| �ܶ�JavaScript���棬��Google��V8���棨��Chrome��Node���ã�����ר��Ϊ��Ҫ����ִ�еĴ���JavaScriptӦ������Ƶġ��������һ�������ߣ����ҹ����ڴ�ʹ�������ҳ�����ܣ���Ӧ���˽��û�������е�JavaScript��������������ġ�������V8��SpiderMonkey�ģ�Firefox����Carakan��Opera����Chakra��IE�����������棬����������������õ��Ż����Ӧ�ó����Ⲣ����˵Ӧ��ר��Ϊijһ��������������Ż���ǧ�����ô����
���ǣ���Ӧ�����Լ��������⣺
1.���ҵĴ�����Ƿ����ʹ�������ЧһЩ
2.������JavaScript���涼������Щ�Ż�
3.ʲô���������Ż��ģ�������������GC���Ƿ��ܻ������������Ķ���

���ؿ��ٵ���վ������һ�����ٵ��ܳ�����Ҫ�õ��ر��Ƶ����. ͼƬ��Դ: dHybridcars.
��д�����ܴ���ʱ��һЩ���������壬����ƪ�����У����ǽ�չʾһЩ������֤�ġ����õı�д���뷽ʽ��
��ô��JavaScript��V8������ι����ģ�
������JS����û�н�����˽⣬����һ������WebӦ��Ҳûɶ���⣬�ͺñȻῪ������Ҳֻ�ǿ�������Ƕ�û�п��������ڵ�����һ��������Chrome���ҵ��������ѡ������̸һ������JavaScript���档V8�������¼������IJ�����ɣ�
1.һ�������ı������������ڴ���ִ��ǰ����JavaScript���벢���ɱ��ػ����룬������ִ���ֽ����ؽ���������Щ�����ʼ�����Ǹ߶��Ż��ġ�
2.V8������Ϊ����ģ�͡���JavaScript�ж������Ϊ�������飬������V8�ж����������ص��࣬һ��Ϊ���Ż���ѯ���ڲ�����ϵͳ��
3.����ʱ�����������������е�ϵͳ������ʶ�ˡ�hot���ĺ��������绨�Ѻܳ�ʱ�����еĴ��룩��
4.�Ż����������±�����Ż���Щ������ʱ��������ʶΪ��hot���Ĵ��룬�����С����������Ż��������ñ������ߵ������滻�������õ�λ�ã���
5.V8֧��ȥ�Ż�������ζ���Ż�������������ֶ��ڴ����Ż��ļ�������ֹۣ����������Ż����Ĵ��롣
6.V8�и������ռ������˽�������ι����ĺ��Ż�JavaScriptһ����Ҫ��
��������
�����������ڴ������һ����ʽ����ʵ����һ���ռ����ĸ�����Ի��ղ��ٱ�ʹ�õĶ�����ռ�õ��ڴ档��JavaScript�����������������У�Ӧ�ó��������ڱ����õĶ��ᱻ�����
�ֶ��������������ڴ�����������û�б�Ҫ�ġ�ͨ���ذѱ���������Ҫ���ǵĵط�����������£��������Ǿֲ����������DZ�ʹ�õĺ���������Ǻ�����㣩��һ�н������غܺá�

�������������Ի����ڴ�. ͼƬ��Դ: Valtteri
M?ki.
��JavaScript�У��Dz�����ǿ�ƽ����������յġ��㲻Ӧ����ô������Ϊ�����ռ�������������ʱ���Ƶģ���֪��ʲô����õ�����ʱ����
��������������
�������������JavaScript�ڴ���յ����۶�̸��delete����ؼ��֣���Ȼ�����Ա�����ɾ������map���е����ԣ�key�������в��ֿ�������Ϊ����������ǿ�ơ��������á������龡���ܱ���ʹ��delete���������������delete
o.x �ı״���������Ϊ���ı���o�������࣬��ʹ����Ϊһ��"������"��
var o = { x: 1 };
delete o.x; // true
o.x; // undefined |
�������������е�JS�����ҵ�����ɾ���������Ǿ�������Ŀ���Եġ�������Ҫע����DZ���������ʱ�ġ�hot������Ľṹ��JavaScript������Լ������֡�hot���Ķ������Զ�������Ż������������������������ṹû�нϴ�ĸı䣬���潫��������Ż�����delete����ʵ���ϻᴥ�����ֽϴ�Ľṹ�ı䣬��˲�����������Ż���
����null����ι���Ҳ�������ġ���һ��������������Ϊnull����û��ʹ����䡰�ա���ֻ�ǽ�������������Ϊ�ն��ѡ�ʹ��o.x=
null��ʹ��delete�����Щ��������Ҳ���Ǻܱ�Ҫ��
var o = { x: 1 };
o = null;
o; // null
o.x // TypeError |
����������ǵ�ǰ�����������ã���ô�ö�����Ϊ�������ա���������ò��ǵ�ǰ�����������ã���ö����ǿɷ��ʵ��Ҳ��ᱻ�������ա�
������Ҫע����ǣ�ȫ�ֱ�����ҳ��������������Dz������������������ġ�����ҳ���ã�JavaScript����ʱȫ�ֶ����������еı�����һֱ���ڡ�
var myGlobalNamespace = {}; |
ȫ�ֶ���ֻ����ˢ��ҳ�桢����������ҳ�桢�رձ�ǩҳ���˳������ʱ�Żᱻ����������������ı������ڳ���������ʱ�����������˳�����ʱ���Ѿ�û���κ����ã������ı����ͱ������ˡ�
���鷨��
Ϊ��ʹ���������������ռ������ܶ�Ķ���Ҫhold�Ų���ʹ�õĶ��������м�������Ҫ��ס��
����ǰ���ᵽ�ģ��ں��ʵķ�Χ��ʹ�ñ������ֶ��������õĸ���ѡ��һ������ֻ��һ��������������ʹ�ã��Ͳ�Ҫ��ȫ��������������������ζ�Ÿ��ɾ�ʡ�ĵĴ��롣
ȷ�������Щ������Ҫ���¼�����������������Щ���������ٵ�DOM���������¼���������
���ʹ�õ����ݻ����ڱ��أ�ȷ������һ�»����ʹ���ϻ����ƣ��Ա�������������õ����ݱ��洢��
����
������������̸̸���������������Ѿ�˵���������ռ��Ĺ���ԭ������ͨ�����ղ����Ƿ��ʵ��ڴ�飨����Ϊ�˸��õ�˵����һ�㣬������һЩ���ӡ�
function foo() {
var bar = new LargeObject();
bar.someCall();
} |
��foo����ʱ��barָ��Ķ��ᱻ�����ռ����Զ����գ���Ϊ����û���κδ��ڵ������ˡ�
�Ա�һ�£�
function foo() {
var bar = new LargeObject();
bar.someCall();
return bar;
}
// somewhere else
var b = foo(); |
����������һ������ָ��bar��������bar������������ھʹ�foo�ĵ���һֱ������������ָ����ı���b����b������Χ����
�հ���CLOSURES��
���㿴��һ������������һ���ڲ����������ڲ���������÷�Χ��ķ���Ȩ����ʹ���ⲿ����ִ��֮������һ�������ıհ�
���� �������ض��������������õı����ı���ʽ�����磺
function sum (x) {
function sumIt(y) {
return x + y;
};
return sumIt;
}
// Usage
var sumA = sum(4);
var sumB = sumA(3);
console.log(sumB); // Returns 7 |
��sum���������������ɵĺ�������sumIt�����������յģ�����ȫ�ֱ�����sumA�������ã����ҿ���ͨ��sumA(n)���á�
����������������һ�����ӣ��������ǿ��Է��ʱ���largeStr��
var a = function () {
var largeStr = new Array(1000000).join('x');
return function () {
return largeStr;
};
}(); |
�ǵģ����ǿ���ͨ��a()����largeStr��������û�б����ա���������أ�
var a = function () {
var smallStr = 'x';
var largeStr = new Array(1000000).join('x');
return function (n) {
return smallStr;
};
}(); |
���Dz����ٷ���largeStr�ˣ����Ѿ����������պ�ѡ���ˡ�������ע����ΪlargeStr�Ѳ������ⲿ�����ˡ�
��ʱ��
������ڴ�й©�ط�֮һ����ѭ���У�������setTimeout()/ setInterval()�У��������൱�����ġ�˼�����������:
var myObj = {
callMeMaybe: function () {
var myRef = this;
var val = setTimeout(function () {
console.log('Time is running out!');
myRef.callMeMaybe();
}, 1000);
}
}; |
�����������myObj.callMeMaybe();��������ʱ�������Կ�������̨ÿ���ӡ����Time
is running out!���������������myObj = null����ʱ�����ɴ��ڼ���״̬��Ϊ���ܹ�����ִ�У��հ���myObj���ݸ�setTimeout������myObj���������յġ��෴�������õ�myObj����Ϊ��������myRef���������Ϊ�˱������ý��հ����������ĺ�����һ���ġ�
ͬ��ֵ���μǵ��ǣ�setTimeout/setInterval����(�纯��)�е����ã�����Ҫִ�к���ɣ��ſ��Ա������ռ���
������������
��Զ��Ҫ�Ż����룬ֱ����������Ҫ�����ھ������Կ���һЩ�����ԣ���ʾN��M��V8�и�Ϊ�Ż���������ģ������Ӧ���в���һ�»ᷢ�֣���Щ�Ż�������Ч������������ҪС�Ķࡣ

���Ĺ������ʲô������. ͼƬ��Դ: Tim
Sheerman-Chase.
����������Ҫ��������һ��ģ�飺
1.��Ҫһ�����ص�����Դ��������ID
2.���ư�����Щ���ݵı���
3.�����¼����������û�������κε�Ԫ��ʱ�л���Ԫ���css class
��������м�����ͬ�����أ���ȻҲ���������������δ洢���ݣ���θ�Ч�ػ��Ʊ�����append��DOM�У���θ��ŵش��������¼���
�����Щ�����ʼ�����棩��������ʹ�ö���洢���ݲ����������У�ʹ��jQuery�������ݻ��Ʊ���append��DOM�У����ʹ���¼������������ص����Ϊ��
ע�⣺�ⲻ����Ӧ������
var moduleA = function () {
return {
data: dataArrayObject,
init: function () {
this.addTable();
this.addEvents();
},
addTable: function () {
for (var i = 0; i < rows; i++) {
$tr = $('<tr></tr>');
for (var j = 0; j < this.data.length; j++) {
$tr.append('<td>' + this.data[j]['id'] + '</td>');
}
$tr.appendTo($tbody);
}
},
addEvents: function () {
$('table td').on('click', function () {
$(this).toggleClass('active');
});
}
};
}(); |
��δ������Ч�����������
������������£����DZ���������ֻ�DZ�Ӧ�üش���������е�����������ID����Ȥ���ǣ�ֱ��ʹ��DocumentFragment�ͱ���DOM������ʹ��jQuery�������ַ�ʽ�������ɱ����Ǹ��ŵ�ѡ��Ȼ���¼������ȵ�����ÿ��td���и��ߵ����ܡ�
Ҫע����ȻjQuery���ڲ�ʹ��DocumentFragment�����������ǵ������У�������ѭ���ڵ���append������Щ�����漰��һЩ������С֪ʶ��������������Ż����ò���ϣ���ⲻ����һ��ʹ�㣬������ؽ��л����ԣ���ȷ���Լ�����ok��
�������ǵ����ӣ����������������ˣ������ģ������������¼������Լİ���һ�ָĽ�����ѡ��DocumentFragmentҲ�����������á�
var moduleD = function () {
return {
data: dataArray,
init: function () {
this.addTable();
this.addEvents();
},
addTable: function () {
var td, tr;
var frag = document.createDocumentFragment();
var frag2 = document.createDocumentFragment();
for (var i = 0; i < rows; i++) {
tr = document.createElement('tr');
for (var j = 0; j < this.data.length; j++) {
td = document.createElement('td');
td.appendChild(document.createTextNode(this.data[j]));
frag2.appendChild(td);
}
tr.appendChild(frag2);
frag.appendChild(tr);
}
tbody.appendChild(frag);
},
addEvents: function () {
$('table').on('click', 'td', function () {
$(this).toggleClass('active');
});
}
};
}(); |
���������������������ܵķ�ʽ����Ҳ���������Ķ�����ʹ��ԭ��ģʽ��ģ��ģʽ���ţ�����˵��ʹ��JSģ�������ܸ��á���ʱ��ȷ��ˣ�����ʹ��������ʵ��Ϊ�˴�����߿ɶ��ԡ����ˣ�����Ԥ���룡�����ǿ�����ʵ���б��ֵ���Σ�
moduleG = function () {};
moduleG.prototype.data = dataArray;
moduleG.prototype.init = function () {
this.addTable();
this.addEvents();
};
moduleG.prototype.addTable = function () {
var template = _.template($('#template').text());
var html = template({'data' : this.data});
$tbody.append(html);
};
moduleG.prototype.addEvents = function () {
$('table').on('click', 'td', function () {
$(this).toggleClass('active');
});
};
var modG = new moduleG(); |
��ʵ֤��������������µĴ����������������Ժ��Բ��ơ�ģ���ԭ�͵�ѡ��û�������ṩ����Ķ�����Ҳ����˵�����ܲ����ǿ�����ʹ�����ǵ�ԭ����������Ŀɶ��ԡ��̳�ģ�ͺͿ�ά���Բ���������ԭ��
�����ӵ����������Ч����canvas�ϻ���ͼƬ�Ͳ�����������������������ݡ�
�ڽ�һЩ�����������Լ���Ӧ��֮ǰ��һ��Ҫ���˽���Щ�����Ļ����ԡ�Ҳ�����˻��ǵ�JSģ���shoot-off��������չ�档��Ҫ����������Բ��Ǵ������㿴��������Щ����Ӧ�ã�����Ӧ�������ʵ�ʴ�����ȥ���Դ������Ż���
V8�Ż�����
��ϸ������ÿ��V8������Ż����ڱ������۷�Χ֮�⣬��Ȼ����Ҳ������ֵ��һ��ļ��ɡ���ס��Щ��������ܼ�����Щ���ܵ��µĴ����ˡ�
�ض�ģʽ����ʹV8�����Ż�������������˵try-catch�����˽�����й���Щ�����ܻ��ܽ����Ż����������V8�Ľű�����d8��ʹ�èCtrace-opt
file.js���
���������ٶȣ�����ʹ��ĺ���ְ��һ����ȷ���������������ԣ����飬����������ֻʹ����ͬ����������Ķ��ٸ����ӣ�����ô�ɣ�
function add(x, y) {
return x+y;
}
add(1, 2);
add('a','b');
add(my_custom_object, undefined); |
��Ҫ����δ��ʼ������ɾ����Ԫ�ء������ô��Ҳ�������ʲô������������ʹ�ٶȱ�����
��Ҫʹ���������������ʹ���Ż��������ѡ�
�������ݿ���ȥ��Daniel Clifford��Google I/O�ķ��� Breaking the
JavaScript Speed Limit with V8�� Optimizing For V8 ��
A SeriesҲ�dz�ֵ��һ����
����VS���飺��Ӧ�����ĸ���
�������洢һ�����֣�����һЩ��ͬ���͵Ķ���ʹ��һ�����顣
�������������Ҫ����һ�ѵĶ�������ԣ���ͬ���͵ģ���ʹ��һ����������ԡ������ڴ淽��dz���Ч���ٶ�Ҳ�൱�졣
����������Ԫ�أ����۴洢��һ�����������У���Ҫ�ȱ�����������Կ�öࡣ
��������ԱȽϸ��ӣ����ǿ��Ա�setter�Ǵ��������в�ͬ��ö���ԺͿ�д�ԡ�������������˵Ķ����ԣ���ֻ�����к���������״̬����������棬����������洢�ṹ������Ż����ر��ǵ������д�������ʱ�����統����Ҫ����ʱ�����ö������x,y,z���Ե��࣬��ֻ������Ϳ����ˡ�
JavaScript�ж��������֮��ֻ��һ������Ҫ�����Ǿ������������length���ԡ�������Լ���ά��������ԣ���ôV8�ж����������ٶ���һ����ġ�
ʹ�ö���ʱ�ļ���
ʹ��һ�����캯�������������⽫ȷ�������������ж��������ͬ�������࣬�������ڱ��������Щ�ࡣ��Ϊһ������ĺô�����Ҳ�Կ���Object.create()
���Ӧ���У�����ʹ�ò�ͬ���͵Ķ�����临�Ӷȣ��ں����ķ�Χ�ڣ���ԭ�����������к��ģ�����ֻ��һ�����������ԵĶ���ȴ������һ�㣩����û���Ƶġ����ڡ�hot�����������ֶ�ԭ���������������ԡ�
�����¡
����Ӧ�ó�����Ա�������¡��һ�����������⡣��Ȼ���ֻ����Կ���֤��V8�����������úܺã�����ҪС�ġ����ƴ�Ķ���ͨ���ǽ����ġ�����Ҫ��ô����JS�е�for..inѭ��������⣬��Ϊ�����Ŷ�ħ��Ĺ淶���������������ĸ������У���������Զ������κζ���졣
����һ��Ҫ�ڹؼ����ܴ���·���ϸ��ƶ���ʱ��ʹ�������һ���Զ���ġ��������캯����������ȷ�ظ���ÿ�����ԡ�����������ķ�ʽ��
function clone(original) {
this.foo = original.foo;
this.bar = original.bar;
}
var copy = new clone(original); |
ģ��ģʽ�л��溯��
ʹ��ģ��ģʽʱ���溯�������ܻᵼ�����ܷ����������������������ӣ���Ϊ�����Ǵ�����Ա�������¸������㿴���ı仯���ܻ�Ƚ�����
������ע�⣬ʹ�����ַ������Ը��ţ�������������ԭ��ģʽ������jsPerf����ȷ�ϣ���
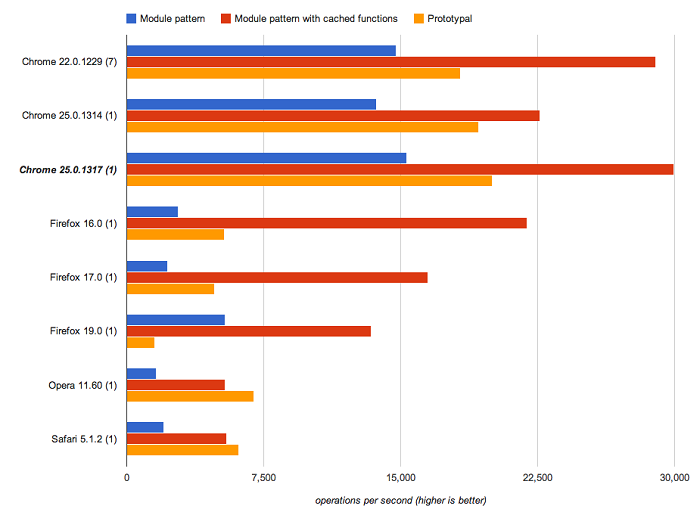
ʹ��ģ��ģʽ��ԭ��ģʽʱ����������
����һ��ԭ��ģʽ��ģ��ģʽ�����ܶԱȲ��ԣ�
// Prototypal pattern
Klass1 = function () {}
Klass1.prototype.foo = function () {
log('foo');
}
Klass1.prototype.bar = function () {
log('bar');
}
// Module pattern
Klass2 = function () {
var foo = function () {
log('foo');
},
bar = function () {
log('bar');
};
return {
foo: foo,
bar: bar
}
}
// Module pattern with cached functions
var FooFunction = function () {
log('foo');
};
var BarFunction = function () {
log('bar');
};
Klass3 = function () {
return {
foo: FooFunction,
bar: BarFunction
}
}
// Iteration tests
// Prototypal
var i = 1000,
objs = [];
while (i--) {
var o = new Klass1()
objs.push(new Klass1());
o.bar;
o.foo;
}
// Module pattern
var i = 1000,
objs = [];
while (i--) {
var o = Klass2()
objs.push(Klass2());
o.bar;
o.foo;
}
// Module pattern with cached functions
var i = 1000,
objs = [];
while (i--) {
var o = Klass3()
objs.push(Klass3());
o.bar;
o.foo;
}
// See the test for full details |
ʹ������ʱ�ļ���
������˵˵������صļ��ɡ���һ������£���Ҫɾ������Ԫ�أ�������ʹ������ɵ��������ڲ���ʾ�����������ϡ�裬V8����ʹԪ��תΪ�������ֵ�ģʽ��
����������
�����������dz����ã�������ʾVM����Ĵ�С�����͡���ͨ�������������������С�
// Here V8 can see that you want a 4-element array containing numbers:
var a = [1, 2, 3, 4];
// Don't do this:
a = []; // Here V8 knows nothing about the array
for(var i = 1; i <= 4; i++) {
a.push(i);
} |
�洢��һ����VS������
��������ͣ��������֡��ַ�����undefined��true/false�������ݴ��������о�����һ�����뷨������var
arr = [1, ��1��, undefined, true, ��true��]
1.�����ƶϵ����ܲ���
���������������Ľ�������������������ġ�
ϡ��������������
����ʹ��ϡ������ʱ��Ҫע�����Ԫ�ؽ�ԶԶ���������顣��ΪV8�������һ����ռ��ֻ�õ����ֿռ�����顣ȡ����֮���ǣ������������ֵ��У��Ƚ�Լ�˿ռ䣬�����ѷ��ʵ�ʱ�䡣
2.ϡ��������������IJ���
Ԥ����ռ�VS��̬����
��ҪԤ��������飨�����64K��Ԫ�أ��������Ĵ�С����Ӧ�ö�̬���䡣��������ƪ���µ����ܲ���֮ǰ�����ס��ֻ���ò���JavaScript���档
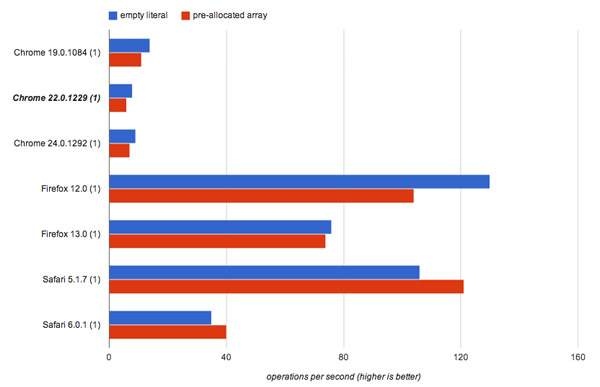
����������Ԥ���������ڲ�ͬ����������в���
Nitro (Safari)��Ԥ���������������������������棨V8��SpiderMonkey���У�Ԥ�ȷ��䲢���Ǹ�Ч�ġ�
3.Ԥ�����������
// Empty array
var arr = [];
for (var i = 0; i < 1000000; i++) {
arr[i] = i;
}
// Pre-allocated array
var arr = new Array(1000000);
for (var i = 0; i < 1000000; i++) {
arr[i] = i;
} |
�Ż����Ӧ��
��WebӦ�õ������У��ٶȾ���һ�С�û���û�ϣ����һ��Ҫ�������Ӽ���ij�����������ӻ�����Ϣ�ı���Ӧ�á�����Ϊʲô��Ҫ�ڴ�����ѹեÿһ�����ܵ���Ҫԭ��

ͼƬ��Դ: Per Olof Forsberg.
��������Ӧ�ó���������Ƿdz����õ�ͬʱ����Ҳ�����ѵġ������Ƽ����µIJ�����������ܵ�ʹ�㣺
1.������������Ӧ�ó������ҵ����ĵط���Լ45����
2.���⣺�ҳ�ʵ�ʵ�������ʲô��Լ45����
3.������ ��Լ10����
�����Ƽ���һЩ���ߺͼ�������Э���㡣
������BENCHMARKING��
�кܶʽ������JavaScript����Ƭ�εĻ����������ܡ���һ��ļ����ǣ����رȽ�����ʱ���������ģʽ��jsPerf�Ŷ�ָ��������SunSpider��Kraken�Ļ�����ʹ�ã�
var totalTime,
start = new Date,
iterations = 1000;
while (iterations--) {
// Code snippet goes here
}
// totalTime �� the number of milliseconds taken
// to execute the code snippet 1000 times
totalTime = new Date - start; |
�����Ҫ���ԵĴ��뱻������һ��ѭ���У�������һ���趨�Ĵ���������6�Σ����ڴ�֮��ʼ���ڼ�ȥ�������ڣ��͵ó���ѭ����ִ�в��������ѵ�ʱ�䡣
Ȼ�������ֻ���������������ڼ��ˣ��ر���������������ڶ��������ͻ����Ļ��������ռ��������Խ������һ��Ӱ��ġ���ʹ��ʹ��window.performance�����Ľ��������Ҳ���뿼�ǵ���Щȱ�ݡ�
�������Ƿ�ֻ���л����ֵĴ��룬��дһ���������������⣬JavaScript����ʵ��������ĸ��ࡣ�������ϸ��ָ�ϻ�����ǿ�ҽ������Ķ���Mathias
Bynens��John-David Dalton�ṩ��Javascript�����ԡ�
������PROFILING��
Chrome�����߹���ΪJavaScript�����кܺõ�֧�֡�����ʹ�ô˹��ܼ����Щ����ռ���˴�ʱ�䣬������Ϳ���ȥ�Ż����ǡ������Ҫ����ʹ�Ǵ����С�ĸı���������ֲ�����Ҫ��Ӱ�졣
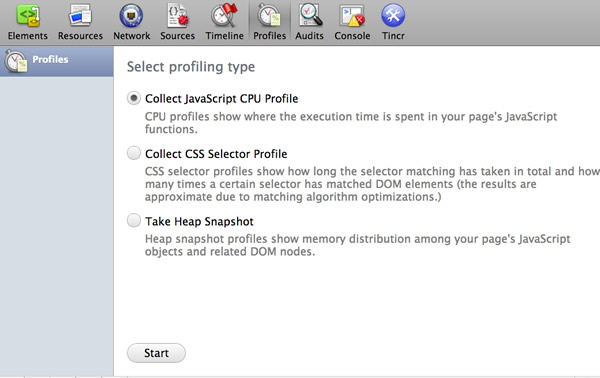
Chrome�����߹��ߵķ������
�������̿�ʼ��ȡ�������ܻ��ߣ�Ȼ����ʱ���ߵ���ʽ���֡��⽫�������Ǵ�����Ҫ�ʱ�����С���Profiles��ѡ���������һ�����õ��ӽ����˽�Ӧ�ó����з�����ʲô��JavaScript
CPU�����ļ�չʾ�˶���CPUʱ�䱻�������ǵĴ��룬CSSѡ���������ļ�չʾ�˶���ʱ�仨���ڴ���ѡ�����ϣ��ѿ�����ʾ�����ڴ������������ǵĶ���
������Щ���ߣ����ǿ��Է��롢���������·������������ǵĹ��ܻ���������Ż��Ƿ��������Ч����
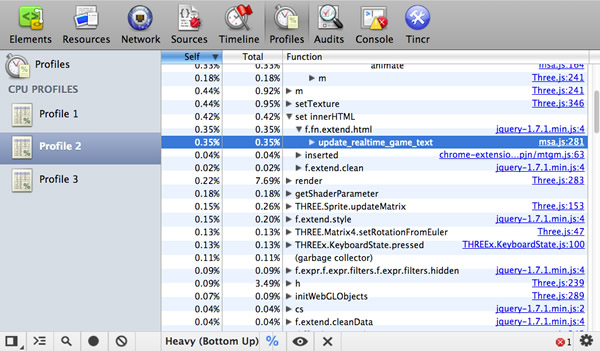
��Profile��ѡ�չʾ�˴���������Ϣ��
һ���ܺõķ������ܣ��Ķ�Zack Grossbart�� JavaScript Profiling With
The Chrome Developer Tools��
��ʾ������������£�����ȷ����ķ�����δ�ܵ��Ѱ�װ��Ӧ�ó������չ���κ�Ӱ�죬����ʹ��--user-data-dir
<empty_directory>��־������Chrome���ڴ��������£����ַ����Ż�����Ӧ�����㹻�ģ���Ҳ��Ҫ������ʱ�䡣����V8��־�����������ġ�
�����ڴ�й©����3���ռ���
�ڹȸ��ڲ���Chrome�����߹��߱�Gmail���ŶӴ���ʹ�ã������������ֺ��ų��ڴ�й©��
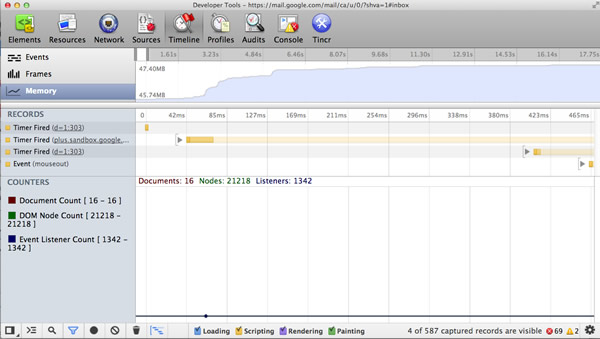
Chrome�����߹����е��ڴ�ͳ��
�ڴ�ͳ�Ƴ������Ŷ������ĵ�˽���ڴ�ʹ�á�JavaScript�ѵĴ�С��DOM�ڵ��������洢�������¼������������������ռ�����Ҫ���յĶ������Ƽ��Ķ�Loreena
Lee�ġ�3���ա��������ü�����Ҫ���ǣ������Ӧ�ó����м�¼һЩ��Ϊ��ǿ���������գ����DOM�ڵ��������û�лָ���Ԥ�ڵĻ��ߣ�Ȼ����������ѵĿ�����ȷ���Ƿ����ڴ�й©��
��ҳ��Ӧ�õ��ڴ����
��ҳ��Ӧ�ó�������AngularJS��Backbone��Ember�����ڴ�����Ƿdz���Ҫ�ģ����Ǽ�����Զ����ˢ��ҳ�档����ζ���ڴ�й©�����൱���ԡ��ƶ��ն��ϵĵ�ҳ��Ӧ�ó��������壬��Ϊ�豸���ڴ����ޣ����ڳ�������Email�ͻ��˻��罻�����Ӧ�ó������������������ء�
�кܶ�취���������⡣��Backbone�У�ȷ��ʹ��dispose()����������ͼ�����ã�Ŀǰ��Backbone(Edge)�п��ã������������������ϵģ��Ƴ����ӵ���ͼ��event�������еĴ����������Լ�ͨ������view�ĵ������������ص������ģ���model��collection���¼���������dispose()Ҳ�ᱻ��ͼ��remove()���ã�������Ԫ�ر��Ƴ�ʱ����Ҫ����������Ember
�������Ŀ��Ԫ�ر��Ƴ�ʱ���������������Ա����ڴ�й©��
Derick Bailey��һЩ���ǵĽ��飺
�����˽��¼�����������ι����ģ�������ѭ�ı�����������JavaScript�е��ڴ档�������������ݵ���һ�������û������Backbone�����У���Ҫ����������ʹ������ռ���ڴ棬�DZ���������ϵ����������Լ������ڶ�������á�һ����������õ����ã���Դ�ͻᱻ���ա�����DZ���JavaScript�������չ���
�������У�Derick����������ʹ��Backbone.jsʱ�ij����ڴ�ȱ�ݣ��Լ���ν����Щ���⡣
Felix Geisend?rfer����Node�е����ڴ�й©�Ľ̳�Ҳֵ��һ���������ǵ����γ��˸��㷺SPA��ջ��һ���֡�
���ٻ�����REFLOWS��
�������������Ⱦ�ĵ��е�Ԫ��ʱ��Ҫ ���¼������ǵ�λ�úͼ�����״�����dz�֮Ϊ�����������������û���������еIJ��������������������ʱ���Ƿdz��а����ġ�
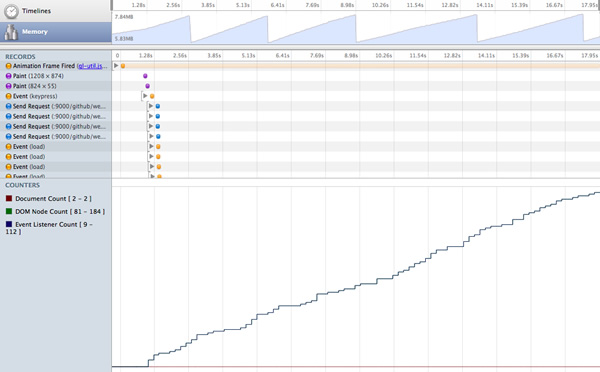
����ʱ��ͼ��
��Ӧ�������ش����������ػ棬����Ҫ���Ƶ�ʹ����Щ����������������DOMҲ����Ҫ������ʹ��DocumentFragment��һ�����������ĵ��������������Ϊһ�ַ�������ȡ�ĵ�����һ���֣���һ���µ��ĵ���Ƭ�Ρ������䲻�ϵ�����DOM�ڵ㣬����ʹ���ĵ�Ƭ�κ�ִֻ��һ��DOM����������Ա������Ļ�����
���磬����дһ��������һ��Ԫ������20��div�����ֻ�Ǽ�ÿ��appendһ��div��Ԫ���У���ᴥ��20�λ�����
function addDivs(element) {
var div;
for (var i = 0; i < 20; i ++) {
div = document.createElement('div');
div.innerHTML = 'Heya!';
element.appendChild(div);
}
} |
Ҫ���������⣬����ʹ��DocumentFragment�����棬���ǿ���ÿ������һ���µ�div�����档��ɺ�DocumentFragment���ӵ�DOM��ֻ�ᴥ��һ�λ�����
function addDivs(element) {
var div;
// Creates a new empty DocumentFragment.
var fragment = document.createDocumentFragment();
for (var i = 0; i < 20; i ++) {
div = document.createElement('a');
div.innerHTML = 'Heya!';
fragment.appendChild(div);
}
element.appendChild(fragment);
} |
JS�ڴ�й©̽����
Ϊ�˰�������JavaScript�ڴ�й©���ȸ�Ŀ�����Ա��(Marja H?ltt?��Jochen Eisinger��������һ�ֹ��ߣ�����Chrome������Ա���߽��ʹ�ã������ѵĿ��ղ�������ʲô���������ڴ�й©��
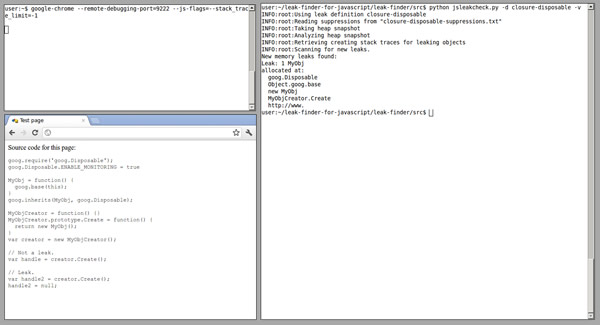
һ��JavaScript�ڴ�й©����
�����������½��������ʹ��������ߣ��������Լ����ڴ�й©̽������Ŀҳ�濴����
�������֪��Ϊʲô�����Ĺ���û���ɵ����ǵĿ������ߣ���ԭ���ж������������Closure���а������Dz�һЩ�ض����ڴ泡���������ʺ���Ϊһ���ⲿ���ߡ�
V8�Ż����Ժ��������յı�־λ
Chrome֧��ֱ��ͨ������һЩ��־��V8���Ի�ø���ϸ�������Ż������������磬����������V8���Ż���
"/Applications/Google Chrome/Google Chrome" --js-flags="--trace-opt --trace-deopt" |
Windows�û������������� chrome.exe �Cjs-flags=���Ctrace-opt �Ctrace-deopt��
�ڿ���Ӧ�ó���ʱ�������V8��־������ʹ�á�
1.trace-opt ���� ��¼�Ż����������ƣ�����ʾ�����Ĵ��룬��Ϊ�Ż�����֪������Ż���
2.trace-deopt ���� ��¼����ʱ��Ҫ��ȥ�Ż����Ĵ��롣
3.trace-gc ���� ��¼ÿ�ε��������ա�
V8�Ĵ����ű���*���Ǻţ���ʶ�Ż����ĺ�������~�����˺ţ���ʾδ�Ż��ĺ�����
���������Ȥ�˽�������V8�ı�־��V8���ڲ�����ι����ģ�ǿ�ҽ��� �Ķ�Vyacheslav Egorov��excellent
post on V8 internals��
HIGH-RESOLUTION TIME �� NAVIGATION TIMING API
�߾���ʱ�䣨HRT����һ���ṩ����ϵͳʱ����û�����Ӱ����Ǻ��뼶�߾���ʱ��ӿڣ������������DZ� new
Date �� Date.now()�����Ķ���������������DZ�д���������ܴ�
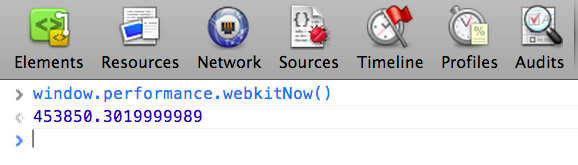
�߾���ʱ�䣨HRT���ṩ�˵�ǰ�Ǻ��뼶��ʱ�侫��
ĿǰHRT��Chrome���ȶ��棩������window.performance.webkitNow()��ʽʹ�ã�����Chrome
Canary��ǰ�������ˣ���ʹ��������ͨ��window.performance.now()��ʽ���á�Paul
Irish��HTML5Rocks���˹���HRT�������ݵ����¡�
��������֪����ǰ�ľ�ʱ�䣬���п���ȷ����ҳ�����ܵ�API�𣿺ðɣ������и�Navigation Timing
API����ʹ�ã����API�ṩ��һ�ּķ�ʽ������ȡ��ҳ�ڼ��س��ָ��û�ʱ����ȷ����ϸ��ʱ�������¼��������console��ʹ��window.performance.timing����ȡʱ����Ϣ��

��ʾ�ڿ���̨�е�ʱ����Ϣ
���ǿ��Դ���������ݻ�ȡ�ܶ����õ���Ϣ������������ʱΪresponseEnd �C fetchStart��ҳ�����ʱ��ΪloadEventEnd
�C responseEnd������������ҳ����ص�ʱ��ΪloadEventEnd �C navigationStart��
�������������ģ�perfomance.memory������Ҳ����ʾJavaScript���ڴ�����ʹ����������ܵĶѴ�С��
����Navigation Timing API��ϸ�ڣ��Ķ� Sam Dutton�� Measuring
Page Load Speed With Navigation Timing��
ABOUT:MEMORY �� ABOUT:TRACING
Chrome�е�about:tracing�ṩ���������������ͼ����¼��Chrome�������̡߳�tabҳ�ͽ��̡�
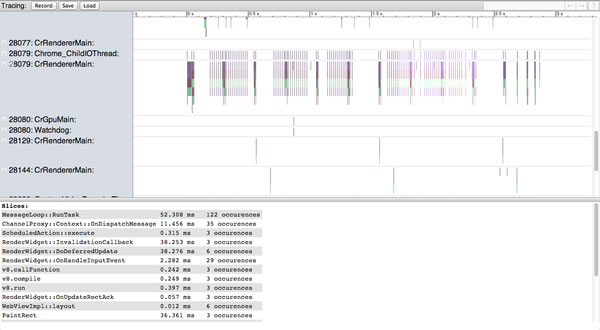
About:Tracing�ṩ���������������ͼ
������ߵ������ô��������㲶��Chrome���������ݣ�������Ϳ����ʵ��ص���JavaScriptִ�У����Ż���Դ���ء�
Lilli Thompson��һƪд����Ϸ�����ߵ�ʹ��about:tracing����WebGL��Ϸ�����£�ͬʱҲ�ʺ�JavaScript�Ŀ����ߡ�
��Chrome�ĵ��������������about:memory��ͬ��ʮ��ʵ�ã����Ի��ÿ��tabҳ���ڴ�ʹ��������Զ�λ�ڴ�й©���а�����
�ܽ�
���ǿ�����JavaScript���������кܶ����ص����壬�Ҳ�û���������ܵ�������ֻ�а�һЩ�Ż������ۺ�ʹ�õ�����ʵ���磩���Ի��������ܻ�������������档������ˣ��˽���������ν��ͺ��Ż����룬�����������Ӧ�ó���
���������⣬���������ظ�������̡�

ͼƬ��Դ: Sally Hunter
���ǹ�ע�Ż�����Ϊ�˱�����������һЩ��С���Ż������磬��Щ������ѡ��.forEach��Object.keys����for��for..inѭ����������������ʹ�ø����㡣Ҫ��֤���ѵ�ͷ�ԣ�֪��ʲô�Ż�����Ҫ�ģ�ʲô�Ż��Dz���Ҫ�ġ�
ͬʱע�⣬��ȻJavaScript����Խ��Խ�죬����һ��������ƿ����DOM���������ػ�ļ���Ҳ����Ҫ�ģ����Ա�Ҫʱ��ȥ��DOM�����о���Ҫ��ע���磬HTTP���������ģ��ر����ƶ��ն��ϣ����Ҫʹ��HTTP�Ļ���ȥ������Դ�ļ��ء�
��ס�⼸����Ա�֤���ȡ�˱��ĵĴ���Ϣ��ϣ����������������
|





