| Youtube是全球最大的视频分享平台,用户量高达10亿+,每天上传的UGC和PGC都是百万级别。那么问题就来了,他们是如何让用户在这么多的视频中快速的发现自己感兴趣的内容呢?大家可能会想到搜索,确实搜索是一个必不可少的工具,但有一个前提条件是用户必须知道视频的关键词,通过搜索关键词才能找到对应的视频,并且用户很多时候其实并不是很知道自己需要什么样的内容,逛youtube纯粹为了打发时间。为了很好的解决用户快速发现可能感兴趣的视频这个问题,推荐系统绝对是搜索的一个很好的补充。
本文主要介绍youtube 10年推荐系统相关的算法和策略变迁。
笔者从网上找到了三篇介绍youtube推荐系统相关的文章,一篇是2008年发表的《Video suggestion
and discovery for youtube: taking random walks through
the view graph》;一篇是2010年发表的《The_YouTube_video_recommendation_system》还有一篇是2016年发表的《
Deep Neural Networks for YouTube Recommendations》,这三篇文章介绍都了youtube推荐系统以及内部算法架构,通过这些文章我们可以窥伺其在不同时期,基于不同资源和技术对系统的进化过程,对于想在自己场景中使用推荐技术的同学有非常好的借鉴意义;
08年发表的那篇相对于后面两篇来说技术上差别还是蛮大的,作者把推荐问题建立在一个user-video的图上,对于某个user,作者定义了他可能感兴趣的video
v 需要满足的条件:
1、u到v的路径是最短的
2、u到v有尽可能多的路径
3、u到v要避开热门v的影响(热门v可以根据度来判断)
根据上述三个标准,可以给图上每个用户推荐适合的video;那如何实现呢?文章里作者提出了一种叫做Adsorption的学习框架,这个框架目标是解决少量有标注(labeled)数据集,来预估大的无标注(unlabeled)数据集的问题。作者使用多种方法在这个算法框架上比如Averageing、Random
Walk、Linear System,并且给出了很多概念定义和算法描述,实验结果也是非常吸引人;对于图模型,Random
Walk是一定会想到的解决方案,其逻辑是将每个顶点V的label发送到相关联的邻居上,在每次传递结束后,对顶点的label进行归一化。对应到视频推荐是我们够建user观看(当然可以是其他行为:转评赞等)video的关系图,把用户喜欢看的视频当作label,然后进行随机游走,将label推广到其他视频上。这个算法试验结果很好,但是文章也是是给出了漂亮的结果,对里面实现一笔带过,我理解对于这么大的数据量级使用这种迭代算法,计算代价是非常高的,所以应用到实际场景,系统工程要求也是非常高。
相比于08年文章,2010年发表在RecSys的文章,不管是行文风格,还是算法架构都发生了非常大的变化,08年文章充满了学术气息,长篇大论,但是如何应用到实际业务中并没有提到很多;2010年的文章很短,4页,非常简单明了的介绍了youtube推荐系统的方方面面,同时还介绍了很多实际业务中需要使用的trick,比如如何解决相关推荐带来的兴趣狭窄问题,引入minimum
score threshold去除不相关视频等,在实际业务中非常有借鉴意义。这篇文章介绍的推荐场景是youtube主页,场景的目的是给用户提供个性化的内容以此提升用户使用网站的互动性和娱乐性。文章介绍的核心算法其实就是item-based算法,然后根据用户在网站上的历史行为给其生成一个个性化的视频列表:

文章作者也提到,他们把这个问题定义成TOP-N推荐问题,而不是点击预估问题,需要完整地考虑内容的新鲜度、精确度、多样性以及用户近期行为。另外认真的同学会发现推荐列表中,每个视频封面图片下面有系列的介绍,标题、视频发表时间、观看次数、Because
you watch XXX;里面推荐理由也是非常重要的,让用户知道为什么会给他推荐这个视频,而且列表前四个Because
you watch都不同,说明是经过了策略的调整。
回到文章核心算法,要根据用户历史行为推荐相关视频,一个核心问题是计算视频与视频的相关度,作者文章中说是使用了association
rule mining的技术来解决,其实是使用co-view来计算视频之间的相似度:

公式里面分子 Cij 表示视频 i 和视频 j 在一个时间窗口(文章用1天)里面co-view的次数,分母f(Vi
,Vj) 是一个规范化函数(normalization functions),来避免热门视频带来的影响,文章中列举了一个简单的函数:f(vi,
vj) = ci · cj ,当然实际业务中可以根据业务知识自定义这个规范函数;如果是使用f(vi,
vj) = ci · cj,那么r(vi, vj)其实就是关联规则置信度的计算公司,对于种子视频Vi,要找到最相似的视频,ci
是不影响排序,而 cj 直接打压了热门视频的影响,一定程度上提升了多样性,并且对于小曝光视频有扶持作用。上述计算相关性的公式,只是一个简单抽象,文章提到实际业务中还考虑了很多因素,比如播放时间戳、播放序列、video
metadata 等。有了视频之间的相关性,就可以将每个视频作为节点,视频之间的相关性rij作为边的权值构建一个有向的
video graph,接下来根据这个图为每个用户 u 来产生推荐候选集合,然后将推荐集合传入进入排序层生成推荐列表,大概逻辑如下:

种子视频生成是根据用户历史正向行为获取的,比如用户收藏、赞、加入播放列表、评分等。有了
video graph 和种子视频,根据 item - based 算法就可以跟每个用户生成一个个性化的推荐候选池,但是作者认为这种传统做法会让用户的兴趣越来越窄,于是他们在搜索最近邻居的基础上加以扩展,搜索多阶的最近邻居,公式如下:


生成完候选之后,下一步是从几百个视频中,挑选几个到十几个视频展示给用户,那必须需要有一个排序算法,文章中提到了三类型的因素用于最终的打分:
1.v 视频质量
2.v 用户的切合程度
3.v 多样性
视频质量主要是根据用户反馈信息来得到,比如收看数目、总被观看时长、评分、评论、赞、分享等,同时还有视频的上传时间之类的信息
用户切合度是取决于用户对种子视频的喜欢程度,以及视频之间的相似程度,同时加强近期行为。多样性主要是通过分类数目来衡量;然后把这三方面的因素作线性加权得到候选集合的权重(注:如果用树模型或者
FM 模型应该可以取得更好的成绩),排序得到推荐列表。
推荐系统实现方面分为三个方面:1、数据收集;2、推荐候选生成;3、线上推荐服务;系统主要使用了 Bigtable
和 mapReduce 实现;
2016年的论文用到的技术相对于2010年有了非常大的改变,所用到的数据源也不仅仅只有用户显性行为,但是主框架还是候选生成+排序模型的模式,只是这两层架构都是使用了深度模型(四层,其实不深)下图是16年论文中提到的架构图:

主架构通过 candidate generation(候选生成)模块,从百万video
corpus(所有推荐候选池)找出几百个与用户相关的待推荐视频;然后ranking(排序)模块将候选模块产生的推荐列表中在选择十几个视频展示给用户。这篇文章比较有开创性的是,在这两个模块中都使用了深度学习,合理的将不同特征和不同数据源融合在一起,并取得非常不错的效果。下图是候选生成模型框架:

文章将推荐问题转换为极多分类问题(extreme multiclass
classication),公式如下:

表示在时刻 t,用户U(上下文信息C)在视频库V中精准的预测出视频 i 的类别(每个具体的视频视为一个类别,i
即为一个类别)的概率。上面的公式是一个明显的 softmax 多分类器的形式;其中 u 和 v,分别是用户的
embdded 向量和视频的 embdded 向量,具体怎么来的呢?对于视频向量,文章采用了 word
embedding 的方式计算出每个视频的 embedded 向量(原文:Inspired by continuous
bag of words language models,we learn high dimensional
embeddings for each video in a fixed vocabulary and
feed these embeddings into a feedforward neural network);而
u 则是通过输入用户信息和上下文信息给上面模型架构训练得到。
整个模型由包含三个隐层DNN组成,输入层输入的的信息有,用户播放历史和搜索历史embedded向量分别取average,再加入用户基础画像(年龄、性别等)其余特征:视频质量、视频age等特征concat成向量输入;从上图可以看出,输出分为serving和training两个部分。Training部分输出层是softmax层,也就是上面提到的那个公式表示的概率值,线上部分通过u向量和v向量得出用户相关topN视频(注:serving是指线上推荐服务;training是离线训练模型;下同)。
Ranking 模型框架:
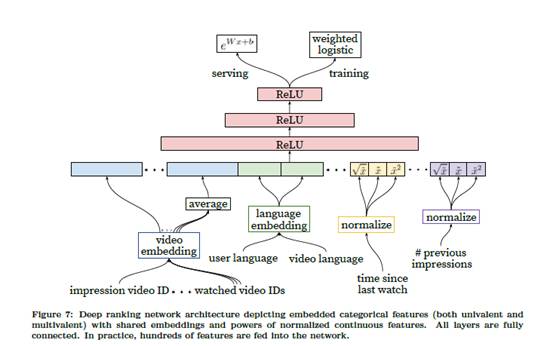
Ranking 层从架构上跟候选生成层基本一致,不同是的最后输出层training是一个
weighted logistic,而serving阶段激活函数是ex;ranking层针对视频播放时长进行建模(并不是一个单纯的ctr预估模型,文章指出,单纯根据
CTR 来进行推荐,会出现“clickbait”,也就是助长标题党,封面党;这样并不能带来用户停留时长的提升),以有没有点击来划分正负样本,正样本根据播放时长进行加权,正样本的权重是播放时长
Ti,负样本权重是1,而最后一层模型是weighted logistic regression;那么LR学到的odds为:

其中 N 是总的样本数量,k 是正样本数量,Ti 是第i正样本的观看时长。k 相对 N 比较小,因此上式的
odds 可以转换成E[T]/(1+P),其中 P 是点击率,点击率一般很小,这样 odds接近于E[T],即期望观看时长。因此在线上
serving 的 inference 阶段,我们采用 ex 作为激励函数,就是近似的估计期望的观看时长。
另外文章也花了很大篇幅将特征工程相关的工作(这与深度学习自动提取特征有点不符,哈哈)作者说虽然深度学习可以缓解人工构造特征的负担,但是原始数据也是无法直接喂给前馈神经网络,所以特征工程依旧非常重要;
在架构上整个推荐系统是建立在 Google brain 上面,使用 TensorFlow 进行建模。
本文通过对 youtube 不同时期发表的文章,可以看到其技术的变迁,10年的推荐技术的积累,有很多东西可以值得我们去学习的。
|





