| 编辑推荐: |
| 本文来自于csdn,本文介绍了Web系统的搭建,需要从实际业务应用的角度出发,具体问题需要具体分析,寻求最合适的技术方案。 |
|
一、越来越多的并发连接数
现在的Web系统面对的并发连接数在近几年呈现指数增长,高并发成为了一种常态,给Web系统带来不小的挑战。以最简单粗暴的方式解决,就是增加Web系统的机器和升级硬件配置。虽然现在的硬件越来越便宜,但是一味地通过增加机器来解决并发量的增长,成本是非常高昂的。结合技术优化方案,才是更有效的解决方法。
并发连接数为什么呈指数增长?实际上,从这几年的用户基数上看,这个数量并没有出现指数增长,因此它并非主要原因。主要原因,还是web变得更复杂,交互更丰富所导致的。
1. 页面元素增多,交互复杂
Web页面元素越来越多,更为丰富。更多的资源元素,意味着更多的下载请求。Web系统的交互越来越复杂,交互场景和次数也大幅增加。以“www.qq.com”的首页为例子,刷新一次,大概会有244个请求。并且,在页面打开完成之后,还会有一些定时的查询或者上报请求持续运作。

目前的Http请求,为了减少反复的创建和销毁连接行为,通常都建立长连接(Connection keep-alive)。一经建立,这个连接会被保持住一段时间,被后续请求复用。然而,它也带来了另一个新的问题,连接的保持是会占用Web系统服务端资源的,如果不充分使用这个连接,会导致资源浪费。长连接被创建后,首批资源传输完毕,之后几乎没有数据交互,一直到超时时间,才会自动释放长连接占据的系统资源。

除此之外,还有一些Web需求本身就需要长期保持连接的,例如Web socket。
2. 主流的浏览器的连接数在增加
面对越来越丰富的Web资源,主流浏览器并发连接数也在增加,同一个域下,早期的浏览器一般只有1-2个下载连接,而目前的主流浏览器通常在2-6个。增加浏览器并发连接数目,在需要下载资源比较多的场景下,可以加快页面的加载速度。更多的连接对浏览器加载页面元素是有好处的,在某些连接遭遇“网络阻塞”的情况下,其他正常的下载连接可以继续工作。
这样自然无形增加了Web系统后端的压力,更多的下载连接意味着占据了更多的Web服务器的资源。而在用户访问高峰期,自热而然就形成了“高并发”场景。这些连接和请求,占据了服务器的大量CPU和内存等资源。尤其在资源数目超过100+的网站页面中,使用更多的下载连接,非常有必要。
二、Web前端优化,降低服务端压力
在缓解“高并发”的压力,需要前端和后端的共同配合优化,才能达到最大效果。在用户第一线的Web前端,可以起到减少或者减轻Http请求的效果。
1. 减少Web请求
常用的实现方法是通过Http协议头中的expire或max-age来控制,将静态内容放入浏览器的本地缓存,在之后的一段时间里,不再请求Web服务器,直接使用本地资源。还有HTML5中的本地存储技术(LocalStorage),也被作为一个强大的数据本地缓存。
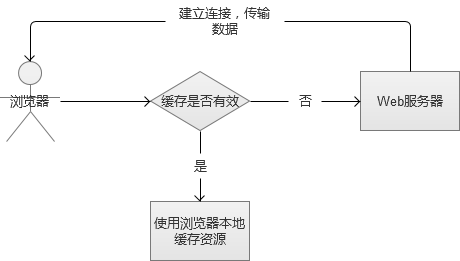
这种方案缓存后,根本不发送请求到Web服务器,大幅降低服务器压力,也带来了良好的用户体验。但是,这种方案,对首次访问的用户无效,同时,也影响部分Web资源的实时性。
2. 减轻Web请求
浏览器的本地缓存是存在过期时间的,一旦过期,就必须重新向服务器请求。这个时候,会有两种情形:
(1)服务器的资源内容没有更新,浏览器请求Web资源,服务器回复“可以继续使用本地缓存”。(发生通信,但是Web服务器只需要做简单“回复”)
(2)服务器的文件或者内容已经更新,浏览器请求Web资源,Web服务器通过网络传输新的资源内容。(发生通信,Web服务器需要完成复杂的传输工作)
这里的协商方式是通过Http协议的Last-Modified或Etag来控制,这个时候请求服务器,如果是内容没有发生变更的情况,服务器会返回304
Not Modified。这样的话,就不需要每次请求Web服务器都做复杂的传输完整数据文件的工作,只要简单的http应答就可以达到相同的效果。

虽然上述请求,起到“减轻”Web服务器的压力,但是连接仍然被建立,请求也发生了。
3. 合并页面请求
如果是比较老一些的Web开发者,应该会更有印象,在ajax盛行之前。页面大部分都是直接输出的,并没有这么多的ajax请求,Web后端将页面内容完全拼凑好了,再返回给前端。那个时候,页面静态化,是一个挺广泛的优化方式。后来,被交互更友好的ajax渐渐替代了,一个页面的请求也变得越来越多。
由于移动端的网络(2G/3G)比起PC宽带差很多,并且部分手机配置比较低,面对一个超过100个请求的网页,加载的速度会缓慢很多。于是,优化的方向又重新回到合并页面元素,减少请求数量:
(1)合并HTML展示内容。将CSS和JS直接嵌入到HTML页面内,不通过连接的方式引入。
(2)Ajax动态内容合并请求。对于动态内容,将10次Ajax请求合并为1次的批量信息查询。
(3)小图片合并,通过CSS的偏移量技术Sprites,将很多小图片合并为一张。这个优化方式,在PC端的Web优化中,也非常常见。


合并请求,减少了传输数据的次数,也就是相当于将它们从一个一个地请求,变为一次的“批量”请求。上述优化方法,到达“减轻”Web服务器压力的目的,减少了需要建立的连接。
三、 节约Web服务端的内存
前端的优化完成,我们就需要着眼于Web服务端本身。内存是Web服务器非常重要的资源,更多的内存通常意味着可以同时放入更多的工作任务。就Web服务占用内存而言,可以粗略划分:
(1)用来维持连接的基本内存,进程初始化时,会载入一些基础模块到内存。
(2)被传输的数据内容载入到各个缓冲区,占据的内存。
(3)程序执行过程中,申请和使用的内存。
如果维持一个连接,能够尽可能少占用内存,那么我们就可以维持更多的并发连接,从而让Web服务器支持更多的并发连接数。
Apache(httpd)是一个成熟并且古老的Web服务,而Apache的发展和演变,一直在追求做到这一点,它试图不断减少服务占据的内存,以支持更大的并发量。以Apache的工作模式的演变为视角,我们一起来看看,它们是如何优化内存的问题的。
MPM: 多处理模块
1. prefork MPM,多进程工作模式
prefork是Apache最成熟和稳定的工作模式,即使是现在,仍然被广泛使用。主进程生成后,它先完成基础的初始化工作,然后,通过fork预先产生一批的子进程(子进程会复制父进程的内存空间,不需要再做基础的初始化工作)。然后等待服务,之所以预先生成,是为了减少频繁创建和销毁进程的开销。多进程的好处,是进程之间的内存数据不会相互干扰,同时,某个进程异常终止也不会影响其他进程。但是,就内存而言,每个httpd子进程占用了很多的内存,因为子进程的内存数据是复制父进程的。我们可以粗略认为,这里存在大量的“重复数据”被放在内存中。最终,导致我们能够生成的子进程最大数量是很有限。在面对高并发时,因为有不少Keep-alive的长连接,将这些子进程“霸占”住,很可能导致可用子进程耗尽。因此,prefork并不太适合高并发场景。

优点:成熟稳定,兼容所有新老模块。同时,不需要担心线程安全的问题。(例如,我们常用的mod_php,将PHP编译为Apache的子模块,就不需要支持线程安全)
缺点:一个服务进程占用很多内存。
2. worker MPM,多进程和多线程的混合模式
worker模式比起prefork,是使用了多进程和多线程的混合模式。它也预先fork了几个子进程(数量很少),然后每个子进程创建一些线程(其中包括一个监听线程)。每个请求过来,会被分配到1个线程来服务。线程比起进程会更轻量,因为线程通常会共享父进程的内存空间,因此,内存的占用会减少一些。在高并发的场景下,因为比起prefork更省内存,因此会有更多的可用线程。

但是,它并没有解决Keep-alive的长连接“霸占”线程的问题,只是对象变成了比较轻量的线程。
有些人会觉得奇怪,那么这里为什么不完全使用多线程呢,还要引入多进程?因为还需要考虑稳定性,如果一个线程挂了,会导致同一个进程下其他正常的子线程都挂了。如果全部采用多线程,某个线程挂掉,就导致整个Apache服务“全军覆没”。而目前的工作模式,受影响的只是Apache的一部分服务,而不是整个服务。
线程共享父进程的内存空间,减少了内存的占用,却又引起了新的问题。就是“线程安全”,多个线程修改共享资源导致的“竞争行为”,又强迫我们所使用的模块必须支持“线程安全”。因此,它有一定程度上增加Web服务的不稳定性。例如,mod_php所使用的PHP拓展,也同样需要支持“线程安全”,否则,不能在该模式下使用。
优点:占据更少的内存,高并发下表现更优秀。
缺点:必须考虑线程安全的问题,同时锁的引入又增加了CPU的开销。
3. event MPM,多进程和多线程的混合模式,引入Epoll
这个是Apache中比较新的模式,在现在的版本(Apache 2.4.10)已经是稳定可用的模式。它和worker模式很像,最大的区别在于,它解决了keep-alive场景下,长期被占用的线程的资源浪费问题。event
MPM中,会有一个专门的线程来管理这些keep-alive类型的线程,当有真实请求过来的时候,将请求传递给服务线程,执行完毕后,又允许它释放。它减少了“占据”连接而又不使用的资源浪费,增强了高并发场景下的请求处理能力。因为减少了“闲等”的线程,线程的数量减少,同等场景下,内存占用会下降一些。

event MPM在遇到某些不兼容的模块时,会失效,将会回退到worker模式,一个工作线程处理一个请求。新版Apache官方自带的模块,全部是支持event
MPM的。注意一点,event MPM需要Linux系统(Linux 2.6+)对EPoll的支持,才能启用。Apache的三种模式中在真实应用场景中,event
MPM是最节约内存的。
4. 使用比较轻量的Nginx作为Web服务器
虽然Apache的不断优化,减少了内存占用,从而增加了处理高并发的能力。但是,正如前面所说,Apache是一个古老而成熟的Web服务,同时,集成很多稳定的模块,是一个比较重的Web服务。Nginx是个比较轻量的Web服务,占据的内存天然就少于Apache。而且,Nginx通过一个进程来服务于N个连接。所使用的方式,并不是Apache的增加进程/线程来支持更多的连接。对于Nginx来说,它少创建了大量的进程/线程,减少了很多内存的开销。

静态文件的QPS性能压测结果,Nginx性能大概3倍于Apache对静态文件的处理。PHP等动态文件的QPS,Nginx的做法通常是通过FastCGI的方式和PHP-FPM通信的方式完成,PHP作为一个与之无关的外部服务存在。而Apache通常将PHP编译为自己的字模块(新版的Apache也支持FastCGI)。PHP动态文件,Nginx的表现略逊于Apache。
5. sendfile节约内存
Apache、Nginx等不少Web服务,都带有sendfile支持的。sendfile可以减少数据到“用户态内存空间”(用户缓冲区)的拷贝,进而减少内存的占用。当然,很多同学第一个反应当然是问Why?为了尽可能清楚讲述这个原理,我们就先回Linux内核态和用户态的存储空间的交互。
一般情况下,用户态(也就是我们的程序所在的内存空间)是不会直接读写或者操作各种设备(磁盘、网络、终端等),中间通常用内核作为“中间人”,来完成对设备的操作或者读写。
以最简单的磁盘读写例子,从磁盘中读取A文件,写入到B文件。A文件数据是从磁盘开始,然后载入到“内核缓冲区”,然后再拷贝到“用户缓冲区”,我们才可以对数据进行处理。写入的时候,也同理,从“用户态缓冲区”载入到“内核缓冲区”,最后写入到磁盘B文件。

这样写文件很累吧,于是有人觉得这里可以跳过“用户缓冲区”的拷贝。其实,这就是MMP(Memory-Mapping,内存映射)的实现,建立一个磁盘空间和内存的直接映射,数据不再复制到“用户态缓冲区”,而是返回一个指向内存空间的指针。于是,我们之前的读写文件例子,就会变成,A文件数据从磁盘载入到“内核缓冲区”,然后从“内核缓冲区”复制到B文件的“内核缓冲区”,B文件再从”内核缓冲区“写回到磁盘中。这个过程,减少了一次内存拷贝,同时也少内存占用。

好了,回到sendfile的话题上来,简单的说,sendfile的做法和MMP类似,就是减少数据从”内核态缓冲区“到”用户态缓冲区“的内存拷贝。
默认的磁盘文件读取,到传输给socket,流程(不使用sendfile)是:

使用sendfile之后:

这种方式,不仅节省了内存,而且还有CPU的开销。
四、节约Web服务器的CPU
对Web服务器而言,CPU是另一个非常核心的系统资源。虽然一般情况下,我们认为业务程序的执行消耗了我们主要CPU。但是,就Web服务程序而言,多线程/多进程的上下文切换,也是比较消耗CPU资源的。一个进程/线程通常不能长期占有CPU,当发生阻塞或者时间片用完,就无法继续占用CPU,这个时候,就会发生上下文切换,CPU时间片从老进程/线程切换到新的。除此之外,在并发连接数目很高的场景下,对这些用户建立的连接(socket文件描述符)状态的轮询和检测,也是比较消耗CPU的。
而Apache和Nginx的发展和演变,也在努力减少CPU开销。

1. Select/Poll(Apache早期版本的I/O多路复用)
通常,Web服务都要维护很多个和用户通信的socket文件描述符,I/O多路复用,其实就是为了方便对这些文件描述符的管理和检测。Apache早期版本,是使用select的模式,简单的说,就是将这些我们关注的socket文件描述符交给内核,让内核告诉我们,那些描述符可操作。Poll与select原理基本相同,因此放在一起,它们之间的区别,就不赘叙了哈。
select/poll返回的是一个我们之前提交的文件描述符集合(内核将其中可读、可写或者异常状态的socket文件描述符的标识位修改了),我们需要通过轮询检查才能获得我们可以操作的文件描述符。在这个过程中,不断重复执行。在实际应用场景中,大部分被我们监控的socket文件描述符,都是”空闲的“,也就是说,不能操作。我们对整个集合轮询,就是为了找了少部分我们可以操作的socket文件描述符。于是,当我们监控的socket文件描述符越多(用户并发连接数越来越多),这个轮询工作,也就越来越沉重,进而导致增大了CPU的开销。
如果我们监控的socket文件描述符,几乎都是”活跃的“,反而使用这种模式更合适一点。
2. Epoll(新版的Apache的event MPM,Nginx等支持)
Epoll是Linux2.6开始正式支持的I/O多路复用,我们可以理解为它是对select/poll的改进。首先,我们同样将我们关注的socket文件描述符集合告诉给内核,同时,给它们注册”回调函数“,如果某个socket文件准备好了,就通过回调函数通知我们。于是,我们就不需要专门去轮询整个全量的socket文件描述符集合,直接可以得到已经可操作的socket文件描述符。那么,那些大部分”空闲“的描述符,我们就不遍历了。即使我们监控的socket文件描述越来越多,我们轮询的也只是”活跃可操作“的socket文件描述符。

其实,有一种极端点的场景,就是我们全部文件描述符几乎都是”活跃“的,这样反而导致了大量回调函数的执行,又增加了CPU的开销。但是,就Web服务的真实场景,绝大部分时候,都是连接集合中都存在很多”空闲“连接。
3. 线程/进程的创建销毁和上下文切换
通常,Apache某一个时间内,是一个进程/线程服务于一个连接。于是,Apache就有很多的进程/线程,服务于很多的连接。Web服务在高峰期,会建立很多的进程/线程,也就带来很多的上下文切换开销。而Nginx,它通常只有1个master主进程和几个worker子进程,然后,1个worker进程服务很多个连接,进而节省了CPU的上下文切换开销。

两种模式虽然不同,但实际上不能直接出分好坏,综合来说,各有各自的优势,就不妄议了哈。
4. 多线程下的锁对CPU的开销
Apache中的worker和event模式,都有采用多线程。多线程因为共享父进程的内存空间,在访问共享数据的时候,就会产生竞争,也就是线程安全问题。因此通常会引入锁(Linux下比较常用的线程相关的锁有互斥量metux,读写锁rwlock等),成功获取锁的线程可以继续执行,获取失败的通常选择阻塞等待。引入锁的机制,程序的复杂度往往增加不少,同时还有线程“死锁”或者“饿死”的风险(多进程在访问进程间共享资源的时候,也有同样的问题)。
死锁现象(两个线程彼此锁住对方想要获取的资源,相互阻塞等待,永远无法达不到满足条件):

饿死现象(某个线程,一直获取不到它想要锁资源,永远无法执行下一步):
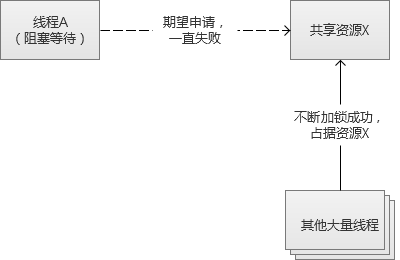
为了避免这些锁导致的问题,就不得不加大程序的复杂度,解决方案一般有:
(1)对资源的加锁,根据约定好的顺序,大家都先对共享资源X加锁,加锁成功之后才能加锁共享资源Y。
(2)如果线程占有资源X,却加锁资源Y失败,则放弃加锁,同时也释放掉之前占有的资源X。
在使用PHP的时候,在Apache的worker和event模式下,也必须兼容线程安全。通常,新版本的PHP官方库是没有线程安全方面的问题,需要关注的是第三方扩展。PHP实现线程安全,不是通过锁的方式实现的。而是为每个线程独立申请一份全局变量的副本,相当于线程的私人内存空间,但是这样做相对消耗多一些内存。不过,这样的好处,是不需要引入复杂的锁机制实现,也避免了锁机制对CPU的开销。
这里顺便提到一下,经常和Nginx搭配工作的PHP-FPM(FastCGI)使用的是多进程,因此不会有线程安全的问题。

五、 小结
可能有些同学看完之后,会得出结论,Nginx+PHP-FPM的工作方式,似乎是最节省系统资源的Web系统工作方式。某种程度上说,的确是可以这么说的,但是Web系统的搭建,需要从实际业务应用的角度出发,具体问题需要具体分析,寻求最合适的技术方案。
Web服务的不断演变和发展,努力地追求用尽可能少的系统资源,来支撑更多的用户请求,这是一条波澜壮阔的前进之路。这些技术方案,汇聚了很多值得学习和借鉴的解决问题的思路。 |








