| 编辑推荐: |
本文来自于machinelearnings。 文章主要引用需要的库,提供训练集,整理数据,迭代:编写代码+测试预测结果+调整模型,抽象,等方面介绍的。
|
|
理解聊天机器人的工作原理是非常重要的。聊天机器人内部一个非常重要的组件就是文本分类器。我们看一下文本分类器的神经网络(ANN)的内部工作原理。
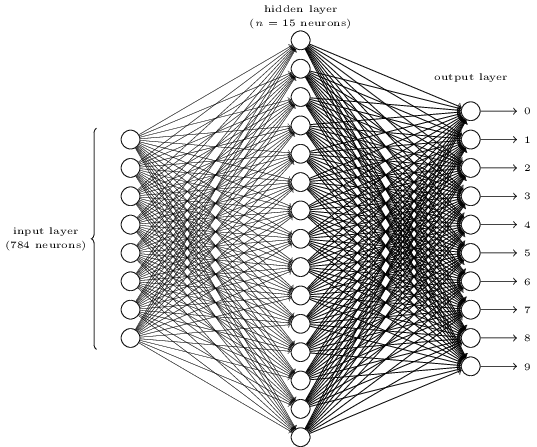
多层神经网络
我们将会使用2层网络(1个隐层)和一个“词包”的方法来组织我们的训练数据。文本分类有3个特点:模式匹配、算法、神经网络。虽然使用多项朴素贝叶斯算法的方法非常有效,但是它有3个致命的缺陷:
这个算法输出一个分数而不是一个概率。我们可以使用概率来忽略特定阈值以下的预测结果。这类似于忽略收音机中的噪声。
这个算法从一个样本中学习一个分类中包含什么,而不是一个分类中不包含什么。一个分类中不包含什么的的学习模式往往也很重要。
不成比例的大训练集的分类将会导致扭曲的分类分数,迫使算法相对于分类规模来调整输出分数,这并不理想。
和它“天真”的对手一样,这种分类器并不试图去理解句子的含义,而仅仅对它进行分类。事实上,所谓的“人工智能聊天机器人”并不理解语言,但那是另一个故事。
如果你刚接触人工神经网络,这是它的工作原理。
理解分类算法,请看这里。
我们来逐个分析文本分类器的每个部分。我们将按照以下顺序:
引用需要的库
提供训练集
整理数据
迭代:编写代码+测试预测结果+调整模型
抽象
代码在这里,我们使用ipython notebook这个在数据科学项目上非常高效的工具。代码语法是python。
我们首先导入自然语言工具包。我们需要一个可靠的方法将句子切分成词并且将单词词干化处理。
# use natural
language toolkit
import nltk
from nltk.stem.lancaster import LancasterStemmer
import os
import json
import datetime
stemmer = LancasterStemmer() |
下面是我们的训练集,12个句子属于3个类别(“意图”)。
# 3 classes of
training data
training_data = []
training_data.append({"class":"greeting",
"sentence":"how are you?"})
training_data.append({"class":"greeting",
"sentence":"how is your day?"})
training_data.append({"class":"greeting",
"sentence":"good day"})
training_data.append({"class":"greeting",
"sentence":"how is it going today?"})
training_data.append({"class":"goodbye",
"sentence":"have a nice day"})
training_data.append({"class":"goodbye",
"sentence":"see you later"})
training_data.append({"class":"goodbye",
"sentence":"have a nice day"})
training_data.append({"class":"goodbye",
"sentence":"talk to you soon"})
training_data.append({"class":"sandwich",
"sentence":"make me a sandwich"})
training_data.append({"class":"sandwich",
"sentence":"can you make a sandwich?"})
training_data.append({"class":"sandwich",
"sentence":"having a sandwich today?"})
training_data.append({"class":"sandwich",
"sentence":"what's for lunch?"})
print ("%s sentences in training data"
% len(training_data)) |
| 12 sentences
in training data |
现在我们可以将数据结构组织为:documents, classes 和words.
words = []
classes = []
documents = []
ignore_words = ['?']
# loop through each sentence in our training data
for pattern in training_data:
# tokenize each word in the sentence
w = nltk.word_tokenize(pattern['sentence'])
# add to our words list
words.extend(w)
# add to documents in our corpus
documents.append((w, pattern['class']))
# add to our classes list
if pattern['class'] not in classes:
classes.append(pattern['class'])
# stem and lower each word and remove duplicates
words = [stemmer.stem(w.lower()) for w in words
if w not in ignore_words]
words = list(set(words))
# remove duplicates
classes = list(set(classes))
print (len(documents), "documents")
print (len(classes), "classes", classes)
print (len(words), "unique stemmed words",
words) |
12 documents
3 classes ['greeting', 'goodbye', 'sandwich']
26 unique stemmed words ['sandwich', 'hav', 'a',
'how', 'for', 'ar', 'good', 'mak', 'me', 'it',
'day', 'soon', 'nic', 'lat', 'going', 'you', 'today',
'can', 'lunch', 'is', "'s", 'see', 'to',
'talk', 'yo', 'what']
|
注意每个单词都是词根并且小写。词根有助于机器将“have”和“having”等同起来。同时我们也不关心大小写。

我们将训练集中的每个句子转换为词包。
# create our training
data
training = []
output = []
# create an empty array for our output
output_empty = [0] * len(classes)
# training set, bag of words for each sentence
for doc in documents:
# initialize our bag of words
bag = []
# list of tokenized words for the pattern
pattern_words = doc[0]
# stem each word
pattern_words = [stemmer.stem(word.lower()) for
word in pattern_words]
# create our bag of words array
for w in words:
bag.append(1) if w in pattern_words else bag.append(0)
training.append(bag)
# output is a '0' for each tag and '1' for current
tag
output_row = list(output_empty)
output_row[classes.index(doc[1])] = 1
output.append(output_row)
# sample training/output
i = 0
w = documents[i][0]
print ([stemmer.stem(word.lower()) for word in
w])
print (training[i])
print (output[i]) |
['how', 'ar',
'you', '?']
[0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[1, 0, 0] |
上面的步骤是文本分类中的一个经典步骤:每个训练句子被转化为一个包含0和1的数组,而不是语料库中包含独特单词的数组。
| ['how', 'are',
'you', '?'] |
被词干化为:
| ['how', 'ar',
'you', '?'] |
然后转换为输入词包的形式:1代表单词存在于词包中(忽略问号?)
[0, 0, 0, 1,
0, 1, 0, 0, 0, 0, 0, 0, 0 , 0, 0 , 1, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0]
|
输出:第一类
注意:一个句子可以有多个分类,也可以没有。确保理解上面的内容,仔细阅读代码直到你理解它。
机器学习的第一步是要有干净的数据

接下来我们的学习2层神经网络的核心功能。
如果你是人工神经网络新手,这里是它的工作原理
我们使用numpy,原因是它可以提供快速的矩阵乘法运算。
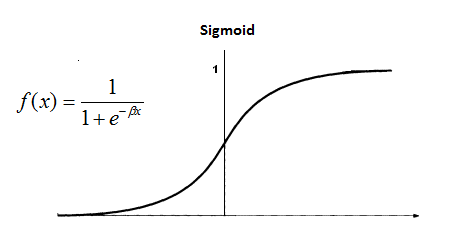
我们使用sigmoid函数对值进行归一化,用其导数来衡量错误率。通过不断迭代和调整,直到错误率低到一个可以接受的值。
下面我们也实现了bag-of-words函数,将输入的一个句子转化为一个包含0和1的数组。这就是转换训练数据,得到正确的转换数据至关重要。
import numpy as
np
import time
# compute sigmoid nonlinearity
def sigmoid(x):
output = 1/(1+np.exp(-x))
return output
# convert output of sigmoid function to its derivative
def sigmoid_output_to_derivative(output):
return output*(1-output)
def clean_up_sentence(sentence):
# tokenize the pattern
sentence_words = nltk.word_tokenize(sentence)
# stem each word
sentence_words = [stemmer.stem(word.lower()) for
word in sentence_words]
return sentence_words
# return bag of words array: 0 or 1 for each word
in the bag that exists in the sentence
def bow(sentence, words, show_details=False):
# tokenize the pattern
sentence_words = clean_up_sentence(sentence)
# bag of words
bag = [0]*len(words)
for s in sentence_words:
for i,w in enumerate(words):
if w == s:
bag[i] = 1
if show_details:
print ("found in bag: %s" % w)
return(np.array(bag))
def think(sentence, show_details=False):
x = bow(sentence.lower(), words, show_details)
if show_details:
print ("sentence:", sentence, "n
bow:", x)
# input layer is our bag of words
l0 = x
# matrix multiplication of input and hidden layer
l1 = sigmoid(np.dot(l0, synapse_0))
# output layer
l2 = sigmoid(np.dot(l1, synapse_1))
return l2 |
现在我们对神经网络训练函数进行编码,创造连接权重。别太激动,这主要是矩阵乘法——来自中学数学课堂。

我们现在准备去构建我们的神经网络模型,我们将连接权重保存为json文件。
你应该尝试不同的“α”(梯度下降参数),看看它是如何影响错误率。此参数有助于错误调整,并找到最低错误率:
synapse_0 += alpha * synapse_0_weight_update
我们在隐藏层使用了20个神经元,你可以很容易地调整。这些参数将随着于您的训练数据规模的不同而不同,将错误率调整到低于10
^ – 3是比较合理的。
X = np.array(training)
y = np.array(output)
start_time = time.time()
train(X, y, hidden_neurons=20, alpha=0.1, epochs=100000,
dropout=False, dropout_percent=0.2)
elapsed_time = time.time() - start_time
print ("processing time:", elapsed_time,
"seconds") |
Training with
20 neurons, alpha:0.1, dropout:False
Input matrix: 12x26 Output matrix: 1x3
delta after 10000 iterations:0.0062613597435
delta after 20000 iterations:0.00428296074919
delta after 30000 iterations:0.00343930779307
delta after 40000 iterations:0.00294648034566
delta after 50000 iterations:0.00261467859609
delta after 60000 iterations:0.00237219554105
delta after 70000 iterations:0.00218521899378
delta after 80000 iterations:0.00203547284581
delta after 90000 iterations:0.00191211022401
delta after 100000 iterations:0.00180823798397
saved synapses to: synapses.json
processing time: 6.501226902008057 seconds
|
synapse.json文件中包含了全部的连接权重,这就是我们的模型。

一旦连接权重已经计算完成,对于分类来说只需要classify()函数了:大约15行代码
备注:如果训练集有变化,我们的模型需要重新计算。对于非常大的数据集,这需要较长的时间。
现在我们可以生成一个句子属于一个或者多个分类的概率了。它的速度非常快,这是因为我们之前定义的think()函数中的点积运算。
# probability
threshold
ERROR_THRESHOLD = 0.2
# load our calculated synapse values
synapse_file = 'synapses.json'
with open(synapse_file) as data_file:
synapse = json.load(data_file)
synapse_0 = np.asarray(synapse['synapse0'])
synapse_1 = np.asarray(synapse['synapse1'])
def classify(sentence, show_details=False):
results = think(sentence, show_details)
results = [[i,r] for i,r in enumerate(results)
if r>ERROR_THRESHOLD ]
results.sort(key=lambda x: x[1], reverse=True)
return_results =[[classes[r[0]],r[1]] for r in
results]
print ("%s n classification: %s" % (sentence,
return_results))
return return_results
classify("sudo make me a sandwich")
classify("how are you today?")
classify("talk to you tomorrow")
classify("who are you?")
classify("make me some lunch")
classify("how was your lunch today?")
print()
classify("good day", show_details=True) |
<strong>sudo
make me a sandwich </strong>
[['sandwich', 0.99917711814437993]]
<strong>how are you today? </strong>
[['greeting', 0.99864563257858363]]
<strong>talk to you tomorrow </strong>
[['goodbye', 0.95647479275905511]]
<strong>who are you? </strong>
[['greeting', 0.8964283843977312]]
<strong>make me some lunch</strong>
[['sandwich', 0.95371924052636048]]
<strong>how was your lunch today? </strong>
[['greeting', 0.99120883810944971], ['sandwich',
0.31626066870883057]]
|
你可以用其它语句、不同概率来试验几次,也可以添加训练数据来改进/扩展当前的模型。尤其注意用很少的训练数据就得到稳定的预测结果。
有一些句子将会产生多个预测结果(高于阈值)。你需要给你的程序设定一个合适的阈值。并非所有的文本分类方案都是相同的:一些预测情况比其他预测需要更高的置信水平。
最后这个分类结果展示了一些内部的细节:
found in bag:
good
found in bag: day
sentence: **good day**
bow: [0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0]
good day
[['greeting', 0.99664077655648697]]
|
从这个句子的词包中可以看到,有两个单词和我们的词库是匹配的。同时我们的神经网络从这些 0 代表的非匹配词语中学习了。
如果提供一个仅仅有一个常用单词 ‘a’ 被匹配的句子,那我们会得到一个低概率的分类结果A:
found in bag:
a
sentence: **a burrito! **
bow: [0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0]
a burrito!
[['sandwich', 0.61776860634647834]] |
现在你已经掌握了构建聊天机器人的一些基础知识结构,它能处理大量不同的意图,并且对于有限或者海量的训练数据都能很好的适配。想要为某个意图添加一个或者多个响应实在轻而易举,就不必多讲了。
|








