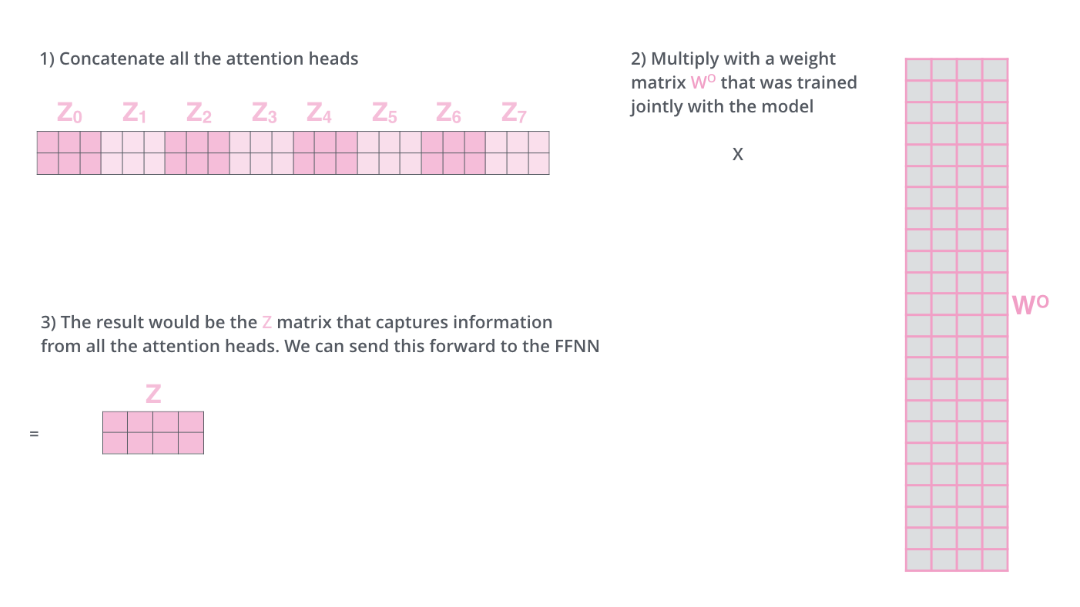
| БрМЭЦМі: |
ЮФеТНщЩмСЫTransformerЕФЭјТчНсЙЙЃЌФЃаЭжаИїжжеХСП/ЯђСПЃЌШчКЮгУЯђСПЕФЗНЪНРДМЦЫуself
attentionВЂЫќЪЧШчКЮЪЙгУОиеѓРДЪЕЯжЕФЕШЯрЙиФкШнЁЃ
БОЮФРДздгкcsdnЃЌгЩЛ№СњЙћШэМўLucaБрМЁЂЭЦМіЁЃ |
|
ЧАбд
TransformerдкGooleЕФвЛЦЊТлЮФAttention is All You NeedБЛЬсГіЃЌЮЊСЫЗНБуЪЕЯжЕїгУTransformer
GoogleЛЙПЊдДСЫвЛИіЕкШ§ЗНПтЃЌЛљгкTensorFlowЕФTensor2TensorЃЌвЛИіNLPЕФЩчЧјбаОПепЙБЯзСЫвЛИіTorchАцБОЕФжЇГжЃКguide
annotating the paper with PyTorch implementationЁЃетРяЃЌЮвЯыгУвЛаЉЗНБуРэНтЕФЗНЪНРДвЛВНвЛВННтЪЭTransformerЕФбЕСЗЙ§ГЬЃЌетбљМДБуФуУЛгаКмЩюЕФЩюЖШбЇЯАжЊЪЖФувВФмДѓИХУїАзЦфжаЕФдРэЁЃ
A High-Level Look
ЮвУЧЯШАбTransformerЯыЯѓГЩвЛИіКкЯЛзгЃЌдкЛњЦїЗвыЕФСьгђжаЃЌетИіКкЯЛзгЕФЙІФмОЭЪЧЪфШывЛжжгябдШЛКѓНЋЫќЗвыГЩЦфЫћгябдЁЃШчЯТЭМЃК

ЯЦЦ№The TransformerЕФИЧЭЗЃЌЮвУЧПДЕНдкетИіКкЯЛзггЩ2ИіВПЗжзщГЩЃЌвЛИіEncodersКЭвЛИіDecodersЁЃ

ЮвУЧдйЖдетИіКкЯЛзгНјвЛВНЕФЦЪЮіЃЌЗЂЯжУПИіEncodersжаЗжБ№гЩ6ИіEncoderзщГЩЃЈТлЮФжаЪЧетбљХфжУЕФЃЉЁЃЖјУПИіDecodersжаЭЌбљвВЪЧгЩ6ИіDecoderзщГЩЁЃ
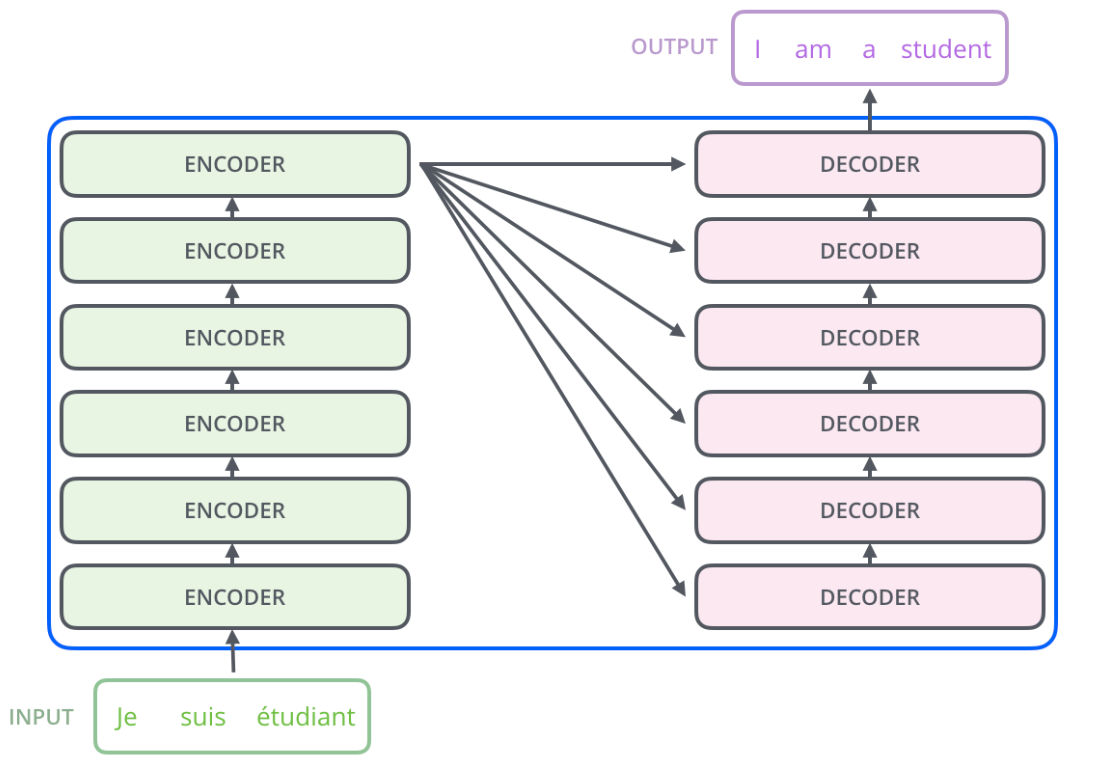
ЖдгкEncodersжаЕФУПвЛИіEncoderЃЌЫћУЧНсЙЙЖМЪЧЯрЭЌЕФЃЌЕЋЪЧВЂВЛЛсЙВЯэШЈжЕЁЃУПВуEncoderга2ИіВПЗжзщГЩЃЌШчЯТЭМЃК
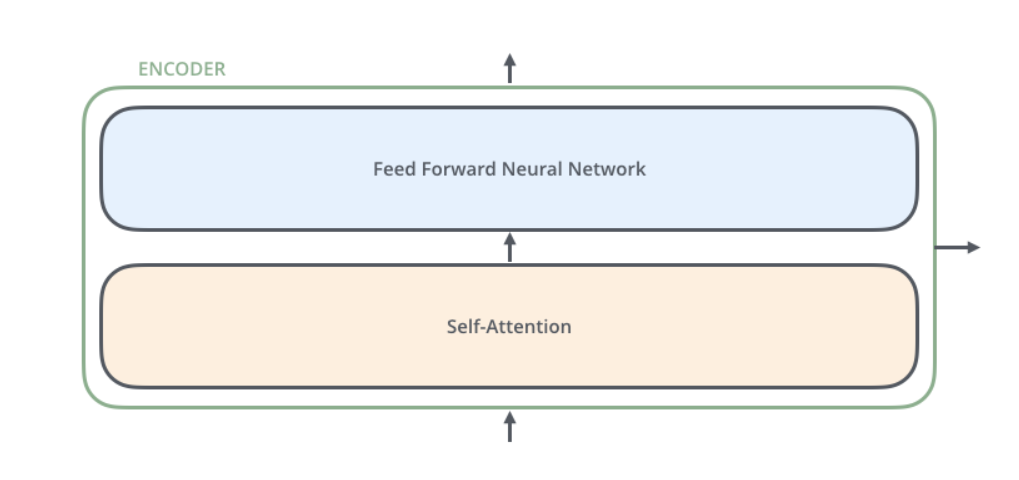
УПИіEncoderЕФЪфШыЪзЯШЛсЭЈЙ§вЛИіself-attentionВуЃЌЭЈЙ§self-attentionВуАяжњEndcoderдкБрТыЕЅДЪЕФЙ§ГЬжаВщПДЪфШыађСажаЕФЦфЫћЕЅДЪЁЃШчЙћФуВЛЧхГўетРядкЫЕЪВУДЃЌВЛгУзХМБЃЌжЎКѓЮвУЧЛсЯъЯИНщЩмself-attentionЕФЁЃ
Self-attentionЕФЪфГіЛсБЛДЋШывЛИіШЋСЌНгЕФЧАРЁЩёОЭјТчЃЌУПИіencoderЕФЧАРЁЩёОЭјТчВЮЪ§ИіЪ§ЖМЪЧЯрЭЌЕФЃЌЕЋЪЧЫћУЧЕФзїгУЪЧЖРСЂЕФЁЃ
УПИіDecoderвВЭЌбљОпгаетбљЕФВуМЖНсЙЙЃЌЕЋЪЧдкетжЎМфгавЛИіAttentionВуЃЌАяжњDecoderзЈзЂгкгыЪфШыОфзгжаЖдгІЕФФЧИіЕЅДЪЃЈРрЫЦгыseq2seq
modelsЕФНсЙЙЃЉ
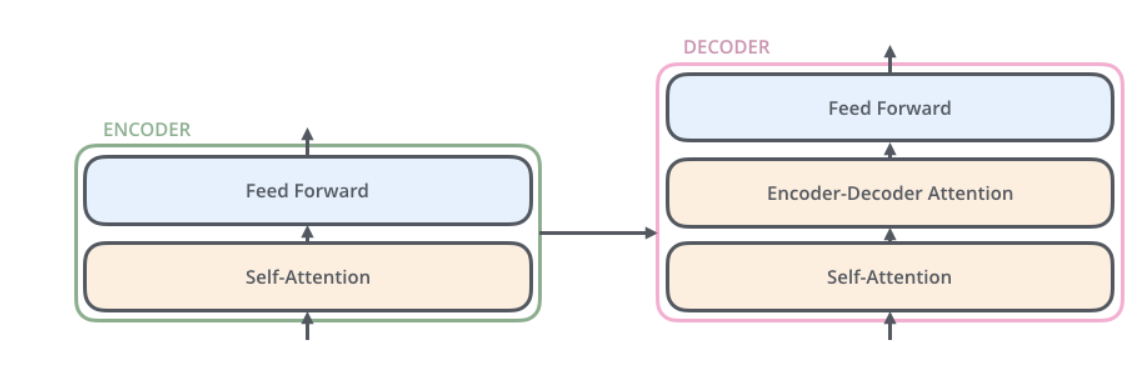
Bringing The Tensors Into The Picture
дкЩЯвЛНкЃЌЮвУЧНщЩмСЫTransformerЕФЭјТчНсЙЙЁЃЯждкЮвУЧвдЭМЪОЕФЗНЪНРДбаОПTransformerФЃаЭжаИїжжеХСП/ЯђСПЃЌЙлВьДгЪфШыЕНЪфГіЕФЙ§ГЬжаетаЉЪ§ОндкИїИіЭјТчНсЙЙжаЕФСїЖЏЁЃ
ЪзЯШЛЙЪЧNLPЕФГЃЙцзіЗЈЃЌЯШзівЛИіДЪЧЖШыЃКЪВУДЪЧЮФБОЕФДЪЧЖШыЃП

ЮвУЧНЋУПИіЕЅДЪБрТыЮЊвЛИі512ЮЌЖШЕФЯђСПЃЌЮвУЧгУЩЯУцетеХМђЖЬЕФЭМаЮРДБэЪОетаЉЯђСПЁЃДЪЧЖШыЕФЙ§ГЬжЛЗЂЩњдкзюЕзВуЕФEncoderЁЃЕЋЪЧЖдгкЫљгаЕФEncoderРДЫЕЃЌФуЖМПЩвдАДЯТЭМРДРэНтЁЃЪфШыЃЈвЛИіЯђСПЕФСаБэЃЌУПИіЯђСПЕФЮЌЖШЮЊ512ЮЌЃЌдкзюЕзВуEncoderзїгУЪЧДЪЧЖШыЃЌЦфЫћВуОЭЪЧЦфЧАвЛВуЕФoutputЃЉЁЃСэЭтетИіСаБэЕФДѓаЁКЭДЪЯђСПЮЌЖШЕФДѓаЁЖМЪЧПЩвдЩшжУЕФГЌВЮЪ§ЁЃвЛАуЧщПіЯТЃЌЫќЪЧЮвУЧбЕСЗЪ§ОнМЏжазюГЄЕФОфзгЕФГЄЖШЁЃ

ЩЯЭМЦфЪЕНщЩмЕНСЫвЛИіTransformerЕФЙиМќЕуЁЃФузЂвтЙлВьЃЌдкУПИіЕЅДЪНјШыSelf-AttentionВуКѓЖМЛсгавЛИіЖдгІЕФЪфГіЁЃSelf-AttentionВужаЕФЪфШыКЭЪфГіЪЧДцдквРРЕЙиЯЕЕФЃЌЖјЧАРЁВудђУЛгавРРЕЃЌЫљвддкЧАРЁВуЃЌЮвУЧПЩвдгУЕНВЂааЛЏРДЬсЩ§ЫйТЪЁЃ
ЯТУцЮвгУвЛИіМђЖЬЕФОфзгзїЮЊР§згЃЌРДвЛВНвЛВНЭЦЕМtransformerУПИізгВуЕФЪ§ОнСїЖЏЙ§ГЬЁЃ
Now WeЁЏre Encoding!
е§ШчжЎЧАЫљЫЕЃЌTransformerжаЕФУПИіEncoderНгЪевЛИі512ЮЌЖШЕФЯђСПЕФСаБэзїЮЊЪфШыЃЌШЛКѓНЋетаЉЯђСПДЋЕнЕНЁЎself-attentionЁЏВуЃЌself-attentionВуВњЩњвЛИіЕШСП512ЮЌЯђСПСаБэЃЌШЛКѓНјШыЧАРЁЩёОЭјТчЃЌЧАРЁЩёОЭјТчЕФЪфГівВЮЊвЛИі512ЮЌЖШЕФСаБэЃЌШЛКѓНЋЪфГіЯђЩЯДЋЕнЕНЯТвЛИіencoderЁЃ
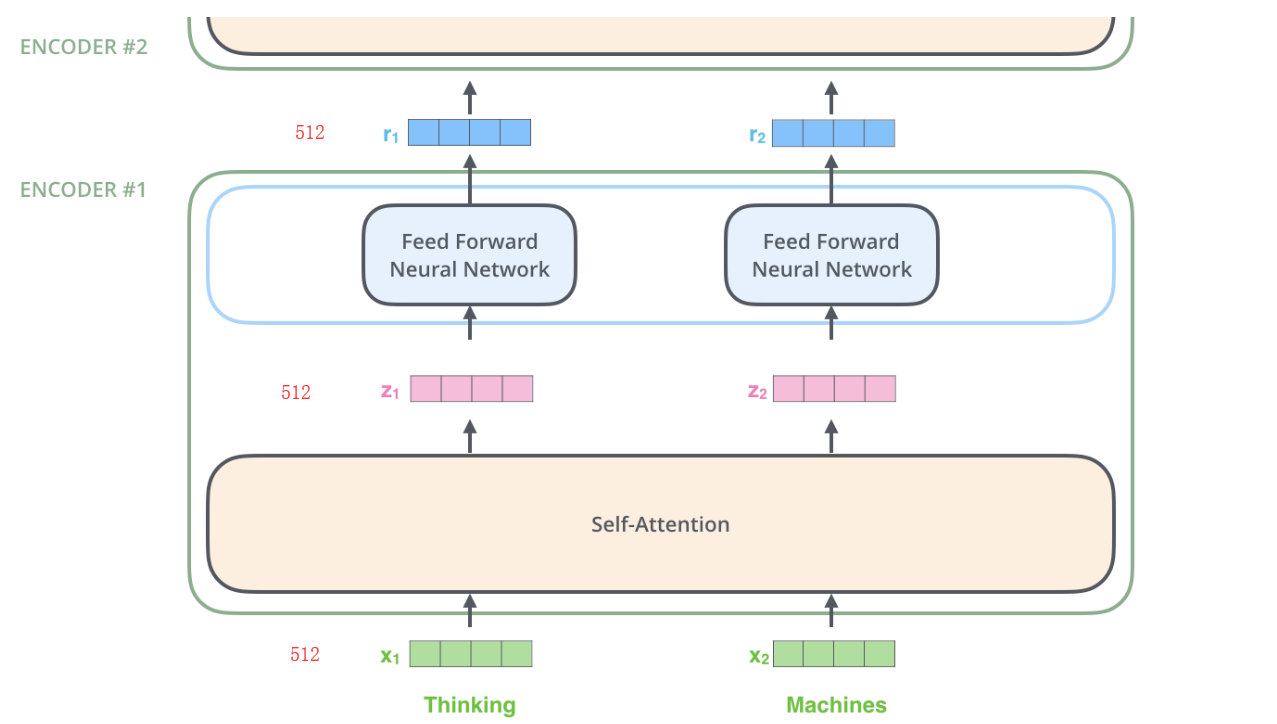
ШчЩЯЭМЫљЪОЃЌУПИіЮЛжУЕФЕЅДЪЪзЯШЛсОЙ§вЛИіself attentionВуЃЌШЛКѓУПИіЕЅДЪЖМЭЈЙ§вЛИіЖРСЂЕФЧАРЁЩёОЭјТчЃЈетаЉЩёОЭјТчНсЙЙЭъШЋЯрЭЌЃЉЁЃ
Self-Attention at a High Level
Self attentionетИіЕЅДЪПДЦ№РДКУЯёУПИіШЫЖМжЊЕРЪЧЪВУДвтЫМЃЌЕЋЪЕжЪЩЯЫћЪЧЫуЗЈСьгђжааТГіЕФИХФюЃЌФуПЩвдЭЈЙ§дФЖСЃКAttention
is All You Need РДРэНтself attentionЕФдРэЁЃ
МйЩшЯТУцЕФОфзгОЭЪЧЮвУЧашвЊЗвыЕФЪфШыОфЃК
ЁБThe animal didn't cross the street because it was
too tiredЁБ
етОфЛАжаЕФ"it"жИЕФЪЧЪВУДЃПЫќжИЕФЪЧЁАanimalЁБЛЙЪЧЁАstreetЁБЃПЖдгкШЫРДЫЕЃЌетЦфЪЕЪЧвЛИіКмМђЕЅЕФЮЪЬтЃЌЕЋЪЧЖдгквЛИіЫуЗЈРДЫЕЃЌДІРэетИіЮЪЬтЦфЪЕВЂВЛШнвзЁЃself
attentionЕФГіЯжОЭЪЧЮЊСЫНтОіетИіЮЪЬтЃЌЭЈЙ§self attentionЃЌЮвУЧФмНЋЁАitЁБгыЁАanimalЁБСЊЯЕЦ№РДЁЃ
ЕБФЃаЭДІРэЕЅДЪЕФЪБКђЃЌself attentionВуПЩвдЭЈЙ§ЕБЧАЕЅДЪШЅВщПДЦфЪфШыађСажаЕФЦфЫћЕЅДЪЃЌвдДЫРДбАевБрТыетИіЕЅДЪИќКУЕФЯпЫїЁЃ
ШчЙћФуЪьЯЄRNNsЃЌФЧУДФуПЩвдЛиЯывЛЯТЃЌRNNЪЧдѕУДДІРэЯШЧАЕЅДЪ(ЯђСПЃЉгыЕБЧАЕЅДЪ(ЯђСПЃЉЕФЙиЯЕЕФЃПRNNЪЧдѕУДМЦЫуЫћЕФhidden
stateЕФЁЃself-attentionе§ЪЧtransformerжаЩшМЦЕФвЛжжЭЈЙ§ЦфЩЯЯТЮФРДРэНтЕБЧАДЪЕФвЛжжАьЗЈЁЃФуЛсКмШнвзЗЂЯж...ЯрНЯгкRNNsЃЌtransformerОпгаИќКУЕФВЂааадЁЃ

ШчЩЯЭМЃЌЪЧЮвУЧЕкЮхВуEncoderеыЖдЕЅДЪ'it'ЕФЭМЪОЃЌПЩвдЗЂЯжЃЌЮвУЧЕФEncoderдкБрТыЕЅДЪЁЎitЁЏЪБЃЌВПЗжзЂвтСІЛњжЦМЏжадкСЫЁЎanimlЁЏЩЯЃЌетВПЗжЕФзЂвтСІЛсЭЈЙ§ШЈжЕДЋЕнЕФЗНЪНгАЯьЕН'it'ЕФБрТыЁЃ
Self-Attention in Detail
етвЛНкЮвУЧЯШНщЩмШчКЮгУЯђСПЕФЗНЪНРДМЦЫуself attentionЃЌШЛКѓдйРДПДПДЫќЪЧШчКЮЪЙгУОиеѓРДЪЕЯжЕФЁЃ
МЦЫуself attentionЕФЕквЛВНЪЧДгУПИіEncoderЕФЪфШыЯђСПЩЯДДНЈ3ИіЯђСПЃЈдкетИіЧщПіЯТЃЌЖдУПИіЕЅДЪзіДЪЧЖШыЃЉЁЃЫљвдЃЌЖдгкУПИіЕЅДЪЃЌЮвУЧДДНЈвЛИіQueryЯђСПЃЌвЛИіKeyЯђСПКЭвЛИіValueЯђСПЁЃетаЉЯђСПЪЧЭЈЙ§ДЪЧЖШыГЫвдЮвУЧбЕСЗЙ§ГЬжаДДНЈЕФ3ИібЕСЗОиеѓЖјВњЩњЕФЁЃ
зЂвтетаЉаТЯђСПЕФЮЌЖШБШЧЖШыЯђСПаЁЁЃЮвУЧжЊЕРЧЖШыЯђСПЕФЮЌЖШЮЊ512ЃЌЖјетРяЕФаТЯђСПЕФЮЌЖШжЛга64ЮЌЁЃаТЯђСПВЂВЛЪЧБиаыаЁвЛаЉЃЌетЪЧЭјТчМмЙЙЩЯЕФбЁдёЪЙЕУMulti-Headed
AttentionЃЈДѓВПЗжЃЉЕФМЦЫуВЛБфЁЃ
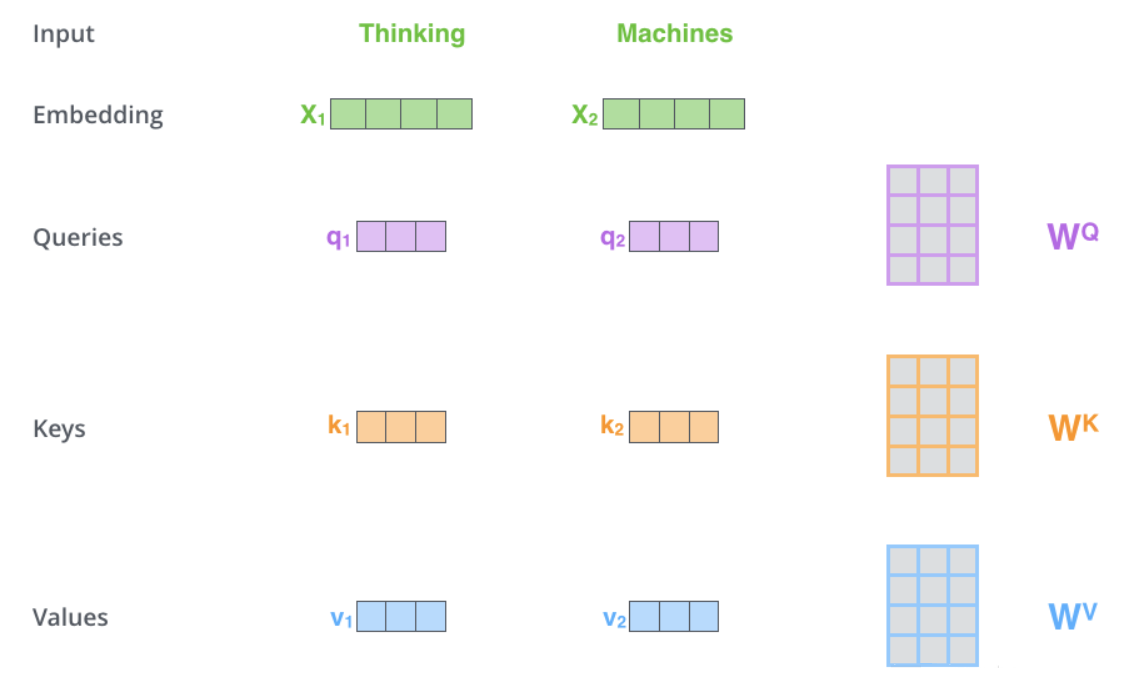
ЮвУЧНЋX1ГЫвдWQЕФШЈжиОиеѓЕУЕНаТЯђСПq1ЃЌq1МШЪЧЁАqueryЁБЕФЯђСПЁЃЭЌРэЃЌзюжеЮвУЧПЩвдЖдЪфШыОфзгЕФУПИіЕЅДЪДДНЈЁАqueryЁБЃЌ
ЁАkeyЁБЃЌЁАvalueЁБЕФаТЯђСПБэЪОаЮЪНЁЃ
ЖдСЫ..ЁАqueryЁБЃЌЁАkeyЁБЃЌЁАvalueЁБЪЧЪВУДЯђСПФиЃПгаЪВУДгУФиЃП
етаЉЯђСПЕФИХФюЪЧКмГщЯѓЃЌЕЋЪЧЫќШЗЪЕгажњгкМЦЫузЂвтСІЁЃВЛЙ§ЯШВЛгУОРНсШЅРэНтЫќЃЌКѓУцЕФЕФФкШнЃЌЛсАяжњФуРэНтЕФЁЃ
МЦЫуself attentionЕФЕкЖўВНЪЧМЦЫуЕУЗжЁЃвдЩЯЭМЮЊР§ЃЌМйЩшЮвУЧдкМЦЫуЕквЛИіЕЅДЪЁАthinkingЁБЕФself
attentionЁЃЮвУЧашвЊИљОнетИіЕЅДЪЖдЪфШыОфзгЕФУПИіЕЅДЪНјааЦРЗжЁЃЕБЮвУЧдкФГИіЮЛжУБрТыЕЅДЪЪБЃЌЗжЪ§ОіЖЈСЫЖдЪфШыОфзгЕФЦфЫћЕЅДЪЕФЙиееГЬЖШЁЃ
ЭЈЙ§НЋqueryЯђСПКЭkeyЯђСПЕуЛїРДЖдЯргІЕФЕЅДЪДђЗжЁЃЫљвдЃЌШчЙћЮвУЧДІРэПЊЪМЮЛжУЕФЕФself
attentionЃЌдђЕквЛИіЗжЪ§ЮЊКЭЕФЕуЛ§ЃЌЕкЖўИіЗжЪ§ЮЊq2КЭk2ЕФЕуЛ§ЁЃШчЯТЭМ
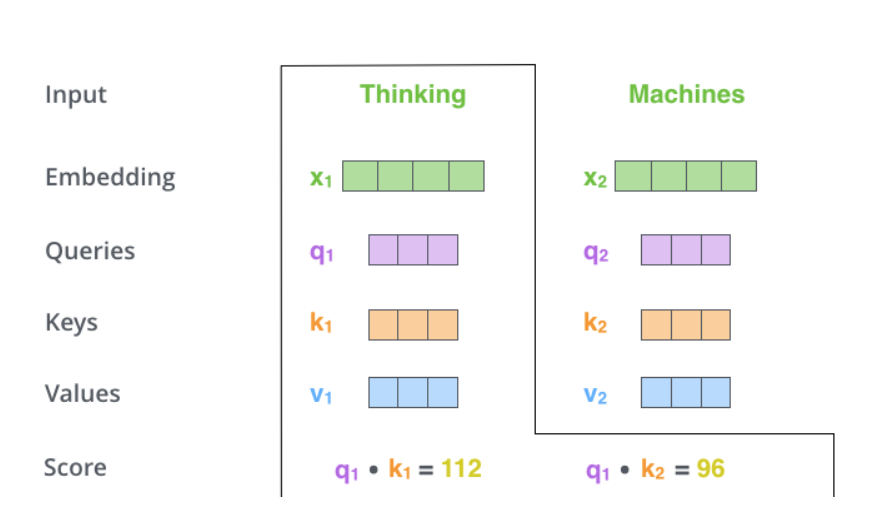
ЕкШ§ВНКЭЕкЫФВНЕФМЦЫуЃЌЪЧНЋЕкЖўВПЕФЕУЗжГ§вд8ЃЈ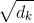 ЃЉЃЈТлЮФжаЪЙгУkeyЯђСПЕФЮЌЖШЪЧ64ЮЌЃЌЦфЦНЗНИљ=8ЃЌетбљПЩвдЪЙЕУбЕСЗЙ§ГЬжаОпгаИќЮШЖЈЕФЬнЖШЁЃетИіВЂВЛЪЧЮЈвЛжЕЃЌОбщЫљЕУЃЉЁЃШЛКѓдйНЋЕУЕНЕФЪфГіЭЈЙ§softmaxКЏЪ§БъзМЛЏЃЌЪЙЕУзюКѓЕФСаБэКЭЮЊ1ЁЃ ЃЉЃЈТлЮФжаЪЙгУkeyЯђСПЕФЮЌЖШЪЧ64ЮЌЃЌЦфЦНЗНИљ=8ЃЌетбљПЩвдЪЙЕУбЕСЗЙ§ГЬжаОпгаИќЮШЖЈЕФЬнЖШЁЃетИіВЂВЛЪЧЮЈвЛжЕЃЌОбщЫљЕУЃЉЁЃШЛКѓдйНЋЕУЕНЕФЪфГіЭЈЙ§softmaxКЏЪ§БъзМЛЏЃЌЪЙЕУзюКѓЕФСаБэКЭЮЊ1ЁЃ
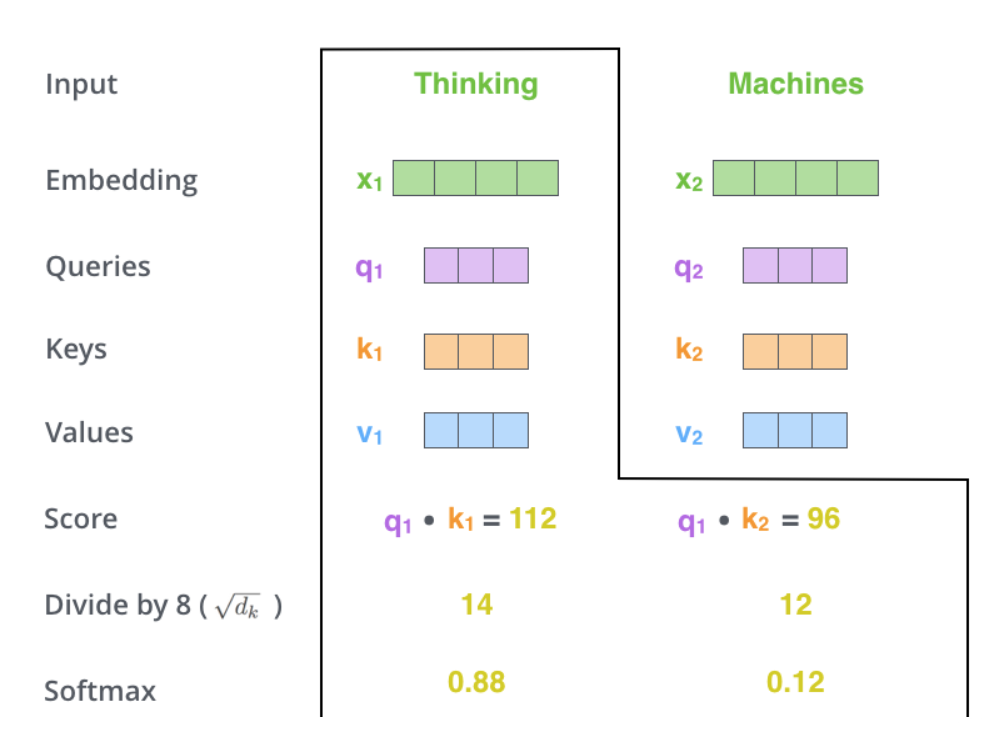
етИіsoftmaxЕФЗжЪ§ОіЖЈСЫЕБЧАЕЅДЪдкУПИіОфзгжаУПИіЕЅДЪЮЛжУЕФБэЪОГЬЖШЁЃКмУїЯдЃЌЕБЧАЕЅДЪЖдгІОфзгжаДЫЕЅДЪЫљдкЮЛжУЕФsoftmaxЕФЗжЪ§зюИпЃЌЕЋЪЧЃЌгаЪБКђattentionЛњжЦвВФмЙизЂЕНДЫЕЅДЪЭтЕФЦфЫћЕЅДЪЃЌетКмгагУЁЃ
ЕкЮхВНЪЧНЋУПИіValueЯђСПГЫвдsoftmaxКѓЕФЕУЗжЁЃетРяЪЕМЪЩЯЕФвтвхдкгкБЃДцЖдЕБЧАДЪЕФЙизЂЖШВЛБфЕФЧщПіЯТЃЌНЕЕЭЖдВЛЯрЙиДЪЕФЙизЂЁЃ
ЕкСљВНЪЧ РлМгМгШЈжЕЕФЯђСПЁЃ етЛсдкДЫЮЛжУВњЩњself-attentionВуЕФЪфГіЃЈЖдгкЕквЛИіЕЅДЪЃЉЁЃ

змНсself-attentionЕФМЦЫуЙ§ГЬЃЌЃЈЕЅДЪМЖБ№ЃЉОЭЪЧЕУЕНвЛИіЮвУЧПЩвдЗХЕНЧАРЁЩёОЭјТчЕФЪИСПЁЃ ШЛЖјдкЪЕМЪЕФЪЕЯжЙ§ГЬжаЃЌИУМЦЫуЛсвдОиеѓЕФаЮЪНЭъГЩЃЌвдБуИќПьЕиДІРэЁЃЯТУцЮвУЧРДПДПДSelf-AttentionЕФОиеѓМЦЫуЗНЪНЁЃ
Matrix Calculation of Self-Attention
ЕквЛВНЪЧШЅМЦЫуQueryЃЌKeyКЭValueОиеѓЁЃЮвУЧНЋДЪЧЖШызЊЛЏГЩОиеѓXжаЃЌВЂНЋЦфГЫвдЮвУЧбЕСЗЕФШЈжЕОиеѓЃЈ,,ЃЉ
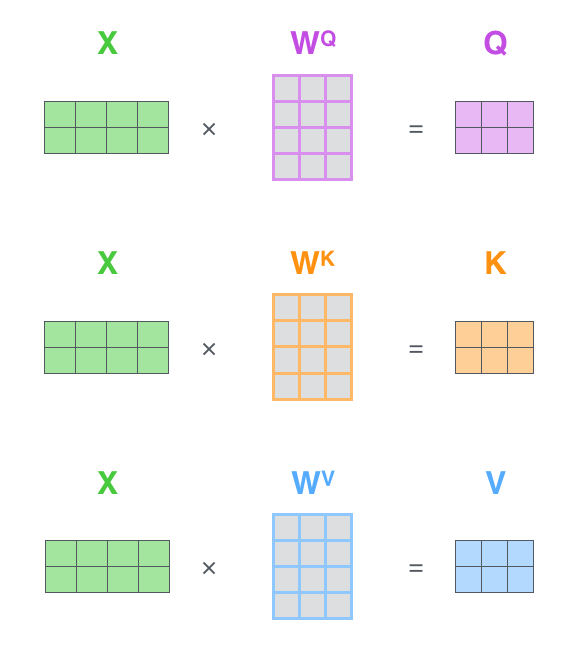
XОиеѓжаЕФУПвЛааЖдгІгкЪфШыОфзгжаЕФвЛИіЕЅДЪЁЃ ЮвУЧПДЕНЕФXУПвЛааЕФЗНПђЪ§ЪЕМЪЩЯЪЧДЪЧЖШыЕФЮЌЖШЃЌЭМжаЫљЪОЕФКЭТлЮФжаЪЧгаВюОрЕФЁЃXЃЈЭМжаЕФ4ИіЗНПђТлЮФжаЮЊ512ИіЃЉКЭq
/ k / vЯђСПЃЈЭМжаЕФ3ИіЗНПђТлЮФжаЮЊ64ИіЃЉ
зюКѓЃЌгЩгкЮвУЧе§дкДІРэОиеѓЃЌЮвУЧПЩвддквЛИіЙЋЪНжаХЈЫѕЧАУцВНжш2ЕН6РДМЦЫуself attentionВуЕФЪфГіЁЃ
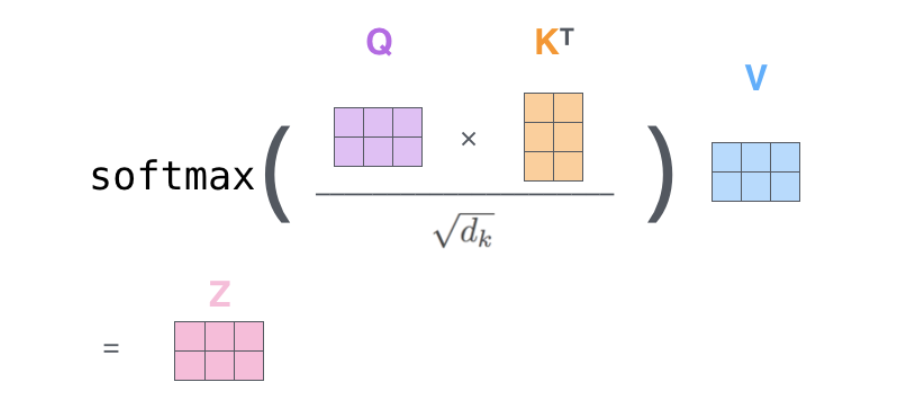
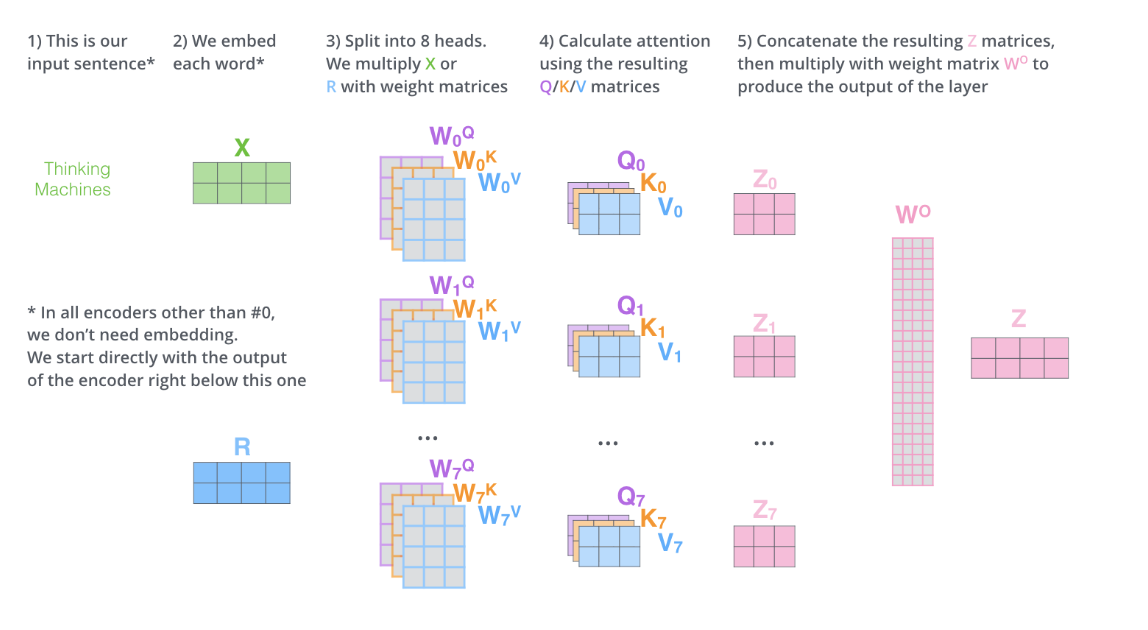
The Beast With Many Heads
БОЮФЭЈЙ§ЪЙгУЁАMulti-headedЁБЕФЛњжЦРДНјвЛВНЭъЩЦself attentionВуЁЃЁАMulti-headedЁБжївЊЭЈЙ§ЯТУц2жаЗНЪНИФЩЦСЫattentionВуЕФадФмЃК
1. ЫќЭиеЙСЫФЃаЭЙизЂВЛЭЌЮЛжУЕФФмСІЁЃдкЩЯУцР§згжаПЩвдПДГіЃЌЁБThe animal didn't cross
the street because it was too tiredЁБЃЌЮвУЧЕФattentionЛњжЦМЦЫуГіЁАitЁБжИДњЕФЮЊЁАanimalЁБЃЌетдкЖдгябдЕФРэНтЙ§ГЬжаЪЧКмгагУЕФЁЃ
2.ЫќЮЊattentionВуЬсЙЉСЫЖрИіЁАrepresentation subspacesЁБЁЃгЩЯТЭМПЩвдПДЕНЃЌдкself
attentionжаЃЌЮвУЧгаЖрИіИіQuery / Key / ValueШЈжиОиеѓЃЈTransformerЪЙгУ8Иіattention
headsЃЉЁЃетаЉМЏКЯжаЕФУПИіОиеѓЖМЪЧЫцЛњГѕЪМЛЏЩњГЩЕФЁЃШЛКѓЭЈЙ§бЕСЗЃЌгУгкНЋДЪЧЖШыЃЈЛђепРДздНЯЕЭEncoder/DecoderЕФЪИСПЃЉЭЖгАЕНВЛЭЌЕФЁАrepresentation
subspacesЃЈБэЪОзгПеМфЃЉЁБжаЁЃ
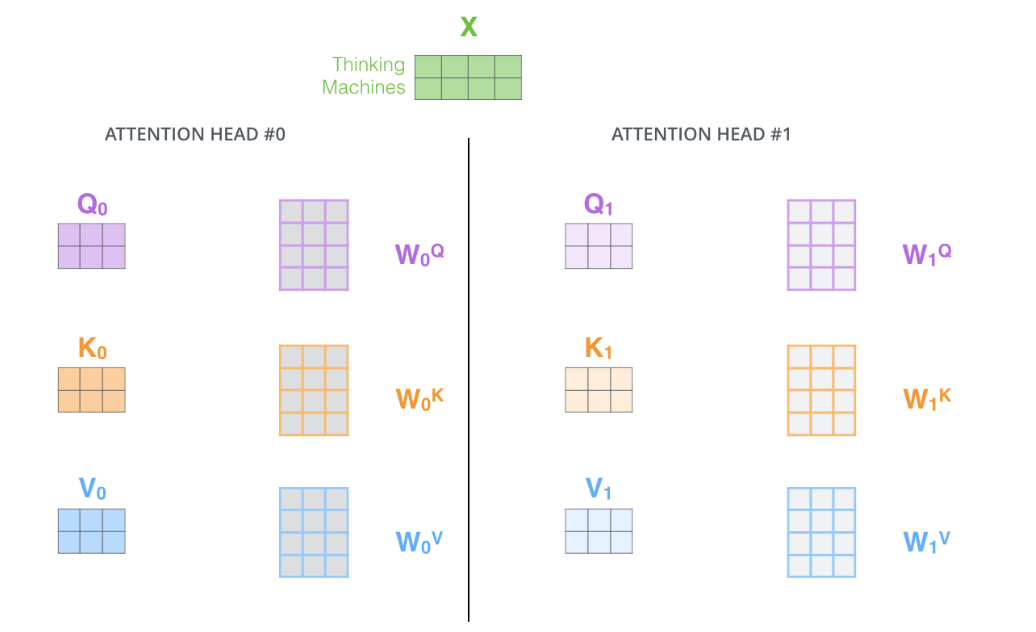
ЭЈЙ§multi-headed attentionЃЌЮвУЧЮЊУПИіЁАheaderЁБЖМЖРСЂЮЌЛЄвЛЬзQ/K/VЕФШЈжЕОиеѓЁЃШЛКѓЮвУЧЛЙЪЧШчжЎЧАЕЅДЪМЖБ№ЕФМЦЫуЙ§ГЬвЛбљДІРэетаЉЪ§ОнЁЃ
ШчЙћЖдЩЯУцЕФР§згзіЭЌбљЕФself attentionМЦЫуЃЌЖјвђЮЊЮвУЧга8ЭЗattentionЃЌЫљвдЮвУЧЛсдкАЫИіЪБМфЕуШЅМЦЫуетаЉВЛЭЌЕФШЈжЕОиеѓЃЌЕЋзюКѓНсЪјЪБЃЌЮвУЧЛсЕУЕН8ИіВЛЭЌЕФОиеѓЁЃШчЯТЭМЃК
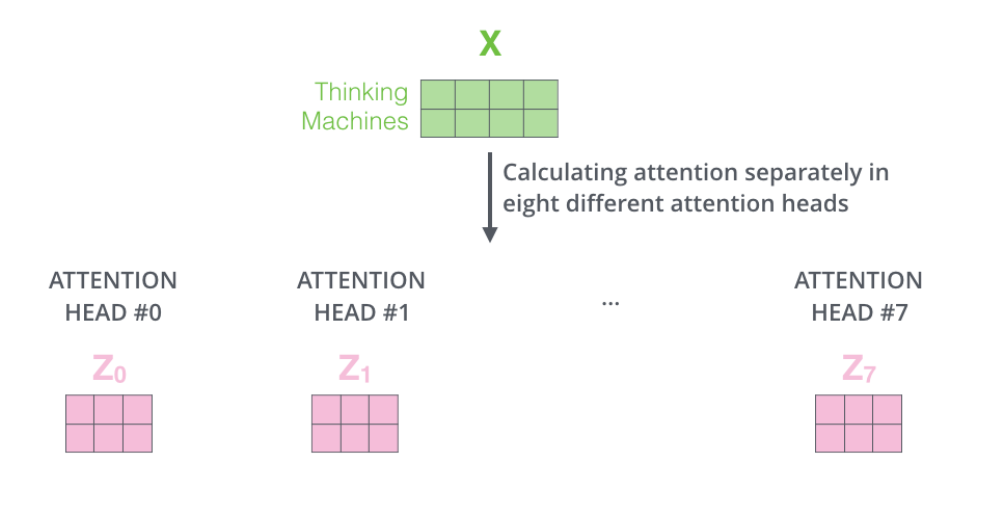
ЧЦЧЦЃЌетЛсИјЮвУЧКѓајЙЄзїдьГЩЪВУДЮЪЬтЃП
ЮвУЧжЊЕРдкself-attentionКѓУцНєИњзХЕФЪЧЧАРЁЩёОЭјТчЃЌЖјЧАРЁЩёОЭјТчНгЪмЕФЪЧЕЅИіОиеѓЯђСПЃЌЖјВЛЪЧ8ИіОиеѓЁЃЫљвдЮвУЧашвЊвЛжжАьЗЈЃЌАбет8ИіОиеѓбЙЫѕГЩвЛИіОиеѓЁЃ
ЮвУЧдѕУДзіЃП
ЮвУЧНЋет8ИіОиеѓСЌНгдквЛЦ№ШЛКѓдйгывЛИіОиеѓЯрГЫЁЃВНжшШчЯТЭМЫљЪОЃК
етбљmulti-headed self attentionЕФШЋВПФкШнОЭНщЩмЭъСЫЁЃжЎЧАПЩФмЖМЪЧвЛаЉЙ§ГЬЕФЭМНтЃЌЯждкЮвНЋетаЉЙ§ГЬСЌНгдквЛЦ№ЃЌгУвЛИіећЬхЕФПђЭМРДБэЪОвЛЯТМЦЫуЕФЙ§ГЬЃЌЯЃЭћПЩвдМгЩюРэНтЁЃ
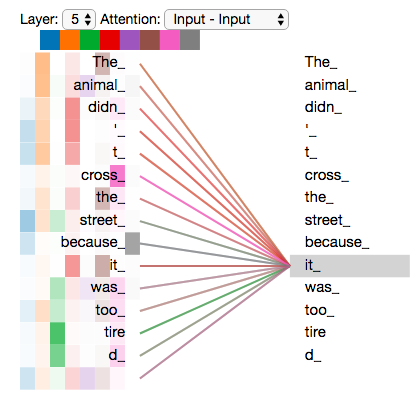
ЯждкЮвУЧвбОДЅМАСЫattentionЕФheaderЃЌШУЮвУЧжиаТЩѓЪгЮвУЧжЎЧАЕФР§згЃЌПДПДР§ОфжаЕФЁАitЁБетИіЕЅДЪдкВЛЭЌЕФattention headerЧщПіЯТЛсгадѕбљВЛЭЌЕФЙизЂЕуЁЃ

ШчЭМЃКЕБЮвУЧЖдЁАitЁБетИіДЪНјааБрТыЪБЃЌвЛИізЂвтСІЕФНЙЕужївЊМЏжадкЁАanimalЁБЩЯЃЌЖјСэвЛИізЂвтСІМЏжадкЁАtiredЁБ
ЕЋЪЧЃЌШчЙћЮвУЧНЋЫљгазЂвтСІЬэМгЕНЭМЦЌжаЃЌФЧУДЪТЧщПЩФмИќФбРэНтЃК
Representing The Order of The Sequence Using Positional
Encoding
# ЪЙгУЮЛжУБрТыБэЪОађСаЕФЫГађ
ЮвУЧПЩФмКіТдСЫШЅНщЩмвЛИіживЊЕФФкШнЃЌОЭЪЧдѕУДПМТЧЪфШыађСажаЕЅДЪЫГађЕФЗНЗЈЁЃ
ЮЊСЫНтОіетИіЮЪЬтЃЌtransformerЮЊУПИіЪфШыЕЅДЪЕФДЪЧЖШыЩЯЬэМгСЫвЛИіаТЯђСП-ЮЛжУЯђСПЁЃ
ЮЊСЫНтОіетИіЮЪЬтЃЌБфЛЛЦїЮЊУПИіЪфШыЧЖШыЬэМгСЫвЛИіЯђСПЁЃетаЉЮЛжУБрТыЯђСПгаЙЬЖЈЕФЩњГЩЗНЪНЃЌЫљвдЛёШЁЫћУЧЪЧКмЗНБуЕФЃЌЕЋЪЧетаЉаХЯЂШЗЪЧКмгагУЕФЃЌЫћУЧФмВЖзНДѓАТУПИіЕЅДЪЕФЮЛжУЃЌЛђепађСажаВЛЭЌЕЅДЪжЎМфЕФОрРыЁЃНЋетаЉаХЯЂвВЬэМгЕНДЪЧЖШыжаЃЌШЛКѓгыQ/K/VЯђСПЕуЛїЃЌЛёЕУЕФattentionОЭгаСЫОрРыЕФаХЯЂСЫЁЃ
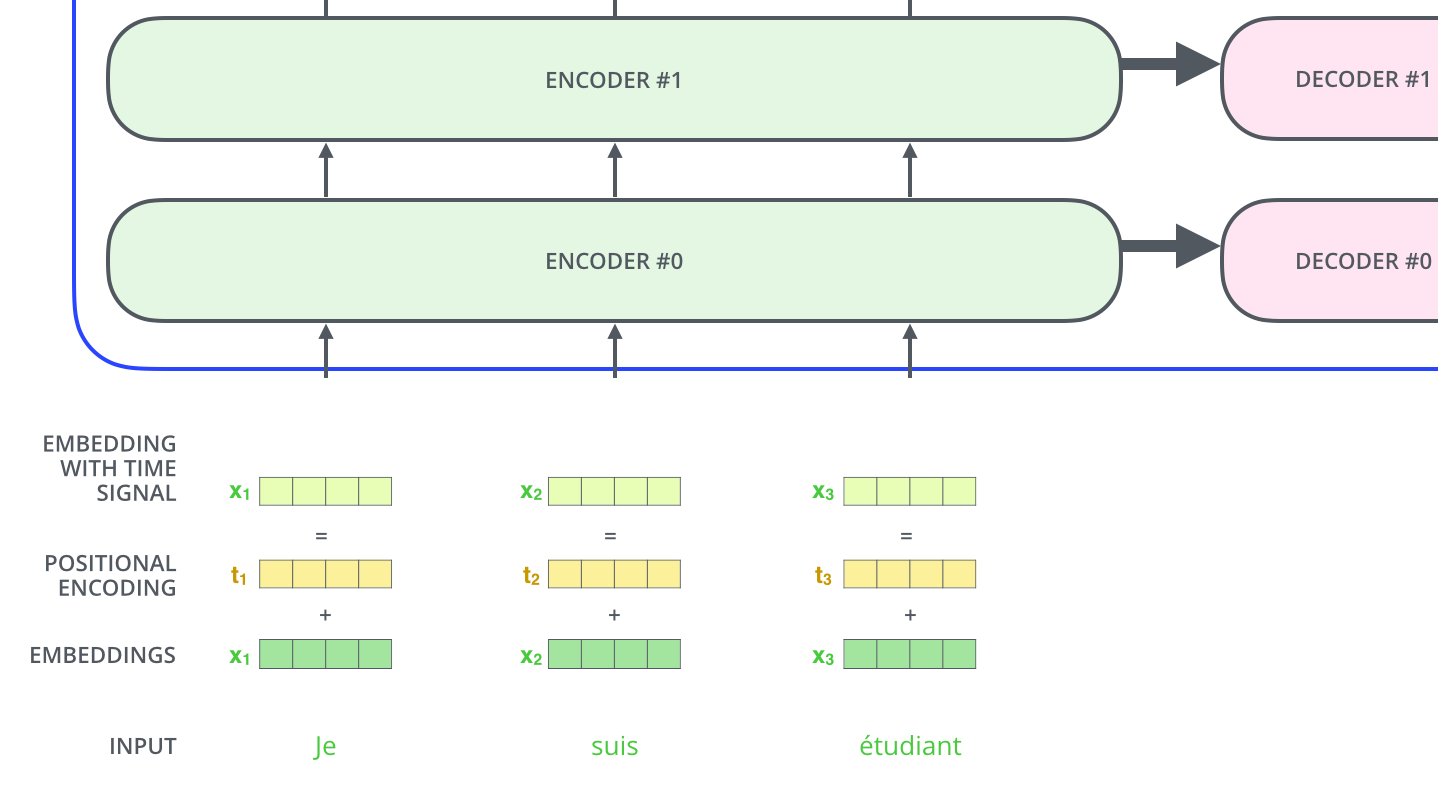
ЮЊСЫШУФЃаЭВЖзНЕНЕЅДЪЕФЫГађаХЯЂЃЌЮвУЧЬэМгЮЛжУБрТыЯђСПаХЯЂЃЈPOSITIONAL ENCODINGЃЉ-ЮЛжУБрТыЯђСПВЛашвЊбЕСЗЃЌЫќгавЛИіЙцдђЕФВњЩњЗНЪНЁЃ
ШчЙћЮвУЧЕФЧЖШыЮЌЖШЮЊ4ЃЌФЧУДЪЕМЪЩЯЕФЮЛжУБрТыОЭШчЯТЭМЫљЪОЃК
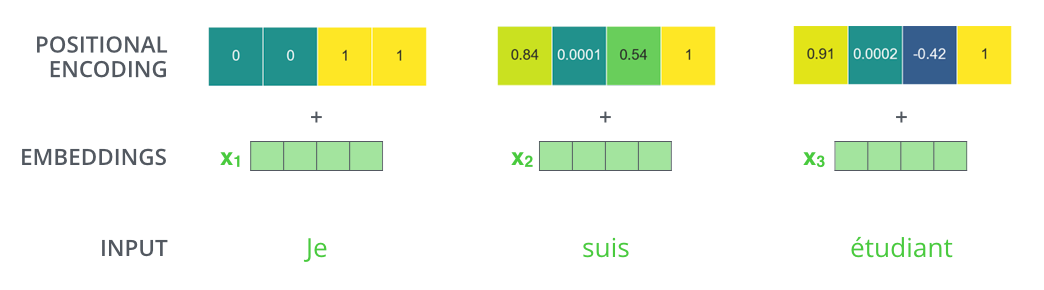
ФЧУДЩњГЩЮЛжУЯђСПашвЊзёбдѕбљЕФЙцдђФиЃП
ЙлВьЯТУцЕФЭМаЮЃЌУПвЛааЖМДњБэзХЖдвЛИіЪИСПЕФЮЛжУБрТыЁЃвђДЫЕквЛааОЭЪЧЮвУЧЪфШыађСажаЕквЛИізжЕФЧЖШыЯђСПЃЌУПааЖМАќКЌ512ИіжЕЃЌУПИіжЕНщгк1КЭ-1жЎМфЁЃЮвУЧгУбеЩЋРДБэЪО1ЃЌ-1жЎМфЕФжЕЃЌетбљЗНБуПЩЪгЛЏЕФЗНЪНБэЯжГіРДЃК
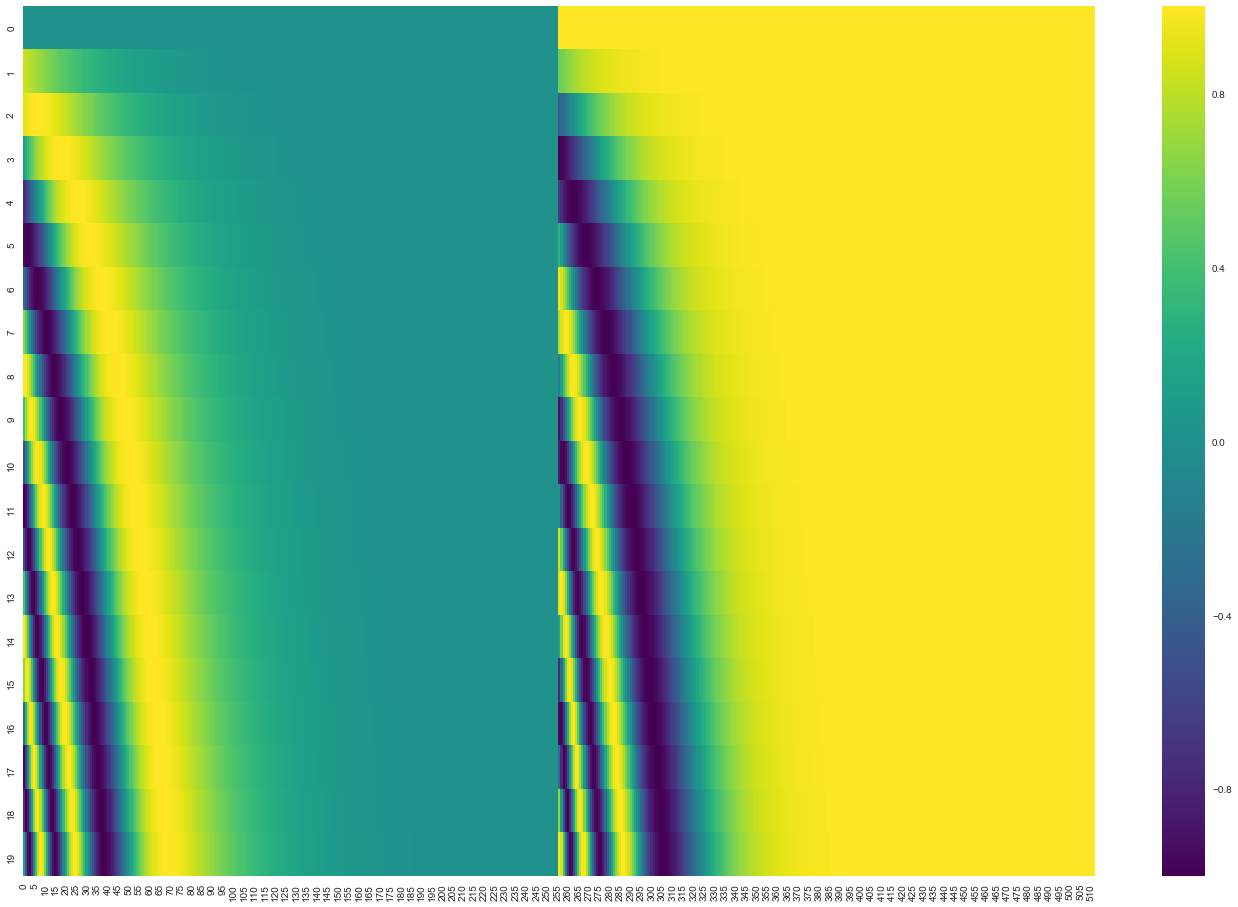
етЪЧвЛИі20ИізжЃЈааЃЉЕФЃЈ512ЃЉСаЮЛжУБрТыЪОР§ЁЃФуЛсЗЂЯжЫќеІжааФЮЛжУБЛЗжЮЊСЫ2АыЃЌетЪЧвђЮЊзѓАыВПЗжЕФжЕЪЧвЛгЩвЛИіе§ЯвКЏЪ§ЩњГЩЕФЃЌЖјгвАыВПЗжЪЧгЩСэвЛИіКЏЪ§ЃЈгрЯвЃЉЩњГЩЁЃШЛКѓНЋЫќУЧСЌНгЦ№РДаЮГЩУПИіЮЛжУБрТыЪИСПЁЃ
ЮЛжУБрТыЕФЙЋЪНдкТлЮФЃЈ3.5НкЃЉжагаУшЪіЁЃФувВПЩвддкжаВщПДгУгкЩњГЩЮЛжУБрТыЕФДњТыget_timing_signal_1d()ЁЃетВЛЪЧЮЛжУБрТыЕФЮЈвЛПЩФмЗНЗЈЁЃШЛЖјЃЌЫќОпгаФмЙЛРЉеЙЕНПДВЛМћЕФађСаГЄЖШЕФгХЕуЃЈР§ШчЃЌШчЙћЮвУЧбЕСЗЕФФЃаЭБЛвЊЧѓЗвыЕФОфзгБШЮвУЧбЕСЗМЏжаЕФШЮКЮОфзгЖМГЄЃЉЁЃ
The Residuals
етвЛНкЮвЯыНщЩмЕФЪЧencoderЙ§ГЬжаЕФУПИіself-attentionВуЕФзѓгвСЌНгЧщПіЃЌЮвУЧГЦетИіЮЊЃКlayer-normalization ВНжшЁЃШчЯТЭМЫљЪОЃК
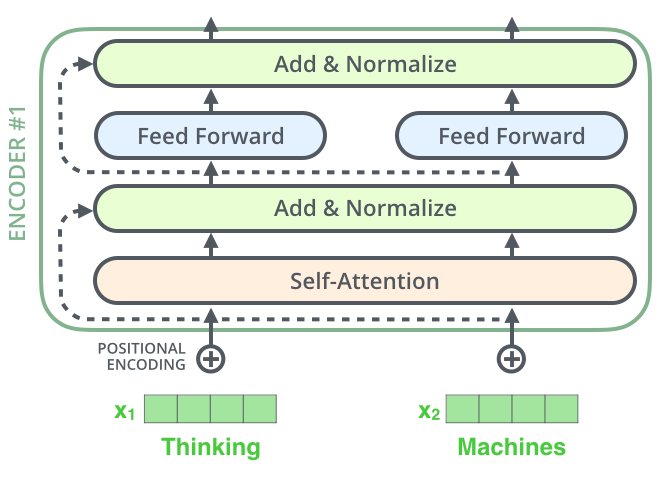
дкНјвЛВНЬНЫїЦфФкВПМЦЫуЗНЪНЃЌЮвУЧПЩвдНЋЩЯУцЭМВуПЩЪгЛЏЮЊЯТЭМЃК
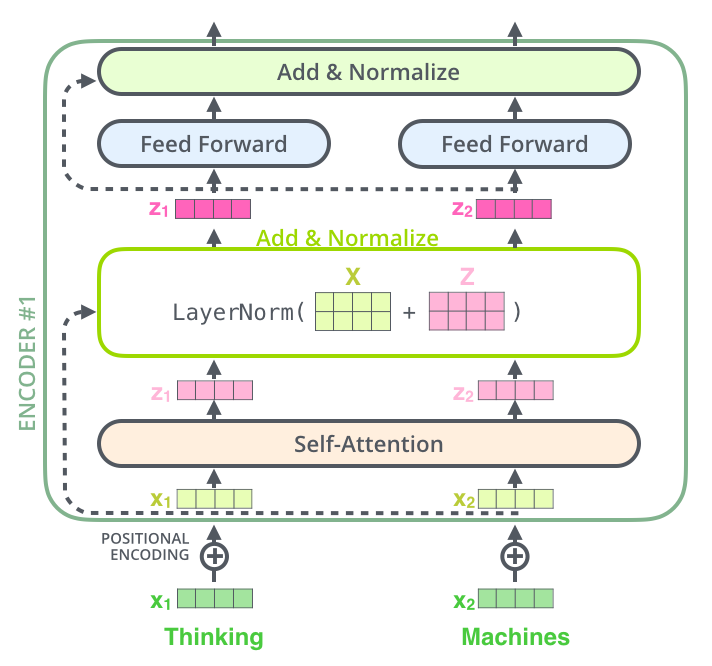
DecoderЕФзгВувВЪЧЭЌбљЕФЃЌШчЙћЮвУЧЯызіЖбЕўСЫ2ИіEncoderКЭ2ИіDecoderЕФTransformerЃЌФЧУДЫќПЩЪгЛЏОЭЛсШчЯТЭМЫљЪОЃК

The Decoder Side
ЮвУЧвбОЛљБОНщЩмЭъСЫEncoderЕФДѓЖрЪ§ИХФюЃЌЮвУЧЛљБОЩЯвВПЩвддЄжЊDecoderЪЧдѕУДЙЄзїЕФЁЃЯждкЮвУЧРДзаЯИЬНЬжЯТDecoderЕФЪ§ОнМЦЫудРэЃЌ
ЕБађСаЪфШыЪБЃЌEncoderПЊЪМЙЄзїЃЌзюКѓдкЦфЖЅВуЕФEncoderЪфГіЪИСПзщГЩЕФСаБэЃЌШЛКѓЮвУЧНЋЦфзЊЛЏЮЊвЛзщattentionЕФМЏКЯЃЈK,VЃЉЁЃЃЈK,VЃЉНЋДјШыУПИіDecoderЕФЁАencoder-decoder
attentionЁБВужаШЅМЦЫуЃЈетбљгажњгкdecoderВЖЛёЪфШыађСаЕФЮЛжУаХЯЂЃЉ

ЭъГЩencoderНзЖЮКѓЃЌЮвУЧПЊЪМdecoderНзЖЮЃЌdecoderНзЖЮжаЕФУПИіВНжшЪфГіРДздЪфГіађСаЕФдЊЫиЃЈдкетжжЧщПіЯТЮЊгЂгяЗвыОфзгЃЉЁЃ
ЩЯУцЪЕМЪЩЯвбОЪЧгІгУЕФНзЖЮСЫЃЌФЧЮвУЧбЕСЗНзЖЮЪЧШчКЮЕФФиЃП
ЮвУЧвдЯТЭМЕФВНжшНјаабЕСЗЃЌжБЕНЪфГівЛИіЬиЪтЕФЗћКХ<end of sentence>ЃЌБэЪОвбОЭъГЩСЫЁЃ The
output of each step is fed to the bottom decoder in
the next time step, and the decoders bubble up their
decoding results just like the encoders did. ЖдгкDecoderЃЌКЭEncoderвЛбљЃЌЮвУЧдкУПИіDecoderЕФЪфШызіДЪЧЖШыВЂЬэМгЩЯБэЪОУПИізжЮЛжУЕФЮЛжУБрТы

DecoderжаЕФself attentionгыEncoderЕФself attentionТдгаВЛЭЌЃК
дкDecoderжаЃЌself attentionжЛЙизЂЪфГіађСажаЕФНЯдчЕФЮЛжУЁЃетЪЧдкself
attentionМЦЫужаЕФsoftmaxВНжшжЎЧАЦСБЮСЫЬиеїЮЛжУЃЈЩшжУЮЊ -infЃЉРДЭъГЩЕФЁЃ
ЁАEncoder-Decoder AttentionЁБВуЕФЙЄзїЗНЪНгы"Multi-Headed
Self-Attention"вЛбљЃЌжЛЪЧЫќДгЯТУцЕФВуДДНЈЦфQueryОиеѓЃЌВЂдкEncoderЖбеЛЕФЪфГіжаЛёШЁKeyКЭValueЕФОиеѓЁЃ
The Final Linear and Softmax Layer
DecoderЕФЪфГіЪЧИЁЕуЪ§ЕФЯђСПСаБэЁЃЮвУЧЪЧШчКЮНЋЦфБфГЩвЛИіЕЅДЪЕФФиЃПетОЭЪЧзюжеЕФЯпадВуКЭsoftmaxВуЫљзіЕФЙЄзїЁЃ
ЯпадВуЪЧвЛИіМђЕЅЕФШЋСЌНгЩёОЭјТчЃЌЫќЪЧгЩDecoderЖбеЛВњЩњЕФЯђСПЭЖгАЕНвЛИіИќДѓЃЌИќДѓЕФЯђСПжаЃЌГЦЮЊЖдЪ§ЯђСП
МйЩшЪЕбщжаЮвУЧЕФФЃаЭДгбЕСЗЪ§ОнМЏЩЯзмЙВбЇЯАЕН1ЭђИігЂгяЕЅДЪЃЈЁАOutput VocabularyЁБЃЉЁЃетЖдгІЕФLogitsЪИСПвВга1ЭђИіГЄЖШ-УПвЛЖЮБэЪОСЫвЛИіЮЈвЛЕЅДЪЕФЕУЗжЁЃдкЯпадВужЎКѓЪЧвЛИіsoftmaxВуЃЌsoftmaxНЋетаЉЗжЪ§зЊЛЛЮЊИХТЪЁЃбЁШЁИХТЪзюИпЕФЫїв§ЃЌШЛКѓЭЈЙ§етИіЫїв§евЕНЖдгІЕФЕЅДЪзїЮЊЪфГіЁЃ
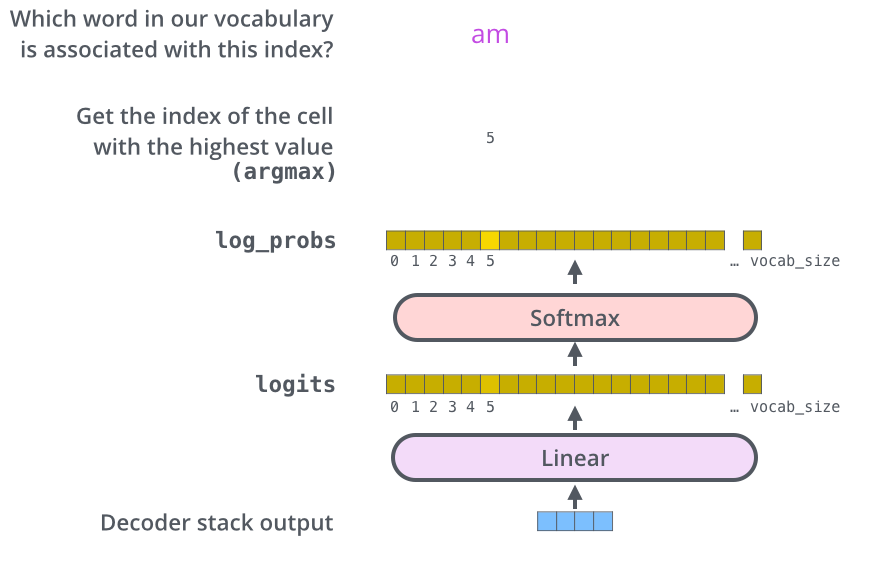
ЩЯЭМЪЧДгDecoderЕФЪфГіПЊЪМЕНзюжеsoftmaxЕФЪфГіЁЃвЛВНвЛВНЕФЭМНтЁЃ
Recap Of Training
ЯждкЮвУЧвбОНВНтСЫtransformerЕФбЕСЗШЋЙ§ГЬСЫЃЌШУЮвУЧЛиЙЫвЛЯТЁЃ
дкбЕСЗЦкМфЃЌЮДОбЕСЗЕФФЃаЭНЋЭЈЙ§ШчЩЯЕФСїГЬвЛВНвЛВНМЦЫуЕФЁЃЖјЧввђЮЊЮвУЧЪЧдкЖдБъМЧЕФбЕСЗЪ§ОнМЏНјаабЕСЗЃЈЛњЦїЗвыПЩвдПДзіЫЋгяЦНаагяСФЃЉЃЌФЧУДЮвУЧПЩвдНЋФЃаЭЪфГігыЪЕМЪЕФе§ШЗД№АИЯрБШНЯЃЌРДНјааЗДЯђДЋВЅЁЃ
ЮЊСЫИќКУЕФРэНтетВПЗжФкШнЃЌЮвУЧМйЩшЮвУЧЪфГіЕФДЪЛужЛгаЃЈЁАaЁБЃЌЁАamЁБЃЌЁАiЁБЃЌЁАthanksЁБЃЌ
ЁАstudentЁБКЭЁА<eos>ЁБЃЈЁАОфФЉЁБЕФЫѕаДЃЉЃЉ
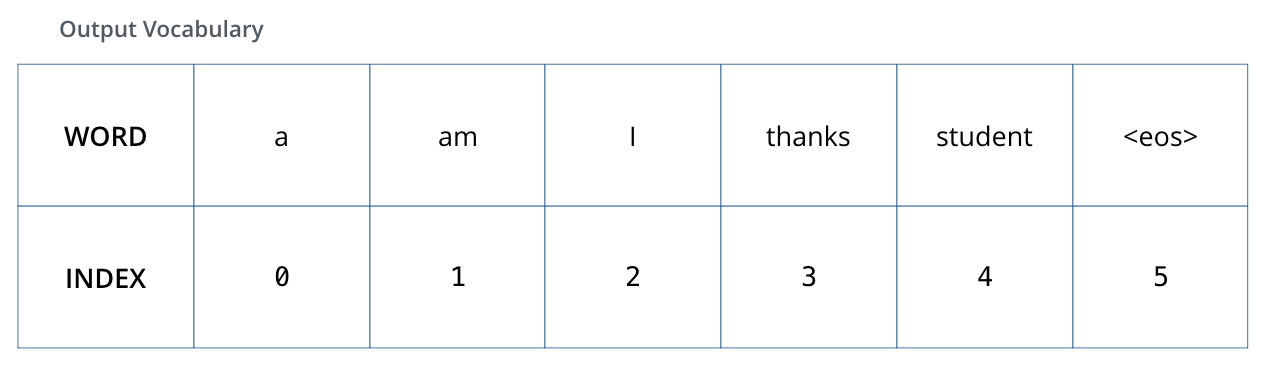
дкЮвУЧПЊЪМбЕСЗжЎЧАЃЌЮвУЧФЃаЭЕФЪфГіДЪЛуЪЧдкдЄДІРэНзЖЮДДНЈЕФЁЃ
вЛЕЉЮвУЧЖЈвхСЫЪфГіЕФДЪЛуБэЃЌФЧУДЮвУЧОЭПЩвдЪЙгУЯрЭЌПэЖШЕФЯђСПРДБэЪОДЪЛуБэжаЕФУПИіЕЅДЪЁЃГЦЮЊone-hotБрТыЁЃР§ШчЃЌЮвУЧПЩвдЪЙгУЯТУцЯђСПРДБэЪОЕЅДЪЁАamЁБЃК

ЪОР§ЃКЮвУЧЕФЪфГіДЪЛуБэЕФone-hotБрТы
ЯТвЛНкЮвУЧдйЬжТлвЛЯТФЃаЭЕФЫ№ЪЇКЏЪ§ЃЌЮвУЧгХЛЏЕФжИБъЃЌв§ЕМвЛИібЕСЗгаЫиЧвСюШЫОЊбШЕФОЋШЗФЃаЭЁЃ
The Loss Function
МйЩшЮвУЧе§дкбЕСЗвЛИіФЃаЭЃЌБШШчНЋЁАmerciЁБЗвыГЩЁАаЛаЛЁБЁЃетвтЮЖзХЮвУЧЯЃЭћФЃаЭМЦЫуКѓЕФЪфГіЮЊЁАаЛаЛЁБЃЌЕЋгЩгкетжжФЃЪНЛЙУЛгаНгЪмЙ§бЕСЗЃЌЫљвдетжжЧщПіВЛЬЋПЩФмЗЂЩњЁЃ
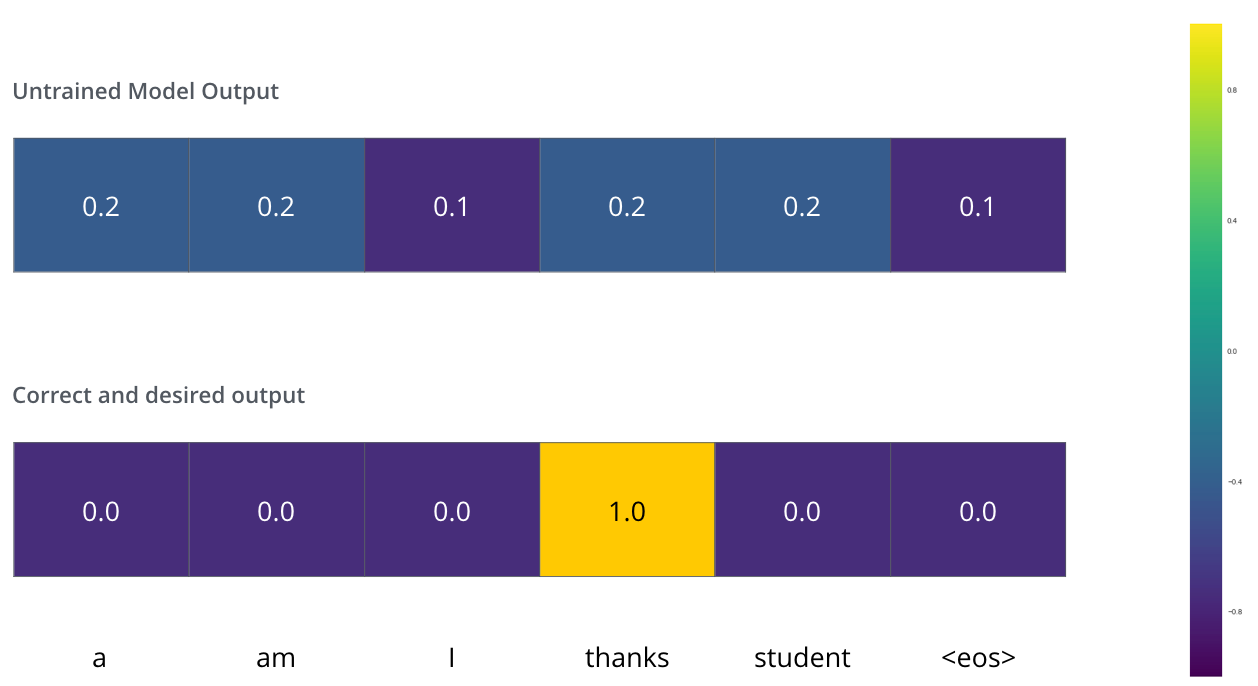
етЪЧвђЮЊФЃаЭЕФВЮЪ§ЃЈШЈжиЃЉЖМЪЧЫцЛњГѕЪМЛЏЕФЃЌвђДЫЃЈЮДОбЕСЗЕФЃЉФЃаЭЖдУПИіЕЅДЪВњЩњЕФИХТЪЗжВМЪЧОпгаЮоЯоПЩФмЕФЃЌЕЋЪЧЮвУЧПЩвдЭЈЙ§ЦфгрЪЕМЪЮвУЧЦкЭћЕФЪфГіНјааБШНЯЃЌШЛКѓРћгУЗДЯђДЋВЅЕїећЫљгаФЃаЭЕФШЈжиЃЌЪЙЕУЪфГіИќНгНќЫљашЕФЪфГіЁЃ
ФЧУДШчКЮБШНЯЫуЗЈдЄВтжЕгыецЪЕЦкЭћжЕФиЃП
ЪЕМЪЩЯЃЌЮвУЧЖдЦфзівЛИіМђЕЅЕФМѕЗЈМДПЩЁЃФувВПЩвдСЫНтНЛВцьиКЭKullback-LeiblerЩЂЖШРДеЦЮеетжжВюжЕЕФХаЖЯЗНЪНЁЃ
ЕЋЪЧЃЌашвЊзЂвтЕФЪЧЃЌетжЛЪЧвЛИіКмМђЕЅЕФdemoЃЌецЪЕЧщПіЯТЃЌЮвУЧашвЊЪфГівЛИіИќГЄЕФОфзгЃЌР§ШчЁЃЪфШыЃКЁАje
suis ЈІtudiantЁБКЭдЄЦкЪфГіЃКЁАI am a studentЁБЁЃетбљЕФОфзгЪфШыЃЌвтЮЖзХЮвУЧЕФФЃаЭФмЙЛСЌајЕФЪфГіИХТЪЗжВМЁЃЦфжаЃК
УПИіИХТЪЗжВМгЩПэЖШЮЊvocab_sizeЕФЯђСПБэЪОЃЈдкЮвУЧЕФЪОР§жаvocab_sizeЮЊ6ЃЌЕЋЪЕМЪЩЯПЩФмЮЊ3,000Лђ10,000ЮЌЖШЃЉ
ЕквЛИХТЪЗжВМдкгыЕЅДЪЁАiЁБЯрЙиСЊЕФЕЅдЊДІОпгазюИпИХТЪ
ЕкЖўИХТЪЗжВМдкгыЕЅДЪЁАamЁБЯрЙиСЊЕФЕЅдЊИёжаОпгазюИпИХТЪ
вРДЫРрЭЦЃЌжБЕНЕкЮхИіЪфГіЗжВМБэЪО' <end of sentence>'ЗћКХЃЌвтЮЖзХдЄВтНсЪјЁЃ

ЩЯЭМЮЊЃКЪфШыЃКЁАje suis ЈІtudiantЁБКЭдЄЦкЪфГіЃКЁАI am a studentЁБЕФЦкЭћдЄВтИХТЪЗжВМЧщПіЁЃ
дкЫуЗЈФЃаЭжаЃЌЫфШЛВЛФмДяЕНЦкЭћЕФЧщПіЃЌЕЋЪЧЮвУЧашвЊдкбЕСЗСЫзуЙЛГЄЪБМфжЎКѓЃЌЮвУЧЕФЫуЗЈФЃаЭФмЙЛгаШчЯТЭМЫљЪОЕФИХТЪЗжВМЧщПіЃК
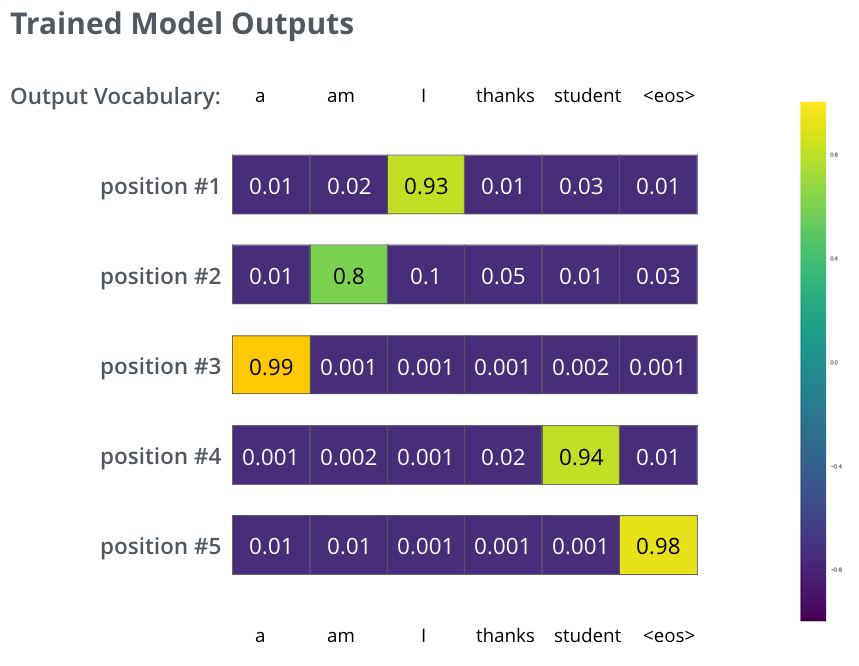
ЯждкЃЌвђЮЊФЃаЭвЛДЮЩњГЩвЛИіЪфГіЃЌЮвУЧПЩвдРэНтЮЊетИіФЃаЭДгИУИХТЪЗжВМЃЈsoftmaxЃЉЪИСПжабЁдёСЫОпгазюИпИХТЪЕФЕЅДЪВЂЖЊЦњСЫЦфгрЕФЕЅДЪЁЃ
ЯждкЃЌвђЮЊФЃаЭвЛДЮЩњГЩвЛИіЪфГіЃЌЮвУЧПЩвдМйЩшФЃаЭДгИУИХТЪЗжВМжабЁдёОпгазюИпИХТЪЕФЕЅДЪВЂЖЊЦњЦфгрЕФЕЅДЪЁЃ
етРяга2ИіЗНЗЈЃКвЛИіЪЧЬАРЗЫуЗЈЃЈgreedy decodingЃЉЃЌвЛИіЪЧВЈЪјЫбЫїЃЈbeam
searchЃЉЁЃВЈЪјЫбЫїЪЧвЛИігХЛЏЬсЩ§ЕФММЪѕЃЌПЩвдГЂЪдШЅСЫНтвЛЯТЃЌетРяВЛзіИќЖрНтЪЭЁЃ |





