| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌБОЮФНЋДјФубЇЯАОЕфЧПЛЏбЇЯАЫуЗЈ
Q-learning ЕФЯрЙижЊЪЖЃЌФуНЋбЇЕНЃКЃЈ1ЃЉQ-learning ЕФИХФюНтЪЭКЭЫуЗЈЯъНтЃЛЃЈ2ЃЉЭЈЙ§
Numpy ЪЕЯж Q-learningЁЃ
|
|
ЙЪЪТАИР§ЃКЦяЪПКЭЙЋжї
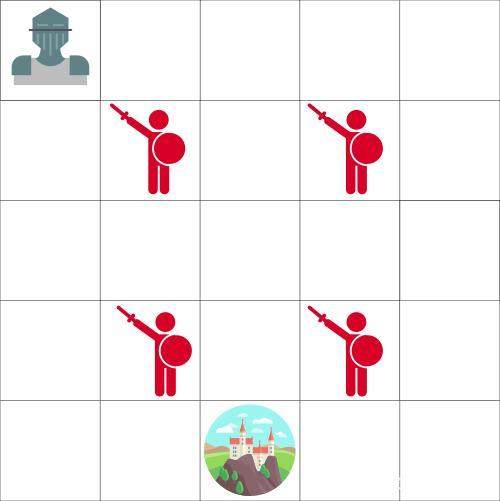
МйЩшФуЪЧвЛУћЦяЪПЃЌВЂЧвФуашвЊеќОШЩЯУцЕФЕиЭМРяБЛРЇдкГЧБЄжаЕФЙЋжїЁЃ
ФуУПДЮПЩвдвЦЖЏвЛИіЗНПщЕФОрРыЁЃЕаШЫЪЧВЛФмвЦЖЏЕФЃЌЕЋЪЧШчЙћФуКЭЕаШЫТфдкСЫЭЌвЛИіЗНПщжаЃЌФуОЭЛсЫРЁЃФуЕФФПБъЪЧвдОЁПЩФмПьЕФТЗЯпзпЕНГЧБЄШЅЁЃетПЩвдЪЙгУвЛИіЁИАДВНЛ§ЗжЁЙЯЕЭГРДЦРЙРЁЃ
1.ФудкУПвЛВНЖМЛсЪЇШЅ 1 ЗжЃЈУПвЛВНЪЇШЅЕФЗжЪ§АяжњжЧФмЬхбЕСЗЕФИќПьЃЉ
2.ШчЙћХіЕНСЫвЛИіЕаШЫЃЌФуЛсЪЇШЅ 100 ЗжЃЌВЂЧвбЕСЗ episode
НсЪјЁЃ
3.ШчЙћНјШыЕНГЧБЄжаЃЌФуОЭЛёЪЄСЫЃЌЛёЕУ 100 ЗжЁЃ
ФЧУДЮЪЬтРДСЫЃКШчКЮВХФмЙЛДДНЈетбљЕФжЧФмЬхФиЃП
ЯТУцЮвНЋНщЩмЕквЛИіВпТдЁЃМйЩшжЧФмЬхЪдЭМзпБщУПвЛИіЗНПщЃЌВЂЧвНЋЦфзХЩЋЁЃТЬЩЋДњБэЁИАВШЋЁЙЃЌКьЩЋДњБэЁИВЛАВШЋЁЙЁЃ

ЭЌбљЕФЕиЭМЃЌЕЋЪЧБЛзХЩЋСЫЃЌгУгкЯдЪОФФаЉЗНПщЪЧПЩвдБЛАВШЋЗУЮЪЕФЁЃ
НгзХЃЌЮвУЧИцЫпжЧФмЬхжЛФмбЁдёТЬЩЋЕФЗНПщЁЃ
ЕЋЮЪЬтЪЧЃЌетжжВпТдВЂВЛЪЧЪЎЗжгагУЁЃЕБТЬЩЋЕФЗНПщБЫДЫЯрСкЪБЃЌЮвУЧВЛжЊЕРбЁдёФФИіЗНПщЪЧзюКУЕФЁЃЫљвдЃЌжЧФмЬхПЩФмЛсдкбАевГЧБЄЕФЙ§ГЬжаЯнШыЮоЯоЕФбЛЗЁЃ
Q-Table МђНщ
ЯТУцЮвНЋНщЩмЕкЖўжжВпТдЃКДДНЈвЛИіБэИёЁЃЭЈЙ§ЫќЃЌЮвУЧПЩвдЮЊУПвЛИізДЬЌЃЈstateЃЉЩЯНјааЕФУПвЛИіЖЏзїЃЈactionЃЉМЦЫуГізюДѓЕФЮДРДНБРјЃЈrewardЃЉЕФЦкЭћЁЃ
ЕУвцгкетИіБэИёЃЌЮвУЧПЩвджЊЕРЮЊУПвЛИізДЬЌВЩШЁЕФзюМбЖЏзїЁЃ
УПИізДЬЌЃЈЗНПщЃЉдЪаэЫФжжПЩФмЕФВйзїЃКзѓвЦЁЂгввЦЁЂЩЯвЦЁЂЯТвЦЁЃ

ЁИ0ЁЙДњБэВЛПЩФмЕФвЦЖЏЃЈШчЙћФудкзѓЩЯНЧЃЌФуВЛПЩФмЯђзѓвЦЖЏЛђепЯђЩЯвЦЖЏЃЁЃЉ
дкМЦЫуЙ§ГЬжаЃЌЮвУЧПЩвдНЋетИіЭјИёзЊЛЛГЩвЛИіБэЁЃ
етжжБэИёБЛГЦЮЊ Q-tableЃЈЁИQЁЙДњБэЖЏзїЕФЁИжЪСПЁЙЃЉЁЃУПвЛСаНЋДњБэЫФИіВйзїЃЈзѓЁЂгвЁЂЩЯЁЂЯТЃЉЃЌааДњБэзДЬЌЁЃУПИіЕЅдЊИёЕФжЕДњБэИјЖЈзДЬЌКЭЯргІЖЏзїЕФзюДѓЮДРДНБРјЦкЭћЁЃ
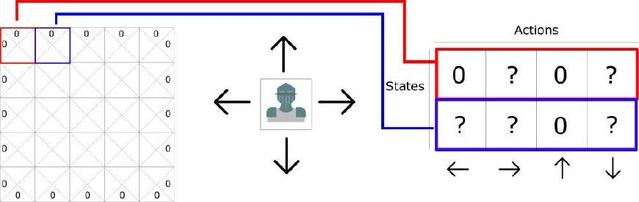
УПИі Q-table ЕФЗжЪ§НЋДњБэдкИјЖЈзюМбВпТдЕФзДЬЌЯТВЩШЁЯргІЖЏзїЛёЕУЕФзюДѓЮДРДНБРјЦкЭћЁЃ
ЮЊЪВУДЮвУЧЫЕЁИИјЖЈЕФВпТдЁЙФиЃПетЪЧвђЮЊЮвУЧВЂВЛЪЕЯжетаЉВпТдЁЃЯрЗДЃЌЮвУЧжЛашвЊИФНј Q-table
ОЭПЩвдвЛжБбЁдёзюМбЕФЖЏзїЁЃ
НЋетИі Q-table ЯыЯѓГЩвЛИіЁИБИЭќжНЬѕЁЙгЮЯЗЁЃЕУвцгкДЫЃЌЮвУЧЭЈЙ§бАевУПвЛаажазюИпЕФЗжЪ§ЃЌПЩвджЊЕРЖдгкУПвЛИізДЬЌЃЈQ-table
жаЕФУПвЛааЃЉРДЫЕЃЌПЩВЩШЁЕФзюМбЖЏзїЪЧЪВУДЁЃ
ЬЋАєСЫЃЁЮвНтОіСЫетИіГЧБЄЮЪЬтЃЁЕЋЪЧЃЌЧыЕШвЛЯТ... ЮвУЧШчКЮМЦЫу Q-table жаУПИідЊЫиЕФжЕФиЃП
ЮЊСЫбЇЯАЕН Q-table жаЕФУПИіжЕЃЌЮвУЧНЋЪЙгУ Q-learning ЫуЗЈЁЃ
Q-learning ЫуЗЈЃКбЇЯАЖЏзїжЕКЏЪ§ЃЈaction value functionЃЉ
ЖЏзїжЕКЏЪ§ЃЈЛђГЦЁИQ КЏЪ§ЁЙЃЉгаСНИіЪфШыЃКЁИзДЬЌЁЙКЭЁИЖЏзїЁЙЁЃЫќНЋЗЕЛидкИУзДЬЌЯТжДааИУЖЏзїЕФЮДРДНБРјЦкЭћЁЃ

ЮвУЧПЩвдАб Q КЏЪ§ЪгЮЊвЛИідк Q-table ЩЯЙіЖЏЕФЖСШЁЦїЃЌгУгкбАевгыЕБЧАзДЬЌЙиСЊЕФаавдМАгыЖЏзїЙиСЊЕФСаЁЃЫќЛсДгЯрЦЅХфЕФЕЅдЊИёжаЗЕЛи
Q жЕЁЃетОЭЪЧЮДРДНБРјЕФЦкЭћЁЃ

дкЮвУЧЬНЫїЛЗОГЃЈenvironmentЃЉжЎЧАЃЌQ-table ЛсИјГіЯрЭЌЕФШЮвтЕФЩшЖЈжЕЃЈДѓЖрЪ§ЧщПіЯТЪЧ
0ЃЉЁЃЫцзХЖдЛЗОГЕФГжајЬНЫїЃЌетИі Q-table ЛсЭЈЙ§ЕќДњЕиЪЙгУ Bellman ЗНГЬЃЈЖЏЬЌЙцЛЎЗНГЬЃЉИќаТ
Q(s,a) РДИјГідНРДдНКУЕФНќЫЦЁЃ
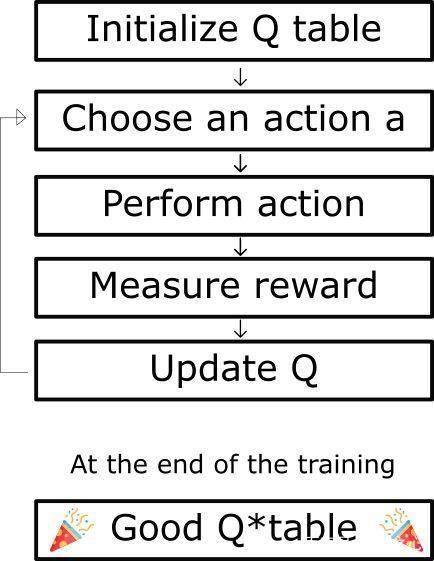

Q-learning ЫуЗЈСїГЬ
Q-learning ЫуЗЈЕФЮБДњТы
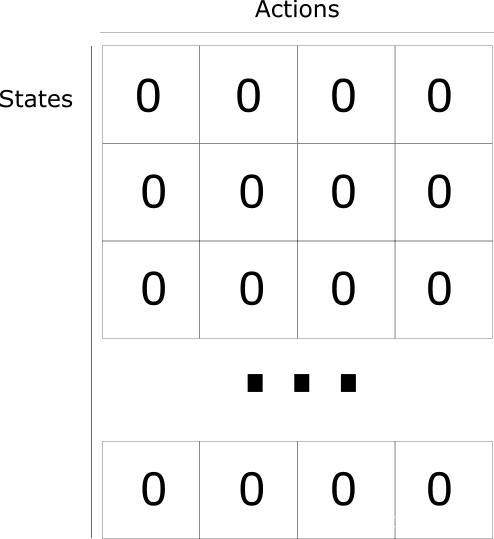
ВНжш 1ЃКГѕЪМЛЏ Q жЕЁЃЮвУЧЙЙдьСЫвЛИі m СаЃЈm = ЖЏзїЪ§ )ЃЌn
ааЃЈn = зДЬЌЪ§ЃЉЕФ Q-tableЃЌВЂНЋЦфжаЕФжЕГѕЪМЛЏЮЊ 0ЁЃ
ВНжш 2ЃКдкећИіЩњУќжмЦкжаЃЈЛђепжБЕНбЕСЗБЛжажЙЧАЃЉЃЌВНжш 3 ЕНВНжш 5 ЛсвЛжББЛжиИДЃЌжБЕНДяЕНСЫзюДѓЕФбЕСЗДЮЪ§ЃЈгЩгУЛЇжИЖЈЃЉЛђепЪжЖЏжажЙбЕСЗЁЃ
ВНжш 3ЃКбЁШЁвЛИіЖЏзїЁЃдкЛљгкЕБЧАЕФ Q жЕЙРМЦЕУГіЕФзДЬЌ s ЯТбЁдёвЛИіЖЏзї aЁЃ
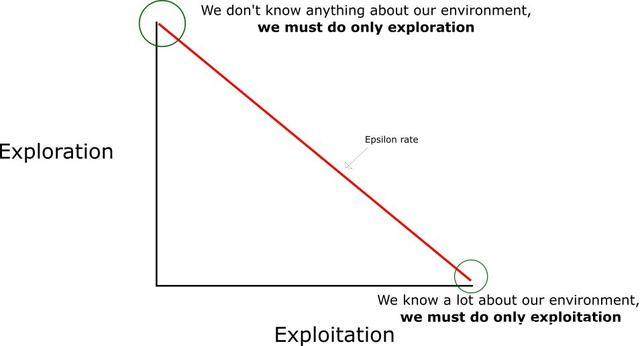
ЕЋЪЧЁЁШчЙћУПИі Q жЕЖМЕШгкСуЃЌЮвУЧвЛПЊЪМИУбЁдёЪВУДЖЏзїФиЃПдкетРяЃЌЮвУЧОЭПЩвдПДЕНЬНЫї/РћгУЃЈexploration/exploitationЃЉЕФШЈКтгаЖрживЊСЫЁЃ
ЫМТЗОЭЪЧЃЌдквЛПЊЪМЃЌЮвУЧНЋЪЙгУ epsilon ЬАРЗВпТдЃК
1.ЮвУЧжИЖЈвЛИіЬНЫїЫйТЪЁИepsilonЁЙЃЌвЛПЊЪМНЋЫќЩшЖЈЮЊ 1ЁЃетИіОЭЪЧЮвУЧНЋЫцЛњВЩгУЕФВНГЄЁЃдквЛПЊЪМЃЌетИіЫйТЪгІИУДІгкзюДѓжЕЃЌвђЮЊЮвУЧВЛжЊЕР
Q-table жаШЮКЮЕФжЕЁЃетвтЮЖзХЃЌЮвУЧашвЊЭЈЙ§ЫцЛњбЁдёЖЏзїНјааДѓСПЕФЬНЫїЁЃ
2.ЩњГЩвЛИіЫцЛњЪ§ЁЃШчЙћетИіЪ§Дѓгк epsilonЃЌФЧУДЮвУЧНЋЛсНјааЁИРћгУЁЙЃЈетвтЮЖзХЮвУЧдкУПвЛВНРћгУвбОжЊЕРЕФаХЯЂбЁдёЖЏзїЃЉЁЃЗёдђЃЌЮвУЧНЋМЬајНјааЬНЫїЁЃ
3.дкИеПЊЪМбЕСЗ Q КЏЪ§ЪБЃЌЮвУЧБиаыгавЛИіДѓЕФ epsilonЁЃЫцзХжЧФмЬхЖдЙРЫуГіЕФ
Q жЕИќгаАбЮеЃЌЮвУЧНЋж№НЅМѕаЁ epsilonЁЃ
ВНжш 4-5ЃКЦРМлЃЁВЩгУЖЏзї a ВЂЧвЙлВьЪфГіЕФзДЬЌ s' КЭНБРј rЁЃЯждкЮвУЧИќаТКЏЪ§ QЃЈsЃЌaЃЉЁЃ
ЮвУЧВЩгУдкВНжш 3 жабЁдёЕФЖЏзї aЃЌШЛКѓжДааетИіЖЏзїЛсЗЕЛивЛИіаТЕФзДЬЌ s' КЭНБРј rЁЃ
НгзХЮвУЧЪЙгУ Bellman ЗНГЬШЅИќаТ QЃЈsЃЌaЃЉЃК
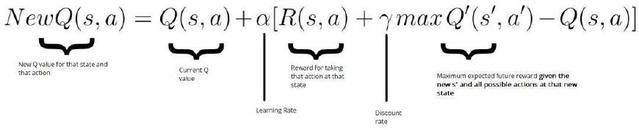
ШчЯТЗНДњТыЫљЪОЃЌИќаТ QЃЈstateЃЌactionЃЉЃК
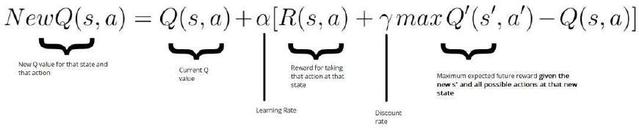
New Q value = Current Q value + lr * [Reward + discount_rate
* (highest Q value between possible actions from the
new state sЁЏ ) ЁЊ Current Q value ]
ШУЮвУЧОйИіР§згЃК

>
вЛПщФЬРв = +1
СНПщФЬРв = +2
вЛДѓЖбФЬРв = +10ЃЈбЕСЗНсЪјЃЉ
ГдЕНСЫЪѓвЉ = -10ЃЈбЕСЗНсЪјЃЉ
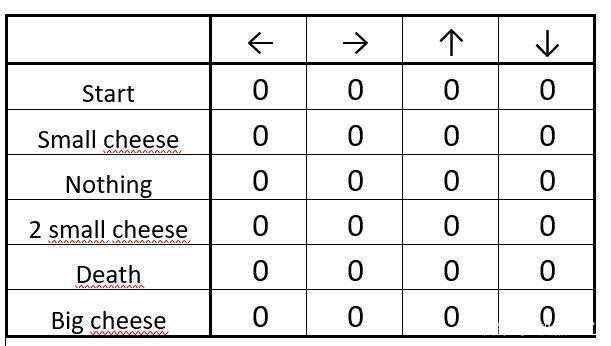
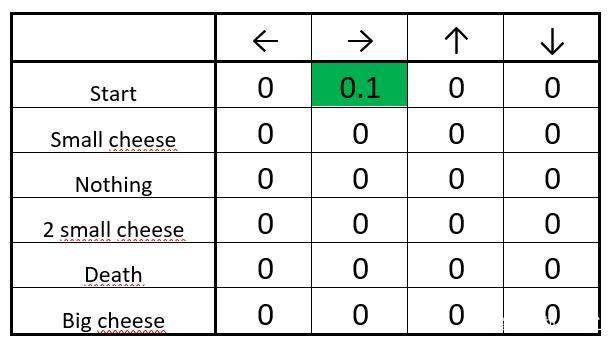
ВНжш 1ЃКГѕЪМЛЏ Q-table
ГѕЪМЛЏжЎКѓЕФ Q-table
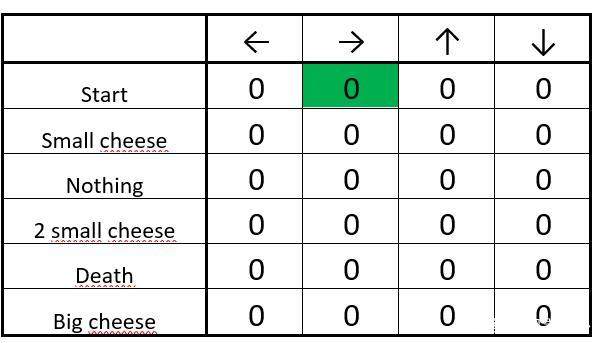
ВНжш 2ЃКбЁдёвЛИіЖЏзїЁЃДгЦ№ЪМЕуЃЌФуПЩвддкЯђгвзпКЭЯђЯТзпЦфжабЁдёвЛИіЁЃгЩгкгавЛИіДѓЕФ
epsilon ЫйТЪЃЈвђЮЊЮвУЧжСНёЖдгкЛЗОГвЛЮоЫљжЊЃЉЃЌЮвУЧЫцЛњЕибЁдёвЛИіЁЃР§ШчЯђгвзпЁЃ
ЮвУЧЫцЛњвЦЖЏЃЈР§ШчЯђгвзпЃЉ

ЮвУЧЗЂЯжСЫвЛПщФЬРвЃЈ+1ЃЉЃЌЯждкЮвУЧПЩвдИќаТПЊЪМЪБЕФ Q жЕВЂЧвЯђгвзпЃЌЭЈЙ§ Bellman ЗНГЬЪЕЯжЁЃ
ВНжш 4-5ЃКИќаТ Q КЏЪ§

ЪзЯШЃЌЮвУЧМЦЫу Q жЕЕФИФБфСП ІЄQ(start, right)ЁЃ
НгзХЮвУЧНЋГѕЪМЕФ Q жЕгы ІЄQ(start, right) КЭбЇЯАТЪЕФЛ§ЯрМгЁЃ
ПЩвдНЋбЇЯАТЪПДзїЪЧЭјТчгаЖрПьЕиХзЦњОЩжЕЁЂЩњГЩаТжЕЕФЖШСПЁЃШчЙћбЇЯАТЪЪЧ
1ЃЌаТЕФЙРМЦжЕЛсГЩЮЊаТЕФ Q жЕЃЌВЂЭъШЋХзЦњОЩжЕЁЃ
ИќаТКѓЕФ Q-table
ЬЋКУСЫЃЁЮвУЧИеИеИќаТСЫЕквЛИі Q жЕЁЃЯждкЮвУЧвЊзіЕФОЭЪЧвЛДЮгжвЛДЮЕизіетИіЙЄзїжБЕНбЇЯАНсЪјЁЃ
ЪЕЯж Q-learning ЫуЗЈ
МШШЛЮвУЧжЊЕРСЫЫќЪЧШчКЮЙЄзїЕФЃЌЮвУЧНЋвЛВНВНЕиЪЕЯж Q-learning ЫуЗЈЁЃДњТыЕФУПвЛВПЗжЖМдкЯТУцЕФ
Jupyter notebook жажБНгБЛНтЪЭСЫЁЃ
ФуПЩвддкЮвЕФЩюЖШЧПЛЏбЇЯАПЮГЬ repo жаЛёЕУДњТыЁЃ
ЛиЙЫ
1.Q-learning ЪЧвЛИіЛљгкжЕЕФЧПЛЏбЇЯАЫуЗЈЃЌРћгУ Q КЏЪ§бАевзюгХЕФЁИЖЏзїЁЊбЁдёЁЙВпТдЁЃ
2.ЫќИљОнЖЏзїжЕКЏЪ§ЦРЙРгІИУбЁдёФФИіЖЏзїЃЌетИіКЏЪ§ОіЖЈСЫДІгкФГвЛИіЬиЖЈзДЬЌвдМАдкИУзДЬЌЯТВЩШЁЬиЖЈЖЏзїЕФНБРјЦкЭћжЕЁЃ
3.ФПЕФЃКзюДѓЛЏ Q КЏЪ§ЕФжЕЃЈИјЖЈвЛИізДЬЌКЭЖЏзїЪБЕФЮДРДНБРјЦкЭћЃЉЁЃ
4.Q-table АяжњЮвУЧевЕНЖдгкУПИізДЬЌРДЫЕЕФзюМбЖЏзїЁЃ
5.ЭЈЙ§бЁдёЫљгаПЩФмЕФЖЏзїжазюМбЕФвЛИіРДзюДѓЛЏЦкЭћНБРјЁЃ
6.Q зїЮЊФГвЛЬиЖЈзДЬЌЯТВЩШЁФГвЛЬиЖЈЖЏзїЕФжЪСПЕФЖШСПЁЃ
7.КЏЪ§ QЃЈstateЃЌactionЃЉЁњЗЕЛидкЕБЧАзДЬЌЯТВЩШЁИУЖЏзїЕФЮДРДНБРјЦкЭћЁЃ
8.етИіКЏЪ§ПЩвдЭЈЙ§ Q-learning ЫуЗЈРДЙРМЦЃЌЪЙгУ Bellman
ЗНГЬЕќДњЕиИќаТ QЃЈsЃЌaЃЉ
9.дкЮвУЧЬНЫїЛЗОГжЎЧАЃКQ-table ИјГіЯрЭЌЕФШЮвтЕФЩшЖЈжЕЁњ
ЕЋЪЧЫцзХЖдЛЗОГЕФГжајЬНЫїЁњQ ИјГідНРДдНКУЕФНќЫЦЁЃ
ОЭЪЧетаЉСЫЃЁВЛвЊЭќМЧздМКШЅЪЕЯжДњТыЕФУПвЛВПЗжЁЊЁЊЪдзХаоИФвбгаЕФДњТыЪЧЪЎЗжживЊЕФЁЃ
|








