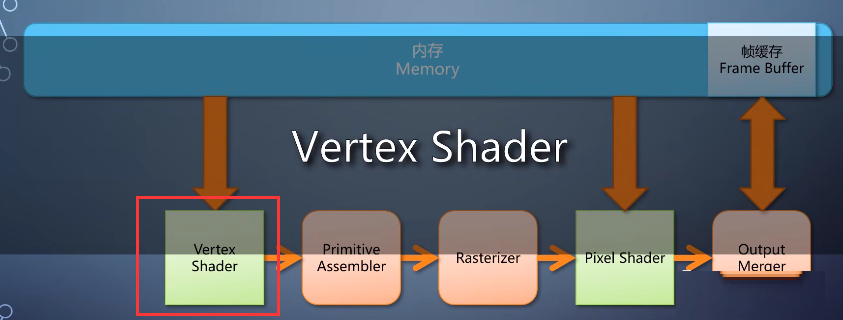
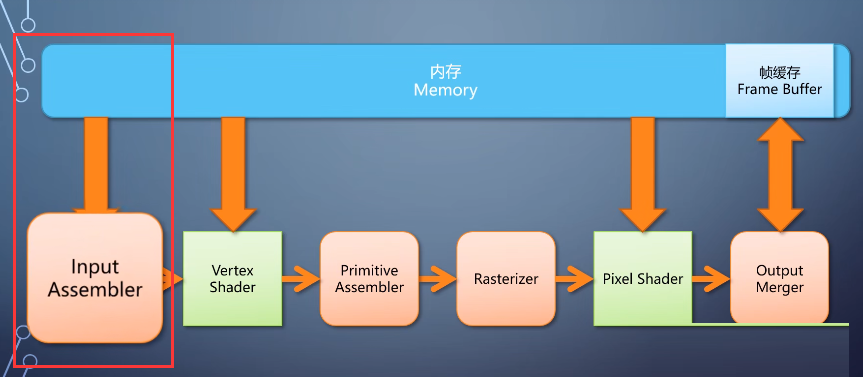
6-input assembler

vertex shader并不需要知道顶点存储的格式。
所以这里需要调用者提供一个顶点格式的描述,由一个固定流水线单元input assembler,从vertex
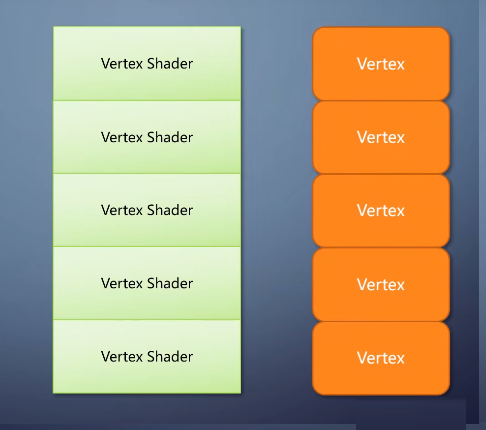
buffer里组装出一个顶点,送给vertex shader处理。
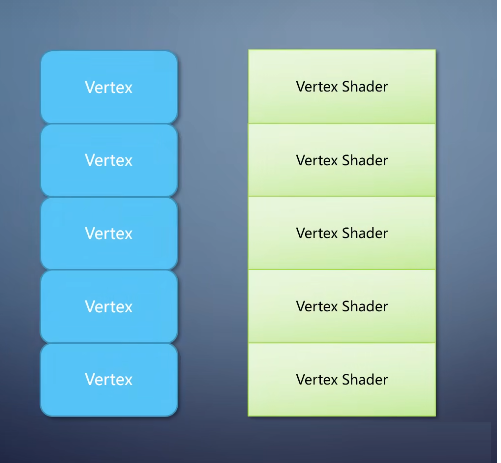
同样,每个vertex shader仅仅处理一个vertex,单入单出。
四、小结
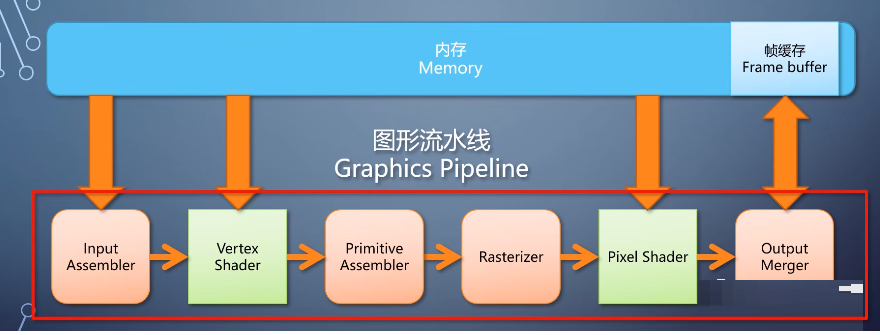
这个时候我们已经得到了一条完整的图形流水线(Graphics Pipeline)
调用者提供输入的信息之后,就能渲染出图像,送去显示。
这条流水线里,有可编程的单元,也有不可编程的单元。取长补短以保证效率和灵活性的平衡。这样的流水线,就是2000年代主流GPU的构成。
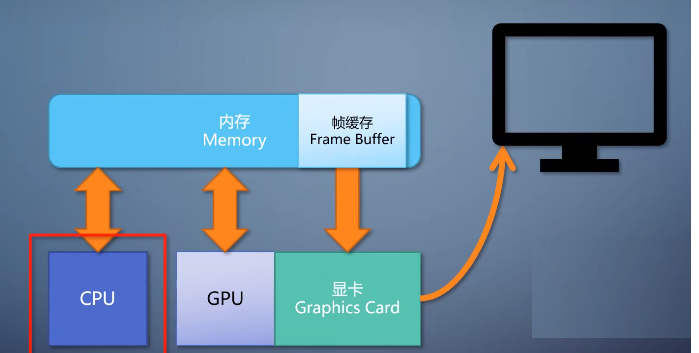
它把CPU从图形渲染过程中,简单但大数据量的操作中解放解放出来, 由专用的GPU来高效地做这些事情。也正是因为有图形渲染的能力,GPU才能叫做Graphics
Processing Unit。
没有图形渲染能力却说自己是GPU的,都是在诈骗。
总结起来,不管是vertex shader还是pixel shader,
它们的程序功能集中,只处理一个硬件塞过来的数据单元,返回处理后的结果。
不需要考虑具体如何从内存读取这些数据,以及处理完怎么写出去,前后都有别的单元来处理。换句话说就像个回调函数,GPU在需要的时候在大量数据上。对每个单元调用一下这个回调函数。
同时,我们也可以看到CPU和GPU的第一个不同之处。

CPU擅长在小数据上做相对复杂的串行计算和逻辑控制。
GPU擅长在大量数据上做相对简单的并行计算,这个特点使得它们有了分工和协作。
那么,随着需求的进一步发展,GPU还有什么变化呢?下一篇顺着这个思路,继续扩充GPU的功能。 |








