| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌЮФеТЯъЯИНщЩмСЫЧПЛЏбЇЯАЕФИХФюЃЌЧјБ№вдМАжївЊЫуЗЈЕШЯрЙижЊЪЖЁЃ
|
|
ЫфШЛЪЧжмФЉЃЌвВБЃГжГфЕчЃЌНёЬьРДПДПДЧПЛЏбЇЯАЃЌВЛЙ§ВЛЪЧвЊгУЫќРДЭцгЮЯЗЃЌЖјЪЧОѕЕУЫќдкжЦдьвЕЃЌПтДцЃЌЕчЩЬЃЌЙуИцЃЌЭЦМіЃЌН№ШкЃЌвНСЦЕШгыЮвУЧЩњЛюЯЂЯЂЯрЙиЕФСьгђвВгаКмКУЕФгІгУЃЌЕБШЛвЊСЫНтвЛЯТСЫЁЃ
БОЮФНсЙЙЃК
ЖЈвх
КЭМрЖНЪНбЇЯА, ЗЧМрЖНЪНбЇЯАЕФЧјБ№
жївЊЫуЗЈКЭРрБ№
гІгУОйР§
1. ЖЈвх
ЧПЛЏбЇЯАЪЧЛњЦїбЇЯАЕФвЛИіживЊЗжжЇЃЌЪЧЖрбЇПЦЖрСьгђНЛВцЕФвЛИіВњЮяЃЌЫќЕФБОжЪЪЧНтОі decision making
ЮЪЬтЃЌМДздЖЏНјааОіВпЃЌВЂЧвПЩвдзіСЌајОіВпЁЃ
ЫќжївЊАќКЌЫФИідЊЫиЃЌagentЃЌЛЗОГзДЬЌЃЌааЖЏЃЌНБРј, ЧПЛЏбЇЯАЕФФПБъОЭЪЧЛёЕУзюЖрЕФРлМЦНБРјЁЃ
ШУЮвУЧвдаЁКЂбЇЯАзпТЗРДзіИіаЮЯѓЕФР§згЃК
аЁКЂЯывЊзпТЗЃЌЕЋдкетжЎЧАЃЌЫћашвЊЯШеОЦ№РДЃЌеОЦ№РДжЎКѓЛЙвЊБЃГжЦНКтЃЌНгЯТРДЛЙвЊЯШТѕГівЛЬѕЭШЃЌЪЧзѓЭШЛЙЪЧгвЭШЃЌТѕГівЛВНКѓЛЙвЊТѕГіЯТвЛВНЁЃ
аЁКЂОЭЪЧ agentЃЌЫћЪдЭМЭЈЙ§ВЩШЁааЖЏЃЈМДаазпЃЉРДВйзнЛЗОГЃЈаазпЕФБэУцЃЉЃЌВЂЧвДгвЛИізДЬЌзЊБфЕНСэвЛИізДЬЌЃЈМДЫћзпЕФУПвЛВНЃЉЃЌЕБЫћЭъГЩШЮЮёЕФзгШЮЮёЃЈМДзпСЫМИВНЃЉЪБЃЌКЂзгЕУЕННБРјЃЈИјЧЩПЫСІГдЃЉЃЌВЂЧвЕБЫћВЛФмзпТЗЪБЃЌОЭВЛЛсИјЧЩПЫСІЁЃ

2. КЭМрЖНЪНбЇЯА, ЗЧМрЖНЪНбЇЯАЕФЧјБ№
дкЛњЦїбЇЯАжаЃЌЮвУЧБШНЯЪьжЊЕФЪЧМрЖНЪНбЇЯАЃЌЗЧМрЖНбЇЯАЃЌДЫЭтЛЙгавЛИіДѓРрОЭЪЧЧПЛЏбЇЯАЃК

ЧПЛЏбЇЯАКЭМрЖНЪНбЇЯАЕФЧјБ№ЃК
МрЖНЪНбЇЯАОЭКУБШФудкбЇЯАЕФЪБКђЃЌгавЛИіЕМЪІдкХдБпжИЕуЃЌЫћжЊЕРдѕУДЪЧЖдЕФдѕУДЪЧДэЕФЃЌЕЋдкКмЖрЪЕМЪЮЪЬтжаЃЌР§Шч
chessЃЌgoЃЌетжжгаГЩЧЇЩЯЭђжжзщКЯЗНЪНЕФЧщПіЃЌВЛПЩФмгавЛИіЕМЪІжЊЕРЫљгаПЩФмЕФНсЙћЁЃ
ЖјетЪБЃЌЧПЛЏбЇЯАЛсдкУЛгаШЮКЮБъЧЉЕФЧщПіЯТЃЌЭЈЙ§ЯШГЂЪдзіГівЛаЉааЮЊЕУЕНвЛИіНсЙћЃЌЭЈЙ§етИіНсЙћЪЧЖдЛЙЪЧДэЕФЗДРЁЃЌЕїећжЎЧАЕФааЮЊЃЌОЭетбљВЛЖЯЕФЕїећЃЌЫуЗЈФмЙЛбЇЯАЕНдкЪВУДбљЕФЧщПіЯТбЁдёЪВУДбљЕФааЮЊПЩвдЕУЕНзюКУЕФНсЙћЁЃ
ОЭКУБШФугавЛжЛЛЙУЛгабЕСЗКУЕФаЁЙЗЃЌУПЕБЫќАбЮнзгХЊТвКѓЃЌОЭМѕЩйУРЮЖЪГЮяЕФЪ§СПЃЈГЭЗЃЃЉЃЌУПДЮБэЯжВЛДэЪБЃЌОЭМгБЖУРЮЖЪГЮяЕФЪ§СПЃЈНБРјЃЉЃЌФЧУДаЁЙЗзюжеЛсбЇЕНвЛИіжЊЪЖЃЌОЭЪЧАбПЭЬќХЊТвЪЧВЛКУЕФааЮЊЁЃ
СНжжбЇЯАЗНЪНЖМЛсбЇЯАГіЪфШыЕНЪфГіЕФвЛИігГЩфЃЌМрЖНЪНбЇЯАГіЕФЪЧжЎМфЕФЙиЯЕЃЌПЩвдИцЫпЫуЗЈЪВУДбљЕФЪфШыЖдгІзХЪВУДбљЕФЪфГіЃЌЧПЛЏбЇЯАГіЕФЪЧИјЛњЦїЕФЗДРЁ
reward functionЃЌМДгУРДХаЖЯетИіааЮЊЪЧКУЪЧЛЕЁЃ
СэЭтЧПЛЏбЇЯАЕФНсЙћЗДРЁгабгЪБЃЌгаЪБКђПЩФмашвЊзпСЫКмЖрВНвдКѓВХжЊЕРвдЧАЕФФГвЛВНЕФбЁдёЪЧКУЛЙЪЧЛЕЃЌЖјМрЖНбЇЯАзіСЫБШНЯЛЕЕФбЁдёЛсСЂПЬЗДРЁИјЫуЗЈЁЃ
ЖјЧвЧПЛЏбЇЯАУцЖдЕФЪфШызмЪЧдкБфЛЏЃЌУПЕБЫуЗЈзіГівЛИіааЮЊЃЌЫќгАЯьЯТвЛДЮОіВпЕФЪфШыЃЌЖјМрЖНбЇЯАЕФЪфШыЪЧЖРСЂЭЌЗжВМЕФЁЃ
ЭЈЙ§ЧПЛЏбЇЯАЃЌвЛИі agent ПЩвддкЬНЫїКЭПЊЗЂЃЈexploration and exploitationЃЉжЎМфзіШЈКтЃЌВЂЧвбЁдёвЛИізюДѓЕФЛиБЈЁЃ
exploration ЛсГЂЪдКмЖрВЛЭЌЕФЪТЧщЃЌПДЫќУЧЪЧЗёБШвдЧАГЂЪдЙ§ЕФИќКУЁЃ
exploitation ЛсГЂЪдЙ§ШЅОбщжазюгааЇЕФааЮЊЁЃ
вЛАуЕФМрЖНбЇЯАЫуЗЈВЛПМТЧетжжЦНКтЃЌОЭжЛЪЧЪЧ exploitativeЁЃ
ЧПЛЏбЇЯАКЭЗЧМрЖНЪНбЇЯАЕФЧјБ№ЃК
ЗЧМрЖНЪНВЛЪЧбЇЯАЪфШыЕНЪфГіЕФгГЩфЃЌЖјЪЧФЃЪНЁЃР§ШчдкЯђгУЛЇЭЦМіаТЮХЮФеТЕФШЮЮёжаЃЌЗЧМрЖНЪНЛсевЕНгУЛЇЯШЧАвбОдФЖСЙ§РрЫЦЕФЮФеТВЂЯђЫћУЧЭЦМіЦфвЛЃЌЖјЧПЛЏбЇЯАНЋЭЈЙ§ЯђгУЛЇЯШЭЦМіЩйСПЕФаТЮХЃЌВЂВЛЖЯЛёЕУРДздгУЛЇЕФЗДРЁЃЌзюКѓЙЙНЈгУЛЇПЩФмЛсЯВЛЖЕФЮФеТЕФЁАжЊЪЖЭМЁБЁЃ
3. жївЊЫуЗЈКЭЗжРр
ДгЧПЛЏбЇЯАЕФМИИідЊЫиЕФНЧЖШЛЎЗжЕФЛАЃЌЗНЗЈжївЊгаЯТУцМИРрЃК
Policy based, ЙизЂЕуЪЧевЕНзюгХВпТдЁЃ
Value based, ЙизЂЕуЪЧевЕНзюгХНБРјзмКЭЁЃ
Action based, ЙизЂЕуЪЧУПвЛВНЕФзюгХааЖЏЁЃ
ЮвУЧПЩвдгУвЛИізюЪьжЊЕФТУааЩЬР§згРДПДЃЌ
ЮвУЧвЊДг A зпЕН FЃЌУПСНЕужЎМфБэЪОетЬѕТЗЕФГЩБОЃЌЮвУЧвЊбЁдёТЗОЖШУГЩБОдНЕЭдНКУЃК

ФЧУДМИДѓдЊЫиЗжБ№ЪЧЃК
states ЃЌОЭЪЧНкЕу {A, B, C, D, E, F}
action ЃЌОЭЪЧДгвЛЕузпЕНЯТвЛЕу {A -> B, C -> D, etc}
reward function ЃЌОЭЪЧБпЩЯЕФ cost
policyЃЌОЭЪЧЭъГЩШЮЮёЕФећЬѕТЗОЖ {A -> C -> F}
гавЛжжзпЗЈЪЧетбљЕФЃЌдк A ЪБЃЌПЩвдбЁЕФ (B, C, D, E)ЃЌЗЂЯж D зюгХЃЌОЭзпЕН DЃЌДЫЪБЃЌПЩвдбЁЕФ
(B, C, F)ЃЌЗЂЯж F зюгХЃЌОЭзпЕН FЃЌДЫЪБЭъГЩШЮЮёЁЃ
етИіЫуЗЈОЭЪЧЧПЛЏбЇЯАЕФвЛжжЃЌНазі epsilon greedyЃЌЪЧвЛжж Policy based ЕФЗНЗЈЃЌЕБШЛСЫетИіТЗОЖВЂВЛЪЧзюгХЕФзпЗЈЁЃ
ДЫЭтЛЙПЩвдДгВЛЭЌНЧЖШЪЙЗжРрИќЯИвЛаЉЃК
ШчЯТЭМЫљЪОЕФЫФжжЗжРрЗНЪНЃЌЗжБ№ЖдгІзХЯргІЕФжївЊЫуЗЈЃК

Model-freeЃКВЛГЂЪдШЅРэНтЛЗОГ, ЛЗОГИјЪВУДОЭЪЧЪВУДЃЌвЛВНвЛВНЕШД§ецЪЕЪРНчЕФЗДРЁ, дйИљОнЗДРЁВЩШЁЯТвЛВНааЖЏЁЃ
Model-basedЃКЯШРэНтецЪЕЪРНчЪЧдѕбљЕФ, ВЂНЈСЂвЛИіФЃаЭРДФЃФтЯжЪЕЪРНчЕФЗДРЁЃЌЭЈЙ§ЯыЯѓРДдЄХаЖЯНгЯТРДНЋвЊЗЂЩњЕФЫљгаЧщПіЃЌШЛКѓбЁдёетаЉЯыЯѓЧщПіжазюКУЕФФЧжжЃЌВЂвРОнетжжЧщПіРДВЩШЁЯТвЛВНЕФВпТдЁЃЫќБШ
Model-free ЖрГіСЫвЛИіащФтЛЗОГЃЌЛЙгаЯыЯѓСІЁЃ
Policy basedЃКЭЈЙ§ИаЙйЗжЮіЫљДІЕФЛЗОГ, жБНгЪфГіЯТвЛВНвЊВЩШЁЕФИїжжЖЏзїЕФИХТЪ, ШЛКѓИљОнИХТЪВЩШЁааЖЏЁЃ
Value basedЃКЪфГіЕФЪЧЫљгаЖЏзїЕФМлжЕ, ИљОнзюИпМлжЕРДбЁЖЏзїЃЌетРрЗНЗЈВЛФмбЁШЁСЌајЕФЖЏзїЁЃ
Monte-carlo updateЃКгЮЯЗПЊЪМКѓ, вЊЕШД§гЮЯЗНсЪј, ШЛКѓдйзмНсетвЛЛиКЯжаЕФЫљгазЊелЕу,
дйИќаТааЮЊзМдђЁЃ
Temporal-difference updateЃКдкгЮЯЗНјаажаУПвЛВНЖМдкИќаТ, ВЛгУЕШД§гЮЯЗЕФНсЪј,
етбљОЭФмБпЭцБпбЇЯАСЫЁЃ
On-policyЃКБиаыБОШЫдкГЁ, ВЂЧввЛЖЈЪЧБОШЫБпЭцБпбЇЯАЁЃ
Off-policyЃКПЩвдбЁдёздМКЭц, вВПЩвдбЁдёПДзХБ№ШЫЭц, ЭЈЙ§ПДБ№ШЫЭцРДбЇЯАБ№ШЫЕФааЮЊзМдђЁЃ
жївЊЫуЗЈгаЯТУцМИжжЃЌНёЬьЯШжЛЪЧМђЪіЃК
1. Sarsa

Q ЮЊЖЏзїаЇгУКЏЪ§ЃЈaction-utility functionЃЉЃЌгУгкЦРМлдкЬиЖЈзДЬЌЯТВЩШЁФГИіЖЏзїЕФгХСгЃЌПЩвдНЋжЎРэНтЮЊжЧФмЬхЃЈAgentЃЉЕФДѓФдЁЃ
SARSA РћгУТэЖћПЦЗђаджЪЃЌжЛРћгУСЫЯТвЛВНаХЯЂ, ШУЯЕЭГАДееВпТджИв§НјааЬНЫїЃЌдкЬНЫїУПвЛВНЖМНјаазДЬЌМлжЕЕФИќаТЃЌИќаТЙЋЪНШчЯТЫљЪОЃК
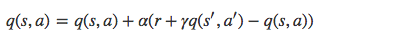
s ЮЊЕБЧАзДЬЌЃЌa ЪЧЕБЧАВЩШЁЕФЖЏзїЃЌsЁЏ ЮЊЯТвЛВНзДЬЌЃЌaЁЏ ЪЧЯТвЛИізДЬЌВЩШЁЕФЖЏзїЃЌr ЪЧЯЕЭГЛёЕУЕФНБРјЃЌ
ІС ЪЧбЇЯАТЪЃЌ ІУ ЪЧЫЅМѕвђзгЁЃ
2. Q learning


Q Learning ЕФЫуЗЈПђМмКЭ SARSA РрЫЦ, вВЪЧШУЯЕЭГАДееВпТджИв§НјааЬНЫїЃЌдкЬНЫїУПвЛВНЖМНјаазДЬЌМлжЕЕФИќаТЁЃЙиМќдкгк
Q Learning КЭ SARSA ЕФИќаТЙЋЪНВЛвЛбљЃЌQ Learning ЕФИќаТЙЋЪНШчЯТЃК

3. Policy Gradients
ЯЕЭГЛсДгвЛИіЙЬЖЈЛђепЫцЛњЦ№ЪМзДЬЌГіЗЂЃЌВпТдЬнЖШШУЯЕЭГЬНЫїЛЗОГЃЌЩњГЩвЛИіДгЦ№ЪМзДЬЌЕНжежЙзДЬЌЕФзДЬЌ-ЖЏзї-НБРјађСаЃЌs1,a1,r1,.....,sT,aT,rTЃЌдкЕк
t ЪБПЬЃЌЮвУЧШУ gt=rt+ІУrt+1+... ЕШгк q(st,a) ЃЌДгЖјЧѓНтВпТдЬнЖШгХЛЏЮЪЬтЁЃ
4. Actor-Critic

ЫуЗЈЗжЮЊСНИіВПЗжЃКActor КЭ CriticЁЃActor ИќаТВпТдЃЌ Critic ИќаТМлжЕЁЃCritic
ОЭПЩвдгУжЎЧАНщЩмЕФ SARSA Лђеп Q Learning ЫуЗЈЁЃ
5. Monte-carlo learning
гУЕБЧАВпТдЬНЫїВњЩњвЛИіЭъећЕФзДЬЌ-ЖЏзї-НБРјађСа:
s1,a1,r1,....,sk,ak,rkЁЋІа
дкађСаЕквЛДЮХіЕНЛђепУПДЮХіЕНвЛИізДЬЌ s ЪБЃЌМЦЫуЦфЫЅМѕНБРј:

зюКѓИќаТзДЬЌМлжЕ:

6. Deep-Q-Network
DQN ЫуЗЈЕФжївЊзіЗЈЪЧ Experience ReplayЃЌНЋЯЕЭГЬНЫїЛЗОГЕУЕНЕФЪ§ОнДЂДцЦ№РДЃЌШЛКѓЫцЛњВЩбљбљБОИќаТЩюЖШЩёОЭјТчЕФВЮЪ§ЁЃЫќвВЪЧдкУПИі
action КЭ environment state ЯТДяЕНзюДѓЛиБЈЃЌВЛЭЌЕФЪЧМгСЫвЛаЉИФНјЃЌМгШыСЫОбщЛиЗХКЭОіЖЗЭјТчМмЙЙЁЃ


4. гІгУОйР§
ЧПЛЏбЇЯАгаКмЖргІгУЃЌГ§СЫЮоШЫМнЪЛЃЌAlphaGoЃЌЭцгЮЯЗжЎЭтЃЌЛЙгаЯТУцетаЉЙЄГЬжаЪЕгУЕФР§згЃК
1. Manufacturing
Р§ШчвЛМвШеБОЙЋЫО FanucЃЌЙЄГЇЛњЦїШЫдкФУЦ№вЛИіЮяЬхЪБЃЌЛсВЖзНетИіЙ§ГЬЕФЪгЦЕЃЌМЧзЁЫќУПДЮВйзїЕФааЖЏЃЌВйзїГЩЙІЛЙЪЧЪЇАмСЫЃЌЛ§РлОбщЃЌЯТвЛДЮПЩвдИќПьИќзМЕиВЩШЁааЖЏЁЃ

2. Inventory Management
дкПтДцЙмРэжаЃЌвђЮЊПтДцСПДѓЃЌПтДцашЧѓВЈЖЏНЯДѓЃЌПтДцВЙЛѕЫйЖШЛКТ§ЕШзшАЪЙЕУЙмРэЪЧИіБШНЯФбЕФЮЪЬтЃЌПЩвдЭЈЙ§НЈСЂЧПЛЏбЇЯАЫуЗЈРДМѕЩйПтДцжмзЊЪБМфЃЌЬсИпПеМфРћгУТЪЁЃ
3. Dynamic pricing
ЧПЛЏбЇЯАжаЕФ Q-learning ПЩвдгУРДДІРэЖЏЬЌЖЈМлЮЪЬтЁЃ
4. Customer Delivery
жЦдьЩЬдкЯђИїИіПЭЛЇдЫЪфЪБЃЌЯывЊдкТњзуПЭЛЇЕФЫљгаашЧѓЕФЭЌЪБНЕЕЭГЕЖгзмГЩБОЁЃЭЈЙ§ multi-agents
ЯЕЭГКЭ Q-learningЃЌПЩвдНЕЕЭЪБМфЃЌМѕЩйГЕСОЪ§СПЁЃ
5. ECommerce Personalization
дкЕчЩЬжаЃЌвВПЩвдгУЧПЛЏбЇЯАЫуЗЈРДбЇЯАКЭЗжЮіЙЫПЭааЮЊЃЌЖЈжЦВњЦЗКЭЗўЮёвдТњзуПЭЛЇЕФИіадЛЏашЧѓЁЃ
6. Ad Serving
Р§ШчЫуЗЈ LinUCB ЃЈЪєгкЧПЛЏбЇЯАЫуЗЈ bandit ЕФвЛжжЫуЗЈЃЉЃЌЛсГЂЪдЭЖЗХИќЙуЗЖЮЇЕФЙуИцЃЌОЁЙмЙ§ШЅЛЙУЛгаБЛфЏРРКмЖрЃЌФмЙЛИќКУЕиЙРМЦецЪЕЕФЕуЛїТЪЁЃ
дйШчЫЋ 11 ЭЦМіГЁОАжаЃЌАЂРяАЭАЭЪЙгУСЫЩюЖШЧПЛЏбЇЯАгыздЪЪгІдкЯпбЇЯАЃЌЭЈЙ§ГжајЛњЦїбЇЯАКЭФЃаЭгХЛЏНЈСЂОіВпв§ЧцЃЌЖдКЃСПгУЛЇааЮЊвдМААйвкМЖЩЬЦЗЬиеїНјааЪЕЪБЗжЮіЃЌАяжњУПвЛИігУЛЇбИЫйЗЂЯжБІБДЃЌЬсИпШЫКЭЩЬЦЗЕФХфЖдаЇТЪЁЃЛЙгаЃЌРћгУЧПЛЏбЇЯАНЋЪжЛњгУЛЇЕуЛїТЪЬсЩ§СЫ
10-20%ЁЃ
7. Financial Investment Decisions
Р§ШчетМвЙЋЫО Pit.aiЃЌгІгУЧПЛЏбЇЯАРДЦРМлНЛвзВпТдЃЌПЩвдАяжњгУЛЇНЈСЂНЛвзВпТдЃЌВЂАяжњЫћУЧЪЕЯжЦфЭЖзЪФПБъЁЃ
8. Medical Industry
ЖЏЬЌжЮСЦЗНАИЃЈDTRЃЉЪЧвНбЇбаОПЕФвЛИіжїЬтЃЌЪЧЮЊСЫИјЛМепевЕНгааЇЕФжЮСЦЗНЗЈЁЃ Р§ШчАЉжЂетжжашвЊГЄЦкЪЉвЉЕФжЮСЦЃЌЧПЛЏбЇЯАЫуЗЈПЩвдНЋЛМепЕФИїжжСйДВжИБъзїЮЊЪфШы
РДжЦЖЈжЮСЦВпТдЁЃ
|








