| БрМЭЦМі: |
| БОЮФРДздsohuЃЌБОЮФжївЊНщЩмСЫвдЪЕЯжЮЂЧАЖЫЕФФПБъЃЌДгСуЙЙНЈвЛЬзЮЂЧАЖЫЕФПЊЗЂЗНАИЕФзюМбЪЕМљЁЃ |
|
ЮЂЧАЖЫЃЈMicro-FrontendЃЉЃЌЪЧНЋЮЂЗўЮёЃЈMicro-ServicesЃЉРэФюгІгУгкЧАЖЫММЪѕКѓЕФЯрЙиЪЕМљЃЌЪЙЕУвЛИіЧАЖЫЯюФПФмЙЛОгЩЖрИіЭХЖгЖРСЂПЊЗЂвдМАЖРСЂВПЪ№ЁЃ
БОЮФжаНЋЛсвдДЫЮЊФПБъЃЌДгСуЙЙНЈвЛЬзЮЂЧАЖЫЕФПЊЗЂЗНАИЕФзюМбЪЕМљ*ЃЌВЂгУгкЭъГЩ Micro Frontends
ЭјеОжаЕФЪОР§гІгУЃК

* ШЮКЮЕиЗНЕФзюМбЪЕМљЖМЪЧЛљгкжїЙлХаЖЯЕФЃЌВЛвЊЭбРыЪЕМЪУЄДгЁЃ
ЮЂЧАЖЫПЊЗЂЕФФПБъ
ЮЂЧАЖЫЪЕМљжаЃЌЪТЪЕЩЯЫљгаЕФашЧѓЖМЪЧЮЊЁИЖРСЂПЊЗЂЁЙвдМАЁИЖРСЂВПЪ№ЁЙетСНДѓФПБъЗўЮёЕФЃЌЛђепПЩвдШЯЮЊЪЧСНепЕФОпЬхЪЕЯжДыЪЉЛђепздШЛбмЩњНсЙћЁЃЭЈГЃЮвУЧЫљЫЕЕФЁИЮЂЧАЖЫЬиадЁЙАќРЈЕЋВЛНіЯогкЃК
ММЪѕЮоЙиЃКИїИіПЊЗЂЭХЖгЖМПЩвдздаабЁдёММЪѕеЛЃЌВЛЪмЭЌвЛЯюФПжаЦфЫќЭХЖггАЯьЃЛ
ДњТыЖРСЂЃКИїИіНЛИЖВњЮяЖМПЩвдБЛЖРСЂЪЙгУЃЌБмУтКЭЦфЫќНЛИЖВњЮяёюКЯЃЛ
бљЪНИєРыЃКИїИіНЛИЖВњЮяжаЕФбљЪНВЛЛсЮлШОЕНЦфЫќзщМўЃЛ
дЩњжЇГжЃКИїИіНЛИЖВњЮяЖМПЩвдздгЩЪЙгУфЏРРЦїдЩњ APIЃЌЖјЗЧвЊЧѓЪЙгУЗтзАКѓЕФ APIЃЛ
ЮЊСЫФмЙЛЪЕЯжЮЂЧАЖЫЕФФПБъЃЌашвЊЖдЯюФПећЬхНјааВ№ЗжКЭИєРыЁЃ

ЮЂЧАЖЫНсКЯЮЂЗўЮёЕФМмЙЙ
дчаЉЪБКђЃЌЮвУЧПЩФмЛсЯыЕН <iframe> ЃЌЯыБиЖдгкЁИЮЊЪВУДВЛгУ <iframe>ЁЙДѓМвЖМФмИјГіСНжЛЪжЪ§ВЛЙ§РДЕФРэгЩСЫЁЃ
НќаЉФъЃЌСэвЛЬз Web дЩњЕФВ№ЗжИєРыЗНАИж№НЅНјШыШЫУЧЕФЪгвАЃЌФЧБуЪЧ Web ComponentsЁЃВЛЙ§ЃЌетРяЖд
Web Components вЛбљГжЗёЖЈЬЌЖШЁЃ
ЮЊЪВУД Web Components ВЛЪЧвЛИігааЇЗНАИ
ЮЊСЫСЫНтЗёЖЈ Web Components ЕФдвђЃЌЪзЯШМђвЊНщЩмвЛЯТ Web Components
ЪЧЪВУДЁЃ

https://www.webcomponents.org/
Web Components ЪЧгЩ W3C ЮЌЛЄЕФММЪѕИХФюМЏЃЌФПЧААќКЌ*ЃК
Shadow DOM
Custom Elements
HTML Templates
CSS changes
етЫФВПЗжММЪѕФкШнЁЃ
* дјОЛЙАќКЌЙ§ HTML ImportsЃЌЕЋдчвбБЛвЦГ§ЃЌКмЖрЯрЙизЪСЯЖМУЛгаИќаТЁЃ
ашвЊзЂвтЕФЪЧЃЌЫфШЛ Web Components АќКЌФФаЉФкШнЪЧ W3C ЮЌЛЄЕФЃЌЕЋЪЧРяУцЕФММЪѕБОЩэВЂВЛЪЧЃЌShadow
DOMЁЂCustom Elements КЭ HTML Templates ЖМЪЧ HTML Living
Standard КЭ DOM Living Standard жаЕФе§ЪНФкШнЃЌгЩ WHATWG ЮЌЛЄЁЃ
вђДЫЖдгк Web Components ЕФЗёЖЈЩцМАЕНСНИіВуУцЃК
зїЮЊНЛЛЅжаМфВуЕФГЁОАЯТЃЌShadow DOMЁЂCustom Elements КЭ HTML Templates
НтОіЕФЮЪЬтЪЧЭъШЋЖРСЂЕФЃКShadow DOM гУгкИЈжњбљЪНИєРыЃЌCustom Elements гУгкМђЛЏЦєЖЏДњТыЃЌЖј
HTML Templates гУгкФкВПЪЕЯжЖджаМфВуЗтзАКСЮоАяжњЁЃзїЮЊММЪѕбЁаЭЖјбдЃЌУПИіЮЪЬтЕФНтОіЗНАИвВЪЧЯрЛЅе§НЛЕФЃЌвђДЫ
Web Components етИіЮБИХФюдкДЫВЂВЛФмЗЂЛгШЮКЮећЬхМлжЕЃЛ
Shadow DOMЁЂCustom Elements ЗжБ№ЖМВЛЪЧЯргІЮЪЬтЕФгааЇНтОіЗНАИЃЌвдЯТЛсЯъЯИЫЕУїЁЃ
жСДЫЃЌЮвУЧвбОПЩвдЭъШЋЭќЕє Web Components етИіЮБИХФюЃЌжЛПДОпЬхММЪѕБОЩэЁЃ
ЪзЯШашвЊзЂвтЕФЪЧ Shadow DOM КЭ Custom Elements ЖМжЛга IE11+ ЕФ
Polyfill жЇГжЃЌвђДЫашвЊПМТЧ IE9 КЭ IE10 ЕФгІгУПЩвджБНгХХГ§ЁЃЕЋМДБуЖдгкжЛашвЊПМТЧ
IE11+ ЕФгІгУЖјбдЃЌетСНЯюММЪѕвВВЂЗЧзюгХНтЁЃ
Custom Elements ЕФвўаЮГЩБО
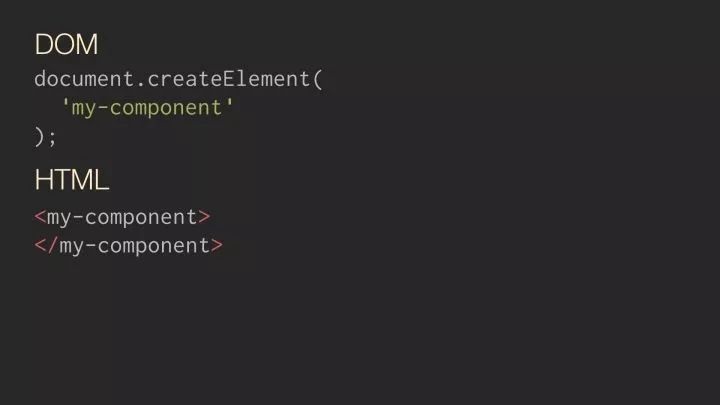
Custom Elements гУЗЈ
Custom Elements гУгкРЉеЙ HTML Elements ЕФ RegistryЃЌШУ HTML
Parser вдМАФмЙЛЪЖБ№здЖЈвхЕФдЊЫиУћ*ЃЌВЂЧвЛЙФмЙЛздЖЏДЅЗЂЯргІЕФЩљУїжмЦкЁЃ
* зМШЗЕФЫЕ Custom Elements АќКЌ Autonomous custom elements
КЭ Customized built-in elements СНжжРраЭЃЌгЩгкКѓепМШУЛгафЏРРЦїЕФЭГвЛдЩњжЇГжЃЈFirefox
аћВМСЫВЛЛсжЇГжЃЉвВУЛгаПЩгУЕФ PolyfillЃЌвђДЫБОЮФжаФЌШЯНіНіжИДњЧАепЁЃ
гаСЫ Custom Elements жЎКѓЃЌЦєЖЏДњТыОЭЪЧ HTML
БОЩэЃЈЛђепЯргІЕФ DOM API ЕїгУЃЉЃК
| <book-cardtitle="Custom
Elements"author="Web"price="42"></book-card> |
вдМАЃК
constbookCard=document.('book-card')
bookCard.setAttribute('title','Custom Elements')
bookCard.setAttribute('author','Web')
bookCard.setAttribute('price','42') |
ЫфШЛПДЫЦКЭвЛАуЕФ HTML ФЃАцДњТыЮовьЃЌЕЋЪТЪЕЩЯ Custom Elements КЭПђМмФЃАцжаУїЯдВЛЭЌжЎДІЕФЪЧЃКУЛга
Scoping КЭ ValidationЁЃ
ШчЙћдЊЫиУћГіЯжЦЋВюЛђепБЛвРРЕзщМўЮДБЛв§ШыдЫааЪБЃЌФЧУДОЭжЛЛсЕУЕНвЛИі HTMLUnknownElementЃЌВЂВЛЛсГіЯжШЮКЮДэЮѓЃЌДгЖјШУгУЛЇЕУЕНВЛдЄЦкЕФНсЙћЁЃ
СэЭтДг DOM ВйзївВФмПДГівЛИіжївЊЮЪЬтЫљдкЃКDOM API ВЛжЇГжХњСПИќаТЁЃ
ЖдгкдЩњЕФ DOM ВйзїЖјбдЃЌетбљЕБШЛВЛЛсв§ЗЂЪВУДЮЪЬтЁЃВЛЙ§дкЕБЧАгІгУжаЃЌCustom
Elements ЕФжАд№ЪЧЩњУќжмЦкДњРэЃЌДІРэЗНЪНОЭЪЧдк attributeChangedCallback
ЩњУќжмЦкжаЭЈжЊЦфЫќПђМмНјааИќаТВйзїЁЃРрЫЦгкЃК
| classBookCardextendsHTMLElement
{attributeChangedCallback (name: string,oldValue:
string,newValue: string) {someOtherFramework.update({[name]:newValue})}} |
ЖјвђЮЊУЛгаХњСПИќаТЃЌЩЯЪіаоИФ titleЁЂauthor КЭ price ЕФГЁОАжаЃЌДЅЗЂСЫећећШ§ДЮЪ§ОнИќаТВйзїЃЌЖјЖдгкЃЈОјДѓЖрЪ§ЃЉЪгЭМЭЌВНПђМмЖјбдЃЌЪ§ОнИќаТЛсгаЙЬЖЈЕФЖюЭтГЩБОЃЈМДЪЙУЛгаШЮКЮЪгЭМаоИФЃЉЃЌВЛНів§Ц№ВЛБивЊЕФадФмРЫЗбЭЌЪБЛЙПЩФмНјШыВЛдЄЦкЕФжаМфзДЬЌЁЃ
ЕБШЛДцдквЛаЉ WorkaroundЃЌР§ШчдкЗтзАВуЭГвЛЕШД§ nextTickЃЌЛђепЪЙгУНгЪмЖдЯѓЕФ DOM
ЪєадРДНјааИќаТВйзїЃЌЕЋЪЧВЛТлЖдгкПЩЮЌЛЄадЛЙЪЧвзгУадЖјбдШдШЛЛсдьГЩПЩЙлЕФгАЯьЁЃ
Shadow DOM ЖдЗўЮёЖЫфжШОЕФИпЖШЦЦЛЕ

DOM Tree with Shadow Root
Shadow DOM V0 жав§ШыСЫ Content Projection ЕФЛњжЦЃЌЭЈЙ§ <content>
дЊЫиЪЕЯжЁЃжЎКѓЕФ V1 АцБОжаИФЮЊ <slot> дЊЫиЁЃ
ЮвУЧжЊЕРЃЌЗўЮёЖЫфжШОФмЙЛжБНгВњГіОВЬЌ HTML БЛфЏРРЦїНтЮіЃЌВЛЙ§ <slot> ЕФГіЯжШУе§ШЗЕФЗўЮёЖЫфжШОБфЕУВЛПЩФмЁЃ
МйЩшвЛИізщМўОпБИШчЯТЕФ Shadow DOMЃК
<divclass="foo"><h4>Foo
</h4><slot></slot>
</div> |
БЛШчЯТДњТыЪЙгУЃК
<element-details><p>Bar
</p>
</element-details> |
ФЧУДЪЕМЪфжШОНсЙћЮЊЃК
<element-details><divclass="foo"><h4>Foo
</h4><p>Bar </p></div>
</element-details> |
ЮЪЬтдкгкЃЌШчЙћЮвУЧецЕФдкЗўЮёЖЫфжШОГіИУНсЙћЃЌдйДгфЏРРЦїЖЫЦєЖЏЃЌФЧУДЗўЮёЖЫЕФфжШОНсЙћОЭЛсБЛЪгЮЊдЪМФкШнЃЌдйДЮНјааЭЖгАЃК
<element-details><divclass="foo"><h4>Foo
</h4><divclass="foo"><h4>Foo
</h4><p>Bar </p></div></div>
</element-details> |
жЎЫљвд Web ПђМмжаВЛЛсГіЯжИУЮЪЬт*ЃЌЪЧФмЙЛЖдЭЖгАЙ§ГЬНјааПижЦЃЈЪЙгУЖюЭтЕФЬиЪтЪєадНјааБъзЂЃЉЃЌЖјдкдЩњЪЕЯжжаВЂУЛгаЯргІЕФПижЦШЈЃЌЮоЗЈЧјЗждЪМФкШнЃЌДгЖјЕМжТВЛе§ШЗЕФЖржифжШОЁЃ
* ИќецЪЕЕФдвђЪЧДѓВПЗж Web ПђМмбЙИљОЭВЛжЇГжДгЭтВП HTML ГщШЁзгФкШнНкЕуЃЌжЛФмдкПђМмФкВПЪЙгУЁЃ
ЫљвдШчЙћвЊЪЙгУ Shadow DOMЃЌБиаыШУЫљгаПЊЗЂШЫдБЧЉУћГаХЕОјВЛЪЙгУ <slot>
дЊЫиЁЃМДБуШчДЫЃЌвВЛЙгаЦфЫќЗНУцЕФЮЪЬтЃЌР§Шч <style>ЁЃ
гывЛАуЕФ Web ПЊЗЂРэФюВЛЭЌЕФЪЧЃЌShadow DOM жаЪЙгУФкЧЖЕФ <style>
дЊЫиЪЧЭЦМіЕФПЊЗЂЗНЪНЃЈГ§ДЫжЎЭтжЛга Inline Style гааЇЃЉЃЌВЂЧвНіЖд Shadow Root
гааЇЁЃ
ЖјвЛЕЉНЋ <style> фжШОЮЊзгНкЕуЃЌФЧНЋЛсЖдвГУцбљЪНВњЩњМЋДѓЕФЦЦЛЕЃК
<element-details><style>p{background-color:red}</style><p>Foo
</p>
</element-details>
<p>Bar </p> |
ЫљвдГ§СЫ <slot> дЊЫижЎЭтЃЌ<style> дЊЫивВБ№гУСЫЃЌРЯРЯЪЕЪЕШЋВПаДГЩ
Inline Style АЩЁЃВЛЙ§ЮЪЬтРДСЫЃЌЪЙгУ Shadow DOM ЕФКЫаФФПЕФОЭЪЧбљЪНИєРыЃЌВЛФмЪмвцгкДЫЕФЛАЮЊЪВУДЛЙвЊгУ
Shadow DOM ФиЃП
НЛИЖВњЮяЕФЩшЖЈ
ЫљЮНЕФЁИЮЂЧАЖЫЁЙРэФюЯТЃЌНЛИЖВњЮяДѓЬхПЩвдЗжЮЊМИИіВЛЭЌЕФМЖБ№ЃК
ЖРСЂВПЪ№ЕФЭјеОЃКПЊЗЂЭХЖгЕФЙЙНЈВњЮяЮЊЖРСЂЭјеОВЂздааЭъГЩЭјеОЕФВПЪ№ЃЌЭЈГЃЖдгІЕФМЏГЩЗНЪНЮЊдкЖрИіГЄЕУКмЯёЕФЭјеОжЎМфЬјзЊЛђеп
<iframe> БъЧЉв§ШыЭтВПвГУцЃЛ
ЭјеОФкШнЃКПЊЗЂЭХЖгЕФЙЙНЈВњЮяЮЊЖРСЂЭјеОЕЋЭЈЙ§бЙЫѕАќЩЯДЋВЂВПЪ№ЕНЭГвЛЮЛжУЃЌЭЈГЃЖдгІЕФМЏГЩЗНЪНЮЊЗўЮёЦїЖЫЕФЗДЯђДњРэЃЛ
вГУцНХБОЃКПЊЗЂЭХЖгЕФЙЙНЈВњЮяЮЊ Java ДњТыЮФМў*ВЂБЛеОЕув§ШыЕНеОЕужаЃЛ
* ФПЧАДцдквЛИі HTML Modules ЬсАИЃЌЫфШЛЗЂВМЕФФкШнЪЧ HTML ЮФМўЕЋЪЧв§ШыЗНЪНЪЧ ES
ModuleЃЌетРявВЪгЮЊЗЂВМ Java ДњТыЕФЗНЪНЁЃ
ЖјКѓдкЗЂВМ Java ДњТыЕФДѓЗНЯђжЎЯТЃЌДѓЬхгжПЩвдЗжЮЊСНИіРрБ№ЃК
ЗЂВМзщМўЃКЦєЖЏЮЛжУКЭЪБЛњЭъШЋгЩИИМЖФкШнПижЦЃЌжЇГжЖрЪЕР§ЃЌР§Шч Custom ElementsЃЛ
ЗЂВМОжВПгІгУЃКЦєЖЏЙ§ГЬгЩздЩэХфжУЃЌжЛФмЕЅЪЕР§ЃЌР§Шч single-spaЃЛ
ПЩвдМђЕЅЕФРрБШЮЊЃЌЧАепЗЂВМЕФЪЧЁИРрЁЙЃЌКѓепЗЂВМЕФЪЧЁИЪЕР§ЁЙЁЃетРяЮвУЧбЁдёЧАепЃЌЫљгаЗЂВМЕФФкШнЖМЪЧПЩвджигУЕФзщМўЃЌгЩИИзщМўОіЖЈКЮЪБМАКЮДІЪЙгУЁЃ
гЩгкжЎЧАвбОХХГ§СЫ Custom Elements ЕФбЁЯюЃЌЕБШЛвВОЭашвЊЖЈвхаТЕФНгПкРДТњзузщМўЛЏЕФашЧѓЃЌЭЌЪББмУт
Custom Elements жаЕФШБЯнЁЃ
зщМўЛЏЩшМЦ

Custom Elements жаЕФЩњУќжмЦк
гЩгкФПБъНіНіЪЧЪЕЯжЩњУќжмЦкДњРэЃЌздЩэВЂВЛашвЊЪгЭМЙмРэЕФжЇГжЃЌЫљвдвЛЧаЯжгаЕФПђМмЖМЙ§жиЃЌЖјЧвВЛПЩПиЕФЗчЯеМЋИпЁЃЮЊДЫашвЊздааЖЈвхвЛЬз
APIЃЌбЁдёЕФЗНАИгаКмЖрЃЌР§ШчвЛИіКмМђНщгааЇЕФЩшМЦОЭЪЧ Svelte ЕФ get/set APIЃК
// Set state
component.set({value:42})
// Get state
const{value}=component.get() |
ЭЈЙ§ЭГвЛЕФзДЬЌИќаТ APIЃЌФмЙЛгааЇНтОіХњСПИќаТЕФЮЪЬтЃК
| component.set({title:'Svelte-style',author:'Svelte',price:42,}) |
жСгкЪТМўЭЈаХ API КЭЩњУќжмЦк API ОЭПЩвдИќЮЊЫцвтСЫЁЃ
жЎКѓЃЌЛЙашвЊПМТЧзщМўгызщМўжЎМфШчЙћНЈСЂвРРЕЙиЯЕЁЃCustom Elements ЗНАИжаДцдкЕФвЛИіЯджјЮЪЬтОЭЪЧЁИзщМўЪЙгУЁЙгыЁИвРРЕНЈСЂЁЙЕФЭбНкЃЌЕЅЗДУцвРППЭтВПЛЗОГвЛДЮадв§ШыЫљгаФкШнЁЃ
вЊНЈСЂ Java ЮФМўжЎМфЕФвРРЕЙиЯЕЃЌзюЮЊжБЙлЕФЗНЪНОЭЪЧ ES ModuleЃЌРрЫЦгкЃК
import{render,Component}from'@domain/mf-helpers'
import{MyComp1}from'@domain/lib1'
classMyComp2extendsComponent{someMethod(){render(MyComp1,myElement)}} |
ДЫЭтЛЙПЩвдПП Dynamic ImportsЃЈStage 3 ProposalЃЉДІРэЖЏЬЌФкШнЕФвРРЕЃК
import{render,Component}from'@domain/mf-helpers'
classMyComp2extendsComponent{asyncsomeMethod()
{const{MyComp1}= awaitimport('@domain/lib1')render(MyComp1,myElement)}} |
Лљгк ES Module НЈСЂЕФв§гУЙиЯЕЃЌПЩвдШУзщМўЕФПЩгУадБфЕУОјЖдПЩППЁЃШчЙћБЛвРРЕФЃПщМгдиЪЇАмЃЌФЧУДЕБЧАФЃПщвВВЛЛсБЛжДааЃЌДгЖјНјШыЕНЭГвЛЕФДэЮѓДІРэвГУцЁЃЕБШЛЃЌдк
Dynamic Import ЕФЗНЪНЯТЃЌЕїгУепПЩвдздааЖЈвхОжВПДэЮѓДІРэЃЌЬсЙЉ Fallback жЇГж*ЁЃ
* Г§ЗЧгаУїШЗЕФгІгУБпНчЃЈР§ШчаЁГЬађМЖБ№ЕФЖРСЂзгГЬађЃЉЃЌЗёдђ Fallback ааЮЊВЂВЛППЦзЃЌЖдгкећЬхгІгУЖјбдвРРЕВЛПЩгУЕФЧщПіЯТгІИУСЂМДБЈДэЃЌЖјЗЧОЁзюДѓХЌСІдЫааЁЃ
етбљдкдДТыВуУцЩЯМЋДѓБЃжЄСЫПЩЖСадКЭПЩЮЌЛЄадЃЌгааЇЬсЩ§СЫПЊЗЂаЇТЪЁЃ
ЕБШЛЃЌЮвУЧжЊЕРЪЕМЪгІгУжаВЂВЛЛсдкЩњВњЛЗОГжБНгЪЙгУфЏРРЦїЕФФЃПщжЇГжЃЌЖјЪЧдЄЯШНјааДђАќЙЙНЈЁЃЮЊСЫБЃГжЖРСЂВПЪ№ЕФФПБъЃЌашвЊдкЙЙНЈЙ§ГЬжаХХГ§ЦфЫќзщМўЕФвРРЕЃЌВЂНЋвРРЕЕФШЗЖЈЙ§ГЬбгЦкЕНдЫааЪБЕФДІРэЁЃ
ЖјжСгкбљЪНИєРыЃЌжБНгНЛгЩИїИіЭХЖгздааДІРэМДПЩЃЌжїСїПђМмЛљБОЖМЬсЙЉСЫзщМўбљЪННтОіЗНАИЁЃДЫЭтЃЌППдМЖЈЧАзКВЂВЛФмБмУтбљЪНГхЭЛЃЌЫфШЛВЛЛсЮлШОИИзщМўЃЌЕЋШдШЛФмЙЛЖдзгзщМўВњЩњЮлШОЁЃЃЈГ§ЗЧжЛЪЙгУИИзгбЁдёЦїВЛгУКѓДњбЁдёЦїЃЉ
вЛАудкећИігІгУжаЃЌжЛгаФГвЛМЖЬиЖЈзщМўВХЛсЪЙгУТЗгЩЃЈУПИізщМўгУВЛгУЕУЕНздМКаФРягаЪ§ЃЉЃЌвђДЫзщМўЩшМЦжаНЋЕБЧАЕФ
basePath КЭ navigationFn ОгЩ Context ВуВуДЋЕнЃЌШчЙћгаФГИізщМўашвЊЪЕЯжзгТЗгЩЃЌздааЗтзАВЂБЉТЖЕНЯТМЖМДПЩЁЃ
ЙЙНЈгыВПЪ№ВпТд
жЎЧАвбОЬсЕНЃЌЮЊСЫБЃжЄПЊЗЂаЇТЪЃЌдДТыжаНіНіЪЙгУ ES Module РДв§ШыЭтВПзщМўЃЌВЛЙ§ВЂВЛДђАќЕНЕБЧАзщМўжаЃЌЖјЪЧЭЦГйЕНдЫааЪБОіЖЈЁЃ
етРяПЩФмЛсВњЩњЕФвЩЮЪЪЧЃЌзщМўЪЧЗёашвЊЗЂВМЕН RegistryЃП
Д№АИЪЧашвЊ*ЃЌЮЊСЫЪЕЯжСНИіФПБъЃК
Library as a ConstraintЃКФЃПщЕМГіЁЂРраЭЧЉУћФмЙЛОВЬЌШЗЖЈЃЛ
Registry as a CDNЃКВЛЭЌАцБОЭЌЪБДІгкПЩЗУЮЪзДЬЌЃЛ
* ММЪѕВуУцЩЯШдШЛЪЧВЛашвЊЕФЃЌжЛашвЊЗЂВМКѓЕФ URL МДПЩЁЃ
етРяЕФ Registry ВЂВЛвЛЖЈЪЧ NPM RegistryЃЌШЮКЮФмЙЛЮШЖЈзЗЫнЕФЛњжЦОљПЩЃЌР§Шч
Git TagsЁЃ
ЫфШЛЙЙНЈЙЄОпВуУцВЛвЊЧѓАВзАвРРЕЃЌЕЋЪЧзїЮЊвРРЕАВзАФмЙЛгааЇЬсЩ§ПЊЗЂЬхбщЃЌР§ШчБрМЦїЕФДњТыЬсЪОЃЌЭЌЪБАцБОЗЂВМгІЕБЗћКЯгявхЛЏАцБОКХЕФвЊЧѓЃЈВЂФмЙЛНјаадЫааЪБбщжЄЃЉЁЃ
ЭЌбљЃЌЫфШЛдЫааЪБашвЊЕФжЛгазщМўЗЂВМЕФ URLЃЌШЛЖјЭЈЙ§ Registry ЗЂВМФмЙЛЛёЕУжюЖргХЪЦЃК
ШЋАцБОЪЕЪБПЩгУЃКЗЂВМаТАцБОВЂВЛЛсЬцЛЛЕєдгаАцБОЃЌЫљгаАцБОЭЌЪБДІгкПЩгУзДЬЌЃЌФмЙЛЭЈЙ§дк
URL жажИУїАцБОНјааЗУЮЪЃЌР§Шч https://unpkg.com/@angular/core@6.0.4
/bundles/core.umd.jsЃЌвджСгкдкЧаЛЛАцБОЃЈИќаТЛђепЛиЭЫЃЉЪБЃЌВЂВЛашвЊжиаТВПЪ№ЯргІДњТыЃЌЖјНіНіаоИФАцБОХфжУЮФМўМДПЩЃЛ
Alias здЖЏИќаТЃКЮЊСЫЗНБуздЖЏЭЌВНЃЌВтЪдЛЗОГжаПЩвдВЂВЛЪЙгУОпЬхАцБОКХЃЌЖјЪЙгУ AliasЃЌР§Шчдк
Staging ЛЗОГжаЪЙгУ @stableЃЌОЭФмЮоашХфжУздЖЏЭЌВНзюаТАцБОЃЌПьЫйбщжЄМцШнадЮЪЬтЁЃ
Г§ДЫжЎЭтЃЌашвЊв§ШыдЫааЪБЕФвРРЕЙмРэЗНАИЁЃ
ES Module ЫфШЛдкЫљгажїСїфЏРРЦїжаЖМвбОЕУЕНжЇГжЃЌЕЋЪЧДѓВПЗжгІгУШдШЛашвЊееЙЫВПЗжРЯОЩАцБОЃЌЭЌЪБ
ES Module ЕФФЃПщв§ШыЙ§ГЬЮоЗЈРЙНиЃЌвђДЫЮоЗЈЪЙгУдЩњЪЕЯжЁЃ
ЕБЧАЕФжїСїФЃПщИёЪНжаЃЌФмЙЛгУгкфЏРРЦїдЫааЪБЕФжЛга AMD КЭ System.register СНжжЃЌЯрБШжЎЯТКѓепвЊЧПДѓЕФЖрЃЌМИКѕЬсЙЉСЫ
ES Module ЕФгявхЕФЭъећжЇГжЃЈР§ШчбЛЗвРРЕКЭЖЅВувьВНЕШД§ЃЉЁЃЭЌЪБЃЌКѓепвВга SystemJS
етбљЕФгХауЙЄОпЃЌздДјРЉеЙжЇГжЃЌДгЖјЮоашДгСуПЊЪМздааЪЕЯжЁЃ
Р§ШчЖдгк ES Module ЕФДњТыЃК
import{render,Component}from'@domain/mf-helpers'
import{MyComp1}from'@domain/lib1'
exportclassMyComp2extendsComponent{someMethod(){render(MyComp1,myElement)}} |
ДђАќЮЊ System.registry ИёЪНКѓЪфГіЮЊЃК
| System.register('@domain/lib2',
['@domain/mf-helpers','@domain/lib1'], function(exports,module)
{'use strict';varrender,Component,MyComp1; return{setters:[function(module)
{render=module.render;Component=module.Component;}
,function(module){MyComp1=module.MyComp1;}], execute:function()
{classMyComp2extendsComponent{someMethod() {render(MyComp1,myElement);}}
exports('MyComp2',MyComp2);}};}); |
етРяЫфШЛУЛгаЦфЫќЭтВПвРРЕЃЌЕЋашвЊзЂвтЕФЪЧЃЌ@domain жЎЭтЕФЦфЫќзщМўФкВПвРРЕВЂУЛгаЪЕЪБИќаТЕФвЊЧѓЃЌПЩвджБНгДђАќЕНЮФМўжаЁЃ
ЮЊСЫНјааАцБОбщжЄЃЌашвЊЖдЪфГіФкШнНјааВПЗжРЉеЙЃК
| System.pkgInfo({name:'@domain/lib2',version:'1.0.1',
dependencies: {'@domain/mf-helpers':{version:'^1.0.0'},'
@domain/lib1':{version:'^1.2.3'},}});System.register(/*
... */); |
ДгЖјФмЙЛбщжЄ lib1 КЭ lib2 ЪЧЗёЦЅХфАцБОвЊЧѓЃЈЛЙПЩвдгаЦфЫќКѓајРЉеЙгУЭОЃЉЁЃ
ЫфШЛетРяНЋ mf-helpers зїЮЊЭтВПвРРЕЃЌЕЋЪЧЭъШЋгІЕБдЪаэФкСЊЃЌвђДЫЦфФкВПЪЕЯжБиаыЭъШЋ StructuralЃЌДгЖјБмУтИББОМфГхЭЛ*ЁЃ
* зМШЗЕФЫЕВЂУЛгаБмУтЃЌжЛЪЧЭЈжЊЯрЙиШЫдБШЅНтОіЁЃ
ЫљвддЫааЪБашвЊРЉеЙ System.register() КЭ System.instantiate()
СНИіЙГзгЃЌВЂдіМг System.pkgInfo() ЕФЪЕЯжЁЃ
вРРЕПтЕФИДгУ
ЫфШЛЮЂЧАЖЫЕФФПБъЪЧДњТыИєРыЃЌЕЋЪЧШдШЛПЩвддЪаэПЊЗЂШЫдБжїЖЏЩљУїЕФПЩИДгУФкШнЁЃ
дкЕБЧАЕФЗЂВМЗНЪНЯТЃЌЖдПЩИДгУвРРЕКЭВЛПЩИДгУвРРЕНјааВювьЛЏДІРэЪЎЗжМђЕЅЃКВЛПЩИДгУвРРЕДђАќЕНзщМўФкВПЃЌПЩИДгУвРРЕБЃСєФЃПщЩљУїЁЃВЛЙ§ШдШЛДцдкЕФЮЪЬтЪЧЃЌШчКЮЪЕЯжПЩИДгУвРРЕЕФИДгУЃП
ЮЊСЫФмЙЛНјаавРРЕИДгУЃЌашвЊФмЙЛЖдвРРЕНјааЖРСЂДђАќВЂМЧТМЦф URLЃК
| System.pkgInfo({name:'@domain/lib3',version:'1.0.1',
dependencies: {'some-lib':{version:'^1.0.0',path:'./some-lib.js'},}}); |
гкЪЧЕБ lib3 БЛдЫааЪБМгдиЪБЃЌЛсХаЖЯЕБЧАЛЗОГжаЪЧЗёвбОДцдкМцШн ^1.0.0 АцБОЕФ some-lib
АќЃЌШчЙћВЛДцдкЃЌдђЧыЧѓЖдгІЕФ URL ЛёШЁЁЃ
ВЛЙ§гІЕБзЂвтЃЌЭЌвЛвРРЕЕФЕЅИББОгыЖрИББОВювьПЩвдЛсгАЯьдЫааНсЙћЃЌЩљУїПЩИДгУЕФвРРЕЪБашвЊШЗБЃЦфзёбгявхЛЏАцБОКХВЂЧвУЛгаФкВПзДЬЌЃЌЭЌЪБвВЯЃЭћздЩэУЛгаЦфЫќЭтВПвРРЕЁЃЕБШЛЯжЪЕжавВКмШнвзевЕНПЩИДгУвРРЕЕФЕфаЭЃЌБШШчГЃгУЕФЙЄОпПтЃКlodash
Лђеп momentЁЃ
дкЯпЪОР§
етРяжиаДСЫ https://micro-frontends.org/жаЕФШ§ЭХЖгЯюФПЃЌЗжБ№гЩ AngularЁЂReactЁЂVue
ЪЕЯжЃЌЭъУРЖдгІбеЩЋЙиЯЕЁЃ
ЪОР§ЕижЗЮЊЃКhttps://trotyl.github.io/ mif-demo-entry/ЃЌЯргІЕФзщМўдДТыЗжБ№ЮЛгкЃК
trotyl/mif-demo-angular
trotyl/mif-demo-react
trotyl/mif-demo-vue |
ЛљДЁЩшЪЉЮЛгкЃК
trotyl/mif-core
trotyl/mif-runtime |
гЩгкЮФеТЪЧЙигк Micro-Frontend ЕФЬжТлЃЌвђДЫЪОР§ДњТыжаЙуЗКЪЙгУ mif зїЮЊЧАзКЁЃ
ЪОР§жавдзюЭтВу Red ЭХЖгзщМўзїЮЊИљзщМўЦєЖЏЃК
| const{render,ROOT_CONTEXT}
=mif.coreSystem.import ('https://trotyl.github.io/mif-demo-angula
r/demo-angular.mif.js') .then(m=>m.RedApp).then
(RedApp=>render(RedApp,{context:ROOT_CONTEXT},document.body)) |
ПЩвдПДГіЃЌЮФеТЗжБ№ДгШ§ИіВЛЭЌЕФ GitHub Repo жаМгдиСЫзщМўНХБОЃЌЙВЭЌЙЙГЩСЫетИіЭъећЕЋЧАЖЫгІгУЃК

вГУцНХБОЧыЧѓ
ЭЌЪБЃЌЫфШЛШ§ИізщМўжаЖМЪЙгУСЫ moment зїЮЊвРРЕЃЌЕЋгЩгкЩшжУСЫдЪаэИДгУЃЌдкећИігІгУжаНіНіБЛМгдивЛДЮЃЌжЎКѓБЛЫљгазщМўЫљЙВгУЁЃ
ЪОР§жаЪЙгУЕФСйЪБжЇГжПтШдШЛДцдкКмЖрЮЪЬтЃЌВЂВЛНЈвщжБНгдкецЪЕЕФЮЂЧАЖЫЯюФПЪЙгУЁЃ
аДдкзюКѓ
ЮЂЧАЖЫЪЧвЛИіОоДѓЕФЛАЬтЃЌБОЮФгЩгкЪБМфЙиЯЕЃЌВЂУЛгаЩцМАЕНЫљгаПЩФмЕФЗНУцЁЃдкФПЧАЕФКмЖрЭХЖгжаЃЌЮЂЧАЖЫЪЕМљЭљЭљвтЮЖзХОоДѓЕФЮўЩќЃЌР§ШчНіНіЮЊСЫгХЛЏЫљЮНЕФВПЪ№ЪБМфЃЌОЭВЛЙЫвЛЧаЕФЗХЦњгІгУадФмЁЂДњТыжЪСПЁЂПЊЗЂЬхбщЕШЕШЁЃЖјБОЮФЕФФПБъдђЪЧЬНЫївЛЬѕОЁПЩФмБЃСєЕБЧАЧАЖЫЩњЬЌЕФгХауЪЕМљЃЌгжФмЙЛТњзуЮЂЧАЖЫПЊЗЂРэФюЕФОЋжТЛЏЗНАИЁЃ |








