| 编辑推荐: |
| 本文来自于网络
主要介绍了一个运行在Hadoop集群的数据库,Apache HBase是一个分布式的、面向列的开源数据库,希望对您的学习有一些帮助。 |
|
Apache HBase是一个运行在Hadoop集群的数据库。 但是HBase和传统意义上的关系型数据库(RDBMS)有所不同,它牺牲了传统数据库的ACID(原子性,一致性,隔离性和持久性)要求
, 达到超大容量和更快的处理速度。 并且, HBase上面存储的数据不需要严格符合表结构,它可以存储非结构化和半结构化的数据。
程序员利用HBase构建大型数据应用程序,但是HBase的开发模式和传统数据库的开发模式相比,有很多不同点。在这篇博客中,
我会先概述HBase,然后讨论关系型数据库的局限,最后深入介绍HBase的数据模型。
关系型数据库 vs HBase - 数据存储模型
为什么我们需要HBase/NoSQL? 在讨论关系型数据库的局限想前, 先看看关系型数据库的优点:
关系型数据库提供标准持久化模型
SQL已经成为数据操作的事实标准
关系型数据库支持并发事务
关系型数据库已经有了很多成熟工具

关系型数据库已经是多年的标准, 所以为什么要改变? 面对越来越多的数据扩容需求,最简单的方式就是购买更加强大的服务器,但这样做成本会变得越来越高。
并且单机服务器无论多强大,它仍然是单机服务器,总有容量上限。
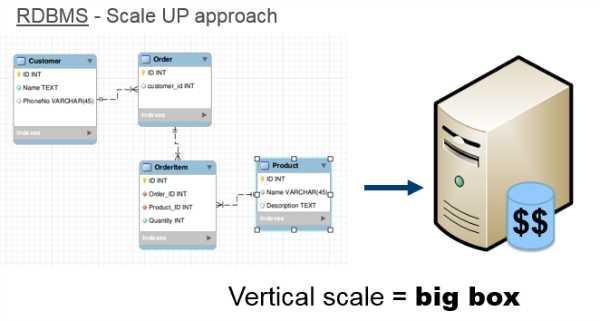
译注: 上图, Scale Up approach就是通过购买更强大服务器扩容的方式,也被翻译为纵向扩展][译者注:上图,垂直扩展
= 强大昂贵的服务器(Vertical scale = big box)
NoSQL能带来什么改变?
除了纵向扩展(vertical scale),还有一种扩展方式, 就是横向扩展(horizontal
scale) . 横向扩展采购多台便宜的PC服务器组成大集群,提供服务,这种方式使用普通PC服务器,相对便宜,同时大集群也比单机服务器可靠。
关系型数据库基于行(row)作为分片(shard),所以一些行(row)被分在某一个服务器上,而其他行分配到别的服务器上。
尽管如此, 数据库分片(shard)仍然非常复杂。 传统数据库最初设计的时候并不支持分片(shard).,这些后期添加的功能与关系型数据库的最初设计并不匹配。比如,分片后的关系型数据库不支持分片(shard)上的查询,
也不支持事务和一致性控制。关系型数据库是设计在单机上运行的,它不是设计在集群上运行。

译注:上图,行ID(id)范围在1-1000被分配到第一台服务器上,行ID范围从1000-2000被分配到另一台服务器上,而最后一台服务器存储ID范围2000-3000的数据
关系型模型的局限性
数据库范式(database normalization)消除了冗余数据,提高了存储效率。然而,范式会导致在处理查询(database
query)请求时,不得不做联表查询(join),同时读取多个表的内容, 而这些表可能分配在不同的服务器上。虽然HBase不支持关系(relation)和联表查询(join),
但是它能把要访问的数据存储在一起,从而避免了关系型模型的限制,请参考下表数据存储模型的差异:

译注:左图关系型数据库工作在集群环境,一个联表查询要同时访问多台服务器上的数据; 右图 HBase,被访问的数据总是也存储在一台服务器上,没有左图中的瓶颈(bottleneck)
HBase的设计目标:可扩展的,高性能分布式数据库
HBase把一起访问的数据也存储在一起,实现了高扩展。主要的设计思想是按照主键(row key)分片数据。针对数据做水平分片(horizontal
shard), 根据主键的范围(row key range)分片。 不同主键范围(row key range)下的数据被分配到不同的服务器中。每台服务器的数据是全体数据的子集。HBase实际上是BigTable存储系统的一个开源实现,Bigtable是由Google开发的分布式存储系统,用来管理可扩展的,大容量的结构化数据。
Hbase在物理上是按照列簇(column-family)存储的,但是在用户角度看,HBase也是面向行的(row
key)。 只要知道主键(row key), HBase就可以做到快速检索(例如,查找ID为1234的客户)。行的具体数据存储在不同的列簇中(column
family) ,如(ID为1234的客户地址,订单等)。HBase中的每一行,由主键,1号列簇中的column
, 2号列簇的column组合而成。

HBase是一个面向列簇的存储系统
译注: HBase是面向列簇的存储系统, 底层是按照列簇(column family)作为单位存储,每个列簇(column
family)可以看作一个单独的文件. 而传统数据是面向行级的存储系统,底层是按照行排列存储在硬盘上
译注:上图, CF1和CF2是一个列簇(column family), 里面可以有多个column.
根据主键(row key)查询到主键(row key)对应在CF1和CF2上的数据,这样就组成了上图红框中的一行
HBase作为分布式数据库。 根据对主键(row key)的分组把数据分配到不同服务器。HBase在行级操作是原子的。
不同的Hbase服务器存储不同的数据分片, 所有数据分片的总和来就是HBase存储的所有数据。

译注: 上图,数据根据主键(row key)分配到3台不同的服务器上
HBase的数据模型
HBase根据主键(row key),分片,存储数据。HBase的主键(row key)和关系型数据库的主键(primary
key)作用非常类似。 HBase上面的所有行按照主键的值排序,即主键小的行排在表的前面。HBase的数据按照主键(row
key)有序排列是HBase区别于其他分布式数据库的重要特征
[译注:对比apache cassandra, cassandra的partition key是无序的]

[译注: 上图,从逻辑上看,HBase的表和传统数据很类似,从红框中可以看出数据按照主键的大小顺序排列,smithj比spata小,因为虽然第一个s一样,但是第二个字母m的ascii码是109,
p的是112,所以smithj比spata小
下图中, HBase表按照主键(row key)的范围, 分成不同的区域(region). 然后把这些区域(region)分配给不同的区域服务器(region
server)管理. 这种分配方式由HBase自动控制,自动调节区域服务器(region server)中的存储容量,
这样就实现了存储数据的无限扩展。

下图显示了列簇(column family)和HBase表之间的对应关系,不同的列簇(column)在物理上被存储在不同的文件中。每个列簇文件都可以被单独访问

译注:主键(row key)从axxx到gxxx被分配到了一台区域服务器(region server)
R1上面, 这个table有2个列簇:CF1和CF2, 相当于2个独立的文件,都存储在HDFS上
数据存储在HBase表格的cell中。cell中包含key和value以及一些其他的信息(如version,
type等)。其中key部分包括row key,column family,column qualifier,
timestamp。并且对于每一个值,key和value和一起存储在列簇(column family)里。如下图所示:

列簇文件里面的数据按照Cell的方式存储。 每个Cell被称为一个键值对(KeyValue)。 Key包括的项目比较多,有主键(rowkey),列簇的名称(column
family), column qualifier和时间戳(timestamp)。 由这四项的组成一个Key,通过这个Key就可以在列簇文件中查询到Value.
从逻辑上看,Cell好像存储在表中的一行。但是在实际物理存储中,HBase的一行由有多个列簇(column
family)的对应Cell拼接而成。
下图所示, 在上面的表显示了一个Hbase表结构, 从逻辑上看和关系型数据库类似,也是按行组织。但在物理存储中,整个表是由2个列簇文件组成。如果要修改某行中的一项(实际上是一个Cell),
需要指定主键(rowkey),列簇的名称(column family), column qualifier和时间戳(timestamp)形成一个Key,
然后在实际的列簇文件中设置Value。

逻辑数据模型 vs 物理存储模型
如前所述, 定位一个Cell, 只需要5项数据拼成Key: <表名称, 主键名称, 列簇名称,
列名称, 时间戳> . HBase的表是一个稀疏表。 如果一项(column)没有数据,它就不会被存储.
此外, Cell是有版本信息的,如果只用4项数据做Key, <表名称, 主键名称, 列簇名称,
列名称>可以查询到一个Cell的多个版本.

HBase默认支持多版本,
Put操作既是一个插入操作也可以是一个修改操作,每个Cell都有自己的版本。删除操作不会真的做删除,只是写入一个删除的标志。
任何查询都不会返回有有删除标记的Cell.
Get操作可以任意指定的版本的数据。如果请求没有指定版本号,会返回最新的版本。HBase允许用户配置最多允许多少版本同时存在,HBase默认为同一个Cell最多存储3个版本。当超过3个版本后,最老版本的Cell会被最终清理。

|








