| БрМЭЦМі: |
БОЮФжївЊНщЩм 5 жжзюСїааЕФЩюЖШбЇЯАМмЙЙ,ШЛКѓЬНЬжгУгкЩюЖШбЇЯАЕФПЊдДШэМўбЁЯюЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкcsdnЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
СЌНгжївхЬхЯЕНсЙЙвбДцдк 70 ЖрФъЃЌЕЋаТЕФМмЙЙКЭЭМаЮДІРэЕЅдЊ (GPU)
НЋЫќУЧЭЦЕНСЫШЫЙЄжЧФмЕФЧАбиЁЃЩюЖШбЇЯАМмЙЙЪЧзюНќ 20 ФъФкЕЎЩњЕФЃЌЫќЯджјдіМгСЫЩёОЭјТчПЩвдНтОіЕФЮЪЬтЕФЪ§СПКЭРраЭЁЃБОЮФНЋНщЩм
5 жжзюСїааЕФЩюЖШбЇЯАМмЙЙЃКЕнЙщЩёОЭјТч (RNN)ЁЂГЄЖЬЦкМЧвф (LSTM)/УХПиЕнЙщЕЅдЊ (GRU)ЁЂОэЛ§ЩёОЭјТч
(CNN)ЁЂЩюЖШаХФюЭјТч (DBN) КЭЩюЖШЕўМгЭјТч (DSN)ЃЌШЛКѓЬНЬжгУгкЩюЖШбЇЯАЕФПЊдДШэМўбЁЯюЁЃ
ЩюЖШбЇЯАВЛЪЧЕЅИіЗНЗЈЃЌЖјЪЧвЛРрПЩгУРДНтОіЙуЗКЮЪЬтЕФЫуЗЈКЭЭиЦЫНсЙЙЁЃЩюЖШбЇЯАЯдШЛвбВЛЪЧаТИХФюЃЌЕЋЩюЖШЗжВуЩёОЭјТчКЭ
GPU ЕФНсКЯЪЙгУМгЫйСЫЫќУЧЕФжДааЃЌЩюЖШбЇЯАе§дкЭЛЗЩУЭНјЕиЗЂеЙЁЃДѓЪ§ОнвВжњЭЦСЫетвЛЗЂеЙЪЦЭЗЁЃвђЮЊЩюЖШбЇЯАвРРЕгкМрЖНбЇЯАЫуЗЈЃЈетаЉЫуЗЈЪЙгУЪОР§Ъ§ОнбЕСЗЩёОЭјТчВЂИљОнГЩЙІЫЎЦНИјгшНБГЭЃЉЃЌЫљвдЪ§ОндНЖрЃЌЙЙНЈетаЉЩюЖШбЇЯАНсЙЙЕФаЇЙћОЭдНКУЁЃ
ЩюЖШбЇЯАгы GPU ЕФаЫЦ№
ЩюЖШбЇЯАгЩВЛЭЌЭиЦЫНсЙЙЕФЩюЖШЭјТчзщГЩЁЃЩёОЭјТчвбДцдкКмГЄвЛЖЮЪБМфЃЌЕЋЖрВуЭјТчЃЈУПИіВуЬсЙЉвЛЖЈЕФЙІФмЃЌБШШчЬиеїЬсШЁЃЉЕФПЊЗЂШУЫќУЧБфЕУИќМгЪЕгУЁЃдіМгВуЪ§втЮЖзХИїВужЎМфКЭВуФкгаИќЖрЯрЛЅСЊЯЕКЭИќЖрШЈжЕЁЃдкетРяЃЌGPU
ПЩЮЊЩюЖШбЇЯАДјРДжњвцЃЌЪЙбЕСЗКЭжДааетаЉЩюЖШЭјТчГЩЮЊПЩФмЃЈдЪМДІРэЦїдкетЗНУцЕФаЇТЪВЛЙЛИпЃЉЁЃ
GPU дквЛаЉЙиМќЗНУцгыДЋЭГЖрКЫДІРэЦїВЛЭЌЁЃЪзЯШЃЌвЛИіДЋЭГДІРэЦїПЩФмАќКЌ
4 ЈC 24 ИіЭЈгУ CPUЃЌЕЋвЛИі GPU ПЩФмАќКЌ 1,000 ЈC 4,000 ИізЈгУЪ§ОнДІРэКЫаФЁЃ
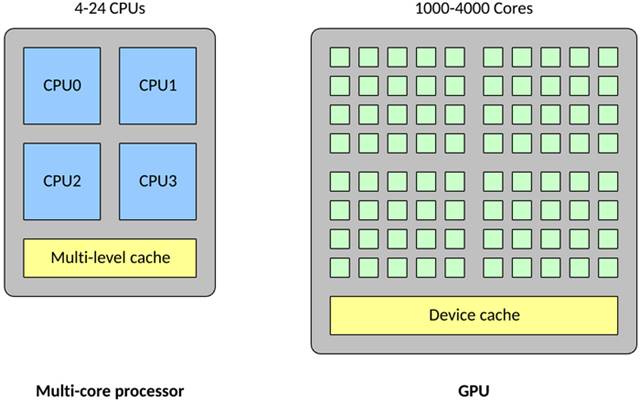
гыДЋЭГ CPU ЯрБШЃЌИпУмЖШЕФКЫаФЪЙЕУ GPU БфЕУИпЖШВЂааЛЏЃЈвВОЭЪЧЫЕЃЌЫќПЩвдвЛДЮжДаааэЖрДЮМЦЫуЃЉЁЃетЪЙЕУ
GPU ГЩЮЊДѓаЭЩёОЭјТчЕФРэЯыбЁдёЃЌдкетаЉЩёОЭјТчжаЃЌПЩвдвЛДЮМЦЫуаэЖрИіЩёОдЊЃЈДЋЭГ CPU ПЩвдВЂааДІРэЕФЪ§СПвЊЩйЕУЖрЃЉЁЃGPU
ЛЙЩУГЄИЁЕуЪИСПдЫЫуЃЌвђЮЊЩёОдЊФмжДааЕФдЫЫуВЛжЙЪЧЪИСПГЫЗЈКЭМгЗЈЁЃЫљгаетаЉЬиеїЪЙЕУ GPU ЩЯЕФЩёОЭјТчДяЕНЫљЮНЕФИпЖШВЂааЃЈвВОЭЪЧЭъУРВЂааЃЌМИКѕВЛашвЊЛЈОЋСІРДВЂааЛЏШЮЮёЃЉЁЃ
ЩюЖШбЇЯАМмЙЙ
ЩюЖШбЇЯАжаЪЙгУЕФМмЙЙКЭЫуЗЈЪ§СПЗсИЛЖрбљЁЃБОНкНЋЬНЬжЙ§ШЅ 20 ФъРДДцдкЕФЩюЖШбЇЯАМмЙЙжаЕФ
5 жжЁЃЯдШЛЃЌLSTM КЭ CNN ЪЧДЫСаБэжазюЙХРЯЕФСНжжЗНЗЈЃЌЕЋвВЪЧИїжжгІгУжаЪЙгУзюЖрЕФСНжжЗНЗЈЁЃ
етаЉМмЙЙБЛгІгУгкЙуЗКЕФГЁОАжаЃЌЕЋЯТБэНіСаГіСЫЫќУЧЕФвЛаЉЕфаЭгІгУЁЃ

ЯждкЃЌШУЮвУЧСЫНтвЛЯТетаЉМмЙЙКЭгУгкбЕСЗЫќУЧЕФЗНЗЈЁЃ
ЕнЙщЩёОЭјТч
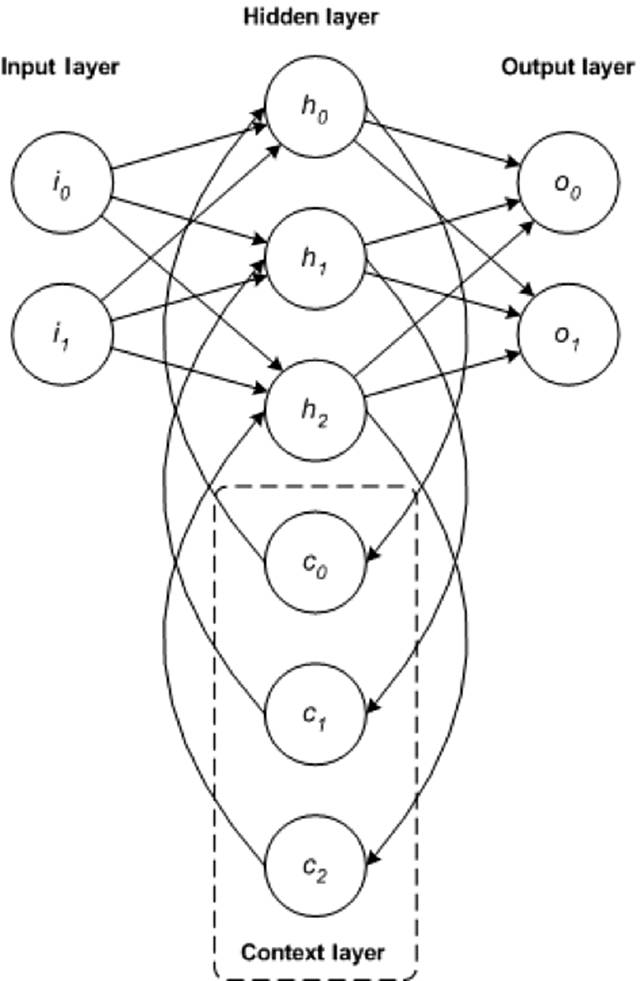
RNN ЪЧвЛжжЛљДЁЭјТчМмЙЙЃЌЦфЫћвЛаЉЩюЖШбЇЯАМмЙЙЪЧЛљгкЫќРДЙЙНЈЕФЁЃЕфаЭЖрВуЭјТчгыЕнЙщЭјТчжЎМфЕФжївЊВюБ№ЪЧЃЌЕнЙщЭјТчУЛгаЭъећЕФЧАРЁСЌНгЃЌЫќПЩФмгЕгаЗДРЁЕНЧАМИВуЃЈЛђЭЌвЛВуЃЉЕФСЌНгЁЃетжжЗДРЁЪЙ
RNN ФмБЃСєЖдЙ§ШЅЕФЪфШыЕФМЧвфВЂАДЪБМфЮЊЮЪЬтНЈФЃЁЃ
RNN АќКЌЗсИЛЕФМмЙЙЃЈНгЯТРДЮвУЧНЋЗжЮівЛжжУћЮЊ LSTM ЕФСїааЭиЦЫНсЙЙЃЉЁЃЙиМќЧјБ№дкгкЭјТчжаЕФЗДРЁЃЌетПЩвддквўВиВуЁЂЪфГіВуЛђЖўепЕФФГжжзщКЯжаЬхЯжГіРДЁЃ
RNN ПЩвдАДЪБМфеЙПЊВЂЭЈЙ§БъзМЗДЯђДЋВЅНјаабЕСЗЃЌЛђепЪЙгУвЛжжбиЪБМфЗДЯђДЋВЅ (BPTT) ЕФЗДЯђДЋВЅБфаЮРДбЕСЗЁЃ
LSTM/GRU ЭјТч
LSTM ЪЧ Hochreiter КЭ Schimdhuber гк 1997 ФъЙВЭЌДДНЈЕФЃЌзюНќМИФъЃЌзїЮЊвЛжжгУгкИїжжгУЭОЕФ
RNN МмЙЙЃЌLSTM БфЕУдНРДдНЪмЛЖгЁЃФњПЩвддкУПЬьЪЙгУЕФВњЦЗЃЈБШШчжЧФмЪжЛњЃЉжаЗЂЯж LSTMЁЃIBM
дк IBM Watson?жагІгУСЫ LSTMЃЌдкЖдЛАгявєЪЖБ№ЩЯШЁЕУСЫРяГЬБЎЪНЕФГЩОЭЁЃ
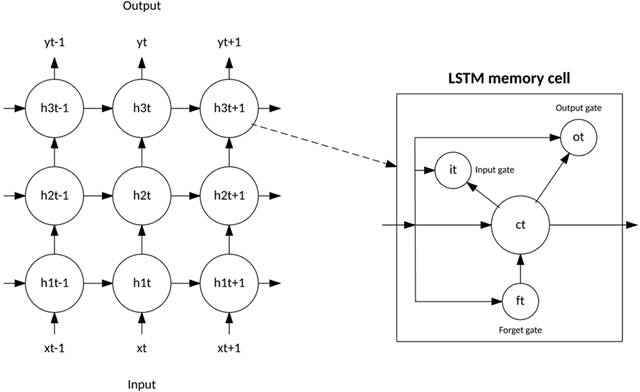
LSTM ЭбРыСЫЛљгкЕфаЭЩёОдЊЕФЩёОЭјТчМмЙЙЃЌв§ШыСЫМЧвфЯИАћЕФИХФюЁЃМЧвфЯИАћПЩвдзїЮЊЪфШыжЕЕФКЏЪ§ЃЌЖЬЪБМфЛђГЄЪБМфЕиБЃСєздЩэЕФдЫЫужЕЃЌетЪЙЕУИУЯИАћФмМЧзЁживЊЕФаХЯЂЃЌЖјВЛжЛЪЧЫќзюКѓМЦЫуЕФжЕЁЃ
LSTM МЧвфЯИАћАќКЌ 3 ИіПижЦаХЯЂШчКЮСїНјЛђСїГіЯИАћЕФУХЁЃЪфШыУХПижЦаТаХЯЂКЮЪБФмСїШыМЧвфжаЁЃвХЭќУХПижЦКЮЪБвХЭќвЛЖЮЯжгааХЯЂЃЌЪЙЯИАћФмМЧвфаТЪ§ОнЁЃзюКѓЃЌЪфГіУХПижЦЯИАћжаАќКЌЕФаХЯЂКЮЪБгУдкРДздИУЯИАћЕФЪфГіжаЁЃМЧвфЯИАћЛЙАќКЌПижЦУПИіУХЕФШЈжЕЁЃбЕСЗЫуЗЈЃЈЭЈГЃЮЊ
BPTTЃЉЛљгкЕУЕНЕФЭјТчЪфГіДэЮѓРДгХЛЏетаЉШЈжЕЁЃ
2014 ФъЃЌЭЦГіСЫ LSTM ЕФвЛИіМђЛЏАцБОЃЌНазіУХПиЕнЙщЕЅдЊЁЃДЫФЃаЭгаСНИіУХЃЌХзЦњСЫ LSTM
ФЃаЭжаДцдкЕФЪфГіУХЁЃЖдгкаэЖргІгУЃЌGRU гЕгаРрЫЦгк LSTM ЕФадФмЃЌЕЋИќМђЕЅвтЮЖзХИќЩйЕФШЈжЕКЭИќПьЕФжДааЫйЖШЁЃ
GRU АќКЌСНИіУХЃКИќаТУХКЭжижУУХЁЃИќаТУХжИЪОБЃСєЖрЩйвдЧАЯИАћЕФФкШнЁЃжижУУХЖЈвхШчКЮНЋаТЪфШыгывдЧАЕФЯИАћФкШнКЯВЂЁЃGRU
ПЩвдЭЈЙ§НЋжижУУХЩшжУЮЊ 1 ВЂНЋИќаТУХЩшжУЮЊ 0 РДФЃФтБъзМ RNNЁЃ
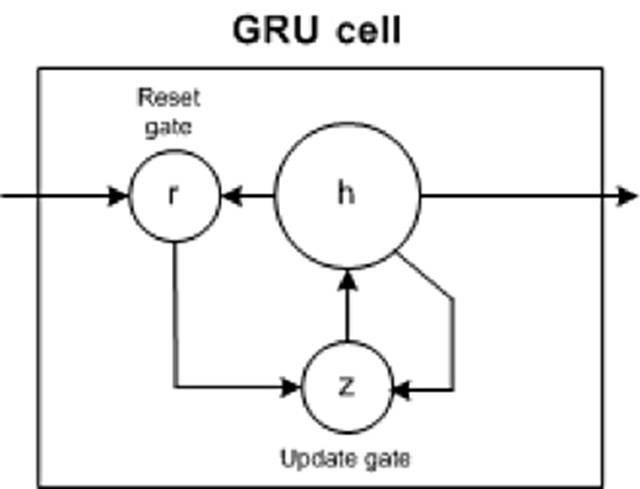
GRU БШ LSTM ИќМђЕЅЃЌФмИќПьЕибЕСЗЃЌЖјЧвжДаааЇТЪИќИпЁЃЕЋЪЧЃЌLSTM ИќИЛгкБэДяЃЌгаИќЖрЕФЪ§ОнЃЌФмДјРДИќКУЕФНсЙћЁЃ
ОэЛ§ЩёОЭјТч
CNN ЪЧвЛжжЖрВуЩёОЭјТчЃЌИУЭјТчЕФДДзїСщИаРДздЖЏЮяЕФЪгОѕЦЄжЪЁЃИУМмЙЙдкЭМЯёДІРэгІгУжаЬиБ№гагУЁЃЕквЛИі
CNN ЪЧгЩ Yann LeCun ДДНЈЕФЃЌЕБЪБЃЌИУМмЙЙзЈзЂгкЪжИхзжЗћЪЖБ№ЃЌБШШчгЪеўБрТыНтЪЭЁЃзїЮЊвЛжжЩюЖШЭјТчЃЌдчЦкЕФВужївЊЪЖБ№ИїжжЬиеїЃЈБШШчБпдЕЃЉЃЌКѓРДЕФВуНЋетаЉЬиеїжиаТзщКЯЕНЪфШыЕФИќИпМЖЪєаджаЁЃ
LeNet CNN МмЙЙАќКЌЖрИіВуЃЌетаЉВуЪЕЯжСЫЬиеїЬсШЁЃЌШЛКѓЪЕЯжСЫЗжРрЃЈВЮМћЯТЭМЃЉЁЃЭМЯёБЛЗжГЩЖрИіНгЪмЧјЃЌЦфжазЂШыСЫЫцКѓПЩДгЪфШыЭМЯёжаЬсШЁЬиеїЕФОэЛ§ВуЁЃЯТвЛВНЪЧГиЛЏЃЌЫќПЩвдЃЈЭЈЙ§НЕВЩбљЃЉНЕЕЭЬсШЁЕФЬиеїЕФЮЌЖШЃЌЭЌЪББЃСєзюживЊЕФаХЯЂЃЈЭЈГЃЭЈЙ§зюДѓГиЛЏЃЉЁЃШЛКѓжДааСэвЛИіОэЛ§КЭГиЛЏВНжшЃЌНЋНсЙћзЂШывЛИіЭъШЋСЌНгЕФЖрВуИажЊЦїжаЁЃДЫЭјТчЕФзюжеЪфГіВуЪЧвЛзщНкЕуЃЌетаЉНкЕуБъЪЖСЫЭМЯёЕФЬиеїЃЈдкБОР§жаЃЌУПИіНкЕуЖдгІвЛИіЪЖБ№ГіЕФЪ§зжЃЉЁЃФњПЩвдЪЙгУЗДЯђДЋВЅбЕСЗИУЭјТчЁЃ
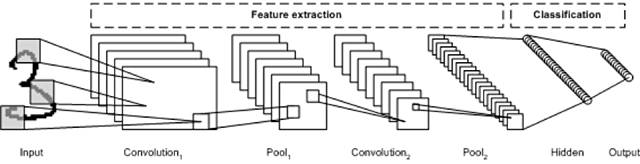
ЩюВуДІРэЁЂОэЛ§ЁЂГиЛЏКЭЭъШЋСЌНгЕФЗжРрВуЕФЪЙгУЃЌЮЊЩюЖШбЇЯАЩёОЭјТчЕФИїжжаТгІгУПЊЦєСЫвЛЩШУХЁЃГ§СЫЭМЯёДІРэжЎЭтЃЌCNN
ЛЙГЩЙІгІгУЕНСЫЪгЦЕЪЖБ№КЭИїжжздШЛгябдДІРэШЮЮёжаЁЃ
ШЫУЧзюНќгІгУ CNN КЭ LSTM РДЩњГЩЭМЯёКЭЪгЦЕЫЕУїЯЕЭГЃЌЪЙгУздШЛгябдзмНсЭМЯёЛђЪгЦЕФкШнЁЃCNN
ЪЕЯжСЫЭМЯёЛђЪгЦЕДІРэЃЌLSTM ОЙ§бЕСЗПЩвдНЋ CNN ЪфГізЊЛЛЮЊздШЛгябдЁЃ
ЩюЖШаХФюЭјТч
DBN ЪЧвЛжжЕфаЭЕФЭјТчМмЙЙЃЌЕЋЫќАќКЌвЛжжаТгБЕФбЕСЗЫуЗЈЁЃDBN ЪЧвЛжжЖрВуЭјТчЃЈЭЈГЃЪЧЩюЖШЭјТчЃЌАќКЌаэЖрвўВиВуЃЉЃЌЦфжаЕФУПЖдСЌНгЕФВуЖМЪЧвЛИіЪмЯоВЃЖћзШТќЛњ
(RBM)ЁЃЭЈЙ§етжжЗНЪНЃЌНЋ DBN БэЪОЮЊвЛаЉЕўМгЕФ RBMЁЃ
дк DBN жаЃЌЪфШыВуБэЪОдЪМИажЊЪфШыЃЌУПИівўВиВуЖМбЇЯАДЫЪфШыЕФГщЯѓБэЪОЁЃЪфГіВуЕФДІРэЗНЪНгыЦфЫћВуЩдгаВЛЭЌЃЌЫќЪЕЯжСЫЭјТчЗжРрЁЃбЕСЗЗжСНВННјааЃКЮоМрЖНдЄбЕСЗКЭМрЖНЕїгХЁЃ
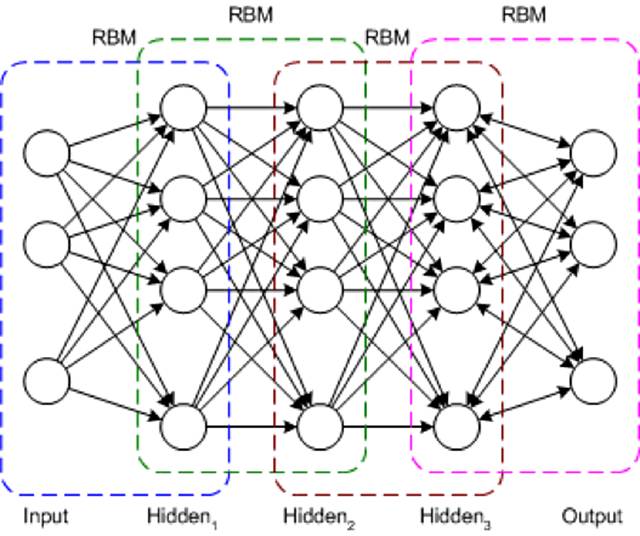
дкЮоМрЖНдЄбЕСЗЙ§ГЬжаЃЌЛсбЕСЗУПИі RBM РДжиЙЙЫќЕФЪфШыЃЈР§ШчЃЌЕквЛИі RBM НЋЪфШыВужиЙЙЕНЕквЛИівўВиВуЃЉЁЃгУРрЫЦЗНЪНбЕСЗЯТвЛИі
RBMЃЌЕЋНЋЕквЛИівўВиВуЪгЮЊЪфШыЃЈЛђПЩЪгЃЉВуЃЌЭЈЙ§ЪЙгУЕквЛИівўВиВуЕФЪфГізїЮЊЪфШыРДбЕСЗ RBMЁЃДЫЙ§ГЬвЛжБГжајЕНЭъГЩУПвЛВуЕФдЄбЕСЗЁЃЭъГЩдЄбЕСЗКѓЃЌПЊЪМНјааЕїгХЁЃдкДЫНзЖЮЃЌПЩЖдЪфГіНкЕуЪЙгУБъЧЉРДЬсЙЉЫќУЧЕФКЌвхЃЈЫќУЧдкЭјТчЕФЩЯЯТЮФжаБэЪОЕФКЌвхЃЉЁЃШЛКѓЪЙгУЬнЖШЯТНЕбЇЯАЛђЗДЯђДЋВЅРДгІгУећИіЭјТчбЕСЗЃЌДгЖјЭъГЩбЕСЗЙ§ГЬЁЃ
ЩюЖШЕўМгЭјТч
зюКѓвЊНщЩмЕФвЛжжМмЙЙЪЧ DSNЃЌвВГЦЮЊЩюЭЙЭјТчЁЃDSN ВЛЭЌгкДЋЭГЕФЩюЖШбЇЯАПђМмЃЌвђЮЊОЁЙмЫќАќКЌвЛИіЩюЖШЭјТчЃЌЕЋЫќЪЕМЪЩЯЪЧИїИіЭјТчЕФЩюЖШМЏКЯЃЌУПИіЭјТчЖМгаздМКЕФвўВиВуЁЃДЫМмЙЙЪЧЖдвЛИіЩюЖШбЇЯАЮЪЬтЕФвЛжжЛигІЃКбЕСЗЕФИДдгадЁЃЩюЖШбЇЯАМмЙЙжаЕФУПвЛВуЕФбЕСЗИДдгадЖМГЪжИЪ§МЖдіГЄЃЌЫљвд
DSN ЮДНЋбЕСЗЪгЮЊЕЅвЛЮЪЬтЃЌЖјНЋЫќЪгЮЊЕЅЖРбЕСЗЮЪЬтЕФМЏКЯЁЃ
DSN АќКЌвЛзщФЃПщЃЌУПИіФЃПщЖМЪЧ DSN ЕФећЬхЗжВуНсЙЙжаЕФвЛИізгЭјЁЃдкДЫМмЙЙЕФвЛИіЪЕР§жаЃЌЮЊ DSN
ДДНЈСЫ 3 ИіФЃПщЁЃУПИіФЃПщЖМАќКЌвЛИіЪфШыВуЁЂвЛИівўВиВуКЭвЛИіЪфГіВуЁЃФЃПщБЫДЫЖбЕўЃЌвЛИіФЃПщЕФЪфШыАќКЌЧАвЛВуЕФЪфГіКЭдЪМЪфШыЪИСПЁЃетжжЗжВуЪЙећИіЭјТчФмбЇЯАБШЕЅИіФЃПщИќИДдгЕФЗжРрЁЃ
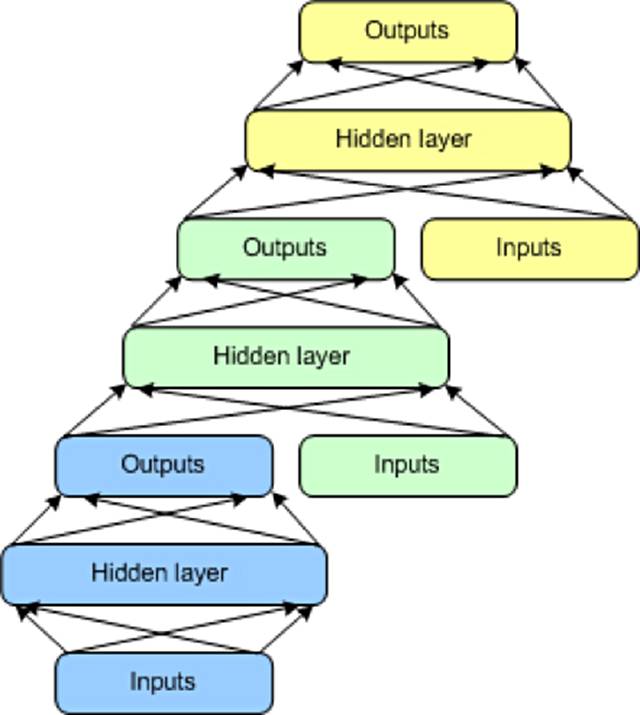
DSN дЪаэИєРыбЕСЗИїИіФЃПщЃЌетЪЙЕУЫќУЧФмВЂаабЕСЗЃЌвђЖјОпгаКмИпЕФаЇТЪЁЃМрЖНбЕСЗЪЕЯжЮЊУПИіФЃПщЩЯЕФЗДЯђДЋВЅЃЌЖјВЛЪЧдкећИіЭјТчЩЯЕФЗДЯђДЋВЅЁЃЖдгкаэЖрЮЪЬтЃЌDSN
БэЯжЕУЖМБШЕфаЭ DBN ИќКУЃЌетЪЙЫќУЧГЩЮЊСЫвЛжжСїааЧвИпаЇЕФЭјТчМмЙЙЁЃ
ПЊдДПђМм
етаЉЩюЖШбЇЯАМмЙЙПЯЖЈЪЧПЩвдЪЕЯжЕФЃЌЕЋДгЭЗПЊЪМПЩФмКмКФЪБЃЌЖјЧввВашвЊЪБМфРДгХЛЏЫќУЧВЂШУЫќУЧБфЕУГЩЪьЁЃавдЫЕФЪЧЃЌПЩвдРћгУвЛаЉПЊдДПђМмРДИќЧсЫЩЕиЪЕЯжКЭВПЪ№ЩюЖШбЇЯАЫуЗЈЁЃетаЉПђМмжЇГж
PythonЁЂC/C++ КЭ Java?ЕШгябдЁЃШУЮвУЧПДПД 3 жжзюСїааЕФПђМмКЭЫќУЧЕФгХШБЕуЁЃ
Caffe
Caffe ЪЧзюСїааЕФЩюЖШбЇЯАПђМмжЎвЛЁЃCaffe зюГѕЪЧдквЛЦЊВЉЪПТлЮФжаЗЂВМЕФЃЌЕЋЯждквбвРОн Berkeley
Software Distribution аэПЩНјааЗЂВМЁЃCaffe жЇГжаэЖрЩюЖШбЇЯАМмЙЙЃЌАќРЈ CNN
КЭ LSTMЃЌЕЋЫќУїЯдВЛжЇГж RBM Лђ DBMЃЈВЛЙ§МДНЋЗЂВМЕФ Caffe2 НЋЛсжЇГжЫќУЧЃЉЁЃ
ЭМЯёЗжРрКЭЦфЫћЪгОѕгІгУжавбВЩгУ CaffeЃЌЖјЧв Caffe жЇГжЭЈЙ§ NVIDIA CUDA Deep
Neural Network ПтЪЕЯжЛљгк GPU ЕФМгЫйЁЃCaffe жЇГжВЩгУПЊЗХЖрДІРэ (Open
Multi-Processing, OpenMP) дквЛИіЯЕЭГМЏШКЩЯВЂаажДааЩюЖШбЇЯАЫуЗЈЁЃЮЊСЫБЃжЄадФмЃЌCaffe
КЭ Caffe2 ЪЧгУ C++ БраДЕФЃЌЫќУЧЛЙЮЊЩюЖШбЇЯАЕФбЕСЗКЭжДааЬсЙЉСЫ Python КЭ MATLAB
НгПкЁЃ
Deeplearning4j
Deeplearning4j ЪЧвЛжжСїааЕФЩюЖШбЇЯАПђМмЃЌЫќзЈзЂгк Java ММЪѕЃЌЕЋАќКЌЪЪгУгкЦфЫћгябдЕФгІгУБрГЬНгПкЃЌБШШч
ScalaЁЂPython КЭ ClojureЁЃИУПђМмвРОн Apache аэПЩЖјЗЂВМЃЌжЇГж RBMЁЂDBNЁЂCNN
КЭ RNNЁЃDeeplearning4j ЛЙАќКЌМцШн Apache Hadoop КЭ SparkЃЈДѓЪ§ОнДІРэПђМмЃЉЕФЗжВМЪНВЂааАцБОЁЃ
ШЫУЧвбгІгУ Deeplearning4j РДНтОіжкЖрЮЪЬтЃЌАќРЈН№ШкСьгђжаЕФЦлеЉМьВтЁЂЭЦМіЯЕЭГЁЂЭМЯёЪЖБ№ЛђЭјТчАВШЋЃЈЭјТчШыЧжМьВтЃЉЁЃИУПђМмМЏГЩСЫ
CUDA РДЪЕЯж GPU гХЛЏЃЌЖјЧвПЩЭЈЙ§ OpenMP Лђ Hadoop НјааЗжЗЂЁЃ
TensorFlow
TensorFlow ЪЧ Google ПЊЗЂЕФвЛИіПЊдДПтЃЌЪЧДгБедД DistBelief бмЩњЖјРДЁЃПЩвдЪЙгУ
TensorFlow бЕСЗКЭВПЪ№ИїжжЩёОЭјТчЃЈCNNЁЂRBMЁЂDBN КЭ RNNЃЉЃЌTensorFlow
ЪЧвРОн Apache 2.0 аэПЩЖјЗЂВМЕФЁЃШЫУЧвбгІгУ TensorFlow РДНтОіжкЖрЮЪЬтЃЌБШШчЭМЯёЫЕУїЁЂЖёвтШэМўМьВтЁЂгявєЪЖБ№КЭаХЯЂМьЫїЁЃзюНќЗЂВМСЫвЛИізЈзЂгк
Android ЕФЖбеЛЃЌУћЮЊ TensorFlow LiteЁЃ
ПЩвддк PythonЁЂC++ЁЂJava гябдЁЂRust Лђ GoЃЈЕЋ Python зюЮШЖЈЃЉжаЪЙгУ
TensorFlow ПЊЗЂгІгУГЬађЃЌВЂЭЈЙ§ Hadoop ЗжЩЂжДааЫќУЧЁЃГ§СЫзЈвЕЕФгВМўНгПкжЎЭтЃЌTensorFlow
ЛЙжЇГж CUDAЁЃ
Distributed Deep Learning
IBM Distributed Deep Learning (DDL) БЛГЦЮЊЁАЩюЖШбЇЯАЕФХчЦјЪНв§ЧцЁБЃЌетИіПтСДНгЕНСЫ
Caffe КЭ TensorFlow ЕШСьЯШПђМмжаЁЃПЩдкЗўЮёЦїМЏШККЭЪ§АйИі GPU ЩЯЪЙгУ DDL
РДМгЫйЩюЖШбЇЯАЫуЗЈЁЃDDLЭЈЙ§ЖЈвхзюжеТЗОЖРДгХЛЏЩёОдЊМЦЫуЕФЭЈаХЃЌзюжеЕФЪ§ОнБиаыдкGPUжЎМфНјааЁЃЭЈЙ§ЧсЫЩЭъГЩ
Microsoft зюНќЩшжУЕФвЛИіЭМЯёЪЖБ№ШЮЮёЃЌжЄУїЩюЖШбЇЯАМЏШКЕФЦПОБФмЙЛЕУвдНтОіЁЃ
НсЪјгя
ЩюЖШбЇЯАЪЧЭЈЙ§вЛЯЕСаМмЙЙРДБэЪОЕФЃЌетаЉМмЙЙПЩЮЊИїжжИїбљЕФЮЪЬтСьгђЙЙНЈНтОіЗНАИЁЃетаЉНтОіЗНАИПЩвдзЈзЂгкЧАРЁЕФЭјТчЃЌЛђепЪЧдЪаэПМТЧвдЧАЕФЪфШыЕФЕнЙщЭјТчЁЃОЁЙмЙЙНЈетаЉРраЭЕФЩюЖШМмЙЙПЩФмКмИДдгЃЌЕЋПЩвдЪЙгУИїжжПЊдДНтОіЗНАИЃЈШчCaffeЃЌDeeplearning4jЃЌTensorFlowКЭDDLЃЉРДПьЫйЦєЖЏКЭдЫааЁЃ
|








