| БрМЭЦМі: |
| БОЮФРДздгкЭјТч
жївЊНщЩмСЫвЛИідЫаадкHadoopМЏШКЕФЪ§ОнПтЃЌApache HBaseЪЧвЛИіЗжВМЪНЕФЁЂУцЯђСаЕФПЊдДЪ§ОнПтЃЌЯЃЭћЖдФњЕФбЇЯАгавЛаЉАяжњЁЃ |
|
Apache HBaseЪЧвЛИідЫаадкHadoopМЏШКЕФЪ§ОнПтЁЃ ЕЋЪЧHBaseКЭДЋЭГвтвхЩЯЕФЙиЯЕаЭЪ§ОнПт(RDBMS)гаЫљВЛЭЌЃЌЫќЮўЩќСЫДЋЭГЪ§ОнПтЕФACID(дзгад,вЛжТад,ИєРыадКЭГжОУад)вЊЧѓ
, ДяЕНГЌДѓШнСПКЭИќПьЕФДІРэЫйЖШЁЃ ВЂЧвЃЌ HBaseЩЯУцДцДЂЕФЪ§ОнВЛашвЊбЯИёЗћКЯБэНсЙЙЃЌЫќПЩвдДцДЂЗЧНсЙЙЛЏКЭАыНсЙЙЛЏЕФЪ§ОнЁЃ
ГЬађдБРћгУHBaseЙЙНЈДѓаЭЪ§ОнгІгУГЬађЃЌЕЋЪЧHBaseЕФПЊЗЂФЃЪНКЭДЋЭГЪ§ОнПтЕФПЊЗЂФЃЪНЯрБШЃЌгаКмЖрВЛЭЌЕуЁЃдкетЦЊВЉПЭжаЃЌ
ЮвЛсЯШИХЪіHBaseЃЌШЛКѓЬжТлЙиЯЕаЭЪ§ОнПтЕФОжЯоЃЌзюКѓЩюШыНщЩмHBaseЕФЪ§ОнФЃаЭЁЃ
ЙиЯЕаЭЪ§ОнПт vs HBase - Ъ§ОнДцДЂФЃаЭ
ЮЊЪВУДЮвУЧашвЊHBase/NoSQL? дкЬжТлЙиЯЕаЭЪ§ОнПтЕФОжЯоЯыЧАЃЌ ЯШПДПДЙиЯЕаЭЪ§ОнПтЕФгХЕуЃК
ЙиЯЕаЭЪ§ОнПтЬсЙЉБъзМГжОУЛЏФЃаЭ
SQLвбОГЩЮЊЪ§ОнВйзїЕФЪТЪЕБъзМ
ЙиЯЕаЭЪ§ОнПтжЇГжВЂЗЂЪТЮё
ЙиЯЕаЭЪ§ОнПтвбОгаСЫКмЖрГЩЪьЙЄОп

ЙиЯЕаЭЪ§ОнПтвбОЪЧЖрФъЕФБъзМЃЌ ЫљвдЮЊЪВУДвЊИФБфЃП УцЖддНРДдНЖрЕФЪ§ОнРЉШнашЧѓЃЌзюМђЕЅЕФЗНЪНОЭЪЧЙКТђИќМгЧПДѓЕФЗўЮёЦїЃЌЕЋетбљзіГЩБОЛсБфЕУдНРДдНИпЁЃ
ВЂЧвЕЅЛњЗўЮёЦїЮоТлЖрЧПДѓЃЌЫќШдШЛЪЧЕЅЛњЗўЮёЦїЃЌзмгаШнСПЩЯЯоЁЃ
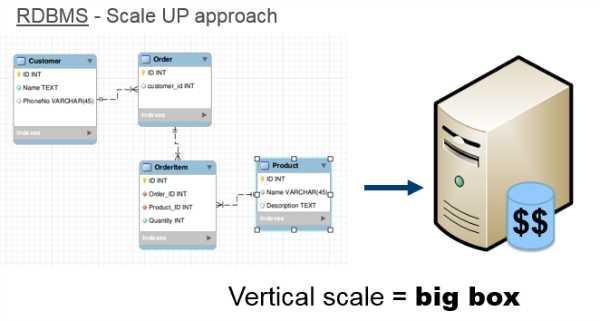
вызЂ: ЩЯЭМ, Scale Up approachОЭЪЧЭЈЙ§ЙКТђИќЧПДѓЗўЮёЦїРЉШнЕФЗНЪНЃЌвВБЛЗвыЮЊзнЯђРЉеЙ][выепзЂЃКЩЯЭМЃЌДЙжБРЉеЙ
= ЧПДѓАКЙѓЕФЗўЮёЦї(Vertical scale = big box)
NoSQLФмДјРДЪВУДИФБфЃП
Г§СЫзнЯђРЉеЙ(vertical scale)ЃЌЛЙгавЛжжРЉеЙЗНЪНЃЌ ОЭЪЧКсЯђРЉеЙ(horizontal
scale) . КсЯђРЉеЙВЩЙКЖрЬЈБувЫЕФPCЗўЮёЦїзщГЩДѓМЏШКЃЌЬсЙЉЗўЮёЃЌетжжЗНЪНЪЙгУЦеЭЈPCЗўЮёЦїЃЌЯрЖдБувЫЃЌЭЌЪБДѓМЏШКвВБШЕЅЛњЗўЮёЦїПЩППЁЃ
ЙиЯЕаЭЪ§ОнПтЛљгкаа(row)зїЮЊЗжЦЌ(shard)ЃЌЫљвдвЛаЉаа(row)БЛЗждкФГвЛИіЗўЮёЦїЩЯЃЌЖјЦфЫћааЗжХфЕНБ№ЕФЗўЮёЦїЩЯЁЃ
ОЁЙмШчДЫЃЌ Ъ§ОнПтЗжЦЌЃЈshardЃЉШдШЛЗЧГЃИДдгЁЃ ДЋЭГЪ§ОнПтзюГѕЩшМЦЕФЪБКђВЂВЛжЇГжЗжЦЌ(shard).ЃЌетаЉКѓЦкЬэМгЕФЙІФмгыЙиЯЕаЭЪ§ОнПтЕФзюГѕЩшМЦВЂВЛЦЅХфЁЃБШШчЃЌЗжЦЌКѓЕФЙиЯЕаЭЪ§ОнПтВЛжЇГжЗжЦЌ(shard)ЩЯЕФВщбЏЃЌ
вВВЛжЇГжЪТЮёКЭвЛжТадПижЦЁЃЙиЯЕаЭЪ§ОнПтЪЧЩшМЦдкЕЅЛњЩЯдЫааЕФЃЌЫќВЛЪЧЩшМЦдкМЏШКЩЯдЫааЁЃ

вызЂЃКЩЯЭМЃЌааID(id)ЗЖЮЇдк1-1000БЛЗжХфЕНЕквЛЬЈЗўЮёЦїЩЯЃЌааIDЗЖЮЇДг1000-2000БЛЗжХфЕНСэвЛЬЈЗўЮёЦїЩЯЃЌЖјзюКѓвЛЬЈЗўЮёЦїДцДЂIDЗЖЮЇ2000-3000ЕФЪ§Он
ЙиЯЕаЭФЃаЭЕФОжЯоад
Ъ§ОнПтЗЖЪН(database normalization)ЯћГ§СЫШпгрЪ§ОнЃЌЬсИпСЫДцДЂаЇТЪЁЃШЛЖјЃЌЗЖЪНЛсЕМжТдкДІРэВщбЏ(database
query)ЧыЧѓЪБЃЌВЛЕУВЛзіСЊБэВщбЏ(join)ЃЌЭЌЪБЖСШЁЖрИіБэЕФФкШнЃЌ ЖјетаЉБэПЩФмЗжХфдкВЛЭЌЕФЗўЮёЦїЩЯЁЃЫфШЛHBaseВЛжЇГжЙиЯЕ(relation)КЭСЊБэВщбЏ(join),
ЕЋЪЧЫќФмАбвЊЗУЮЪЕФЪ§ОнДцДЂдквЛЦ№ЃЌДгЖјБмУтСЫЙиЯЕаЭФЃаЭЕФЯожЦЃЌЧыВЮПМЯТБэЪ§ОнДцДЂФЃаЭЕФВювь:

вызЂЃКзѓЭМЙиЯЕаЭЪ§ОнПтЙЄзїдкМЏШКЛЗОГЃЌвЛИіСЊБэВщбЏвЊЭЌЪБЗУЮЪЖрЬЈЗўЮёЦїЩЯЕФЪ§Он; гвЭМ HBaseЃЌБЛЗУЮЪЕФЪ§ОнзмЪЧвВДцДЂдквЛЬЈЗўЮёЦїЩЯЃЌУЛгазѓЭМжаЕФЦПОБ(bottleneck)
HBaseЕФЩшМЦФПБъЃКПЩРЉеЙЕФЃЌИпадФмЗжВМЪНЪ§ОнПт
HBaseАбвЛЦ№ЗУЮЪЕФЪ§ОнвВДцДЂдквЛЦ№ЃЌЪЕЯжСЫИпРЉеЙЁЃжївЊЕФЩшМЦЫМЯыЪЧАДеежїМќ(row key)ЗжЦЌЪ§ОнЁЃеыЖдЪ§ОнзіЫЎЦНЗжЦЌЃЈhorizontal
shardЃЉЃЌ ИљОнжїМќЕФЗЖЮЇ(row key range)ЗжЦЌЁЃ ВЛЭЌжїМќЗЖЮЇЃЈrow key rangeЃЉЯТЕФЪ§ОнБЛЗжХфЕНВЛЭЌЕФЗўЮёЦїжаЁЃУПЬЈЗўЮёЦїЕФЪ§ОнЪЧШЋЬхЪ§ОнЕФзгМЏЁЃHBaseЪЕМЪЩЯЪЧBigTableДцДЂЯЕЭГЕФвЛИіПЊдДЪЕЯжЃЌBigtableЪЧгЩGoogleПЊЗЂЕФЗжВМЪНДцДЂЯЕЭГЃЌгУРДЙмРэПЩРЉеЙЕФЃЌДѓШнСПЕФНсЙЙЛЏЪ§ОнЁЃ
HbaseдкЮяРэЩЯЪЧАДееСаДиЃЈcolumn-familyЃЉДцДЂЕФЃЌЕЋЪЧдкгУЛЇНЧЖШПДЃЌHBaseвВЪЧУцЯђааЕФ(row
key)ЁЃ жЛвЊжЊЕРжїМќ(row key), HBaseОЭПЩвдзіЕНПьЫйМьЫїЃЈР§ШчЃЌВщевIDЮЊ1234ЕФПЭЛЇЃЉЁЃааЕФОпЬхЪ§ОнДцДЂдкВЛЭЌЕФСаДижа(column
family) ЃЌШчЃЈIDЮЊ1234ЕФПЭЛЇЕижЗЃЌЖЉЕЅЕШЃЉЁЃHBaseжаЕФУПвЛааЃЌгЩжїМќЃЌ1КХСаДижаЕФcolumn
, 2КХСаДиЕФcolumnзщКЯЖјГЩЁЃ

HBaseЪЧвЛИіУцЯђСаДиЕФДцДЂЯЕЭГ
вызЂ: HBaseЪЧУцЯђСаДиЕФДцДЂЯЕЭГЃЌ ЕзВуЪЧАДееСаДи(column family)зїЮЊЕЅЮЛДцДЂЃЌУПИіСаДиЃЈcolumn
familyЃЉПЩвдПДзївЛИіЕЅЖРЕФЮФМў. ЖјДЋЭГЪ§ОнЪЧУцЯђааМЖЕФДцДЂЯЕЭГЃЌЕзВуЪЧАДееааХХСаДцДЂдкгВХЬЩЯ
вызЂЃКЩЯЭМ, CF1КЭCF2ЪЧвЛИіСаДиЃЈcolumn family), РяУцПЩвдгаЖрИіcolumn.
ИљОнжїМќ(row key)ВщбЏЕНжїМќ(row key)ЖдгІдкCF1КЭCF2ЩЯЕФЪ§ОнЃЌетбљОЭзщГЩСЫЩЯЭМКьПђжаЕФвЛаа
HBaseзїЮЊЗжВМЪНЪ§ОнПтЁЃ ИљОнЖджїМќ(row key)ЕФЗжзщАбЪ§ОнЗжХфЕНВЛЭЌЗўЮёЦїЁЃHBaseдкааМЖВйзїЪЧдзгЕФЁЃ
ВЛЭЌЕФHbaseЗўЮёЦїДцДЂВЛЭЌЕФЪ§ОнЗжЦЌЃЌ ЫљгаЪ§ОнЗжЦЌЕФзмКЭРДОЭЪЧHBaseДцДЂЕФЫљгаЪ§ОнЁЃ

вызЂ: ЩЯЭМЃЌЪ§ОнИљОнжїМќ(row key)ЗжХфЕН3ЬЈВЛЭЌЕФЗўЮёЦїЩЯ
HBaseЕФЪ§ОнФЃаЭ
HBaseИљОнжїМќ(row key)ЃЌЗжЦЌЃЌДцДЂЪ§ОнЁЃHBaseЕФжїМќ(row key)КЭЙиЯЕаЭЪ§ОнПтЕФжїМќ(primary
key)зїгУЗЧГЃРрЫЦЁЃ HBaseЩЯУцЕФЫљгаааАДеежїМќЕФжЕХХађЃЌМДжїМќаЁЕФааХХдкБэЕФЧАУцЁЃHBaseЕФЪ§ОнАДеежїМќ(row
key)гаађХХСаЪЧHBaseЧјБ№гкЦфЫћЗжВМЪНЪ§ОнПтЕФживЊЬиеї
[вызЂЃКЖдБШapache cassandra, cassandraЕФpartition keyЪЧЮоађЕФ]

[вызЂ: ЩЯЭМЃЌДгТпМЩЯПДЃЌHBaseЕФБэКЭДЋЭГЪ§ОнКмРрЫЦЃЌДгКьПђжаПЩвдПДГіЪ§ОнАДеежїМќЕФДѓаЁЫГађХХСа,smithjБШspataаЁЃЌвђЮЊЫфШЛЕквЛИіsвЛбљЃЌЕЋЪЧЕкЖўИізжФИmЕФasciiТыЪЧ109,
pЕФЪЧ112ЃЌЫљвдsmithjБШspataаЁ
ЯТЭМжа, HBaseБэАДеежїМќ(row key)ЕФЗЖЮЇ, ЗжГЩВЛЭЌЕФЧјгђ(region). ШЛКѓАбетаЉЧјгђ(region)ЗжХфИјВЛЭЌЕФЧјгђЗўЮёЦї(region
server)ЙмРэ. етжжЗжХфЗНЪНгЩHBaseздЖЏПижЦЃЌздЖЏЕїНкЧјгђЗўЮёЦї(region server)жаЕФДцДЂШнСП,
етбљОЭЪЕЯжСЫДцДЂЪ§ОнЕФЮоЯоРЉеЙЁЃ

ЯТЭМЯдЪОСЫСаДи(column family)КЭHBaseБэжЎМфЕФЖдгІЙиЯЕЃЌВЛЭЌЕФСаДи(column)дкЮяРэЩЯБЛДцДЂдкВЛЭЌЕФЮФМўжаЁЃУПИіСаДиЮФМўЖМПЩвдБЛЕЅЖРЗУЮЪ

вызЂЃКжїМќ(row key)ДгaxxxЕНgxxxБЛЗжХфЕНСЫвЛЬЈЧјгђЗўЮёЦї(region server)
R1ЩЯУцЃЌ етИіtableга2ИіСаДи:CF1КЭCF2ЃЌ ЯрЕБгк2ИіЖРСЂЕФЮФМўЃЌЖМДцДЂдкHDFSЩЯ
Ъ§ОнДцДЂдкHBaseБэИёЕФcellжаЁЃcellжаАќКЌkeyКЭvalueвдМАвЛаЉЦфЫћЕФаХЯЂЃЈШчversion,
typeЕШЃЉЁЃЦфжаkeyВПЗжАќРЈrow keyЃЌcolumn familyЃЌcolumn qualifier,
timestampЁЃВЂЧвЖдгкУПвЛИіжЕЃЌkeyКЭvalueКЭвЛЦ№ДцДЂдкСаДи(column family)РяЁЃШчЯТЭМЫљЪО:

СаДиЮФМўРяУцЕФЪ§ОнАДееCellЕФЗНЪНДцДЂЁЃ УПИіCellБЛГЦЮЊвЛИіМќжЕЖд(KeyValue)ЁЃ KeyАќРЈЕФЯюФПБШНЯЖрЃЌгажїМќ(rowkey)ЃЌСаДиЕФУћГЦ(column
family), column qualifierКЭЪБМфДС(timestamp)ЁЃ гЩетЫФЯюЕФзщГЩвЛИіKeyЃЌЭЈЙ§етИіKeyОЭПЩвддкСаДиЮФМўжаВщбЏЕНValue.
ДгТпМЩЯПДЃЌCellКУЯёДцДЂдкБэжаЕФвЛааЁЃЕЋЪЧдкЪЕМЪЮяРэДцДЂжаЃЌHBaseЕФвЛаагЩгаЖрИіСаДиЃЈcolumn
family)ЕФЖдгІCellЦДНгЖјГЩЁЃ
ЯТЭМЫљЪОЃЌ дкЩЯУцЕФБэЯдЪОСЫвЛИіHbaseБэНсЙЙЃЌ ДгТпМЩЯПДКЭЙиЯЕаЭЪ§ОнПтРрЫЦЃЌвВЪЧАДаазщжЏЁЃЕЋдкЮяРэДцДЂжаЃЌећИіБэЪЧгЩ2ИіСаДиЮФМўзщГЩЁЃШчЙћвЊаоИФФГаажаЕФвЛЯюЃЈЪЕМЪЩЯЪЧвЛИіCellЃЉ,
ашвЊжИЖЈжїМќ(rowkey)ЃЌСаДиЕФУћГЦ(column family), column qualifierКЭЪБМфДС(timestamp)аЮГЩвЛИіKeyЃЌ
ШЛКѓдкЪЕМЪЕФСаДиЮФМўжаЩшжУValueЁЃ

ТпМЪ§ОнФЃаЭ vs ЮяРэДцДЂФЃаЭ
ШчЧАЫљЪіЃЌ ЖЈЮЛвЛИіCell, жЛашвЊ5ЯюЪ§ОнЦДГЩKey: <БэУћГЦ, жїМќУћГЦ, СаДиУћГЦ,
СаУћГЦ, ЪБМфДС> . HBaseЕФБэЪЧвЛИіЯЁЪшБэЁЃ ШчЙћвЛЯю(column)УЛгаЪ§ОнЃЌЫќОЭВЛЛсБЛДцДЂ.
ДЫЭт, CellЪЧгаАцБОаХЯЂЕФЃЌШчЙћжЛгУ4ЯюЪ§ОнзіKey, <БэУћГЦ, жїМќУћГЦ, СаДиУћГЦ,
СаУћГЦ>ПЩвдВщбЏЕНвЛИіCellЕФЖрИіАцБО.

HBaseФЌШЯжЇГжЖрАцБОЃЌ
PutВйзїМШЪЧвЛИіВхШыВйзївВПЩвдЪЧвЛИіаоИФВйзїЃЌУПИіCellЖМгаздМКЕФАцБОЁЃЩОГ§ВйзїВЛЛсецЕФзіЩОГ§ЃЌжЛЪЧаДШывЛИіЩОГ§ЕФБъжОЁЃ
ШЮКЮВщбЏЖМВЛЛсЗЕЛигагаЩОГ§БъМЧЕФCell.
GetВйзїПЩвдШЮвтжИЖЈЕФАцБОЕФЪ§ОнЁЃШчЙћЧыЧѓУЛгажИЖЈАцБОКХЃЌЛсЗЕЛизюаТЕФАцБОЁЃHBaseдЪаэгУЛЇХфжУзюЖрдЪаэЖрЩйАцБОЭЌЪБДцдкЃЌHBaseФЌШЯЮЊЭЌвЛИіCellзюЖрДцДЂ3ИіАцБОЁЃЕБГЌЙ§3ИіАцБОКѓЃЌзюРЯАцБОЕФCellЛсБЛзюжеЧхРэЁЃ

|





