| БрМЭЦМі: |
БОЮФРДздcsdnЃЌБОЮФжївЊЭЈЙ§ДњТыЪЕР§ЯъЯИНщЩмСЫОэЛ§ЩёОЭјТчЃЈCNNЃЉМмЙЙжаЕФОэЛ§ВуЃЌГиЛЏВуКЭШЋСЌНгВуЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ |
|
1.ЛљДЁНщЩм
ОэЛ§ЩёОЭјТчЕФЛљДЁФкШнПЩвдВЮПМЃКЛњЦїбЇЯАЫуЗЈжЎОэЛ§ЩёОЭјТч
2.ЭјТчНсЙЙ
ОэЛ§ЩёОЭјТчвЛАуАќРЈОэЛ§ВуЃЌГиЛЏВуКЭШЋСЌНгВуЃЌЯТУцЗжБ№НщЩмвЛЯТ
2.1ОэЛ§Ву
ОэЛ§ЩёОЭјТчРяУцЕФетИіОэЛ§КЭаХКХРяУцЕФОэЛ§ЪЧгааЉВюБ№ЕФЃЌаХКХжаЕФОэЛ§МЦЫуЗжЮЊОЕЯёЯрГЫЯрМгЃЌОэЛ§ВужаЕФОэЛ§УЛгаОЕЯёетвЛВйзїЃЌжБНгЪЧЯрГЫКЭЯрМгЃЌШчЯТЭМЫљЪО

зюзѓБпЕФЪЧОэЛ§ЕФЪфШыЃЌжаМфЕФЮЊОэЛ§КЫЃЌзюгвБпЕФЮЊОэЛ§ЕФЪфГіЁЃПЩвдЗЂЯжОэЛ§МЦЫуКмМђЕЅЃЌОЭЪЧОэЛ§КЫгыЪфШыЖдгІЮЛжУЯрГЫШЛКѓЧѓКЭЁЃГ§СЫЭМжаТЬбеЩЋЕФР§згЃЌЮвУЧПЩвдМЦЫувЛЯТЭМжаКьЩЋШІЖдгІЕФОэЛ§НсЙћЃК(-1)*2+(-1)*9+(-1)*2+1*4+1*4=-5ЁЃвдЩЯОЭЪЧОэЛ§МЦЫуЕФЙ§ГЬЃЌЖдгкећИіЪфШыРДЫЕЃЌМЦЫуНсЙћЛЙШЁОігкСНИіВЮЪ§ЃКpadding
КЭ stride,ЯТУцЗжБ№НщЩмЯТетСНИіВЮЪ§
2.1.1 Padding
paddingЪЧКмЖрЕиЗНЖМЛсгУЕНЕФвЛжжВйзїБШШчдкМгУмЙ§ГЬжаУїЮФВЛЙЛГЄОЭашвЊМгpaddingРДЪЙЕУУїЮФгыУмдПГЄЖШЯрЭЌЃЌЦфвтЫМОЭЪЧдкдгаЕФЛљДЁжЎЩЯдіМгвЛаЉЖЋЮїЪЧЦфЙцФЃЗћКЯКѓајВйзїЁЃШчЯТЭМЫљЪОЃК
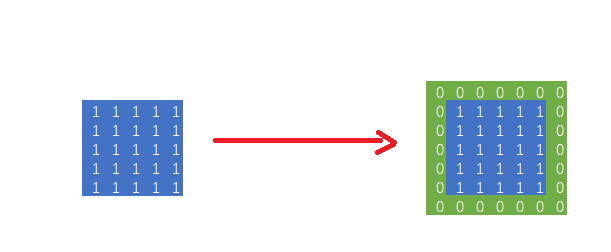
дкTensorflowжаpaddingгаСНжжЪєадЃЌвЛжжЪЧvalidЃЌетжжБэЪОВЛашвЊpaddingВйзїЃЌМйЩшЪфШыДѓаЁЮЊn*n,ОэЛ§КЫДѓаЁЮЊf*fЃЌДЫЪБЪфГіДѓаЁЮЊЃЈn-f+1)ЃЛСэвЛжжЪЧsameЃЌБэЪОЪфШыКЭЪфГіЕФДѓаЁЯрЭЌЃЌМйЩшpaddingЕФДѓаЁЮЊpЃЌДЫЪБЮЊСЫБЃГжЪфГіКЭЪфШыЯћЯЂЯрЭЌp
= (f-1)/2ЃЌЕЋЪЧДЫЪБОэЛ§КЫвЊЪЧЦцЪ§ДѓаЁЁЃ
2.1.2 Stride
strideЪЧжИОэЛ§КЫдкЪфШыЩЯвЦЖЏЪБУПДЮвЦЖЏЕФОрРыЃЌжБНгЩЯЭМРДЫЕУїЁЃЦфжаАДКьПђРДвЦЖЏЕФЛАstride
= 1;АДРЖЩЋПђРДвЦЖЏЕФЛАstride = 2ЁЃМгШыstrideКѓЃЌЪфГіЕФМЦЫугавЛаЉБфЛЏЃЌМйЩшЪфШыДѓаЁЮЊn*nЃЌОэЛ§КЫДѓаЁЮЊf*fЃЌpaddingДѓаЁЮЊpЃЌstrideДѓаЁЮЊ
s,ФЧУДзюКѓЕФЪфГіДѓаЁЮЊЃК
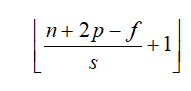
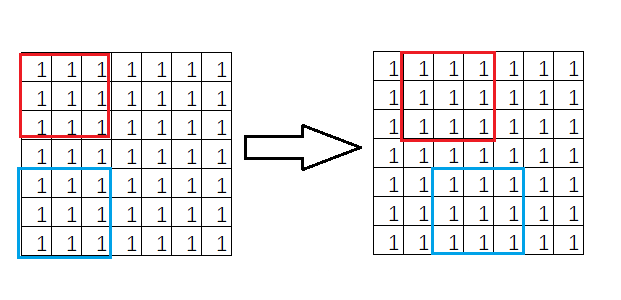
ОйИіДњТыЕФР§згЃЌЯТУцСНааДњТыЪЧTensorflowНјааОэЛ§МЦЫуЕФДњТыЃЌxЮЊЪфШыЃЌWЮЊШЈжиЃЌstrideЕФдаЭЮЊstrides
=[b, h, w, c],ЦфжаbБэЪОдкбљБОЩЯЕФВНГЄЃЌФЌШЯЮЊ1БэЪОУПИібљБОЖМЛсНјааМЦЫуЃЛh,wБэЪОИпЖШКЭПэЖШЃЌМДКсЯђКЭзнЯђВНГЄЃЛcБэЪОЭЈЕРЪ§ЃЌФЌШЯЮЊ1ЃЌБэЪОУПИіЭЈЕРЖМЛсВЮгыМЦЫуЁЃ
tf.nn.conv2d(x,
W, stride=[1, 1, 1, 1], padding='SAME')
tf.nn.conv2d(x, W, stride=[1, 2, 2, 1], padding='VALID')
|
2.1.3 ЖрЭЈЕРМЦЫу
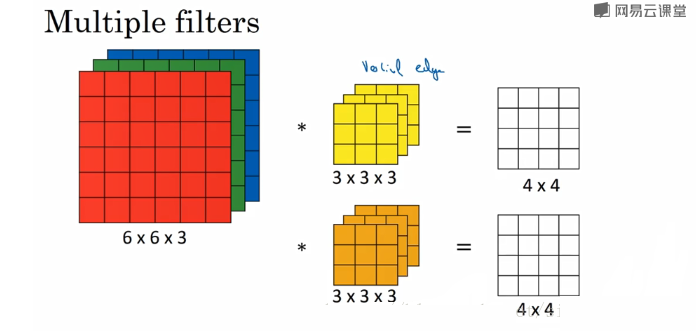
ОэЛ§КЫГ§СЫГЄПэетСНИіВЮЪ§жЎЭтЛЙгаЭЈЕРЪ§етИіВЮЪ§ЃЌЪзЯШашвЊУїШЗЕФЪЧЕЅИіОэЛ§КЫЕФЭЈЕРЪ§вЊЕШгкЭМЯёЕФЭЈЕРЪ§ЃЌвЛАуЭМЯёЪЧRGBФЃЪНЕФЛАЃЌОэЛ§КЫЕФДѓаЁЮЊh*w*3ЁЃгУЮтЖїДяЕФЪгЦЕФкШнНВНтвЛЯТЃЌжЛгавЛИіОэЛ§КЫЕФЪБКђЃЌЭМЯёОЙ§ОэЛ§МЦЫуКѓЕФНсЙћЭЈЕРЪ§ЪЧвЛЮЌЕФЃЌМЦЫуЗНЗЈвВМђЕЅДжБЉУПИіЭЈЕРЕФЖдгІЮЛжУЯрГЫШЛКѓЃЌВЛЭЌЭЈЕРЪ§жЎМфЯрМгЁЃ

вЛАуОэЛ§КЫВЛжЙвЛИіЃЌЖдгкЖрИіОэЛ§КЫЕФЧщПівВВЛИДдгЃЌжБНгЖдУПИіОэЛ§КЫНјааЕЅИіОэЛ§КЫЕФВйзїЃЌШЛКѓАбЫќУЧЦДдквЛЦ№ОЭааСЫЃЌШчЭМЫљЪОЃК
2.2ГиЛЏВу
ГиЛЏВуЃЈpoolingЃЉЕФзїгУжївЊЪЧНЕЕЭЮЌЖШЃЌЭЈЙ§ЖдОэЛ§КѓЕФНсЙћНјааНЕВЩбљРДНЕЕЭЮЌЖШЃЌЗжЮЊзюДѓГиЛЏКЭЦНОљГиЛЏСНРрЁЃ
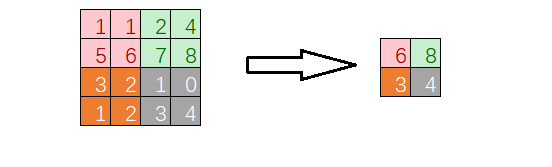
2.2.1 зюДѓГиЛЏ
зюДѓГиЛЏЙЫУћЫМвхЃЌНЕВЩбљЕФЪБКђВЩгУзюДѓжЕЕФЗНЪНВЩбљЃЌШчЭМЫљЪОЃЌЦфжаГиЛЏКЫЕФДѓаЁЮЊ2*2ЃЌВНГЄвВЮЊ2*2
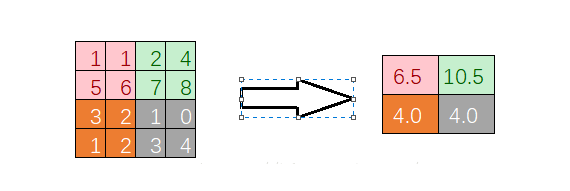
2.2.2 ЦНОљГиЛЏ
ЦНОљГиЛЏОЭЪЧгУОжВПЕФЦНОљжЕзїЮЊВЩбљЕФжЕЃЌЛЙЪЧЩЯУцЕФЪ§ОнЃЌЦНОљГиЛЏКѓЕФНсЙћЮЊЃК
ЭЌбљЩЯИіДњТы,ЦфжаЕФksizeЕФВЮЪ§КЭstrideВюВЛЖрЃЌОЭВЛзИЪіСЫЁЃ
tf.nn.max_pool(x,
ksize=[1, 2, 2, 1], stride=[1, 2, 2, 1], padding='SAME')
tf.nn.avg_pool(x, ksize=[1, 2, 2, 1], stride=[1,
2, 2, 1], padding='SAME') |
2.3ШЋСЌНгВу
ШЋСЌНгВуОЭЪЧАбОэЛ§ВуКЭГиЛЏВуЕФЪфГіеЙПЊГЩвЛЮЌаЮЪНЃЌдкКѓУцНгЩЯгыЦеЭЈЭјТчНсЙЙЯрЭЌЕФЛиЙщЭјТчЛђепЗжРрЭјТчЃЌвЛАуНгдкГиЛЏВуКѓУцЃЌШчЭМЫљЪО;
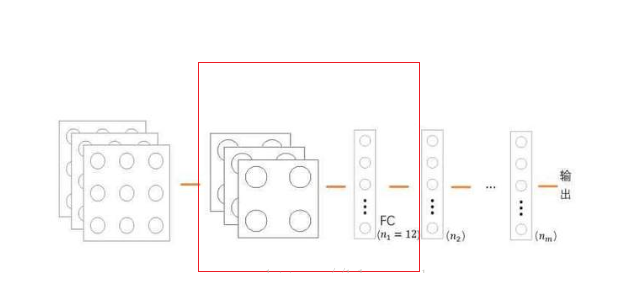
гУДњТыЛсИќКУРэНтвЛаЉ,ЦфжаdimsЮЊГиЛЏВуеЙПЊГЩвЛЮЌЪ§зщЕФЮЌЖШЃЌЕкЖўааВЩгУreluзїЮЊШЋСЌНгВуЕФМЄЛюКЏЪ§ЁЃ
fc = tf.reshape(pool_out,[-1,
dims])
fc_out = tf.nn.relu(tf.matmul(fc, W_fc) + b_fc)
|
3.ДњТыЪЕР§
ЯТУцвдAlexNetЮЊР§згЃЌИјГівЛИіЯъЯИЕФОэЛ§ЩёОЭјТчМмЙЙЃЌЪзЯШAlexNetМмЙЙвдМАУПВПЗжбЇЯАЕНЕФЬиеїШчЯТЭМЫљЪО
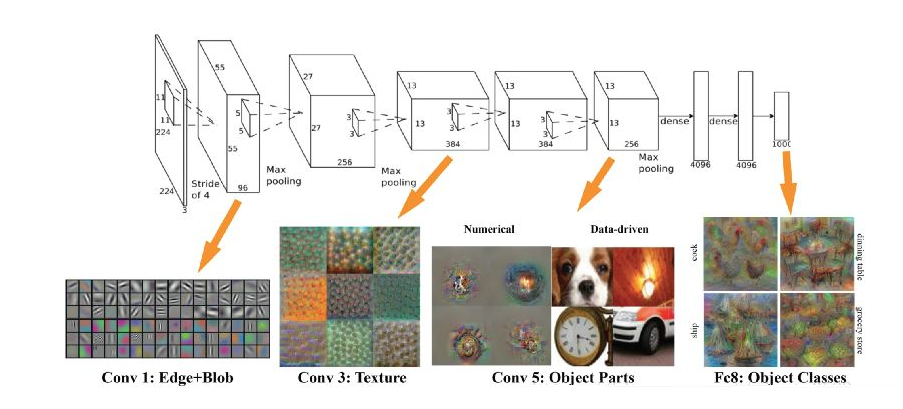
ДњТыШчЯТЃК
import tensorflow
as tf
import numpy as np
# ЖЈвхИїВуЙІФм
# зюДѓГиЛЏВу
def maxPoolLayer(x, kHeight, kWidth, strideX,
strideY, name, padding = "SAME"):
"""max-pooling"""
return tf.nn.max_pool(x, ksize = [1, kHeight,
kWidth, 1],
strides = [1, strideX, strideY, 1], padding =
padding, name = name)
# dropout
def dropout(x, keepPro, name = None):
"""dropout"""
return tf.nn.dropout(x, keepPro, name)
# ЙщвЛЛЏВу
def LRN(x, R, alpha, beta, name = None, bias =
1.0):
"""LRN"""
return tf.nn.local_response_normalization(x, depth_radius
= R, alpha = alpha,
beta = beta, bias = bias, name = name)
# ШЋСЌНгВу
def fcLayer(x, inputD, outputD, reluFlag, name):
"""fully-connect"""
with tf.variable_scope(name) as scope:
w = tf.get_variable("w", shape = [inputD,
outputD], dtype = "float")
b = tf.get_variable("b", [outputD],
dtype = "float")
out = tf.nn.xw_plus_b(x, w, b, name = scope.name)
if reluFlag:
return tf.nn.relu(out)
else:
return out
# ОэЛ§Ву
def convLayer(x, kHeight, kWidth, strideX, strideY,
featureNum, name, padding = "SAME",
groups = 1):
"""convolution"""
channel = int(x.get_shape()[-1])
conv = lambda a, b: tf.nn.conv2d(a, b, strides
= [1, strideY, strideX, 1], padding = padding)
with tf.variable_scope(name) as scope:
w = tf.get_variable("w", shape = [kHeight,
kWidth, channel/groups, featureNum])
b = tf.get_variable("b", shape = [featureNum])
xNew = tf.split(value = x, num_or_size_splits
= groups, axis = 3)
wNew = tf.split(value = w, num_or_size_splits
= groups, axis = 3)
featureMap = [conv(t1, t2) for t1, t2 in zip(xNew,
wNew)]
mergeFeatureMap = tf.concat(axis = 3, values =
featureMap)
# print mergeFeatureMap.shape
out = tf.nn.bias_add(mergeFeatureMap, b)
return tf.nn.relu(tf.reshape(out, mergeFeatureMap.get_shape().as_list()),
name = scope.name)
class alexNet(object):
"""alexNet
model"""
def __init__(self, x, keepPro, classNum, skip,
modelPath = "bvlc_alexnet.npy"):
self.X = x
self.KEEPPRO = keepPro
self.CLASSNUM = classNum
self.SKIP = skip
self.MODELPATH = modelPath
#build CNN
self.buildCNN()
# ЙЙНЈAlexNet
def buildCNN(self):
"""build
model"""
conv1 = convLayer(self.X, 11, 11, 4, 4, 96, "conv1",
"VALID")
lrn1 = LRN(conv1, 2, 2e-05, 0.75, "norm1")
pool1 = maxPoolLayer(lrn1, 3, 3, 2, 2, "pool1",
"VALID")
conv2 = convLayer(pool1, 5, 5, 1, 1, 256, "conv2",
groups = 2)
lrn2 = LRN(conv2, 2, 2e-05, 0.75, "lrn2")
pool2 = maxPoolLayer(lrn2, 3, 3, 2, 2, "pool2",
"VALID")
conv3 = convLayer(pool2, 3, 3, 1, 1, 384, "conv3")
conv4 = convLayer(conv3, 3, 3, 1, 1, 384, "conv4",
groups = 2)
conv5 = convLayer(conv4, 3, 3, 1, 1, 256, "conv5",
groups = 2)
pool5 = maxPoolLayer(conv5, 3, 3, 2, 2, "pool5",
"VALID")
fcIn = tf.reshape(pool5, [-1, 256 * 6 * 6])
fc1 = fcLayer(fcIn, 256 * 6 * 6, 4096, True, "fc6")
dropout1 = dropout(fc1, self.KEEPPRO)
fc2 = fcLayer(dropout1, 4096, 4096, True, "fc7")
dropout2 = dropout(fc2, self.KEEPPRO)
self.fc3 = fcLayer(dropout2, 4096, self.CLASSNUM,
True, "fc8")
def loadModel(self, sess):
"""load
model"""
wDict = np.load(self.MODELPATH, encoding = "bytes").item()
#for layers in model
for name in wDict:
if name not in self.SKIP:
with tf.variable_scope(name, reuse = True):
for p in wDict[name]:
if len(p.shape) == 1:
#bias
sess.run(tf.get_variable('b', trainable = False).assign(p))
else:
#weights
sess.run(tf.get_variable('w', trainable = False).assign(p))
|
|





