| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌБОЮФеТжївЊЭЈЙ§ЪЕбщРДНВНтЩюЖШбЇЯАFaster
RCNNПђМмЕФЪЕР§ЗжИюШЮЮёвдМАRoI AlignВйзїЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
|
|
ЫМЯы

ЛљгкFaster RCNNПђМмЃЌдкзюКѓЭЌЗжРрКЭЛиЙщВуЃЌдіМгСЫЪЕР§ЗжИюШЮЮёЁОa
small FCN applied to each RoIЁП
НЋFaster RCNNжаЕФRoI PoolingЬцЛЛГЩRoI AlignВйзї
зюжеЕФЬиеїВуЃЌВЩгУFPN(Feature Pyramid Network)НјааЬиеїЬсШЁ
ВЩгУResNet101зїЮЊЛљДЁЭјТч
RPNжаЕФanchorВЩгУ5 scalesКЭ3 aspect ratios
зЂЃК
ЪЕР§ЗжИю
Mask RCNNдкFasterRCNNзюКѓРЉеЙСЫЗжРрКЭЛиЙщШЮЮёЃЌдіМгСЫвЛИіеыЖдУПвЛИіRoIЧјгђЕФЗжИюШЮЮёЁЃИУШЮЮёЪЧвЛИіМђЕЅЕФFCNЭјТчЁЃ
RoIAlignВйзї
вђЮЊRoIPoolВйзїЃЌЬЋЙ§гкДжБЉЃЌЕМжТЬиеїВугыдЪМЭМЯёЩЯЕФЖдгІЙиЯЕЮѓВюЬЋДѓЁОетЪЧFast/Faster
R-CNNЕФжївЊЮЪЬтЁПЃЌЫљвдЬсГіСЫRoIAlignВйзїЃЌПЩвдБЃСєПеМфЮЛжУЕФОЋЖШЁОpreserves
exact spatial locationsЁП
ИУВйзїЃЌЗЧГЃжЛЪЧаоИФСЫвЛЕуЕуЃЌЕЋЪЧзїгУЗЧГЃДѓЃЌФмЙЛЬсИпДѓИХ10%ЁЋ50%ЕФЗжИюОЋЖШ
НтёюКЯ
НЋЗжИюШЮЮёКЭЗжРрШЮЮёНтёюКЯ
RoI classificationЗжжЇНјааЗжРрдЄВт
FCNНјааЯёЫиМЖБ№ЕФЖрРрБ№ЗжРрдЄВтЁОЗжИюЁПЃЌЦфАќРЈЗжИюКЭЗжРрСНЗНУцШЮЮёЁЃ
зюжеFCNЪфГівЛИіKВуЕФmaskЃЌУПвЛВуЮЊвЛРрЃЌLogЪфГіЃЌгУ0.5зїЮЊуажЕНјааЖўжЕЛЏЃЌВњЩњБГОАКЭЧАОАЕФЗжИюMask
СщЛюад
ПђМмОЙ§ЗЧГЃаЁЕФИФЖЏКѓЃЌПЩвдНјааhuman pose estimation
НЋШЫЬхЕФУПвЛИіkeypointзїЮЊвЛИіРрБ№НјаабЕСЗКЭМьВт
ЪБМф
ИУЫуЗЈвђЮЊдкFaster RCNNЩЯдіМгвЛИіЗЧГЃаЁЕФШЮЮёЃЌМЦЫуСПдіМгЕФЗЧГЃаЁЃЌДгЖјПЩвдДяЕН5fpsЕФЫйЖШ
Mask R-CNN
| Faster
R-CNN has two outputs for each caniateobject,
a class label and a bounding-box offset; to
this we add a third branch that outputs the
object mask.
Mask R-CNN is thus a natural and intuitive idea.
But the additional mask output is distinct from
the class and box outputs, requiring extraction
of much finer spatial layout of an object.
|
RoI Loss:
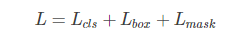
ЦфжаЃК
LclsLclsЮЊЗжРрЫ№ЪЇ
LboxLboxЮЊbounding-boxЛиЙщЫ№ЪЇЃЌЭЌFast R-CNN
LmaskLmaskЮЊЪЕР§ЗжИюЫ№ЪЇ
ЪфГіДѓаЁЮЊЃКK?m2K?m2ЃЌЦфжаKKЮЊРрБ№Ъ§СПЃЌmmБэЪОRoI AlignЬиеїЭМЕФДѓаЁ
ЖдУПвЛИіЯёЫигІгУsigmoidЃЌШЛКѓШЁRoIЩЯЫљгаЯёЫиЕФНЛВцьиЕФЦНОљжЕзїЮЊLmaskLmask
ЗДЯђДЋВЅЃКLossжЛЖдground-truthФЧвЛВуНјааМЦЫуКЭЗДЯьДЋВЅЁЃИУВйзїгааЇБмУтСЫРрБ№ОКељЃЌвВЪЙЕУЗжИюКЭЗжРрНтёюКЯЁОзїепЪЕбщвВжЄУїСЫетжжНтёюКЯгавЛЖЈЕФзїгУ[ВЮПМTable
2b]ЃЌжЎЧАЕФЗжИюШЮЮёШчFCNЃЌзюжеЖМЪЧеыЖдУПвЛИіЯёЫиЕуНјааsoftmaxЪфГіЃЌШЛКѓМЦЫуНЛВцьиLossЁП
жЛЖдground-truth kВуЩЯЕФmЁСmmЁСmИіЯёЫиМЦЫуЫљгаЕуЕФНЛВцьиЃЌВЂЧѓЦНОљ
For an Roi associated with ground-truth class k, LmaskLmask
is only defined on the k-th mask(other mask outputs
do not contributed to the loss)
Mask Representation
ВЛЭЌгкЦфЫћЕФRoIЬиеїЬсШЁЃЌзюКѓНЋRoIЬсШЁГЩвЛИіЙЬЖЈГЄЖШЕФЬиеїЯђСПvectorЃЌMask R-CNNзюжеНЋRoIЧјгђдЄВтГЦвЛИіmЁСmmЁСmЕФmask
ШчSPPNetзюжеЪфГіЕФЪЧвЛИіЙЬЖЈГЄЖШЕФЬиеїЯђСПЃЌЖЊЪЇСЫПеМфаХЯЂ
ИУВйзїгааЇЕФБЃСєСЫПеМфаХЯЂЃЌЕЋЪЧашвЊИќМгОЋШЗЕФЯёЫиЖдЦыВйзї
RoIAlignВйзї
ЮЊСЫТњзуMask RepresentationЕФОЋЖШвЊЧѓЃЌЬсГіСЫRoIAlignВйзї
БъзМЕФRoIPoolВйзїЃЌФмЙЛНЋRoIЬсШЁГЩвЛИіаЁЕФЬиеїВуЁО7x7ЁП
НЋfloating-numberЕФRoIСПЛЏЃЌРыЩЂЛЏГЩаЁЭјИёЃЌШЛКѓНјааmax poolingВйзїЃЌЩњГЩвЛИіЙЬЖЈДѓаЁЕФЬиеїЭМ
дкРыЩЂЛЏЙ§ГЬжаЃЌСЌајЕФзјБъxБЛЖдгІдкЬиеїВуЩЯЕФЮЛжУЮЊ[x16][x16]ЁОШЁећЁП
етжжВйзїЃЌЪЙЕУRoIЁОproposalЁПЖдгІЬиеїЭМЯёЩЯЕФЮЛжУЗЂЩњСЫЦЋвЦЃЌЕМжТЮѓВю
While this may not impact classification, which is
robust to small translations, it has a large negative
effect on predicting pixel-accurate masks.
RoIAlignВйзї
НЋfeatureВугыinputВуОЋШЗЖдЦы
ЪЙгУx16x16ДњЬц[x16][x16]
ЪЙгУЫЋЯпадВхжЕМЦЫуinputЖдгІRoI binЩЯЕФЫФИізјБъжЕ
ИУВйзїЖдЭјТчЕФФмСІЬсЩ§ЗЧГЃДѓЁОВЮПМTable 2cЁП
Network Architecture

ЙВЯэЛљДЁЭјТчЁОЬиеїЬсШЁЁП
жЎКѓЖдУПвЛИіRoIНјааЖрШЮЮёдЄВт
bounding-box recognition(cls & reg)
mask prediction
ЛљДЁЭјТч
ResNet
ResNeXt
FPN(Feature Pyramid Network)
FPN uses a top-down architecture with lateral connections
to build an in-network feature pyramid from a single-scale
input
ВЩгУResNet+FPNзїЮЊЛљДЁЭјТчЃЌзюжеЕФаЇЙћзюКУ
Implementation Detail
бЕСЗ
бљБОЩњГЩЃК
е§бљБОЃКRoIЃЈIoU>0.5ЃЉ
ИКбљБОЃКЦфЫћ
Mask Loss
жЛМЦЫуpostive roiЩЯЕФloss
maskЕФецжЕground-truthЃКЮЊRoIКЭground-truthЕФНЛМЏ
ВЮЪ§
mini-batchЮЊ2
УПеХЭМЯёВњЩњNИіRoIЧјгђЃЌЦфжае§ИКбљБОЕФБШР§ЮЊ1:3
N=64 for C4
N=256 for FPN
бЇЯАТЪЃК0.02/120k ЈC> 0.002
ЕќДњДЮЪ§ЃК160k
momentumЃК0.9
decayЃК0.0001
RPNВЮЪ§ЃК
5 scales
3 aspect ratios
ВтЪд
proposal
300 for C4
1000 for FPN
дкетаЉКђбЁЧјгђЩЯНјааbox regЃЌШЛКѓНјааnmsВйзї
maskжЛдЫаадкзюИпЕФ100ИіМьВтПђжаЃЌЪфГіK masksЁОжЛгУЕкk-th maskЁП
етЕуКЭбЕСЗВЛЭЌЃЌЕЋЪЧПЩвдгааЇЬсИпдЫаааЇТЪ
НЋmЁСxmЁСxЕФmask outputЫѕЗХЕНRoIДѓаЁЃЌВЂНјааЖўжЕЛЏЁО0.5уажЕЁП
ЪЕбщ
ЪЕбщвЛ
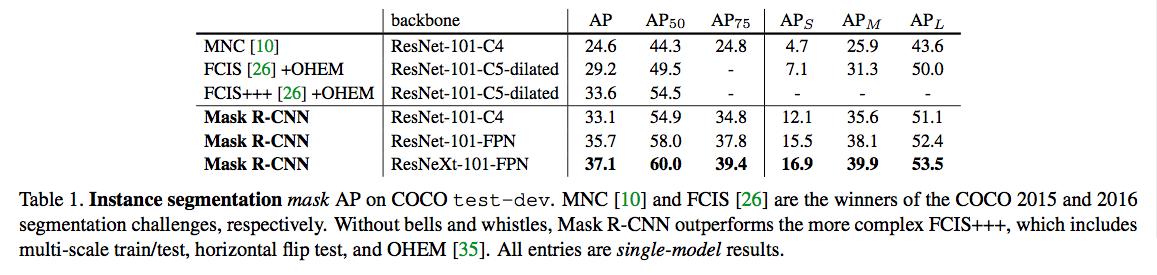
ЫЕУїЃК
1.Mask RCNNаЇЙћУїЯд
2.ResNeXt-101-FPNЭјТчЕФБэДяФмСІзюКУ


ЪЕбщЖў
ЙиМќИФНјЗжЮі
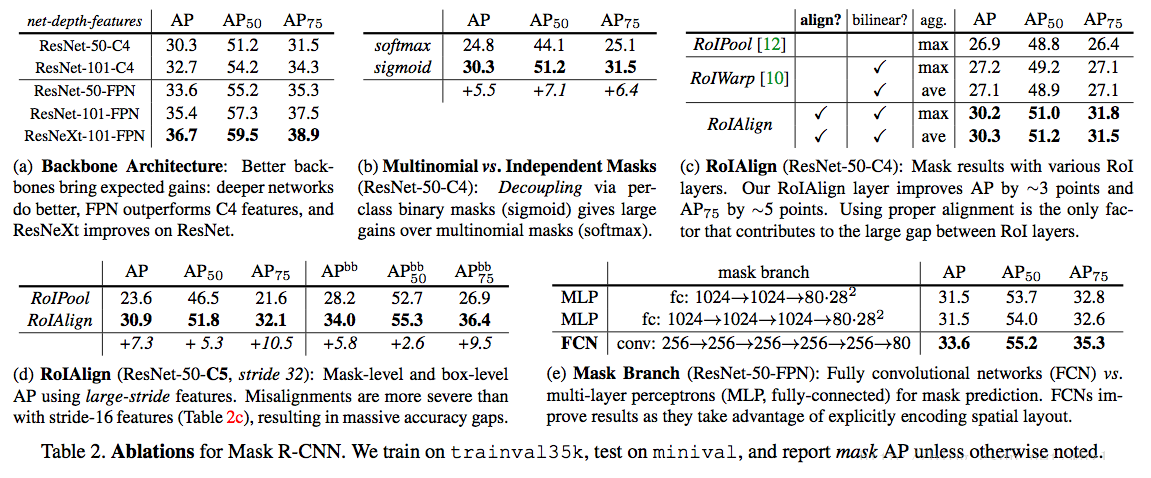
ЫЕУїЃК
Backbone Architecture
ЭјТчдНЩюЃЌаЇЙћдНКУ
Multinomial vs. Independent Masks
ЗжИюШЮЮёгыЗжРрШЮЮёНтёюКЯКѓЃЌаЇЙћИќКУ
class-Specific vs. Class-Agnostic Masks:
ЪфГіKИіmЁСmmЁСmИіЗжИюmaskКЭЪфГі1ИіmЁСmmЁСmИіЗжИюmaskЁОВЛЧјЗжРрБ№аХЯЂЁПНјааЖдБШЃЌЗЂЯжЧјБ№РрБ№ЗжИюКѓЃЌаЇЙћИќКУ
APДг29.7Щ§ЕНСЫ30.3
RoIAlign
ЭЈЙ§ЩЯЪіЕФЭМcЃЌdПЩвдПДГіЃЌИУВйзїФмЬсИпДѓИХ3points
RoiWarpВЩгУЫЋЯпадВхжЕЃЌЕЋЪЧУЛгаЖдinputКЭfeatureВузјБъНјааЖдЦыЃЌДгЖјаЇЙћБШRoIAlignВюКмЖр
Mask Branch
НјааЗжИюЕФЪБКђЃЌFCNвЊКУгкMLP
ЪЕбщШ§
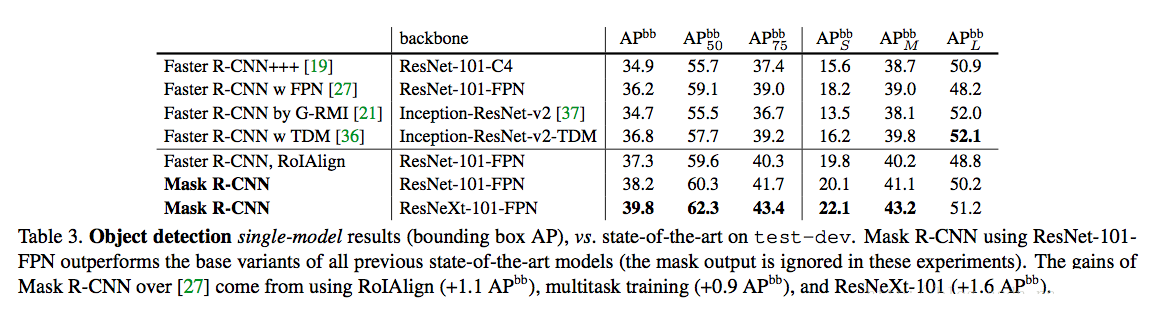
ФПБъМьВтBounding Box Detection
ЫЕУїЃК
RoIAlginзїгУЃК
ЕЅЖРЪЙгУFaster R-CNNКЭRoIAlignВйзїЃЌМьВтаЇЙћЬсЩ§СЫ%1mAP
ЫЕУїRoIAlignЖдФПБъМьВтаЇЙћгжвЛЖЈЕФАяжњ
ЖрШЮЮёЃК
ЗжИюФмЪЙFaster RCNNМьВтЬсЩ§1-2%mAP
ЛљДЁЭјТчЃК
ResNeXtЭјТчЪЙЕУFaster RCNNМьВтЬсЩ§СЫ1%mAP
ЪЕбщЫФ
ЪБМфВтЪд
ЫЕУїЃК
ВтЪд
ResNet-101-FPNЙВЯэRPNКЭMask R-CNN stagesЬиеїЃЌдЫааЪБМфДѓИХдк195msЁОNvidia
Tesla M40 GPUЁП+ 15msЁОresizing the outputs to the original
resolutionЁП
вђЮЊResNet101-C4ЛљДЁЭјТчДѓИХашвЊЁЋ400msЃЌвђДЫзїепВПЭЦМіЪЙгУИУЭјТч
бЕСЗ
ResNet-50-FPN: COCO trainval35kЈC> 32h
ResNet-101-FPN: COCO trainval35kЈC>44h
Mask R-CNN for Human Pose Estimation
Mask R-CNNПђМмОЙ§МђЕЅЕФаоИФОЭПЩвдНјааHuman Pose Estimation
РрБ№Ъ§СПЃКHuman PoseжаЕФkeypointsИіЪ§
НЋmЁСmmЁСmЗжИюmaskЕФlabelЃЏtargetБфГЩone-hotаЮЪН
targetЃКжЛгавЛИіpixelБъМЧЮЊЧАОА
ЖдmЁСmmЁСmИіЪфГіМЦЫуНЛВцьиЃЌзїЮЊlossЁОетбљПЩвдМЄРјЭјТчбЇЯАжЛМьВтЕЅИіЕуЁП
ЪфГіШдШЛЪЧKИіmЁСmmЁСmИіmask
ВЩгУResNet-FPNзїЮЊЛљДЁЭјТчЃЌ
ШЛКѓЭЈЙ§вЛЯЕСаЕФ3x3 512-dЕФОэЛ§НјааЬиеїШкКЯЃЌ
жЎКѓЃЌЭЈЙ§НтОэЛ§deconvНјааЩЯВЩбљЕН56x56ЁОдЪМЕФЪЧ28x28ЁП
ЯёЫидНИпЃЌаЇЙћдНКУ
бЕСЗ
Ъ§ОнМЏЃКCOCO trainval35k
randomly scales from [640, 800]
ВтЪдЕФЪБКђЃЌЙЬЖЈЮЊ800
ЕќДњДЮЪ§ЃК90K
бЇЯАТЪЃК0.02/60kЈC>0.002/8kЈC>0.0002
NMSЃК0.5
аЇЙћ

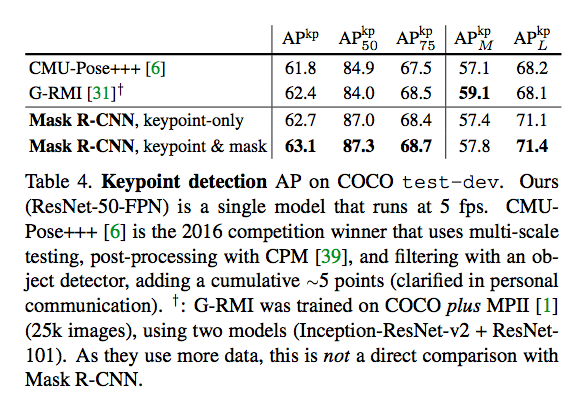
ЫЕУїЃК
ЯрБШНЯЦфЫћЗНЗЈЃЌИУЗНЗЈМђЕЅгааЇЃЌЫйЖШПь5fps
More importantly, we have a unified model that can
simultaneously predict boxes, segments, and keypoints
while running at 5fps.
ЖрШЮЮёаЇЙћИќКУ
Adding a segment branch(for the person
category) improves the APkp to 63.1ЁЃ
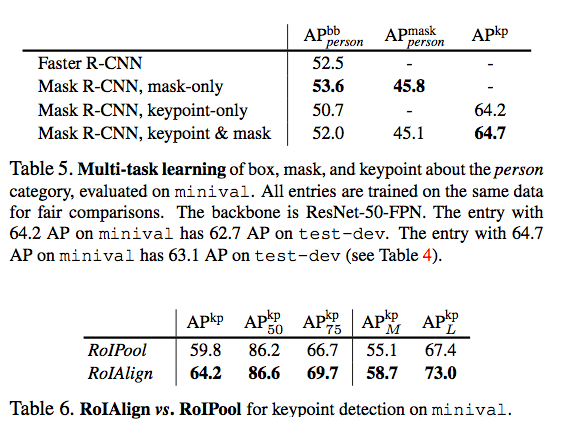
ЫЕУїЃК
ЖрШЮЮёаЇЙћКУ
Adding the mask branch to the box-only(i.e. Faster
R-CNN) or keypoint-only versions consistently improves
these tasksЁЃ
ЕЋЪЧдіМгkeypoint-onlyЩдЮЂгАЯьСЫAPЁОНіЯоИУЪЕбщЃЌВЛФмЭЦЙуЕНЦфЫћШЮЮёЁП
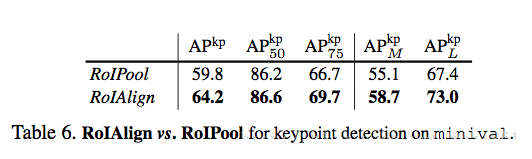
ЫЕУїЃК
ЖдгкHuman Pose EstimationШЮЮёЃЌRoIAlignвРШЛЦфЕНКмДѓЕФзїгУ
Experiments on Cityscapes


|





