| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌБОЮФНЋЭЈЙ§вдOCRЃЈЙтбЇзжЗћЪЖБ№ЃЉЕФГЁОАРДНщЩмЩюЖШбЇЯАдкМЦЫуЛњЪгОѕжаЕФгІгУЁЃ
|
|
БГОА
МЦЫуЛњЪгОѕЪЧРћгУЩуЯёЛњКЭЕчФдДњЬцШЫблЃЌЪЙЕУМЦЫуЛњгЕгаРрЫЦгкШЫРрЕФЖдФПБъНјааМьВтЁЂЪЖБ№ЁЂРэНтЁЂИњзйЁЂХаБ№ОіВпЕФЙІФмЁЃвдУРЭХвЕЮёЮЊР§ЃЌдкЩЬМвЩЯЕЅЁЂЭХЕЅеЙЪОЁЂЯћЗбЦРМлЕШЖрИіЛЗНкЖМЛсЩцМАМЦЫуЛњЪгОѕЕФгІгУЃЌАќРЈЮФзжЪЖБ№ЁЂЭМЦЌЗжРрЁЂФПБъМьВтКЭЭМЯёжЪСПЦРМлЕШЗНЯђЁЃБОЮФНЋЭЈЙ§вдOCRЃЈЙтбЇзжЗћЪЖБ№ЃЉЕФГЁОАРДНщЩмЩюЖШбЇЯАдкМЦЫуЛњЪгОѕжаЕФгІгУЁЃ
ЛљгкЩюЖШбЇЯАЕФOCR
ЮФзжЪЧВЛПЩЛђШБЕФЪгОѕаХЯЂРДдДЁЃЯрЖдгкЭМЯё/ЪгЦЕжаЕФЦфЫћФкШнЃЌЮФзжЭљЭљАќКЌИќЧПЕФгявхаХЯЂЃЌвђДЫЖдЭМЯёжаЕФЮФзжЬсШЁКЭЪЖБ№ОпгажиДѓвтвхЁЃOCRдкУРЭХвЕЮёжажївЊЦ№зХСНЗНУцзїгУЁЃвЛЗНУцЪЧИЈжњТМШыЃЌБШШчдквЦЖЏжЇИЖЛЗНкЭЈЙ§ЖдвјааПЈПЈКХЕФХФееЪЖБ№вдЪЕЯжздЖЏАѓПЈЃЌИЈжњдЫгЊТМШыВЫЕЅжаВЫЦЗаХЯЂЃЌдкХфЫЭЛЗНкЭЈЙ§ЖдЩЬМваЁЦБЕФЪЖБ№вдЪЕЯжЕїЖШКЫЕЅЃЌШчЭМ1ЫљЪОЁЃСэвЛЗНУцЪЧЩѓКЫаЃбщЃЌБШШчдкЩЬМвзЪжЪЩѓКЫЛЗНкЖдЩЬМвЩЯДЋЕФЩэЗнжЄЁЂгЊвЕжДееКЭВЭвћаэПЩжЄЕШжЄМўееЦЌНјаааХЯЂЬсШЁКЭКЫбщвдШЗБЃИУЩЬМвЕФКЯЗЈадЃЌЛњЦїЙ§ТЫЩЬМвЩЯЕЅКЭгУЛЇЦРМлЛЗНкВњЩњЕФАќКЌЮЅНћДЪЕФЭМЦЌЁЃ
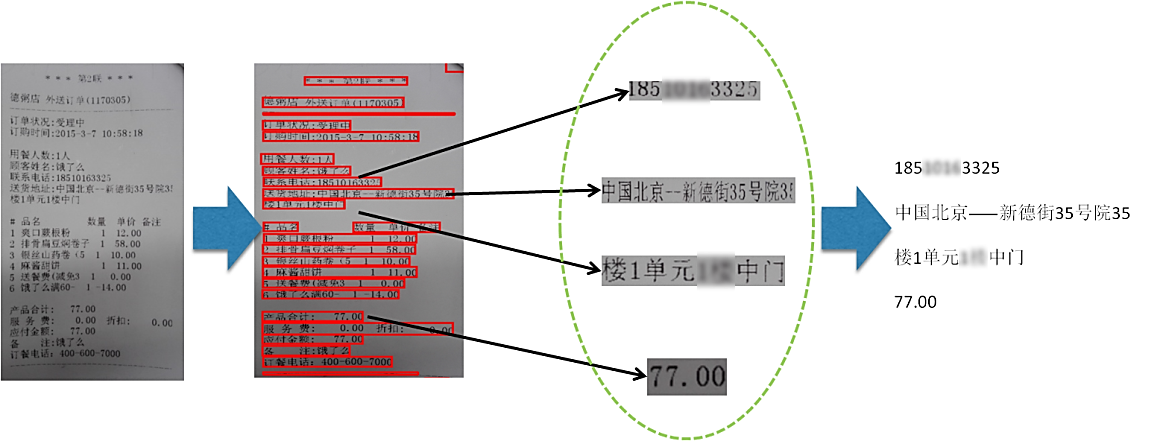
ЭМ1 ЭМЯёжаЕФЮФзжЬсШЁКЭЪЖБ№СїГЬ
OCRММЪѕЗЂеЙРњГЬ
ДЋЭГЕФOCRЛљгкЭМЯёДІРэЃЈЖўжЕЛЏЁЂСЌЭЈгђЗжЮіЁЂЭЖгАЗжЮіЕШЃЉКЭЭГМЦЛњЦїбЇЯАЃЈAdaboostЁЂSVMЃЉЃЌЙ§ШЅ20ФъМфдкгЁЫЂЬхКЭЩЈУшЮФЕЕЩЯШЁЕУСЫВЛДэЕФаЇЙћЁЃДЋЭГЕФгЁЫЂЬхOCRНтОіЗНАИећЬхСїГЬШчЭМ2ЫљЪОЁЃ

ЭМ2 ДЋЭГЕФгЁЫЂЬхOCRНтОіЗНАИ
ДгЪфШыЭМЯёЕНИјГіЪЖБ№НсЙћОРњСЫЭМЯёдЄДІРэЁЂЮФзжааЬсШЁКЭЮФзжааЪЖБ№Ш§ИіНзЖЮЁЃЦфжаЮФзжааЬсШЁЕФЯрЙиВНжшЃЈАцУцЗжЮіЁЂааЧаЗжЃЉЛсЩцМАДѓСПЕФЯШбщЙцдђЃЌЖјЮФзжааЪЖБ№жївЊЛљгкДЋЭГЕФЛњЦїбЇЯАЗНЗЈЁЃЫцзХвЦЖЏЩшБИЕФЦеМАЃЌЖдХФЩуЭМЯёжаЕФЮФзжЬсШЁКЭЪЖБ№ГЩЮЊжїСїашЧѓЃЌЭЌЪБЖдГЁОАжаЮФзжЕФЪЖБ№ашЧѓдНРДдНЭЛГіЁЃвђДЫЃЌЯрБШгкгЁЫЂЬхГЁОАЃЌХФееЮФзжЕФЪЖБ№НЋУцСйвдЯТШ§ЗНУцЬєеНЃК
ГЩЯёИДдгЁЃдыЩљЁЂФЃК§ЁЂЙтЯпБфЛЏЁЂаЮБфЁЃ
ЮФзжИДдгЁЃзжЬхЁЂзжКХЁЂЩЋВЪЁЂФЅЫ№ЁЂБЪЛПэЖШШЮвтЁЂЗНЯђШЮвтЁЃ
ГЁОАИДдгЁЃАцУцШБЪЇЁЂБГОАИЩШХЁЃ
ЖдгкЩЯЪіЬєеНЃЌДЋЭГЕФOCRНтОіЗНАИДцдкзХвдЯТВЛзуЃК
ЭЈЙ§АцУцЗжЮіЃЈСЌЭЈгђЗжЮіЃЉКЭааЧаЗжЃЈЭЖгАЗжЮіЃЉРДЩњГЩЮФБОааЃЌвЊЧѓАцУцНсЙЙгаНЯЧПЕФЙцдђадЧвЧАБГОАПЩЗжадЧПЃЈР§ШчКкАзЮФЕЕЭМЯёЁЂГЕХЦЃЉЃЌЮоЗЈДІРэЧАБГОАИДдгЕФЫцвтЮФзжЃЈР§ШчГЁОАЮФзжЁЂВЫЕЅЁЂЙуИцЮФзжЕШЃЉЁЃСэЭтЃЌЖўжЕЛЏВйзїБОЩэЖдЭМЯёГЩЯёЬѕМўКЭБГОАвЊЧѓБШНЯПСПЬЁЃ
ЭЈЙ§ШЫЙЄЩшМЦБпдЕЗНЯђЬиеїЃЈР§ШчЗНЯђЬнЖШжБЗНЭМЃЉРДбЕСЗзжЗћЪЖБ№ФЃаЭЃЌдкзжЬхБфЛЏЁЂФЃК§ЛђБГОАИЩШХЪБЃЌДЫРрЕЅвЛЕФЬиеїЕФЗКЛЏФмСІбИЫйЯТНЕЁЃ
Й§ЖШвРРЕгкзжЗћЧаЗжЕФНсЙћЃЌдкзжЗћХЄЧњЁЂеГСЌЁЂдыЩљИЩШХЕФЧщПіЯТЃЌЧаЗжЕФДэЮѓДЋВЅгШЦфЭЛГіЁЃ
ОЁЙмЭМЯёдЄДІРэФЃПщПЩгааЇИФЩЦЪфШыЭМЯёЕФжЪСПЃЌЕЋЖрИіЖРСЂЕФаЃе§ФЃПщЕФДЎСЊБиШЛДјРДЮѓВюДЋЕнЁЃСэЭтгЩгкИїФЃПщгХЛЏФПБъЖРСЂЃЌЫќУЧЮоЗЈШкКЯЕНЭГвЛЕФПђМмжаНјааЁЃ
ЮЊСЫНтОіЩЯЪіЮЪЬтЃЌЯжгаММЪѕдквдЯТШ§ЗНУцНјааСЫИФНјЁЃ
1.ЮФзжааЬсШЁ
ДЋЭГOCRЃЈШчЭМ3ЫљЪОЃЉВЩШЁздЩЯЖјЯТЕФЧаЗжЪНЃЌЕЋЫќжЛЪЪгУгкАцУцЙцдђБГОАМђЕЅЕФЧщПіЁЃИУСьгђЛЙгаСэЭтСНРрЫМТЗЁЃ
здЕзЯђЩЯЕФЩњГЩЪНЗНЗЈЁЃИУРрЗНЗЈЭЈЙ§СЌЭЈгђЗжЮіЛђзюДѓЮШЖЈМЋжЕЧјгђЃЈMSERЃЉЕШЗНЗЈЬсШЁКђбЁЧјгђЃЌШЛКѓЭЈЙ§ЮФзж/ЗЧЮФзжЕФЗжРрЦїНјааЧјгђЩИбЁЃЌЖдЩИбЁКѓЕФЧјгђНјааКЯВЂЩњГЩЮФзжааЃЌдйНјааЮФзжааМЖБ№ЕФЙ§ТЫЃЌШчЭМ3ЫљЪОЁЃИУРрЗНЗЈЕФВЛзуЪЧЃЌвЛЗНУцСїГЬШпГЄЕМжТЕФГЌВЮЪ§Й§ЖрЃЌСэвЛЗНУцЮоЗЈРћгУШЋОжаХЯЂЁЃ

ЭМ3 ЛљгкздЕзЯђЩЯЕФЮФзжМьВт
ЛљгкЛЌЖЏДАПкЕФЗНЗЈЁЃИУРрЗНЗЈРћгУЭЈгУФПБъМьВтЕФЫМТЗРДЬсШЁЮФзжаааХЯЂЃЌРћгУбЕСЗЕУЕНЕФЮФзжаа/ДЪгя/зжЗћМЖБ№ЕФЗжРрЦїРДНјааШЋЭМЫбЫїЁЃдЪМЕФЛљгкЛЌЖЏДАПкЗНЗЈЭЈЙ§бЕСЗЮФзж/БГОАЖўЗжРрМьВтЦїЃЌжБНгЖдЪфШыЭМЯёНјааЖрГпЖШЕФДАПкЩЈУшЁЃМьВтЦїПЩвдЪЧДЋЭГЛњЦїбЇЯАФЃаЭЃЈAdaboostЁЂRandom
FernsЃЉЃЌвВПЩвдЪЧЩюЖШОэЛ§ЩёОЭјТчЁЃ
ЮЊСЫЬсЩ§аЇТЪЃЌDeepTextЁЂTextBoxesЕШЗНЗЈЯШЬсШЁКђбЁЧјгђдйНјааЧјгђЛиЙщКЭЗжРрЃЌЭЌЪБИУРрЗНЗЈПЩНјааЖЫЕНЖЫбЕСЗЃЌЕЋЖдЖрНЧЖШКЭМЋЖЫПэИпБШЕФЮФзжЧјгђейЛиЕЭЁЃ
2.ДЋЭГЕЅзжЪЖБ№в§ЧцЁњЛљгкЩюЖШбЇЯАЕФЕЅзжЪЖБ№в§Чц
гЩгкЕЅзжЪЖБ№в§ЧцЕФбЕСЗЪЧвЛИіЕфаЭЕФЭМЯёЗжРрЮЪЬтЃЌЖјОэЛ§ЩёОЭјТчдкУшЪіЭМЯёЕФИпВугявхЗНУцгХЪЦУїЯдЃЌЫљвджїСїЗНЗЈЪЧЛљгкОэЛ§ЩёОЭјТчЕФЭМЯёЗжРрФЃаЭЁЃЪЕМљжаЕФЙиМќЕудкгкШчКЮЩшМЦЭјТчНсЙЙКЭКЯГЩбЕСЗЪ§ОнЁЃЖдгкЭјТчНсЙЙЃЌЮвУЧПЩвдНшМјЪжаДЪЖБ№СьгђЯрЙиЭјТчНсЙЙЃЌвВПЩВЩгУOCRСьгђШЁЕУГіЩЋаЇЙћЕФMaxoutЭјТчНсЙЙЃЌШчЭМ4ЫљЪОЁЃЖдгкЪ§ОнКЯГЩЃЌашПМТЧзжЬхЁЂаЮБфЁЂФЃК§ЁЂдыЩљЁЂБГОАБфЛЏЕШвђЫиЁЃ
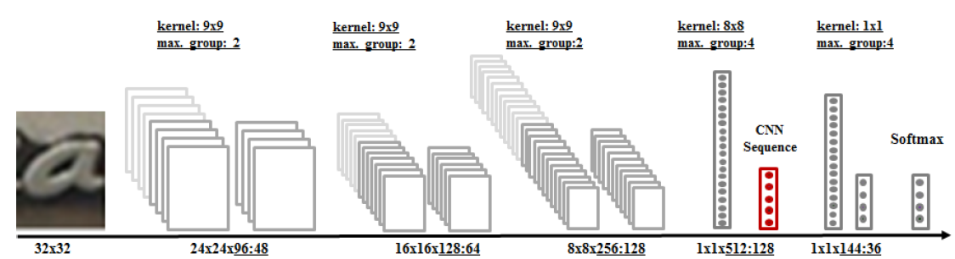
ЭМ4 ЛљгкMaxout ОэЛ§ЩёОЭјТчНсЙЙЕФЕЅзжЪЖБ№ФЃаЭ
Бэ1ИјГіСЫОэЛ§ЩёОЭјТчЕФЬиеїбЇЯАКЭДЋЭГЬиеїЕФадФмБШНЯЃЌПЩвдПДГіЭЈЙ§ОэЛ§ЩёОЭјТчбЇЯАЕУЕНЕФЬиеїМјБ№ФмСІИќЧПЁЃ

Бэ1 ЕЅзжЗћЪЖБ№в§ЧцадФмБШНЯ
3.ЮФзжааЪЖБ№СїГЬ
ДЋЭГOCRНЋЮФзжааЪЖБ№ЛЎЗжЮЊзжЗћЧаЗжКЭЕЅзжЗћЪЖБ№СНИіЖРСЂЕФВНжшЃЌОЁЙмЭЈЙ§бЕСЗЛљгкОэЛ§ЩёОЭјТчЕФЕЅзжЗћЪЖБ№в§ЧцПЩвдгааЇЬсЩ§зжЗћЪЖБ№ТЪЃЌЕЋЧаЗжЖдгкзжЗћеГСЌЁЂФЃК§КЭаЮБфЕФЧщПіЕФШнДэадНЯВюЃЌЖјЧвЧаЗжДэЮѓЖдгкЪЖБ№ЪЧВЛПЩаоИДЕФЁЃвђДЫдкИУПђМмЯТЃЌЮФБОааЪЖБ№ЕФзМШЗТЪжївЊЪмЯогкзжЗћЧаЗжЁЃМйЩшвббЕСЗЕЅзжЗћЪЖБ№в§ЧцЕФзМШЗТЪp=99%ЃЌзжЗћЧаЗжзМШЗТЪЮЊq=
95%ЃЌдђЖдгквЛЖЮГЄЖШЮЊLЕФЮФзжааЃЌЦфЪЖБ№ЕФЦНОљзМШЗТЪЮЊP= (pq)ЕФLДЮЗНЃЌЦфжаL=10ЪБЃЌP=54.1%ЁЃ
гЩгкЖРСЂгХЛЏзжЗћЧаЗжЬсЩ§ПеМфгаЯоЃЌвђДЫгаЯрЙиЗНЗЈЪдЭМСЊКЯгХЛЏЧаЗжКЭЪЖБ№СНИіШЮЮёЁЃЯжгаММЪѕжївЊПЩЗжЮЊЛљгкЧаЗжЕФЗНЗЈЃЈSegmentation-BasedЃЉКЭВЛвРРЕЧаЗжЕФЗНЗЈЃЈSegmentation-
FreeЃЉСНРрЗНЗЈЁЃ
ЛљгкЧаЗжЕФЗНЗЈ
ИУРрЗНЗЈЛЙЪЧБЃСєжїЖЏЧаЗжЕФВНжшЃЌЕЋв§ШыСЫЖЏЬЌКЯВЂЛњжЦЃЌЭЈЙ§ЪЖБ№жУаХЖШЕШаХЯЂРДжИЕМЧаЗжЃЌШчЭМ5ЫљЪОЁЃ
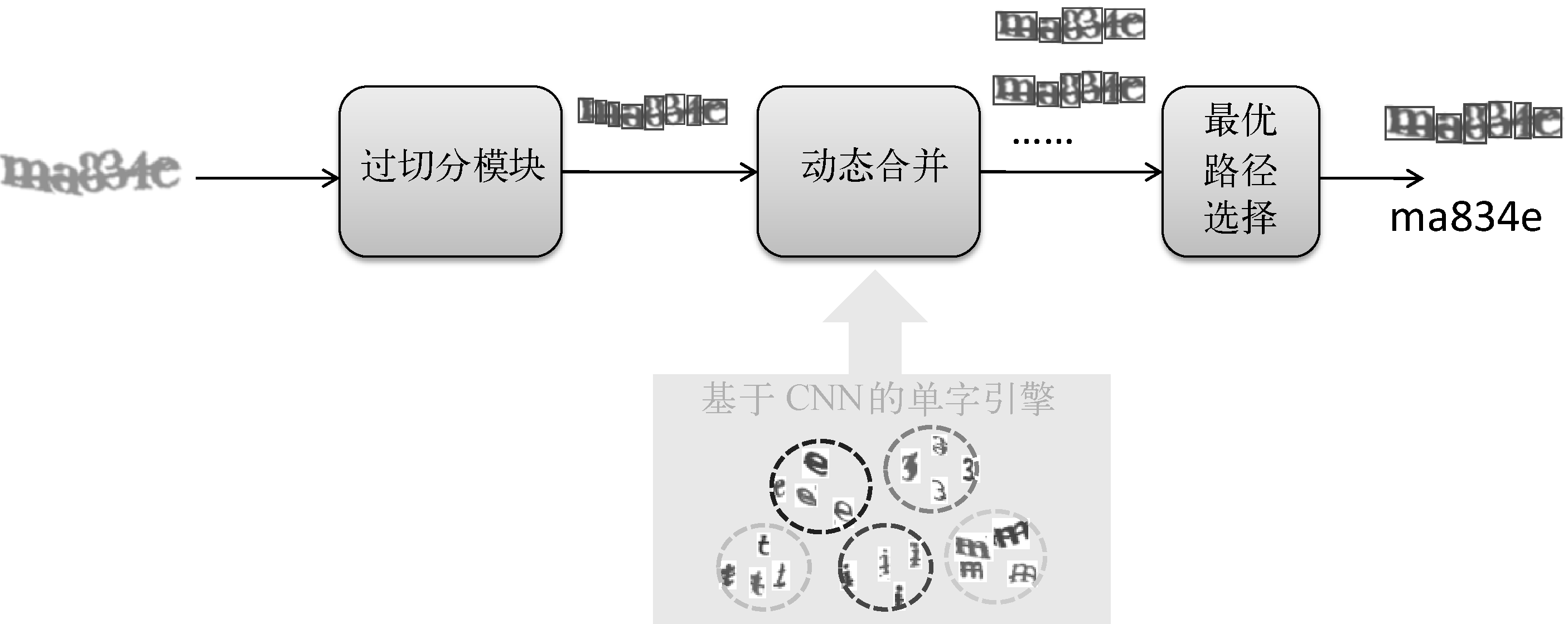
ЭМ5ЁЁЛљгкCNNЕФЖЏЬЌЧаЗжгыЪЖБ№СїГЬ
Й§ЧаЗжФЃПщНЋЮФзжаадкДЙжБгкЛљЯпЗНЯђЩЯЗжИюГЩЫщЦЌЃЌЪЙЕУЦфжаУПИіЫщЦЌжСЖрАќКЌвЛИізжЗћЁЃЭЈГЃРДЫЕЃЌЙ§ЧаЗжФЃПщЛсНЋзжЗћЗжИюЮЊЖрИіСЌајБЪЛЎЁЃЙ§ЧаЗжПЩвдВЩгУЛљгкЙцдђЛђЛњЦїбЇЯАЕФЗНЗЈЁЃЙцдђЗНЗЈжївЊЪЧжБНгдкЭМЯёЖўжЕЛЏЕФНсЙћЩЯНјааСЌЭЈгђЗжЮіКЭЭЖгАЗжЮіРДШЗЖЈКђВЙЧаЕуЮЛжУЃЌЭЈЙ§ЕїећВЮЪ§ПЩвдПижЦСЃЖШРДЪЙЕУзжЗћОЁПЩФмБЛЧаЫщЁЃЛљгкЙцдђЕФЗНЗЈЪЕЯжМђЕЅЃЌЕЋдкГЩЯё/БГОАИДдгЕФЬѕМўЯТЦфаЇЙћВЛКУЁЃЛњЦїбЇЯАЗНЗЈЭЈЙ§РыЯпбЕСЗМјБ№ЧаЕуЕФЖўРрЗжРрЦїЃЌШЛКѓЛљгкИУЗжРрЦїдкЮФзжааЭМЯёЩЯНјааЛЌДАМьВтЁЃ
ЖЏЬЌКЯВЂФЃПщНЋЯрСкЕФБЪЛЎИљОнЪЖБ№НсЙћзщКЯГЩПЩФмЕФзжЗћЧјгђЃЌзюгХзщКЯЗНЪНМДЖдгІзюМбЧаЗжТЗОЖКЭЪЖБ№НсЙћЁЃжБЙлРДПДЃЌбАевзюгХзщКЯЗНЪНПЩзЊЛЛЮЊТЗОЖЫбЫїЮЪЬтЃЌЖдгІгаЩюЖШгХЯШКЭЙуЖШгХЯШСНжжЫбЫїВпТдЁЃЩюЖШгХЯШВпТддкУПвЛВНбЁдёРЉеЙЕБЧАзюгХЕФзДЬЌЃЌвђДЫШЋОжРДПДЫќЪЧДЮгХВпТдЃЌВЛЪЪКЯЙ§ГЄЕФЮФзжааЁЃЙуЖШгХЯШВпТддкУПвЛВНЛсЖдЕБЧАЖрИізДЬЌЭЌЪБНјааРЉеЙЃЌБШШчдкгявєЪЖБ№СьгђЙуЗКгІгУЕФViterbiНтТыКЭBeam
SearchЁЃЕЋПМТЧЕНадФмЃЌBeam SearchЭЈГЃЛсв§ШыМєжІВйзїРДПижЦТЗОЖГЄЖШЃЌМєжІВпТдАќКЌЯожЦРЉеЙЕФзДЬЌЪ§ЃЈБШШчЃЌУПвЛВНжЛРЉеЙTopNЕФзДЬЌЃЉКЭМгШызДЬЌдМЪјЃЈБШШчЃЌКЯВЂКѓзжЗћаЮзДЃЉЕШЁЃ
гЩгкЖЏЬЌКЯВЂЛсВњЩњЖрИіКђбЁТЗОЖЃЌЫљвдашвЊЩшМЦКЯЪЪЕФЦРМлКЏЪ§РДНјааТЗОЖбЁдёЁЃЦРМлКЏЪ§ЕФЩшМЦжївЊДгТЗОЖНсЙЙЫ№ЪЇКЭТЗОЖЪЖБ№ДђЗжСНЗНУцГіЗЂЁЃТЗОЖНсЙЙЫ№ЪЇжївЊДгзжЗћаЮзДЬиеїЗНУцКтСПЧаЗжТЗОЖЕФКЯРэадЃЌТЗОЖЪЖБ№ДђЗждђЖдгІгкЬиЖЈЧаЗжТЗОЖЯТЕФЕЅзжЦНОљЪЖБ№жУаХЖШКЭгябдФЃаЭЗжЁЃ
ИУЗНАИЪдЭМНЋзжЗћЧаЗжКЭЕЅзжЗћЪЖБ№ШкКЯдкЭЌвЛИіПђМмЯТНтОіЃЌЕЋгЩгкЙ§ЗжИюЪЧЖРСЂЕФВНжшЃЌвђДЫУЛгаДгБОжЪЩЯЪЕЯжЖЫЕНЖЫбЇЯАЁЃ
ВЛвРРЕЧаЗжЕФЗНЗЈ
ИУРрЗНЗЈЭъШЋПчдНСЫзжЗћЧаЗжЃЌЭЈЙ§ЛЌЖЏДАПкЛђађСаНЈФЃжБНгЖдЮФзжааНјааЪЖБ№ЁЃ
ЛЌДАЪЖБ№НшМјСЫЛЌЖЏДАПкМьВтЕФЫМТЗЃЌЛљгкРыЯпбЕСЗЕФЕЅзжЪЖБ№в§ЧцЃЌЖдЮФзжааЭМЯёДгзѓЕНгвНјааЖрГпЖШЩЈУшЃЌвдЬиЖЈДАПкЮЊжааФНјааЪЖБ№ЁЃдкТЗОЖОіВпЩЯПЩВЩгУЬАаФВпТдЛђЗЧМЋДѓжЕвжжЦЃЈNMSЃЉВпТдРДЕУЕНзюжеЕФЪЖБ№ТЗОЖЁЃЭМ6ИјГіСЫЛЌДАЪЖБ№ЕФЪОвтСїГЬЁЃПЩМћЛЌДАЪЖБ№ДцдкСНИіЮЪЬтЃКЛЌЖЏВНГЄЕФСЃЖШЙ§ЯИдђМЦЫуДњМлДѓЃЌЙ§ДждђЩЯЯТЮФаХЯЂвзЖЊЪЇЃЛЮоТлВЩгУКЮжжТЗОЖОіВпЗНАИЃЌЫќУЧЖдЕЅзжЪЖБ№ЕФжУаХЖШвРРЕНЯИпЁЃ
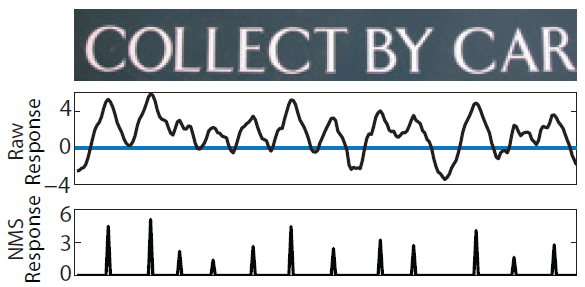
ЭМ6ЁЁЛљгкЛЌЖЏДАПкЕФЮФзжМьВт
ађСабЇЯАЦ№дДгкЪжаДЪЖБ№ЁЂгявєЪЖБ№СьгђЃЌвђЮЊетРрЮЪЬтЕФЙВЭЌЬиЕуЪЧашвЊЖдЪБађЪ§ОнНјааНЈФЃЁЃОЁЙмЮФзжааЭМЯёЪЧЖўЮЌЕФЃЌЕЋШчЙћАбДгзѓЕНгвЕФЩЈУшЖЏзїРрБШЮЊЪБађЃЌЮФзжааЪЖБ№ДгБОжЪЩЯвВПЩЙщЮЊетРрЮЪЬтЁЃЭЈЙ§ЖЫЕНЖЫЕФбЇЯАЃЌо№ЦњНУе§/ЧаЗж/зжЗћЪЖБ№ЕШжаМфВНжшЃЌвдДЫЬсЩ§ађСабЇЯАЕФаЇЙћЃЌетвбОГЩЮЊЕБЧАбаОПЕФШШЕуЁЃ
ЛљгкЯжгаММЪѕКЭУРЭХвЕЮёЩцМАЕФOCRГЁОАЃЌЮвУЧдкЮФзжМьВтКЭЮФзжааЪЖБ№ВЩгУШчЭМ7ЫљЪОЕФЩюЖШбЇЯАПђМмЁЃ
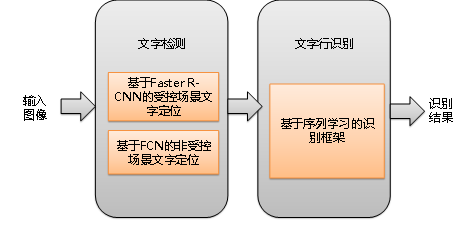
ЭМ7ЁЁЛљгкЩюЖШбЇЯАЕФOCRНтОіЗНАИ
КѓУцНЋЗжБ№НщЩмЮФзжМьВтКЭЮФзжааЪЖБ№етСНВПЗжЕФОпЬхЗНАИЁЃ
ЛљгкЩюЖШбЇЯАЕФЮФзжМьВт
ЖдгкУРЭХЕФOCRГЁОАЃЌИљОнАцУцЪЧЗёгаЯШбщаХЯЂЃЈПЈЦЌЕФОиаЮЧјгђЁЂжЄМўЕФЙиМќзжЖЮБъЪЖЃЉвдМАЮФзжздЩэЕФИДдгадЃЈШчЫЎЦНЮФзжЁЂЖрНЧЖШЃЉЃЌЭМЯёПЩЛЎЗжЮЊЪмПиГЁОАЃЈШчЩэЗнжЄЁЂгЊвЕжДееЁЂвјааПЈЃЉКЭЗЧЪмПиГЁОАЃЈШчВЫЕЅЁЂУХЭЗЭМЃЉЃЌШчЭМ8ЫљЪОЁЃ

ЭМ8ЁЁЪмПиГЁОАгыЗЧЪмПиГЁОА
ПМТЧЕНетСНРрГЁОАЕФЬиЕуВЛЭЌЃЌЮвУЧНшМјВЛЭЌЕФМьВтПђМмЁЃгЩгкЪмПиГЁОАЮФзжжюЖрдМЪјЬѕМўПЩНЋЮЪЬтМђЛЏЃЌвђДЫРћгУдкЭЈгУФПБъМьВтСьгђЙуЗКгІгУЕФFaster
R-CNNПђМмНјааМьВтЁЃЖјЖдгкЗЧЪмПиГЁОАЮФзжЃЌгЩгкаЮБфКЭБЪЛПэЖШВЛвЛжТЕШдвђЃЌФПБъТжРЊВЛОпБИСМКУЕФБеКЯБпНчЃЌЮвУЧашвЊНшжњЭМЯёгявхЗжИюРДБъМЧЮФзжЧјгђгыБГОАЧјгђЁЃ
1.ЪмПиГЁОАЕФЮФзжМьВт
ЖдгкЪмПиГЁОАЃЈШчЩэЗнжЄЃЉЃЌЮвУЧНЋЮФзжМьВтзЊЛЛЮЊЖдЙиМќзжФПБъЃЈШчаеУћЁЂЩэЗнжЄКХЁЂЕижЗЃЉЛђЙиМќЬѕФПЃЈШчвјааПЈКХЃЉЕФМьВтЮЪЬтЁЃЛљгкFaster
R-CNNЕФЙиМќзжМьВтСїГЬШчЭМ9ЫљЪОЁЃЮЊСЫБЃжЄЛиЙщПђЕФЖЈЮЛОЋЖШЃЌЭЌЪБЬсЩ§дЫЫуЫйЖШЃЌЮвУЧЖддгаПђМмКЭбЕСЗЗНЪННјааСЫЮЂЕїЁЃ
ПМТЧЕНЙиМќзжЛђЙиМќЬѕФПЕФРрФкБфЛЏгаЯоЃЌЭјТчНсЙЙжЛВЩгУСЫ3ИіОэЛ§ВуЁЃ
бЕСЗЙ§ГЬжаЬсИпе§бљБОЕФжиЕўТЪуажЕЁЃ
ИљОнЙиМќзжЛђЙиМќЬѕФПЕФПэИпБШЗЖЮЇРДЪЪХфRPNВуAnchorЕФПэИпБШЁЃ
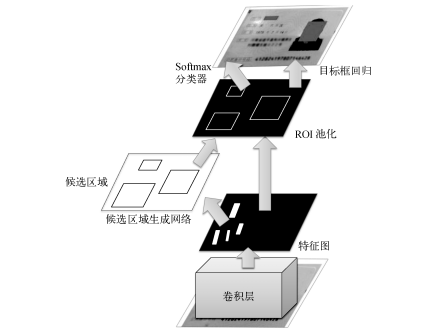
ЭМ9 ЛљгкFaster R-CNNЕФOCRНтОіЗНАИ
Faster R-CNNПђМмгЩRPNЃЈКђбЁЧјгђЩњГЩЭјТчЃЉКЭRCNЃЈЧјгђЗжРрЭјТчЃЉСНИізгЭјТчзщГЩЁЃRPNЭЈЙ§МрЖНбЇЯАЕФЗНЗЈЬсШЁКђбЁЧјгђЃЌИјГіЕФЪЧЮоБъЧЉЕФЧјгђКЭДжЖЈЮЛНсЙћЁЃRCNв§ШыРрБ№ИХФюЃЌЭЌЪБНјааКђбЁЧјгђЕФЗжРрКЭЮЛжУЛиЙщЃЌИјГіОЋЯИЖЈЮЛНсЙћЁЃбЕСЗЪБСНИізгЭјТчЭЈЙ§ЖЫЕНЖЫЕФЗНЪНСЊКЯгХЛЏЁЃЭМ10вдвјааПЈПЈКХЪЖБ№ЮЊР§ЃЌИјГіСЫRPNВуКЭRCNВуЕФЪфГіЁЃ

ЭМ10 ЛљгкFaster R-CNNЕФвјааПЈПЈКХМьВт
ЖдгкШЫЪжГжжЄМўГЁОАЃЌгЩгкжЄМўФПБъдкЭМЯёжаЫљеМБШР§Й§аЁЃЌжБНгЬсШЁЮЂаЁКђбЁФПБъЛсЕМжТвЛЖЈЕФЖЈЮЛОЋЖШЫ№ЪЇЁЃЮЊСЫБЃжЄИпейЛиКЭИпЖЈЮЛОЋЖШЃЌПЩВЩгУгЩДжЕНОЋЕФВпТдНјааМьВтЁЃЪзЯШЖЈЮЛПЈЦЌЫљдкЧјгђЮЛжУЃЌШЛКѓдкПЈЦЌЧјгђЗЖЮЇФкНјааЙиМќзжМьВтЃЌЖјЧјгђЖЈЮЛвВПЩВЩгУFaster
R-CNNПђМмЃЌШчЭМ11ЫљЪОЁЃ
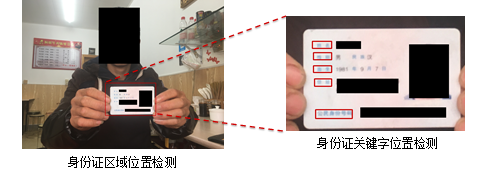
ЭМ11 гЩДжЕНОЋЕФМьВтВпТд
ЗЧЪмПиГЁОАЕФЮФзжМьВт
ЖдгкВЫЕЅЁЂУХЭЗЭМЕШЗЧЪмПиГЁОАЃЌгЩгкЮФзжааБОЩэЕФЖрНЧЖШЧвзжЗћЕФБЪЛПэЖШБфЛЏДѓЃЌИУГЁОАЯТЕФЮФзжааЖЈЮЛШЮЮёЬєеНКмДѓЁЃгЩгкЭЈгУФПБъМьВтЗНЗЈЕФЖЈЮЛСЃЖШЪЧЛиЙщПђМЖЃЌДЫЗНЗЈЪЪгУгкИеЬхетРргаСМКУБеКЯБпНчЕФЮяЬхЁЃШЛЖјЮФзжЭљЭљгЩвЛЯЕСаЫЩЩЂЕФБЪЛЙЙГЩЃЌгШЦфЖдгкШЮвтЗНЯђЛђБЪЛПэЖШЕФЮФзжЃЌНівдЛиЙщПђНсЙћзїЮЊЖЈЮЛНсЙћЛсгаНЯДѓЦЋВюЁЃСэЭтИеЬхМьВтЕФвЊЧѓЯрЖдНЯЕЭЃЌМДБужЛЖЈЮЛЕНВПЗжжїЬхЃЈШчЖЈЮЛНсЙћгыецжЕЕФжиЕўТЪЪЧ50%ЃЉЃЌвВВЛЛсЖдИеЬхЪЖБ№ВњЩњжиДѓгАЯьЃЌЖјетбљЕФЖЈЮЛЮѓВюЖдгкЮФзжЪЖБ№дђКмПЩФмЪЧжТУќЕФЁЃ
ЮЊСЫЪЕЯжзуЙЛОЋЯИЕФЖЈЮЛЃЌЮвУЧРћгУгявхЗжИюжаГЃгУЕФШЋОэЛ§ЭјТчЃЈFCNЃЉРДНјааЯёЫиМЖБ№ЕФЮФзж/БГОАБъзЂЃЌећЬхСїГЬШчЭМ12ЫљЪОЁЃ
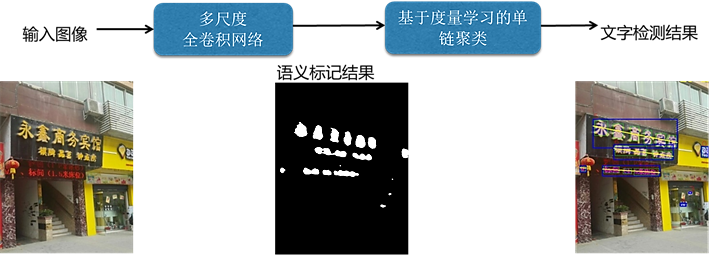
ЭМ12 ЛљгкШЋОэЛ§ЭјТчЕФЮФзжМьВт
ЖрГпЖШШЋОэЛ§ЭјТчЭЈЙ§ЖдЖрИіНзЖЮЕФЗДОэЛ§НсЙћЕФШкКЯЃЌЪЕЯжСЫШЋОжЬиеїКЭОжВПЬиеїЕФСЊКЯЃЌНјЖјДяЕНСЫгЩДжЕНОЋЕФЯёЫиМЖБ№БъзЂЃЌЪЪгІгкШЮвтЗЧЪмПиГЁОАЃЈУХЭЗЭМЁЂВЫЕЅЭМЦЌЃЉЁЃ
ЛљгкЖрГпЖШШЋОэЛ§ЭјТчЕУЕНЕФЯёЫиМЖБъзЂЃЌЭЈЙ§СЌЭЈгђЗжЮіММЪѕПЩЕУЕНвЛЯЕСаСЌЭЈЧјгђЃЈБЪЛЎаХЯЂЃЉЁЃЕЋгЩгкЮоЗЈШЗЖЈФФаЉСЌЭЈгђЪєгкЭЌвЛЮФзжааЃЌвђДЫашвЊНшжњЕЅСДОлРрММЪѕРДНјааЮФзжааЬсШЁЁЃжСгкОлРрЩцМАЕФОрРыЖШСПЃЌжївЊДгСЌЭЈгђМфЕФОрРыЁЂаЮзДЁЂбеЩЋЕФЯрЫЦЖШЕШЗНУцЬсШЁЬиеїЃЌВЂЭЈЙ§ЖШСПбЇЯАздЪЪгІЕиЕУЕНЬиеїШЈжиКЭуажЕЃЌШчЭМ13ЫљЪОЁЃ
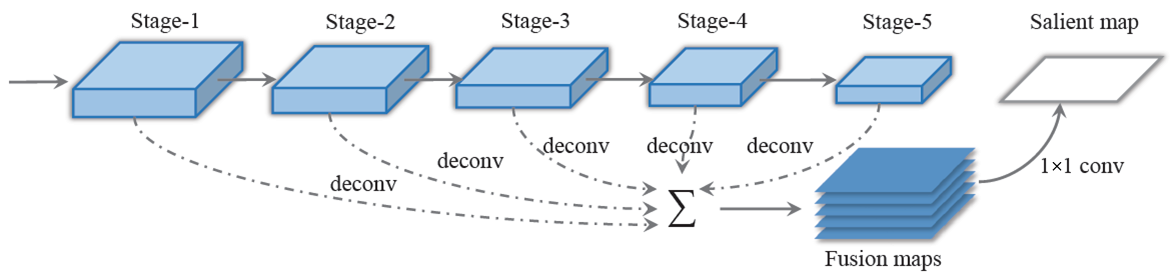
ЭМ13 ЛљгкШЋОэЛ§ЭјТчЕФЭМЯёгявхЗжИю
ЭМ14ЗжБ№ИјГіСЫдкВЫЕЅКЭУХЭЗЭМГЁОАжаЕФШЋОэЛ§ЭјТчЖЈЮЛаЇЙћЁЃЕкЖўСаЮЊШЋОэЛ§ЭјТчЕФЯёЫиМЖБъзЂНсЙћЃЌЕкШ§СаЮЊзюжеЮФзжМьВтНсЙћЁЃПЩвдПДГіЃЌШЋОэЛ§ЭјТчПЩвдНЯКУЕигІЖдИДдгАцУцЛђЖрНЧЖШЮФзжЖЈЮЛЁЃ

ЭМ14 ЛљгкFCNЕФЮФзжЖЈЮЛНсЙћ
ЛљгкађСабЇЯАЕФЮФзжЪЖБ№
ЮвУЧНЋећааЮФзжЪЖБ№ЮЪЬтЙщНсЮЊвЛИіађСабЇЯАЮЪЬтЁЃРћгУЛљгкЫЋЯђГЄЖЬЦкМЧвфЩёОЭјТчЃЈBi-directional
Long Short-term MemoryЃЌBLSTMЃЉЕФЕнЙщЩёОЭјТчзїЮЊађСабЇЯАЦїЃЌРДгааЇНЈФЃађСаФкВПЙиЯЕЁЃЮЊСЫв§ШыИќгааЇЕФЪфШыЬиеїЃЌЮвУЧВЩгУОэЛ§ЩёОЭјТчФЃаЭРДНјааЬиеїЬсШЁЃЌвдУшЪіЭМЯёЕФИпВугявхЁЃДЫЭтдкЫ№ЪЇКЏЪ§ЕФЩшМЦЗНУцЃЌПМТЧЕНЪфГіађСагыЪфШыЬиеїжЁађСаЮоЗЈЖдЦыЃЌЮвУЧжБНгЪЙгУНсЙЙЛЏЕФLossЃЈађСаЖдађСаЕФЫ№ЪЇЃЉЃЌСэЭтв§ШыСЫБГОАЃЈBlankЃЉРрБ№вдЮќЪеЯрСкзжЗћЕФЛьЯ§адЁЃ
ећЬхЭјТчНсЙЙЗжЮЊШ§ВуЃКОэЛ§ВуЁЂЕнЙщВуКЭЗвыВуЃЌШчЭМ15ЫљЪОЁЃЦфжаОэЛ§ВуЬсШЁЬиеїЃЛЕнЙщВуМШбЇЯАЬиеїађСажазжЗћЬиеїЕФЯШКѓЙиЯЕЃЌгжбЇЯАзжЗћЕФЯШКѓЙиЯЕЃЛЗвыВуЪЕЯжЖдЪБМфађСаЗжРрНсЙћЕФНтТыЁЃ
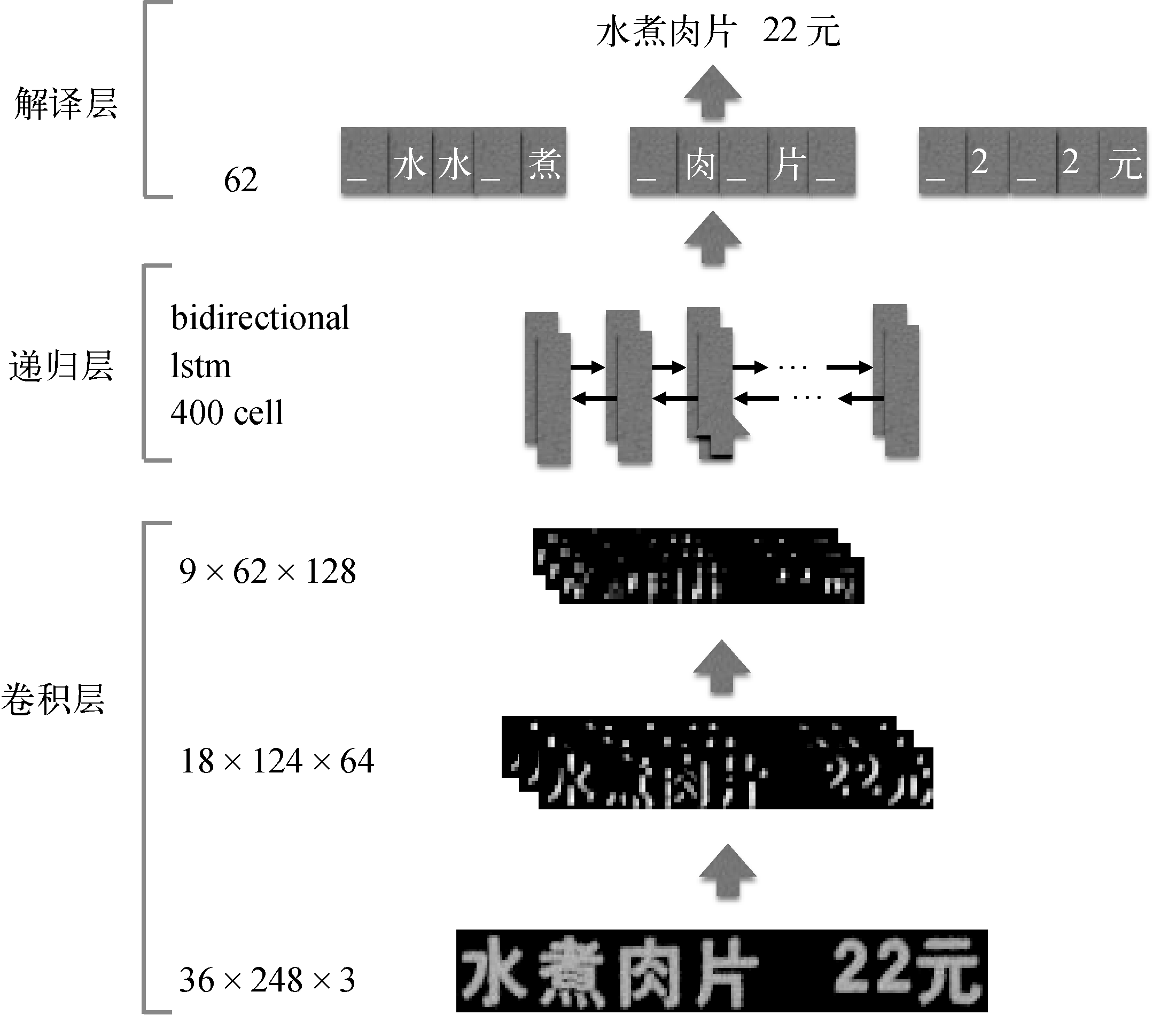
ЭМ15 ЛљгкађСабЇЯАЕФЖЫЕНЖЫЪЖБ№ПђМм
ЖдгкЪфШыЕФЙЬЖЈИпЖШh0= 36ЕФЭМЯёЃЈПэЖШШЮвтЃЌШчW0 = 248ЃЉЃЌЮвУЧЭЈЙ§CNNЭјТчНсЙЙЬсШЁЬиеїЃЌЕУЕН9ЁС62ЁС128ЕФЬиеїЭМЃЌПЩНЋЦфПДзївЛИіГЄЖШЮЊ62ЕФЪБМфађСаЪфШыЕНRNNВуЁЃRNNВуга400ИівўВиНкЕуЃЌЦфжаУПИівўВиНкЕуЕФЪфШыЪЧ9ЁС128ЮЌЕФЬиеїЃЌЪЧЖдЭМЯёОжВПЧјгђЕФУшЪіЁЃПМТЧЕНЖдгІгкФГИіЪБПЬЬиеїЕФЭМЯёЧјгђЃЌЫќгыЦфЧАКѓФкШнЖМОпгаНЯЧПЕФЯрЙиадЃЌЫљвдЮвУЧвЛАуВЩгУЫЋЯђRNNЭјТчЃЌШчЭМ16ЫљЪОЁЃ
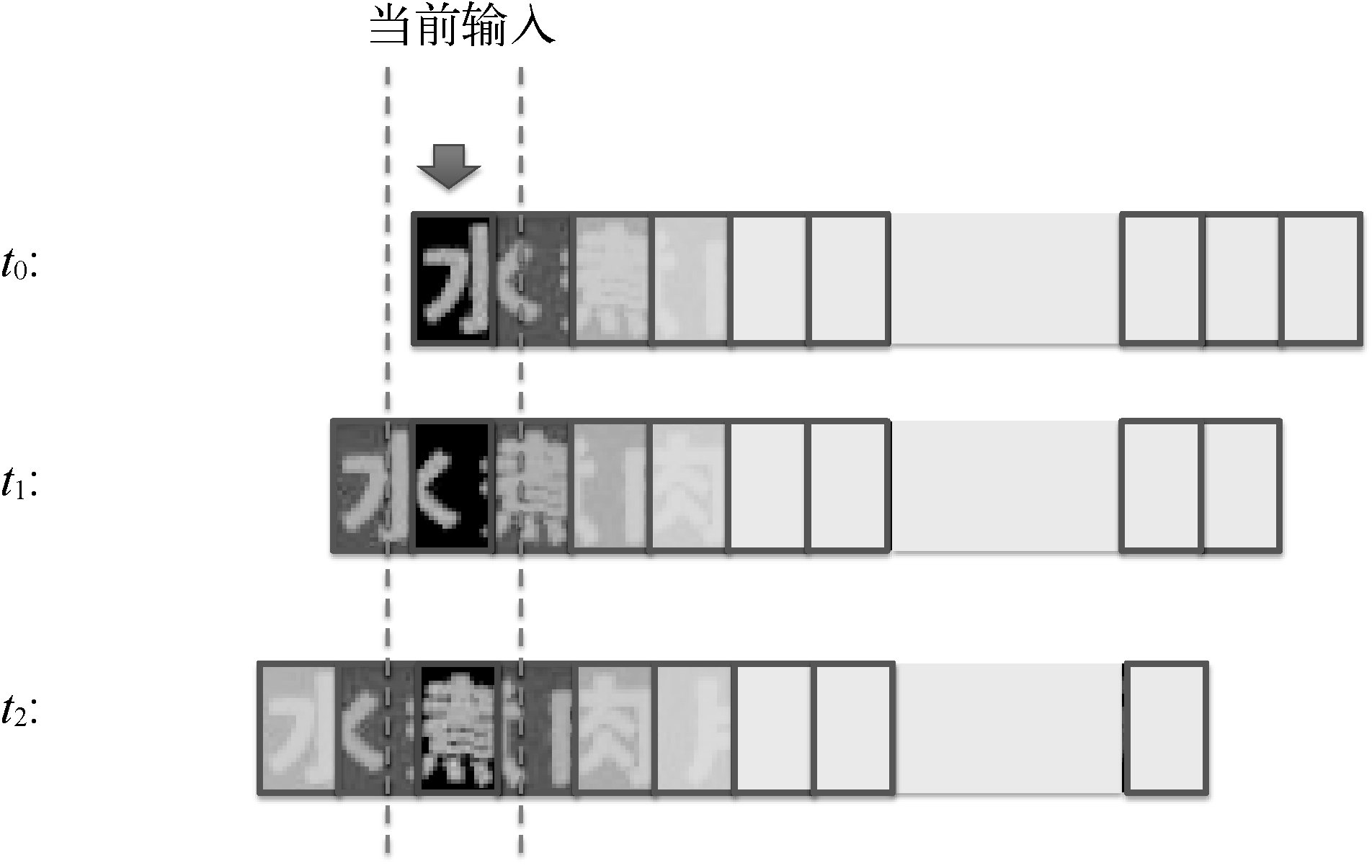
ЭМ16 ЫЋЯђRNNађСа
ЫЋЯђRNNКѓНгвЛИіШЋСЌНгВуЃЌЪфШыЮЊRNNВуЃЈдкФГИіЪБПЬЃЉЪфГіЕФЬиеїЭМЃЌЪфГіЮЊИУЮЛжУЪЧБГОАЁЂзжЗћБэжаЮФзжЕФИХТЪЁЃШЋСЌНгВуКѓНгCTCЃЈСЊНсжївхЪБМфЗжРрЦїЃЉзїЮЊЫ№ЪЇКЏЪ§ЁЃдкбЕСЗЪБЃЌИљОнУПИіЪБПЬЖдгІЕФЮФзжЁЂБГОАИХТЪЗжВМЃЌЕУЕНецжЕзжЗћДЎдкЭМЯёжаГіЯжЕФИХТЪP(ground
truth)ЃЌНЋ-log(P(ground truth))зїЮЊЫ№ЪЇКЏЪ§ЁЃдкВтЪдЪБЃЌCTCПЩвдПДзївЛИіНтТыЦїЃЌНЋУПвЛЪБПЬЕФдЄВтНсЙћЃЈЕБЧАЪБПЬЕФзюДѓКѓбщИХТЪЖдгІЕФзжЗћЃЉСЊКЯЦ№РДЃЌШЛКѓШЅЕєПеАзКЭжиИДЕФФЃЪНЃЌОЭаЮГЩСЫзюжеЕФађСадЄВтНсЙћЃЌШчЭМ17ЫљЪОЁЃ
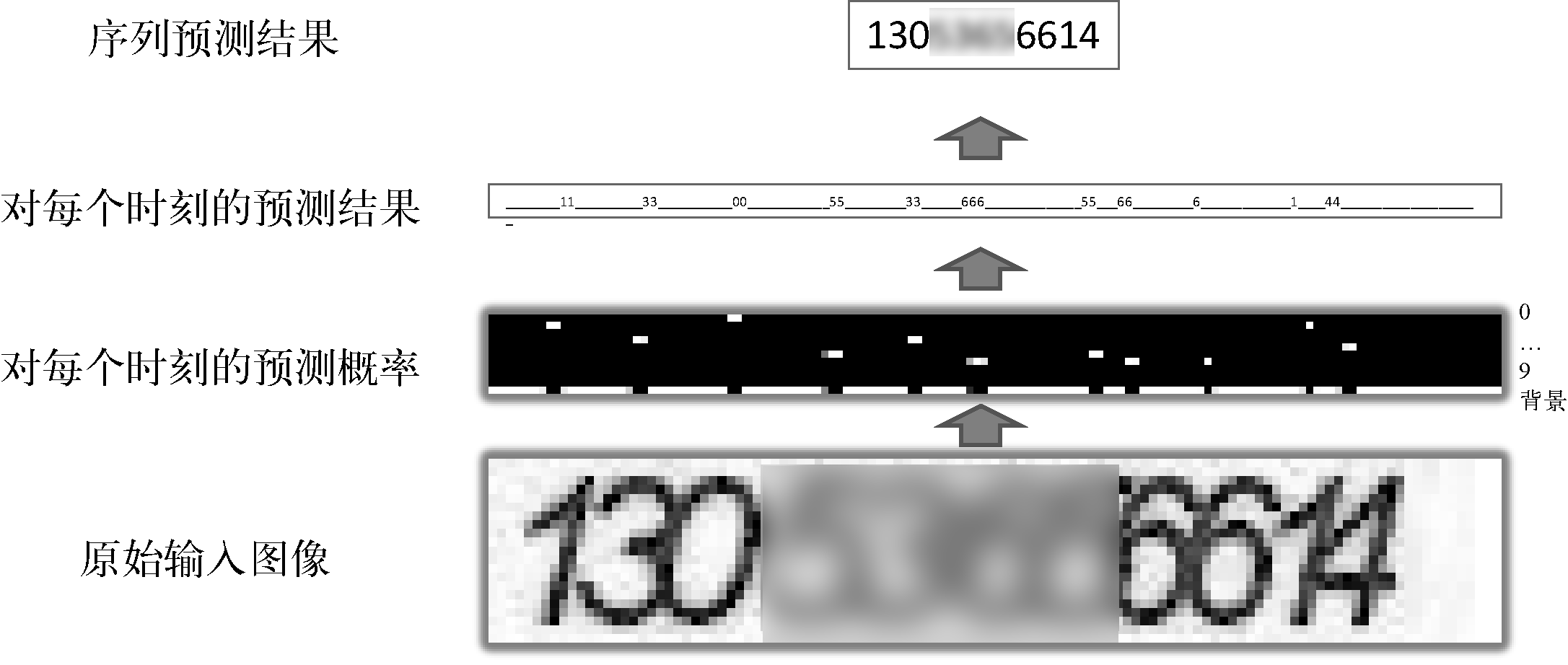
ЭМ17 CTCНтТыЙ§ГЬ
ДгЭМ17жавВПЩвдПДГіЃЌЖдгІЪфШыађСажаЕФУПИізжЗћЃЌLSTMЪфГіВуЖМЛсВњЩњУїЯдЕФМтЗхЃЌОЁЙмИУМтЗхЮДБиЖдгІзжЗћЕФжааФЮЛжУЁЃЛЛОфЛАЫЕЃЌв§ШыCTCЛњжЦКѓЃЌЮвУЧВЛашвЊПМТЧУПИізжЗћГіЯжЕФОпЬхЮЛжУЃЌжЛашЙизЂећИіЭМЯёађСаЖдгІЕФЮФзжФкШнЃЌзюжеЪЕЯжЩюЖШбЇЯАЕФЖЫЕНЖЫбЕСЗгыдЄВтЁЃ
гЩгкађСабЇЯАПђМмЖдбЕСЗбљБОЕФЪ§СПКЭЗжВМвЊЧѓНЯИпЃЌЮвУЧВЩгУСЫецЪЕбљБО+КЯГЩбљБОЕФЗНЪНЁЃецЪЕбљБОвдУРЭХвЕЮёРДдДЃЈР§ШчЃЌВЫЕЅЁЂЩэЗнжЄЁЂгЊвЕжДееЃЉЮЊжїЃЌКЯГЩбљБОдђПМТЧСЫзжЬхЁЂаЮБфЁЂФЃК§ЁЂдыЩљЁЂБГОАЕШвђЫиЁЃ
ЛљгкЩЯЪіађСабЇЯАПђМмЃЌЮвУЧИјГіСЫдкВЛЭЌГЁОАЯТЕФЮФзжааЪЖБ№НсЙћЃЌШчЭМ18ЫљЪОЁЃЦфжаЧАСНааЕФЭМЦЌЮЊбщжЄТыГЁОАЃЌЕкШ§ааЮЊвјааПЈЃЌЕкЫФааЮЊзЪжЪжЄМўЃЌЕкЮхааЮЊУХЭЗЭМЃЌЕкСљааЮЊВЫЕЅЁЃПЩвдПДЕНЃЌЪЖБ№ФЃаЭЖдгкЮФзжаЮБфЁЂеГСЌЁЂГЩЯёЕФФЃК§КЭЙтЯпБфЛЏЁЂБГОАЕФИДдгЕШЖМгаНЯКУЕФНЁзГадЁЃ

ЭМ18 ЮФзжааЪЖБ№НсЙћ
ЛљгкЩЯЪіЪдбщЃЌгыДЋЭГOCRЯрБШЃЌЮвУЧдкЖржжГЁОАЕФЮФзжЪЖБ№ЩЯЖМгаНЯДѓЗљЖШЕФадФмЬсЩ§ЃЌШчЭМ19ЫљЪОЁЃ
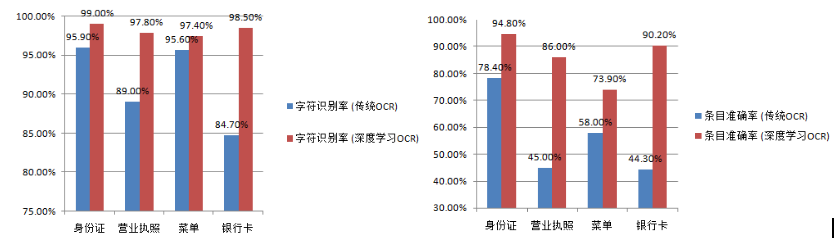
ЭМ19 ДЋЭГOCRКЭЩюЖШбЇЯАOCRадФмБШНЯ
гыДЋЭГOCRЯрБШЃЌЛљгкЩюЖШбЇЯАЕФOCRдкЪЖБ№ТЪЗНУцгаСЫДѓЗљЩЯЩ§ЁЃЕЋЖдгкЬиЖЈЕФгІгУГЁОАЃЈгЊвЕжДееЁЂВЫЕЅЁЂвјааПЈЕШЃЉЃЌЬѕФПзМШЗТЪЛЙгаД§ЬсЩ§ЁЃвЛЗНУцашвЊШкКЯЛљгкЩюЖШбЇЯАЕФЮФзжМьВтгыДЋЭГАцУцЗжЮіММЪѕЃЌвдНјвЛВНЬсЩ§ЯожЦГЁОАЯТЕФМьВтадФмЁЃСэвЛЗНУцашвЊЗсИЛецЪЕбЕСЗбљБОКЭгябдФЃаЭЃЌвдЬсЩ§ЮФзжЪЖБ№зМШЗТЪЁЃ |





