| 编辑推荐: |
本文来自于cnblogs,文章详细介绍了Deep
Learning、Tensorflow模型建模与训练以及TensorflowOnSpark的案例实践等相关知识。
|
|
近年来,机器学习和深度学习不断被炒热,tensorflow 作为谷歌发布的数值计算和神经网络的新框架也获得了诸多关注,spark和tensorflow深度学习框架的结合,使得tensorflow在现有的spark集群上就可以进行深度学习,而不需要为深度学习设置单独的集群,为了深入了解spark遇上tensorflow分布式深度学习框架的原理和实践,主要内容介绍spark和深度学习的基本原理、spark与深度学习领域相结合的最新的发展方向,以及如何结合tensorflowonspark开源框架,构建一个分布式图像分类模型训练。
以下是本次分享实录:

上面这张图片显示的是本次直播所针对的受众和可能的收益,大家可以了解一下。
一.大数据的价值
什么是大数据的价值呢?李老师根据自身以往的项目经验和互联网主流的大数据应用场景,大致总结了以下三种价值。

二.计算的核心问题
结合上面所说的大数据的价值和应用场景,我们把它归纳为一条计算流:首先从数据存储当中经过数据加工、抽取,得到提炼后的数据、特征,然后进行进一步的模型训练,得到模型。
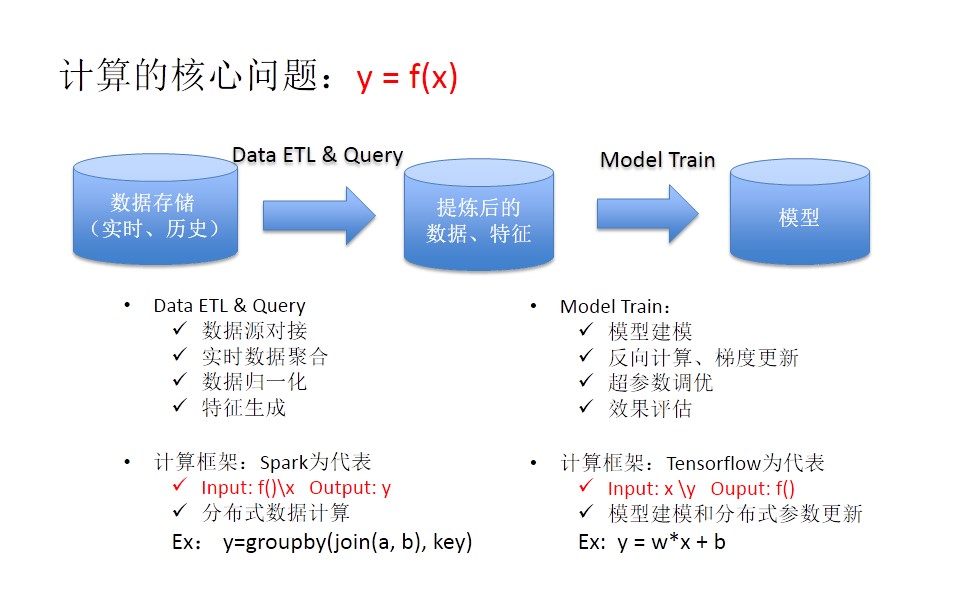
这条计算流的核心问题可以归纳为y=f(x)这个函数。对于第一阶段的数据ETL和查询来讲,主要解决的是数据源对接、实时数据整合、数据归一化、特征生成等应用场景,它的计算框架代表是spark,输入是f()\x,输出是y,非常适合做分布式数据计算。第二阶段的模型训练,主要有模型建模、反向计算、梯度更新、超参数调优、效果评估等流程,它的计算框架代表是tensorflow,输入是x\y,输出是f(),更多关注的是模型建模和分布式参数更新。
接下来,我们就针对以上两个框架做一些基本原理的介绍和概述。
三.spark概述
1.spark的核心抽象:RDD
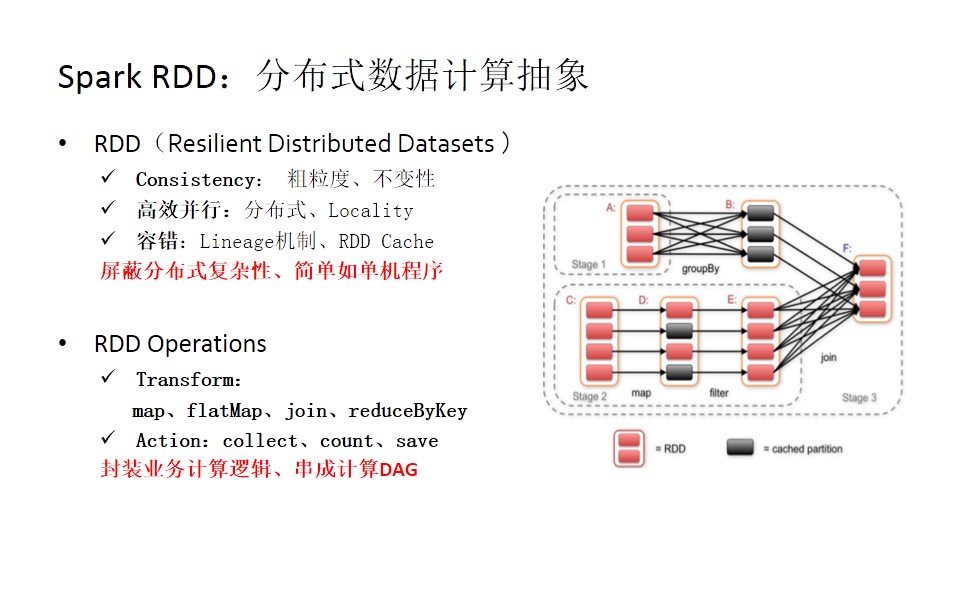
为什么要做RDD这样的抽象呢?主要是因为它的一致性、高效并行、容错机制,RDD屏蔽了分布式的复杂性,使开发程序时简单如写单机程序。
RDD也提供了一些操作,如transform和action,通过对RDD操作业务的封装以及计算逻辑,我们就会形成一个大的DAG计算图(参考下图右)。
2.spark的大数据生态:
这部分是讲spark的数据生态,包括它支持的组件库、部署环境和数据来源。

3.Spark SQL和Spark Streaming:
我们简要介绍一下这两个比较重要的组件,首先是spark sql,它的典型应用场景是OLAP多维分析,它提供了一个DataFrame抽象接口,等价于RDD,如下图所示。

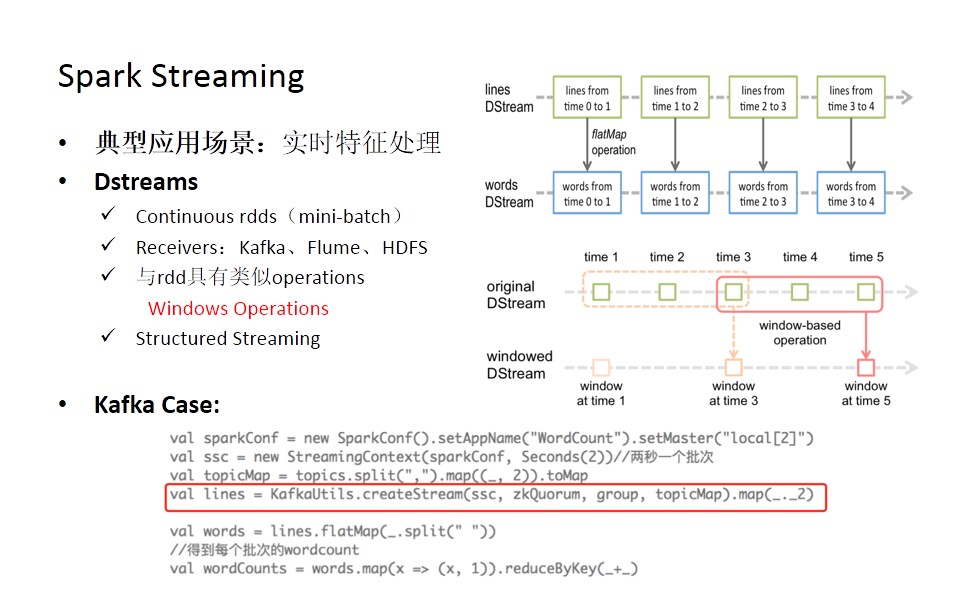
Spark Streaming是spark的一个实时处理组件,它的典型应用场景是实时特征处理,它提供了一个Dstreams抽象接口,直观上理解Dstreams就是一个持续的RDD,如下图。
四.Deep Learning概述
下面,我们一起来了解关于Deep Learning的相关内容。
1.Deep Learning模型:
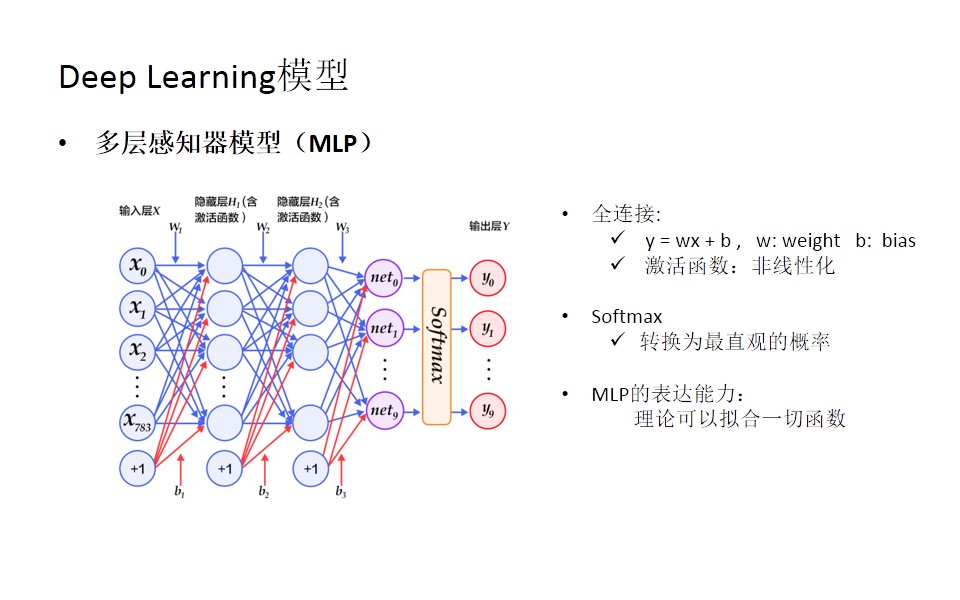
第一个模型是非常经典的多层感知器模型(MLP)。首次这个模型有一个输入层,在输入层后面有两个隐藏层,最后是输出层。这个模型的特点是全连接,在最后输出之前有一个Softmax函数,它的作用是把最终的权值转换为最直观的概率。理论上来讲,MLP这种带有隐藏层的神经网络可以拟合一切的函数,但它的计算量很大,所以传统的MLP模型并不适合去更深层次地加深网络结构。
真正把神经网络推向更深层次网络结构模型的是CNN卷积神经网络,它通常应用在图像分类等领域,这里有一个概念—感受野,所谓感受野就是空间局部性的考虑,它认为图像上比较接近的图像领域具有更强的相关性,图像上更远的像素之间相关性更弱,基于感受野的考虑,它把全连接层替换为卷积操作。
卷积操作的特点是可以将局部特征抽象化,另外大幅减少计算量,以便加深神经网络,丰富语义表达。
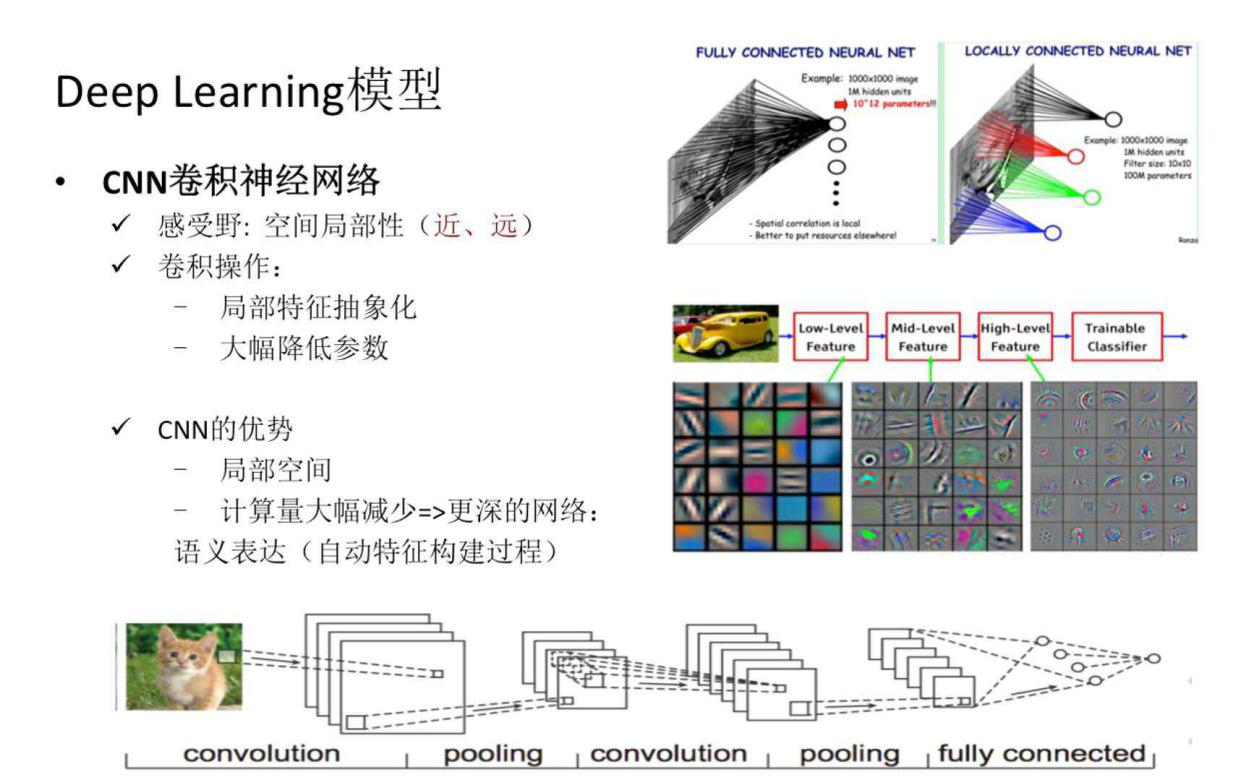
2.Tensorflow模型建模与训练:
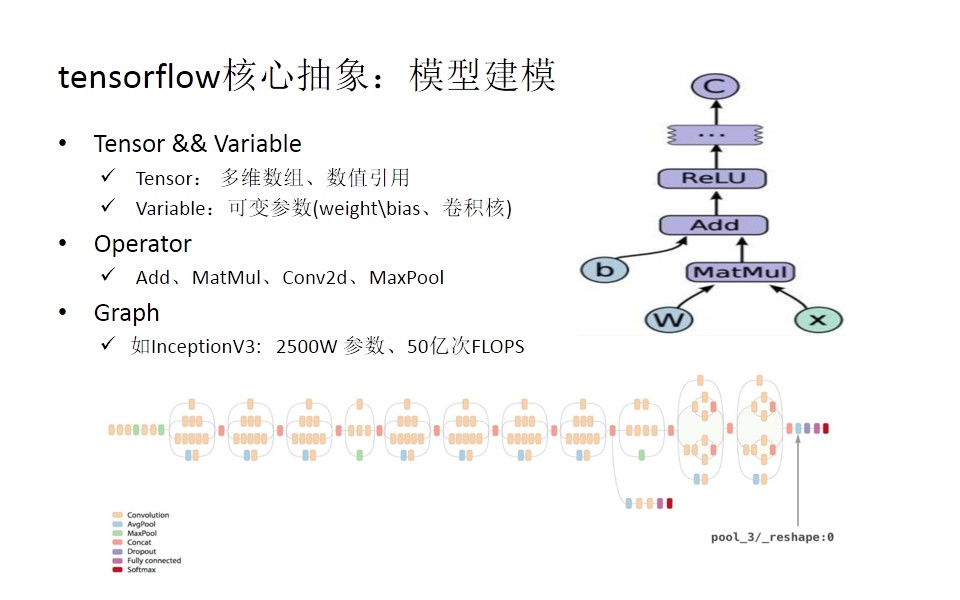
介绍完深度学习模型后,回到我们的tensorflow部分,首先我们了解一下tensorflow是怎样来做模型建模的。如下图所示,X是Tensor,W和b是Variable,Matmul、Add、ReLU都是Operator,最后组成一个神经网络图Graph。
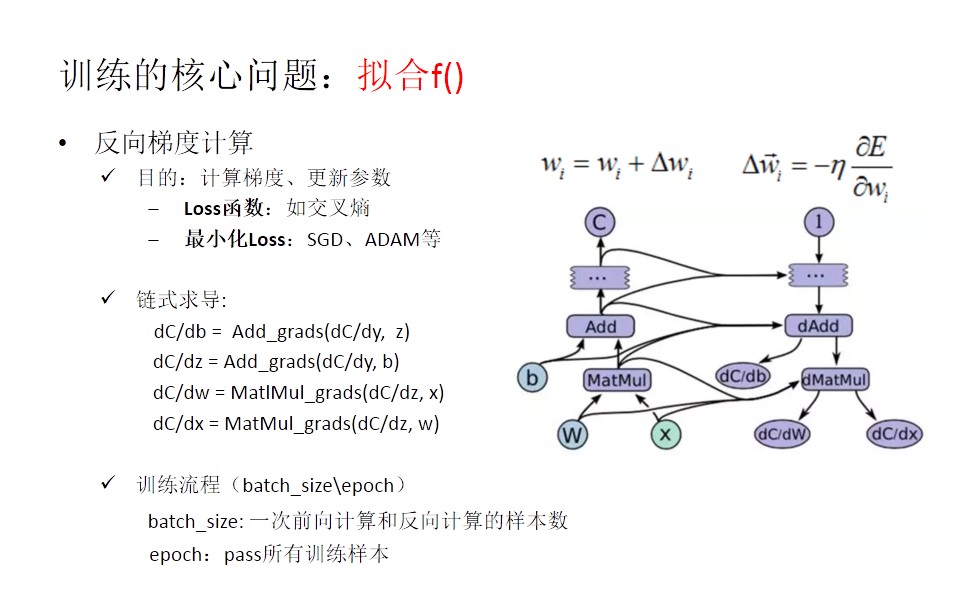
其次,我们来了解一下tensorflow训练的核心问题—拟合f(),主要通过反向梯度计算来拟合f(),反向梯度计算的目的是计算梯度和更新参数,这里涉及到Loss函数和最小化Loss。那么怎么去计算梯度呢?主要通过链式求导(看下图右)。一次链式求导只是一次的前向和后向的计算结果,在训练流程当中,我们通常批量计算,所以会涉及batch_size和epoch。
最后我们结合一个代码事例,回顾一下前面所讲的知识点:

我们以多层感知器模型MLP为例,首先需要创建一个模型,模型定义就是两个隐藏层加最后的输出层,定义好模型之后,我们需要定义损失函数,在这里它是对你的标签和预测输出进行的交叉熵的损失定义,然后选择一个optimizer的优化器来做优化训练,
在训练开始之前,你需要去调一个sess.run(init)对权值做一个随机初始化的过程,初始化之后,进入到我们的训练阶段。
3.Tensorflow分布式训练机制:
刚才介绍的是tensorflow怎么去定义模型以及怎么去做反向计算,那么,在大规模数据场景下,它又是怎样工作的?
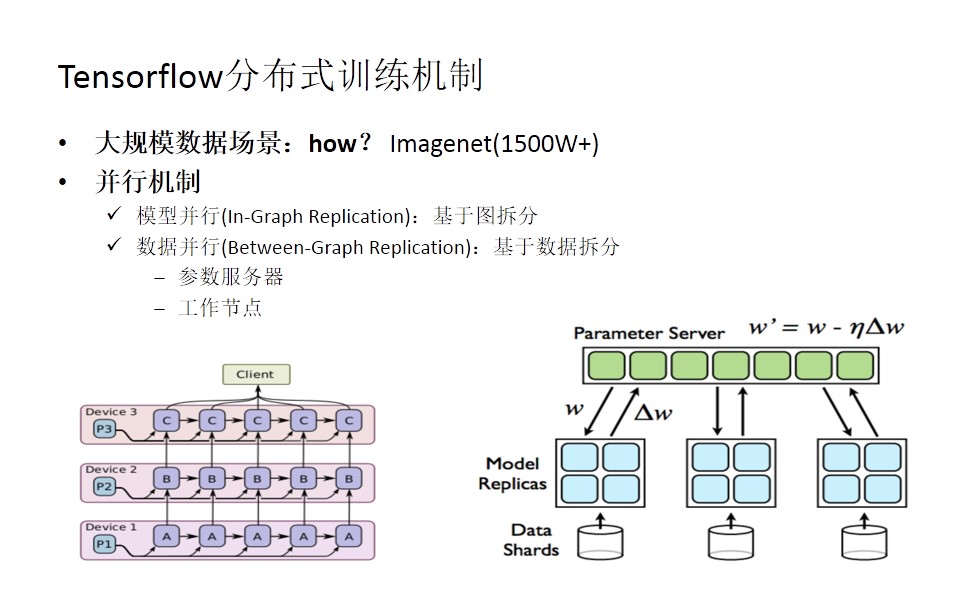
Tensorflow本身提供了一些并行机制,第一个是模型并行机制,就是基于图去拆分(如上图左下),它会把一张大的图拆分成很多部分,每个部分都会在很多设备上去运行、计算。通常是针对一个节点无法存下整个模型的情况下,去对图进行拆分。
更多场景下我们的数据量会比较大,这时候就采用数据并行机制,在这种机制下tensorflow有两个角色,一个是参数服务器,负责参数的存储和交换更新,一个是工作节点,负责具体的模型计算。每个工作节点会负责它领域内的数据分片所对应模型参数的更新计算,同时它们又会向参数服务器去传递它所计算的梯度,由参数服务器来汇总所有的梯度,再进一步反馈到所有节点,根据参数服务器合并参数的方式又分为同步更新和异步更新,这两种更新方式各有优缺点,异步更新可能会更快速地完成整个梯度计算,而对于同步更新来讲,它可以更快地进行一个收敛,选择哪种方式取决于实际的应用场景。
五.Deep Learning On Spark
经过刚才的介绍,我们知道spark是一个分布式的通用计算框架,而以tensorflow为代表的deep
learning是一个分布式模型训练框架,它更多专注在梯度计算,那为什么要将两者整合呢?整合的意义在哪里?意义就是能实现更好的分布式训练和数据传输。

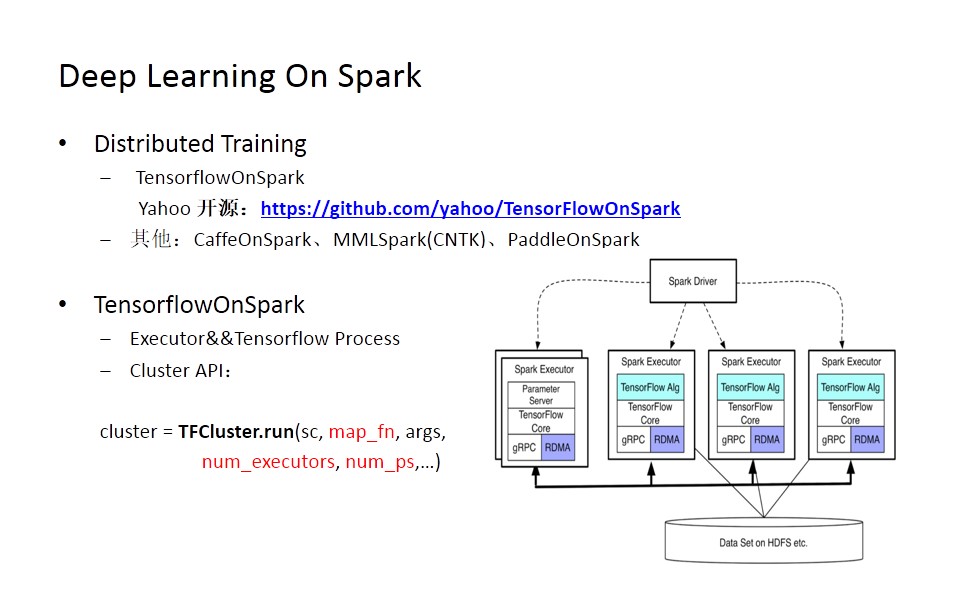
针对分布式训练的场景,雅虎开源了TensorflowOnSpark的开源框架,它主要实现tensorflow能够与spark相结合做分布式训练。同时也有其它的一些机制,例如,CaffeOnSpark、MMLSpark(CNTK)、PaddleOnSpark。
TensorflowOnSpark解决的核心问题是将spark作为分布式tensorflow的底层调动机制,通过spark
executor去把tensorflow的进程调动起来,这样在进行tensorflow训练时就不需要手动地去组建网络。它也提供了一个API,通过调TFCluster.run这样一个API,可以快速获得tensorflow的一个分布式训练环境。
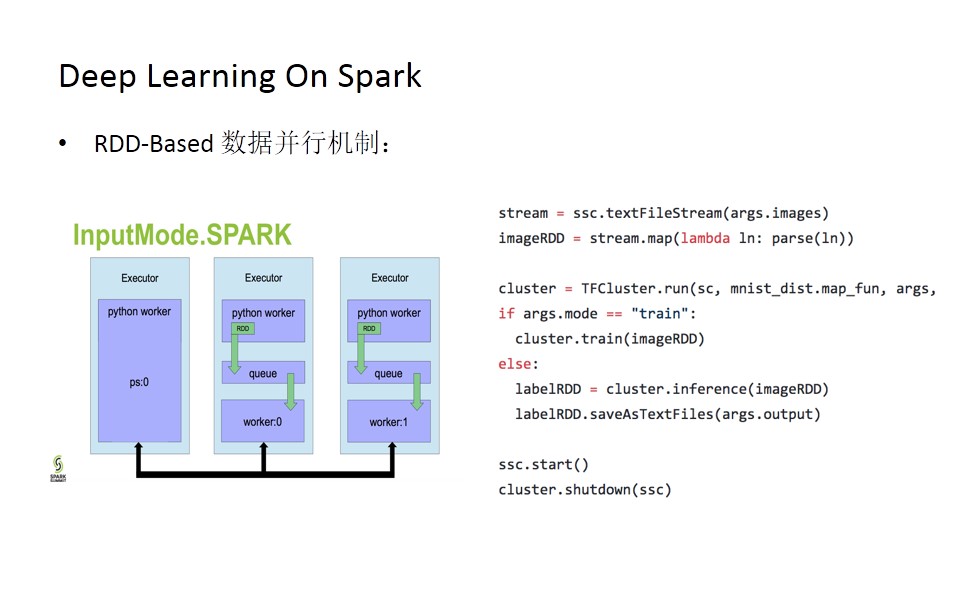
除此之外TensorflowOnSpark还提供了基于RDD的数据并行机制,如下图所示。这套机制非常方便地集成了spark已有的RDD处理机制,可以更好地跟spark
sql或spark streaming去做相应的集成。
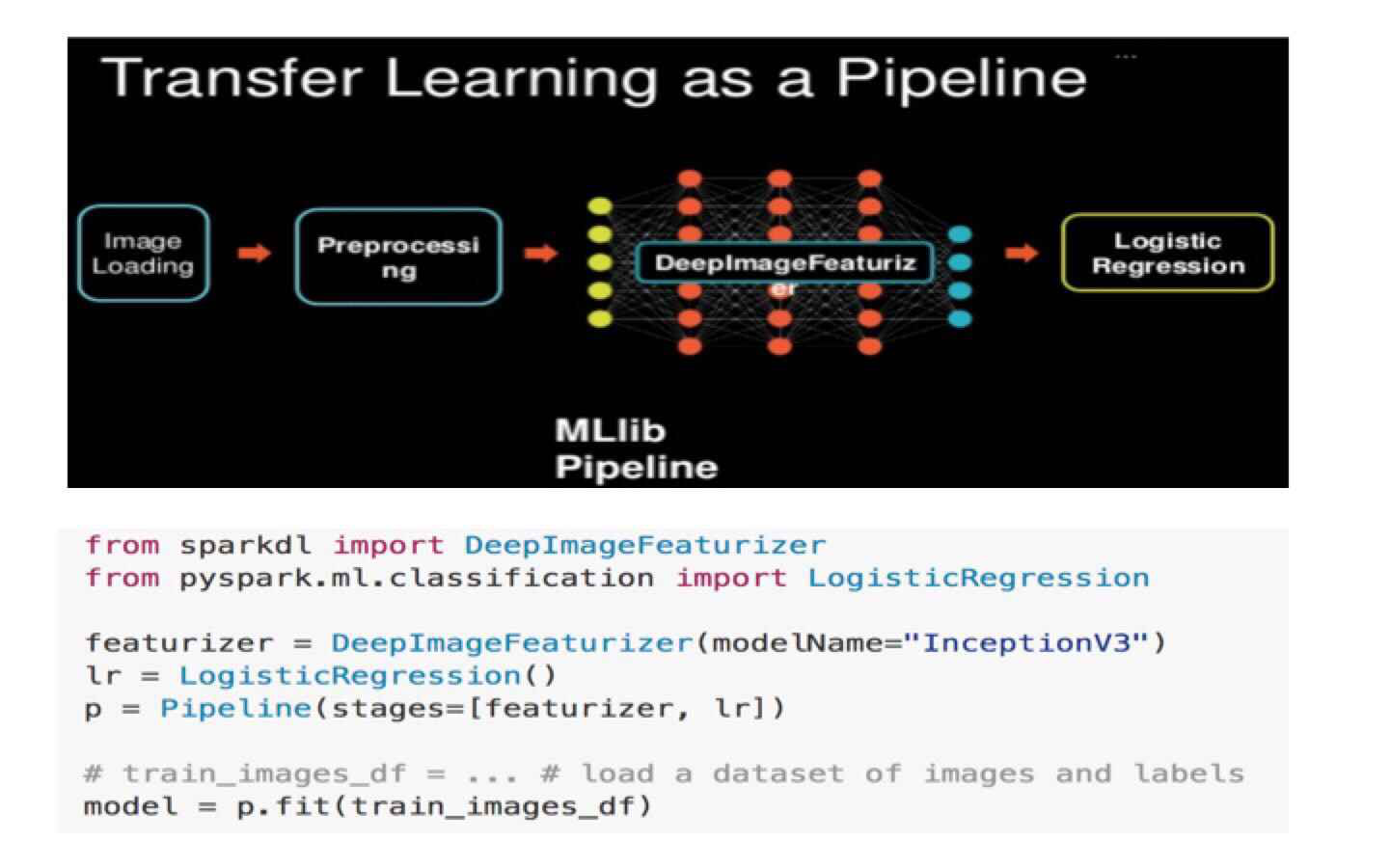
然后进入到另外一个方向,叫做spark-deep-learning,是由spark的创始公司—Data
Bricks发起的,它主要的目标是提供一些high-level的API,把底层的模型进行组件化,同时它期望可以兼容底层深度式学习框架。

这里有个“Transfer Learning as a Pipeline”的例子供大家了解,如下图所示:
TensorflowOnSpark Pipeline开发了两个API,一个是TFEstimator,另一个是TFModel,提供了这两个之后,你可以直接把它们集成到spark-deep-learning
pipeline里面,进行进一步的训练。

六.TensorflowOnSpark案例实践
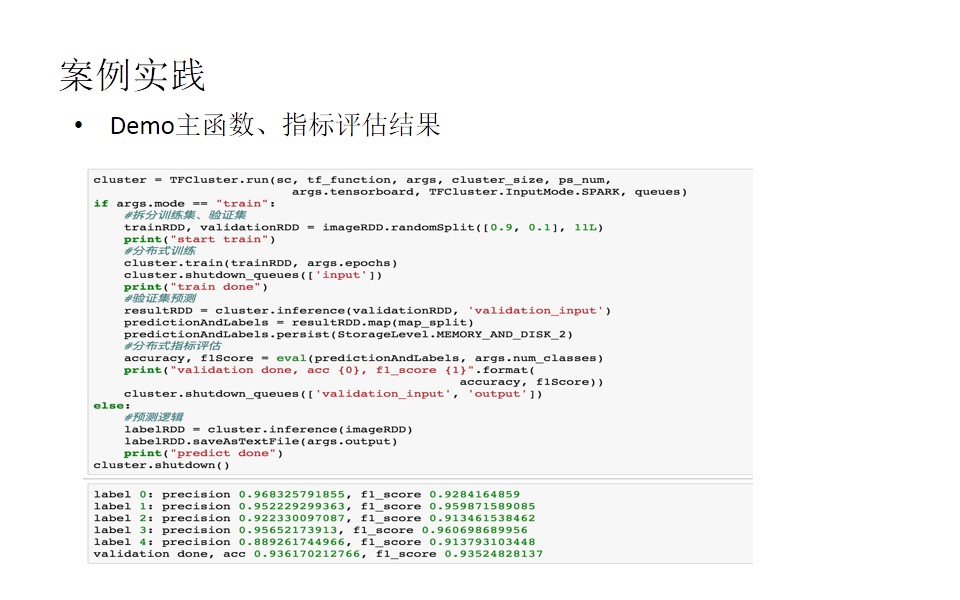
最后一部分,我们来进行案例实践介绍,我们要解决的是一个图像分类问题,这里采用了一个kaggle dataset,叫做花朵识别,有5个类别,4000多张图片,包括郁金香、太阳花、蒲公英、玫瑰和雏菊这五种花。把这些数据预先存储于MongoDB中。我们的案例实践是一个分布式解决方案,包括分布式数据获取、分布式训练、分布式评估。

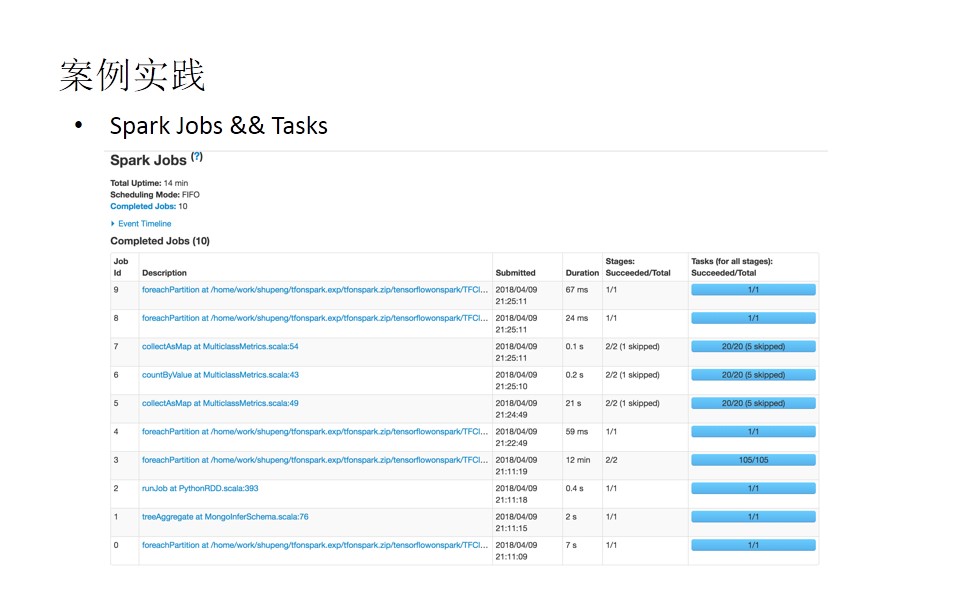
以下几张图片是代码示例,简单了解一下:



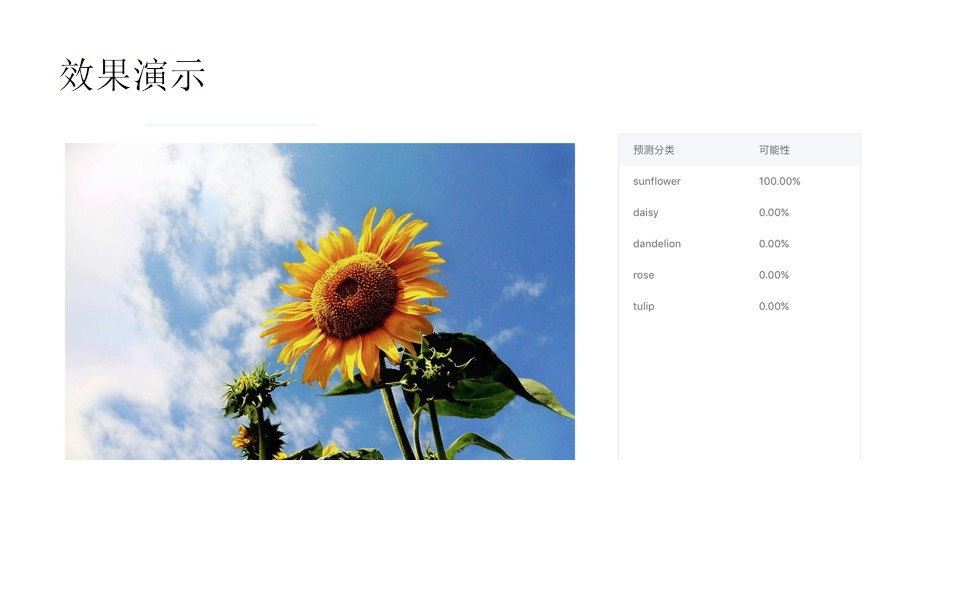
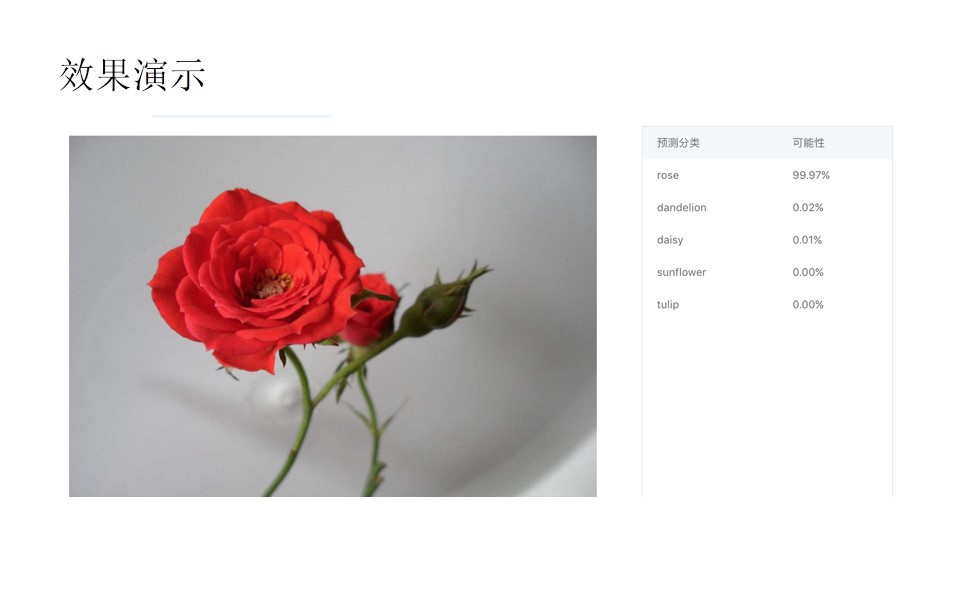
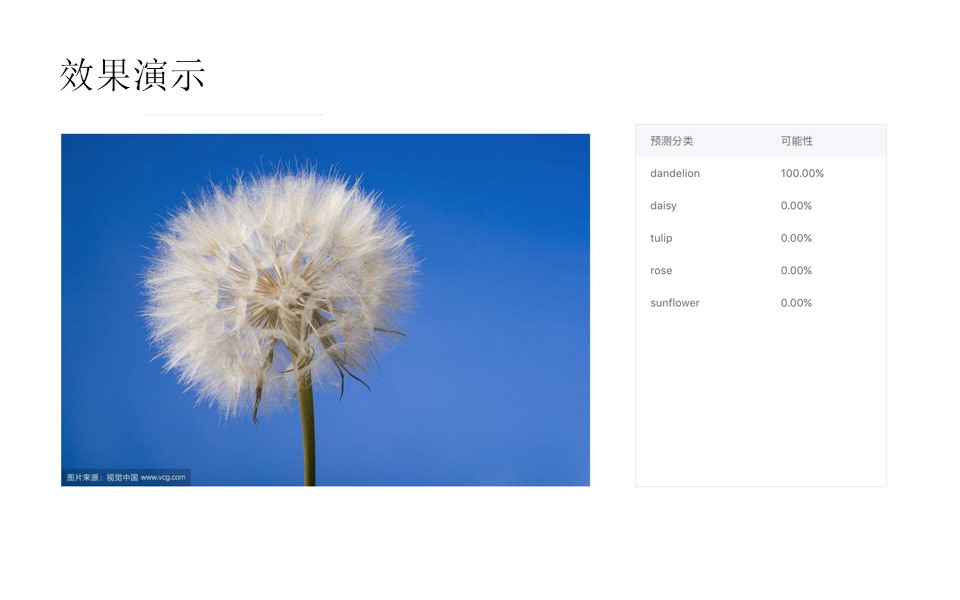
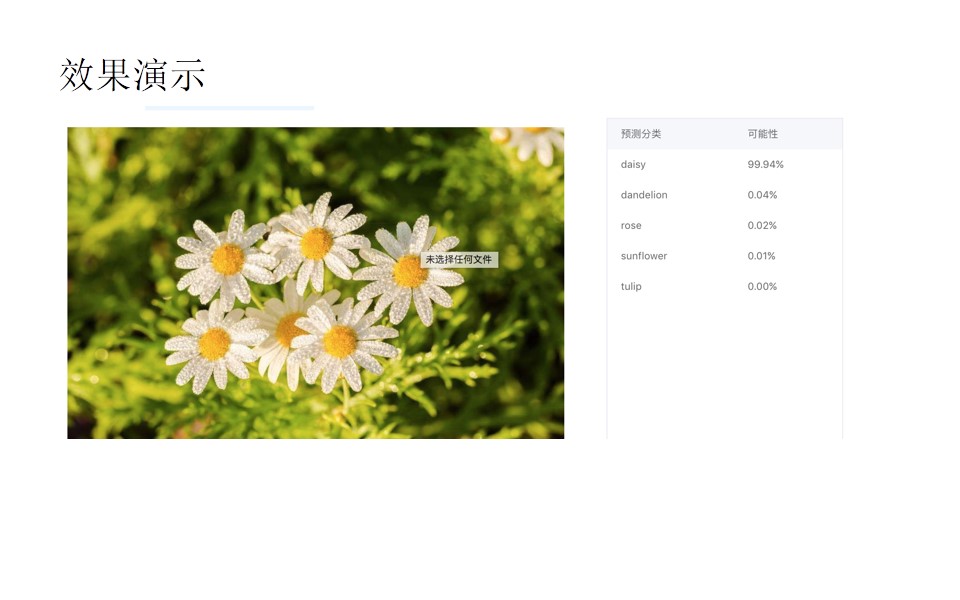
下面是效果演示,左边是图片,右边是模型预测结果,预测结果都是一个概率值,根据概率值的大小来判定这是哪一类花朵:

以上六部分就是本次分享的主要内容,接下来是问答时间,我们来看看都有哪些问题。
1.整个训练过程需要人工参与吗?准确率的提高是需要人工来参与吗?
答:整个训练过程不需要人工参与,准确率的提高涉及超参优化,deep leaning pipeline中提供了grid search机制,可以做些自动超参选择。
2.现在这训练的过程是不是只针对静态的图片?动态的场景可以吗?
答:你的动态场景如果是视频,本身也可抽帧为图片,视频分类是另外一种应用问题,但底层也需要借助已有的图像分类模型,图像分类本身的应用场景非常广,比如和无人机相结合。
3.这套框架适用于文本的自动分类吗?
答:框架同样适合文本分类等其他领域,差别在于数据schema和模型,训练过程涉及到一些图像归一化的过程,但没有模版匹配,你可以理解为所有的特征抽取都是由deep learning自动抽取出来的。
|





