| 一.性能剖析功能介绍
1.性能剖析功能的原理简述
性能剖析是一个低强度分析工具,可以用在生产应用程序中识别瓶颈。
它是在指定时间范围(持续时间)内定时(采样周期)的调用系统中断,然后收集当前的调用栈(call stack
Trace)信息,记录调用栈中出现的函数及这些函数的调用结构,基于这些信息得到函数的调用关系图及每个函数的
CPU 使用信息。通过这些信息,我们可以清楚的看到时间是花费在哪一个方法的哪一行上,从而有针对性的进行代码的优化。
详细数据介绍:性能剖析相关知识
我们的Ai产品中有两种方法可以进行性能剖析的设置,分别是 应用>tier>性能剖析 以及
关键事务>性能剖析。
2.应用>tier>性能剖析
针对单个实例,进行线程的抓取。
默认设置: 持续时间:2min; 采样周期:100ms 可以根据需要进行调整。

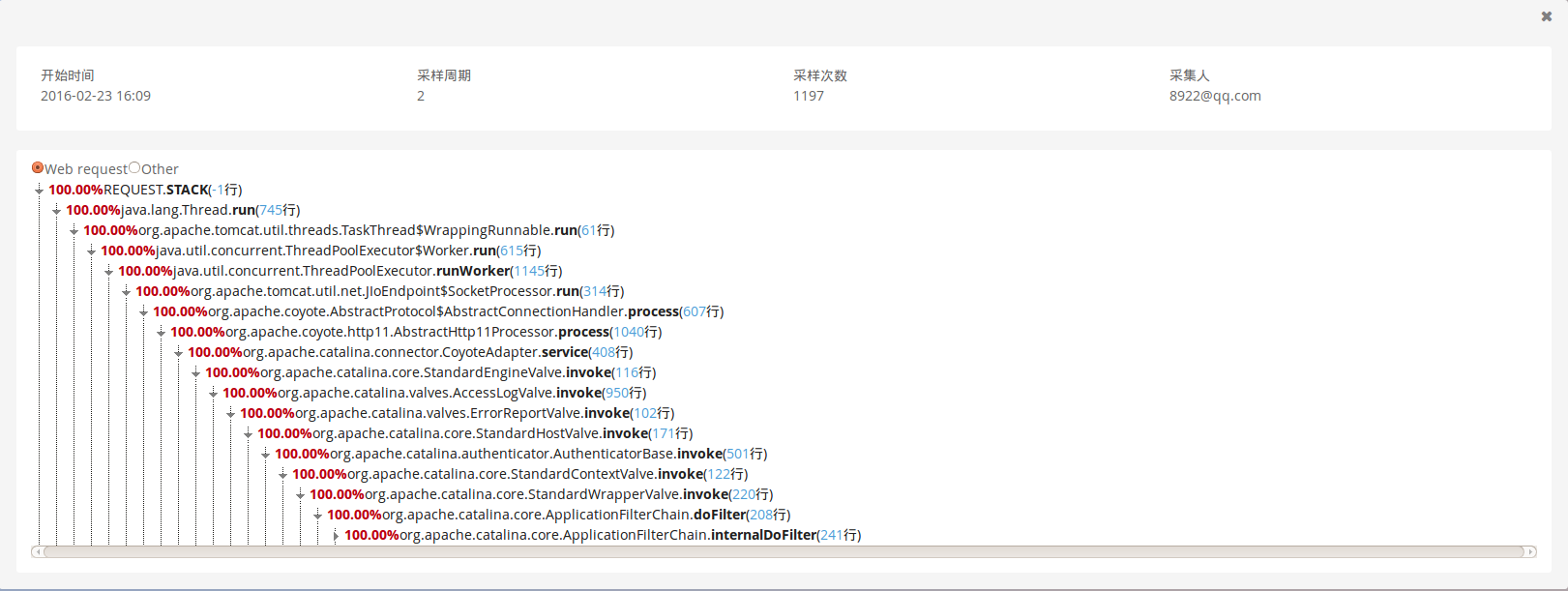
剖析页面:
剖析页面即线程分析页面,其中包含性能剖析的开始时间、采样周期、采样次数、采样人以及调用栈信息。
调用栈信息可以根据需要进行展开和收缩。
此处的百分比是根据在采样周期中,该行代码总计被采样到的次数与总采样次数的百分比。代码后括号中的内容是该代码在事务中的行数。
3.关键事务>性能剖析
关键事务>性能剖析 抓取的结果 是 应用>tier>性能剖析 的一个子集。针对的是
选定探针对应的关键事务 (一类请求)进行线程的抓取。
对于某个关键事务来说只能同时对多个不同探针进行多个性能剖析。(一个探针一次只能做一个性能剖析)

默认设置: 持续时间:60 min; 采样周期:1000 ms 可以根据需要进行调整。
注:采样周期和持续时间 只能在开始创建性能剖析时进行设定。

剖析页面:
关键事务的新能剖析由总览和线程分析和性能剖析信息(对应的关键事务和应用名称,开始时间、状态和采样次数)。

总览页面 展示了抓取到的全部的trace数据以及Trace响应时间分布,响应时间&吞吐量,APP
Server Breakdown和耗时最长的统计等图表。
下面是可以进行深度链接操作的简要总结:

线程分析页面
调用栈信息可以根据需要进行展开和收缩。
此处的百分比是根据在采样周期中,该行代码总计被采样到的次数与总采样次数的百分比。代码后括号中的内容是该代码在事务中的行数。
停到某个类的某个方法比如 get 的方法,一般都是由于在进行密集计算,或者调用数据库但是数据库长时间没有返回结果,或者数据库中有锁。如果是
cpu 慢,就会出现在这里;如果由于锁等原因,就会出现在线程和锁的标签页中。
时间分布图的百分比计算: 该行代码总计被采样到的次数与总采样次数的百分比
CPU时间图的百分比计算: 该行代码总计在runable状态被采样到的次数与总采样次数的百分比。 可以理解是该方法在这类请求中的对于CPU开销占比。
线程和锁图的百分比计算:该行代码总计在norunable状态被采样到的次数与总采样次数的百分比。 可以理解是该方法在这类请求中的对于处于blocked状态时间的占比。

注:如果想要进行 关键事务>性能剖析 则需要预先将要进行性能剖析的Web 事务设为关键事务,且性能剖析进行时必须确保剖析的探针具有持续的访问。
设置方法如下,

二.我遇到过的用户案例分析
1.问题类型:过度加载动态类导致性能下降
问题现象:
客户在进行一次大的负载测试,在负载相同的情况下,应用的响应时间在6个小时左右的时间内逐步上升,最终上升到了一个不可容忍的情况,应用的平均响应时间达到6s。
问题调查和分析:
我们在测试的后期,使用 JVM 性能剖析功能 发现,客户代码有超过50%以上的时间集中在java.lang.classloader.defineclass动态类加载上,这明显是一个由于过度的动态类加载造成的应用缓慢。

同时结合JVM中对于class count的监控,发现客户的class count(1.5W的活动类加载,25w的卸载类):

class count的运行应该是比较平稳的:

这个问题的后续:
客户开发团队根据 性能剖析的结果发现,适由于他们在格式转换使用的框架导致的大量类不断地被加载和卸载,在经过客户团队的修改后,再次进行的负载测试运行6小时内,平均响应时间都维持在600ms左右,并且通过对于class
count的检测,发现卸载类的数量明显有一个大幅度的下降。

2.问题类型:不正确的thread sleep使用导致性能下降
问题现象:
客户在进行一次营销秒杀活动,每个小时都会有10分钟高并发访问,在这10分钟高并发的时段,客户终端请求有大量502报错。
问题调查和分析:
第一阶段:
分析高峰时期的CPU使用情况,线程使用情况,响应时间情况,吞吐量情况(这是我非常喜欢的一个关联分析,能有效定位客户是不是因为CPU开销导致的性能问题),发现响应时间/吞吐量大幅度上涨,线程池用尽,但是CPU使用虽然有所上涨,但是远远未达到上限。

同时结合客户终端请求有大量502报错。
初步分析是因为线程池用尽,导致请求堵塞在请求队列中,最后导致大量请求访问超时,报502错误。
给出建议操作: 增大线程池最大线程数量,继续观察。
第二阶段:
此时给出的相关建议:线程是一种十分宝贵的资源,创建,销毁,切换 都是相当耗性能的,当Sleep的时候,就等于说:现在我不用,但是你也别想用。你要用,自己去Create一个。当creat的线程到底最大值以后,请求就只能阻塞在请求队列中了。因此sleep的时候虽然不占用CPU,但是占着线程资源,会严重阻碍系统的线程调度。
增大线程池最大线程数量以后,高峰期访问性能并没有得到提高,我们需要进一步分析。
由a1进一步分析:应用表现出性能的下降,却没有观察到CPU占用的提高,那就表示线程可能在等待I/O或是其他一些操作的结果。
同时通过 JVM性能剖析功能,发现确实用户在 发起对于后台系统调用 以后会进入都会进入thread.sleep。(时间太久找不到图,就不提供截图了。)
与客户开发确认后发现,在调用 交易平台 后端的 client.jar包中每次调用发起以后都会调用thread.sleep进行线程休眠(休眠时间与thread数量成正比)。
经过现场与客户后台系统开发确认,为了保证前台系统的正常运行,临时取消了thread.sleep的调用。同时在客户后台系统加装探针,调整线程池大小,确认后台系统可能的瓶颈。
第三阶段:
经过第二阶段调整,压力成功由前台系统传导至后台系统,而后台系统存在大量update操作缓慢,导致数据库连接用尽的情况。(如何使用AI发现和诊断由于数据库调用产生的性能问题
一文中的问题3和问题4的现象,这里就不在详述。)
经过优化update语句,增加数据库连接池数量等操作,使用户的响应时间访问速度得到大方提高,故障有所缓解。
3.问题类型:应用性能异常缓慢
问题现象:客户系统办理业务异常缓慢打不开。
问题调查和分析:
我们分析客户系统响应时间占比最高的事务为xxx,占比达到57%:

我们将其设为关键事务,然后进行性能剖析发现是由于其数据库查询时间过长,导致数据库库的连接数不够导致系统故障

随后通过采取重建用户表、增加数据库连接数和重启APP实例等措施,使故障情况有所好转,缓慢问题得到解决。
|





