| БрМЭЦМі: |
БОЮФРДздгкsegmentfaultЃЌЮФеТЪЙгУЭМЦЌМгДњТыЕФаЮЪННВНтCNNЭјТчЃЌВЂЖдУПВуЕФЪфГіНјааПЩЪгЛЏЁЃ |
|
ШчНёЃЌЛњЦївбОФмЙЛдкРэНтЁЂЪЖБ№ЭМЯёжаЕФЬиеїКЭЖдЯѓЕШСьгђЪЕЯж99ЃЅМЖБ№ЕФзМШЗТЪЁЃЩњЛюжаЃЌЮвУЧУПЬьЖМЛсдЫгУЕНетвЛЕуЃЌБШШчЃЌжЧФмЪжЛњХФееЕФЪБКђФмЙЛЪЖБ№СГВПЁЂдкРрЫЦгкЙШИшЫбЭМжаЫбЫїЬиЖЈееЦЌЁЂДгЬѕаЮТыЩЈУшЮФБОЛђЩЈУшЪщМЎЕШЁЃдьОЭЛњЦїФмЙЛЛёЕУдкетаЉЪгОѕЗНУцШЁЕУгХвьадФмПЩФмЪЧдДгквЛжжЬиЖЈРраЭЕФЩёОЭјТчЁЊЁЊОэЛ§ЩёОЭјТчЃЈCNNЃЉЁЃШчЙћФуЪЧвЛИіЩюЖШбЇЯААЎКУепЃЌФуПЩФмдчвбЬ§ЫЕЙ§етжжЩёОЭјТчЃЌВЂЧвПЩФмвбОЪЙгУвЛаЉЩюЖШбЇЯАПђМмБШШчcaffeЁЂTensorFlowЁЂpytorchЪЕЯжСЫвЛаЉЭМЯёЗжРрЦїЁЃШЛЖјЃЌетШдШЛДцдквЛИіЮЪЬтЃКЪ§ОнЪЧШчКЮдкШЫЙЄЩёОЭјТчДЋЫЭвдМАМЦЫуЛњЪЧШчКЮДгжабЇЯАЕФЁЃЮЊСЫДгЭЗПЊЪМЛёЕУЧхЮњЕФЪгНЧЃЌБОЮФНЋЭЈЙ§ЖдУПвЛВуНјааПЩЪгЛЏвдЩюШыРэНтОэЛ§ЩёОЭјТчЁЃ

ОэЛ§ЩёОЭјТч
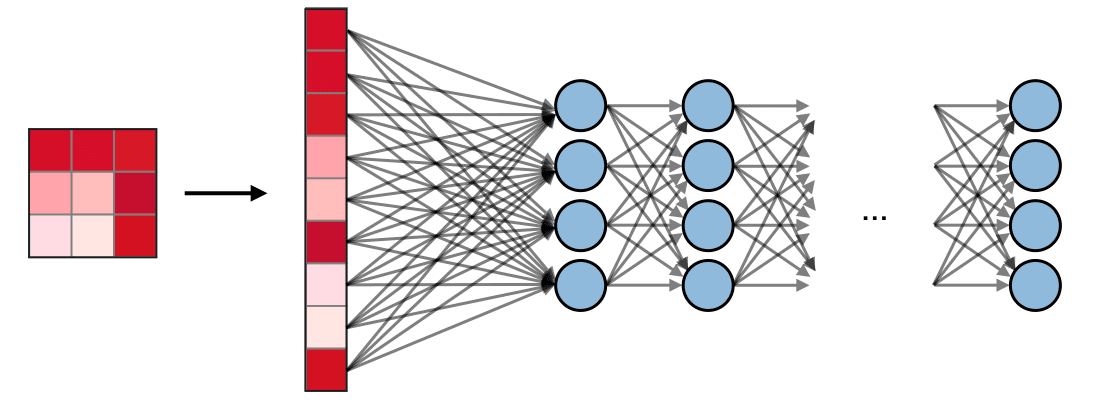
дкбЇЯАОэЛ§ЩёОЭјТчжЎЧАЃЌЪзЯШвЊСЫНтЩёОЭјТчЕФЙЄзїдРэЁЃЩёОЭјТчЪЧФЃЗТШЫРрДѓФдРДНтОіИДдгЮЪЬтВЂдкИјЖЈЪ§ОнжаевЕНФЃЪНЕФвЛжжЗНЗЈЁЃдкЙ§ШЅМИФъжаЃЌетаЉЩёОЭјТчЫуЗЈвбОГЌдНСЫаэЖрДЋЭГЕФЛњЦїбЇЯАКЭМЦЫуЛњЪгОѕЫуЗЈЁЃЁАЩёОЭјТчЁБЪЧгЩМИВуЛђЖрВузщГЩЃЌВЛЭЌВужаОпгаЖрИіЩёОдЊЁЃУПИіЩёОЭјТчЖМгавЛИіЪфШыКЭЪфГіВуЃЌИљОнЮЪЬтЕФИДдгаддіМгвўВиВуЕФИіЪ§ЁЃвЛЕЉНЋЪ§ОнЫЭШыЭјТчжаЃЌЩёОдЊОЭЛсбЇЯАВЂНјааФЃЪНЪЖБ№ЁЃвЛЕЉЩёОЭјТчФЃаЭБЛбЕСЗКУКѓЃЌФЃаЭОЭФмЙЛдЄВтВтЪдЪ§ОнЁЃ
СэвЛЗНУцЃЌCNNЪЧвЛжжЬиЪтРраЭЕФЩёОЭјТчЃЌЫќдкЭМЯёСьгђжаБэЯжЕУЗЧГЃКУЁЃИУЭјТчЪЧгЩYanLeCunnдк1998ФъЬсГіЕФЃЌБЛгІгУгкЪ§зжЪжаДЬхЪЖБ№ШЮЮёжаЁЃЦфЫќгІгУСьгђАќРЈгявєЪЖБ№ЁЂЭМЯёЗжИюКЭЮФБОДІРэЕШЁЃдкCNNБЛЗЂУїжЎЧАЃЌЖрВуИажЊЛњЃЈMLPЃЉБЛгУгкЙЙНЈЭМЯёЗжРрЦїЁЃЭМЯёЗжРрШЮЮёЪЧжИДгЖрВЈЖЮЃЈВЪЩЋЁЂКкАзЃЉЙтеЄЭМЯёжаЬсШЁаХЯЂРрЕФШЮЮёЁЃMLPашвЊИќЖрЕФЪБМфКЭПеМфРДВщевЭМЦЌжаЕФаХЯЂЃЌвђЮЊУПИіЪфШыдЊЫиЖМгыЯТвЛВужаЕФУПИіЩёОдЊСЌНгЁЃЖјCNNЭЈЙ§ЪЙгУГЦЮЊОжВПСЌНгЕФИХФюБмУтетаЉЃЌНЋУПИіЩёОдЊСЌНгЕНЪфШыОиеѓЕФОжВПЧјгђЁЃетЭЈЙ§дЪаэЭјТчЕФВЛЭЌВПЗжзЈУХДІРэжюШчЮЦРэЛђжиИДФЃЪНЕФИпМЖЬиеїРДзюаЁЛЏВЮЪ§ЕФЪ§СПЁЃЯТУцЭЈЙ§БШНЯЫЕУїЩЯЪіетвЛЕуЁЃ
БШНЯMLPКЭCNN
вђЮЊЪфШыЭМЯёЕФДѓаЁЮЊ28x28=784ЃЈMNISTЪ§ОнМЏЃЉЃЌMLPЕФЪфШыВуЩёОдЊзмЪ§НЋЮЊ784ЁЃЭјТчдЄВтИјЖЈЪфШыЭМЯёжаЕФЪ§зжЃЌЪфГіЪ§зжЗЖЮЇЪЧ0-9ЁЃдкЪфГіВуЃЌвЛАуЗЕЛиЕФЪЧРрБ№ЗжЪ§ЃЌБШШчЫЕИјЖЈЪфШыЪЧЪ§зжЁА3ЁБЕФЭМЯёЃЌФЧУДдкЪфГіВужаЃЌЯргІЕФЩёОдЊЁА3ЁБгыЦфЫќЩёОдЊЯрБШОпгаИќИпЕФРрБ№ЗжЪ§ЁЃетРягжЛсГіЯжвЛИіЮЪЬтЃЌФЃаЭашвЊАќКЌЖрЩйИівўВиВуЃЌУПВугІИУАќКЌЖрЩйЩёОдЊЃПетаЉЖМЪЧашвЊШЫЮЊЩшжУЕФЃЌЯТУцЪЧвЛИіЙЙНЈMLPФЃаЭЕФР§згЃК
Num_classes
= 10
Model = Sequntial()
Model.add(Dense(512, activation=ЁЏreluЁЏ, input_shape=(784,
)))
Model.add(Dropout(0.2))
Model.add(Dense(512, activation=ЁЏreluЁЏ))
Model.add(Dropout(0.2))
Model.add(Dense(num_classes, activation=ЁЏsoftmaxЁЏ)) |
ЩЯУцЕФДњТыЦЌЖЮЪЧЪЙгУKerasПђМмЪЕЯжЃЈднЪБКіТдгяЗЈДэЮѓЃЉЃЌИУДњТыБэУїЕквЛИівўВиВужага512ИіЩёОдЊЃЌСЌНгЕНЮЌЖШЮЊ784ЕФЪфШыВуЁЃвўВиВуКѓУцМгвЛИіdropoutВуЃЌЖЊЦњБШР§ЩшжУЮЊ0.2ЃЌИУВйзїдквЛЖЈГЬЖШЩЯПЫЗўЙ§ФтКЯЕФЮЪЬтЁЃжЎКѓдйДЮЬэМгЕкЖўИівўВиВуЃЌвВОпга512ЙШИшЩёОдЊЃЌШЛКѓдйЬэМгвЛИіdropoutВуЁЃзюКѓЃЌЪЙгУАќКЌ10ИіРрЕФЪфГіВуЭъГЩФЃаЭЙЙНЈЁЃЦфЪфГіЕФЯђСПжаОпгазюДѓжЕЕФИУРрНЋЪЧФЃаЭЕФдЄВтНсЙћЁЃ
етжжЖрВуИажЊЦїЕФвЛИіШБЕуЪЧВугыВужЎМфЭъШЋСЌНгЃЌетЕМжТФЃаЭашвЊЛЈЗбИќЖрЕФбЕСЗЪБМфКЭВЮЪ§ПеМфЁЃВЂЧвЃЌMLPжЛНгЪмЯђСПзїЮЊЪфШыЁЃ

ОэЛ§ЪЙгУЯЁЪшСЌНгЕФВуЃЌВЂЧвЦфЪфШыПЩвдЪЧОиеѓЃЌгХгкMLPЁЃЪфШыЬиеїСЌНгЕНОжВПБрТыНкЕуЁЃдкMLPжаЃЌУПИіНкЕуЖМгаФмСІгАЯьећИіЭјТчЁЃЖјCNNНЋЭМЯёЗжНтЮЊЧјгђЃЈЯёЫиЕФаЁОжВПЧјгђЃЉЃЌУПИівўВиНкЕугыЪфГіВуЯрЙиЃЌЪфГіВуНЋНгЪеЕФЪ§ОнНјаазщКЯвдВщевЯргІЕФФЃЪНЁЃ

МЦЫуЛњШчКЮВщПДЪфШыЕФЭМЯёЃП
ПДзХЭМЦЌВЂНтЪЭЦфКЌвхЃЌетЖдгкШЫРрРДЫЕКмМђЕЅЕФвЛМўЪТЧщЁЃЮвУЧЩњЛюдкЪРНчЩЯЃЌЮвУЧЪЙгУздМКЕФжївЊИаОѕЦїЙйЃЈМДблОІЃЉХФЩуЛЗОГПьееЃЌШЛКѓНЋЦфДЋЕнЕНЪгЭјФЄЁЃетвЛЧаПДЦ№РДЖМКмгаШЄЁЃЯждкШУЮвУЧЯыЯѓвЛЬЈМЦЫуЛњвВдкзіЭЌбљЕФЪТЧщЁЃ
дкМЦЫуЛњжаЃЌЪЙгУвЛзщЮЛгк0ЕН255ЗЖЮЇФкЕФЯёЫижЕРДНтЪЭЭМЯёЁЃМЦЫуЛњВщПДетаЉЯёЫижЕВЂРэНтЫќУЧЁЃеЇвЛПДЃЌЫќВЂВЛжЊЕРЭМЯёжагаЪВУДЮяЬхЃЌвВВЛжЊЕРЦфбеЩЋЁЃЫќжЛФмЪЖБ№ГіЯёЫижЕЃЌЭМЯёЖдгкМЦЫуЛњРДЫЕОЭЯрЕБгквЛзщЯёЫижЕЁЃжЎКѓЃЌЭЈЙ§ЗжЮіЯёЫижЕЃЌЫќЛсТ§Т§СЫНтЭМЯёЪЧЛвЖШЭМЛЙЪЧВЪЩЋЭМЁЃЛвЖШЭМжЛгавЛИіЭЈЕРЃЌвђЮЊУПИіЯёЫиДњБэвЛжжбеЩЋЕФЧПЖШЁЃ0БэЪОКкЩЋЃЌ255БэЪОАзЩЋЃЌЖўепжЎМфЕФжЕБэУїЦфЫќЕФВЛЭЌЕШМЖЕФЛвЛвЩЋЁЃВЪЩЋЭМЯёгаШ§ИіЭЈЕРЃЌКьЩЋЁЂТЬЩЋКЭРЖЩЋЃЌЫќУЧЗжБ№ДњБэ3жжбеЩЋЃЈШ§ЮЌОиеѓЃЉЕФЧПЖШЃЌЕБШ§епЕФжЕЭЌЪББфЛЏЪБЃЌЫќЛсВњЩњДѓСПбеЩЋЃЌРрЫЦгквЛИіЕїЩЋАхЁЃжЎКѓЃЌМЦЫуЛњЪЖБ№ЭМЯёжаЮяЬхЕФЧњЯпКЭТжРЊЁЃЁЃ
ЯТУцЪЙгУPyTorchМгдиЪ§ОнМЏВЂдкЭМЯёЩЯгІгУЙ§ТЫЦїЃК
# Load the libraries
import torch
import numpy as np
from torchvision import datasets
import torchvision.transforms as transforms
# Set the parameters
num_workers = 0
batch_size = 20
# Converting the Images to tensors using Transforms
transform = transforms.ToTensor()
train_data = datasets.MNIST(root='data', train=True,
download=True, transform=transform)
test_data = datasets.MNIST(root='data', train=False,
download=True, transform=transform)
# Loading the Data
train_loader = torch.utils.data.DataLoader(train_data,
batch_size=batch_size,
num_workers=num_workers)
test_loader = torch.utils.data.DataLoader(test_data,
batch_size=batch_size,
num_workers=num_workers)
import matplotlib.pyplot as plt
%matplotlib inline
dataiter = iter(train_loader)
images, labels = dataiter.next()
images = images.numpy()
# Peeking into dataset
fig = plt.figure(figsize=(25, 4))
for image in np.arange(20):
ax = fig.add_subplot(2, 20/2, image+1, xticks=[],
yticks=[])
ax.imshow(np.squeeze(images[image]), cmap='gray')
ax.set_title(str(labels[image].item())) |

ЯТУцПДПДШчКЮНЋЕЅИіЭМЯёЪфШыЩёОЭјТчжаЃК
img = np.squeeze(images[7])
fig = plt.figure(figsize = (12,12))
ax = fig.add_subplot(111)
ax.imshow(img, cmap='gray')
width, height = img.shape
thresh = img.max()/2.5
for x in range(width):
for y in range(height):
val = round(img[x][y],2) if img[x][y] !=0 else
0
ax.annotate(str(val), xy=(y,x),
color='white' if img[x][y]<thresh else 'black') |
ЩЯЪіДњТыНЋЪ§зж'3'ЭМЯёЗжНтЮЊЯёЫиЁЃдквЛзщЪжаДЪ§зжжаЃЌЫцЛњбЁдёЁА3ЁБЁЃВЂЧвНЋЪЕМЪЯёЫижЕЃЈ0-255
ЃЉБъзМЛЏЃЌВЂНЋЫќУЧЯожЦдк0ЕН1ЕФЗЖЮЇФкЁЃЙщвЛЛЏЕФВйзїФмЙЛМгПьФЃаЭбЕСЗЪеСВЫйЖШЁЃ
ЙЙНЈЙ§ТЫЦї
Й§ТЫЦїЃЌЙЫУћЫМвхЃЌОЭЪЧЙ§ТЫаХЯЂЁЃдкЪЙгУCNNДІРэЭМЯёЪБЃЌЙ§ТЫЯёЫиаХЯЂЁЃЮЊЪВУДашвЊЙ§ТЫФиЃЌМЦЫуЛњгІИУОРњРэНтЭМЯёЕФбЇЯАЙ§ГЬЃЌетгыКЂзгбЇЯАЙ§ГЬЗЧГЃЯрЫЦЃЌЕЋбЇЯАЪБМфЛсЩйЕФЖрЁЃМђЖјбджЎЃЌЫќЭЈЙ§ДгЭЗбЇЯАЃЌШЛКѓДгЪфШыВуДЋЕНЪфГіВуЁЃвђДЫЃЌЭјТчБиаыЪзЯШжЊЕРЭМЯёжаЕФЫљгадЪМВПЗжЃЌМДБпдЕЁЂТжРЊКЭЦфЫќЕЭМЖЬиеїЁЃМьВтЕНетаЉЕЭМЖЬиеїжЎКѓЃЌДЋЕнИјКѓУцИќЩюЕФвўВиВуЃЌЬсШЁИќИпМЖЁЂИќГщЯѓЕФЬиеїЁЃЙ§ТЫЦїЬсЙЉСЫвЛжжЬсШЁгУЛЇашвЊЕФаХЯЂЕФЗНЪНЃЌЖјВЛЪЧУЄФПЕиДЋЕнЪ§ОнЃЌвђЮЊМЦЫуЛњВЛЛсРэНтЭМЯёЕФНсЙЙЁЃдкГѕЪМЧщПіЯТЃЌПЩвдЭЈЙ§ПМТЧЬиЖЈЙ§ТЫЦїРДЬсШЁЕЭМЖЬиеїЃЌетРяЕФТЫВЈЦївВЪЧвЛзщЯёЫижЕЃЌРрЫЦгкЭМЯёЁЃПЩвдРэНтЮЊСЌНгОэЛ§ЩёОЭјТчжаЕФШЈжиЁЃетаЉШЈжиЛђТЫВЈЦїгыЪфШыЯрГЫвдЕУЕНжаМфЭМЯёЃЌУшЛцСЫМЦЫуЛњЖдЭМЯёЕФВПЗжРэНтЁЃжЎКѓЃЌетаЉжаМфВуЪфГіНЋгыЖрИіЙ§ТЫЦїЯрГЫвдРЉеЙЦфЪгЭМЁЃШЛКѓЬсШЁЕНвЛаЉГщЯѓЕФаХЯЂЃЌБШШчШЫСГЕШЁЃ
ОЭЁАЙ§ТЫЁБЖјбдЃЌЮвУЧгаКмЖрРраЭЕФЙ§ТЫЦїЁЃБШШчФЃК§ТЫОЕЁЂШёЛЏТЫОЕЁЂБфССЁЂБфАЕЁЂБпдЕМьВтЕШТЫОЕЁЃ
ЯТУцгУвЛаЉДњТыЦЌЖЮРДРэНтЙ§ТЫЦїЕФЬиеїЃК
Import matplotlib.pyplot
as plt
Import matplotib.image as mpimg
Import cv2
Import numpy as np
Image = mpimg.imread(ЁЎdog.jpgЁЏ)
Plt.imshow(image) |

# зЊЛЛЮЊЛвЖШЭМ
gray = cv2.cvtColor(image, cv2.COLOR_RB2GRAY)
# ЖЈвхsobelЙ§ТЫЦї
sobel = np.array([-1, -2, -1],
[0, 0, 0],
[1, 2, 1]))
# гІгУsobelЙ§ТЫЦї
Filtered_image = cv2.filter2D(gray, -1, sobel_y)
# ЛЭМ
Plt.imshow(filtered_image, cmp=ЁЏgrayЁЏ) |

вдЩЯЪЧгІгУsobelБпдЕМьВтТЫОЕКѓЭМЯёЕФбљзгЃЌ ПЩвдПДЕНМьВтГіТжРЊаХЯЂЁЃ
ЭъећЕФCNNНсЙЙ
ЕНФПЧАЮЊжЙЃЌвбОПДЕНСЫШчКЮЪЙгУТЫОЕДгЭМЯёжаЬсШЁЬиеїЁЃЯждквЊЭъГЩећИіОэЛ§ЩёОЭјТчЃЌcnnЪЙгУЕФВуЪЧЃК
1.ОэЛ§ВуЃЈConvolutional layerЃЉ
2.ГиВу(Pooling layer)
3.ШЋСЌНгВу(fully connected layer)
ЕфаЭЕФcnnЭјТчНсЙЙЪЧгЩЩЯЪіШ§РрВуЙЙГЩЃК

ЯТУцШУЮвУЧПДПДУПИіЭМВуЦ№ЕНЕФЕФзїгУЃК
* ОэЛ§ВуЃЈCONVЃЉЁЊЁЊЪЙгУЙ§ТЫЦїжДааОэЛ§ВйзїЁЃвђЮЊЫќЩЈУшЪфШыЭМЯёЕФГпДчЁЃЫќЕФГЌВЮЪ§АќРЈТЫВЈЦїДѓаЁЃЌПЩвдЪЧ2x2ЁЂ3x3ЁЂ4x4ЁЂ5x5ЃЈЛђЦфЫќЃЉКЭВНГЄSЁЃНсЙћЪфГіOГЦЮЊЬиеїгГЩфЛђМЄЛюгГЩфЃЌОпгаЪЙгУЪфШыВуМЦЫуЕФЫљгаЬиеїКЭЙ§ТЫЦїЁЃЯТУцУшЛцСЫгІгУОэЛ§ЕФЙЄзїЙ§ГЬЃК

ГиЛЏВуЃЈPOOLЃЉЁЊЁЊгУгкЬиеїЕФЯТВЩбљЃЌЭЈГЃдкОэЛ§ВужЎКѓгІгУЁЃГиЛЏДІРэЗНЪНгаЖржжРраЭЃЌГЃМћЕФЪЧзюДѓГиЛЏЃЈmax
poolingЃЉКЭЦНОљГиЛЏЃЈave poolingЃЉЃЌЗжБ№ВЩгУЬиеїЕФзюДѓжЕКЭЦНОљжЕЁЃЯТУцУшЪіСЫГиЛЏЕФЙЄзїЙ§ГЬЃК


ШЋСЌНгВуЃЈFCЃЉЁЊЁЊдкеЙПЊЕФЬиеїЩЯНјааВйзїЃЌЦфжаУПИіЪфШыСЌНгЕНЫљгаЕФЩёОдЊЃЌЭЈГЃдкЭјТчФЉЖЫгУгкНЋвўВиВуСЌНгЕНЪфГіВуЃЌЯТЭМеЙЪОШЋСЌНгВуЕФЙЄзїЙ§ГЬЃК
дкPyTorchжаПЩЪгЛЏCNN
дкСЫНтСЫCNNЭјТчЕФШЋВПЙЙМўКѓЃЌЯждкШУЮвУЧЪЙгУPyTorchПђМмЪЕЯжCNNЁЃ
ВНжш1ЃКМгдиЪфШыЭМЯёЃК
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
img_path = 'dog.jpg'
bgr_img = cv2.imread(img_path)
gray_img = cv2.cvtColor(bgr_img, cv2.COLOR_BGR2GRAY)
# Normalise
gray_img = gray_img.astype("float32")/255
plt.imshow(gray_img, cmap='gray')
plt.show() |

ВНжш2ЃКПЩЪгЛЏЙ§ТЫЦї
ЖдЙ§ТЫЦїНјааПЩЪгЛЏЃЌвдИќКУЕиСЫНтНЋЪЙгУФФаЉЙ§ТЫЦїЃК
import numpy
as np
filter_vals = np.array([
[-1, -1, 1, 1],
[-1, -1, 1, 1],
[-1, -1, 1, 1],
[-1, -1, 1, 1]
])
print('Filter shape: ', filter_vals.shape)
# Defining the Filters
filter_1 = filter_vals
filter_2 = -filter_1
filter_3 = filter_1.T
filter_4 = -filter_3
filters = np.array([filter_1, filter_2, filter_3,
filter_4])
# Check the Filters
fig = plt.figure(figsize=(10, 5))
for i in range(4):
ax = fig.add_subplot(1, 4, i+1, xticks=[], yticks=[])
ax.imshow(filters[i], cmap='gray')
ax.set_title('Filter %s' % str(i+1))
width, height = filters[i].shape
for x in range(width):
for y in range(height):
ax.annotate(str(filters[i][x][y]), xy=(y,x),
color='white' if filters[i][x][y]<0 else
'black') |
ВНжш3ЃКЖЈвхCNNФЃаЭ
БОЮФЙЙНЈЕФCNNФЃаЭОпгаОэЛ§ВуКЭзюДѓГиВуЃЌВЂЧвЪЙгУЩЯЪіЙ§ТЫЦїГѕЪМЛЏШЈжиЃК
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self, weight):
super(Net, self).__init__()
# initializes the weights of the convolutional
layer to be the weights of the 4 defined filters
k_height, k_width = weight.shape[2:]
# assumes there are 4 grayscale filters
self.conv = nn.Conv2d(1, 4, kernel_size=(k_height,
k_width), bias=False)
# initializes the weights of the convolutional
layer
self.conv.weight = torch.nn.Parameter(weight)
# define a pooling layer
self.pool = nn.MaxPool2d(2, 2)
def forward(self, x):
# calculates the output of a convolutional layer
# pre- and post-activation
conv_x = self.conv(x)
activated_x = F.relu(conv_x)
# applies pooling layer
pooled_x = self.pool(activated_x)
# returns all layers
return conv_x, activated_x, pooled_x
# instantiate the model and set the weights
weight = torch.from_numpy(filters).unsqueeze(1).type
(torch.FloatTensor)
model = Net(weight)
# print out the layer in the network
print(model) |
Net(
(conv): Conv2d(1, 4, kernel_size=(4, 4), stride=(1,
1), bias=False)
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0,
dilation=1, ceil_mode=False)
) |
ВНжш4ЃКПЩЪгЛЏЙ§ТЫЦї
ПьЫйфЏРРвЛЯТЫљЪЙгУЕФЙ§ТЫЦї
def viz_layer(layer,
n_filters= 4):
fig = plt.figure(figsize=(20, 20))
for i in range(n_filters):
ax = fig.add_subplot(1, n_filters, i+1)
ax.imshow(np.squeeze(layer[0,i].data.numpy()),
cmap='gray')
ax.set_title('Output %s' % str(i+1))
fig = plt.figure(figsize=(12, 6))
fig.subplots_adjust(left=0, right=1.5, bottom=0.8,
top=1, hspace=0.05, wspace=0.05)
for i in range(4):
ax = fig.add_subplot(1, 4, i+1, xticks=[], yticks=[])
ax.imshow(filters[i], cmap='gray')
ax.set_title('Filter %s' % str(i+1))
gray_img_tensor = torch.from_numpy(gray_img).unsqueeze(0).unsqueeze(1) |

ВНжш5ЃКУПВуЙ§ТЫЦїЕФЪфГі
дкОэЛ§ВуКЭГиЛЏВуЪфГіЕФЭМЯёШчЯТЫљЪОЃК
ОэЛ§ВуЃК

ГиЛЏВуЃК

ПЩвдПДЕНВЛЭЌВуНсЙЙЕУЕНЕФаЇЙћЛсгаЫљВюБ№ЃЌе§ЪЧгЩгкВЛЭЌВуЬсШЁЕНЕФЬиеїВЛЭЌЃЌдкЪфГіВуМЏКЯЕНЕФЬиеїВХФмКмКУЕиГщЯѓГіЭМЯёаХЯЂЁЃ |






