| БрМЭЦМі: |
БОЮФжївЊНВНтСЫПЩЪгЛЏЭМаЮ+дДТыЗжЮіАяжњДѓМвПьЫйЩюШыЕиРэНтTransformerдРэ,ЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздЮЂаХЙЋжкКХ УЈЕАЖљЕФаЁЮбЃЌзїепЮќН№аЁЗВЃЌгЩЛ№СњЙћШэМўСѕшЁБрМЭЦМіЁЃ |
|
вЛЁЂTransformerМђНщ
1.1ЁЂSeq2seq model
Transformer(БфаЮН№Ие)МђЕЅРДНВЃЌЮвУЧПЩвдНЋЦфПДзївЛИіseq2seq with self-attention modelЁЃЮвУЧПЩвдетУДРэНтЃЌTransformerећЬхзїЮЊвЛИіЗвыЦїЃЌЪфШыЗЈЮФЕФОфзгЃЌФЃаЭНЋЦфЗвыЮЊгЂЮФЪфГіЁЃ

1.2ЁЂTransformerећЬхПђМм
гЩЩЯЭМжЊЃЌTransformerжївЊгЩencoderКЭdecoderСНВПЗжзщГЩЁЃдкTransformerЕФpaperжаЃЌencoderКЭdecoderОљгЩ6Иіencoder layerКЭdecoder layerзщГЩЃЌЭЈГЃЮвУЧГЦжЎЮЊencoder blockЁЃ

1.3ЁЂTransformerПђМмдДТы
ЮвУЧвбОжЊЕРTransformerжївЊгЩencoderКЭdecoderСНВПЗжзщГЩЁЃФЧУДДњТыжаЙЙНЈвВЪЧЗЧГЃМђЕЅЕФЃЌЙиМќДњТыШчЯТЃК
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
# TransformerЕФСНИізщГЩВПЗж
self.encoder = Encoder()
self.decoder = Decoder()
self.projection = nn.Linear(d_model, tgt_vocab_size,
bias=False) |
ЖўЁЂEncoderБрТыЦї

EncoderзмЬхЕФЙЙНЈДњТыШчЯТЃК
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model)
# ДЪЯђСПembedding
self.pos_emb = nn.Embedding.from_pretrained (get_sinusoid_encoding_table
(src_len+1, d_model),freeze=True) # ЮЛжУЯђСПembedding
# encoderКЫаФВйзїЃКгЩn_layerИіencoder blockЙЙНЈЕУЕН encoder
self.layers = nn.ModuleList([EncoderLayer() for
_ in range(n_layers)]) |
EncoderLayer()ИКд№УПвЛИіEncoder blockЕФЙЙНЈЃК
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet() |
ЯТУцЮвУЧОЭРДПДвЛЯТMulti-head AttentionКЭFeed forwardЕФЕзВудРэЪЧШчКЮЪЕЯжЃП
2.1ЁЂMulti-head Attention
Multihead attentionЦфЪЕОЭЪЧself-attentionЕФnДЮМЦЫуЃЌМђЕЅРДНВЃЌЦфЪЕОЭЪЧжиИДЕФОиеѓЯрГЫдЫЫуЁЃвђДЫЃЌЮвУЧЪзЯШвЊИуЧхГўSelf-attentionЕФдЫЫуЙ§ГЬЁЃ
2.1.1 Self-Attention
Self-AttentionБОжЪЩЯОЭЪЧвЛЯЕСаОиеѓдЫЫуЁЃФЧУДЫќЕФЕФМЦЫуЙ§ГЬЪЧдѕбљЕФФиЃПЮвУЧвдЪфШыЮЊx1ЖдгІЪфГіЮЊb1ЮЊР§ЃЌНјааЫЕУїЃЌШчЯТЭМЁЃ

еыЖдвдЩЯЖЏЭМЩцМАЕФМЦЫуЙ§ГЬЃЌЮвУЧдкЯТЭМНјаавЛвЛЖдгІЃК
Self-AttentionећЬхЕФМЦЫуЙ§ГЬгУШчЯТЭМНјааЙщФЩЃК
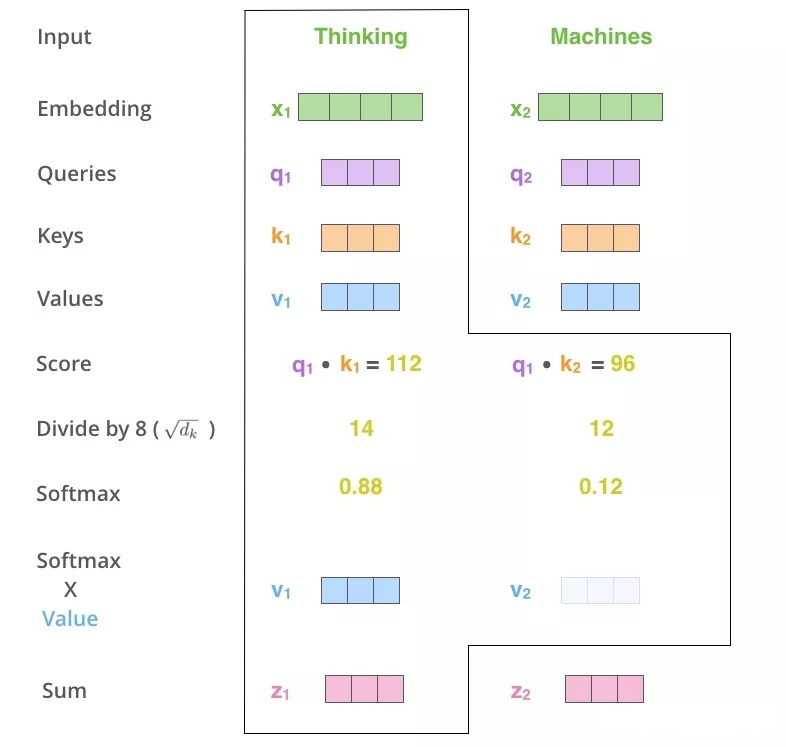
ЖдгкSelf-attentionЛњжЦетРяОЭВЛНјааЯИНВСЫЃЌВЉжїдкЧАвЛЦЊЗЂЕФЮФеТжаНјааЯъЯИЕФНщЩмЃЌаЁЛяАщУЧПЩвдЛЈСНЗжжгШЅЖСвЛЯТдйЛиРДНгзХЭљЯТПДЃЌSelf-attentionДЋЫЭУХЃКЭМНтBertЯЕСажЎSelf-Attention
2.1.2 Multihead-Attention
ЮвУЧЛЙЪЧЯШРДПДДњТыЃК
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads)
self.W_K = nn.Linear(d_model, d_k * n_heads)
self.W_V = nn.Linear(d_model, d_v * n_heads)
def forward(self, Q, K, V, attn_mask):
# q: [batch_size x len_q x d_model], k: [batch_size
x len_k x d_model],
v: [batch_size x len_k x d_model]
residual, batch_size = Q, Q.size(0)
# (B, S, D) -proj-> (B, S, D) -split-> (B,
S, H, W) -trans-> (B, H, S, W)
q_s = self.W_Q(Q).view(batch_size, -1, n_heads,
d_k).transpose(1,2)
# q_s: [batch_size x n_heads
x len_q x d_k]
k_s = self.W_K(K).view(batch_size, -1, n_heads,
d_k).transpose(1,2)
# k_s: [batch_size x n_heads
x len_k x d_k]
v_s = self.W_V(V).view(batch_size, -1, n_heads,
d_v).transpose(1,2)
# v_s: [batch_size x n_heads
x len_k x d_v]
attn_mask = attn_mask.unsqueeze(1).repeat(1,
n_heads, 1, 1) # attn_mask : [batch_size x n_heads
x len_q x len_k]
# context: [batch_size x n_heads x len_q x
d_v], attn: [batch_size x n_heads x len_q(=len_k)
x len_k(=len_q)]
context, attn = ScaledDotProductAttention()(q_s,
k_s, v_s, attn_mask)
context = context.transpose(1, 2).contiguous().view(batch_size,
-1, n_heads * d_v) # context: [batch_size x
len_q x n_heads * d_v]
output = nn.Linear(n_heads * d_v, d_model)(context)
return nn.LayerNorm(d_model)(output + residual),
attn # output: [batch_size x len_q x d_model]
|
етРяЕФTransformerЪЧЖдself-attentionзіСЫвЛИі2ДЮЕФОиеѓЯрГЫЁЃРэНтСЫSelf-attentionжЎКѓЃЌMultihead attentionРэНтЦ№РДЪЧЗжЗжжгШіШіЫЎРВЁЃ
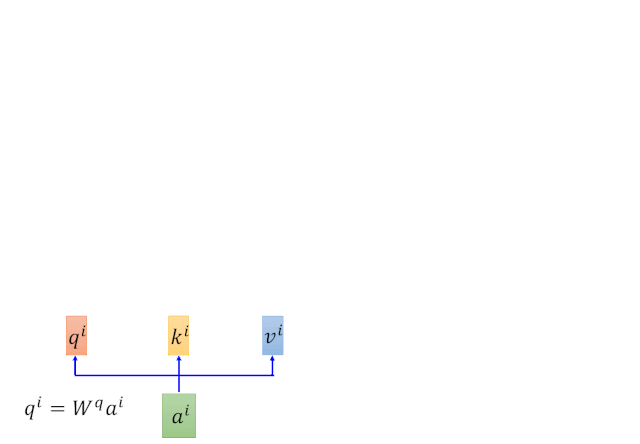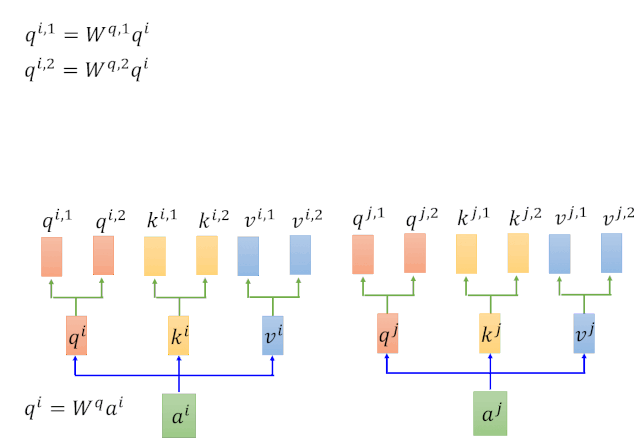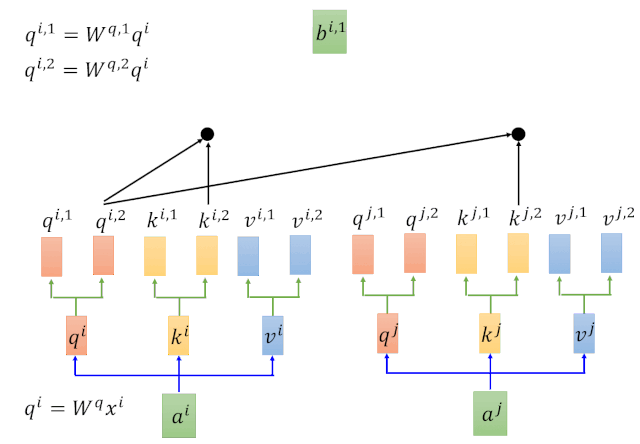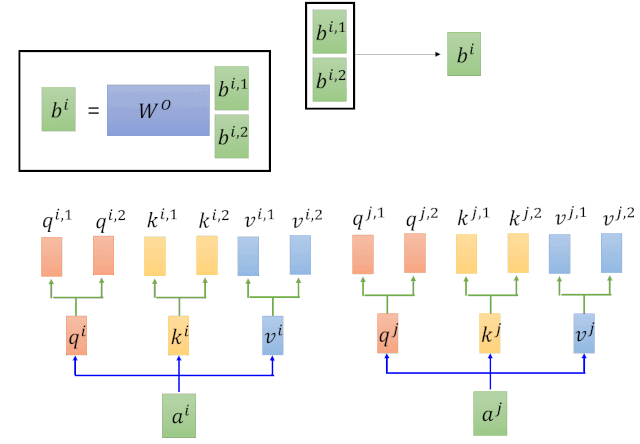
ЭЈЙ§ЖдвдЩЯМЦЫуВНжшЕФЗДИДЕќДњЃЌЕУЕНQЁЂKЁЂVШ§ИіОиеѓЁЃ

2.1.3 Position VectorЮЛжУЯђСП
ФЃаЭРэНтвЛИіОфзггаСНИівЊЫиЃКвЛЪЧЕЅДЪЕФКЌвхЃЌЖўЪЧЕЅДЪдкОфжаЫљДІЕФЮЛжУЁЃ
дкSelf-attentionжаУПИіЕЅДЪЯђСПОЙ§МЦЫужЎКѓЕФЪфГіЖМЪмЕНећОфЕФгАЯьЃЌQЁЂKЁЂVЕФОиеѓдЫЫувВЖМЪЧВЂаадЫЫуЃЌЕЋЕЅДЪМфЕФЫГађаХЯЂШДБЛЖЊЪЇСЫЁЃвђДЫGoogleЭХЖгдкTransformerжаЪЙгУPositionЮЛжУЯђСПНтОіетИіЮЪЬтЁЃ
УПИіЕЅДЪЕФЧЖШыЯђСПЛсбЇЯАЕЅДЪЕФКЌвхЃЌЫљвдЮвУЧашвЊЪфШывЛаЉаХЯЂЃЌШУЩёОЭјТчжЊЕРЕЅДЪдкОфжаЫљДІЕФЮЛжУЁЃРћгУЮвУЧЪьЯЄЕФsinЁЂcosШ§НЧКЏЪ§ДДНЈЮЛжУЬивьадГЃСПРДНтОіетРрЮЪЬтЃК

ЦфжаЃЌдкИјДЪЯђСПЬэМгЮЛжУБрТыжЎЧАЃЌЮвУЧвЊРЉДѓДЪЯђСПЕФЪ§жЕЃЌФПЕФЪЧШУЮЛжУБрТыЯрЖдНЯаЁЁЃетвтЮЖзХЯђДЪЯђСПЬэМгЮЛжУБрТыЪБЃЌДЪЯђСПЕФдЪМКЌвхВЛЛсЖЊЪЇЁЃ
зЂЪЭЃКЮЛжУБрТыОиеѓЪЧвЛИіГЃСПЃЌЫќЕФжЕПЩвдгУЩЯУцЕФЫуЪНМЦЫуГіРДЁЃАбГЃСПЧЖШыОиеѓЃЌШЛКѓУПИіЧЖШыЕФЕЅДЪЛсИљОнЫќЫљДІЕФЮЛжУЗЂЩњЬиЖЈзЊБфЁЃ

РћгУPytorchНјааЪЕЯжЃК
def get_sinusoid_encoding_table(n_position, d_model):
def cal_angle(position, hid_idx):
return position / np.power(10000, 2 * (hid_idx
// 2) / d_model)
def get_posi_angle_vec(position):
return [cal_angle(position, hid_j) for hid_j in
range (d_model)]
sinusoid_table = np.array([get_posi_angle_vec(pos_i)
for pos_i in range(n_position)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:,
0::2]) # dim 2i
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:,
1::2]) # dim 2i+1
return torch.FloatTensor(sinusoid_table) |
2.2ЁЂFeed Forward ЧАРЁЩёОЭјТч
жегкЕНСЫencoderЕФзюКѓвЛаЁВПЗжЃЌРэНтСЫвдЩЯВПЗжЃЌетРяЕФЩёОЭјТчЗЧГЃМђЕЅСЫЃЌЭЈЙ§МЄЛюКЏЪ§ReluзівЛИіЗЧЯпадБфЛЛ()ЃЌШЛКѓЙщвЛЛЏВйзї(ЖдгІДњТыжаЕФLayerNormКЏЪ§)ЃЌЕУЕНencoderзюжеЕФЪфГіНсЙћЁЃ
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff,
kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model,
kernel_size=1)
def forward(self, inputs):
residual = inputs # inputs : [batch_size, len_q,
d_model]
output = nn.ReLU()(self.conv1(inputs.transpose
(1, 2)))
output = self.conv2(output).transpose(1, 2)
return nn.LayerNorm(d_model)(output + residual) |
Ш§ЁЂDecoderНтТыЦї
ЮвУЧдйРДЛиЙЫвЛЯТTransformerЕФећЬхНсЙЙЃК

DecoderгыEncoderВЛЭЌЕФЪЧЃЌЖюЭтЖрМгСЫвЛВуEncoder-Decoder AttentionЕФдЫЫуЃЌОпЬхНщЩмШчЯТЁЃ
3.1ЁЂEncoder-decoder attention
DecoderАќРЈ6Иіdecoder blockЃЌУПвЛИіdecoder blockгЩШ§ВПЗжзщГЩЃЌГ§СЫdecoder blockАќКЌЕФСНВувдЭтЃЌЖрСЫвЛВуencoder-decoder attentionЁЃвВОЭЪЧЫЕЃЌГ§СЫdecoderБОЩэЕФЪфШыЃЌencoderЕФЪфГівВзїЮЊdecoderЪфШыЕФвЛВПЗжНјаадЫЫуЁЃДгДњТыDecoderLayer()жаЕк5ааПЩвдЬхЯжГіРДЁЃ
дк1.2НкжаЮвУЧжЊЕРTransformerЕФEncoderБрТыЦїАќРЈ6Иіencoder blockЃЌЦфжаУПвЛИіencoder blockжївЊгЩСНВПЗжзщГЩЃЌАќРЈMultihead attentionВуЁЂFeed ForwardВуЁЃEncoderЕФЪфШыЪзЯШОЙ§Multihead attentionВуЃЌетвЛВуАяжњencoderдкЪфШыФГИіЕЅДЪЪБРэНтЦфдкећИіОфзгжаЕФЩЯЯТЮФгявхЃЌЪфГіжЎКѓдйЫЭЕНЧАРЁЩёОЭјТчжаЃЌИїВувРДЮбЛЗЕќДњЁЃ

DecoderзмЬхЕФЙЙНЈДњТыШчЯТЃК
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = nn.Embedding.from_pretrained (get_sinusoid_
encoding_ table(tgt_len+1, d_model),freeze=True)
self.layers = nn.ModuleList([DecoderLayer() for
_ in range (n_layers)]) |
DecoderLayer()ИКд№УПвЛИіEncoder blockЕФЙЙНЈЃК
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs,
dec_self_ attn_mask, dec_enc_attn_mask):
dec_outputs, dec_self_attn = self.dec_self_attn
(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
dec_outputs, dec_enc_attn = self.dec_enc_attn
(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
dec_outputs = self.pos_ffn (dec_outputs)
return dec_outputs, dec_self_attn, dec_enc_attn |
ЬсЪОЃК
DecoderжаЕФattentionгыencoderжаЕФattentionгаЫљВЛЭЌЁЃDecoderжаЕФattentionжаЕБЧАЕЅДЪжЛЪмЕБЧАЕЅДЪжЎЧАФкШнЕФгАЯьЃЌЖјencoderжаЕФУПИіЕЅДЪЛсЪмЕНЧАКѓФкШнЕФгАЯьЁЃОпЬхЪЧШчКЮЪЕЯжЕФФиЃПЧыПД3.2НкmaskЛњжЦЕФНВНтЁЃ
3.2ЁЂMaskЛњжЦ
MasksдкtransformerФЃаЭжївЊгаСНИізїгУЃК
1ЁЂдкБрТыЦїКЭНтТыЦїжаЃКЕБЪфШыЮЊpaddingЃЌзЂвтСІЛсЪЧ0ЁЃ
2ЁЂдкНтТыЦїжаЃКдЄВтЯТвЛИіЕЅДЪЃЌБмУтНтТыЦїЭЕЭЕПДЕНКѓУцЕФЗвыФкШнЁЃ
EncoderЪфШыЖЫЩњГЩmaskКмМђЕЅЃК
def get_attn_pad_mask(seq_q, seq_k):
# print(seq_q)
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1)
# batch _size x 1 x len_k(=len_q), one is masking
return pad_attn_mask.expand(batch_size, len_q,
len_k) # batch_size x len_q x len_ |
ЭЌбљЕФЃЌЪфГіЖЫвВПЩвдЩњГЩвЛИіmaskЃЌЕЋЪЧЛсЖюЭтдіМгвЛИіВНжшЃК
ФПБъгяОфЃЈЪфШыЗЈгяЁЊЁЊ>ЪфГігЂгяЃЉзїЮЊГѕЪМжЕЪфНјНтТыЦїжаЁЃdecoderЭЈЙ§encoderЕФШЋВПЪфГіЃЌвдМАФПЧАвбЗвыЕФЕЅДЪРДдЄВтЯТвЛИіЕЅДЪЁЃвђДЫЃЌЮвУЧашвЊЗРжЙНтТыЦїЭЕПДЕНЛЙУЛдЄВтЕФЕЅДЪЁЃЮЊСЫДяГЩетИіФПЕФЃЌЮвУЧгУЕНСЫsubsequent_maskКЏЪ§ЃК
def get_attn_subsequent_mask(seq):
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
subsequent_mask = np.triu(np.ones (attn_shape),
k=1)
subsequent_mask = torch.from_numpy (subsequent_mask)
.byte()
return subsequent_mask |

етбљдкDecoderЕФattentionжагІгУmaskЃЌУПвЛДЮдЄВтЖМжЛЛсгУЕНетИіДЪжЎЧАЕФОфзгЃЌЖјВЛЪмжЎКѓОфзгЕФгАЯь
ЫФЁЂЮФФЉзмНс
ЭЈЙ§БОЮФЮвУЧЖдTransformerЕФРДСњШЅТівбОИуЕУВюВЛЖрСЫЃЌЪЧЪБКђЖдBertЯТЪжСЫЁЃBertБОжЪЩЯОЭЪЧЫЋЯђTransformerЕФEncoderЃЌвђДЫИуЖЎTransformerЕФдРэЖдBertФЃаЭЕФРэНтжСЙиживЊЁЃДгSelf-AttentionЕНTransformerЃЌдйЕНBertПЩвдЫЕЪЧЛЗЛЗЯрПлЃЌШБвЛВЛПЩЁЃ
|






