| БрМЭЦМі: |
| БОЮФРДздЭјТчЃЌБОЮФжївЊНВЪіСЫдкЧАЖЫПЊЗЂжавьГЃВЖЛёЕФЗНЗЈвдМАадФмВтЪдЃЌЭЌЪБНВНтСЫШчКЮНЋетаЉвьГЃКЭадФмЪ§ОнШчКЮЩЯБЈЁЃ |
|
ИХЪі
ЖдгкКѓЬЈПЊЗЂРДЫЕЃЌМЧТМШежОЪЧвЛжжЗЧГЃГЃМћЕФПЊЗЂЯАЙпЃЌЭЈГЃЮвУЧЛсЪЙгУ try...catchДњТыПщРДжїЖЏВЖЛёДэЮѓЁЂЖдгкУПДЮНгПкЕїгУЃЌвВЛсМЧТМЯТУПДЮНгПкЕїгУЕФЪБМфЯћКФЃЌвдБуЮвУЧМрПиЗўЮёЦїНгПкадФмЃЌНјааЮЪЬтХХВщЁЃ
ИеНјЙЋЫОЪБЃЌдкНјаа Node.jsЕФНгПкПЊЗЂЪБЃЌЮвВЛЬЋЯАЙпУПДЮХХВщЮЪЬтЖМвЊЭЈЙ§ЬјАхЛњЕЧЩЯЗўЮёЦїПДШежОЃЌКѓРДТ§Т§ЯАЙпСЫетжжЗНЪНЁЃ
ОйИіР§згЃК
/**
* ЛёШЁСаБэЪ§Он
* @parma req, res
*/
exports.getList = async function (req, res) {
//ЛёШЁЧыЧѓВЮЪ§
const openId = req.session.userinfo.openId;
logger.info(`handler getList, user openId is ${openId}`);
try {
// ФУЕНСаБэЪ§Он
const startTime = new Date().getTime();
let res = await ListService.getListFromDB(openId);
logger.info(`handler getList, ListService.getListFromDB
cost time ${new Date().getTime() - startDate}`);
// ЖдЪ§ОнДІРэЃЌЗЕЛиИјЧАЖЫ
// ...
} catch(error) {
logger.error(`handler getList is error, ${JSON.stringify(error)}`);
}
}; |
вдЯТДњТыОГЃЛсГіЯждкгУ Node.jsЕФНгПкжаЃЌдкНгПкжаЛсЭГМЦВщбЏ DBЫљКФЪБМфЁЂврЛђЪЧЭГМЦ RPCЗўЮёЕїгУЫљКФЪБМфЃЌвдБуМрВтадФмЦПОБЃЌЖдадФмзігХЛЏЃЛгжЛђЪЧЖдвьГЃЪЙгУ
try ... catchжїЖЏВЖЛёЃЌвдБуЫцЪБЖдЮЪЬтНјааЛиЫнЁЂЛЙдЮЪЬтЕФГЁОАЃЌНјаа bugЕФаоИДЁЃ
ЖјЖдгкЧАЖЫРДЫЕФиЃППЩвдПДвдЯТЕФГЁОАЁЃ
зюНќдкНјаавЛИіашЧѓПЊЗЂЪБЃЌХМЖћЗЂЯж webglфжШОгАЯёЪЇАмЕФЧщПіЃЌЛђепЫЕгАЯёЛсГіЯжНтЮіЪЇАмЕФЧщПіЃЌЮвУЧПЩФмИљБОВЛжЊЕРФФеХгАЯёЛсНтЮіЛђфжШОЪЇАмЃЛгжЛђШчзюНќПЊЗЂЕФСэЭтвЛИіашЧѓЃЌЮвУЧЛсзівЛИіЙигк
webglфжШОЪБМфЕФгХЛЏКЭгАЯёдЄМгдиЕФашЧѓЃЌШчЙћШБЗІадФмМрПиЃЌИУШчКЮЭГМЦЫљзіЕФфжШОгХЛЏКЭгАЯёдЄМгдигХЛЏЕФгХЛЏБШР§ЃЌШчКЮжЄУїздМКЫљзіЕФЪТЧщОпгаМлжЕФиЃППЩФмЪЧЭЈЙ§ВтЪдЭЌбЇЕФКкКаВтЪдЃЌЖдгХЛЏЧАКѓЕФЪБМфНјааТМЦСЃЌЗжЮіДгНјШывГУцЕНгАЯёфжШОЭъГЩЕНЕзОЙ§СЫЖрЩйжЁЭМЯёЁЃетбљЕФЪ§ОнЃЌПЩФмМШВЛзМШЗЁЂгжНЯЮЊЦЌУцЃЌЩшЯыВтЪдЭЌбЇВЂВЛЪЧеце§ЕФгУЛЇЃЌвВЮоЗЈЛЙдецЪЕЕФгУЛЇЫћУЧЫљДІЕФЭјТчЛЗОГЁЃЛиЙ§ЭЗРДЗЂЯжЃЌЮвУЧЕФЯюФПЃЌЫфШЛдкЗўЮёЖЫВуУцзіКУСЫШежОКЭадФмЭГМЦЃЌЕЋдкЧАЖЫЖдвьГЃЕФМрПиКЭадФмЕФЭГМЦЁЃЖдгкЧАЖЫЕФадФмгывьГЃЩЯБЈЕФПЩааадЬНЫїЪЧгаБивЊЕФЁЃ
вьГЃВЖЛё
ЖдгкЧАЖЫРДЫЕЃЌЮвУЧашвЊЕФвьГЃВЖЛёЮоЗЧЮЊвдЯТСНжжЃК
НгПкЕїгУЧщПіЃЛ
вГУцТпМЪЧЗёДэЮѓЃЌР§ШчЃЌгУЛЇНјШывГУцКѓвГУцЯдЪОАзЦСЃЛ
ЖдгкНгПкЕїгУЧщПіЃЌдкЧАЖЫЭЈГЃашвЊЩЯБЈПЭЛЇЖЫЯрЙиВЮЪ§ЃЌР§ШчЃКгУЛЇOSгыфЏРРЦїАцБОЁЂЧыЧѓВЮЪ§ЃЈШчвГУцIDЃЉЃЛЖјЖдгквГУцТпМЪЧЗёДэЮѓЮЪЬтЃЌЭЈГЃГ§СЫгУЛЇOSгыфЏРРЦїАцБОЭтЃЌашвЊЕФЪЧБЈДэЕФЖбеЛаХЯЂМАОпЬхБЈДэЮЛжУЁЃ
вьГЃВЖЛёЗНЗЈ
ШЋОжВЖЛё
ПЩвдЭЈЙ§ШЋОжМрЬ§вьГЃРДВЖЛёЃЌЭЈЙ§ window.onerrorЛђеп addEventListenerЃЌПДвдЯТР§згЃК
window.onerror
= function(errorMessage, scriptURI, lineNo, columnNo,
error) {
console.log('errorMessage: ' + errorMessage);
// вьГЃаХЯЂ
console.log('scriptURI: ' + scriptURI); // вьГЃЮФМўТЗОЖ
console.log('lineNo: ' + lineNo); // вьГЃааКХ
console.log('columnNo: ' + columnNo); // вьГЃСаКХ
console.log('error: ' + error); // вьГЃЖбеЛаХЯЂ
// ...
// вьГЃЩЯБЈ
};
throw new Error('етЪЧвЛИіДэЮѓ'); |
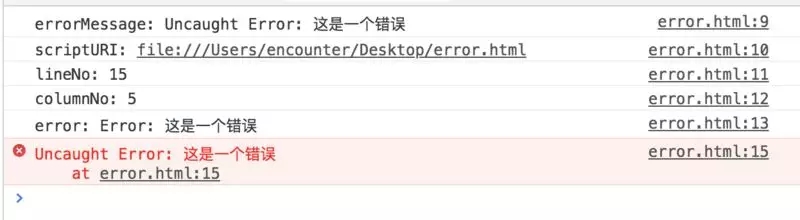
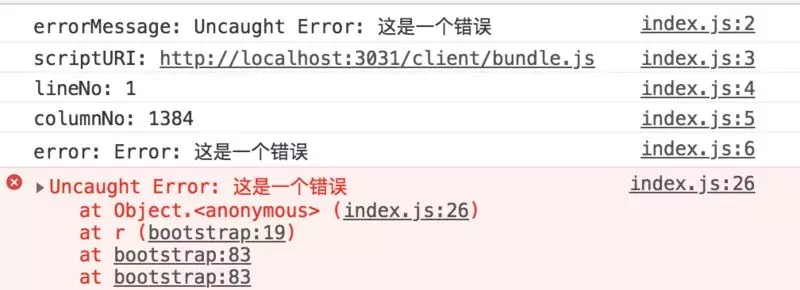
ЭЈЙ§ window.onerrorЪТМўЃЌПЩвдЕУЕНОпЬхЕФвьГЃаХЯЂЁЂвьГЃЮФМўЕФURLЁЂвьГЃЕФааКХгыСаКХМАвьГЃЕФЖбеЛаХЯЂЃЌдйВЖЛёвьГЃКѓЃЌЭГвЛЩЯБЈжСЮвУЧЕФШежОЗўЮёЦїЁЃ
врЛђЪЧЃЌЭЈЙ§ window.addEventListenerЗНЗЈРДНјаавьГЃЩЯБЈЃЌЕРРэЭЌРэЃК
window.addEventListener('error',
function() {
console.log(error);
// ...
// вьГЃЩЯБЈ
});
throw new Error('етЪЧвЛИіДэЮѓ'); |
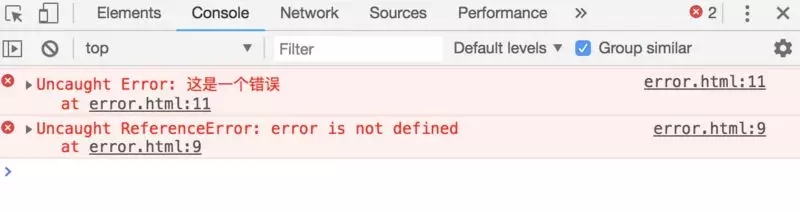
try... catch
ЪЙгУ try... catchЫфШЛФмЙЛНЯКУЕиНјаавьГЃВЖЛёЃЌВЛжСгкЪЙЕУвГУцгЩгквЛДІДэЮѓЙвЕєЃЌЕЋ try
... catchВЖЛёЗНЪНЯдЕУЙ§гкгЗжзЃЌДѓЖрДњТыЪЙгУ try ...catchАќЙќЃЌгАЯьДњТыПЩЖСадЁЃ
ГЃМћЮЪЬт
ПчгђНХБОЮоЗЈзМШЗВЖЛёвьГЃ
ЭЈГЃЧщПіЯТЃЌЮвУЧЛсАбОВЬЌзЪдДЃЌШч JavaScriptНХБОЗХЕНзЈУХЕФОВЬЌзЪдДЗўЮёЦїЃЌврЛђеп CDNЃЌПДвдЯТР§згЃК
<!DOCTYPE
html>
<html>
<head>
<title></title>
</head>
<body>
<script type="text/javascript">
// дкindex.html
window.onerror = function(errorMessage, scriptURI,
lineNo, columnNo, error) {
console.log('errorMessage: ' + errorMessage);
// вьГЃаХЯЂ
console.log('scriptURI: ' + scriptURI); // вьГЃЮФМўТЗОЖ
console.log('lineNo: ' + lineNo); // вьГЃааКХ
console.log('columnNo: ' + columnNo); // вьГЃСаКХ
console.log('error: ' + error); // вьГЃЖбеЛаХЯЂ
// ...
// вьГЃЩЯБЈ
};
</script>
<script src="./error.js"></script>
</body>
</html> |
// error.js
throw new Error('етЪЧвЛИіДэЮѓ'); |
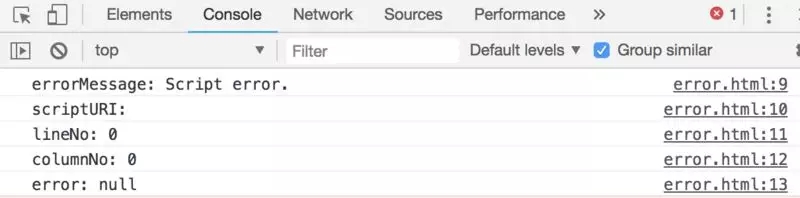
НсЙћЯдЪОЃЌПчгђжЎКѓ window.onerrorИљБОВЖЛёВЛЕНе§ШЗЕФвьГЃаХЯЂЃЌЖјЪЧЭГвЛЗЕЛивЛИі Script
errorЃЌ
НтОіЗНАИЃКЖд scriptБъЧЉдіМгвЛИі crossorigin=ЁБanonymousЁБЃЌВЂЧвЗўЮёЦїЬэМг
Access-Control-Allow-OriginЁЃ
| <script src="http://cdn.xxx.com/index.js"
crossorigin="anonymous"></script> |
sourceMap
ЭЈГЃдкЩњВњЛЗОГЯТЕФДњТыЪЧОЙ§ webpackДђАќКѓбЙЫѕЛьЯ§ЕФДњТыЃЌЫљвдЮвУЧПЩФмЛсгіЕНетбљЕФЮЪЬтЃЌШчЭМЫљЪОЃК
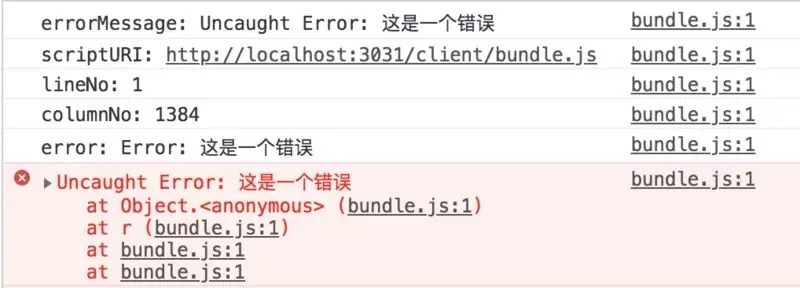
ЮвУЧЗЂЯжЫљгаЕФБЈДэЕФДњТыааЪ§ЖМдкЕквЛааСЫЃЌЮЊЪВУДФиЃПетЪЧвђЮЊдкЩњВњЛЗОГЯТЃЌЮвУЧЕФДњТыБЛбЙЫѕГЩСЫвЛааЃК
!function(e){var
n={};function r(o){if(n[o])return
n[o].exports;var
t=n[o]={i:o,l:!1,exports:{}};return
e[o].call(t.exports,t,t.exports,r),t.l=!0,t.exports}
r.m=e,r.c=n,r.d=function(e,n,o){r.o(e,n)||
Object.defineProperty(e,n,{enumerable:!0,get:o})},
r.r=function(e){"undefined"!=typeof
Symbol&&
Symbol.toStringTag&&Object.defineProperty
(e,Symbol.toStringTag,{value:"Module"}),Object.defineProperty
(e,"__esModule",{value:!0})},r.t=function(e,n)
{if(1&n&&(e=r(e)),8&n)return
e;if(4&n&&"object"==typeof
e&&e&&e.__esModule)return e;var
o=Object.create(null);
if(r.r(o),Object.defineProperty(o,"default",
{enumerable:!0,value:e}),2&n&&"string"!=typeof
e)for(var t in e)r.d(o,t,function(n){return e[n]}.bind(null,t));
return
o},r.n=function(e){var n=e&&e.__esModule?function(){return
e.default}:function(){return e};return r.d(n,"a",n),n},r.o
=function(e,n){return
Object.prototype.hasOwnProperty.call(e,n)}
,r.p="",r(r.s=0)}([function(e,n){throw
window.onerror=function(e,n,r,o,t){console.log("errorMessage:
"+e),console.log("scriptURI: "+n),console.log("lineNo:
"+r),console.log("columnNo: "+o),console.log("error:
"+t);var l={errorMessage:e||null,scriptURI:n||null,
lineNo:r||null,columnNo:o||null,stack:t&&t.stack?t.stack:null};
if(XMLHttpRequest){var
u=new XMLHttpRequest;
u.open("post","/middleware/errorMsg",!0),
u.setRequestHeader("Content-Type","application/json"),
u.send(JSON.stringify(l))}},new
Error("етЪЧвЛИіДэЮѓ")}]); |
дкЮвЕФПЊЗЂЙ§ГЬжавВгіЕНЙ§етИіЮЪЬтЃЌЮвдкПЊЗЂвЛИіЙІФмзщМўПтЕФЪБКђЃЌЪЙгУ npm linkСЫЮвЕФзщМўПтЃЌЕЋЪЧгЩгкзщМўПтБЛ
npm linkКѓЪЧДђАќКѓЕФЩњВњЛЗОГЯТЕФДњТыЃЌЫљгаЕФБЈДэЖМЖЈЮЛЕНСЫЕквЛааЁЃ
НтОіАьЗЈЪЧПЊЦє webpackЕФ source-mapЃЌЮвУЧРћгУ webpackДђАќКѓЕФЩњГЩЕФвЛЗн
.mapЕФНХБОЮФМўОЭПЩвдШУфЏРРЦїЖдДэЮѓЮЛжУНјаазЗзйСЫЁЃДЫДІПЩвдВЮПМwebpack documentЁЃ
ЦфЪЕОЭЪЧ webpack.config.jsжаМгЩЯвЛаа devtool: 'source-map'ЃЌШчЯТЫљЪОЃЌЮЊЪОР§ЕФ
webpack.config.jsЃК
var path = require('path');
module.exports = {
devtool: 'source-map',
mode: 'development',
entry: './client/index.js',
output: {
filename: 'bundle.js',
path: path.resolve(__dirname, 'client')
}
} |
дк webpackДђАќКѓЩњГЩЖдгІЕФ source-mapЃЌетбљфЏРРЦїОЭФмЙЛЖЈЮЛЕНОпЬхДэЮѓЕФЮЛжУЃК
ПЊЦє source-mapЕФШБЯнЪЧМцШнадЃЌФПЧАжЛга ChromeфЏРРЦїКЭ FirefoxфЏРРЦїВХЖд
source-mapжЇГжЁЃВЛЙ§ЮвУЧЖдетвЛРрЧщПівВгаНтОіАьЗЈЁЃПЩвдЪЙгУв§Шы npmПтРДжЇГж source-mapЃЌПЩвдВЮПМmozilla/source-mapЁЃетИі
npmПтМШПЩвддЫаадкПЭЛЇЖЫвВПЩвддЫаадкЗўЮёЖЫЃЌВЛЙ§ИќЮЊЭЦМіЕФЪЧдкЗўЮёЖЫЪЙгУ Node.jsЖдНгЪеЕНЕФШежОаХЯЂЪБЪЙгУ
source-mapНтЮіЃЌвдБмУтдДДњТыЕФаЙТЖдьГЩЗчЯеЃЌШчЯТДњТыЫљЪОЃК
const express
= require('express');
const fs = require('fs');
const router = express.Router();
const sourceMap = require('source-map');
const path = require('path');
const resolve = file => path.resolve(__dirname,
file);
// ЖЈвхpostНгПк
router.get('/error/', async function(req, res)
{
// ЛёШЁЧАЖЫДЋЙ§РДЕФБЈДэЖдЯѓ
let error = JSON.parse(req.query.error);
let url = error.scriptURI; // бЙЫѕЮФМўТЗОЖ
if (url) {
let fileUrl = url.slice(url.indexOf('client/'))
+ '.map'; // mapЮФМўТЗОЖ
// НтЮіsourceMap
let consumer = await new sourceMap.SourceMapConsumer(fs.readFileSync(resolve('../'
+ fileUrl), 'utf8')); // ЗЕЛивЛИіpromiseЖдЯѓ
// НтЮідЪМБЈДэЪ§Он
let result = consumer.originalPositionFor({
line: error.lineNo, // бЙЫѕКѓЕФааКХ
column: error.columnNo // бЙЫѕКѓЕФСаКХ
});
console.log(result);
}
});
module.exports = router; |
ШчЯТЭМЫљЪОЃЌЮвУЧвбОПЩвдПДЕНЃЌдкЗўЮёЖЫвбОГЩЙІНтЮіГіСЫОпЬхДэЮѓЕФааКХЁЂСаКХЃЌЮвУЧПЩвдЭЈЙ§ШежОЕФЗНЪННјааМЧТМЃЌДяЕНСЫЧАЖЫвьГЃМрПиЕФФПЕФЁЃ
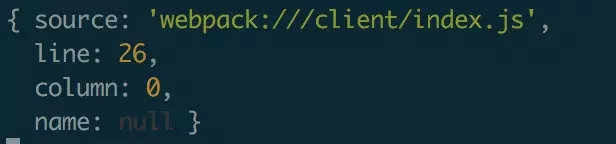
VueВЖЛёвьГЃ
дкЮвЕФЯюФПжаОЭгіЕНетбљЕФЮЪЬтЃЌЪЙгУСЫ js-trackerетбљЕФВхМўРДЭГвЛНјааШЋОжЕФвьГЃВЖЛёКЭШежОЩЯБЈЃЌНсЙћЗЂЯжЮвУЧИљБОВЖЛёВЛЕН
VueзщМўЕФвьГЃЃЌВщдФзЪСЯЕУжЊЃЌдк VueжаЃЌвьГЃПЩФмБЛ VueздЩэИј try ... catchСЫЃЌВЛЛсДЋЕН
window.onerrorЪТМўДЅЗЂЃЌФЧУДЮвУЧШчКЮАб VueзщМўжаЕФвьГЃзїЭГвЛВЖЛёФиЃП
ЪЙгУVue.config.errorHandlerетбљЕФ VueШЋОжХфжУЃЌПЩвддк VueжИЖЈзщМўЕФфжШОКЭЙлВьЦкМфЮДВЖЛёДэЮѓЕФДІРэКЏЪ§ЁЃетИіДІРэКЏЪ§БЛЕїгУЪБЃЌПЩЛёШЁДэЮѓаХЯЂКЭ
Vue ЪЕР§ЁЃ
Vue.config.errorHandler
= function (err, vm, info) {
// handle error
// `info` ЪЧ Vue ЬиЖЈЕФДэЮѓаХЯЂЃЌБШШчДэЮѓЫљдкЕФЩњУќжмЦкЙГзг
// жЛдк 2.2.0+ ПЩгУ
} |
дк ReactжаЃЌПЩвдЪЙгУ ErrorBoundaryзщМўАќРЈвЕЮёзщМўЕФЗНЪННјаавьГЃВЖЛёЃЌХфКЯ React
16.0+аТГіЕФ componentDidCatch APIЃЌПЩвдЪЕЯжЭГвЛЕФвьГЃВЖЛёКЭШежОЩЯБЈЁЃ
class ErrorBoundary
extends React.Component {
constructor(props) {
super(props);
this.state = { hasError: false };
}
componentDidCatch(error, info) {
// Display fallback UI
this.setState({ hasError: true });
// You can also log the error to an error reporting
service
logErrorToMyService(error, info);
}
render() {
if (this.state.hasError) {
// You can render any custom fallback UI
return <h1>Something went wrong.</h1>;
}
return this.props.children;
}
} |
ЪЙгУЗНЪНШчЯТЃК
<ErrorBoundary>
<MyWidget />
</ErrorBoundary> |
адФмМрПи
зюМђЕЅЕФадФмМрПи
зюГЃМћЕФадФмМрПиашЧѓдђЪЧашвЊЮвУЧЭГМЦгУЛЇДгПЊЪМЧыЧѓвГУцЕНЫљга DOMдЊЫифжШОЭъГЩЕФЪБМфЃЌвВОЭЪЧЫзГЦЕФЪзЦСМгдиЪБМфЃЌ
DOMЬсЙЉСЫетвЛНгПкЃЌМрЬ§ documentЕФ DOMContentLoadedЪТМўгы windowЕФ
loadЪТМўПЩЭГМЦвГУцЪзЦСМгдиЪБМфМДЫљга DOMфжШОЪБМфЃК
<!DOCTYPE
html>
<html>
<head>
<title></title>
<script type="text/javascript">
// МЧТМвГУцМгдиПЊЪМЪБМф
var timerStart = Date.now();
</script>
<!-- МгдиОВЬЌзЪдДЃЌШчбљЪНзЪдД -->
</head>
<body>
<!-- МгдиОВЬЌJSзЪдД -->
<script
type="text/javascript">
document.addEventListener('DOMContentLoaded',
function() {
console.log("DOM ЙвдиЪБМф: ", Date.now()
- timerStart);
// адФмШежОЩЯБЈ
});
window.addEventListener('load', function() {
console.log("ЫљгазЪдДМгдиЭъГЩЪБМф: ", Date.now()-timerStart);
// адФмШежОЩЯБЈ
});
</script>
</body>
</html> |
ЖдгкЪЙгУПђМмЃЌШч VueЛђепЫЕ ReactЃЌзщМўЪЧвьВНфжШОШЛКѓЙвдиЕН DOMЕФЃЌдквГУцГѕЪМЛЏЪБВЂУЛгаЬЋЖрЕФ
DOMНкЕуЃЌПЩвдВЮПМЯТЮФЙигкЪзЦСЪБМфВЩМЏздЖЏЛЏЕФНтОіЗНАИРДЖдфжШОЪБМфНјааДђЕуЁЃ
performance
ЕЋЪЧвдЩЯЪБМфЕФМрПиЙ§гкДжТдЃЌР§ШчЮвУЧЯыЭГМЦЮФЕЕЕФЭјТчМгдиКФЪБЁЂНтЮі DOMЕФКФЪБгыфжШО DOMЕФКФЪБЃЌОЭВЛЬЋКУАьЕНСЫЃЌЫљавЕФЪЧфЏРРЦїЬсЙЉСЫ
window.performanceНгПкЃЌОпЬхПЩМћMDNЮФЕЕ
МИКѕЫљгафЏРРЦїЖМжЇГж window.performanceНгПкЃЌЯТУцРДПДПДдкПижЦЬЈДђгЁ window.performanceПЩвдЕУЕНаЉЪВУДЃК

ПЩвдПДЕНЃЌ window,performanceжївЊАќРЈга memoryЁЂ navigationЁЂ
timingвдМА timeOriginМА onresourcetimingbufferfullЗНЗЈЁЃ
navigationЖдЯѓЬсЙЉСЫдкжИЖЈЕФЪБМфЖЮРяЗЂЩњЕФВйзїЯрЙиаХЯЂЃЌАќРЈвГУцЪЧМгдиЛЙЪЧЫЂаТЁЂЗЂЩњСЫЖрЩйДЮжиЖЈЯђЕШЕШЁЃ
timingЖдЯѓАќКЌбгГйЯрЙиЕФадФмаХЯЂЁЃетЪЧЮвУЧвГУцМгдиадФмгХЛЏашЧѓжажївЊЩЯБЈЕФЯрЙиаХЯЂЁЃ
memoryЮЊ ChromeЬэМгЕФвЛИіЗЧБъзМРЉеЙЃЌетИіЪєадЬсЙЉСЫвЛИіПЩвдЛёШЁЕНЛљБОФкДцЪЙгУЧщПіЕФЖдЯѓЁЃдкЦфЫќфЏРРЦїгІИУПМТЧЕНетИі
APIЕФМцШнДІРэЁЃ
timeOriginдђЗЕЛиадФмВтСППЊЪМЪБЕФЪБМфЕФИпОЋЖШЪБМфДСЁЃШчЭМЫљЪОЃЌОЋШЗЕНСЫаЁЪ§ЕуКѓЫФЮЛЁЃ
onresourcetimingbufferfullЗНЗЈЃЌЫќЪЧвЛИідк resourcetimingbufferfullЪТМўДЅЗЂЪБЛсБЛЕїгУЕФ
event handlerЁЃетИіЪТМўЕБфЏРРЦїЕФзЪдДЪБМфадФмЛКГхЧјвбТњЪБЛсДЅЗЂЁЃПЩвдЭЈЙ§МрЬ§етвЛЪТМўДЅЗЂРДдЄЙРвГУц
crashЃЌЭГМЦвГУц crashИХТЪЃЌвдБуКѓЦкЕФадФмгХЛЏЃЌШчЯТЪОР§ЫљЪОЃК
function buffer_full(event)
{
console.log("WARNING: Resource Timing Buffer
is FULL!");
performance.setResourceTimingBufferSize(200);
}
function init() {
// Set a callback if the resource buffer becomes
filled
performance.onresourcetimingbufferfull = buffer_full;
}
<body onload="init()"> |
МЦЫуЭјеОадФм
ЪЙгУ performanceЕФ timingЪєадЃЌПЩвдФУЕНвГУцадФмЯрЙиЕФЪ§ОнЃЌетРядкКмЖрЮФеТЖМгаЬсЕНЙигкРћгУ
window.performance.timingМЧТМвГУцадФмЕФЮФеТЃЌР§Шч alloyteamЭХЖгаДЕФГѕЬН
performance ЈC МрПиЭјвГгыГЬађадФмЃЌЖдгк timingЕФИїЯюЪєадКЌвхЃЌПЩвдНшжњеЊздДЫЮФЕФЯТЭМРэНтЃЌвдЯТДњТыеЊздДЫЮФзїЮЊМЦЫуЭјеОадФмЕФЙЄОпКЏЪ§ВЮПМЃК
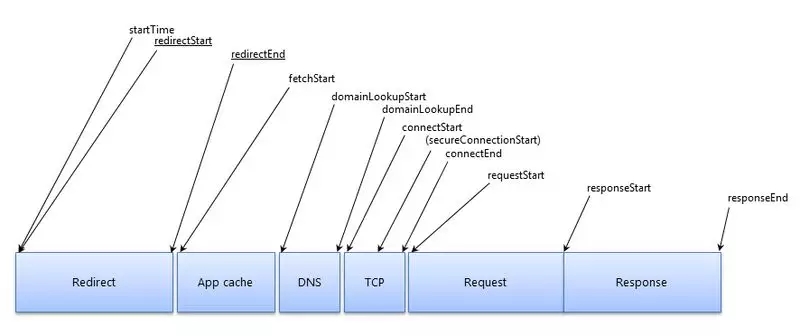
// ЛёШЁ performance
Ъ§Он
var performance = {
// memory ЪЧЗЧБъзМЪєадЃЌжЛдк Chrome га
// ВЦИЛЮЪЬтЃКЮвгаЖрЩйФкДц
memory: {
usedJSHeapSize: 16100000, // JS ЖдЯѓЃЈАќРЈV8в§ЧцФкВПЖдЯѓЃЉеМгУЕФФкДцЃЌвЛЖЈаЁгк
totalJSHeapSize
totalJSHeapSize: 35100000, // ПЩЪЙгУЕФФкДц
jsHeapSizeLimit: 793000000 // ФкДцДѓаЁЯожЦ
},
// ембЇЮЪЬтЃКЮвДгФФРяРДЃП
navigation: {
redirectCount: 0, // ШчЙћгажиЖЈЯђЕФЛАЃЌвГУцЭЈЙ§МИДЮжиЖЈЯђЬјзЊЖјРД
type: 0 // 0 МД TYPE_NAVIGATENEXT е§ГЃНјШыЕФвГУцЃЈЗЧЫЂаТЁЂЗЧжиЖЈЯђЕШЃЉ
// 1 МД TYPE_RELOAD ЭЈЙ§ window.location.reload()
ЫЂаТЕФвГУц
// 2 МД TYPE_BACK_FORWARD ЭЈЙ§фЏРРЦїЕФЧАНјКѓЭЫАДХЅНјШыЕФвГУцЃЈРњЪЗМЧТМЃЉ
// 255 МД TYPE_UNDEFINED ЗЧвдЩЯЗНЪННјШыЕФвГУц
},
timing: {
// дкЭЌвЛИіфЏРРЦїЩЯЯТЮФжаЃЌЧАвЛИіЭјвГЃЈгыЕБЧАвГУцВЛвЛЖЈЭЌгђЃЉunload ЕФЪБМфДСЃЌШчЙћЮоЧАвЛИіЭјвГ
unload ЃЌдђгы fetchStart жЕЯрЕШ
navigationStart: 1441112691935,
// ЧАвЛИіЭјвГЃЈгыЕБЧАвГУцЭЌгђЃЉunload ЕФЪБМфДСЃЌШчЙћЮоЧАвЛИіЭјвГ unload
ЛђепЧАвЛИіЭјвГгыЕБЧАвГУцВЛЭЌгђЃЌдђжЕЮЊ 0
unloadEventStart: 0,
// КЭ unloadEventStart ЯрЖдгІЃЌЗЕЛиЧАвЛИіЭјвГ unload ЪТМўАѓЖЈЕФЛиЕїКЏЪ§жДааЭъБЯЕФЪБМфДС
unloadEventEnd: 0,
// ЕквЛИі HTTP жиЖЈЯђЗЂЩњЪБЕФЪБМфЁЃгаЬјзЊЧвЪЧЭЌгђУћФкЕФжиЖЈЯђВХЫуЃЌЗёдђжЕЮЊ
0
redirectStart: 0,
// зюКѓвЛИі HTTP жиЖЈЯђЭъГЩЪБЕФЪБМфЁЃгаЬјзЊЧвЪЧЭЌгђУћФкВПЕФжиЖЈЯђВХЫуЃЌЗёдђжЕЮЊ
0
redirectEnd: 0,
// фЏРРЦїзМБИКУЪЙгУ HTTP ЧыЧѓзЅШЁЮФЕЕЕФЪБМфЃЌетЗЂЩњдкМьВщБОЕиЛКДцжЎЧА
fetchStart: 1441112692155,
// DNS гђУћВщбЏПЊЪМЕФЪБМфЃЌШчЙћЪЙгУСЫБОЕиЛКДцЃЈМДЮо DNS ВщбЏЃЉЛђГжОУСЌНгЃЌдђгы
fetchStart жЕЯрЕШ
domainLookupStart: 1441112692155,
// DNS гђУћВщбЏЭъГЩЕФЪБМфЃЌШчЙћЪЙгУСЫБОЕиЛКДцЃЈМДЮо DNS ВщбЏЃЉЛђГжОУСЌНгЃЌдђгы
fetchStart жЕЯрЕШ
domainLookupEnd: 1441112692155,
// HTTPЃЈTCPЃЉ ПЊЪМНЈСЂСЌНгЕФЪБМфЃЌШчЙћЪЧГжОУСЌНгЃЌдђгы fetchStart
жЕЯрЕШ
// зЂвтШчЙћдкДЋЪфВуЗЂЩњСЫДэЮѓЧвжиаТНЈСЂСЌНгЃЌдђетРяЯдЪОЕФЪЧаТНЈСЂЕФСЌНгПЊЪМЕФЪБМф
connectStart: 1441112692155,
// HTTPЃЈTCPЃЉ ЭъГЩНЈСЂСЌНгЕФЪБМфЃЈЭъГЩЮеЪжЃЉЃЌШчЙћЪЧГжОУСЌНгЃЌдђгы fetchStart
жЕЯрЕШ
// зЂвтШчЙћдкДЋЪфВуЗЂЩњСЫДэЮѓЧвжиаТНЈСЂСЌНгЃЌдђетРяЯдЪОЕФЪЧаТНЈСЂЕФСЌНгЭъГЩЕФЪБМф
// зЂвтетРяЮеЪжНсЪјЃЌАќРЈАВШЋСЌНгНЈСЂЭъГЩЁЂSOCKS ЪкШЈЭЈЙ§
connectEnd: 1441112692155,
// HTTPS СЌНгПЊЪМЕФЪБМфЃЌШчЙћВЛЪЧАВШЋСЌНгЃЌдђжЕЮЊ 0
secureConnectionStart: 0,
// HTTP ЧыЧѓЖСШЁецЪЕЮФЕЕПЊЪМЕФЪБМфЃЈЭъГЩНЈСЂСЌНгЃЉЃЌАќРЈДгБОЕиЖСШЁЛКДц
// СЌНгДэЮѓжиСЌЪБЃЌетРяЯдЪОЕФвВЪЧаТНЈСЂСЌНгЕФЪБМф
requestStart: 1441112692158,
// HTTP ПЊЪМНгЪеЯьгІЕФЪБМфЃЈЛёШЁЕНЕквЛИізжНкЃЉЃЌАќРЈДгБОЕиЖСШЁЛКДц
responseStart: 1441112692686,
// HTTP ЯьгІШЋВПНгЪеЭъГЩЕФЪБМфЃЈЛёШЁЕНзюКѓвЛИізжНкЃЉЃЌАќРЈДгБОЕиЖСШЁЛКДц
responseEnd: 1441112692687,
// ПЊЪМНтЮіфжШО DOM ЪїЕФЪБМфЃЌДЫЪБ Document.readyState
БфЮЊ loadingЃЌВЂНЋХзГі readystatechange ЯрЙиЪТМў
domLoading: 1441112692690,
// ЭъГЩНтЮі DOM ЪїЕФЪБМфЃЌDocument.readyState БфЮЊ interactiveЃЌВЂНЋХзГі
readystatechange ЯрЙиЪТМў
// зЂвтжЛЪЧ DOM ЪїНтЮіЭъГЩЃЌетЪБКђВЂУЛгаПЊЪММгдиЭјвГФкЕФзЪдД
domInteractive: 1441112693093,
// DOM НтЮіЭъГЩКѓЃЌЭјвГФкзЪдДМгдиПЊЪМЕФЪБМф
// дк DOMContentLoaded ЪТМўХзГіЧАЗЂЩњ
domContentLoadedEventStart: 1441112693093,
// DOM НтЮіЭъГЩКѓЃЌЭјвГФкзЪдДМгдиЭъГЩЕФЪБМфЃЈШч JS НХБОМгдижДааЭъБЯЃЉ
domContentLoadedEventEnd: 1441112693101,
// DOM ЪїНтЮіЭъГЩЃЌЧвзЪдДвВзМБИОЭаїЕФЪБМфЃЌDocument.readyState
БфЮЊ completeЃЌВЂНЋХзГі readystatechange ЯрЙиЪТМў
domComplete: 1441112693214,
// load ЪТМўЗЂЫЭИјЮФЕЕЃЌвВМД load ЛиЕїКЏЪ§ПЊЪМжДааЕФЪБМф
// зЂвтШчЙћУЛгаАѓЖЈ load ЪТМўЃЌжЕЮЊ 0
loadEventStart: 1441112693214,
// load ЪТМўЕФЛиЕїКЏЪ§жДааЭъБЯЕФЪБМф
loadEventEnd: 1441112693215
// зжФИЫГађ
// connectEnd: 1441112692155,
// connectStart: 1441112692155,
// domComplete: 1441112693214,
// domContentLoadedEventEnd: 1441112693101,
// domContentLoadedEventStart: 1441112693093,
// domInteractive: 1441112693093,
// domLoading: 1441112692690,
// domainLookupEnd: 1441112692155,
// domainLookupStart: 1441112692155,
// fetchStart: 1441112692155,
// loadEventEnd: 1441112693215,
// loadEventStart: 1441112693214,
// navigationStart: 1441112691935,
// redirectEnd: 0,
// redirectStart: 0,
// requestStart: 1441112692158,
// responseEnd: 1441112692687,
// responseStart: 1441112692686,
// secureConnectionStart: 0,
// unloadEventEnd: 0,
// unloadEventStart: 0
}
}; |
// МЦЫуМгдиЪБМф
function getPerformanceTiming() {
var performance = window.performance;
if (!performance) {
// ЕБЧАфЏРРЦїВЛжЇГж
console.log('ФуЕФфЏРРЦїВЛжЇГж performance НгПк');
return;
}
var t = performance.timing;
var times = {};
//ЁОживЊЁПвГУцМгдиЭъГЩЕФЪБМф
//ЁОдвђЁПетМИКѕДњБэСЫгУЛЇЕШД§вГУцПЩгУЕФЪБМф
times.loadPage = t.loadEventEnd - t.navigationStart;
//ЁОживЊЁПНтЮі DOM ЪїНсЙЙЕФЪБМф
//ЁОдвђЁПЗДЪЁЯТФуЕФ DOM ЪїЧЖЬзЪЧВЛЪЧЬЋЖрСЫЃЁ
times.domReady = t.domComplete - t.responseEnd;
//ЁОживЊЁПжиЖЈЯђЕФЪБМф
//ЁОдвђЁПОмОјжиЖЈЯђЃЁБШШчЃЌhttp://example.com/ ОЭВЛИУаДГЩ http://example.com
times.redirect = t.redirectEnd - t.redirectStart;
//ЁОживЊЁПDNS ВщбЏЪБМф
//ЁОдвђЁПDNS дЄМгдизіСЫУДЃПвГУцФкЪЧВЛЪЧЪЙгУСЫЬЋЖрВЛЭЌЕФгђУћЕМжТгђУћВщбЏЕФЪБМфЬЋГЄЃП
// ПЩЪЙгУ HTML5 Prefetch дЄВщбЏ DNS ЃЌМћЃК[HTML5 prefetch](http://segmentfault.com/a/1190000000633364)
times.lookupDomain = t.domainLookupEnd - t.domainLookupStart;
//ЁОживЊЁПЖСШЁвГУцЕквЛИізжНкЕФЪБМф
//ЁОдвђЁПетПЩвдРэНтЮЊгУЛЇФУЕНФуЕФзЪдДеМгУЕФЪБМфЃЌМгвьЕиЛњЗПСЫУДЃЌМгCDN ДІРэСЫУДЃПМгДјПэСЫУДЃПМг
CPU дЫЫуЫйЖШСЫУДЃП
// TTFB МД Time To First Byte ЕФвтЫМ
//ЁОживЊЁПФкШнМгдиЭъГЩЕФЪБМф
//ЁОдвђЁПвГУцФкШнОЙ§ gzip бЙЫѕСЫУДЃЌОВЬЌзЪдД css/js ЕШбЙЫѕСЫУДЃП
times.request = t.responseEnd - t.requestStart;
//ЁОживЊЁПжДаа onload ЛиЕїКЏЪ§ЕФЪБМф
//ЁОдвђЁПЪЧЗёЬЋЖрВЛБивЊЕФВйзїЖМЗХЕН onload ЛиЕїКЏЪ§РяжДааСЫЃЌПМТЧЙ§бгГйМгдиЁЂАДашМгдиЕФВпТдУДЃП
times.loadEvent = t.loadEventEnd - t.loadEventStart;
// DNS ЛКДцЪБМф
times.appcache = t.domainLookupStart - t.fetchStart;
// аЖдивГУцЕФЪБМф
times.unloadEvent = t.unloadEventEnd - t.unloadEventStart;
// TCP НЈСЂСЌНгЭъГЩЮеЪжЕФЪБМф
times.connect = t.connectEnd - t.connectStart;
return times;
} |
ШежОЩЯБЈ
ЕЅЖРЕФШежОгђУћ
ЖдгкШежОЩЯБЈЪЙгУЕЅЖРЕФШежОгђУћЕФФПЕФЪЧБмУтЖдвЕЮёдьГЩгАЯьЁЃЦфвЛЃЌЖдгкЗўЮёЦїРДЫЕЃЌЮвУЧПЯЖЈВЛЯЃЭћеМгУвЕЮёЗўЮёЦїЕФМЦЫузЪдДЃЌвВВЛЯЃЭћЙ§ЖрЕФШежОдквЕЮёЗўЮёЦїЖбЛ§ЃЌдьГЩвЕЮёЗўЮёЦїЕФДцДЂПеМфВЛЙЛЕФЧщПіЁЃЦфЖўЃЌЮвУЧжЊЕРдквГУцГѕЪМЛЏЕФЙ§ГЬжаЃЌЛсЖдвГУцМгдиЪБМфЁЂPVЁЂUVЕШЪ§ОнНјааЩЯБЈЃЌетаЉЩЯБЈЧыЧѓЛсКЭМгдивЕЮёЪ§ОнМИКѕЪЧЭЌЪБПЬЗЂГіЃЌЖјфЏРРЦївЛАуЛсЖдЭЌвЛИігђУћЕФЧыЧѓСПгаВЂЗЂЪ§ЕФЯожЦЃЌШч
ChromeЛсгаЖдВЂЗЂЪ§ЮЊ 6ИіЕФЯожЦЁЃвђДЫашвЊЖдШежОЯЕЭГЕЅЖРЩшЖЈгђУћЃЌзюаЁЛЏЖдвГУцМгдиадФмдьГЩЕФгАЯьЁЃ
ПчгђЕФЮЪЬт
ЖдгкЕЅЖРЕФШежОгђУћЃЌПЯЖЈЛсЩцМАЕНПчгђЕФЮЪЬтЃЌВЩШЁЕФНтОіЗНАИвЛАугавдЯТСНжжЃК
вЛжжЪЧЙЙдьПеЕФ ImageЖдЯѓЕФЗНЪНЃЌЦфдвђЪЧЧыЧѓЭМЦЌВЂВЛЩцМАЕНПчгђЕФЮЪЬтЃЛ
var url = 'xxx';
new Image().src = url; |
РћгУ AjaxЩЯБЈШежОЃЌБиаыЖдШежОЗўЮёЦїНгПкПЊЦєПчгђЧыЧѓЭЗВП Access-Control-Allow-Origin:*ЃЌетРя
AjaxОЭВЂВЛЧПжЦЪЙгУ GETЧыЧѓСЫЃЌМДПЩПЫЗў URLГЄЖШЯожЦЕФЮЪЬтЁЃ
if (XMLHttpRequest)
{
var xhr = new XMLHttpRequest();
xhr.open('post', 'https://log.xxx.com', true);
// ЩЯБЈИјnodeжаМфВуДІРэ
xhr.setRequestHeader('Content-Type', 'application/json');
// ЩшжУЧыЧѓЭЗ
xhr.send(JSON.stringify(errorObj)); // ЗЂЫЭВЮЪ§
} |
дкЮвЕФЯюФПжаЪЙгУЕФЪЧЕквЛжжЕФЗНЪНЃЌвВОЭЪЧЙЙдьПеЕФ ImageЖдЯѓЃЌЕЋЪЧЮвУЧжЊЕРЖдгк GETЧыЧѓЛсгаГЄЖШЕФЯожЦЃЌашвЊШЗБЃЕФЪЧЧыЧѓЕФГЄЖШВЛЛсГЌЙ§уажЕЁЃ
ЪЁШЅЯьгІжїЬх
ЖдгкЮвУЧЩЯБЈШежОЃЌЦфЪЕЖдгкПЭЛЇЖЫРДЫЕЃЌВЂВЛашвЊПМТЧЩЯБЈЕФНсЙћЃЌЩѕжСЖдгкЩЯБЈЪЇАмЃЌЮвУЧвВВЛашвЊдкЧАЖЫзіШЮКЮНЛЛЅЃЌЫљвдЩЯБЈРДЫЕЃЌЦфЪЕЪЙгУ
HEADЧыЧѓОЭЙЛСЫЃЌНгПкЗЕЛиПеЕФНсЙћЃЌзюДѓЕиМѕЩйЩЯБЈШежОдьГЩЕФзЪдДРЫЗбЁЃ
КЯВЂЩЯБЈ
РрЫЦгкбЉБЬЭМЕФЫМЯыЃЌШчЙћЮвУЧЕФгІгУашвЊЩЯБЈЕФШежОЪ§СПКмЖрЃЌФЧУДгаБивЊКЯВЂШежОНјааЭГвЛЕФЩЯБЈЁЃ
НтОіЗНАИПЩвдЪЧГЂЪддкгУЛЇРыПЊвГУцЛђепзщМўЯњЛйЪБЗЂЫЭвЛИівьВНЕФ POSTЧыЧѓРДНјааЩЯБЈЃЌЕЋЪЧГЂЪддкаЖдиЃЈ
unloadЃЉЮФЕЕжЎЧАЯђ webЗўЮёЦїЗЂЫЭЪ§ОнЁЃБЃжЄдкЮФЕЕаЖдиЦкМфЗЂЫЭЪ§ОнвЛжБЪЧвЛИіРЇФбЁЃвђЮЊгУЛЇДњРэЭЈГЃЛсКіТддкаЖдиЪТМўДІРэЦїжаВњЩњЕФвьВН
XMLHttpRequestЃЌвђЮЊДЫЪБвбОЛсЬјзЊЕНЯТвЛИівГУцЁЃЫљвдетРяЪЧБиаыЩшжУЮЊЭЌВНЕФ XMLHttpRequestЧыЧѓТ№ЃП
window.addEventListener('unload',
logData, false);
function logData() {
var client = new XMLHttpRequest();
client.open("POST", "/log",
false); // ЕкШ§ИіВЮЪ§БэУїЪЧЭЌВНЕФ xhr
client.setRequestHeader("Content-Type",
"text/plain;charset=UTF-8");
client.send(analyticsData);
} |
ЪЙгУЭЌВНЕФЗНЪНЪЦБиЛсЖдгУЛЇЬхбщдьГЩгАЯьЃЌЩѕжСЛсШУгУЛЇИаЪмЕНфЏРРЦїПЈЫРИаОѕЃЌЖдгкВњЦЗЖјбдЃЌЬхбщЗЧГЃВЛКУЃЌЭЈЙ§ВщдФMDNЮФЕЕЃЌПЩвдЪЙгУ
sendBeacon()ЗНЗЈЃЌНЋЛсЪЙгУЛЇДњРэдкгаЛњЛсЪБвьВНЕиЯђЗўЮёЦїЗЂЫЭЪ§ОнЃЌЭЌЪБВЛЛсбгГйвГУцЕФаЖдиЛђгАЯьЯТвЛЕМКНЕФдиШыадФмЁЃетОЭНтОіСЫЬсНЛЗжЮіЪ§ОнЪБЕФЫљгаЕФЮЪЬтЃКЪЙЫќПЩППЃЌвьВНВЂЧвВЛЛсгАЯьЯТвЛвГУцЕФМгдиЁЃДЫЭтЃЌДњТыЪЕМЪЩЯЛЙвЊБШЦфЫћММЪѕМђЕЅЃЁ
ЯТУцЕФР§згеЙЪОСЫвЛИіРэТлЩЯЕФЭГМЦДњТыФЃЪНЁЊЁЊЭЈЙ§ЪЙгУ sendBeacon()ЗНЗЈЯђЗўЮёЦїЗЂЫЭЪ§ОнЁЃ
window.addEventListener('unload',
logData, false);
function logData() {
navigator.sendBeacon("/log", analyticsData);
} |
аЁНс
зїЮЊЧАЖЫПЊЗЂепЖјбдЃЌвЊЖдВњЦЗБЃГжОДЮЗжЎаФЃЌЪБПЬБЃГжЖдадФмзЗЧѓМЋжТЃЌЖдвьГЃВЛПЩШнШЬЕФЬЌЖШЁЃЧАЖЫЕФадФмМрПигывьГЃЩЯБЈЯдЕУгШЮЊживЊЁЃ
ДњТыФбУтгаЮЪЬтЃЌЖдгквьГЃПЩвдЪЙгУ window.onerrorЛђеп addEventListenerЕФЗНЪНЬэМгШЋОжЕФвьГЃВЖЛёеьЬ§КЏЪ§ЃЌЕЋПЩФмЪЙгУетжжЗНЪНЮоЗЈе§ШЗВЖЛёЕНДэЮѓЃКЖдгкПчгђЕФНХБОЃЌашвЊЖд
scriptБъЧЉдіМгвЛИі crossorigin=ЁБanonymousЁБЃЛЖдгкЩњВњЛЗОГДђАќЕФДњТыЃЌЮоЗЈе§ШЗЖЈЮЛЕНвьГЃВњЩњЕФааЪ§ЃЌПЩвдЪЙгУ
source-mapРДНтОіЃЛЖјЖдгкЪЙгУПђМмЕФЧщПіЃЌашвЊдкПђМмЭГвЛЕФвьГЃВЖЛёДІТёЕуЁЃ
ЖјЖдгкадФмЕФМрПиЃЌЫљавЕФЪЧфЏРРЦїЬсЙЉСЫ window.performance APIЃЌЭЈЙ§етИі APIЃЌКмБуНнЕиЛёШЁЕНЕБЧАвГУцадФмЯрЙиЕФЪ§ОнЁЃ
ЖјетаЉвьГЃКЭадФмЪ§ОнШчКЮЩЯБЈФиЃПвЛАуЫЕРДЃЌЮЊСЫБмУтЖдвЕЮёВњЩњЕФгАЯьЃЌЛсЕЅЖРНЈСЂШежОЗўЮёЦїКЭШежОгђУћЃЌЕЋЖдгкВЛЭЌЕФгђУћЃЌгжЛсВњЩњПчгђЕФЮЪЬтЁЃЮвУЧПЩвдЭЈЙ§ЙЙдьПеЕФ
ImageЖдЯѓРДНтОіЃЌврЛђЪЧЭЈЙ§ЩшЖЈПчгђЧыЧѓЭЗВП Access-Control-Allow-Origin:*РДНтОіЁЃДЫЭтЃЌШчЙћЩЯБЈЕФадФмКЭШежОЪ§ОнИпЦЕДЅЗЂЃЌдђПЩвддквГУц
unloadЪБЭГвЛЩЯБЈЃЌЖј unloadЪБЕФвьВНЧыЧѓгжПЩФмЛсБЛфЏРРЦїЫљКіТдЃЌЧвВЛФмИФЮЊЭЌВНЧыЧѓЁЃДЫЪБ
navigator.sendBeacon APIПЩЫуАяСЫЮвУЧДѓУІЃЌЫќПЩгУгкЭЈЙ§ HTTPНЋЩйСПЪ§ОнвьВНДЋЪфЕН
WebЗўЮёЦїЁЃЖјКіТдвГУц unloadЪБЕФгАЯьЁЃ
|








