| БрМЭЦМі: |
БОЮФРДздгкЭјТчВЉПЭ,БОЮФНЋДјФуСьТдЩюЖШбЇЯАИпЖЫЗЖЖљБГКѓЕФЗНЗЈгыЙ§ГЬЁЃ
|
|
ЮЪЬтЕМЖСЃК
1ЁЂЪВУДЪЧЩюЖШбЇЯАЃП
2ЁЂШчКЮРэНтЬиеїЃП
3ЁЂDeep LearningЕФЛљБОЫМЯыЪЧЪВУДЃП
4ЁЂШчКЮРэНтЩёОЭјТчЃП
5ЁЂDeep learningбЕСЗЙ§ГЬгаФФаЉЃП
6ЁЂDeep LearningЕФГЃгУФЃаЭЛђепЗНЗЈгаФФаЉЃП
в§бд
ЩюЖШбЇЯАЃЌМДDeep Learning,ЪЧвЛжжбЇЯАЫуЗЈЃЈLearning
algorithmЃЉ,врЪЧШЫЙЄжЧФмСьгђЕФвЛИіживЊЗжжЇЁЃДгПьЫйЗЂеЙЕНЪЕМЪгІгУЃЌЖЬЖЬМИФъЪБМфРяЃЌЩюЖШбЇЯАЕпИВСЫгявєЪЖБ№ЁЂЭМЯёЗжРрЁЂЮФБОРэНтЕШжкЖрСьгђЕФЫуЗЈЩшМЦЫМТЗЃЌНЅНЅаЮГЩСЫвЛжжДгбЕСЗЪ§ОнГіЗЂЃЌОЙ§вЛИіЖЫЕНЖЫЃЈend-to-endЃЉЕФФЃаЭЃЌШЛКѓжБНгЪфГіЕУЕНзюжеНсЙћЕФвЛжжаТФЃЪНЁЃФЧУДЃЌЩюЖШбЇЯАгаЖрЩюЃПбЇСЫОПОЙгаМИЗжЃП
вЛЁЂИХЪі
Artificial IntelligenceЃЌвВОЭЪЧШЫЙЄжЧФмЃЌОЭЯёГЄЩњВЛРЯКЭаЧМЪТўгЮвЛбљЃЌЪЧШЫРрзюУРКУЕФУЮЯыжЎвЛЁЃЫфШЛМЦЫуЛњММЪѕвбОШЁЕУСЫГЄзуЕФНјВНЃЌЕЋЪЧЕНФПЧАЮЊжЙЃЌЛЙУЛгавЛЬЈЕчФдФмВњЩњЁАздЮвЁБЕФвтЪЖЁЃЪЧЕФЃЌдкШЫРрКЭДѓСПЯжГЩЪ§ОнЕФАяжњЯТЃЌЕчФдПЩвдБэЯжЕФЪЎЗжЧПДѓЃЌЕЋЪЧРыПЊСЫетСНепЃЌЫќЩѕжСЖМВЛФмЗжБцвЛИіпїаЧШЫКЭвЛИіЭєаЧШЫЁЃ
ЭМСщЃЈЭМСщЃЌДѓМвЖМжЊЕРАЩЁЃМЦЫуЛњКЭШЫЙЄжЧФмЕФБЧзцЃЌЗжБ№ЖдгІгкЦфжјУћЕФЁАЭМСщЛњЁБКЭЁАЭМСщВтЪдЁБЃЉдк
1950 ФъЕФТлЮФРяЃЌЬсГіЭМСщЪдбщЕФЩшЯыЃЌМДЃЌИєЧНЖдЛАЃЌФуНЋВЛжЊЕРгыФуЬИЛАЕФЃЌЪЧШЫЛЙЪЧЕчФдЁЃетЮовЩИјМЦЫуЛњЃЌгШЦфЪЧШЫЙЄжЧФмЃЌдЄЩшСЫвЛИіКмИпЕФЦкЭћжЕЁЃЕЋЪЧАыИіЪРМЭЙ§ШЅСЫЃЌШЫЙЄжЧФмЕФНјеЙЃЌдЖдЖУЛгаДяЕНЭМСщЪдбщЕФБъзМЁЃетВЛНіШУЖрФъЧЬЪзвдД§ЕФШЫУЧЃЌаФЛввтРфЃЌШЯЮЊШЫЙЄжЧФмЪЧКігЦЃЌЯрЙиСьгђЪЧЁАЮБПЦбЇЁБЁЃ
ЕЋЪЧзд 2006 ФъвдРДЃЌЛњЦїбЇЯАСьгђЃЌШЁЕУСЫЭЛЦЦадЕФНјеЙЁЃЭМСщЪдбщЃЌжСЩйВЛЪЧФЧУДПЩЭћЖјВЛПЩМАСЫЁЃжСгкММЪѕЪжЖЮЃЌВЛНіНівРРЕгкдЦМЦЫуЖдДѓЪ§ОнЕФВЂааДІРэФмСІЃЌЖјЧввРРЕгкЫуЗЈЁЃетИіЫуЗЈОЭЪЧЃЌDeep
LearningЁЃНшжњгк Deep Learning ЫуЗЈЃЌШЫРржегкевЕНСЫШчКЮДІРэЁАГщЯѓИХФюЁБетИіиЈЙХФбЬтЕФЗНЗЈЁЃ

2012Фъ6дТЃЌЁЖХІдМЪББЈЁЗХћТЖСЫGoogle BrainЯюФПЃЌЮќв§СЫЙЋжкЕФЙуЗКЙизЂЁЃетИіЯюФПЪЧгЩжјУћЕФЫЙЬЙИЃДѓбЇЕФЛњЦїбЇЯАНЬЪкAndrew
NgКЭдкДѓЙцФЃМЦЫуЛњЯЕЭГЗНУцЕФЪРНчЖЅМтзЈМвJeffDeanЙВЭЌжїЕМЃЌгУ16000ИіCPU CoreЕФВЂааМЦЫуЦНЬЈбЕСЗвЛжжГЦЮЊЁАЩюЖШЩёОЭјТчЁБЃЈDNNЃЌDeep
Neural NetworksЃЉЕФЛњЦїбЇЯАФЃаЭЃЈФкВПЙВга10вкИіНкЕуЁЃетвЛЭјТчздШЛЪЧВЛФмИњШЫРрЕФЩёОЭјТчЯрЬсВЂТлЕФЁЃвЊжЊЕРЃЌШЫФджаПЩЪЧга150ЖрвкИіЩёОдЊЃЌЛЅЯрСЌНгЕФНкЕувВОЭЪЧЭЛДЅЪ§ИќЪЧШчвјКгЩГЪ§ЁЃдјОгаШЫЙРЫуЙ§ЃЌШчЙћНЋвЛИіШЫЕФДѓФджаЫљгаЩёОЯИАћЕФжсЭЛКЭЪїЭЛвРДЮСЌНгЦ№РДЃЌВЂРГЩвЛИљжБЯпЃЌПЩДгЕиЧђСЌЕНдТССЃЌдйДгдТССЗЕЛиЕиЧђЃЉЃЌдкгявєЪЖБ№КЭЭМЯёЪЖБ№ЕШСьгђЛёЕУСЫОоДѓЕФГЩЙІЁЃ
ЯюФПИКд№ШЫжЎвЛAndrewГЦЃКЁАЮвУЧУЛгаЯёЭЈГЃзіЕФФЧбљздМКПђЖЈБпНчЃЌЖјЪЧжБНгАбКЃСПЪ§ОнЭЖЗХЕНЫуЗЈжаЃЌШУЪ§ОнздМКЫЕЛАЃЌЯЕЭГЛсздЖЏДгЪ§ОнжабЇЯАЁЃЁБСэЭтвЛУћИКд№ШЫJeffдђЫЕЃКЁАЮвУЧдкбЕСЗЕФЪБКђДгРДВЛЛсИцЫпЛњЦїЫЕЃКЁЎетЪЧвЛжЛУЈЁЃЁЏЯЕЭГЦфЪЕЪЧздМКЗЂУїЛђепСьЮђСЫЁАУЈЁБЕФИХФюЁЃЁБ

2012Фъ11дТЃЌЮЂШэдкжаЙњЬьНђЕФвЛДЮЛюЖЏЩЯЙЋПЊбнЪОСЫвЛИіШЋздЖЏЕФЭЌЩљДЋвыЯЕЭГЃЌНВбнепгУгЂЮФбнНВЃЌКѓЬЈЕФМЦЫуЛњвЛЦјКЧГЩздЖЏЭъГЩгявєЪЖБ№ЁЂгЂжаЛњЦїЗвыКЭжаЮФгявєКЯГЩЃЌаЇЙћЗЧГЃСїГЉЁЃОнБЈЕРЃЌКѓУцжЇГХЕФЙиМќММЪѕвВЪЧDNNЃЌЛђепЩюЖШбЇЯАЃЈDLЃЌDeepLearningЃЉЁЃ
2013Фъ1дТЃЌдкАйЖШФъЛсЩЯЃЌДДЪМШЫМцCEOРюбхКъИпЕїаћВМвЊГЩСЂАйЖШбаОПдКЃЌЦфжаЕквЛИіГЩСЂЕФОЭЪЧЁАЩюЖШбЇЯАбаОПЫљЁБЃЈIDLЃЌInstitue
of Deep LearningЃЉЁЃ

ЮЊЪВУДгЕгаДѓЪ§ОнЕФЛЅСЊЭјЙЋЫОељЯрЭЖШыДѓСПзЪдДбаЗЂЩюЖШбЇЯАММЪѕЁЃЬ§Ц№РДИаОѕdeeplearningКмХЃФЧбљЁЃФЧЪВУДЪЧdeep
learningЃПЮЊЪВУДгаdeep learningЃПЫќЪЧдѕУДРДЕФЃПгжФмИЩЪВУДФиЃПФПЧАДцдкФФаЉРЇФбФиЃПетаЉЮЪЬтЕФМђД№ЖМашвЊТ§Т§РДЁЃдлУЧЯШРДСЫНтЯТЛњЦїбЇЯАЃЈШЫЙЄжЧФмЕФКЫаФЃЉЕФБГОАЁЃ
ЖўЁЂБГОА
ЛњЦїбЇЯАЃЈMachine LearningЃЉЪЧвЛУХзЈУХбаОПМЦЫуЛњдѕбљФЃФтЛђЪЕЯжШЫРрЕФбЇЯАааЮЊЃЌвдЛёШЁаТЕФжЊЪЖЛђММФмЃЌжиаТзщжЏвбгаЕФжЊЪЖНсЙЙЪЙжЎВЛЖЯИФЩЦздЩэЕФадФмЕФбЇПЦЁЃЛњЦїФмЗёЯёШЫРрвЛбљФмОпгабЇЯАФмСІФиЃП1959ФъУРЙњЕФШћчбЖћ(Samuel)ЩшМЦСЫвЛИіЯТЦхГЬађЃЌетИіГЬађОпгабЇЯАФмСІЃЌЫќПЩвддкВЛЖЯЕФЖдоФжаИФЩЦздМКЕФЦхвеЁЃ4ФъКѓЃЌетИіГЬађеНЪЄСЫЩшМЦепБОШЫЁЃгжЙ§СЫ3ФъЃЌетИіГЬађеНЪЄСЫУРЙњвЛИіБЃГж8ФъжЎОУЕФГЃЪЄВЛАмЕФЙкОќЁЃетИіГЬађЯђШЫУЧеЙЪОСЫЛњЦїбЇЯАЕФФмСІЃЌЬсГіСЫаэЖрСюШЫЩюЫМЕФЩчЛсЮЪЬтгыембЇЮЪЬтЃЈКЧКЧЃЌШЫЙЄжЧФме§ГЃЕФЙьЕРУЛгаКмДѓЕФЗЂеЙЃЌетаЉЪВУДембЇТзРэАЁЕЙЗЂеЙЕФЭІПьЁЃЪВУДЮДРДЛњЦїдНРДдНЯёШЫЃЌШЫдНРДдНЯёЛњЦїАЁЁЃЪВУДЛњЦїЛсЗДШЫРрАЁЃЌATMЪЧПЊЕквЛЧЙЕФАЁЕШЕШЁЃШЫРрЕФЫМЮЌЮоЧюАЁЃЉЁЃ
ЛњЦїбЇЯАЫфШЛЗЂеЙСЫМИЪЎФъЃЌЕЋЛЙЪЧДцдкКмЖрУЛгаСМКУНтОіЕФЮЪЬтЃК

Р§ШчЭМЯёЪЖБ№ЁЂгявєЪЖБ№ЁЂздШЛгябдРэНтЁЂЬьЦјдЄВтЁЂЛљвђБэДяЁЂФкШнЭЦМіЕШЕШЁЃФПЧАЮвУЧЭЈЙ§ЛњЦїбЇЯАШЅНтОіетаЉЮЪЬтЕФЫМТЗЖМЪЧетбљЕФЃЈвдЪгОѕИажЊЮЊР§згЃЉЃК 
ДгПЊЪМЕФЭЈЙ§ДЋИаЦїЃЈР§ШчCMOSЃЉРДЛёЕУЪ§ОнЁЃШЛКѓОЙ§дЄДІРэЁЂЬиеїЬсШЁЁЂЬиеїбЁдёЃЌдйЕНЭЦРэЁЂдЄВтЛђепЪЖБ№ЁЃзюКѓвЛИіВПЗжЃЌвВОЭЪЧЛњЦїбЇЯАЕФВПЗжЃЌОјДѓВПЗжЕФЙЄзїЪЧдкетЗНУцзіЕФЃЌвВДцдкКмЖрЕФpaperКЭбаОПЁЃ
ЖјжаМфЕФШ§ВПЗжЃЌИХРЈЦ№РДОЭЪЧЬиеїБэДяЁЃСМКУЕФЬиеїБэДяЃЌЖдзюжеЫуЗЈЕФзМШЗадЦ№СЫЗЧГЃЙиМќЕФзїгУЃЌЖјЧвЯЕЭГжївЊЕФМЦЫуКЭВтЪдЙЄзїЖМКФдкетвЛДѓВПЗжЁЃЕЋЃЌетПщЪЕМЪжавЛАуЖМЪЧШЫЙЄЭъГЩЕФЁЃППШЫЙЄЬсШЁЬиеїЁЃ

НижЙЯждкЃЌвВГіЯжСЫВЛЩйNBЕФЬиеїЃЈКУЕФЬиеїгІОпгаВЛБфадЃЈДѓаЁЁЂГпЖШКЭа§зЊЕШЃЉКЭПЩЧјЗжадЃЉЃКР§ШчSiftЕФГіЯжЃЌЪЧОжВПЭМЯёЬиеїУшЪізгбаОПСьгђвЛЯюРяГЬБЎЪНЕФЙЄзїЁЃгЩгкSIFTЖдГпЖШЁЂа§зЊвдМАвЛЖЈЪгНЧКЭЙтееБфЛЏЕШЭМЯёБфЛЏЖМОпгаВЛБфадЃЌВЂЧвSIFTОпгаКмЧПЕФПЩЧјЗжадЃЌЕФШЗШУКмЖрЮЪЬтЕФНтОіБфЮЊПЩФмЁЃЕЋЫќвВВЛЪЧЭђФмЕФЁЃ

ШЛЖјЃЌЪжЙЄЕибЁШЁЬиеїЪЧвЛМўЗЧГЃЗбСІЁЂЦєЗЂЪНЃЈашвЊзЈвЕжЊЪЖЃЉЕФЗНЗЈЃЌФмВЛФмбЁШЁКУКмДѓГЬЖШЩЯППОбщКЭдЫЦјЃЌЖјЧвЫќЕФЕїНкашвЊДѓСПЕФЪБМфЁЃМШШЛЪжЙЄбЁШЁЬиеїВЛЬЋКУЃЌФЧУДФмВЛФмздЖЏЕибЇЯАвЛаЉЬиеїФиЃПД№АИЪЧФмЃЁDeep
LearningОЭЪЧгУРДИЩетИіЪТЧщЕФЃЌПДЫќЕФвЛИіБ№УћUnsupervisedFeature LearningЃЌОЭПЩвдЙЫУћЫМвхСЫЃЌUnsupervisedЕФвтЫМОЭЪЧВЛвЊШЫВЮгыЬиеїЕФбЁШЁЙ§ГЬЁЃ
ФЧЫќЪЧдѕУДбЇЯАЕФФиЃПдѕУДжЊЕРФФаЉЬиеїКУФФаЉВЛКУФиЃПЮвУЧЫЕЛњЦїбЇЯАЪЧвЛУХзЈУХбаОПМЦЫуЛњдѕбљФЃФтЛђЪЕЯжШЫРрЕФбЇЯАааЮЊЕФбЇПЦЁЃКУЃЌФЧЮвУЧШЫЕФЪгОѕЯЕЭГЪЧдѕУДЙЄзїЕФФиЃПЮЊЪВУДдкУЃУЃШЫКЃЃЌмПмПжкЩњЃЌЙіЙіКьГОжаЮвУЧЖМПЩвдевЕНСэвЛИіЫ§ЃЈвђЮЊЃЌФуДцдкЮвЩюЩюЕФФдКЃРяЃЌЮвЕФУЮРя
ЮвЕФаФРя ЮвЕФИшЩљРяЁЁЃЉЁЃШЫФдФЧУДNBЃЌЮвУЧФмВЛФмВЮПМШЫФдЃЌФЃФтШЫФдФиЃПЃЈКУЯёКЭШЫФдГЖЩЯЕуЙиЯЕЕФЬиеїАЁЃЌЫуЗЈАЁЃЌЖМВЛДэЃЌЕЋВЛжЊЕРЪЧВЛЪЧШЫЮЊЧПМгЕФЃЌЮЊСЫЪЙздМКЕФзїЦЗБфЕУЩёЪЅКЭИпбХЁЃЃЉ
НќМИЪЎФъвдРДЃЌШЯжЊЩёОПЦбЇЁЂЩњЮябЇЕШЕШбЇПЦЕФЗЂеЙЃЌШУЮвУЧЖдздМКетИіЩёУиЕФЖјгжЩёЦцЕФДѓФдВЛдйФЧУДЕФФАЩњЁЃвВИјШЫЙЄжЧФмЕФЗЂеЙЭЦВЈжњРНЁЃ
Ш§ЁЂШЫФдЪгОѕЛњРэ
1981 ФъЕФХЕБДЖћвНбЇНБЃЌАфЗЂИјСЫ David HubelЃЈГіЩњгкМгФУДѓЕФУРЙњЩёОЩњЮябЇМвЃЉ
КЭTorstenWieselЃЌвдМА Roger SperryЁЃЧАСНЮЛЕФжївЊЙБЯзЃЌЪЧЁАЗЂЯжСЫЪгОѕЯЕЭГЕФаХЯЂДІРэЁБЃКПЩЪгЦЄВуЪЧЗжМЖЕФЃК

ЮвУЧПДПДЫћУЧзіСЫЪВУДЁЃ1958 ФъЃЌDavidHubel КЭTorsten Wiesel дк JohnHopkins
UniversityЃЌбаОПЭЋПзЧјгђгыДѓФдЦЄВуЩёОдЊЕФЖдгІЙиЯЕЁЃЫћУЧдкУЈЕФКѓФдЭЗЙЧЩЯЃЌПЊСЫвЛИі3 КСУзЕФаЁЖДЃЌЯђЖДРяВхШыЕчМЋЃЌВтСПЩёОдЊЕФЛюдОГЬЖШЁЃ
ШЛКѓЃЌЫћУЧдкаЁУЈЕФблЧАЃЌеЙЯжИїжжаЮзДЁЂИїжжССЖШЕФЮяЬхЁЃВЂЧвЃЌдкеЙЯжУПвЛМўЮяЬхЪБЃЌЛЙИФБфЮяЬхЗХжУЕФЮЛжУКЭНЧЖШЁЃЫћУЧЦкЭћЭЈЙ§етИіАьЗЈЃЌШУаЁУЈЭЋПзИаЪмВЛЭЌРраЭЁЂВЛЭЌЧПШѕЕФДЬМЄЁЃ
жЎЫљвдзіетИіЪдбщЃЌФПЕФЪЧШЅжЄУївЛИіВТВтЁЃЮЛгкКѓФдЦЄВуЕФВЛЭЌЪгОѕЩёОдЊЃЌгыЭЋПзЫљЪмДЬМЄжЎМфЃЌДцдкФГжжЖдгІЙиЯЕЁЃвЛЕЉЭЋПзЪмЕНФГвЛжжДЬМЄЃЌКѓФдЦЄВуЕФФГвЛВПЗжЩёОдЊОЭЛсЛюдОЁЃОРњСЫКмЖрЬьЗДИДЕФПндяЕФЪдбщЃЌЭЌЪБЮўЩќСЫШєИЩжЛПЩСЏЕФаЁУЈЃЌDavid
Hubel КЭTorsten Wiesel ЗЂЯжСЫвЛжжБЛГЦЮЊЁАЗНЯђбЁдёадЯИАћЃЈOrientation
Selective CellЃЉЁБЕФЩёОдЊЯИАћЁЃЕБЭЋПзЗЂЯжСЫблЧАЕФЮяЬхЕФБпдЕЃЌЖјЧветИіБпдЕжИЯђФГИіЗНЯђЪБЃЌетжжЩёОдЊЯИАћОЭЛсЛюдОЁЃ
етИіЗЂЯжМЄЗЂСЫШЫУЧЖдгкЩёОЯЕЭГЕФНјвЛВНЫМПМЁЃЩёО-жаЪр-ДѓФдЕФЙЄзїЙ§ГЬЃЌЛђаэЪЧвЛИіВЛЖЯЕќДњЁЂВЛЖЯГщЯѓЕФЙ§ГЬЁЃ
етРяЕФЙиМќДЪгаСНИіЃЌвЛИіЪЧГщЯѓЃЌвЛИіЪЧЕќДњЁЃДгдЪМаХКХЃЌзіЕЭМЖГщЯѓЃЌж№НЅЯђИпМЖГщЯѓЕќДњЁЃШЫРрЕФТпМЫМЮЌЃЌОГЃЪЙгУИпЖШГщЯѓЕФИХФюЁЃ
Р§ШчЃЌДгдЪМаХКХЩуШыПЊЪМЃЈЭЋПзЩуШыЯёЫи PixelsЃЉЃЌНгзХзіГѕВНДІРэЃЈДѓФдЦЄВуФГаЉЯИАћЗЂЯжБпдЕКЭЗНЯђЃЉЃЌШЛКѓГщЯѓЃЈДѓФдХаЖЈЃЌблЧАЕФЮяЬхЕФаЮзДЃЌЪЧдВаЮЕФЃЉЃЌШЛКѓНјвЛВНГщЯѓЃЈДѓФдНјвЛВНХаЖЈИУЮяЬхЪЧжЛЦјЧђЃЉЁЃ

етИіЩњРэбЇЕФЗЂЯжЃЌДйГЩСЫМЦЫуЛњШЫЙЄжЧФмЃЌдкЫФЪЎФъКѓЕФЭЛЦЦадЗЂеЙЁЃ
змЕФРДЫЕЃЌШЫЕФЪгОѕЯЕЭГЕФаХЯЂДІРэЪЧЗжМЖЕФЁЃДгЕЭМЖЕФV1ЧјЬсШЁБпдЕЬиеїЃЌдйЕНV2ЧјЕФаЮзДЛђепФПБъЕФВПЗжЕШЃЌдйЕНИќИпВуЃЌећИіФПБъЁЂФПБъЕФааЮЊЕШЁЃвВОЭЪЧЫЕИпВуЕФЬиеїЪЧЕЭВуЬиеїЕФзщКЯЃЌДгЕЭВуЕНИпВуЕФЬиеїБэЪОдНРДдНГщЯѓЃЌдНРДдНФмБэЯжгявхЛђепвтЭМЁЃЖјГщЯѓВуУцдНИпЃЌДцдкЕФПЩФмВТВтОЭдНЩйЃЌОЭдНРћгкЗжРрЁЃР§ШчЃЌЕЅДЪМЏКЯКЭОфзгЕФЖдгІЪЧЖрЖдвЛЕФЃЌОфзгКЭгявхЕФЖдгІгжЪЧЖрЖдвЛЕФЃЌгявхКЭвтЭМЕФЖдгІЛЙЪЧЖрЖдвЛЕФЃЌетЪЧИіВуМЖЬхЯЕЁЃ
УєИаЕФШЫзЂвтЕНЙиМќДЪСЫЃКЗжВуЁЃЖјDeep learningЕФdeepЪЧВЛЪЧОЭБэЪОЮвДцдкЖрЩйВуЃЌвВОЭЪЧЖрЩюФиЃПУЛДэЁЃФЧDeep
learningЪЧШчКЮНшМјетИіЙ§ГЬЕФФиЃПБЯОЙЪЧЙщгкМЦЫуЛњРДДІРэЃЌУцЖдЕФвЛИіЮЪЬтОЭЪЧдѕУДЖдетИіЙ§ГЬНЈФЃЃП
вђЮЊЮвУЧвЊбЇЯАЕФЪЧЬиеїЕФБэДяЃЌФЧУДЙигкЬиеїЃЌЛђепЫЕЙигкетИіВуМЖЬиеїЃЌЮвУЧашвЊСЫНтЕиИќЩюШыЕуЁЃЫљвддкЫЕDeep
LearningжЎЧАЃЌЮвУЧгаБивЊдйЊрТЯТЬиеїЃЈКЧКЧЃЌЪЕМЪЩЯЪЧПДЕНФЧУДКУЕФЖдЬиеїЕФНтЪЭЃЌВЛЗХдкетРягаЕуПЩЯЇЃЌЫљвдОЭШћЕНетСЫЃЉЁЃ
вђЮЊЮвУЧвЊбЇЯАЕФЪЧЬиеїЕФБэДяЃЌФЧУДЙигкЬиеїЃЌЛђепЫЕЙигкетИіВуМЖЬиеїЃЌЮвУЧашвЊСЫНтЕиИќЩюШыЕуЁЃЫљвддкЫЕDeep
LearningжЎЧАЃЌЮвУЧгаБивЊдйЊрТЯТЬиеїЃЈКЧКЧЃЌЪЕМЪЩЯЪЧПДЕНФЧУДКУЕФЖдЬиеїЕФНтЪЭЃЌВЛЗХдкетРягаЕуПЩЯЇЃЌЫљвдОЭШћЕНетСЫЃЉЁЃ
ЫФЁЂЙигкЬиеї
ЬиеїЪЧЛњЦїбЇЯАЯЕЭГЕФдВФСЯЃЌЖдзюжеФЃаЭЕФгАЯьЪЧЮугЙжУвЩЕФЁЃШчЙћЪ§ОнБЛКмКУЕФБэДяГЩСЫЬиеїЃЌЭЈГЃЯпадФЃаЭОЭФмДяЕНТњвтЕФОЋЖШЁЃФЧЖдгкЬиеїЃЌЮвУЧашвЊПМТЧЪВУДФиЃП
4.1ЁЂЬиеїБэЪОЕФСЃЖШ
бЇЯАЫуЗЈдквЛИіЪВУДСЃЖШЩЯЕФЬиеїБэЪОЃЌВХгаФмЗЂЛгзїгУЃПОЭвЛИіЭМЦЌРДЫЕЃЌЯёЫиМЖЕФЬиеїИљБОУЛгаМлжЕЁЃР§ШчЯТУцЕФФІЭаГЕЃЌДгЯёЫиМЖБ№ЃЌИљБОЕУВЛЕНШЮКЮаХЯЂЃЌЦфЮоЗЈНјааФІЭаГЕКЭЗЧФІЭаГЕЕФЧјЗжЁЃЖјШчЙћЬиеїЪЧвЛИіОпгаНсЙЙадЃЈЛђепЫЕгаКЌвхЃЉЕФЪБКђЃЌБШШчЪЧЗёОпгаГЕАбЪжЃЈhandleЃЉЃЌЪЧЗёОпгаГЕТжЃЈwheelЃЉЃЌОЭКмШнвзАбФІЭаГЕКЭЗЧФІЭаГЕЧјЗжЃЌбЇЯАЫуЗЈВХФмЗЂЛгзїгУЁЃ

4.2ЁЂГѕМЖЃЈЧГВуЃЉЬиеїБэЪО
МШШЛЯёЫиМЖЕФЬиеїБэЪОЗНЗЈУЛгазїгУЃЌФЧдѕбљЕФБэЪОВХгагУФиЃП
1995 ФъЧАКѓЃЌBruno OlshausenКЭ David Field СНЮЛбЇепШЮжА Cornell
UniversityЃЌЫћУЧЪдЭМЭЌЪБгУЩњРэбЇКЭМЦЫуЛњЕФЪжЖЮЃЌЫЋЙмЦыЯТЃЌбаОПЪгОѕЮЪЬтЁЃ
ЫћУЧЪеМЏСЫКмЖрКкАзЗчОАееЦЌЃЌДгетаЉееЦЌжаЃЌЬсШЁГі400ИіаЁЫщЦЌЃЌУПИіееЦЌЫщЦЌЕФГпДчОљЮЊ
16x16 ЯёЫиЃЌВЛЗСАбет400ИіЫщЦЌБъМЧЮЊ S, i = 0,.. 399ЁЃНгЯТРДЃЌдйДгетаЉКкАзЗчОАееЦЌжаЃЌЫцЛњЬсШЁСэвЛИіЫщЦЌЃЌГпДчвВЪЧ
16x16 ЯёЫиЃЌВЛЗСАбетИіЫщЦЌБъМЧЮЊ TЁЃ
ЫћУЧЬсГіЕФЮЪЬтЪЧЃЌШчКЮДгет400ИіЫщЦЌжаЃЌбЁШЁвЛзщЫщЦЌЃЌS[k], ЭЈЙ§ЕўМгЕФАьЗЈЃЌКЯГЩГівЛИіаТЕФЫщЦЌЃЌЖјетИіаТЕФЫщЦЌЃЌгІЕБгыЫцЛњбЁдёЕФФПБъЫщЦЌ
TЃЌОЁПЩФмЯрЫЦЃЌЭЌЪБЃЌS[k] ЕФЪ§СПОЁПЩФмЩйЁЃгУЪ§бЇЕФгябдРДУшЪіЃЌОЭЪЧЃК
Sum_k (a[k] * S[k]) --> T, Цфжа a[k] ЪЧдкЕўМгЫщЦЌ S[k]
ЪБЕФШЈжиЯЕЪ§ЁЃ
ЮЊНтОіетИіЮЪЬтЃЌBruno OlshausenКЭ David Field ЗЂУїСЫвЛИіЫуЗЈЃЌЯЁЪшБрТыЃЈSparse
CodingЃЉЁЃ
ЯЁЪшБрТыЪЧвЛИіжиИДЕќДњЕФЙ§ГЬЃЌУПДЮЕќДњЗжСНВНЃК
1ЃЉбЁдёвЛзщ S[k]ЃЌШЛКѓЕїећ a[k]ЃЌЪЙЕУSum_k (a[k] * S[k]) зюНгНќ TЁЃ
2ЃЉЙЬЖЈзЁ a[k]ЃЌдк 400 ИіЫщЦЌжаЃЌбЁдёЦфЫќИќКЯЪЪЕФЫщЦЌSЁЏ[k]ЃЌЬцДњдЯШЕФ S[k]ЃЌЪЙЕУSum_k
(a[k] * SЁЏ[k]) зюНгНќ TЁЃ
ОЙ§МИДЮЕќДњКѓЃЌзюМбЕФ S[k] зщКЯЃЌБЛхрбЁГіРДСЫЁЃСюШЫОЊЦцЕФЪЧЃЌБЛбЁжаЕФ S[k]ЃЌЛљБОЩЯЖМЪЧееЦЌЩЯВЛЭЌЮяЬхЕФБпдЕЯпЃЌетаЉЯпЖЮаЮзДЯрЫЦЃЌЧјБ№дкгкЗНЯђЁЃ
Bruno OlshausenКЭ David Field ЕФЫуЗЈНсЙћЃЌгы David Hubel
КЭTorsten Wiesel ЕФЩњРэЗЂЯжЃЌВЛФБЖјКЯЃЁ
вВОЭЪЧЫЕЃЌИДдгЭМаЮЃЌЭљЭљгЩвЛаЉЛљБОНсЙЙзщГЩЁЃБШШчЯТЭМЃКвЛИіЭМПЩвдЭЈЙ§гУ64жже§НЛЕФedgesЃЈПЩвдРэНтГЩе§НЛЕФЛљБОНсЙЙЃЉРДЯпадБэЪОЁЃБШШчбљР§ЕФxПЩвдгУ1-64ИіedgesжаЕФШ§ИіАДее0.8,0.3,0.5ЕФШЈжиЕїКЭЖјГЩЁЃЖјЦфЫћЛљБОedgeУЛгаЙБЯзЃЌвђДЫОљЮЊ0
ЁЃ 
СэЭтЃЌДѓХЃУЧЛЙЗЂЯжЃЌВЛНіЭМЯёДцдкетИіЙцТЩЃЌЩљвєвВДцдкЁЃЫћУЧДгЮДБъзЂЕФЩљвєжаЗЂЯжСЫ20жжЛљБОЕФЩљвєНсЙЙЃЌЦфгрЕФЩљвєПЩвдгЩет20жжЛљБОНсЙЙКЯГЩЁЃ


4.3ЁЂНсЙЙадЬиеїБэЪО
аЁПщЕФЭМаЮПЩвдгЩЛљБОedgeЙЙГЩЃЌИќНсЙЙЛЏЃЌИќИДдгЕФЃЌОпгаИХФюадЕФЭМаЮШчКЮБэЪОФиЃПетОЭашвЊИќИпВуДЮЕФЬиеїБэЪОЃЌБШШчV2ЃЌV4ЁЃвђДЫV1ПДЯёЫиМЖЪЧЯёЫиМЖЁЃV2ПДV1ЪЧЯёЫиМЖЃЌетИіЪЧВуДЮЕнНјЕФЃЌИпВуБэДягЩЕзВуБэДяЕФзщКЯЖјГЩЁЃзЈвЕЕуЫЕОЭЪЧЛљbasisЁЃV1ШЁЬсГіЕФbasisЪЧБпдЕЃЌШЛКѓV2ВуЪЧV1ВуетаЉbasisЕФзщКЯЃЌетЪБКђV2ЧјЕУЕНЕФгжЪЧИпвЛВуЕФbasisЁЃМДЩЯвЛВуЕФbasisзщКЯЕФНсЙћЃЌЩЯЩЯВугжЪЧЩЯвЛВуЕФзщКЯbasisЁЁЃЈЫљвдгаДѓХЃЫЕDeep
learningОЭЪЧЁАИуЛљЁБЃЌвђЮЊФбЬ§ЃЌЫљвдУРЦфУћдЛDeep learningЛђепUnsupervised
Feature LearningЃЉ

жБЙлЩЯЫЕЃЌОЭЪЧевЕНmake senseЕФаЁpatchдйНЋЦфНјааcombineЃЌОЭЕУЕНСЫЩЯвЛВуЕФfeatureЃЌЕнЙщЕиЯђЩЯlearning
featureЁЃ
дкВЛЭЌobjectЩЯзіtrainingЪЧЃЌЫљЕУЕФedge basis ЪЧЗЧГЃЯрЫЦЕФЃЌЕЋobject
partsКЭmodels ОЭЛсcompletely differentСЫЃЈФЧдлУЧЗжБцcarЛђепfaceЪЧВЛЪЧШнвзЖрСЫЃЉЃК

ДгЮФБОРДЫЕЃЌвЛИіdocБэЪОЪВУДвтЫМЃПЮвУЧУшЪівЛМўЪТЧщЃЌгУЪВУДРДБэЪОБШНЯКЯЪЪЃПгУвЛИівЛИізжТяЃЌЮвПДВЛЪЧЃЌзжОЭЪЧЯёЫиМЖБ№СЫЃЌЦ№ТыгІИУЪЧtermЃЌЛЛОфЛАЫЕУПИіdocЖМгЩtermЙЙГЩЃЌЕЋетбљБэЪОИХФюЕФФмСІОЭЙЛСЫТяЃЌПЩФмвВВЛЙЛЃЌашвЊдйЩЯвЛВНЃЌДяЕНtopicМЖЃЌгаСЫtopicЃЌдйЕНdocОЭКЯРэЁЃЕЋУПИіВуДЮЕФЪ§СПВюОрКмДѓЃЌБШШчdocБэЪОЕФИХФю->topicЃЈЧЇ-ЭђСПМЖЃЉ->termЃЈ10ЭђСПМЖЃЉ->wordЃЈАйЭђСПМЖЃЉЁЃ
вЛИіШЫдкПДвЛИіdocЕФЪБКђЃЌблОІПДЕНЕФЪЧwordЃЌгЩетаЉwordдкДѓФдРяздЖЏЧаДЪаЮГЩtermЃЌдкАДееИХФюзщжЏЕФЗНЪНЃЌЯШбщЕФбЇЯАЃЌЕУЕНtopicЃЌШЛКѓдйНјааИпВуДЮЕФlearningЁЃ
4.4ЁЂашвЊгаЖрЩйИіЬиеїЃП
ЮвУЧжЊЕРашвЊВуДЮЕФЬиеїЙЙНЈЃЌгЩЧГШыЩюЃЌЕЋУПвЛВуИУгаЖрЩйИіЬиеїФиЃП
ШЮКЮвЛжжЗНЗЈЃЌЬиеїдНЖрЃЌИјГіЕФВЮПМаХЯЂОЭдНЖрЃЌзМШЗадЛсЕУЕНЬсЩ§ЁЃЕЋЬиеїЖрвтЮЖзХМЦЫуИДдгЃЌЬНЫїЕФПеМфДѓЃЌПЩвдгУРДбЕСЗЕФЪ§ОндкУПИіЬиеїЩЯОЭЛсЯЁЪшЃЌЖМЛсДјРДИїжжЮЪЬтЃЌВЂВЛвЛЖЈЬиеїдНЖрдНКУЁЃ

КУСЫЃЌЕНСЫетвЛВНЃЌжегкПЩвдСФЕНDeep learningСЫЁЃЩЯУцЮвУЧСФЕНЮЊЪВУДЛсгаDeep
learningЃЈШУЛњЦїздЖЏбЇЯАСМКУЕФЬиеїЃЌЖјУтШЅШЫЙЄбЁШЁЙ§ГЬЁЃЛЙгаВЮПМШЫЕФЗжВуЪгОѕДІРэЯЕЭГЃЉЃЌЮвУЧЕУЕНвЛИіНсТлОЭЪЧDeep
learningашвЊЖрВуРДЛёЕУИќГщЯѓЕФЬиеїБэДяЁЃФЧУДЖрЩйВуВХКЯЪЪФиЃПгУЪВУДМмЙЙРДНЈФЃФиЃПдѕУДНјааЗЧМрЖНбЕСЗФиЃП
ЮхЁЂDeep LearningЕФЛљБОЫМЯы
МйЩшЮвУЧгавЛИіЯЕЭГSЃЌЫќгаnВуЃЈS1,ЁSnЃЉЃЌЫќЕФЪфШыЪЧIЃЌЪфГіЪЧOЃЌаЮЯѓЕиБэЪОЮЊЃК I =>S1=>S2=>Ё..=>Sn
=> OЃЌШчЙћЪфГіOЕШгкЪфШыIЃЌМДЪфШыIОЙ§етИіЯЕЭГБфЛЏжЎКѓУЛгаШЮКЮЕФаХЯЂЫ№ЪЇЃЈКЧКЧЃЌДѓХЃЫЕЃЌетЪЧВЛПЩФмЕФЁЃаХЯЂТлжагаИіЁАаХЯЂж№ВуЖЊЪЇЁБЕФЫЕЗЈЃЈаХЯЂДІРэВЛЕШЪНЃЉЃЌЩшДІРэaаХЯЂЕУЕНbЃЌдйЖдbДІРэЕУЕНcЃЌФЧУДПЩвджЄУїЃКaКЭcЕФЛЅаХЯЂВЛЛсГЌЙ§aКЭbЕФЛЅаХЯЂЁЃетБэУїаХЯЂДІРэВЛЛсдіМгаХЯЂЃЌДѓВПЗжДІРэЛсЖЊЪЇаХЯЂЁЃЕБШЛСЫЃЌШчЙћЖЊЕєЕФЪЧУЛгУЕФаХЯЂФЧЖрКУАЁЃЉЃЌБЃГжСЫВЛБфЃЌетвтЮЖзХЪфШыIОЙ§УПвЛВуSiЖМУЛгаШЮКЮЕФаХЯЂЫ№ЪЇЃЌМДдкШЮКЮвЛВуSiЃЌЫќЖМЪЧдгааХЯЂЃЈМДЪфШыIЃЉЕФСэЭтвЛжжБэЪОЁЃЯждкЛиЕНЮвУЧЕФжїЬтDeep
LearningЃЌЮвУЧашвЊздЖЏЕибЇЯАЬиеїЃЌМйЩшЮвУЧгавЛЖбЪфШыIЃЈШчвЛЖбЭМЯёЛђепЮФБОЃЉЃЌМйЩшЮвУЧЩшМЦСЫвЛИіЯЕЭГSЃЈгаnВуЃЉЃЌЮвУЧЭЈЙ§ЕїећЯЕЭГжаВЮЪ§ЃЌЪЙЕУЫќЕФЪфГіШдШЛЪЧЪфШыIЃЌФЧУДЮвУЧОЭПЩвдздЖЏЕиЛёШЁЕУЕНЪфШыIЕФвЛЯЕСаВуДЮЬиеїЃЌМДS1ЃЌЁ,
SnЁЃ
ЖдгкЩюЖШбЇЯАРДЫЕЃЌЦфЫМЯыОЭЪЧЖдЖбЕўЖрИіВуЃЌвВОЭЪЧЫЕетвЛВуЕФЪфГізїЮЊЯТвЛВуЕФЪфШыЁЃЭЈЙ§етжжЗНЪНЃЌОЭПЩвдЪЕЯжЖдЪфШыаХЯЂНјааЗжМЖБэДяСЫЁЃ
СэЭтЃЌЧАУцЪЧМйЩшЪфГібЯИёЕиЕШгкЪфШыЃЌетИіЯожЦЬЋбЯИёЃЌЮвУЧПЩвдТдЮЂЕиЗХЫЩетИіЯожЦЃЌР§ШчЮвУЧжЛвЊЪЙЕУЪфШыгыЪфГіЕФВюБ№ОЁПЩФмЕиаЁМДПЩЃЌетИіЗХЫЩЛсЕМжТСэЭтвЛРрВЛЭЌЕФDeep
LearningЗНЗЈЁЃЩЯЪіОЭЪЧDeep LearningЕФЛљБОЫМЯыЁЃ
СљЁЂЧГВубЇЯАЃЈShallow LearningЃЉКЭЩюЖШбЇЯАЃЈDeep LearningЃЉ
ЧГВубЇЯАЪЧЛњЦїбЇЯАЕФЕквЛДЮРЫГБЁЃ
20ЪРМЭ80ФъДњФЉЦкЃЌгУгкШЫЙЄЩёОЭјТчЕФЗДЯђДЋВЅЫуЗЈЃЈвВНаBack PropagationЫуЗЈЛђепBPЫуЗЈЃЉЕФЗЂУїЃЌИјЛњЦїбЇЯАДјРДСЫЯЃЭћЃЌЯЦЦ№СЫЛљгкЭГМЦФЃаЭЕФЛњЦїбЇЯАШШГБЁЃетИіШШГБвЛжБГжајЕННёЬьЁЃШЫУЧЗЂЯжЃЌРћгУBPЫуЗЈПЩвдШУвЛИіШЫЙЄЩёОЭјТчФЃаЭДгДѓСПбЕСЗбљБОжабЇЯАЭГМЦЙцТЩЃЌДгЖјЖдЮДжЊЪТМўзідЄВтЁЃетжжЛљгкЭГМЦЕФЛњЦїбЇЯАЗНЗЈБШЦ№Й§ШЅЛљгкШЫЙЄЙцдђЕФЯЕЭГЃЌдкКмЖрЗНУцЯдГігХдНадЁЃетИіЪБКђЕФШЫЙЄЩёОЭјТчЃЌЫфвВБЛГЦзїЖрВуИажЊЛњЃЈMulti-layer
PerceptronЃЉЃЌЕЋЪЕМЪЪЧжжжЛКЌгавЛВувўВуНкЕуЕФЧГВуФЃаЭЁЃ
20ЪРМЭ90ФъДњЃЌИїжжИїбљЕФЧГВуЛњЦїбЇЯАФЃаЭЯрМЬБЛЬсГіЃЌР§ШчжЇГХЯђСПЛњЃЈSVMЃЌSupport Vector
MachinesЃЉЁЂ BoostingЁЂзюДѓьиЗНЗЈЃЈШчLRЃЌLogistic RegressionЃЉЕШЁЃетаЉФЃаЭЕФНсЙЙЛљБОЩЯПЩвдПДГЩДјгавЛВувўВуНкЕуЃЈШчSVMЁЂBoostingЃЉЃЌЛђУЛгавўВуНкЕуЃЈШчLRЃЉЁЃетаЉФЃаЭЮоТлЪЧдкРэТлЗжЮіЛЙЪЧгІгУжаЖМЛёЕУСЫОоДѓЕФГЩЙІЁЃЯрБШжЎЯТЃЌгЩгкРэТлЗжЮіЕФФбЖШДѓЃЌбЕСЗЗНЗЈгжашвЊКмЖрОбщКЭММЧЩЃЌетИіЪБЦкЧГВуШЫЙЄЩёОЭјТчЗДЖјЯрЖдГСМХЁЃ
ЩюЖШбЇЯАЪЧЛњЦїбЇЯАЕФЕкЖўДЮРЫГБЁЃ
2006ФъЃЌМгФУДѓЖрТзЖрДѓбЇНЬЪкЁЂЛњЦїбЇЯАСьгђЕФЬЉЖЗGeoffrey HintonКЭЫћЕФбЇЩњRuslanSalakhutdinovдкЁЖПЦбЇЁЗЩЯЗЂБэСЫвЛЦЊЮФеТЃЌПЊЦєСЫЩюЖШбЇЯАдкбЇЪѕНчКЭЙЄвЕНчЕФРЫГБЁЃетЦЊЮФеТгаСНИіжївЊЙлЕуЃК1ЃЉЖрвўВуЕФШЫЙЄЩёОЭјТчОпгагХвьЕФЬиеїбЇЯАФмСІЃЌбЇЯАЕУЕНЕФЬиеїЖдЪ§ОнгаИќБОжЪЕФПЬЛЃЌДгЖјгаРћгкПЩЪгЛЏЛђЗжРрЃЛ2ЃЉЩюЖШЩёОЭјТчдкбЕСЗЩЯЕФФбЖШЃЌПЩвдЭЈЙ§ЁАж№ВуГѕЪМЛЏЁБЃЈlayer-wise
pre-trainingЃЉРДгааЇПЫЗўЃЌдкетЦЊЮФеТжаЃЌж№ВуГѕЪМЛЏЪЧЭЈЙ§ЮоМрЖНбЇЯАЪЕЯжЕФЁЃ
ЕБЧАЖрЪ§ЗжРрЁЂЛиЙщЕШбЇЯАЗНЗЈЮЊЧГВуНсЙЙЫуЗЈЃЌЦфОжЯоаддкгкгаЯобљБОКЭМЦЫуЕЅдЊЧщПіЯТЖдИДдгКЏЪ§ЕФБэЪОФмСІгаЯоЃЌеыЖдИДдгЗжРрЮЪЬтЦфЗКЛЏФмСІЪмЕНвЛЖЈжЦдМЁЃЩюЖШбЇЯАПЩЭЈЙ§бЇЯАвЛжжЩюВуЗЧЯпадЭјТчНсЙЙЃЌЪЕЯжИДдгКЏЪ§БЦНќЃЌБэеїЪфШыЪ§ОнЗжВМЪНБэЪОЃЌВЂеЙЯжСЫЧПДѓЕФДгЩйЪ§бљБОМЏжабЇЯАЪ§ОнМЏБОжЪЬиеїЕФФмСІЁЃЃЈЖрВуЕФКУДІЪЧПЩвдгУНЯЩйЕФВЮЪ§БэЪОИДдгЕФКЏЪ§ЃЉ 
ЩюЖШбЇЯАЕФЪЕжЪЃЌЪЧЭЈЙ§ЙЙНЈОпгаКмЖрвўВуЕФЛњЦїбЇЯАФЃаЭКЭКЃСПЕФбЕСЗЪ§ОнЃЌРДбЇЯАИќгагУЕФЬиеїЃЌДгЖјзюжеЬсЩ§ЗжРрЛђдЄВтЕФзМШЗадЁЃвђДЫЃЌЁАЩюЖШФЃаЭЁБЪЧЪжЖЮЃЌЁАЬиеїбЇЯАЁБЪЧФПЕФЁЃЧјБ№гкДЋЭГЕФЧГВубЇЯАЃЌЩюЖШбЇЯАЕФВЛЭЌдкгкЃК1ЃЉЧПЕїСЫФЃаЭНсЙЙЕФЩюЖШЃЌЭЈГЃга5ВуЁЂ6ВуЃЌЩѕжС10ЖрВуЕФвўВуНкЕуЃЛ2ЃЉУїШЗЭЛГіСЫЬиеїбЇЯАЕФживЊадЃЌвВОЭЪЧЫЕЃЌЭЈЙ§ж№ВуЬиеїБфЛЛЃЌНЋбљБОдкдПеМфЕФЬиеїБэЪОБфЛЛЕНвЛИіаТЬиеїПеМфЃЌДгЖјЪЙЗжРрЛђдЄВтИќМгШнвзЁЃгыШЫЙЄЙцдђЙЙдьЬиеїЕФЗНЗЈЯрБШЃЌРћгУДѓЪ§ОнРДбЇЯАЬиеїЃЌИќФмЙЛПЬЛЪ§ОнЕФЗсИЛФкдкаХЯЂЁЃ
ЦпЁЂDeep learningгыNeural Network
ЩюЖШбЇЯАЪЧЛњЦїбЇЯАбаОПжаЕФвЛИіаТЕФСьгђЃЌЦфЖЏЛњдкгкНЈСЂЁЂФЃФтШЫФдНјааЗжЮібЇЯАЕФЩёОЭјТчЃЌЫќФЃЗТШЫФдЕФЛњжЦРДНтЪЭЪ§ОнЃЌР§ШчЭМЯёЃЌЩљвєКЭЮФБОЁЃЩюЖШбЇЯАЪЧЮоМрЖНбЇЯАЕФвЛжжЁЃ
ЩюЖШбЇЯАЕФИХФюдДгкШЫЙЄЩёОЭјТчЕФбаОПЁЃКЌЖрвўВуЕФЖрВуИажЊЦїОЭЪЧвЛжжЩюЖШбЇЯАНсЙЙЁЃЩюЖШбЇЯАЭЈЙ§зщКЯЕЭВуЬиеїаЮГЩИќМгГщЯѓЕФИпВуБэЪОЪєадРрБ№ЛђЬиеїЃЌвдЗЂЯжЪ§ОнЕФЗжВМЪНЬиеїБэЪОЁЃ
Deep learningБОЩэЫуЪЧmachine learningЕФвЛИіЗжжЇЃЌМђЕЅПЩвдРэНтЮЊneural
networkЕФЗЂеЙЁЃДѓдМЖўШ§ЪЎФъЧАЃЌneural networkдјОЪЧMLСьгђЬиБ№Л№ШШЕФвЛИіЗНЯђЃЌЕЋЪЧКѓРДШЗТ§Т§ЕГіСЫЃЌдвђАќРЈвдЯТМИИіЗНУцЃК
1ЃЉБШНЯШнвзЙ§ФтКЯЃЌВЮЪ§БШНЯФбtuneЃЌЖјЧвашвЊВЛЩйtrickЃЛ
2ЃЉбЕСЗЫйЖШБШНЯТ§ЃЌдкВуДЮБШНЯЩйЃЈаЁгкЕШгк3ЃЉЕФЧщПіЯТаЇЙћВЂВЛБШЦфЫќЗНЗЈИќгХЃЛ
ЫљвджаМфгаДѓдМ20ЖрФъЕФЪБМфЃЌЩёОЭјТчБЛЙизЂКмЩйЃЌетЖЮЪБМфЛљБОЩЯЪЧSVMКЭboostingЫуЗЈЕФЬьЯТЁЃЕЋЪЧЃЌвЛИіГеаФЕФРЯЯШЩњHintonЃЌЫћМсГжСЫЯТРДЃЌВЂзюжеЃЈКЭЦфЫќШЫвЛЦ№BengioЁЂYann.lecunЕШЃЉЬсГЩСЫвЛИіЪЕМЪПЩааЕФdeep
learningПђМмЁЃ
Deep learningгыДЋЭГЕФЩёОЭјТчжЎМфгаЯрЭЌЕФЕиЗНвВгаКмЖрВЛЭЌЁЃ
ЖўепЕФЯрЭЌдкгкdeep learningВЩгУСЫЩёОЭјТчЯрЫЦЕФЗжВуНсЙЙЃЌЯЕЭГгЩАќРЈЪфШыВуЁЂвўВуЃЈЖрВуЃЉЁЂЪфГіВузщГЩЕФЖрВуЭјТчЃЌжЛгаЯрСкВуНкЕужЎМфгаСЌНгЃЌЭЌвЛВувдМАПчВуНкЕужЎМфЯрЛЅЮоСЌНгЃЌУПвЛВуПЩвдПДзїЪЧвЛИіlogistic
regressionФЃаЭЃЛетжжЗжВуНсЙЙЃЌЪЧБШНЯНгНќШЫРрДѓФдЕФНсЙЙЕФЁЃ 
ЖјЮЊСЫПЫЗўЩёОЭјТчбЕСЗжаЕФЮЪЬтЃЌDLВЩгУСЫгыЩёОЭјТчКмВЛЭЌЕФбЕСЗЛњжЦЁЃДЋЭГЩёОЭјТчжаЃЌВЩгУЕФЪЧback
propagationЕФЗНЪННјааЃЌМђЕЅРДНВОЭЪЧВЩгУЕќДњЕФЫуЗЈРДбЕСЗећИіЭјТчЃЌЫцЛњЩшЖЈГѕжЕЃЌМЦЫуЕБЧАЭјТчЕФЪфГіЃЌШЛКѓИљОнЕБЧАЪфГіКЭlabelжЎМфЕФВюШЅИФБфЧАУцИїВуЕФВЮЪ§ЃЌжБЕНЪеСВЃЈећЬхЪЧвЛИіЬнЖШЯТНЕЗЈЃЉЁЃЖјdeep
learningећЬхЩЯЪЧвЛИіlayer-wiseЕФбЕСЗЛњжЦЁЃетбљзіЕФдвђЪЧвђЮЊЃЌШчЙћВЩгУback propagationЕФЛњжЦЃЌЖдгквЛИіdeep
networkЃЈ7ВувдЩЯЃЉЃЌВаВюДЋВЅЕНзюЧАУцЕФВувбОБфЕУЬЋаЁЃЌГіЯжЫљЮНЕФgradient diffusionЃЈЬнЖШРЉЩЂЃЉЁЃетИіЮЪЬтЮвУЧНгЯТРДЬжТлЁЃ
АЫЁЂDeep learningбЕСЗЙ§ГЬ
8.1ЁЂДЋЭГЩёОЭјТчЕФбЕСЗЗНЗЈЮЊЪВУДВЛФмгУдкЩюЖШЩёОЭјТч
BPЫуЗЈзїЮЊДЋЭГбЕСЗЖрВуЭјТчЕФЕфаЭЫуЗЈЃЌЪЕМЪЩЯЖдНіКЌМИВуЭјТчЃЌИУбЕСЗЗНЗЈОЭвбОКмВЛРэЯыЁЃЩюЖШНсЙЙЃЈЩцМАЖрИіЗЧЯпадДІРэЕЅдЊВуЃЉЗЧЭЙФПБъДњМлКЏЪ§жаЦеБщДцдкЕФОжВПзюаЁЪЧбЕСЗРЇФбЕФжївЊРДдДЁЃ
BPЫуЗЈДцдкЕФЮЪЬтЃК
ЃЈ1ЃЉЬнЖШдНРДдНЯЁЪшЃКДгЖЅВудНЭљЯТЃЌЮѓВюаЃе§аХКХдНРДдНаЁЃЛ
ЃЈ2ЃЉЪеСВЕНОжВПзюаЁжЕЃКгШЦфЪЧДгдЖРызюгХЧјгђПЊЪМЕФЪБКђЃЈЫцЛњжЕГѕЪМЛЏЛсЕМжТетжжЧщПіЕФЗЂЩњЃЉЃЛ
ЃЈ3ЃЉвЛАуЃЌЮвУЧжЛФмгУгаБъЧЉЕФЪ§ОнРДбЕСЗЃКЕЋДѓВПЗжЕФЪ§ОнЪЧУЛБъЧЉЕФЃЌЖјДѓФдПЩвдДгУЛгаБъЧЉЕФЕФЪ§ОнжабЇЯАЃЛ
8.2ЁЂdeep learningбЕСЗЙ§ГЬ
ШчЙћЖдЫљгаВуЭЌЪБбЕСЗЃЌЪБМфИДдгЖШЛсЬЋИпЃЛШчЙћУПДЮбЕСЗвЛВуЃЌЦЋВюОЭЛсж№ВуДЋЕнЁЃетЛсУцСйИњЩЯУцМрЖНбЇЯАжаЯрЗДЕФЮЪЬтЃЌЛсбЯжиЧЗФтКЯЃЈвђЮЊЩюЖШЭјТчЕФЩёОдЊКЭВЮЪ§ЬЋЖрСЫЃЉЁЃ
2006ФъЃЌhintonЬсГіСЫдкЗЧМрЖНЪ§ОнЩЯНЈСЂЖрВуЩёОЭјТчЕФвЛИігааЇЗНЗЈЃЌМђЕЅЕФЫЕЃЌЗжЮЊСНВНЃЌвЛЪЧУПДЮбЕСЗвЛВуЭјТчЃЌЖўЪЧЕїгХЃЌЪЙдЪМБэЪОxЯђЩЯЩњГЩЕФИпМЖБэЪОrКЭИУИпМЖБэЪОrЯђЯТЩњГЩЕФx'ОЁПЩФмвЛжТЁЃЗНЗЈЪЧЃК
1ЃЉЪзЯШж№ВуЙЙНЈЕЅВуЩёОдЊЃЌетбљУПДЮЖМЪЧбЕСЗвЛИіЕЅВуЭјТчЁЃ
2ЃЉЕБЫљгаВубЕСЗЭъКѓЃЌHintonЪЙгУwake-sleepЫуЗЈНјааЕїгХЁЃ
НЋГ§зюЖЅВуЕФЦфЫќВуМфЕФШЈжиБфЮЊЫЋЯђЕФЃЌетбљзюЖЅВуШдШЛЪЧвЛИіЕЅВуЩёОЭјТчЃЌЖјЦфЫќВудђБфЮЊСЫЭМФЃаЭЁЃЯђЩЯЕФШЈжигУгкЁАШЯжЊЁБЃЌЯђЯТЕФШЈжигУгкЁАЩњГЩЁБЁЃШЛКѓЪЙгУWake-SleepЫуЗЈЕїећЫљгаЕФШЈжиЁЃШУШЯжЊКЭЩњГЩДяГЩвЛжТЃЌвВОЭЪЧБЃжЄЩњГЩЕФзюЖЅВуБэЪОФмЙЛОЁПЩФме§ШЗЕФИДдЕзВуЕФНсЕуЁЃБШШчЖЅВуЕФвЛИіНсЕуБэЪОШЫСГЃЌФЧУДЫљгаШЫСГЕФЭМЯёгІИУМЄЛюетИіНсЕуЃЌВЂЧветИіНсЙћЯђЯТЩњГЩЕФЭМЯёгІИУФмЙЛБэЯжЮЊвЛИіДѓИХЕФШЫСГЭМЯёЁЃWake-SleepЫуЗЈЗжЮЊабЃЈwakeЃЉКЭЫЏЃЈsleepЃЉСНИіВПЗжЁЃ
1ЃЉwakeНзЖЮЃКШЯжЊЙ§ГЬЃЌЭЈЙ§ЭтНчЕФЬиеїКЭЯђЩЯЕФШЈжиЃЈШЯжЊШЈжиЃЉВњЩњУПвЛВуЕФГщЯѓБэЪОЃЈНсЕузДЬЌЃЉЃЌВЂЧвЪЙгУЬнЖШЯТНЕаоИФВуМфЕФЯТааШЈжиЃЈЩњГЩШЈжиЃЉЁЃвВОЭЪЧЁАШчЙћЯжЪЕИњЮвЯыЯѓЕФВЛвЛбљЃЌИФБфЮвЕФШЈжиЪЙЕУЮвЯыЯѓЕФЖЋЮїОЭЪЧетбљЕФЁБЁЃ
2ЃЉsleepНзЖЮЃКЩњГЩЙ§ГЬЃЌЭЈЙ§ЖЅВуБэЪОЃЈабЪБбЇЕУЕФИХФюЃЉКЭЯђЯТШЈжиЃЌЩњГЩЕзВуЕФзДЬЌЃЌЭЌЪБаоИФВуМфЯђЩЯЕФШЈжиЁЃвВОЭЪЧЁАШчЙћУЮжаЕФОАЯѓВЛЪЧЮвФджаЕФЯргІИХФюЃЌИФБфЮвЕФШЯжЊШЈжиЪЙЕУетжжОАЯѓдкЮвПДРДОЭЪЧетИіИХФюЁБЁЃ
deep learningбЕСЗЙ§ГЬОпЬхШчЯТЃК
1ЃЉЪЙгУздЯТЩЯЩ§ЗЧМрЖНбЇЯАЃЈОЭЪЧДгЕзВуПЊЪМЃЌвЛВувЛВуЕФЭљЖЅВубЕСЗЃЉЃК
ВЩгУЮоБъЖЈЪ§ОнЃЈгаБъЖЈЪ§ОнвВПЩЃЉЗжВубЕСЗИїВуВЮЪ§ЃЌетвЛВНПЩвдПДзїЪЧвЛИіЮоМрЖНбЕСЗЙ§ГЬЃЌЪЧКЭДЋЭГЩёОЭјТчЧјБ№зюДѓЕФВПЗжЃЈетИіЙ§ГЬПЩвдПДзїЪЧfeature
learningЙ§ГЬЃЉЃК
ОпЬхЕФЃЌЯШгУЮоБъЖЈЪ§ОнбЕСЗЕквЛВуЃЌбЕСЗЪБЯШбЇЯАЕквЛВуЕФВЮЪ§ЃЈетвЛВуПЩвдПДзїЪЧЕУЕНвЛИіЪЙЕУЪфГіКЭЪфШыВюБ№зюаЁЕФШ§ВуЩёОЭјТчЕФвўВуЃЉЃЌгЩгкФЃаЭcapacityЕФЯожЦвдМАЯЁЪшаддМЪјЃЌЪЙЕУЕУЕНЕФФЃаЭФмЙЛбЇЯАЕНЪ§ОнБОЩэЕФНсЙЙЃЌДгЖјЕУЕНБШЪфШыИќОпгаБэЪОФмСІЕФЬиеїЃЛдкбЇЯАЕУЕНЕкn-1ВуКѓЃЌНЋn-1ВуЕФЪфГізїЮЊЕкnВуЕФЪфШыЃЌбЕСЗЕкnВуЃЌгЩДЫЗжБ№ЕУЕНИїВуЕФВЮЪ§ЃЛ
2ЃЉздЖЅЯђЯТЕФМрЖНбЇЯАЃЈОЭЪЧЭЈЙ§ДјБъЧЉЕФЪ§ОнШЅбЕСЗЃЌЮѓВюздЖЅЯђЯТДЋЪфЃЌЖдЭјТчНјааЮЂЕїЃЉЃК
ЛљгкЕквЛВНЕУЕНЕФИїВуВЮЪ§НјвЛВНfine-tuneећИіЖрВуФЃаЭЕФВЮЪ§ЃЌетвЛВНЪЧвЛИігаМрЖНбЕСЗЙ§ГЬЃЛЕквЛВНРрЫЦЩёОЭјТчЕФЫцЛњГѕЪМЛЏГѕжЕЙ§ГЬЃЌгЩгкDLЕФЕквЛВНВЛЪЧЫцЛњГѕЪМЛЏЃЌЖјЪЧЭЈЙ§бЇЯАЪфШыЪ§ОнЕФНсЙЙЕУЕНЕФЃЌвђЖјетИіГѕжЕИќНгНќШЋОжзюгХЃЌДгЖјФмЙЛШЁЕУИќКУЕФаЇЙћЃЛЫљвдdeep
learningаЇЙћКУКмДѓГЬЖШЩЯЙщЙІгкЕквЛВНЕФfeature learningЙ§ГЬЁЃ
ОХЁЂDeep LearningЕФГЃгУФЃаЭЛђепЗНЗЈ
9.1ЁЂAutoEncoderздЖЏБрТыЦї
Deep LearningзюМђЕЅЕФвЛжжЗНЗЈЪЧРћгУШЫЙЄЩёОЭјТчЕФЬиЕуЃЌШЫЙЄЩёОЭјТчЃЈANNЃЉБОЩэОЭЪЧОпгаВуДЮНсЙЙЕФЯЕЭГЃЌШчЙћИјЖЈвЛИіЩёОЭјТчЃЌЮвУЧМйЩшЦфЪфГігыЪфШыЪЧЯрЭЌЕФЃЌШЛКѓбЕСЗЕїећЦфВЮЪ§ЃЌЕУЕНУПвЛВужаЕФШЈжиЁЃздШЛЕиЃЌЮвУЧОЭЕУЕНСЫЪфШыIЕФМИжжВЛЭЌБэЪОЃЈУПвЛВуДњБэвЛжжБэЪОЃЉЃЌетаЉБэЪООЭЪЧЬиеїЁЃздЖЏБрТыЦїОЭЪЧвЛжжОЁПЩФмИДЯжЪфШыаХКХЕФЩёОЭјТчЁЃЮЊСЫЪЕЯжетжжИДЯжЃЌздЖЏБрТыЦїОЭБиаыВЖзНПЩвдДњБэЪфШыЪ§ОнЕФзюживЊЕФвђЫиЃЌОЭЯёPCAФЧбљЃЌевЕНПЩвдДњБэдаХЯЂЕФжївЊГЩЗжЁЃ
ОпЬхЙ§ГЬМђЕЅЕФЫЕУїШчЯТЃК
1ЃЉИјЖЈЮоБъЧЉЪ§ОнЃЌгУЗЧМрЖНбЇЯАбЇЯАЬиеїЃК 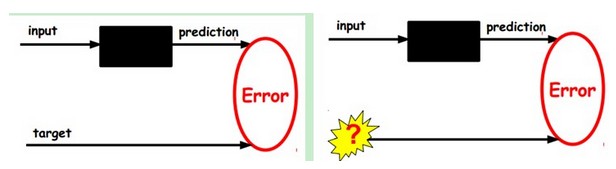
дкЮвУЧжЎЧАЕФЩёОЭјТчжаЃЌШчЕквЛИіЭМЃЌЮвУЧЪфШыЕФбљБОЪЧгаБъЧЉЕФЃЌМДЃЈinput, targetЃЉЃЌетбљЮвУЧИљОнЕБЧАЪфГіКЭtargetЃЈlabelЃЉжЎМфЕФВюШЅИФБфЧАУцИїВуЕФВЮЪ§ЃЌжБЕНЪеСВЁЃЕЋЯждкЮвУЧжЛгаЮоБъЧЉЪ§ОнЃЌвВОЭЪЧгвБпЕФЭМЁЃФЧУДетИіЮѓВюдѕУДЕУЕНФиЃП 
ШчЩЯЭМЃЌЮвУЧНЋinputЪфШывЛИіencoderБрТыЦїЃЌОЭЛсЕУЕНвЛИіcodeЃЌетИіcodeвВОЭЪЧЪфШыЕФвЛИіБэЪОЃЌФЧУДЮвУЧдѕУДжЊЕРетИіcodeБэЪОЕФОЭЪЧinputФиЃПЮвУЧМгвЛИіdecoderНтТыЦїЃЌетЪБКђdecoderОЭЛсЪфГівЛИіаХЯЂЃЌФЧУДШчЙћЪфГіЕФетИіаХЯЂКЭвЛПЊЪМЕФЪфШыаХКХinputЪЧКмЯёЕФЃЈРэЯыЧщПіЯТОЭЪЧвЛбљЕФЃЉЃЌФЧКмУїЯдЃЌЮвУЧОЭгаРэгЩЯраХетИіcodeЪЧППЦзЕФЁЃЫљвдЃЌЮвУЧОЭЭЈЙ§ЕїећencoderКЭdecoderЕФВЮЪ§ЃЌЪЙЕУжиЙЙЮѓВюзюаЁЃЌетЪБКђЮвУЧОЭЕУЕНСЫЪфШыinputаХКХЕФЕквЛИіБэЪОСЫЃЌвВОЭЪЧБрТыcodeСЫЁЃвђЮЊЪЧЮоБъЧЉЪ§ОнЃЌЫљвдЮѓВюЕФРДдДОЭЪЧжБНгжиЙЙКѓгыдЪфШыЯрБШЕУЕНЁЃ

2ЃЉЭЈЙ§БрТыЦїВњЩњЬиеїЃЌШЛКѓбЕСЗЯТвЛВуЁЃетбљж№ВубЕСЗЃК
ФЧЩЯУцЮвУЧОЭЕУЕНЕквЛВуЕФcodeЃЌЮвУЧЕФжиЙЙЮѓВюзюаЁШУЮвУЧЯраХетИіcodeОЭЪЧдЪфШыаХКХЕФСМКУБэДяСЫЃЌЛђепЧЃЧПЕуЫЕЃЌЫќКЭдаХКХЪЧвЛФЃвЛбљЕФЃЈБэДяВЛвЛбљЃЌЗДгГЕФЪЧвЛИіЖЋЮїЃЉЁЃФЧЕкЖўВуКЭЕквЛВуЕФбЕСЗЗНЪНОЭУЛгаВюБ№СЫЃЌЮвУЧНЋЕквЛВуЪфГіЕФcodeЕБГЩЕкЖўВуЕФЪфШыаХКХЃЌЭЌбљзюаЁЛЏжиЙЙЮѓВюЃЌОЭЛсЕУЕНЕкЖўВуЕФВЮЪ§ЃЌВЂЧвЕУЕНЕкЖўВуЪфШыЕФcodeЃЌвВОЭЪЧдЪфШыаХЯЂЕФЕкЖўИіБэДяСЫЁЃЦфЫћВуОЭЭЌбљЕФЗНЗЈХкжЦОЭааСЫЃЈбЕСЗетвЛВуЃЌЧАУцВуЕФВЮЪ§ЖМЪЧЙЬЖЈЕФЃЌВЂЧвЫћУЧЕФdecoderвбОУЛгУСЫЃЌЖМВЛашвЊСЫЃЉЁЃ

3ЃЉгаМрЖНЮЂЕїЃК
ОЙ§ЩЯУцЕФЗНЗЈЃЌЮвУЧОЭПЩвдЕУЕНКмЖрВуСЫЁЃжСгкашвЊЖрЩйВуЃЈЛђепЩюЖШашвЊЖрЩйЃЌетИіФПЧАБОЩэОЭУЛгавЛИіПЦбЇЕФЦРМлЗНЗЈЃЉашвЊздМКЪдбщЕїСЫЁЃУПвЛВуЖМЛсЕУЕНдЪМЪфШыЕФВЛЭЌЕФБэДяЁЃЕБШЛСЫЃЌЮвУЧОѕЕУЫќЪЧдНГщЯѓдНКУСЫЃЌОЭЯёШЫЕФЪгОѕЯЕЭГвЛбљЁЃ
ЕНетРяЃЌетИіAutoEncoderЛЙВЛФмгУРДЗжРрЪ§ОнЃЌвђЮЊЫќЛЙУЛгабЇЯАШчКЮШЅСЌНсвЛИіЪфШыКЭвЛИіРрЁЃЫќжЛЪЧбЇЛсСЫШчКЮШЅжиЙЙЛђепИДЯжЫќЕФЪфШыЖјвбЁЃЛђепЫЕЃЌЫќжЛЪЧбЇЯАЛёЕУСЫвЛИіПЩвдСМКУДњБэЪфШыЕФЬиеїЃЌетИіЬиеїПЩвдзюДѓГЬЖШЩЯДњБэдЪфШыаХКХЁЃФЧУДЃЌЮЊСЫЪЕЯжЗжРрЃЌЮвУЧОЭПЩвддкAutoEncoderЕФзюЖЅЕФБрТыВуЬэМгвЛИіЗжРрЦїЃЈР§ШчТоНмЫЙЬиЛиЙщЁЂSVMЕШЃЉЃЌШЛКѓЭЈЙ§БъзМЕФЖрВуЩёОЭјТчЕФМрЖНбЕСЗЗНЗЈЃЈЬнЖШЯТНЕЗЈЃЉШЅбЕСЗЁЃ
вВОЭЪЧЫЕЃЌетЪБКђЃЌЮвУЧашвЊНЋзюКѓВуЕФЬиеїcodeЪфШыЕНзюКѓЕФЗжРрЦїЃЌЭЈЙ§гаБъЧЉбљБОЃЌЭЈЙ§МрЖНбЇЯАНјааЮЂЕїЃЌетвВЗжСНжжЃЌвЛИіЪЧжЛЕїећЗжРрЦїЃЈКкЩЋВПЗжЃЉЃК 
вЛЕЉМрЖНбЕСЗЭъГЩЃЌетИіЭјТчОЭПЩвдгУРДЗжРрСЫЁЃЩёОЭјТчЕФзюЖЅВуПЩвдзїЮЊвЛИіЯпадЗжРрЦїЃЌШЛКѓЮвУЧПЩвдгУвЛИіИќКУадФмЕФЗжРрЦїШЅШЁДњЫќЁЃ
дкбаОПжаПЩвдЗЂЯжЃЌШчЙћдкдгаЕФЬиеїжаМгШыетаЉздЖЏбЇЯАЕУЕНЕФЬиеїПЩвдДѓДѓЬсИпОЋШЗЖШЃЌЩѕжСдкЗжРрЮЪЬтжаБШФПЧАзюКУЕФЗжРрЫуЗЈаЇЙћЛЙвЊКУЃЁ
AutoEncoderДцдквЛаЉБфЬхЃЌетРяМђвЊНщЩмЯТСНИіЃК
Sparse AutoEncoderЯЁЪшздЖЏБрТыЦїЃК
ЕБШЛЃЌЮвУЧЛЙПЩвдМЬајМгЩЯвЛаЉдМЪјЬѕМўЕУЕНаТЕФDeep LearningЗНЗЈЃЌШчЃКШчЙћдкAutoEncoderЕФЛљДЁЩЯМгЩЯL1ЕФRegularityЯожЦЃЈL1жївЊЪЧдМЪјУПвЛВужаЕФНкЕужаДѓВПЗжЖМвЊЮЊ0ЃЌжЛгаЩйЪ§ВЛЮЊ0ЃЌетОЭЪЧSparseУћзжЕФРДдДЃЉЃЌЮвУЧОЭПЩвдЕУЕНSparse
AutoEncoderЗЈЁЃ 
ШчЩЯЭМЃЌЦфЪЕОЭЪЧЯожЦУПДЮЕУЕНЕФБэДяcodeОЁСПЯЁЪшЁЃвђЮЊЯЁЪшЕФБэДяЭљЭљБШЦфЫћЕФБэДявЊгааЇЃЈШЫФдКУЯёвВЪЧетбљЕФЃЌФГИіЪфШыжЛЪЧДЬМЄФГаЉЩёОдЊЃЌЦфЫћЕФДѓВПЗжЕФЩёОдЊЪЧЪмЕНвжжЦЕФЃЉЁЃ
Denoising AutoEncodersНЕдыздЖЏБрТыЦїЃК
НЕдыздЖЏБрТыЦїDAЪЧдкздЖЏБрТыЦїЕФЛљДЁЩЯЃЌбЕСЗЪ§ОнМгШыдыЩљЃЌЫљвдздЖЏБрТыЦїБиаыбЇЯАШЅШЅГ§етжждыЩљЖјЛёЕУеце§ЕФУЛгаБЛдыЩљЮлШОЙ§ЕФЪфШыЁЃвђДЫЃЌетОЭЦШЪЙБрТыЦїШЅбЇЯАЪфШыаХКХЕФИќМгТГАєЕФБэДяЃЌетвВЪЧЫќЕФЗКЛЏФмСІБШвЛАуБрТыЦїЧПЕФдвђЁЃDAПЩвдЭЈЙ§ЬнЖШЯТНЕЫуЗЈШЅбЕСЗЁЃ

9.2ЁЂSparse CodingЯЁЪшБрТы

етжжЗНЗЈБЛГЦЮЊSparse CodingЁЃЭЈЫзЕФЫЕЃЌОЭЪЧНЋвЛИіаХКХБэЪОЮЊвЛзщЛљЕФЯпадзщКЯЃЌЖјЧввЊЧѓжЛашвЊНЯЩйЕФМИИіЛљОЭПЩвдНЋаХКХБэЪОГіРДЁЃЁАЯЁЪшадЁБЖЈвхЮЊЃКжЛгаКмЩйЕФМИИіЗЧСудЊЫиЛђжЛгаКмЩйЕФМИИідЖДѓгкСуЕФдЊЫиЁЃвЊЧѓЯЕЪ§
ai ЪЧЯЁЪшЕФвтЫМОЭЪЧЫЕЃКЖдгквЛзщЪфШыЯђСПЃЌЮвУЧжЛЯыгаОЁПЩФмЩйЕФМИИіЯЕЪ§дЖДѓгкСуЁЃбЁдёЪЙгУОпгаЯЁЪшадЕФЗжСПРДБэЪОЮвУЧЕФЪфШыЪ§ОнЪЧгадвђЕФЃЌвђЮЊОјДѓЖрЪ§ЕФИаЙйЪ§ОнЃЌБШШчздШЛЭМЯёЃЌПЩвдБЛБэЪОГЩЩйСПЛљБОдЊЫиЕФЕўМгЃЌдкЭМЯёжаетаЉЛљБОдЊЫиПЩвдЪЧУцЛђепЯпЁЃЭЌЪБЃЌБШШчгыГѕМЖЪгОѕЦЄВуЕФРрБШЙ§ГЬвВвђДЫЕУЕНСЫЬсЩ§ЃЈШЫФдгаДѓСПЕФЩёОдЊЃЌЕЋЖдгкФГаЉЭМЯёЛђепБпдЕжЛгаКмЩйЕФЩёОдЊаЫЗмЃЌЦфЫћЖМДІгквжжЦзДЬЌЃЉЁЃ
ЯЁЪшБрТыЫуЗЈЪЧвЛжжЮоМрЖНбЇЯАЗНЗЈЃЌЫќгУРДбАеввЛзщЁАГЌЭъБИЁБЛљЯђСПРДИќИпаЇЕиБэЪОбљБОЪ§ОнЁЃЫфШЛаЮШчжїГЩЗжЗжЮіММЪѕЃЈPCAЃЉФмЪЙЮвУЧЗНБуЕиевЕНвЛзщЁАЭъБИЁБЛљЯђСПЃЌЕЋЪЧетРяЮвУЧЯывЊзіЕФЪЧевЕНвЛзщЁАГЌЭъБИЁБЛљЯђСПРДБэЪОЪфШыЯђСПЃЈвВОЭЪЧЫЕЃЌЛљЯђСПЕФИіЪ§БШЪфШыЯђСПЕФЮЌЪ§вЊДѓЃЉЁЃГЌЭъБИЛљЕФКУДІЪЧЫќУЧФмИќгааЇЕиевГівўКЌдкЪфШыЪ§ОнФкВПЕФНсЙЙгыФЃЪНЁЃШЛЖјЃЌЖдгкГЌЭъБИЛљРДЫЕЃЌЯЕЪ§aiВЛдйгЩЪфШыЯђСПЮЈвЛШЗЖЈЁЃвђДЫЃЌдкЯЁЪшБрТыЫуЗЈжаЃЌЮвУЧСэМгСЫвЛИіЦРХаБъзМЁАЯЁЪшадЁБРДНтОівђГЌЭъБИЖјЕМжТЕФЭЫЛЏЃЈdegeneracyЃЉЮЪЬтЁЃЃЈЯъЯИЙ§ГЬЧыВЮПМЃКUFLDL
TutorialЯЁЪшБрТыЃЉ

БШШчдкЭМЯёЕФFeature ExtractionЕФзюЕзВувЊзіEdge DetectorЕФЩњГЩЃЌФЧУДетРяЕФЙЄзїОЭЪЧДгNatural
ImagesжаrandomlyбЁШЁвЛаЉаЁpatchЃЌЭЈЙ§етаЉpatchЩњГЩФмЙЛУшЪіЫћУЧЕФЁАЛљЁБЃЌвВОЭЪЧгвБпЕФ8*8=64ИіbasisзщГЩЕФbasisЃЌШЛКѓИјЖЈвЛИіtest
patch, ЮвУЧПЩвдАДееЩЯУцЕФЪНзгЭЈЙ§basisЕФЯпадзщКЯЕУЕНЃЌЖјsparse matrixОЭЪЧaЃЌЯТЭМжаЕФaжага64ИіЮЌЖШЃЌЦфжаЗЧСуЯюжЛга3ИіЃЌЙЪГЦЁАsparseЁБЁЃ
етРяПЩФмДѓМвЛсгавЩЮЪЃЌЮЊЪВУДАбЕзВузїЮЊEdge DetectorФиЃПЩЯВугжЪЧЪВУДФиЃПетРязіИіМђЕЅНтЪЭДѓМвОЭЛсУїАзЃЌжЎЫљвдЪЧEdge
DetectorЪЧвђЮЊВЛЭЌЗНЯђЕФEdgeОЭФмЙЛУшЪіГіећЗљЭМЯёЃЌЫљвдВЛЭЌЗНЯђЕФEdgeздШЛОЭЪЧЭМЯёЕФbasisСЫЁЁЖјЩЯвЛВуЕФbasisзщКЯЕФНсЙћЃЌЩЯЩЯВугжЪЧЩЯвЛВуЕФзщКЯbasisЁЁЃЈОЭЪЧЩЯУцЕкЫФВПЗжЕФЪБКђдлУЧЫЕЕФФЧбљЃЉ
Sparse codingЗжЮЊСНИіВПЗжЃК
1ЃЉTrainingНзЖЮЃКИјЖЈвЛЯЕСаЕФбљБОЭМЦЌ[x1, x 2, Ё]ЃЌЮвУЧашвЊбЇЯАЕУЕНвЛзщЛљ[ІЕ1,
ІЕ2, Ё]ЃЌвВОЭЪЧзжЕфЁЃ
ЯЁЪшБрТыЪЧk-meansЫуЗЈЕФБфЬхЃЌЦфбЕСЗЙ§ГЬвВВюВЛЖрЃЈEMЫуЗЈЕФЫМЯыЃКШчЙћвЊгХЛЏЕФФПБъКЏЪ§АќКЌСНИіБфСПЃЌШчL(W,
B)ЃЌФЧУДЮвУЧПЩвдЯШЙЬЖЈWЃЌЕїећBЪЙЕУLзюаЁЃЌШЛКѓдйЙЬЖЈBЃЌЕїећWЪЙLзюаЁЃЌетбљЕќДњНЛЬцЃЌВЛЖЯНЋLЭЦЯђзюаЁжЕЁЃEMЫуЗЈПЩвдМћЮвЕФВЉПЭЃКЁАДгзюДѓЫЦШЛЕНEMЫуЗЈЧГНтЁБЃЉЁЃ
бЕСЗЙ§ГЬОЭЪЧвЛИіжиИДЕќДњЕФЙ§ГЬЃЌАДЩЯУцЫљЫЕЃЌЮвУЧНЛЬцЕФИќИФaКЭІЕЪЙЕУЯТУцетИіФПБъКЏЪ§зюаЁЁЃ 
УПДЮЕќДњЗжСНВНЃК
aЃЉЙЬЖЈзжЕфІЕ[k]ЃЌШЛКѓЕїећa[k]ЃЌЪЙЕУЩЯЪНЃЌМДФПБъКЏЪ§зюаЁЃЈМДНтLASSOЮЪЬтЃЉЁЃ
bЃЉШЛКѓЙЬЖЈзЁa [k]ЃЌЕїећІЕ [k]ЃЌЪЙЕУЩЯЪНЃЌМДФПБъКЏЪ§зюаЁЃЈМДНтЭЙQPЮЪЬтЃЉЁЃ
ВЛЖЯЕќДњЃЌжБжСЪеСВЁЃетбљОЭПЩвдЕУЕНвЛзщПЩвдСМКУБэЪОетвЛЯЕСаxЕФЛљЃЌвВОЭЪЧзжЕфЁЃ
2ЃЉCodingНзЖЮЃКИјЖЈвЛИіаТЕФЭМЦЌxЃЌгЩЩЯУцЕУЕНЕФзжЕфЃЌЭЈЙ§НтвЛИіLASSOЮЪЬтЕУЕНЯЁЪшЯђСПaЁЃетИіЯЁЪшЯђСПОЭЪЧетИіЪфШыЯђСПxЕФвЛИіЯЁЪшБэДяСЫЁЃ 
9.3ЁЂRestricted Boltzmann Machine (RBM)ЯожЦВЈЖћзШТќЛњ
МйЩшгавЛИіЖўВПЭМЃЌУПвЛВуЕФНкЕужЎМфУЛгаСДНгЃЌвЛВуЪЧПЩЪгВуЃЌМДЪфШыЪ§ОнВуЃЈv)ЃЌвЛВуЪЧвўВиВу(h)ЃЌШчЙћМйЩшЫљгаЕФНкЕуЖМЪЧЫцЛњЖўжЕБфСПНкЕуЃЈжЛФмШЁ0Лђеп1жЕЃЉЃЌЭЌЪБМйЩшШЋИХТЪЗжВМp(v,h)ТњзуBoltzmann
ЗжВМЃЌЮвУЧГЦетИіФЃаЭЪЧRestricted BoltzmannMachine (RBM)ЁЃ 
ЯТУцЮвУЧРДПДПДЮЊЪВУДЫќЪЧDeep LearningЗНЗЈЁЃЪзЯШЃЌетИіФЃаЭвђЮЊЪЧЖўВПЭМЃЌЫљвддквбжЊvЕФЧщПіЯТЃЌЫљгаЕФвўВиНкЕужЎМфЪЧЬѕМўЖРСЂЕФЃЈвђЮЊНкЕужЎМфВЛДцдкСЌНгЃЉЃЌМДp(h|v)=p(h1|v)Ёp(hn|v)ЁЃЭЌРэЃЌдквбжЊвўВиВуhЕФЧщПіЯТЃЌЫљгаЕФПЩЪгНкЕуЖМЪЧЬѕМўЖРСЂЕФЁЃЭЌЪБгжгЩгкЫљгаЕФvКЭhТњзуBoltzmann
ЗжВМЃЌвђДЫЃЌЕБЪфШыvЕФЪБКђЃЌЭЈЙ§p(h|v) ПЩвдЕУЕНвўВиВуhЃЌЖјЕУЕНвўВиВуhжЎКѓЃЌЭЈЙ§p(v|h)гжФмЕУЕНПЩЪгВуЃЌЭЈЙ§ЕїећВЮЪ§ЃЌЮвУЧОЭЪЧвЊЪЙЕУДгвўВиВуЕУЕНЕФПЩЪгВуv1гыдРДЕФПЩЪгВуvШчЙћвЛбљЃЌФЧУДЕУЕНЕФвўВиВуОЭЪЧПЩЪгВуСэЭтвЛжжБэДяЃЌвђДЫвўВиВуПЩвдзїЮЊПЩЪгВуЪфШыЪ§ОнЕФЬиеїЃЌЫљвдЫќОЭЪЧвЛжжDeep
LearningЗНЗЈЁЃ


ШчЙћЃЌЮвУЧАбвўВиВуЕФВуЪ§діМгЃЌЮвУЧПЩвдЕУЕНDeep Boltzmann Machine(DBM)ЃЛШчЙћЮвУЧдкППНќПЩЪгВуЕФВПЗжЪЙгУБДвЖЫЙаХФюЭјТчЃЈМДгаЯђЭМФЃаЭЃЌЕБШЛетРявРШЛЯожЦВужаНкЕужЎМфУЛгаСДНгЃЉЃЌЖјдкзюдЖРыПЩЪгВуЕФВПЗжЪЙгУRestricted
Boltzmann MachineЃЌЮвУЧПЩвдЕУЕНDeepBelief NetЃЈDBNЃЉЁЃ 
9.4ЁЂDeep Belief NetworksЩюаХЖШЭјТч
DBNsЪЧвЛИіИХТЪЩњГЩФЃаЭЃЌгыДЋЭГЕФХаБ№ФЃаЭЕФЩёОЭјТчЯрЖдЃЌЩњГЩФЃаЭЪЧНЈСЂвЛИіЙлВьЪ§ОнКЭБъЧЉжЎМфЕФСЊКЯЗжВМЃЌЖдP(Observation|Label)КЭ
P(Label|Observation)ЖМзіСЫЦРЙРЃЌЖјХаБ№ФЃаЭНіНіЖјвбЦРЙРСЫКѓепЃЌвВОЭЪЧP(Label|Observation)ЁЃЖдгкдкЩюЖШЩёОЭјТчгІгУДЋЭГЕФBPЫуЗЈЕФЪБКђЃЌDBNsгіЕНСЫвдЯТЮЪЬтЃК
ЃЈ1ЃЉашвЊЮЊбЕСЗЬсЙЉвЛИігаБъЧЉЕФбљБОМЏЃЛ
ЃЈ2ЃЉбЇЯАЙ§ГЬНЯТ§ЃЛ
ЃЈ3ЃЉВЛЪЪЕБЕФВЮЪ§бЁдёЛсЕМжТбЇЯАЪеСВгкОжВПзюгХНтЁЃ 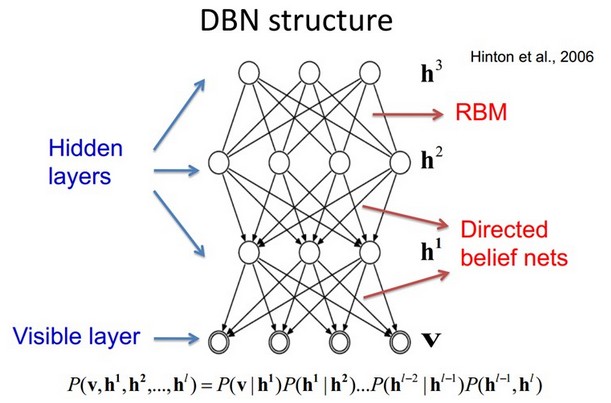
DBNsгЩЖрИіЯожЦВЃЖћзШТќЛњЃЈRestricted Boltzmann MachinesЃЉВузщГЩЃЌвЛИіЕфаЭЕФЩёОЭјТчРраЭШчЭМШ§ЫљЪОЁЃетаЉЭјТчБЛЁАЯожЦЁБЮЊвЛИіПЩЪгВуКЭвЛИівўВуЃЌВуМфДцдкСЌНгЃЌЕЋВуФкЕФЕЅдЊМфВЛДцдкСЌНгЁЃвўВуЕЅдЊБЛбЕСЗШЅВЖзНдкПЩЪгВуБэЯжГіРДЕФИпНзЪ§ОнЕФЯрЙиадЁЃ
ЪзЯШЃЌЯШВЛПМТЧзюЖЅЙЙГЩвЛИіСЊЯыМЧвфЃЈassociative memoryЃЉЕФСНВуЃЌвЛИіDBNЕФСЌНгЪЧЭЈЙ§здЖЅЯђЯТЕФЩњГЩШЈжЕРДжИЕМШЗЖЈЕФЃЌRBMsОЭЯёвЛИіНЈжўПщвЛбљЃЌЯрБШДЋЭГКЭЩюЖШЗжВуЕФsigmoidаХФюЭјТчЃЌЫќФмвзгкСЌНгШЈжЕЕФбЇЯАЁЃ
зюПЊЪМЕФЪБКђЃЌЭЈЙ§вЛИіЗЧМрЖНЬАРЗж№ВуЗНЗЈШЅдЄбЕСЗЛёЕУЩњГЩФЃаЭЕФШЈжЕЃЌЗЧМрЖНЬАРЗж№ВуЗНЗЈБЛHintonжЄУїЪЧгааЇЕФЃЌВЂБЛЦфГЦЮЊЖдБШЗжЦчЃЈcontrastive
divergenceЃЉЁЃ
дкетИібЕСЗНзЖЮЃЌдкПЩЪгВуЛсВњЩњвЛИіЯђСПvЃЌЭЈЙ§ЫќНЋжЕДЋЕнЕНвўВуЁЃЗДЙ§РДЃЌПЩЪгВуЕФЪфШыЛсБЛЫцЛњЕФбЁдёЃЌвдГЂЪдШЅжиЙЙдЪМЕФЪфШыаХКХЁЃзюКѓЃЌетаЉаТЕФПЩЪгЕФЩёОдЊМЄЛюЕЅдЊНЋЧАЯђДЋЕнжиЙЙвўВуМЄЛюЕЅдЊЃЌЛёЕУhЃЈдкбЕСЗЙ§ГЬжаЃЌЪзЯШНЋПЩЪгЯђСПжЕгГЩфИјвўЕЅдЊЃЛШЛКѓПЩЪгЕЅдЊгЩвўВуЕЅдЊжиНЈЃЛетаЉаТПЩЪгЕЅдЊдйДЮгГЩфИјвўЕЅдЊЃЌетбљОЭЛёШЁаТЕФвўЕЅдЊЁЃжДааетжжЗДИДВНжшНазіМЊВМЫЙВЩбљЃЉЁЃетаЉКѓЭЫКЭЧАНјЕФВНжшОЭЪЧЮвУЧЪьЯЄЕФGibbsВЩбљЃЌЖјвўВуМЄЛюЕЅдЊКЭПЩЪгВуЪфШыжЎМфЕФЯрЙиадВюБ№ОЭзїЮЊШЈжЕИќаТЕФжївЊвРОнЁЃ
бЕСЗЪБМфЛсЯджјЕФМѕЩйЃЌвђЮЊжЛашвЊЕЅИіВНжшОЭПЩвдНгНќзюДѓЫЦШЛбЇЯАЁЃдіМгНјЭјТчЕФУПвЛВуЖМЛсИФНјбЕСЗЪ§ОнЕФЖдЪ§ИХТЪЃЌЮвУЧПЩвдРэНтЮЊдНРДдННгНќФмСПЕФецЪЕБэДяЁЃетИігавтвхЕФЭиеЙЃЌКЭЮоБъЧЉЪ§ОнЕФЪЙгУЃЌЪЧШЮКЮвЛИіЩюЖШбЇЯАгІгУЕФОіЖЈадЕФвђЫиЁЃ 
дкзюИпСНВуЃЌШЈжЕБЛСЌНгЕНвЛЦ№ЃЌетбљИќЕЭВуЕФЪфГіНЋЛсЬсЙЉвЛИіВЮПМЕФЯпЫїЛђепЙиСЊИјЖЅВуЃЌетбљЖЅВуОЭЛсНЋЦфСЊЯЕЕНЫќЕФМЧвфФкШнЁЃЖјЮвУЧзюЙиаФЕФЃЌзюКѓЯыЕУЕНЕФОЭЪЧХаБ№адФмЃЌР§ШчЗжРрШЮЮёРяУцЁЃ
дкдЄбЕСЗКѓЃЌDBNПЩвдЭЈЙ§РћгУДјБъЧЉЪ§ОнгУBPЫуЗЈШЅЖдХаБ№адФмзіЕїећЁЃдкетРяЃЌвЛИіБъЧЉМЏНЋБЛИНМгЕНЖЅВуЃЈЭЦЙуСЊЯыМЧвфЃЉЃЌЭЈЙ§вЛИіздЯТЯђЩЯЕФЃЌбЇЯАЕНЕФЪЖБ№ШЈжЕЛёЕУвЛИіЭјТчЕФЗжРрУцЁЃетИіадФмЛсБШЕЅДПЕФBPЫуЗЈбЕСЗЕФЭјТчКУЁЃетПЩвдКмжБЙлЕФНтЪЭЃЌDBNsЕФBPЫуЗЈжЛашвЊЖдШЈжЕВЮЪ§ПеМфНјаавЛИіОжВПЕФЫбЫїЃЌетЯрБШЧАЯђЩёОЭјТчРДЫЕЃЌбЕСЗЪЧвЊПьЕФЃЌЖјЧвЪеСВЕФЪБМфвВЩйЁЃ
DBNsЕФСщЛюадЪЙЕУЫќЕФЭиеЙБШНЯШнвзЁЃвЛИіЭиеЙОЭЪЧОэЛ§DBNsЃЈConvolutional Deep
Belief Networks(CDBNs)ЃЉЁЃDBNsВЂУЛгаПМТЧЕНЭМЯёЕФ2ЮЌНсЙЙаХЯЂЃЌвђЮЊЪфШыЪЧМђЕЅЕФДгвЛИіЭМЯёОиеѓвЛЮЌЯђСПЛЏЕФЁЃЖјCDBNsОЭЪЧПМТЧЕНСЫетИіЮЪЬтЃЌЫќРћгУСкгђЯёЫиЕФПегђЙиЯЕЃЌЭЈЙ§вЛИіГЦЮЊОэЛ§RBMsЕФФЃаЭЧјДяЕНЩњГЩФЃаЭЕФБфЛЛВЛБфадЃЌЖјЧвПЩвдШнвзЕУБфЛЛЕНИпЮЌЭМЯёЁЃDBNsВЂУЛгаУїШЗЕиДІРэЖдЙлВьБфСПЕФЪБМфСЊЯЕЕФбЇЯАЩЯЃЌЫфШЛФПЧАвбОгаетЗНУцЕФбаОПЃЌР§ШчЖбЕўЪБМфRBMsЃЌвдДЫЮЊЭЦЙуЃЌгаађСабЇЯАЕФdubbed
temporal convolutionmachinesЃЌетжжађСабЇЯАЕФгІгУЃЌИјгявєаХКХДІРэЮЪЬтДјРДСЫвЛИіШУШЫМЄЖЏЕФЮДРДбаОПЗНЯђЁЃ
ФПЧАЃЌКЭDBNsгаЙиЕФбаОПАќРЈЖбЕўздЖЏБрТыЦїЃЌЫќЪЧЭЈЙ§гУЖбЕўздЖЏБрТыЦїРДЬцЛЛДЋЭГDBNsРяУцЕФRBMsЁЃетОЭЪЙЕУПЩвдЭЈЙ§ЭЌбљЕФЙцдђРДбЕСЗВњЩњЩюЖШЖрВуЩёОЭјТчМмЙЙЃЌЕЋЫќШБЩйВуЕФВЮЪ§ЛЏЕФбЯИёвЊЧѓЁЃгыDBNsВЛЭЌЃЌздЖЏБрТыЦїЪЙгУХаБ№ФЃаЭЃЌетбљетИіНсЙЙОЭКмФбВЩбљЪфШыВЩбљПеМфЃЌетОЭЪЙЕУЭјТчИќФбВЖзНЫќЕФФкВПБэДяЁЃЕЋЪЧЃЌНЕдыздЖЏБрТыЦїШДФмКмКУЕФБмУтетИіЮЪЬтЃЌВЂЧвБШДЋЭГЕФDBNsИќгХЁЃЫќЭЈЙ§дкбЕСЗЙ§ГЬЬэМгЫцЛњЕФЮлШОВЂЖбЕўВњЩњГЁЗКЛЏадФмЁЃбЕСЗЕЅвЛЕФНЕдыздЖЏБрТыЦїЕФЙ§ГЬКЭRBMsбЕСЗЩњГЩФЃаЭЕФЙ§ГЬвЛбљЁЃ
9.5ЁЂConvolutional Neural NetworksОэЛ§ЩёОЭјТч
ОэЛ§ЩёОЭјТчЪЧШЫЙЄЩёОЭјТчЕФвЛжжЃЌвбГЩЮЊЕБЧАгявєЗжЮіКЭЭМЯёЪЖБ№СьгђЕФбаОПШШЕуЁЃЫќЕФШЈжЕЙВЯэЭјТчНсЙЙЪЙжЎИќРрЫЦгкЩњЮяЩёОЭјТчЃЌНЕЕЭСЫЭјТчФЃаЭЕФИДдгЖШЃЌМѕЩйСЫШЈжЕЕФЪ§СПЁЃИУгХЕудкЭјТчЕФЪфШыЪЧЖрЮЌЭМЯёЪББэЯжЕФИќЮЊУїЯдЃЌЪЙЭМЯёПЩвджБНгзїЮЊЭјТчЕФЪфШыЃЌБмУтСЫДЋЭГЪЖБ№ЫуЗЈжаИДдгЕФЬиеїЬсШЁКЭЪ§ОнжиНЈЙ§ГЬЁЃОэЛ§ЭјТчЪЧЮЊЪЖБ№ЖўЮЌаЮзДЖјЬиЪтЩшМЦЕФвЛИіЖрВуИажЊЦїЃЌетжжЭјТчНсЙЙЖдЦНвЦЁЂБШР§ЫѕЗХЁЂЧуаБЛђепЙВЫћаЮЪНЕФБфаЮОпгаИпЖШВЛБфадЁЃ
CNNsЪЧЪмдчЦкЕФбгЪБЩёОЭјТчЃЈTDNNЃЉЕФгАЯьЁЃбгЪБЩёОЭјТчЭЈЙ§дкЪБМфЮЌЖШЩЯЙВЯэШЈжЕНЕЕЭбЇЯАИДдгЖШЃЌЪЪгУгкгявєКЭЪБМфађСааХКХЕФДІРэЁЃ
CNNsЪЧЕквЛИіеце§ГЩЙІбЕСЗЖрВуЭјТчНсЙЙЕФбЇЯАЫуЗЈЁЃЫќРћгУПеМфЙиЯЕМѕЩйашвЊбЇЯАЕФВЮЪ§Ъ§ФПвдЬсИпвЛАуЧАЯђBPЫуЗЈЕФбЕСЗадФмЁЃCNNsзїЮЊвЛИіЩюЖШбЇЯАМмЙЙЬсГіЪЧЮЊСЫзюаЁЛЏЪ§ОнЕФдЄДІРэвЊЧѓЁЃдкCNNжаЃЌЭМЯёЕФвЛаЁВПЗжЃЈОжВПИаЪмЧјгђЃЉзїЮЊВуМЖНсЙЙЕФзюЕЭВуЕФЪфШыЃЌаХЯЂдйвРДЮДЋЪфЕНВЛЭЌЕФВуЃЌУПВуЭЈЙ§вЛИіЪ§зжТЫВЈЦїШЅЛёЕУЙлВтЪ§ОнЕФзюЯджјЕФЬиеїЁЃетИіЗНЗЈФмЙЛЛёШЁЖдЦНвЦЁЂЫѕЗХКЭа§зЊВЛБфЕФЙлВтЪ§ОнЕФЯджјЬиеїЃЌвђЮЊЭМЯёЕФОжВПИаЪмЧјгђдЪаэЩёОдЊЛђепДІРэЕЅдЊПЩвдЗУЮЪЕНзюЛљДЁЕФЬиеїЃЌР§ШчЖЈЯђБпдЕЛђепНЧЕуЁЃ
1ЃЉОэЛ§ЩёОЭјТчЕФРњЪЗ
1962ФъHubelКЭWieselЭЈЙ§ЖдУЈЪгОѕЦЄВуЯИАћЕФбаОПЃЌЬсГіСЫИаЪмвА(receptive field)ЕФИХФюЃЌ1984ФъШеБОбЇепFukushimaЛљгкИаЪмвАИХФюЬсГіЕФЩёОШЯжЊЛњ(neocognitron)ПЩвдПДзїЪЧОэЛ§ЩёОЭјТчЕФЕквЛИіЪЕЯжЭјТчЃЌвВЪЧИаЪмвАИХФюдкШЫЙЄЩёОЭјТчСьгђЕФЪзДЮгІгУЁЃЩёОШЯжЊЛњНЋвЛИіЪгОѕФЃЪНЗжНтГЩаэЖрзгФЃЪНЃЈЬиеїЃЉЃЌШЛКѓНјШыЗжВуЕнНзЪНЯрСЌЕФЬиеїЦНУцНјааДІРэЃЌЫќЪдЭМНЋЪгОѕЯЕЭГФЃаЭЛЏЃЌЪЙЦфФмЙЛдкМДЪЙЮяЬхгаЮЛвЦЛђЧсЮЂБфаЮЕФЪБКђЃЌвВФмЭъГЩЪЖБ№ЁЃ
ЭЈГЃЩёОШЯжЊЛњАќКЌСНРрЩёОдЊЃЌМДГаЕЃЬиеїГщШЁЕФS-дЊКЭПЙБфаЮЕФC-дЊЁЃS-дЊжаЩцМАСНИіживЊВЮЪ§ЃЌМДИаЪмвАгыуажЕВЮЪ§ЃЌЧАепШЗЖЈЪфШыСЌНгЕФЪ§ФПЃЌКѓепдђПижЦЖдЬиеїзгФЃЪНЕФЗДгІГЬЖШЁЃаэЖрбЇепвЛжБжТСІгкЬсИпЩёОШЯжЊЛњЕФадФмЕФбаОПЃКдкДЋЭГЕФЩёОШЯжЊЛњжаЃЌУПИіS-дЊЕФИаЙтЧјжагЩC-дЊДјРДЕФЪгОѕФЃК§СПГЪе§ЬЌЗжВМЁЃШчЙћИаЙтЧјЕФБпдЕЫљВњЩњЕФФЃК§аЇЙћвЊБШжабыРДЕУДѓЃЌS-дЊНЋЛсНгЪметжжЗЧе§ЬЌФЃК§ЫљЕМжТЕФИќДѓЕФБфаЮШнШЬадЁЃЮвУЧЯЃЭћЕУЕНЕФЪЧЃЌбЕСЗФЃЪНгыБфаЮДЬМЄФЃЪНдкИаЪмвАЕФБпдЕгыЦфжааФЫљВњЩњЕФаЇЙћжЎМфЕФВювьБфЕУдНРДдНДѓЁЃЮЊСЫгааЇЕиаЮГЩетжжЗЧе§ЬЌФЃК§ЃЌFukushimaЬсГіСЫДјЫЋC-дЊВуЕФИФНјаЭЩёОШЯжЊЛњЁЃ
Van OoyenКЭNiehuisЮЊЬсИпЩёОШЯжЊЛњЕФЧјБ№ФмСІв§ШыСЫвЛИіаТЕФВЮЪ§ЁЃЪТЪЕЩЯЃЌИУВЮЪ§зїЮЊвЛжжвжжЦаХКХЃЌвжжЦСЫЩёОдЊЖджиИДМЄРјЬиеїЕФМЄРјЁЃЖрЪ§ЩёОЭјТчдкШЈжЕжаМЧвфбЕСЗаХЯЂЁЃИљОнHebbбЇЯАЙцдђЃЌФГжжЬиеїбЕСЗЕФДЮЪ§дНЖрЃЌдквдКѓЕФЪЖБ№Й§ГЬжаОЭдНШнвзБЛМьВтЁЃвВгабЇепНЋНјЛЏМЦЫуРэТлгыЩёОШЯжЊЛњНсКЯЃЌЭЈЙ§МѕШѕЖджиИДадМЄРјЬиеїЕФбЕСЗбЇЯАЃЌЖјЪЙЕУЭјТчзЂвтФЧаЉВЛЭЌЕФЬиеївджњгкЬсИпЧјЗжФмСІЁЃЩЯЪіЖМЪЧЩёОШЯжЊЛњЕФЗЂеЙЙ§ГЬЃЌЖјОэЛ§ЩёОЭјТчПЩПДзїЪЧЩёОШЯжЊЛњЕФЭЦЙуаЮЪНЃЌЩёОШЯжЊЛњЪЧОэЛ§ЩёОЭјТчЕФвЛжжЬиР§ЁЃ
2ЃЉОэЛ§ЩёОЭјТчЕФЭјТчНсЙЙ
ОэЛ§ЩёОЭјТчЪЧвЛИіЖрВуЕФЩёОЭјТчЃЌУПВугЩЖрИіЖўЮЌЦНУцзщГЩЃЌЖјУПИіЦНУцгЩЖрИіЖРСЂЩёОдЊзщГЩЁЃ 
ЭМЃКОэЛ§ЩёОЭјТчЕФИХФюЪОЗЖЃКЪфШыЭМЯёЭЈЙ§КЭШ§ИіПЩбЕСЗЕФТЫВЈЦїКЭПЩМгЦЋжУНјааОэЛ§ЃЌТЫВЈЙ§ГЬШчЭМвЛЃЌОэЛ§КѓдкC1ВуВњЩњШ§ИіЬиеїгГЩфЭМЃЌШЛКѓЬиеїгГЩфЭМжаУПзщЕФЫФИіЯёЫидйНјааЧѓКЭЃЌМгШЈжЕЃЌМгЦЋжУЃЌЭЈЙ§вЛИіSigmoidКЏЪ§ЕУЕНШ§ИіS2ВуЕФЬиеїгГЩфЭМЁЃетаЉгГЩфЭМдйНјЙ§ТЫВЈЕУЕНC3ВуЁЃетИіВуМЖНсЙЙдйКЭS2вЛбљВњЩњS4ЁЃзюжеЃЌетаЉЯёЫижЕБЛЙтеЄЛЏЃЌВЂСЌНгГЩвЛИіЯђСПЪфШыЕНДЋЭГЕФЩёОЭјТчЃЌЕУЕНЪфГіЁЃ
вЛАуЕиЃЌCВуЮЊЬиеїЬсШЁВуЃЌУПИіЩёОдЊЕФЪфШыгыЧАвЛВуЕФОжВПИаЪмвАЯрСЌЃЌВЂЬсШЁИУОжВПЕФЬиеїЃЌвЛЕЉИУОжВПЬиеїБЛЬсШЁКѓЃЌЫќгыЦфЫћЬиеїМфЕФЮЛжУЙиЯЕвВЫцжЎШЗЖЈЯТРДЃЛSВуЪЧЬиеїгГЩфВуЃЌЭјТчЕФУПИіМЦЫуВугЩЖрИіЬиеїгГЩфзщГЩЃЌУПИіЬиеїгГЩфЮЊвЛИіЦНУцЃЌЦНУцЩЯЫљгаЩёОдЊЕФШЈжЕЯрЕШЁЃЬиеїгГЩфНсЙЙВЩгУгАЯьКЏЪ§КЫаЁЕФsigmoidКЏЪ§зїЮЊОэЛ§ЭјТчЕФМЄЛюКЏЪ§ЃЌЪЙЕУЬиеїгГЩфОпгаЮЛвЦВЛБфадЁЃ
ДЫЭтЃЌгЩгквЛИігГЩфУцЩЯЕФЩёОдЊЙВЯэШЈжЕЃЌвђЖјМѕЩйСЫЭјТчздгЩВЮЪ§ЕФИіЪ§ЃЌНЕЕЭСЫЭјТчВЮЪ§бЁдёЕФИДдгЖШЁЃОэЛ§ЩёОЭјТчжаЕФУПвЛИіЬиеїЬсШЁВуЃЈC-ВуЃЉЖМНєИњзХвЛИігУРДЧѓОжВПЦНОљгыЖўДЮЬсШЁЕФМЦЫуВуЃЈS-ВуЃЉЃЌетжжЬигаЕФСНДЮЬиеїЬсШЁНсЙЙЪЙЭјТчдкЪЖБ№ЪБЖдЪфШыбљБОгаНЯИпЕФЛћБфШнШЬФмСІЁЃ
3ЃЉЙигкВЮЪ§МѕЩйгыШЈжЕЙВЯэ
ЩЯУцСФЕНЃЌКУЯёCNNвЛИіХЃБЦЕФЕиЗНОЭдкгкЭЈЙ§ИаЪмвАКЭШЈжЕЙВЯэМѕЩйСЫЩёОЭјТчашвЊбЕСЗЕФВЮЪ§ЕФИіЪ§ЁЃФЧОПОЙЪЧЩЖЕФФиЃП
ЯТЭМзѓЃКШчЙћЮвУЧга1000x1000ЯёЫиЕФЭМЯёЃЌга1АйЭђИівўВуЩёОдЊЃЌФЧУДЫћУЧШЋСЌНгЕФЛАЃЈУПИівўВуЩёОдЊЖМСЌНгЭМЯёЕФУПвЛИіЯёЫиЕуЃЉЃЌОЭга1000x1000x1000000=10^12ИіСЌНгЃЌвВОЭЪЧ10^12ИіШЈжЕВЮЪ§ЁЃШЛЖјЭМЯёЕФПеМфСЊЯЕЪЧОжВПЕФЃЌОЭЯёШЫЪЧЭЈЙ§вЛИіОжВПЕФИаЪмвАШЅИаЪмЭтНчЭМЯёвЛбљЃЌУПвЛИіЩёОдЊЖМВЛашвЊЖдШЋОжЭМЯёзіИаЪмЃЌУПИіЩёОдЊжЛИаЪмОжВПЕФЭМЯёЧјгђЃЌШЛКѓдкИќИпВуЃЌНЋетаЉИаЪмВЛЭЌОжВПЕФЩёОдЊзлКЯЦ№РДОЭПЩвдЕУЕНШЋОжЕФаХЯЂСЫЁЃетбљЃЌЮвУЧОЭПЩвдМѕЩйСЌНгЕФЪ§ФПЃЌвВОЭЪЧМѕЩйЩёОЭјТчашвЊбЕСЗЕФШЈжЕВЮЪ§ЕФИіЪ§СЫЁЃШчЯТЭМгвЃКМйШчОжВПИаЪмвАЪЧ10x10ЃЌвўВуУПИіИаЪмвАжЛашвЊКЭет10x10ЕФОжВПЭМЯёЯрСЌНгЃЌЫљвд1АйЭђИівўВуЩёОдЊОЭжЛгавЛвкИіСЌНгЃЌМД10^8ИіВЮЪ§ЁЃБШдРДМѕЩйСЫЫФИі0ЃЈЪ§СПМЖЃЉЃЌетбљбЕСЗЦ№РДОЭУЛФЧУДЗбСІСЫЃЌЕЋЛЙЪЧИаОѕКмЖрЕФАЁЃЌФЧЛЙгаЩЖАьЗЈУЛЃП 
ЮвУЧжЊЕРЃЌвўКЌВуЕФУПвЛИіЩёОдЊЖМСЌНг10x10ИіЭМЯёЧјгђЃЌвВОЭЪЧЫЕУПвЛИіЩёОдЊДцдк10x10=100ИіСЌНгШЈжЕВЮЪ§ЁЃФЧШчЙћЮвУЧУПИіЩёОдЊет100ИіВЮЪ§ЪЧЯрЭЌЕФФиЃПвВОЭЪЧЫЕУПИіЩёОдЊгУЕФЪЧЭЌвЛИіОэЛ§КЫШЅОэЛ§ЭМЯёЁЃетбљЮвУЧОЭжЛгаЖрЩйИіВЮЪ§ЃПЃПжЛга100ИіВЮЪ§АЁЃЁЃЁЃЁЧзЃЁВЛЙмФувўВуЕФЩёОдЊИіЪ§гаЖрЩйЃЌСНВуМфЕФСЌНгЮвжЛга100ИіВЮЪ§АЁЃЁЧзЃЁетОЭЪЧШЈжЕЙВЯэАЁЃЁЧзЃЁетОЭЪЧОэЛ§ЩёОЭјТчЕФжїДђТєЕуАЁЃЁЧзЃЁЃЈгаЕуЗГСЫЃЌКЧКЧЃЉвВаэФуЛсЮЪЃЌетбљзіППЦзТ№ЃПЮЊЪВУДПЩааФиЃПетИіЁЁЙВЭЌбЇЯАЁЃ
КУСЫЃЌФуОЭЛсЯыЃЌетбљЬсШЁЬиеївВпЏВЛППЦзАЩЃЌетбљФужЛЬсШЁСЫвЛжжЬиеїАЁЃПЖдСЫЃЌецДЯУїЃЌЮвУЧашвЊЬсШЁЖржжЬиеїЖдВЛЃПМйШчвЛжжТЫВЈЦїЃЌвВОЭЪЧвЛжжОэЛ§КЫОЭЪЧЬсГіЭМЯёЕФвЛжжЬиеїЃЌР§ШчФГИіЗНЯђЕФБпдЕЁЃФЧУДЮвУЧашвЊЬсШЁВЛЭЌЕФЬиеїЃЌдѕУДАьЃЌМгЖрМИжжТЫВЈЦїВЛОЭааСЫТ№ЃПЖдСЫЁЃЫљвдМйЩшЮвУЧМгЕН100жжТЫВЈЦїЃЌУПжжТЫВЈЦїЕФВЮЪ§ВЛвЛбљЃЌБэЪОЫќЬсГіЪфШыЭМЯёЕФВЛЭЌЬиеїЃЌР§ШчВЛЭЌЕФБпдЕЁЃетбљУПжжТЫВЈЦїШЅОэЛ§ЭМЯёОЭЕУЕНЖдЭМЯёЕФВЛЭЌЬиеїЕФЗХгГЃЌЮвУЧГЦжЎЮЊFeature
MapЁЃЫљвд100жжОэЛ§КЫОЭга100ИіFeature MapЁЃет100ИіFeature MapОЭзщГЩСЫвЛВуЩёОдЊЁЃЕНетИіЪБКђУїСЫСЫАЩЁЃЮвУЧетвЛВугаЖрЩйИіВЮЪ§СЫЃП100жжОэЛ§КЫxУПжжОэЛ§КЫЙВЯэ100ИіВЮЪ§=100x100=10KЃЌвВОЭЪЧ1ЭђИіВЮЪ§ЁЃВХ1ЭђИіВЮЪ§АЁЃЁЧзЃЁЃЈгжРДСЫЃЌЪмВЛСЫСЫЃЁЃЉМћЯТЭМгвЃКВЛЭЌЕФбеЩЋБэДяВЛЭЌЕФТЫВЈЦїЁЃ 
КйгДЃЌвХТЉвЛИіЮЪЬтСЫЁЃИеВХЫЕвўВуЕФВЮЪ§ИіЪ§КЭвўВуЕФЩёОдЊИіЪ§ЮоЙиЃЌжЛКЭТЫВЈЦїЕФДѓаЁКЭТЫВЈЦїжжРрЕФЖрЩйгаЙиЁЃФЧУДвўВуЕФЩёОдЊИіЪ§дѕУДШЗЖЈФиЃПЫќКЭдЭМЯёЃЌвВОЭЪЧЪфШыЕФДѓаЁЃЈЩёОдЊИіЪ§ЃЉЁЂТЫВЈЦїЕФДѓаЁКЭТЫВЈЦїдкЭМЯёжаЕФЛЌЖЏВНГЄЖМгаЙиЃЁР§ШчЃЌЮвЕФЭМЯёЪЧ1000x1000ЯёЫиЃЌЖјТЫВЈЦїДѓаЁЪЧ10x10ЃЌМйЩшТЫВЈЦїУЛгажиЕўЃЌвВОЭЪЧВНГЄЮЊ10ЃЌетбљвўВуЕФЩёОдЊИіЪ§ОЭЪЧ(1000x1000
)/ (10x10)=100x100ИіЩёОдЊСЫЃЌМйЩшВНГЄЪЧ8ЃЌвВОЭЪЧОэЛ§КЫЛсжиЕўСНИіЯёЫиЃЌФЧУДЁЁЮвОЭВЛЫуСЫЃЌЫМЯыЖЎСЫОЭКУЁЃзЂвтСЫЃЌетжЛЪЧвЛжжТЫВЈЦїЃЌвВОЭЪЧвЛИіFeature
MapЕФЩёОдЊИіЪ§ХЖЃЌШчЙћ100ИіFeature MapОЭЪЧ100БЖСЫЁЃгЩДЫПЩМћЃЌЭМЯёдНДѓЃЌЩёОдЊИіЪ§КЭашвЊбЕСЗЕФШЈжЕВЮЪ§ИіЪ§ЕФЦЖИЛВюОрОЭдНДѓЁЃ 
ашвЊзЂвтЕФвЛЕуЪЧЃЌЩЯУцЕФЬжТлЖМУЛгаПМТЧУПИіЩёОдЊЕФЦЋжУВПЗжЁЃЫљвдШЈжЕИіЪ§ашвЊМг1 ЁЃетИівВЪЧЭЌвЛжжТЫВЈЦїЙВЯэЕФЁЃ
змжЎЃЌОэЛ§ЭјТчЕФКЫаФЫМЯыЪЧНЋЃКОжВПИаЪмвАЁЂШЈжЕЙВЯэЃЈЛђепШЈжЕИДжЦЃЉвдМАЪБМфЛђПеМфбЧВЩбљетШ§жжНсЙЙЫМЯыНсКЯЦ№РДЛёЕУСЫФГжжГЬЖШЕФЮЛвЦЁЂГпЖШЁЂаЮБфВЛБфадЁЃ
4ЃЉвЛИіЕфаЭЕФР§згЫЕУї
вЛжжЕфаЭЕФгУРДЪЖБ№Ъ§зжЕФОэЛ§ЭјТчЪЧLeNet-5ЃЈаЇЙћКЭpaperЕШМћетЃЉЁЃЕБФъУРЙњДѓЖрЪ§вјааОЭЪЧгУЫќРДЪЖБ№жЇЦБЩЯУцЕФЪжаДЪ§зжЕФЁЃФмЙЛДяЕНетжжЩЬгУЕФЕиВНЃЌЫќЕФзМШЗадПЩЯыЖјжЊЁЃБЯОЙФПЧАбЇЪѕНчКЭЙЄвЕНчЕФНсКЯЪЧзюЪмељвщЕФЁЃ


LeNet-5ЙВга7ВуЃЌВЛАќКЌЪфШыЃЌУПВуЖМАќКЌПЩбЕСЗВЮЪ§ЃЈСЌНгШЈжиЃЉЁЃЪфШыЭМЯёЮЊ32*32ДѓаЁЁЃетвЊБШMnistЪ§ОнПтЃЈвЛИіЙЋШЯЕФЪжаДЪ§ОнПтЃЉжазюДѓЕФзжФИЛЙДѓЁЃетбљзіЕФдвђЪЧЯЃЭћЧБдкЕФУїЯдЬиеїШчБЪЛЖЯЕчЛђНЧЕуФмЙЛГіЯждкзюИпВуЬиеїМрВтзгИаЪмвАЕФжааФЁЃ
ЮвУЧЯШвЊУїШЗвЛЕуЃКУПИіВугаЖрИіFeature MapЃЌУПИіFeature MapЭЈЙ§вЛжжОэЛ§ТЫВЈЦїЬсШЁЪфШыЕФвЛжжЬиеїЃЌШЛКѓУПИіFeature
MapгаЖрИіЩёОдЊЁЃ
C1ВуЪЧвЛИіОэЛ§ВуЃЈЮЊЪВУДЪЧОэЛ§ЃПОэЛ§дЫЫувЛИіживЊЕФЬиЕуОЭЪЧЃЌЭЈЙ§ОэЛ§дЫЫуЃЌПЩвдЪЙдаХКХЬиеїдіЧПЃЌВЂЧвНЕЕЭдывєЃЉЃЌгЩ6ИіЬиеїЭМFeature
MapЙЙГЩЁЃЬиеїЭМжаУПИіЩёОдЊгыЪфШыжа5*5ЕФСкгђЯрСЌЁЃЬиеїЭМЕФДѓаЁЮЊ28*28ЃЌетбљФмЗРжЙЪфШыЕФСЌНгЕєЕНБпНчжЎЭтЃЈЪЧЮЊСЫBPЗДРЁЪБЕФМЦЫуЃЌВЛжТЬнЖШЫ№ЪЇЃЌИіШЫМћНтЃЉЁЃC1га156ИіПЩбЕСЗВЮЪ§ЃЈУПИіТЫВЈЦї5*5=25ИіunitВЮЪ§КЭвЛИіbiasВЮЪ§ЃЌвЛЙВ6ИіТЫВЈЦїЃЌЙВ(5*5+1)*6=156ИіВЮЪ§ЃЉЃЌЙВ156*(28*28)=122,304ИіСЌНгЁЃ
S2ВуЪЧвЛИіЯТВЩбљВуЃЈЮЊЪВУДЪЧЯТВЩбљЃПРћгУЭМЯёОжВПЯрЙиадЕФдРэЃЌЖдЭМЯёНјаазгГщбљЃЌПЩвдМѕЩйЪ§ОнДІРэСПЭЌЪББЃСєгагУаХЯЂЃЉЃЌга6Иі14*14ЕФЬиеїЭМЁЃЬиеїЭМжаЕФУПИіЕЅдЊгыC1жаЯрЖдгІЬиеїЭМЕФ2*2СкгђЯрСЌНгЁЃS2ВуУПИіЕЅдЊЕФ4ИіЪфШыЯрМгЃЌГЫвдвЛИіПЩбЕСЗВЮЪ§ЃЌдйМгЩЯвЛИіПЩбЕСЗЦЋжУЁЃНсЙћЭЈЙ§sigmoidКЏЪ§МЦЫуЁЃПЩбЕСЗЯЕЪ§КЭЦЋжУПижЦзХsigmoidКЏЪ§ЕФЗЧЯпадГЬЖШЁЃШчЙћЯЕЪ§БШНЯаЁЃЌФЧУДдЫЫуНќЫЦгкЯпаддЫЫуЃЌбЧВЩбљЯрЕБгкФЃК§ЭМЯёЁЃШчЙћЯЕЪ§БШНЯДѓЃЌИљОнЦЋжУЕФДѓаЁбЧВЩбљПЩвдБЛПДГЩЪЧгадыЩљЕФЁАЛђЁБдЫЫуЛђепгадыЩљЕФЁАгыЁБдЫЫуЁЃУПИіЕЅдЊЕФ2*2ИаЪмвАВЂВЛжиЕўЃЌвђДЫS2жаУПИіЬиеїЭМЕФДѓаЁЪЧC1жаЬиеїЭМДѓаЁЕФ1/4ЃЈааКЭСаИї1/2ЃЉЁЃS2Вуга12ИіПЩбЕСЗВЮЪ§КЭ5880ИіСЌНгЁЃ 
ЭМЃКОэЛ§КЭзгВЩбљЙ§ГЬЃКОэЛ§Й§ГЬАќРЈЃКгУвЛИіПЩбЕСЗЕФТЫВЈЦїfxШЅОэЛ§вЛИіЪфШыЕФЭМЯёЃЈЕквЛНзЖЮЪЧЪфШыЕФЭМЯёЃЌКѓУцЕФНзЖЮОЭЪЧОэЛ§ЬиеїmapСЫЃЉЃЌШЛКѓМгвЛИіЦЋжУbxЃЌЕУЕНОэЛ§ВуCxЁЃзгВЩбљЙ§ГЬАќРЈЃКУПСкгђЫФИіЯёЫиЧѓКЭБфЮЊвЛИіЯёЫиЃЌШЛКѓЭЈЙ§БъСПWx+1МгШЈЃЌдйдіМгЦЋжУbx+1ЃЌШЛКѓЭЈЙ§вЛИіsigmoidМЄЛюКЏЪ§ЃЌВњЩњвЛИіДѓИХЫѕаЁЫФБЖЕФЬиеїгГЩфЭМSx+1ЁЃ
ЫљвдДгвЛИіЦНУцЕНЯТвЛИіЦНУцЕФгГЩфПЩвдПДзїЪЧзїОэЛ§дЫЫуЃЌS-ВуПЩПДзїЪЧФЃК§ТЫВЈЦїЃЌЦ№ЕНЖўДЮЬиеїЬсШЁЕФзїгУЁЃвўВугывўВужЎМфПеМфЗжБцТЪЕнМѕЃЌЖјУПВуЫљКЌЕФЦНУцЪ§ЕндіЃЌетбљПЩгУгкМьВтИќЖрЕФЬиеїаХЯЂЁЃ
C3ВувВЪЧвЛИіОэЛ§ВуЃЌЫќЭЌбљЭЈЙ§5x5ЕФОэЛ§КЫШЅОэЛ§ВуS2ЃЌШЛКѓЕУЕНЕФЬиеїmapОЭжЛга10x10ИіЩёОдЊЃЌЕЋЪЧЫќга16жжВЛЭЌЕФОэЛ§КЫЃЌЫљвдОЭДцдк16ИіЬиеїmapСЫЁЃетРяашвЊзЂвтЕФвЛЕуЪЧЃКC3жаЕФУПИіЬиеїmapЪЧСЌНгЕНS2жаЕФЫљга6ИіЛђепМИИіЬиеїmapЕФЃЌБэЪОБОВуЕФЬиеїmapЪЧЩЯвЛВуЬсШЁЕНЕФЬиеїmapЕФВЛЭЌзщКЯЃЈетИізіЗЈвВВЂВЛЪЧЮЈвЛЕФЃЉЁЃЃЈПДЕНУЛгаЃЌетРяЪЧзщКЯЃЌОЭЯёжЎЧАСФЕНЕФШЫЕФЪгОѕЯЕЭГвЛбљЃЌЕзВуЕФНсЙЙЙЙГЩЩЯВуИќГщЯѓЕФНсЙЙЃЌР§ШчБпдЕЙЙГЩаЮзДЛђепФПБъЕФВПЗжЃЉЁЃ
ИеВХЫЕC3жаУПИіЬиеїЭМгЩS2жаЫљга6ИіЛђепМИИіЬиеїmapзщКЯЖјГЩЁЃЮЊЪВУДВЛАбS2жаЕФУПИіЬиеїЭМСЌНгЕНУПИіC3ЕФЬиеїЭМФиЃПдвђга2ЕуЁЃЕквЛЃЌВЛЭъШЋЕФСЌНгЛњжЦНЋСЌНгЕФЪ§СПБЃГждкКЯРэЕФЗЖЮЇФкЁЃЕкЖўЃЌвВЪЧзюживЊЕФЃЌЦфЦЦЛЕСЫЭјТчЕФЖдГЦадЁЃгЩгкВЛЭЌЕФЬиеїЭМгаВЛЭЌЕФЪфШыЃЌЫљвдЦШЪЙЫћУЧГщШЁВЛЭЌЕФЬиеїЃЈЯЃЭћЪЧЛЅВЙЕФЃЉЁЃ
Р§ШчЃЌДцдкЕФвЛИіЗНЪНЪЧЃКC3ЕФЧА6ИіЬиеїЭМвдS2жа3ИіЯрСкЕФЬиеїЭМзгМЏЮЊЪфШыЁЃНгЯТРД6ИіЬиеїЭМвдS2жа4ИіЯрСкЬиеїЭМзгМЏЮЊЪфШыЁЃШЛКѓЕФ3ИівдВЛЯрСкЕФ4ИіЬиеїЭМзгМЏЮЊЪфШыЁЃзюКѓвЛИіНЋS2жаЫљгаЬиеїЭМЮЊЪфШыЁЃетбљC3Вуга1516ИіПЩбЕСЗВЮЪ§КЭ151600ИіСЌНгЁЃ
S4ВуЪЧвЛИіЯТВЩбљВуЃЌгЩ16Иі5*5ДѓаЁЕФЬиеїЭМЙЙГЩЁЃЬиеїЭМжаЕФУПИіЕЅдЊгыC3жаЯргІЬиеїЭМЕФ2*2СкгђЯрСЌНгЃЌИњC1КЭS2жЎМфЕФСЌНгвЛбљЁЃS4Вуга32ИіПЩбЕСЗВЮЪ§ЃЈУПИіЬиеїЭМ1ИівђзгКЭвЛИіЦЋжУЃЉКЭ2000ИіСЌНгЁЃ
C5ВуЪЧвЛИіОэЛ§ВуЃЌга120ИіЬиеїЭМЁЃУПИіЕЅдЊгыS4ВуЕФШЋВП16ИіЕЅдЊЕФ5*5СкгђЯрСЌЁЃгЩгкS4ВуЬиеїЭМЕФДѓаЁвВЮЊ5*5ЃЈЭЌТЫВЈЦївЛбљЃЉЃЌЙЪC5ЬиеїЭМЕФДѓаЁЮЊ1*1ЃКетЙЙГЩСЫS4КЭC5жЎМфЕФШЋСЌНгЁЃжЎЫљвдШдНЋC5БъЪОЮЊОэЛ§ВуЖјЗЧШЋЯрСЊВуЃЌЪЧвђЮЊШчЙћLeNet-5ЕФЪфШыБфДѓЃЌЖјЦфЫћЕФБЃГжВЛБфЃЌФЧУДДЫЪБЬиеїЭМЕФЮЌЪ§ОЭЛсБШ1*1ДѓЁЃC5Вуга48120ИіПЩбЕСЗСЌНгЁЃ
F6Вуга84ИіЕЅдЊЃЈжЎЫљвдбЁетИіЪ§зжЕФдвђРДздгкЪфГіВуЕФЩшМЦЃЉЃЌгыC5ВуШЋЯрСЌЁЃга10164ИіПЩбЕСЗВЮЪ§ЁЃШчЭЌОЕфЩёОЭјТчЃЌF6ВуМЦЫуЪфШыЯђСПКЭШЈжиЯђСПжЎМфЕФЕуЛ§ЃЌдйМгЩЯвЛИіЦЋжУЁЃШЛКѓНЋЦфДЋЕнИјsigmoidКЏЪ§ВњЩњЕЅдЊiЕФвЛИізДЬЌЁЃ
зюКѓЃЌЪфГіВугЩХЗЪНОЖЯђЛљКЏЪ§ЃЈEuclidean Radial Basis FunctionЃЉЕЅдЊзщГЩЃЌУПРрвЛИіЕЅдЊЃЌУПИіга84ИіЪфШыЁЃЛЛОфЛАЫЕЃЌУПИіЪфГіRBFЕЅдЊМЦЫуЪфШыЯђСПКЭВЮЪ§ЯђСПжЎМфЕФХЗЪНОрРыЁЃЪфШыРыВЮЪ§ЯђСПдНдЖЃЌRBFЪфГіЕФдНДѓЁЃвЛИіRBFЪфГіПЩвдБЛРэНтЮЊКтСПЪфШыФЃЪНКЭгыRBFЯрЙиСЊРрЕФвЛИіФЃаЭЕФЦЅХфГЬЖШЕФГЭЗЃЯюЁЃгУИХТЪЪѕгяРДЫЕЃЌRBFЪфГіПЩвдБЛРэНтЮЊF6ВуХфжУПеМфЕФИпЫЙЗжВМЕФИКlog-likelihoodЁЃИјЖЈвЛИіЪфШыФЃЪНЃЌЫ№ЪЇКЏЪ§гІФмЪЙЕУF6ЕФХфжУгыRBFВЮЪ§ЯђСПЃЈМДФЃЪНЕФЦкЭћЗжРрЃЉзуЙЛНгНќЁЃетаЉЕЅдЊЕФВЮЪ§ЪЧШЫЙЄбЁШЁВЂБЃГжЙЬЖЈЕФЃЈжСЩйГѕЪМЪБКђШчДЫЃЉЁЃетаЉВЮЪ§ЯђСПЕФГЩЗжБЛЩшЮЊ-1Лђ1ЁЃЫфШЛетаЉВЮЪ§ПЩвдвд-1КЭ1ЕШИХТЪЕФЗНЪНШЮбЁЃЌЛђепЙЙГЩвЛИіОРДэТыЃЌЕЋЪЧБЛЩшМЦГЩвЛИіЯргІзжЗћРрЕФ7*12ДѓаЁЃЈМД84ЃЉЕФИёЪНЛЏЭМЦЌЁЃетжжБэЪОЖдЪЖБ№ЕЅЖРЕФЪ§зжВЛЪЧКмгагУЃЌЕЋЪЧЖдЪЖБ№ПЩДђгЁASCIIМЏжаЕФзжЗћДЎКмгагУЁЃ
ЪЙгУетжжЗжВМБрТыЖјЗЧИќГЃгУЕФЁА1 of NЁББрТыгУгкВњЩњЪфГіЕФСэвЛИідвђЪЧЃЌЕБРрБ№БШНЯДѓЕФЪБКђЃЌЗЧЗжВМБрТыЕФаЇЙћБШНЯВюЁЃдвђЪЧДѓЖрЪ§ЪБМфЗЧЗжВМБрТыЕФЪфГіБиаыЮЊ0ЁЃетЪЙЕУгУsigmoidЕЅдЊКмФбЪЕЯжЁЃСэвЛИідвђЪЧЗжРрЦїВЛНігУгкЪЖБ№зжФИЃЌвВгУгкОмОјЗЧзжФИЁЃЪЙгУЗжВМБрТыЕФRBFИќЪЪКЯИУФПБъЁЃвђЮЊгыsigmoidВЛЭЌЃЌЫћУЧдкЪфШыПеМфЕФНЯКУЯожЦЕФЧјгђФкаЫЗмЃЌЖјЗЧЕфаЭФЃЪНИќШнвзТфЕНЭтБпЁЃ
RBFВЮЪ§ЯђСПЦ№зХF6ВуФПБъЯђСПЕФНЧЩЋЁЃашвЊжИГіетаЉЯђСПЕФГЩЗжЪЧ+1Лђ-1ЃЌете§КУдкF6 sigmoidЕФЗЖЮЇФкЃЌвђДЫПЩвдЗРжЙsigmoidКЏЪ§БЅКЭЁЃЪЕМЪЩЯЃЌ+1КЭ-1ЪЧsigmoidКЏЪ§ЕФзюДѓЭфЧњЕФЕуДІЁЃетЪЙЕУF6ЕЅдЊдЫаадкзюДѓЗЧЯпадЗЖЮЇФкЁЃБиаыБмУтsigmoidКЏЪ§ЕФБЅКЭЃЌвђЮЊетНЋЛсЕМжТЫ№ЪЇКЏЪ§НЯТ§ЕФЪеСВКЭВЁЬЌЮЪЬтЁЃ
5ЃЉбЕСЗЙ§ГЬ
ЩёОЭјТчгУгкФЃЪНЪЖБ№ЕФжїСїЪЧгажИЕМбЇЯАЭјТчЃЌЮожИЕМбЇЯАЭјТчИќЖрЕФЪЧгУгкОлРрЗжЮіЁЃЖдгкгажИЕМЕФФЃЪНЪЖБ№ЃЌгЩгкШЮвЛбљБОЕФРрБ№ЪЧвбжЊЕФЃЌбљБОдкПеМфЕФЗжВМВЛдйЪЧвРОнЦфздШЛЗжВМЧуЯђРДЛЎЗжЃЌЖјЪЧвЊИљОнЭЌРрбљБОдкПеМфЕФЗжВММАВЛЭЌРрбљБОжЎМфЕФЗжРыГЬЖШеввЛжжЪЪЕБЕФПеМфЛЎЗжЗНЗЈЃЌЛђепевЕНвЛИіЗжРрБпНчЃЌЪЙЕУВЛЭЌРрбљБОЗжБ№ЮЛгкВЛЭЌЕФЧјгђФкЁЃетОЭашвЊвЛИіГЄЪБМфЧвИДдгЕФбЇЯАЙ§ГЬЃЌВЛЖЯЕїећгУвдЛЎЗжбљБОПеМфЕФЗжРрБпНчЕФЮЛжУЃЌЪЙОЁПЩФмЩйЕФбљБОБЛЛЎЗжЕНЗЧЭЌРрЧјгђжаЁЃ
ОэЛ§ЭјТчдкБОжЪЩЯЪЧвЛжжЪфШыЕНЪфГіЕФгГЩфЃЌЫќФмЙЛбЇЯАДѓСПЕФЪфШыгыЪфГіжЎМфЕФгГЩфЙиЯЕЃЌЖјВЛашвЊШЮКЮЪфШыКЭЪфГіжЎМфЕФОЋШЗЕФЪ§бЇБэДяЪНЃЌжЛвЊгУвбжЊЕФФЃЪНЖдОэЛ§ЭјТчМгвдбЕСЗЃЌЭјТчОЭОпгаЪфШыЪфГіЖджЎМфЕФгГЩфФмСІЁЃОэЛ§ЭјТчжДааЕФЪЧгаЕМЪІбЕСЗЃЌЫљвдЦфбљБОМЏЪЧгЩаЮШчЃКЃЈЪфШыЯђСПЃЌРэЯыЪфГіЯђСПЃЉЕФЯђСПЖдЙЙГЩЕФЁЃЫљгаетаЉЯђСПЖдЃЌЖМгІИУЪЧРДдДгкЭјТчМДНЋФЃФтЕФЯЕЭГЕФЪЕМЪЁАдЫааЁБНсЙћЁЃЫќУЧПЩвдЪЧДгЪЕМЪдЫааЯЕЭГжаВЩМЏРДЕФЁЃдкПЊЪМбЕСЗЧАЃЌЫљгаЕФШЈЖМгІИУгУвЛаЉВЛЭЌЕФаЁЫцЛњЪ§НјааГѕЪМЛЏЁЃЁАаЁЫцЛњЪ§ЁБгУРДБЃжЄЭјТчВЛЛсвђШЈжЕЙ§ДѓЖјНјШыБЅКЭзДЬЌЃЌДгЖјЕМжТбЕСЗЪЇАмЃЛЁАВЛЭЌЁБгУРДБЃжЄЭјТчПЩвде§ГЃЕибЇЯАЁЃЪЕМЪЩЯЃЌШчЙћгУЯрЭЌЕФЪ§ШЅГѕЪМЛЏШЈОиеѓЃЌдђЭјТчЮоФмСІбЇЯАЁЃ
бЕСЗЫуЗЈгыДЋЭГЕФBPЫуЗЈВюВЛЖрЁЃжївЊАќРЈ4ВНЃЌет4ВНБЛЗжЮЊСНИіНзЖЮЃК

6ЃЉОэЛ§ЩёОЭјТчЕФгХЕу
ОэЛ§ЩёОЭјТчCNNжївЊгУРДЪЖБ№ЮЛвЦЁЂЫѕЗХМАЦфЫћаЮЪНХЄЧњВЛБфадЕФЖўЮЌЭМаЮЁЃгЩгкCNNЕФЬиеїМьВтВуЭЈЙ§бЕСЗЪ§ОнНјаабЇЯАЃЌЫљвддкЪЙгУCNNЪБЃЌБмУтСЫЯдЪНЕФЬиеїГщШЁЃЌЖјвўЪНЕиДгбЕСЗЪ§ОнжаНјаабЇЯАЃЛдйепгЩгкЭЌвЛЬиеїгГЩфУцЩЯЕФЩёОдЊШЈжЕЯрЭЌЃЌЫљвдЭјТчПЩвдВЂаабЇЯАЃЌетвВЪЧОэЛ§ЭјТчЯрЖдгкЩёОдЊБЫДЫЯрСЌЭјТчЕФвЛДѓгХЪЦЁЃОэЛ§ЩёОЭјТчвдЦфОжВПШЈжЕЙВЯэЕФЬиЪтНсЙЙдкгявєЪЖБ№КЭЭМЯёДІРэЗНУцгазХЖРЬиЕФгХдНадЃЌЦфВМОжИќНгНќгкЪЕМЪЕФЩњЮяЩёОЭјТчЃЌШЈжЕЙВЯэНЕЕЭСЫЭјТчЕФИДдгадЃЌЬиБ№ЪЧЖрЮЌЪфШыЯђСПЕФЭМЯёПЩвджБНгЪфШыЭјТчетвЛЬиЕуБмУтСЫЬиеїЬсШЁКЭЗжРрЙ§ГЬжаЪ§ОнжиНЈЕФИДдгЖШЁЃ
СїЕФЗжРрЗНЪНМИКѕЖМЪЧЛљгкЭГМЦЬиеїЕФЃЌетОЭвтЮЖзХдкНјааЗжБцЧАБиаыЬсШЁФГаЉЬиеїЁЃШЛЖјЃЌЯдЪНЕФЬиеїЬсШЁВЂВЛШнвзЃЌдквЛаЉгІгУЮЪЬтжавВВЂЗЧзмЪЧПЩППЕФЁЃОэЛ§ЩёОЭјТчЃЌЫќБмУтСЫЯдЪНЕФЬиеїШЁбљЃЌвўЪНЕиДгбЕСЗЪ§ОнжаНјаабЇЯАЁЃетЪЙЕУОэЛ§ЩёОЭјТчУїЯдгаБ№гкЦфЫћЛљгкЩёОЭјТчЕФЗжРрЦїЃЌЭЈЙ§НсЙЙжизщКЭМѕЩйШЈжЕНЋЬиеїЬсШЁЙІФмШкКЯНјЖрВуИажЊЦїЁЃЫќПЩвджБНгДІРэЛвЖШЭМЦЌЃЌФмЙЛжБНггУгкДІРэЛљгкЭМЯёЕФЗжРрЁЃ
ОэЛ§ЭјТчНЯвЛАуЩёОЭјТчдкЭМЯёДІРэЗНУцгаШчЯТгХЕуЃК aЃЉЪфШыЭМЯёКЭЭјТчЕФЭиЦЫНсЙЙФмКмКУЕФЮЧКЯЃЛbЃЉЬиеїЬсШЁКЭФЃЪНЗжРрЭЌЪБНјааЃЌВЂЭЌЪБдкбЕСЗжаВњЩњЃЛcЃЉШЈжиЙВЯэПЩвдМѕЩйЭјТчЕФбЕСЗВЮЪ§ЃЌЪЙЩёОЭјТчНсЙЙБфЕУИќМђЕЅЃЌЪЪгІадИќЧПЁЃ
7ЃЉаЁНс
CNNsжаетжжВуМфСЊЯЕКЭПегђаХЯЂЕФНєУмЙиЯЕЃЌЪЙЦфЪЪгкЭМЯёДІРэКЭРэНтЁЃЖјЧвЃЌЦфдкздЖЏЬсШЁЭМЯёЕФЯджјЬиеїЗНУцЛЙБэЯжГіСЫБШНЯгХЕФадФмЁЃдквЛаЉР§згЕБжаЃЌGaborТЫВЈЦївбОБЛЪЙгУдквЛИіГѕЪМЛЏдЄДІРэЕФВНжшжаЃЌвдДяЕНФЃФтШЫРрЪгОѕЯЕЭГЖдЪгОѕДЬМЄЕФЯьгІЁЃдкФПЧАДѓВПЗжЕФЙЄзїжаЃЌбаОПепНЋCNNsгІгУЕНСЫЖржжЛњЦїбЇЯАЮЪЬтжаЃЌАќРЈШЫСГЪЖБ№ЃЌЮФЕЕЗжЮіКЭгябдМьВтЕШЁЃЮЊСЫДяЕНбАевЪгЦЕжажЁгыжЁжЎМфЕФЯрИЩадЕФФПЕФЃЌФПЧАCNNsЭЈЙ§вЛИіЪБМфЯрИЩадШЅбЕСЗЃЌЕЋетИіВЛЪЧCNNsЬигаЕФЁЃ
етВПЗжНВЕУЬЋЊрТСЫЃЌгжУЛНВЕНЕуЩЯЁЃУЛАьЗЈСЫЃЌЯШетбљЕФЃЌетбљетИіЙ§ГЬЮвЛЙУЛгазпЙ§ЃЌЫљвдздМКЫЎЦНгаЯоАЁЃЌЭћИїЮЛУїВьЁЃашвЊКѓУцдйИФСЫЃЌКЧКЧЁЃ
ЪЎЁЂзмНсгыеЙЭћ
1ЃЉDeep learningзмНс
ЩюЖШбЇЯАЪЧЙигкздЖЏбЇЯАвЊНЈФЃЕФЪ§ОнЕФЧБдкЃЈвўКЌЃЉЗжВМЕФЖрВуЃЈИДдгЃЉБэДяЕФЫуЗЈЁЃЛЛОфЛАРДЫЕЃЌЩюЖШбЇЯАЫуЗЈздЖЏЕФЬсШЁЗжРрашвЊЕФЕЭВуДЮЛђепИпВуДЮЬиеїЁЃИпВуДЮЬиеїЃЌвЛЪЧжИИУЬиеїПЩвдЗжМЖЃЈВуДЮЃЉЕивРРЕЦфЫћЬиеїЃЌР§ШчЃКЖдгкЛњЦїЪгОѕЃЌЩюЖШбЇЯАЫуЗЈДгдЪМЭМЯёШЅбЇЯАЕУЕНЫќЕФвЛИіЕЭВуДЮБэДяЃЌР§ШчБпдЕМьВтЦїЃЌаЁВЈТЫВЈЦїЕШЃЌШЛКѓдкетаЉЕЭВуДЮБэДяЕФЛљДЁЩЯдйНЈСЂБэДяЃЌР§ШчетаЉЕЭВуДЮБэДяЕФЯпадЛђепЗЧЯпадзщКЯЃЌШЛКѓжиИДетИіЙ§ГЬЃЌзюКѓЕУЕНвЛИіИпВуДЮЕФБэДяЁЃ
Deep learningФмЙЛЕУЕНИќКУЕиБэЪОЪ§ОнЕФfeatureЃЌЭЌЪБгЩгкФЃаЭЕФВуДЮЁЂВЮЪ§КмЖрЃЌcapacityзуЙЛЃЌвђДЫЃЌФЃаЭгаФмСІБэЪОДѓЙцФЃЪ§ОнЃЌЫљвдЖдгкЭМЯёЁЂгявєетжжЬиеїВЛУїЯдЃЈашвЊЪжЙЄЩшМЦЧвКмЖрУЛгажБЙлЮяРэКЌвхЃЉЕФЮЪЬтЃЌФмЙЛдкДѓЙцФЃбЕСЗЪ§ОнЩЯШЁЕУИќКУЕФаЇЙћЁЃДЫЭтЃЌДгФЃЪНЪЖБ№ЬиеїКЭЗжРрЦїЕФНЧЖШЃЌdeep
learningПђМмНЋfeatureКЭЗжРрЦїНсКЯЕНвЛИіПђМмжаЃЌгУЪ§ОнШЅбЇЯАfeatureЃЌдкЪЙгУжаМѕЩйСЫЪжЙЄЩшМЦfeatureЕФОоДѓЙЄзїСПЃЈетЪЧФПЧАЙЄвЕНчЙЄГЬЪІИЖГіХЌСІзюЖрЕФЗНУцЃЉЃЌвђДЫЃЌВЛНіНіаЇЙћПЩвдИќКУЃЌЖјЧвЃЌЪЙгУЦ№РДвВгаКмЖрЗНБужЎДІЃЌвђДЫЃЌЪЧЪЎЗжжЕЕУЙизЂЕФвЛЬзПђМмЃЌУПИізіMLЕФШЫЖМгІИУЙизЂСЫНтвЛЯТЁЃ
ЕБШЛЃЌdeep learningБОЩэвВВЛЪЧЭъУРЕФЃЌвВВЛЪЧНтОіЪРМфШЮКЮMLЮЪЬтЕФРћЦїЃЌВЛгІИУБЛЗХДѓЕНвЛИіЮоЫљВЛФмЕФГЬЖШЁЃ
2ЃЉDeep learningЮДРД
ЩюЖШбЇЯАФПЧАШдгаДѓСПЙЄзїашвЊбаОПЁЃФПЧАЕФЙизЂЕуЛЙЪЧДгЛњЦїбЇЯАЕФСьгђНшМјвЛаЉПЩвддкЩюЖШбЇЯАЪЙгУЕФЗНЗЈЃЌЬиБ№ЪЧНЕЮЌСьгђЁЃР§ШчЃКФПЧАвЛИіЙЄзїОЭЪЧЯЁЪшБрТыЃЌЭЈЙ§бЙЫѕИажЊРэТлЖдИпЮЌЪ§ОнНјааНЕЮЌЃЌЪЙЕУЗЧГЃЩйЕФдЊЫиЕФЯђСПОЭПЩвдОЋШЗЕФДњБэдРДЕФИпЮЌаХКХЁЃСэвЛИіР§згОЭЪЧАыМрЖНСїаабЇЯАЃЌЭЈЙ§ВтСПбЕСЗбљБОЕФЯрЫЦадЃЌНЋИпЮЌЪ§ОнЕФетжжЯрЫЦадЭЖгАЕНЕЭЮЌПеМфЁЃСэЭтвЛИіБШНЯЙФЮшШЫаФЕФЗНЯђОЭЪЧevolutionary
programming approachesЃЈвХДЋБрГЬЗНЗЈЃЉЃЌЫќПЩвдЭЈЙ§зюаЁЛЏЙЄГЬФмСПШЅНјааИХФюадздЪЪгІбЇЯАКЭИФБфКЫаФМмЙЙЁЃ
Deep learningЛЙгаКмЖрКЫаФЕФЮЪЬташвЊНтОіЃК
ЃЈ1ЃЉЖдгквЛИіЬиЖЈЕФПђМмЃЌЖдгкЖрЩйЮЌЕФЪфШыЫќПЩвдБэЯжЕУНЯгХЃЈШчЙћЪЧЭМЯёЃЌПЩФмЪЧЩЯАйЭђЮЌЃЉЃП
ЃЈ2ЃЉЖдВЖзНЖЬЪБЛђепГЄЪБМфЕФЪБМфвРРЕЃЌФФжжМмЙЙВХЪЧгааЇЕФЃП
ЃЈ3ЃЉШчКЮЖдгквЛИіИјЖЈЕФЩюЖШбЇЯАМмЙЙЃЌШкКЯЖржжИажЊЕФаХЯЂЃП
ЃЈ4ЃЉгаЪВУДе§ШЗЕФЛњРэПЩвдШЅдіЧПвЛИіИјЖЈЕФЩюЖШбЇЯАМмЙЙЃЌвдИФНјЦфТГАєадКЭЖдХЄЧњКЭЪ§ОнЖЊЪЇЕФВЛБфадЃП
ЃЈ5ЃЉФЃаЭЗНУцЪЧЗёгаЦфЫћИќЮЊгааЇЧвгаРэТлвРОнЕФЩюЖШФЃаЭбЇЯАЫуЗЈЃП
ЬНЫїаТЕФЬиеїЬсШЁФЃаЭЪЧжЕЕУЩюШыбаОПЕФФкШнЁЃДЫЭтгааЇЕФПЩВЂаабЕСЗЫуЗЈвВЪЧжЕЕУбаОПЕФвЛИіЗНЯђЁЃЕБЧАЛљгкзюаЁХњДІРэЕФЫцЛњЬнЖШгХЛЏЫуЗЈКмФбдкЖрМЦЫуЛњжаНјааВЂаабЕСЗЁЃЭЈГЃАьЗЈЪЧРћгУЭМаЮДІРэЕЅдЊМгЫйбЇЯАЙ§ГЬЁЃШЛЖјЕЅИіЛњЦїGPUЖдДѓЙцФЃЪ§ОнЪЖБ№ЛђЯрЫЦШЮЮёЪ§ОнМЏВЂВЛЪЪгУЁЃдкЩюЖШбЇЯАгІгУЭиеЙЗНУцЃЌШчКЮКЯРэГфЗжРћгУЩюЖШбЇЯАдкдіЧПДЋЭГбЇЯАЫуЗЈЕФадФмШдЪЧФПЧАИїСьгђЕФбаОПжиЕуЁЃ
|






