| БрМЭЦМі: |
БОЮФгкsohu,НщЩмСЫзїЮЊВњЦЗОРэашвЊСЫНтЫуЗЈЕФдРэвдМАЫќЕФБпНчКЭгХЪЦЃЌФмЙЛжЊЕРдкВЛЭЌГЁОАЯТгІгУЪВУДЫуЗЈЪВУДФЃаЭПЩвдДяЕНФПЕФЁЃ
|
|
вЛЁЂЛњЦїбЇЯАЕФЯжзДКЭЦПОБ
ЛњЦїбЇЯАШчНёвбЫуЪЧдкЛЅСЊЭјШІМвгїЛЇЯўЕФУћДЪСЫЁЃЯжЪЕЩњЛюжаЦфЪЕвВдчгаКмЖргІгУЃЌЪВУДЮоШЫМнЪЛЃЌШЫСГЪЖБ№ЃЌжЧФмвєЯьЕШЕШЁЃШЅФъЦпдТЙњМвЗЂВМСЫЁЖаТвЛДњШЫЙЄжЧФмЗЂеЙЙцЛЎЁЗЃЌЫЕУїШЫЙЄжЧФмСьгђвбОЩЯЩ§ЕНСЫЙњМвеНТдВуУцЁЃЩэБпвЛжБЯлФНЕФЭСКРХѓгбУЧЮхФъКѓЕФГЄЯпЙЩвВЖМвбОТђКУСЫЁЃЮхФъКѓЕФЪТЧщЮвВЛжЊЕРЃЌЕЋЪЧЖдЮвгЁЯѓзюЩюЕФОЭЪЧШЅФъЛЅСЊЭјДѓЛсЃЌдЯШШЫУЧПкжаЕФЛЅСЊЭјЯждкЖМИФУћНаДЋЭГЛЅСЊЭјСЫЁЃЕБЮвУЧЛЙдкРэНтЪВУДЪЧЛњЦїбЇЯАЕФЪБКђЃЌБ№ШЫвбОПЊЙЋЫОАяШЫжЦЖЈНтОіЗНАИСЫЁЃ
ЪЕМЪЩЯЕБЧАЛњЦїбЇЯАзїЮЊЙЄОпЩЬвЕЛЏНЯЮЊЙуЗКЕФЛЙЪЧдкBЖЫЃЌБШШчвЛаЉН№ШкЙЋЫОЛсЪфГіздМКЕФЗчПиФмСІЁЂЗДзїБзФмСІЁЃдквЛаЉИпОЋУмЙЄвЕСьгђЭЈЙ§AR+AIЕФММЪѕЃЌвбОПЩвдАяжњММЪѕШЫдБбИЫйВтСПГівЧЦїЕФжИБъЃЌВЂНЋЯрЙиЪ§ОнЛиДЋжСПижЦЯЕЭГжаЁЃДѓДѓЕЮМѕЩйСЫММЪѕШЫдБЪжЙЄВтСПЕФЙЄзїЃЌЭЌЪБвВМѕЩйСЫШЫЙЄВтСПЪ§ОнЕФЮѓВюЁЃИќЖрЕФгІгУГЁОАБШШчАВЗРСьгђЃЌЭЈЙ§ШЫСГЪЖБ№ММЪѕПЩвдПьЫйМЧТМГіШыШЫдБЃЌДгЖјАбЗЧНсЙЙЛЏЪ§ОнБфГЩНсЙЙЛЏЁЃ
ВЛЙ§ЛњЦїбЇЯАвВВЂВЛЪЧдкЫљгаСьгђЖМФмЗЂЛгГіОоДѓзїгУЃЌЦ№ТыЪЧдкЯждкетИіНзЖЮЁЃЛњЦїбЇЯАКмЖрЧщПіЪЧашвЊКмЖрБъзЂЪ§ОнРДЙЉЛњЦїНјаабЇЯАЃЌЭЈЙ§ЖдБъзЂЪ§ОнВЛЖЯЕФбЇЯАКЭгХЛЏДгЖјЪЙЦфНЈСЂвЛИіЗКЛЏЕФФЃаЭЃЌЕБаТЕФЪ§ОнЭЈЙ§етИіФЃаЭЪБЛњЦїБуЛсЖдЦфНјааЗжРрЛђепдЄВтЁЃ
БШШчЫЕШчЙћвЊХаЖЯвЛИіВЁШЫЪЧЗёЛМгабЊЙмАЉЃЌОЭашвЊгаДѓСПБЛБъзЂЕФбЊЙмВЁБфЪ§ОнЁЃЕЋетаЉБъзЂЪ§ОнЕФЙЄзїЪЧашвЊЗЧГЃгаСйДВОбщЕФвНЩњвЛИівЛИіЕФШЅХаЖЯКЭБъзЂЕФЁЃвЛЗНУцЪЧгаОбщЕФзЈМввНЩњКмЩйЃЌСэвЛЗНУцЖдгкетРрЪ§ОнБОЩэЪ§СПвВгаЯоЁЃСэЭтвНСЦаавЕЖдгкФЃаЭЕФзМШЗТЪвЊЧѓПЯЖЈВЛЛсбЧгкЮоШЫМнЪЛЁЃЫљвдВЛПЩЗёШЯЛњЦїбЇЯАЕФгІгУЕФШЗгаЫќЕФЧПДѓжЎДІЃЌЕЋдкВЛЭЌСьгђжаГфТњЕФЬєеНвВЗЧГЃЖрЁЃ
ЖўЁЂЩёОЭјТчЫуЗЈ
АДееЙпР§ЃЌМђЕЅНщЩмвЛЯТЩёОЭјТчЁЃ
1ЁЂЩёОдЊ
ШЫРрЖдЪТЮяЕФИажЊЪЧЭЈЙ§ЮоЪ§ИіЩёОдЊЭЈЙ§БЫДЫСДНгЖјаЮГЩЕФвЛИіОоДѓЩёОЭјТчЃЌШЛКѓУПВуЩёОдЊЛсНЋНгЪеЕНЕФаХКХОЙ§ДІРэКѓж№ВуДЋЕнИјДѓФдЃЌзюКѓдйгЩДѓФдзіГіЯТвЛВНОіВпЁЃЩёОЭјТчЫуЗЈЪЕМЪЩЯОЭЪЧдкФЃЗТетвЛЩњЮядРэЁЃ

2ЁЂМрЖНЮоМрЖН
ЩёОЭјТчЫуЗЈЪЧЪєгкгаМрЖНбЇЯАЕФвЛжжЁЃгаМрЖНбЇЯАЪЕМЪЩЯОЭЪЧашвЊгаДѓСПЕФБЛБъзЂЪ§ОнЙЉЦфбЇЯАЁЃЗДжЎЮоМрЖНОЭЪЧВЛашвЊЪТЯШЖдЪ§ОнНјааБъзЂЃЌЖјЪЧРћгУЫуЗЈЭкОђЪ§ОнжаЧБдкЕФЙцТЩЃЌБШШчвЛаЉОлРрЫуЗЈЁЃФЧУДАыМрЖНбЇЯАЃЌЯраХвВВЛФбРэНтЁЃ
3ЁЂШЈжиВЮЪ§
ЩёОЭјТчЫуЗЈжаЕФзюаЁЕЅдЊМДЮЊЩёОдЊЃЌвЛИіЩёОдЊПЩФмЛсНгЪмЕНnИіДЋЕнЙ§РДЕФЪ§ОнЁЃУПЬѕЪ§ОндкЪфШыЩёОдЊЪБЖМашвЊГЫвдвЛИіШЈжижЕwЃЌШЛКѓНЋnИіЪ§ОнЧѓКЭЃЌдкМгЩЯЦЋжУСПbЁЃетЪБЕУЕНЕФжЕгыИУЩёОдЊЕФуажЕНјааБШНЯЃЌзюКѓдкЭЈЙ§МЄЛюКЏЪ§ЪфГіДІРэНсЙћЁЃ
4ЁЂЯпадгыЗЧЯпад
ЪЕМЪЩЯЫуЗЈБОЩэзюКЫаФЕФЪЧвЛИіЯпадКЏЪ§y=wx+bЁЃwЮЊШЈжижЕЃЌbЮЊЦЋжУСПЃЌxЮЊЪфШыЪ§ОнЃЌyЮЊЪфГіЪ§ОнЁЃЕБЮвУЧдкДІРэФГаЉЪ§ОнЪБЃЌРэЯыЧщПіЪЧетаЉЪ§ОнЮЊЯпадПЩЗжЕФЁЃетбљжЛвЊЮвУЧевЕНетЬѕжБЯпЕФwКЭbОЭПЩвдзїЮЊФГИіФЃаЭРДЖдЪ§ОнНјааЗжРрЛђдЄВтСЫЁЃШчЯТЭМЃК
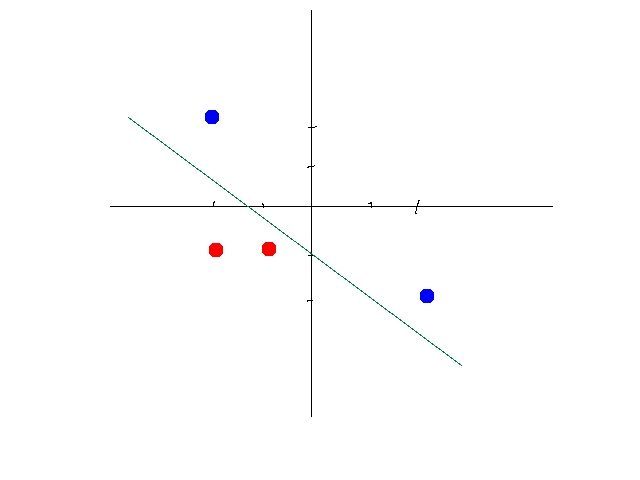
ЕЋЪТЪЕЩЯДѓВПЗжЕФЪ§ОнВЂВЛЪЧЯпадПЩЗжЕФЃЌЛђепЫЕвЛЬѕжБЯпЮоЗЈКмКУЕФБэДяетаЉЪ§ОнМЏЁЃетЪБКђдѕУДАьФиЃПетЪБКђвЛАуЧщПіЯТОЭЛсЭЈЙ§діМгЖрИіЩёОдЊвдМАМЄЛюКЏЪ§РДЪЙФЃаЭФтКЯЪ§ОнМЏЁЃ
5ЁЂМЄЛюКЏЪ§
ФЧУДЃЌЪВУДЪЧМЄЛюКЏЪ§ЃПЫЕАзСЫЃЌМЄЛюКЏЪ§ОЭЪЧвЛИіФмАбЯпадКЏЪ§ъўЭфЕФКЏЪ§ЁЃБШШчЯТУцЕФетзщЪ§ОнЮвУЧЪЧЮоЗЈЭЈЙ§вЛЬѕжБЯпНЋКьРЖСНжжЪ§ОнЗжИєПЊЁЃЕЋЪЧЭЈЙ§МЄЛюКЏЪ§ЃЌЮвУЧЩѕжСПЩвдНЋвЛЬѕжБЯпъўГЩвЛИідВЁЃетбљЮвУЧОЭПЩвдНЋСНзщЪ§ОнЗжИєПЊСЫЁЃ
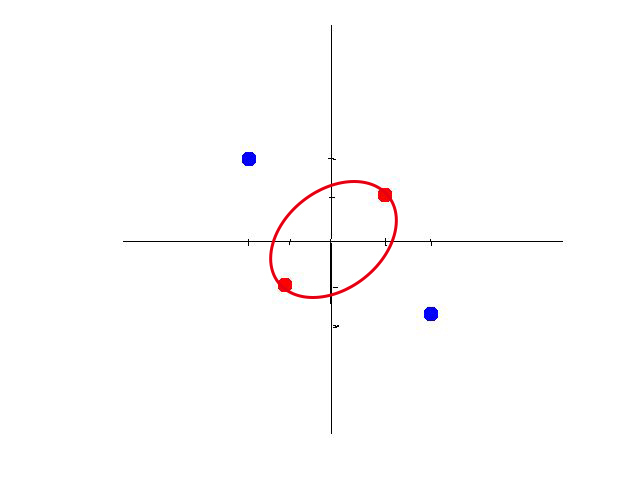
ЫљвдРэТлЩЯЃЌЮвУЧПЩвдНЋвЛЬѕжБЯпзіШЮвтЕФБфЛЏЪЙЦфИќМгЬљНќЪ§ОнМЏЃЌВЂбЁШЁвЛЬѕзюгХЧњЯпМДЮЊЮвУЧЦкЭћЕФзюжебЕСЗФЃаЭЁЃФЧУДЮвУЧЕФФПБъОЭКмУїШЗСЫЁЃ
6ЁЂгХЛЏЦї
ЕЋЪЧШчКЮВХФмевЕНетУДвЛЬѕЧњЯпЃПетЪБКђЮвУЧПЩвдв§ШывЛЯЕСаЕФгХЛЏЫуЗЈЃЌБШШчЬнЖШЯТНЕЁЃЭЈЙ§гХЛЏЫуЗЈЖдКЏЪ§ЧѓЕМЮвУЧПЩвдЪЙФЃаЭжаЕФВЮЪ§ж№НЅЬљНќецЪЕжЕЁЃЭЌЪБдкгХЛЏЙ§ГЬжаЛЙашвЊМгШыЫ№ЪЇКЏЪ§ЁЃ
7ЁЂЫ№ЪЇКЏЪ§
ЪВУДЪЧЫ№ЪЇКЏЪ§ЃПЫ№ЪЇКЏЪ§ЫЕАзСЫПЩвдРэНтГЩЮЊвЛИібщЪеепЁЃЫ№ЪЇКЏЪ§ЛсШЅКтСПВтЪдЪ§ОнжаЕФНсЙћгыЪЕМЪжЕЕФЦЋВюЧщПіЁЃШчЙћЦЋВюНЯДѓОЭвЊИцЫпгХЛЏКЏЪ§МЬајгХЛЏжБЕНФЃаЭЭъШЋЪеСВЁЃГЃгУЕФЫ№ЪЇКЏЪ§ШчЃКНЛВцьиЁЂЦНЗНВюЕШЁЃ
8ЁЂЙ§ФтКЯЧЗФтКЯ
ВЛЙ§ашвЊзЂвтЕФЪЧЃЌШчЙћЮвУЧЕФЧњЯпЭъУРЕФФтКЯСЫЫљгаЪ§ОнЃЌФЧУДетЬѕЧњЯпЪЧЗёМДЮЊЮвУЧФЃаЭЕФзюгХЧњЯпФиЃПД№АИЪЧЗёЖЈЕФЁЃетРяЮвУЧЛЙашвЊПМТЧвЛИіФЃаЭЗКЛЏЕФЮЪЬтЁЃШчЙћЮвУЧбЕСЗСЫвЛИіФЃаЭЃЌЕЋЪЧетИіФЃаЭНіФмдкбЕСЗЪ§ОнМЏжаЗЂЛгКмДѓаЇгУЃЌФЧУДЫќЪЕМЪЕФгІгУвтвхЦфЪЕВЂВЛДѓЁЃЮвУЧашвЊЕФЪЧЭЈЙ§етИіФЃаЭФмЙЛШУЮвУЧСЫНтЕНЮвУЧЮДжЊЕФаХЯЂЃЌЖјВЛЪЧвбжЊЕФЁЃЫљвдЮвУЧВЂВЛЯЃЭћетЬѕЧњЯпФмЙЛДЉЙ§ЫљгаЕФЪ§ОнЃЌЖјЪЧШУЫќОЁПЩФмЕФУшЛцГіетИіЪ§ОнМЏЁЃЮЊСЫЗРжЙФЃаЭЙ§ФтКЯПЩвдГЂЪддіМгбЕСЗЪ§ОнЭЌЪБМѕаЁФЃаЭИДдгЖШЁЃЭЌбљЮвУЧвВВЛПЩФмШУетЬѕЧњЯпЭъШЋЦЋРыЪ§ОнМЏЁЃ

Ш§ЁЂЩюЖШбЇЯАПђМм
здМКЭЦЕМЫуЗЈЃПздМКЩшМЦФЃаЭЃПВЛДцдкЕФЁДѓЩёУЧдчОЭАяФуЗтзАКУСЫЁЃАВаФзівЛИіЕїАќЯРАЩЁЃ
УЛгабЕСЗЪ§ОнЃПУЛгаВтЪдбљБОЃПВЛДцдкЕФЁДѓЩёУЧдчОЭАяФузМБИКУСЫЁЃАВаФзівЛИіЕїВЮЙЗАЩЁЃ
ЪВУДЃПЛЙЪЧВЛжЊЕРдѕУДзіЃПВЛДцдкЕФЃЁЯТУцШУФуУыБфЛњЦїбЇЯАДѓЩёЃЈзАБЦЙЗЃЉЁЃ
Keras
ЛњЦїбЇЯАЕФПђМметРяОЭВЛУЖОйСЫЃЌВЛЙ§KerasЛЙЪЧЗЧГЃжЕЕУЬсвЛЯТЁЃЯрБШTensorflowЃЌKerasИќШнвзаТЪжЩЯЪжЃЌЗтзАЕФИќМгИпМЖЁЃНЈвщдкГЂЪдЪЙгУПђМмЧАЯШСЫНтЛђбЇЯАвЛЯТpythonЃЌШЛКѓжБНгKerasжаЮФЮФЕЕАЩЁЃ
ФЧУДШчКЮУыБфДѓЩёЃПKerasПђМмжаЦфЪЕвбОФкжУСЫКмЖрдЄбЕСЗКУЕФФЃаЭЃЌШчResNet50ЭМЦЌЗжРрЦїЁЃФужЛашвЊНЋЯТЭМжаЕФДњТыИДжЦЕНФуЕФKerasПђМмжаВЂдЫааЁЃШЛКѓХнвЛБПЇЗШЃЌЯыЯѓздМКвбОГЩЮЊЮтЖїДявЛбљЕФДѓЩёЁЃОВОВЕФЕШД§зХЩюВиЙІгыУћЕФФЧвЛПЬЕФЕНРДЁЃ
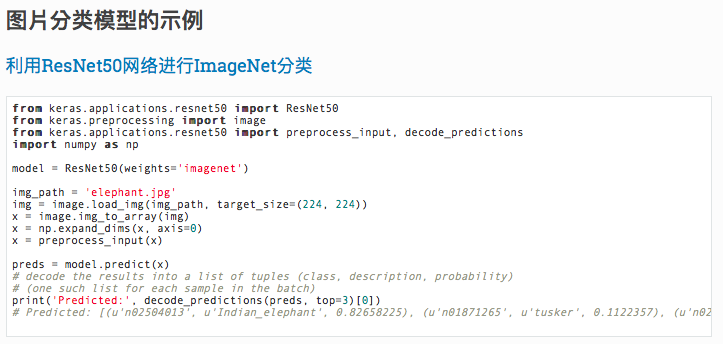
ДѓИХАыаЁЪБЕФЪБМфЃЌФЃаЭЯТдиАВзАЭъБЯЁЃМЄЖЏШЫаФЕФЪБПЬжегкРДСйЃЌИЯПьРДВтвЛЯТетИіФЃаЭЁЃДгАйЖШЩЯЫцБуЫбЫїСЫвЛеХУЈЕФЭМЦЌЃЌВЂНЋЭМЦЌЕФДѓаЁИФЮЊ224*224ЯёЫиЁЃШЛКѓНЋЭМЦЌЗХЕНЯюФПЕФИљФПТМжаЃЈВЛвЊЭќМЧаоИФДњТыжаЕФЭМЦЌУћГЦЃЉЃЌзюКѓдЫааГЬађЁЃФуЛсЗЂЯжФЃаЭВЛНіФмЪЖБ№ГіРДЪЧвЛжЛУЈЃЌВЂЧвЛЙжЊЕРЪЧвЛжЛВЈЫЙУЈЁЃОЊВЛОЊЯВЃПДЬВЛДЬМЄЃПЪЧВЛЪЧгаКмЖраЁЭМЦЌЯывЊГЂЪдЃПИЯПьЭцЦ№РДАЩЁЃ
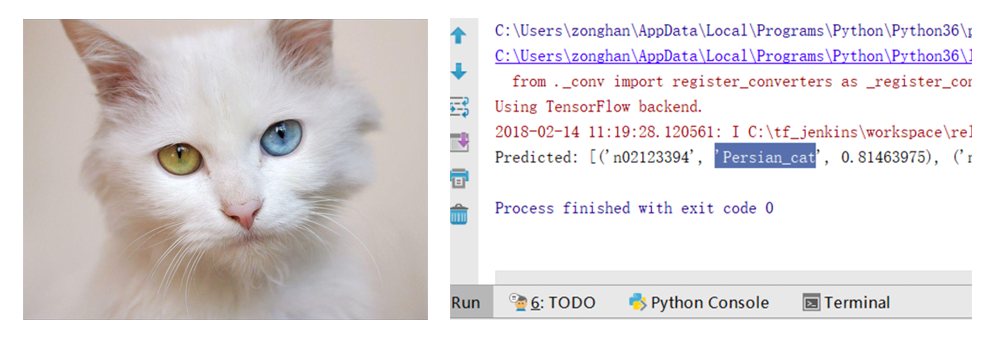
ЭЈЙ§ЖдетИіФЃаЭЕФЗтзАвдМАзїЮЊВњЦЗОРэЕФФуЃЌЯраХвВПЩвдYYГіКмЖрКУЭцЕФгІгУЁЃЫфШЛЭЈЙ§KerasжаЕФдЄжУФЃаЭПЩвдШУЮвУЧПьЫйЬхбщЛњЦїбЇЯАЕФФмСІЃЌЕЋЪЧИіШЫНЈвщзюКУЛЙЪЧздМКЪжЖЏДюНЈвЛЬзМђЕЅЕФФЃаЭЛсИќМгАяжњРэНтЁЃKerasЪЧЭЈЙ§SequentialФЃаЭЯпадЖбЕўЭјТчВуЁЃЦфжавЛаЉГЃгУЕФВуKerasвбОЗтзАКУСЫЃЌЭЌЪБЩЯУцЫЕЕНЕФМЄЛюКЏЪ§ЁЂгХЛЏЦїЁЂЫ№ЪЇКЏЪ§ЕШЕШвВЖМЪЧШЮО§ЬєбЁЕФЁЃЫљвдЯывЊЭЈЙ§KerasДюНЈздМКЕФФЃаЭЦфЪЕвВВЛФбЁЃЩЯЪіФкШнЪЕМЪЩЯвВжЛЪЧвЛИіХззЉв§гёЃЌжСЩйИіШЫвВЪЧЭЈЙ§етаЉВХПЊЪМЖдЛњЦїбЇЯАИааЫШЄЕФЁЃ
ЯывЊГЩЮЊЛњЦїбЇЯАДѓЩёЃПРЇФбЕФШЗДцдкЁЃВЛЙ§ЃЌзїЮЊВњЦЗОРэЦ№ТывЊСЫНтЫуЗЈЕФдРэвдМАЫќЕФБпНчКЭгХЪЦЃЌФмЙЛжЊЕРдкВЛЭЌГЁОАЯТгІгУЪВУДЫуЗЈЪВУДФЃаЭПЩвдДяЕНФПЕФЁЃ
|








