| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌЮФеТЯъЯИНщЩмСЫSupervised
Learning(гаМрЖНбЇЯА)вдМАROCЧњЯпЕШЯрЙижЊЪЖЁЃ
|
|
Supervised Learning(гаМрЖНбЇЯА)
Machine LearningЗжЮЊгаМрЖНбЇЯАгыЮоМрЖНбЇЯАЃЌетИіЯЕСажидкНщЩмгаМрЖНбЇЯАЃЌМДЃЌЭЈЙ§ИцжЊЫуЗЈгаЙиFeaturesКЭЖдгІЕФЪфГіLabelsЃЌШЛКѓЕБгааТЕФfeatureЪ§ОнЪБЃЌзіlabelдЄВтЁЃ
ЛЗОГДюНЈ
ЪзбЁAnacondaАВзАЃЌMacЯТПЩвдгУbrewжБНгзАЁЃ
ЭЈЙ§IrisЪ§ОнПтЙмжаПњБЊ
IrisЪЧsklearnжаФкЧЖЕФвЛзщЪ§ОнЃЌПЩвдгУвдбЇЯАЭЈЙ§ЬиеїжЕЖд№АЮВЛЈНјааЗжРрЁЃ1
Ъ§ОнМгди
from sklearn.datasets
import load_iris
iris = load_iris()
X = iris.data # numpy.ndarray, FeaturesЕФФЧаЉobservation
y = iris.target # numpy.ndarrayгыdataЕФвЛИіlabelЕФвЛвЛЖдгІ |
ЩЯУцСНИіЪ§ОнЖМЪЧnumpyжаndarrayРраЭЁЃndarrayзїЮЊРрЫЦгкИпДњжаЕФОиеѓРДБэДяЪ§ОнЃЌЭЈЙ§ИпаЇЕФCЕзВуПтЃЌФмБШpythonФкжУРрПтИќПьЕизіДѓСПЪ§ОнДІРэЁЃ
iris.data.shape ЕФНсЙћЮЊ ЃЈ150ЃЌ 4ЃЉЃЌБэУцвЛЙВга150зщЪ§Он(Observations)ЃЌУПзщга4ИіЪ§Он(Features)ЁЃдкН№ШкСьгђЕФЪ§ОнЗжЮіДІРэЩЯЃЌвђЮЊЖдгкБэВйзїЕУБШНЯЖрЃЌЫљвдpandasЃЈНЈСЂдкnumpyжЎЩЯЃЉвВЪЧЪЙгУБШНЯЖрЕФПтЁЃ
K-nearest neighbors (KNN) classification
ЖдвбгаЪ§ОнНјааЗжРрЃЌЕБаТЕФЪ§ОнГіЯжЪБЃЌбАеввбжЊЪ§ОнжаKИіКЭаТЪ§ОнзюНгНќЕФЪ§ОнЃЌШЛКѓЭЈЙ§етKИіЪ§ОнЕФlabelЃЌЕУГіаТЕФЪ§ОнгІИУЗждкФФИіРраЭжаЁЃ
from sklearn.neighbors
import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X, y)
X_new = [[3, 5, 4, 2], [5, 4, 3, 2]]
knn.predict(X_new) |
ЭЈЙ§ЕїгУKNeighborsClassifierетИіРрЃЌШЛКѓАбвЛПЊЪММгдиЕФЪ§ОнЭЈЙ§fit()КЏЪ§РДЪЪХфЃЌШЛКѓЖдгкаТЕФЪ§ОнгУpredictРДЕУГіЪєгкФФвЛРрЁЃетИіРяУцЕФKжЕЪЙгУСЫ1ЃЌВЛвЛЖЈЪЧзюгХЕФЃЌФЧШчКЮевЕНетИізюгХВЮЪ§ЃП
бщжЄФЃаЭВЮЪ§
ЖдгкФЃаЭНјаабщжЄЃЌвЛжжЗНЗЈОЭЪЧАбЪ§ОнНјааЗжРрЃЌЗжГЩ2РрЁЃШЛКѓбАевВтЪдЪ§ОнЦЅХфЖШКУЕФВЮЪ§ЁЃгааЉЙ§ФтКЯЕФЧщПіЯТЃЌбЕСЗЪ§ОнЕФФтКЯЖШКмКУЃЌЕЋЕНВтЪдЪ§ОнОЭБЏОчСЫЁЃ
бЕСЗЪ§Он ЃЈФЃаЭгУвдЦЅХфЃЉ
ВтЪдЪ§Он ЃЈФЃаЭгУвдВтЪдЦфгааЇадЃЉ
ЦфжаЃЌtrain_test_splitПЩвдздЖЏЭъГЩетИіЗжРрЙЄзїЃЌВЂЧвЭЈЙ§test_sizeздЖЏЛЎЗжАйЗжжЎЖрЩйЕФЪ§ОнзїЮЊВтЪдЪ§ОнЁЃ
from sklearn.model_selection
import train_test_split # зЂвтЃЌетИіФЃПщДг0.20ПЊЪМВЛДцдкгк sklearn.cross_validationСЫ!
# STEP 1: split X and y into training and testing
sets
X_train, X_test, y_train, y_test = train_test_split(X,
y, test_size=0.4, random_state=4)
from sklearn.linear_model import LogisticRegression
# STEP 2: train the model on the training set
logreg = LogisticRegression()
logreg.fit(X_train, y_train)
# STEP 3: make predictions on the testing set
y_pred = logreg.predict(X_test)
# compare actual response values (y_test) with
predicted response values (y_pred)
from sklearn import metrics
print(metrics.accuracy_score(y_test, y_pred)) |
ЩЯУцР§зггУЕФФЃаЭЪЧLogisticRegressionЃЌЫќЖдЪфШыжЕЛсГіЯжвЛИіЖўдЊХаЖЯЃЌПЩвдРэНтЮЊЪЧЛђепЗёЕФХаЖЯЁЃЛиЕНKNNЕФФЃаЭЁЃПЩвдгавдЯТЪОР§ДњТыЁЃ
# try K=1 through
K=25 and record testing accuracy
k_range = list(range(1, 26))
scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
scores.append(metrics.accuracy_score(y_test, y_pred)) |
ФУЕНЕФmetricsЦРЗжЃЌПЩвдЭЈЙ§matplotlib.pyplot2ЛцЛГіРДЃЌвдбЁдёзюКЯЪЪЕФЁЃ
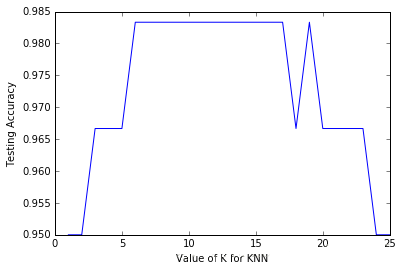
ПЩвдПДЕНЃЌвЛПЊЪМЫцзХKЕФдіМгЃЌВтЪдЪ§ОнЕФЦЅХфдкЬсИпЃЌЕЋЙ§ЖржЎКѓЃЌЗДЖјЯТНЕСЫЃЌФЧЪЧзїЮЊЖдгкЙ§ФтКЯЕФГЭЗЃЁЃДгетИіЭМБэПДЃЌ7ЕН16КЭ18ЖМЪЧВЛДэЕФКђбЁKжЕЁЃ
ЫфШЛАбЪ§ОнЗжГЩЖрЗнФмЙЛЖдФЃаЭЕФЦЅХфГЬЖШзібщжЄЃЌВЂГЭЗЃФЧаЉЙ§ФтКЯЕФХфжУЃЌЕЋЪЧЮўЩќСЫгаЯоЕФЪ§ОнЃЌЫљвдЃЌЯТУцгавЛжжK-fold
cross-validationЕФЗНЗЈзюДѓЛЏЕиРДРћгУЪ§ОнЃЌевЕНИќКЯЪЪЕФЦЅХфВЮЪ§ЁЃ
FeatureбЁдё
гааЉfeatureЙиСЊадБШНЯЕЭЃЌШЅГ§жЎКѓЃЌЗДЖјФмгаИќКУЕидЄВтЁЃетОЭашвЊвЛПЊЪМдкfit()жЎЧАЃЌЖдгкXЃЌАбВЛашвЊЕФfeatureШЅГ§ЕєЁЃШчЙћжЎКѓЕУЕНЕФmetrics.mean_squared_error3ЗДЖјБфаЁЃЌЫЕУїЦЅХфЖШЬсИпЁЃФЧетИіfeatureШЅГ§okЁЃ
K-fold cross-validation
K-fold cross-validationНЋдЪМЪ§ОнОљдШЕиЗжЮЊKЗнЃЌУПвЛДЮНЋЦфжавЛЗнФУГіРДзіВтЪдЪ§Он4ЃЌЦфЫћВЮгыФЃаЭбЕСЗЃЌЕУЕНвЛИіВтЪдЯТЕФЦЅХфжЕЁЃШчДЫзіKДЮЃЌдђгаKИіВтЪдЦЅХфжЕЃЌЫќУЧЕФЦНОљжЕОЭЪЧЦНОљВтЪдЦЅХфжЕЃЌЦНОљжЕзюаЁЕФФЃаЭЫљЪЙгУЕФВЮЪ§ЃЌМДЪЧзюМбВЮЪ§ЁЃ
from sklearn.model_selection
import cross_val_score
# 10-fold cross-validation with K=5 for KNN (the
n_neighbors parameter)
knn = KNeighborsClassifier(n_neighbors=5)
scores = cross_val_score(knn, X, y, cv=10, scoring='accuracy') |
АбФЃаЭknnДЋИјcross_val_scoreВЂЩшжУСЫK-foldЕФжЕЮЊ10ЃЌЕБШЛЃЌcross_val_scoreвВжЇГжДЋздЖЈвхЕФcross-validation
generatorЁЃЗЕЛижЕЪЧKИіВтЪдЦЅХфжЕЕФЪ§зщЁЃ
ЖдгкжЎЧАЬсЕН№АЮВЛЈЗжРрЃЌПЩвдИќаТЮЊ
# search for
an optimal value of K for KNN
k_range = list(range(1, 31))
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, X, y, cv=10, scoring='accuracy')
k_scores.append(scores.mean()) |
ЭЈЙ§ЛцЭМЃЌЕУЕНШчЯТЦЅХфЧњЯп
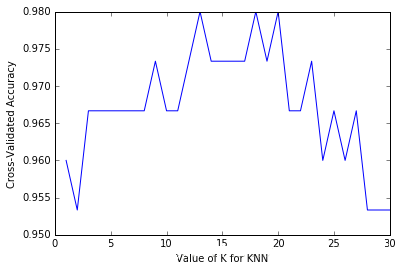
ПЩМћЃЌKдк13ЃЌ18ЃЌ20ЕФЧщПіЯТЃЌЗЕЛижЕЕФЦЅХфЖШзюИпЁЃЫфШЛЪ§ОнЕФРћгУТЪИпСЫЃЌЕЋЪЧетИіЗНЗЈЕФВйзїДњТыБШНЯШпгрЃЌШБЩйpythonЕФМђНрУРбЇЁЃЯТУцНщЩмИќИпаЇЕФДІРэЗНЗЈЁЃ
здЖЏбАевзюМбЦЅХфВЮЪ§
ВЩгУGridSearchCVЃЌЫќЛсБщРњЫљвдИјгшЕФВЮЪ§ЃЌВЂИцжЊзюгХНтЕФВЮЪ§ЁЃ
from sklearn.grid_search
import GridSearchCV
# define the parameter values that should be searched
k_range = list(range(1, 31))
param_grid = dict(n_neighbors=k_range)
# instantiate the grid
grid = GridSearchCV(knn, param_grid, cv=10, scoring='accuracy')
# fit the grid with data
grid.fit(X, y)
# examine the best model
print(grid.best_score_) # 0.98
print(grid.best_params_) # {'n_neighbors': 13}
print(grid.best_estimator_) # KNeighborsClassifier(algorithm='auto',
leaf_size=30, metric='minkowski', metric_params=None,
n_jobs=1, n_neighbors=13, p=2, weights='uniform') |
ШчЙћЕїгУ grid.predictдђФЌШЯВЩгУзюгХВЮЪ§РДдЄВтЃЌМДЩЯУцKжЕЮЊ13РДдЄВтЁЃ
ЩЯУцЕФР§згжЛеыЖдСЫkжЕЕїећЃЌвВОЭЪЧЫЕknnжаЕФn_neighborsетвЛИіВЮжЕЁЃШчЙћДцдкЖрИіВЮЪ§ашвЊЭЌЪБЕїећЃЌПЩвддкparam_gridГѕЪМЛЏЕФЪБКђЃЌвЛЦ№дкdictжаЩшжУЃЌШч
k_range = list(range(1,
31)) # ЕїећВЮЪ§1
weight_options = ['uniform', 'distance'] # ЕїећВЮЪ§2
param_grid = dict(n_neighbors=k_range, weights=weight_options)
grid = GridSearchCV(knn, param_grid, cv=10, scoring='accuracy') |
GridSearchCVЛсБщРњЫљгаЕФВЮЪ§ЕФЫљгазщКЯЃЌЫљвдЗЧГЃКФЪБЁЃвЊМѕЩйБщРњЪ§ЃЌЛЙгавЛжжзіЗЈЪЧВЩгУ
RandomizedSearchCVЃЌЫќжЛЛсЖдзщКЯЕФвЛИізгМЏзібщжЄЁЃБШШчЃЌгУЛЇПЩвдЭЈЙ§n_iter=10ЯожЦжЛБщРњ10ИізгМЏЁЃ
ROCЧњЯп
ЖдгкЖўЗжФЃаЭ(binary classifierЃЌБШШчЩЯУцЬсЕНЙ§ЕФLogisticRegression)дЄВтЕФЪ§ОнЃЌБШШчЫЕЃЌИјГіФГ4ИіВЮЪ§ЃЌдЄВтЪЧЗёЪЧФГжж№АЮВЛЈЃЌФЧУДЃЌашвЊжЊЕРетИіНсТлЕФПЩаХЖШгаЖрЩйЁЃетжжПЩаХЖШЃЌПЩвдДгдЄВтЪЧЛђЗёЕФНсЙћвдМАдЄВтНсЙћгыЪЕМЪНсЙћЖдБШетМИИіНЧЖШПМТЧЁЃ
ROCЧњЯпЃЌОЭЪЧдкxжсБъМЧЃЌШчЙћЪЕМЪЗжРрЮЊЪЧЕФЧщаЮЯТЃЌФЃаЭНЋЦфДэЮѓЕиБъЪОЮЊЪЧЕФИХТЪЃЈFalse
Positive RateЃЉЁЃЖјyжсдђЮЊЃЌШчЙћЪЕМЪЗжРрЪЧЪЧЕФЧщаЮЯТЃЌФЃаЭвВБъЪОЪЧЪЧЕФИХТЪЃЈTrue
Positive RateЃЉЁЃ
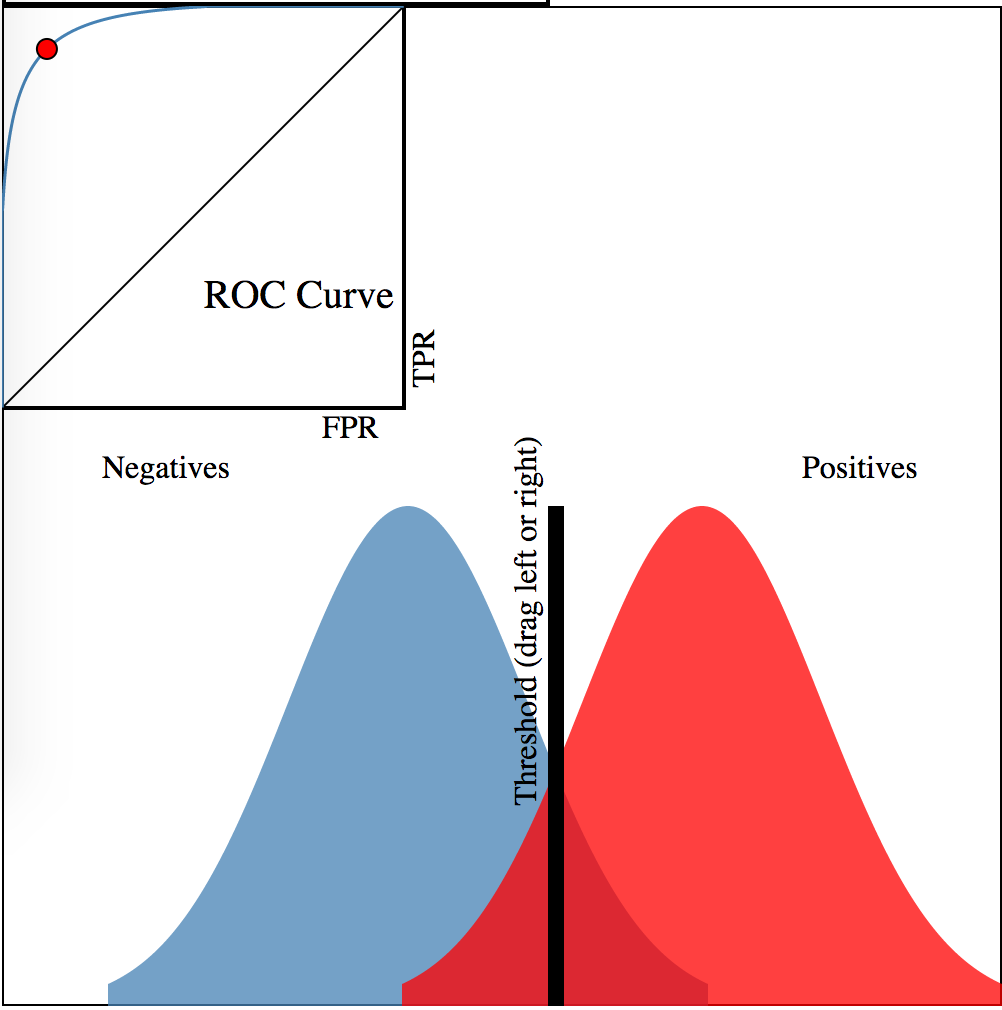
ЭМжаЕФЪОР§ЭМЃЌКьЩЋЮЊЪЧЃЌРЖЩЋЮЊЗёЃЌФЃаЭгавЛИіХаЖЯЕуЃЌгвБпЖМШЯЮЊЪЧЪЧЃЌзѓБпЕФЖМШЯЮЊЪЧЗёЃЌФЧДцдкFPRКЭTPRЃЌROCЧњЯпЩЯЕФКьЕуОЭЪЧетИіФЃаЭЕФХаЖЯЕуЁЃ
дкFPRЩЯЃЌЫќжЕЦЋаЁЃЌЫЕУїДѓЖрЪ§ДэЮѓЕФБЛЙ§ТЫЕєЁЃе§ШЗадФмБЃжЄЁЃ
дкTPRЩЯЃЌЫќжЕЦЋДѓЃЌЫЕУїДѓЖрЪ§е§ШЗЕФБЛЪЖБ№ГіЃЌзМШЗадФмБЃжЄЁЃ
ШчЙћХаЖЯЕугввЦЕНЕзЃЌКьЕуЛсзѓвЦЕНЕзЃЌетЪБКђЃЌЫљгаЕФЪ§ОнЖМБЛХаЖЯЮЊЗёЃЌФЧУДЃЌFPRЮЊ0ЃЌМДЃЌУЛгавЛИіДэЮѓЕФБЛХаЖЯЮЊе§ШЗЃЌе§ШЗадзюИпЁЃЕЋЪЧЃЌTPRвВБфЮЊ0ЃЌЕМжТУЛгавЛИіе§ШЗЕФБЛЪЖБ№ГіЃЌзМШЗадЭъШЋЖЊЪЇЁЃ
ПЩМћЃЌжЛгаДцдквЛаЉФЃК§Й§ЖШЕФНзЖЮЃЌМДЭМжаРЖЩЋгыКьЩЋгаНЛЛуЃЌФЧХаЖЯЪфГіБиШЛДцдквЛИіФЃК§ЕФНзЖЮЃЌЫљвдашвЊROCЧњЯпЖдЦфзМШЗадКЭе§ШЗадзіЦРЙРЁЃЖдгквЛИіРэЯыЕФХаЖЯЕуЃЌетИіКЭФуЕФвЕЮёОіВпЯрЙиСЊЃЌФуашвЊFPRОЁСПаЁ(->0)ЃЌЛЙЪЧTPRвЊОЁСПДѓ(->1)ЃП
ШчЙћРЖЩЋЭМЯёКЭКьЩЋЭМЯёНќКѕжиЕўЃЌФЧУДROCЧњЯпвВНќЫЦгкЖдНЧЯпЃЌетИіЧщаЮЯТЃЌХаЖЯЕФзМШЗадКЭЯЙВТУЛЩЖЧјБ№ЁЃ
X_train, X_test,
y_train, y_test = train_test_split(X, y, random_state=0)
logreg = LogisticRegression()
logreg.fit(X_train, y_train)
y_pred_class = logreg.predict(X_test)
# IMPORTANT: first argument is true values, second
argument is predicted values
confusion = metrics.confusion_matrix(y_test, y_pred_class)
TP = confusion[1, 1]
TN = confusion[0, 0]
FP = confusion[0, 1]
FN = confusion[1, 0]
print(metrics.recall_score(y_test, y_pred_class))
# TPR:(TP / float(TP + FN))
print(FP / float(TN + FP)) # FPR
y_pred_prob = logreg.predict_proba(X_test)[:,
1]
import matplotlib.pyplot as plt
fpr, tpr, thresholds = metrics.roc_curve(y_test,
y_pred_prob)
plt.plot(fpr, tpr)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.title('ROC curve for diabetes classifier')
plt.xlabel('False Positive Rate (1 - Specificity)')
plt.ylabel('True Positive Rate (Sensitivity)')
plt.grid(True)
plt.show() |
ЛцжЦГіЭМЯёШчЯТ
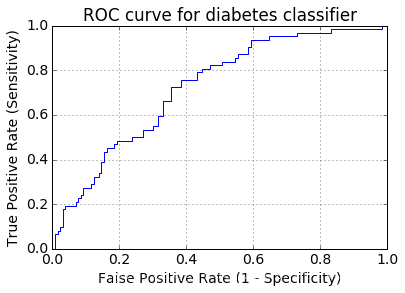
ЖдгкЧњЯпЃЌашвЊМЦЫуЯТУцЕФУцЛ§(Area Under Curve)ЃЌУцЛ§дНДѓдНгХЁЃМЦЫуЗНЪНЪЧ
# IMPORTANT:
first argument is true values, second argument
is predicted probabilities
print(metrics.roc_auc_score(y_test, y_pred_prob)) |
ЕБШЛЃЌвВПЩвдгУРЯХѓгбcross_validationРДевзюгХХфжУФЃаЭ
| cross_val_score(logreg,
X, y, cv=10, scoring='roc_auc').mean() |
зЂвт
БОЮФжаЕФжаЮФгябдВЛШЗЖЈЖдгІЕФЪѕгяЃЌПЩФмДцдкВЛзМШЗЕФЧщПіЁЃ
етИіЪЧОЕфЕФMachine LearningШыУХЪОР§ЃЌдкЁЖBuilding Machine Learning
Systems with PythonЁЗвЛЪщжаЃЌОЭзЈУХгавЛеТвдетИіеЙПЊЁЃ
дкЛцЭМЩЯЃЌЛЙПЩвдВЩгУseabornЃЌЫќЗтзАСЫmatplotlibЁЃ
дЮФжаЪЙгУСЫЯпадФЃаЭLinearRegressionЃЌЖдЦфЬсЕН3жжбщжЄзМШЗТЪЕФЗНЪНЃЌmetrics.mean_absolute_errorЃЌmetrics.mean_squared_error
КЭ np.sqrt(metrics.mean_squared_error()) ет3жжЁЃ
sklearnгаИізЈУХЕФKFoldРрЃЌПЩвдЭЈЙ§ from sklearn.cross_validation
import KFold в§гУЁЃ
|








