| 编辑推荐: |
本文来自于segmentfault,文章详细介绍了Python中如何使用scikit-learn模型对分类、回归进行预测的实现原理等相关知识。
|
|
摘要: 在Python中如何使用scikit-learn模型对分类、回归进行预测?本文简述了其实现原理和代码实现。
一旦你在scikit-learn中选择好机器学习模型,就可以用它来预测新的数据实例。初学者经常会有这样的疑问:
如何在scikit-learn中用我自己的模型进行预测?
在本教程中,你将会发现如何在Python的机器学习库scikit-learn 中使用机器学习模型进行分类和回归预测。文章结构如下:
1.如何构建一个模型,为预测做好准备。
2.如何在scikit-learn库中进行类别和概率预测。
3.如何在scikit-learn库中进行回归预测。

一、构建一个模型
在进行预测之前,你必须训练一个最终模型。你可以使用k-fold交叉验证或训练/测试数据,对模型进行训练。这样做的目的就是为了评估模型在样本外数据上的表现及其性能,比如新的数据。
你可以在这里了解更多关于如何训练最终模型的信息:
如何训练一个最终的机器学习模型?
如何预测分类模型
分类问题,就是模型学习输入特征与输出特征之间的映射,确定某一个或多个数据实例是否为某一个类标签的问题,比如“是垃圾邮件”和“不是垃圾邮件”。
下面是针对一个简单二元分类问题的Logistic回归模型的示例代码。
尽管我们在本教程中使用Logistic回归,在scikit-learn中几乎所有的分类算法中也都可以使用该函数。
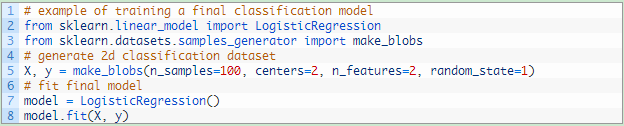
模型构建完成以后,需要将模型保存到文件中,如pickle库。保存后,你可以随时加载模型并使用它进行预测。为了简单起见,我们将跳过这一步,有关这方面的详细内容,请参阅以下文章:
在scikit-learn库中如何使用Python保存并加载机器学习模型
现在,我们希望用最终模型进行两种分类预测:类别预测和概率预测。
1、类别预测
类别预测就是给定最终模型和一个或多个数据实例,使用模型对预测数据实例进行分类。
首先我们并不知道新数据的类别。这就是我们需要这个模型的原因。使用predict()函数在scikit-learn库中使用最终分类模型预测新数据实例的类。
例如,Xnew的数组中有一个或多个数据实例,将数组传递给模型的predict()函数,来预测数组中每个实例的类别。

(1)多个实例的类别预测
我们来举个例子,对多种类别预测进行详细论述。
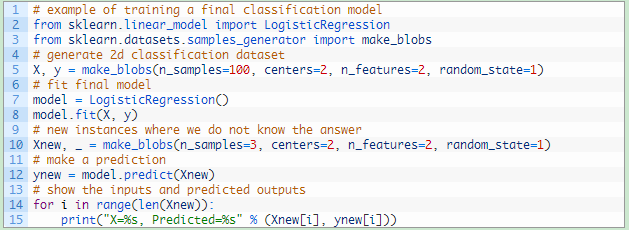
对三个新的数据实例的类别进行预测,然后将数据实例和预测结果一起打印出来,如下图所示。

(2)单个实例的类别预测
如果你只有一个新的数据实例,你可以将这个实例以数组的形式传递给predict()函数,例如:
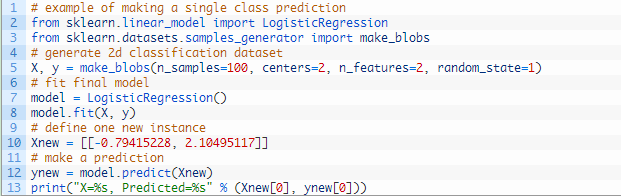
运行上述代码,打印出实例数据和预测结果,如下图所示。

关于类别标签的注意事项
准备好数据后,可能使用过LabelEncoder将图像的类别(例如字符串型)映射为整型。也可以用LabelEncoder中的inverse_transform()函数将整型再转换回字符串型。出于这个原因,在拟合最终模型时,您可能想要在pickle库中保存用于编码输出预测结果的LabelEncoder。
2、概率预测
概率预测就是预测每个数据实例所属类别的概率。给定一个或多个新实例,该模型将预测每个数据所属类别的概率,并返回0和1之间的某一个值。
你可以在scikit-learn中调用predict_proba()函数进行这些实例的类别概率的预测,如下图所示: 
该函数仅适用于使用大多数模型对数据实例的类别进行概率预测,这是大多数但不是全部的模型。
下面的代码是对数据实例数组Xnew中的每个实例进行概率预测。
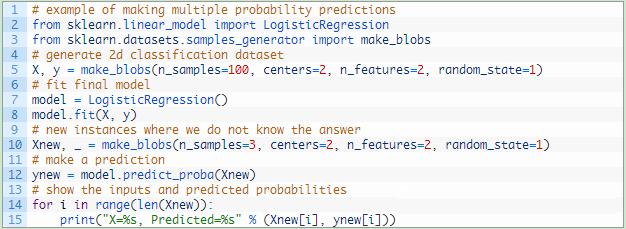
运行上述代码进行概率预测,然后分别打印出输入实例数据、每个实例属于第1类(用0表示)或第2类(用1表示)的概率,如下图所示。

三、如何使用回归模型进行预测
回归属于监督学习,给定输入实例数据,模型学习并将数据映射到一个合适的输出量,例如0.1,0.2等。
下图中的代码是一个最终化线性回归模型的示例。同样地,用于回归预测的函数也适用于scikit-learn中的所有回归模型。
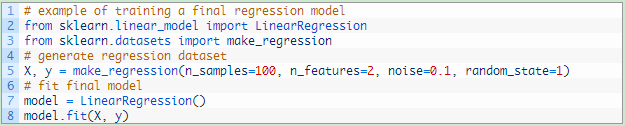
我们可以在最终模型上调用predict()函数来预测所述类别的概率。和分类一样,predict()函数将一个或多个数据实例的列表或数组作为输入。
多个实例的回归预测
下面的示例是演示如何对具有未知预期结果的多个数据实例进行回归预测。
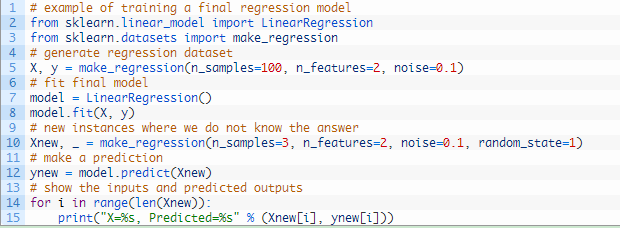
运行上述代码,对多个数据实例进行预测,并将输出和预测结果打印出来,如下图所示。

单个实例的回归预测
将相同的函数用于适当的列表或数组中,就可以对单个数据实例进行预测。
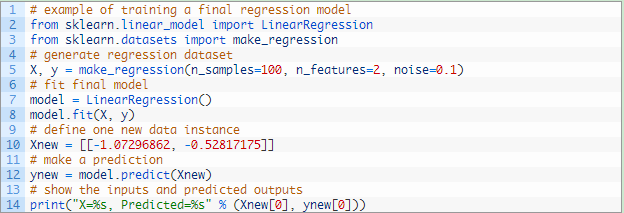
运行上述代码,并打印出数据实例和预测结果,如下图所示。

总结
阅读完本文,你已经了解了如何使用scikit-learn Python库中的机器学习最终模型进行分类和回归预测。 |








