| БрМЭЦМі: |
БОЮФгкibm,НщЩмСЫШнвзРэНтЕФбЇЯАФЃаЭЃЌЩёОЭјТчЃЌЯрЖдМђЕЅЕФбЇЯАФЃаЭЃЌK
ОљжЕМЏШКЃЌздЪЪгІЙВеёРэТлЕШЁЃ
|
|
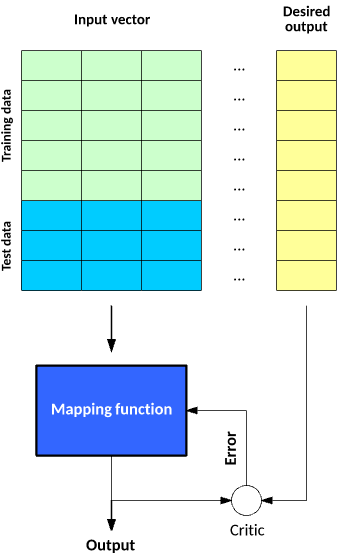
ЛњЦїбЇЯАжаЪЙгУЕФЫуЗЈДѓЬхЗжЮЊ 3 РрЃКМрЖНбЇЯАЁЂЮоМрЖНбЇЯАКЭЧПЛЏбЇЯАЁЃМрЖНбЇЯАЬсЙЉСЫЗДРЁРДБэУїдЄВте§ШЗгыЗёЃЌЖјЮоМрЖНбЇЯАУЛгаЯьгІЃКЫуЗЈНіГЂЪдИљОнЪ§ОнЕФвўКЌНсЙЙЖдЪ§ОнНјааЗжРрЁЃЧПЛЏбЇЯАРрЫЦгкМрЖНбЇЯАЃЌвђЮЊЫќЛсНгЪеЗДРЁЃЌЕЋЗДРЁВЂВЛЪЧЖдУПИіЪфШыЛђзДЬЌЖМЪЧБивЊЕФЁЃБОНЬГЬНЋЬНЫїетаЉбЇЯАФЃаЭБГКѓЕФРэФюЃЌвдМАгУгкУПжжФЃаЭЕФвЛаЉЙиМќЫуЗЈЁЃ
ЛњЦїбЇЯАЫуЗЈВЛЖЯдкЗЂеЙбнБфЁЃЕЋЪЧЃЌдкДѓВПЗжЧщПіЯТЃЌетаЉЫуЗЈЖМЧуЯђгкЪЪгІ 3 жжбЇЯАФЃаЭжЎвЛЁЃФЃаЭЕФДцдкЃЌжЛЪЧЮЊСЫвдФГжжЗНЪННјааздЖЏЕїНкЃЌвдБуИФНјЫуЗЈЕФВйзїЛђааЮЊЁЃ
ЭМ 1. ЫуЗЈЕФ 3 жжбЇЯАФЃаЭ

дкМрЖНбЇЯАжаЃЌЪ§ОнМЏАќКЌЦфФПБъЪфГіЃЈЛђБъЧЉЃЉЃЌвдБуКЏЪ§ФмЙЛМЦЫуИјЖЈдЄВтЕФЮѓВюЁЃдкзіГідЄВтВЂЩњГЩЃЈЪЕМЪНсЙћгыФПБъНсЙћЕФЃЉЮѓВюЪБЃЌЛсв§ШыМрЖНРДЕїНкКЏЪ§ВЂбЇЯАетвЛгГЩфЁЃ
дкЮоМрЖНбЇЯАжаЃЌЪ§ОнМЏВЛКЌФПБъЪфГіЃЛвђДЫЮоЗЈМрЖНКЏЪ§ЁЃКЏЪ§ГЂЪдНЋЪ§ОнМЏЛЎЗжЮЊЁАРрЁБЃЌвдБуУПИіРрЖМАќКЌЪ§ОнМЏЕФОпгаЙВЭЌЬиеїЕФвЛВПЗжЁЃ
зюКѓЃЌдкЧПЛЏбЇЯАжаЃЌЫуЗЈГЂЪдбЇЯАвЛаЉВйзїЃЌвдБуЛёЕУЕМжТФПБъзДЬЌЕФвЛзщИјЖЈзДЬЌЁЃЮѓВюВЛЛсдкУПИіЪОР§КѓЬсЙЉЃЈОЭЯёМрЖНбЇЯАвЛбљЃЉЃЌЖјЪЧдкЪеЕНЧПЛЏаХКХЃЈБШШчДяЕНФПБъзДЬЌЃЉКѓЬсЙЉЁЃДЫааЮЊРрЫЦгкШЫРрбЇЯАЃЌНідкИјгшНБРјЪБЮЊЫљгаВйзїЬсЙЉБивЊЗДРЁЁЃ
ЯждкЃЌШУЮвУЧЩюШыЗжЮівЛЯТУПжжФЃаЭЃЌСЫНтЫќУЧЕФЗНЗЈКЭЙиМќЫуЗЈЁЃ
МрЖНбЇЯА
МрЖНбЇЯАЪЧзюШнвзРэНтЕФбЇЯАФЃаЭЁЃМрЖНФЃаЭжаЕФбЇЯАашвЊДДНЈвЛИіКЏЪ§ЃЌИУКЏЪ§ПЩвдЪЙгУвЛИібЕСЗЪ§ОнМЏРДбЕСЗЃЌШЛКѓгІгУгкЮДМћЙ§ЕФЪ§ОнРДДяЕНвЛЖЈЕФдЄВтадФмЁЃЙЙНЈИУКЏЪ§ЕФФПЕФЪЧЮЊСЫНЋгГЩфКЏЪ§гааЇЭЦЙуЕНДгЮДМћЙ§ЕФЪ§ОнЁЃ
ПЩЭЈЙ§СНИіНзЖЮРДЙЙНЈКЭВтЪдвЛИіОпгаМрЖНбЇЯАФмСІЕФгГЩфКЏЪ§ЁЃдкЕквЛНзЖЮЃЌНЋвЛИіЪ§ОнМЏЛЎЗжЮЊСНжжбљБОЃКбЕСЗЪ§ОнКЭВтЪдЪ§ОнЁЃбЕСЗЪ§ОнКЭВтЪдЪ§ОнЖМАќКЌвЛИіВтЪдЪИСПЃЈЪфШыЃЉЃЌвдМАвЛИіЛђЖрИівбжЊЕФФПБъЪфГіжЕЁЃЪЙгУбЕСЗЪ§ОнМЏбЕСЗгГЩфКЏЪ§ЃЌжБЕНЫќДяЕНвЛЖЈЕФадФмЫЎЦНЃЈвЛИіКтСПгГЩфКЏЪ§НЋбЕСЗЪ§ОнгГЩфЕНЙиСЊЕФФПБъЪфГіЕФзМШЗадЕФжИБъЃЉЁЃдкМрЖНбЇЯАЕФЩЯЯТЮФжаЃЌЛсЖдУПИібЕСЗбљБОЖМжДааДЫЙ§ГЬЃЌдкДЫЙ§ГЬжаЃЌЪЙгУСЫЃЈЪЕМЪЪфГігыФПБъЪфГіЕФЃЉЮѓВюРДЕїНкгГЩфКЏЪ§ЁЃдкЯТвЛНзЖЮЃЌНЋЛсЪЙгУВтЪдЪ§ОнРДВтЪдбЕСЗЕФгГЩфКЏЪ§ЁЃВтЪдЪ§ОнБэЪОЮДгУгкбЕСЗЕФЪ§ОнЃЌВЂЮЊШчКЮНЋгГЩфКЏЪ§гааЇЭЦЙуЕНЮДМћЙ§ЕФЪ§ОнЬсЙЉСЫвЛжжКмКУЕФЖШСПЗНЗЈЁЃ
ЭМ 2. ЙЙНЈВЂВтЪдОпгаМрЖНбЇЯАФмСІЕФгГЩфКЏЪ§ЕФСНИіНзЖЮ
аэЖрЫуЗЈЖМЪєгкМрЖНбЇЯАРрБ№ЃЌБШШчжЇГжЪИСПЛњКЭЦгЫиБДвЖЫЙЁЃШУЮвУЧВщПДСНжжЙиМќЗНЗЈЃКЩёОЭјТчКЭОіВпЪїЁЃ
ЩёОЭјТч
ЩёОЭјТчЭЈЙ§вЛИіФЃаЭНЋЪфШыЪИСПДІРэЮЊНсЙћЪфГіЪИСПЃЌИУФЃаЭЕФСщИаРДдДгкДѓФджаЕФЩёОдЊКЭЫќУЧжЎМфЕФСЌНгЁЃИУФЃаЭАќКЌвЛаЉЭЈЙ§ШЈжЕЯрЛЅСЌНгЕФЩёОдЊВуЃЌШЈжЕПЩвдЕїНкФГаЉЪфШыЯрЖдгкЦфЫћЪфШыЕФживЊадЁЃУПИіЩёОдЊЖМАќКЌвЛИігУРДШЗЖЈИУЩёОдЊЕФЪфГіЕФМЄЛюКЏЪ§ЃЈзїЮЊЪфШыЪИСПгыШЈЪИСПЕФГЫЛ§ЕФКЏЪ§ЃЉЁЃМЦЫуЪфГіЕФЗНЪНЪЧЃЌНЋЪфШыЪИСПгІгУгкЭјТчЕФЪфШыВуЃЌШЛКѓЃЈВЩгУЧАРЁЗНЪНЃЉМЦЫуЭјТчжаУПИіЩёОдЊЕФЪфГіЁЃ
ЭМ 3. ЕфаЭЩёОЭјТчЕФВу

зюГЃгУгкЩёОЭјТчЕФМрЖНбЇЯАЗНЗЈжЎвЛЪЧЗДЯђДЋВЅЁЃдкЗДЯђДЋВЅжаЃЌЛсгІгУвЛИіЪфШыЪИСПВЂМЦЫуЪфГіЪИСПЁЃМЦЫуЃЈЪЕМЪЪфГігыФПБъЪфГіЕФЃЉЮѓВюЃЌШЛКѓДгЪфГіВуЯђЪфШыВужДааЗДЯђДЋВЅЃЌвдБуЕїНкШЈжЕКЭЦЋВюЃЈзїЮЊЖдЪфГіЕФЙБЯзЕФКЏЪ§ЃЌПЩвдеыЖдбЇЯАТЪНјааЕїНкЃЉЁЃвЊНјвЛВНСЫНтЩёОЭјТчКЭЗДЯђДЋВЅЃЌЧыВЮдФЁАЩёОЭјТчЩюШыЦЪЮіЁБЁЃ
ОіВпЪїЃЈDecision treesЃЉ
ОіВпЪїЪЧвЛжжгУгкЗжРрЕФМрЖНбЇЯАЗНЗЈЁЃИљОнгЩЪ§ОнЕФЬиеїЭЦЖЯГіЕФОіВпЙцдђЃЌетжжЫуЗЈЛсДДНЈЪїРДдЄВтЪфШыЪИСПЕФНсЙћЁЃОіВпЪїКмгагУЃЌвђЮЊЫќУЧКмШнвзПЩЪгЛЏЃЌЪЙФњФмЙЛРэНтЕМжТНсЙћЕФвђЫиЁЃ
ЭМ 4. вЛжжЕфаЭЕФОіВпЪї
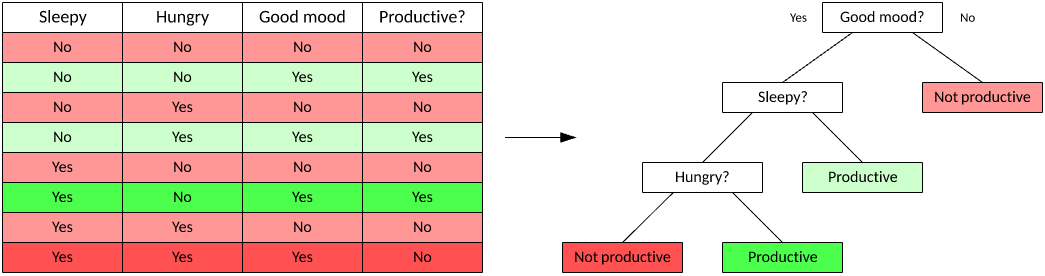
ОіВпЪїгаСНжжФЃаЭЃКЗжРрЪїКЭЛиЙщЪїЁЃдкЗжРрЪїжаЃЌФПБъБфСПЪЧвЛИіРыЩЂжЕЃЌЪївЖБэЪОРрБъЧЉЃЈШчЪОР§ЪїжаЫљЪОЃЉЃЛдкЛиЙщЪїжаЃЌФПБъБфСППЩвдНгЪмСЌајжЕЁЃФњЪЙгУвЛИіЪ§ОнМЏРДбЕСЗЪїЃЌШЛКѓЃЌИУЪїРћгУЪ§ОнЙЙНЈвЛжжФЃаЭЁЃФњЫцКѓПЩвдЪЙгУИУЪїЃЌРћгУЮДМћЙ§ЕФЪ§ОнжЦЖЈОіВпЃЈЭЈЙ§ЛљгкЕБЧАЕФВтЪдЪИСПБщРњЪїЃЌжБЕНгіЕНЪївЖЃЉЁЃ
гаДѓСПгУгкОіВпЪїбЇЯАЕФЫуЗЈЁЃзюдчЕФЫуЗЈжЎвЛЪЧЕќДњЖўВцЪї 3ЃЈIterative Dichotomiser
3ЃЌID3ЃЉЃЌЫќЛљгкЪИСПжаЕФвЛИізжЖЮЃЌНЋЪ§ОнМЏВ№ЗжЮЊСНИіВЛЭЌЕФЪ§ОнМЏЁЃЭЈЙ§МЦЫузжЖЮЕФьиРДбЁдёзжЖЮЃЈьиЪЧЖдзжЖЮжЕЕФЗжВМЕФвЛжжЖШСПЃЉЁЃИУЫуЗЈЕФФПЕФЪЧДгЪИСПжабЁдёвЛИізжЖЮЃЌЫцзХЪїЕФЙЙНЈЃЌетИізжЖЮЛсЕМжТЖдЪ§ОнМЏЕФКѓајВ№ЗжЕФьиЯТНЕЁЃ
Г§ ID3 ЭтЃЌЛЙгавЛИіУћЮЊ C4.5 ЕФИФСМЫуЗЈЃЈID3 ЕФЛЛДњЫуЗЈЃЉКЭЖрдЊздЪЪгІЛиЙщбљЬѕ (MARS)ЃЌКѓепЙЙНЈЕФОіВпЪїИФНјСЫЪ§зжДІРэЁЃ
ЮоМрЖНбЇЯА
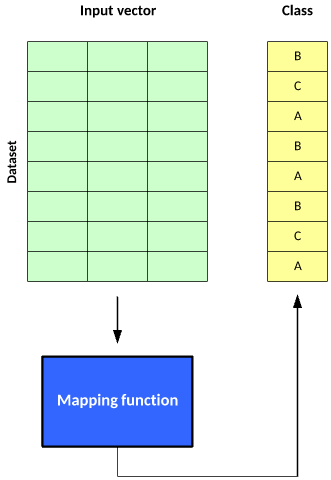
ЮоМрЖНбЇЯАвВЪЧвЛжжЯрЖдМђЕЅЕФбЇЯАФЃаЭЃЌЕЋДгУћГЦПЩвдПДГіЃЌЫќШБЗІЦРМлЃЌЧвЮоЗЈЖШСПадФмЁЃЫќЕФФПЕФЪЧЙЙНЈвЛИігГЩфКЏЪ§ЃЌвдБуЛљгкЪ§ОнжавўВиЕФЬиеїНЋЪ§ОнЛЎЗжЮЊВЛЭЌРрЁЃ
гыМрЖНбЇЯАвЛбљЃЌЮоМрЖНбЇЯАЕФЪЙгУвВЗжЮЊСНИіНзЖЮЁЃдкЕквЛНзЖЮЃЌгГЩфКЏЪ§НЋвЛИіЪ§ОнМЏЛЎЗжЮЊВЛЭЌЕФРрЁЃУПИіЪфШыЪИСПЖМАќКЌдквЛИіРржаЃЌЕЋИУЫуЗЈЮоЗЈЖдетаЉРргІгУБъЧЉЁЃ
ЭМ 5. ЪЙгУЮоМрЖНбЇЯАЕФСНИіНзЖЮ
НсЙћПЩФмЪЧЪ§ОнБЛЛЎЗжЮЊВЛЭЌЕФРрЃЈШЛКѓФњПЩвдДгжаЕУГігаЙиНсЙћРрЕФНсТлЃЉЃЌЕЋФњПЩвдИљОнгІгУЧщПіНјвЛВНЪЙгУетаЉРрЁЃЭЦМіЯЕЭГОЭЪЧетРргІгУжаЕФвЛжжЃЌЦфжаЕФЪфШыЪИСППЩФмБэЪОгУЛЇЕФЬиеїЛђЙКТђааЮЊЃЌвЛИіРржаЕФгУЛЇБэЪООпгаРрЫЦаЫШЄЕФгУЛЇЃЌШЛКѓПЩвдЖдетаЉгУЛЇНјаагЊЯњЛђЭЦМіВњЦЗЁЃ
вЊЪЕЯжЮоМрЖНбЇЯАЃЌПЩвдВЩгУИїжжИїбљЕФЫуЗЈЃЌБШШч k ОљжЕМЏШКЛђздЪЪгІЙВеёРэТлЃЌЛђеп ARTЃЈЪЕЯжЪ§ОнМЏЕФЮоМрЖНМЏШКЕФвЛЯЕСаЫуЗЈЃЉЁЃ
K ОљжЕМЏШКЃЈK-means clusteringЃЉ
k ОљжЕМЏШКЦ№дДгкаХКХДІРэЃЌЪЧвЛжжМђЕЅЕФСїааМЏШКЫуЗЈЁЃИУЫуЗЈЕФФПЕФЪЧНЋЪ§ОнМЏжаЕФЪОР§ЛЎЗжЮЊЕН k
ИіМЏШКжаЁЃУПИіЪОР§ЖМЪЧвЛИіЪ§зжЪИСПЃЌдЪаэМЦЫуЪИСПМфЕФОрРызїЮЊХЗМИРяЕТОрРыЁЃ
ЯТУцЕФМђЕЅЪОР§жБЙлЕиеЙЪОСЫШчКЮНЋЪ§ОнЛЎЗжЕН k = 2 ИіМЏШКжаЃЌЦфжаЕФЪОР§МфЕФХЗМИРяЕТОрРыЪЧРыМЏШКЕФжЪаФЃЈжааФЃЉзюНќЕФОрРыЃЌЫќБэУїСЫМЏШКЕФГЩдБЙиЯЕЁЃ
ЭМ 6. k ОљжЕМЏШКЕФМђЕЅЪОР§

k ОљжЕЫуЗЈЗЧГЃШнвзРэНтКЭЪЕЯжЁЃЪзЯШНЋЪ§ОнМЏжаЕФУПИіЪОР§ЫцЛњЗжХфЕНвЛИіМЏШКЃЌМЦЫуМЏШКЕФжЪаФзїЮЊЫљгаГЩдБЪОР§ЕФОљжЕЃЌШЛКѓЕќДњИУЪ§ОнМЏЃЌвдШЗЖЈвЛИіЪОР§РыЫљЪєМЏШКИќНќЛЙЪЧРыЬцДњМЏШКИќНќЃЈМйЩш
k = 2ЃЉЁЃШчЙћГЩдБРыЬцДњМЏШКИќНќЃЌдђНЋИУЪОР§вЦЕНаТМЏШКВЂжиаТМЦЫуЫќЕФжЪаФЁЃДЫЙ§ГЬвЛжБГжајЕНУЛгаЪОР§вЦЖЏЕНЬцДњМЏШКЮЊжЙЁЃ
ШчЭМЫљЪОЃЌдкЖдЪОР§ЪИСПжаЕФЬиеївЛЮоЫљжЊЃЈМДУЛгаМрЖНЃЉЕФЧщПіЯТЃЌk ОљжЕНЋЪОР§Ъ§ОнМЏЛЎЗжЮЊ k ИіМЏШКЁЃ
здЪЪгІЙВеёРэТлЃЈAdaptive resonance theoryЃЉ
здЪЪгІЙВеёРэТл (ART) ЪЧвЛЯЕСаЬсЙЉФЃЪНЪЖБ№КЭдЄВтФмСІЕФЫуЗЈЁЃПЩвдАДЮоМрЖНКЭМрЖНФЃаЭРДЛЎЗж ARTЃЌЕЋетРяНЋжиЕуНщЩмЮоМрЖНЗНУцЁЃART
ЪЧвЛжжздзщжЏЩёОЭјТчМмЙЙЁЃИУЗНЗЈдЪаэдкЮЌЛЄЯжгажЊЪЖЕФЭЌЪБбЇЯАаТгГЩфЁЃ
Яё k ОљжЕвЛбљЃЌПЩвдЪЙгУ ART1 ЛЎЗжМЏШКЃЌЕЋЫќгавЛИіЙиМќгХЪЦЃЌвђЮЊЮоашдкдЫааЪБЖЈвх kЃЌART1
ПЩвдЛљгкЪ§ОнРДЕїНкМЏШКЪ§СПЁЃ
ART1 АќКЌ 3 жжЙиМќЬиеїЃКвЛИіБШНЯзжЖЮЃЈгУгкШЗЖЈвЛИіаТЬиеїЪИСПгаЖрЪЪКЯЯжгаРрБ№ЃЉЁЂвЛИіЪЖБ№зжЖЮЃЈАќКЌБэЪОЛюЖЏМЏШКЕФЩёОдЊЃЉЃЌвдМАвЛИіжижУФЃПщЁЃгІгУЪфШыЪИСПКѓЃЌБШНЯзжЖЮЛсЪЖБ№зюЪЪКЯЫќЕФМЏШКЁЃШчЙћЪфШыЪИСПгыЪЖБ№зжЖЮЕФЦЅХфЖШИпгкФГИіОЏНфВЮЪ§ЃЌдђИќаТгыЪЖБ№зжЖЮжаЕФЩёОдЊЕФСЌНгЃЌвдБуПМТЧетИіаТЪИСПЁЃЗёдђЃЌдкЪЖБ№зжЖЮжаДДНЈвЛИіаТЩёОдЊЃЌвдБуПМТЧвЛИіаТМЏШКЁЃДДНЈаТЩёОдЊКѓЃЌВЛЛсИќаТЯжгаЩёОдЊЕФШЈжЕЃЌВЂдЪаэЫќУЧБЃСєЯжгажЊЪЖЁЃвдетжжЗНЪНгІгУЪ§ОнМЏжаЕФЫљгаЪОР§ЃЌжБЕНУЛгаЪОР§ЪфШыЪИСПИќИФМЏШКЁЃДЫПЬЃЌбЕСЗВХЫуЭъГЩЁЃ
ЭМ 7. ART1 ЕФЬиад

ART АќКЌЖрИіжЇГжЖўНјжЦЪфШыЪИСПЛђЪЕжЕЪИСП (ART2) ЕФЫуЗЈЁЃдЄВт ART ЪЧ ART1/2
ЕФвЛжжБфЬхЃЌЕЋЫќвРРЕгкМрЖНЪНбЕСЗЁЃ
ЧПЛЏбЇЯА
ЧПЛЏбЇЯАЪЧвЛИігаШЄЕФбЇЯАФЃаЭЃЌВЛНіФмбЇЯАШчКЮНЋЪфШыгГЩфЕНЪфГіЃЌЛЙФмбЇЯАШчКЮНшжњвРРЕЙиЯЕНЋвЛЯЕСаЪфШыгГЩфЕНЪфГіЃЈР§Шч
Markov ОіВпСїГЬЃЉЁЃдкЛЗОГжаЕФзДЬЌКЭИјЖЈзДЬЌЯТЕФПЩФмВйзїЕФЩЯЯТЮФжаЃЌПЩвдгІгУЧПЛЏбЇЯАЁЃдкбЇЯАЙ§ГЬжаЃЌИУЫуЗЈЫцЛњЬНЫїФГИіЛЗОГжаЕФзДЬЌ-ВйзїЖдЃЈвдЙЙНЈвЛИізДЬЌ-ВйзїЖдБэЃЉЃЌШЛКѓгІгУЫљбЇаХЯЂРДЭкОђзДЬЌ-ВйзїЖдНБРјЃЌвдБуЮЊИјЖЈзДЬЌбЁдёФмЕМжТФГИіФПБъзДЬЌЕФзюМбВйзїЁЃвЊНјвЛВНСЫНтЧПЛЏбЇЯАЃЌЧыВЮдФЁАЭЈЙ§ЧПЛЏбЇЯАбЕСЗШэМўДњРэРДжДааКЯРэааЮЊЁБЁЃ
ЭМ 8. ЧПЛЏбЇЯАФЃаЭ
ПМТЧвЛИіЭц 21ЕуЦЫПЫгЮЯЗЕФМђЕЅДњРэЁЃзДЬЌБэЪОЭцМвЕФХЦЪ§ЁЃВйзїБэЪОЭц 21ЕуЦЫПЫгЮЯЗЕФДњРэПЩвджДааЕФВйзї
ЁЊ дкБОР§жаЮЊФУХЦЛђЭЃХЦЁЃбЕСЗДњРэЭц 21ЕуЦЫПЫгЮЯЗЩцМАЕНЖрЪжХЦЃЌЛсеыЖдЛёЪЄЛђЪЇАмЮЊИјЖЈзДЬЌ-ВйзїСЊНсЬсЙЉНБРјЁЃР§ШчЃЌзДЬЌжЕ
10 БэЪОФУХЦЕФНБРјЮЊ 1.0ЃЌЭЃХЦЕФНБРјЮЊ 0.0ЃЈБэУїФУХЦЪЧзюМббЁдёЃЉЁЃЖдгкзДЬЌ 20ЃЌбЇЕНЕФНБРјПЩФмЪЧЃКФУХЦЕФНБРјЮЊ
1.0ЃЌЭЃХЦЕФНБРјЮЊ 0.0ЁЃЖдгквЛЪжВЛЬЋУїШЗЕФХЦЃЌзДЬЌ 17 ЕФВйзїжЕПЩФмБэЪОЭЃХЦНБРј 0.95
КЭФУХЦНБРј 0.05ЁЃШЛКѓЃЌДЫДњРэЛсИљОнИХТЪдк 95% ЕФЪБМфЭЃХЦЃЌдк 5% ЕФЪБМфФУХЦЁЃдкГіСЫаэЖрЪжХЦжЎКѓЃЌетаЉНБРјЛсБфЕУУїШЗЃЌБэУїИјЖЈзДЬЌЃЈЛђвЛЪжХЦЃЉЕФзюМббЁдёЁЃ
дкМрЖНбЇЯАжаЃЌЦРМлЛЗНкЛсЖдУПИіЪОР§НјааЦРЗжЃЌЖјдкЧПЛЏбЇЯАжаЃЌЦРМлЛЗНкНідкДяЕНФПБъзДЬЌЃЈгЕгазДЬЌЮЊ
21 ЕФвЛЪжХЦЃЉЪБЬсЙЉЦРЗжЁЃ
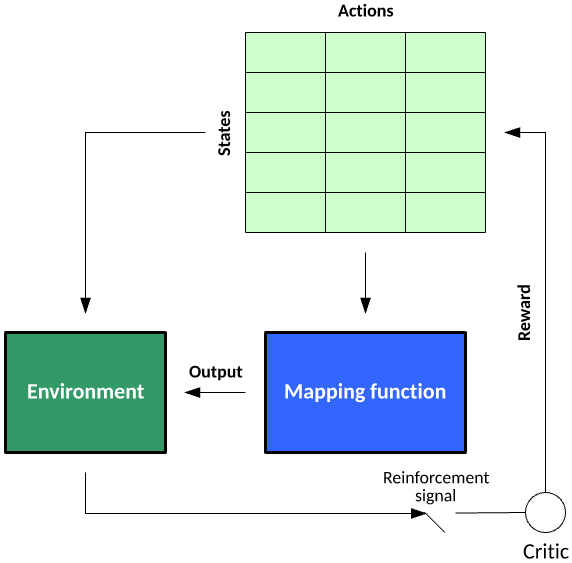
Q-learning
Q-learning ЪЧвЛжжЧПЛЏбЇЯАЗНЗЈЃЌЫќКЯВЂСЫУПИізДЬЌ-ВйзїЖдЕФ Q жЕРДБэУїзёбИјЖЈзДЬЌТЗОЖЕФНБРјЁЃQ-learning
ЕФвЛАуЫуЗЈЪЧЗжНзЖЮбЇЯАвЛИіЛЗОГжаЕФНБРјЁЃУПИізДЬЌЖМАќРЈЮЊзДЬЌжДааВйзїЃЌжБЕНДяЕНФПБъзДЬЌЁЃдкбЇЯАЦкМфЃЌИљОнИХТЪЭъГЩбЁдёЕФВйзїЃЈзїЮЊ
Q жЕЕФКЏЪ§ЃЉЃЌетдЪаэЬНЫїзДЬЌ-ВйзїПеМфЁЃдкДяЕНФПБъзДЬЌЪБЃЌСїГЬДгФГИіГѕЪМЮЛжУдйДЮПЊЪМЁЃ
ЮЊИјЖЈзДЬЌбЁдёВйзїКѓЃЌЛсеыЖдУПИізДЬЌ-ВйзїЖдРДИќаТ Q жЕЁЃЖдЕБЧАзДЬЌгІгУВйзїРДДяЕНаТзДЬЌЃЈгІгУСЫелПлЯЕЪ§ЃЉКѓЃЌЛсЪЙгУПЩгУгкИУаТзДЬЌЧвОпгазюДѓ
Q жЕЕФВйзїЃЈПЩФмЪВУДвВВЛзіЃЉЫљЬсЙЉЕФНБРјЃЌЖдзДЬЌ-ВйзїЖдЕФ Q жЕНјааИќаТЁЃЭЈЙ§бЇЯАТЪЃЌПЩвдЪЕЯжИќаТНсЙћЕФНјвЛВНелПлЃЌбЇЯАТЪПЩвдШЗЖЈБІЙѓЕФаТаХЯЂвбДцдкЖрГЄЪБМфЁЃелПлЯЕЪ§БэУїСЫЮДРДНБРјЯрНЯгкЖЬЦкНБРјЕФживЊадЁЃЧызЂвтЃЌЛЗОГжаПЩФмЬюШыИКжЕКЭе§жЕНБРјЃЌЛђепжЛгаФПБъзДЬЌПЩвдБэУїНБРјЁЃ
ЭМ 9. вЛжжЕфаЭЕФ Q-learning
ЫуЗЈ
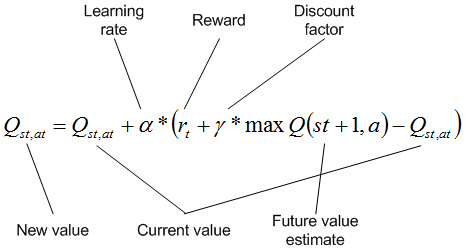
ДЫЫуЗЈгУгкаэЖрДяЕНФПБъзДЬЌЕФЪБМфЕуЃЌВЂдЪаэЛљгкзДЬЌЕФИХТЪадВйзїбЁдёРДИќаТ Q жЕЁЃЭъГЩЪБЃЌПЩвдздгЩЪЙгУ
Q жЕЃЈЖдИјЖЈзДЬЌЪЙгУОпгазюДѓ Q жЕЕФВйзїЃЉРДРћгУЫљЛёЕУЕФжЊЪЖЃЌвдБуВЩгУзюМбЗНЪНДяЕНФПБъзДЬЌЁЃ
ЧПЛЏбЇЯАЛЙАќКЌЦфЫћОпгаВЛЭЌЬиеїЕФЫуЗЈЁЃзДЬЌ-Вйзї-НБРј-зДЬЌ-ВйзїЕФбЛЗРрЫЦгк Q-learningЃЌЕЋВйзїЕФбЁдёВЛЛљгкзюДѓ
Q жЕЃЌЖјЪЧАќКЌвЛЖЈЕФИХТЪЁЃЧПЛЏбЇЯАЪЧвЛжжРэЯыЕФЫуЗЈЃЌПЩвдбЇЯАШчКЮдкВЛШЗЖЈЕФЛЗОГжажЦЖЈОіВпЁЃ
НсЪјгя
ЛњЦїбЇЯАЪмвцгкТњзуВЛЭЌашЧѓЕФИїжжИїбљЕФЫуЗЈЁЃМрЖНбЇЯАЫуЗЈбЇЯАвЛИівбОЗжРрЕФЪ§ОнМЏЕФгГЩфКЏЪ§ЃЌЖјЮоМрЖНбЇЯАЫуЗЈПЩЛљгкЪ§ОнжаЕФвЛаЉвўВиЬиеїЖдЮДБъМЧЕФЪ§ОнМЏНјааЗжРрЁЃзюКѓЃЌЧПЛЏбЇЯАПЩвдЭЈЙ§ЗДИДЬНЫїФГИіВЛШЗЖЈЕФЛЗОГЃЌбЇЯАИУЛЗОГжаЕФОіВпжЦЖЈВпТдЁЃ
|








