| БрМЭЦМі: |
БОЮФжївЊжївЊЪЧЪсРэвЛЯТTransformerЕФРэТлжЊЪЖ,
ЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздcsdnЃЌгЩЛ№СњЙћШэМўDeloresБрМЭЦМі |
|
1. ећЬхНсЙЙ
ЪзЯШДгећЬхЩЯПДвЛЯТTransformerЕФНсЙЙЃК

ДгЭМжаПЩвдПДГіЃЌећЬхЩЯTransformerгЩЫФВПЗжзщГЩЃК
Inputs : Inputs=WordEmbedding(Inputs)+PositionalEmbedding Inputs = WordEmbedding(Inputs)+ PositionalEmbeddingInputs=WordEmbedding(Inputs)+PositionalEmbedding
Outputs : Ouputs=WordEmbedding(Outputs)+PositionalEmbedding Ouputs = WordEmbedding(Outputs) + PositionalEmbeddingOuputs=WordEmbedding(Outputs)+PositionalEmbedding
Encoders stack : гЩСљИіЯрЭЌЕФEncoderВузщГЩЃЌГ§СЫЕквЛИіEncoderВуЕФЪфШыЮЊInputsЃЌЦфЫћEncoderВуЕФЪфШыЮЊЩЯвЛИіEncoderВуЕФЪфГі
Decoders stack : гЩСљИіЯрЭЌЕФDecoderВузщГЩЃЌГ§СЫЕквЛИіDecoderВуЕФЪфШыЮЊOutputsКЭзюКѓвЛИіEncoderВуЕФЪфГіЃЌЦфЫћDecoderВуЕФЪфШыЮЊЩЯвЛИіDecoderВуЕФЪфГіКЭзюКѓвЛИіEncoderВуЕФЪфГі
ШчЯТЭМЫљЪОЃЌдкИќИпЕФВуМЖЩЯРДРэНтEncoderКЭDecoderВужЎМфЕФЪфШыКЭЪфГіЕФЙиЯЕЃЌПЩвдИќжБЙлЁЃ

ЖјEncoderВуКЭDecoderВуЕФФкВПзщГЩжЎМфЕФВювьШчЯТЭМЫљЪОЁЃУПвЛИіEncoderВуЖМАќКЌСЫвЛИіSelf-AttentionзгВуКЭвЛИіFeed ForwardзгВуЁЃУПИіDecoderВуЖМАќКЌСЫвЛИіSelf-AttentionзгВуЁЂвЛИіEncoder-Decoder AttentionзгВуКЭвЛИіFeed ForwardзгВуЁЃEncoderВуКЭDecoderВужЎМфЕФВюБ№дкгкDecoderжаЖрСЫвЛИіEncoder-Decoder AttentionзгВуЃЌЖјЦфЫћСНИізгВуЕФНсЙЙдкСНепжаЪЧЯрЭЌЕФЁЃ

2. Self-Attention
2.1 ЮЊЪВУДбЁдёSelf-Attention
ЪзЯШЭЈЙ§вЛИіМђЕЅЕФР§згЃЌРДМђЕЅЫЕУївЛЯТself-AttentionетжжЛњжЦНЯжЎДЋЭГЕФађСаФЃаЭЕФгХЪЦЫљдкЁЃБШШчЮвУЧЕБЧАвЊЗвыЕФОфзгЮЊThe animal didnЁЏt cross the street because it was too tiredЃЌдкЗвыitЪБЃЌЫќОПОЙжИДњЕФЪЧЪВУДФиЃПвЊШЗЖЈitжИДњЕФФкШнЃЌКСЮовЩЮЪЮвУЧашвЊЭЌЪБЙизЂЕНетИіДЪЕФЩЯЯТЮФгяОГжаЕФЫљгаДЪЃЌдкетОфЛАжажиЕуЮЊanimal, street, tiredЃЌШЛКѓИљОнГЃЪЖЃЌЮвУЧжЊЕРжЛгаanimalВХЛсtiredЃЌЫљвдШЗЖЈСЫitжИДњЕФЪЧanimalЁЃШчЙћНЋtiredИФЮЊnarrowЃЌФЧКмЯдШЛitгІИУжИЕФЪЧstreetЃЌвђЮЊжЛгаstreetВХФмгУnarrowаоЪЮЁЃ
Self-AttentionЛњжЦдкЖдвЛИіДЪНјааБрТыЪБЃЌЛсПМТЧетИіДЪЩЯЯТЮФжаЕФЫљгаДЪКЭетаЉДЪЖдзюжеБрТыЕФЙБЯзЃЌдйИљОнЕУЕНЕФаХЯЂЖдЕБЧАДЪНјааБрТыЃЌетОЭБЃжЄСЫдкЗвыitЪБЃЌдкЫќЩЯЯТЮФжаЕФanimal, street, tiredЖМЛсБЛПМТЧНјРДЃЌДгЖјНЋitе§ШЗЕФЗвыГЩanimal
ФЧУДШчЙћЮвУЧВЩгУДЋЭГЕФЯёLSTMетбљЕФађСаФЃаЭРДНјааЗвыФиЃПгЩгкLSTMФЃаЭЪЧЕЅЯђЕФ(ЧАЯђЛђепКѓЯђ)ЃЌЯдШЛЫќЮоЗЈЭЌЪБПМТЧЕНitЕФЩЯЯТЮФаХЯЂЃЌетЛсдьГЩЗвыЕФДэЮѓЁЃвдЧАЯђLSTMЮЊР§ЃЌЕБЗвыitЪБЃЌФмПМТЧЕФаХЯЂжЛгаThe animal didn't cross the street becauseЃЌЖјЮоЗЈПМТЧwas too tiredЃЌетЪЙЕУФЃаЭЮоЗЈШЗЖЈitЕНЕзжИДњЕФЪЧstreetЛЙЪЧanimalЁЃЕБШЛЮвУЧПЩвдВЩгУЖрВуЕФLSTMНсЙЙЃЌЕЋетжжНсЙЙВЂЗЧЯёSelf-AttentionвЛбљЪЧеце§втвхЩЯЕФЫЋЯђЃЌЖјЪЧЭЈЙ§ЦДНгЧАЯђLSTMКЭКѓЯђLSTMЕФЪфГіЪЕЯжЕФЃЌетЛсЪЙЕУФЃаЭЕФИДдгЖШЛсдЖдЖИпгкSelf-AttentionЁЃ
ЯТЭМЪЧФЃаЭЕФзюЩЯвЛВу(ЯТБъ0ЪЧЕквЛВуЃЌ5ЪЧЕкСљВу)EncoderЕФAttentionПЩЪгЛЏЭМЁЃетЪЧtensor2tensorетИіЙЄОпЪфГіЕФФкШнЁЃЮвУЧПЩвдПДЕНЃЌдкБрТыitЕФЪБКђгавЛИіAttention Head(КѓУцЛсНВЕН)зЂвтЕНСЫAnimalЃЌвђДЫБрТыКѓЕФitгаAnimalЕФгявхЁЃ

Self-AttentionЕФгХЪЦВЛНіНідкгкЖдДЪгяНјааБрТыЪБФмГфЗжПМТЧЕНДЪгяЩЯЯТЮФжаЕФЫљгааХЯЂЃЌЛЙдкгкетжжЛњжЦФмЙЛЪЕЯжФЃаЭбЕСЗЙ§ГЬжаЕФВЂааЃЌетЪЙЕУФЃаЭЕФбЕСЗЪБМфФмЙЛНЯДЋЭГЕФађСаФЃаЭДѓДѓЫѕЖЬЁЃДЋЭГЕФађСаФЃаЭгЩгкt ttЪБПЬЕФзДЬЌЛсЪмЕНt*1 t-1t*1ЪБПЬзДЬЌЕФгАЯьЃЌЫљвддкбЕСЗЕФЙ§ГЬжаЪЧЮоЗЈЪЕЯжВЂааЕФЃЌжЛФмДЎааЁЃЖјSelf-AttentionФЃаЭжаЃЌећИіВйзїПЩвдЭЈЙ§ОиеѓдЫЫуКмШнвзЕФЪЕЯжВЂааЁЃ
2.2 Self-AttentionНсЙЙ
ЮЊСЫФмИќКУЕФРэНтSelf-AttentionЕФНсЙЙЃЌЪзЯШНщЩмЯђСПаЮЪНЕФSelf-AttentionЕФЪЕЯжЃЌдйДгЯђСПаЮЪНЭЦЙуЕНОиеѓаЮЪНЁЃ
ЖдгкФЃаЭжаЕФУПвЛИіЪфШыЯђСП(ЕквЛВуЕФЪфШыЮЊДЪгяЖдгІЕФEmbeddingЯђСПЃЌШчЙћгаЖрВудђЦфЫќВуЕФЪфШыЮЊЩЯвЛВуЕФЪфГіЯђСП)ЃЌЪзЯШЮвУЧашвЊИљОнЪфШыЯђСПЩњГЩШ§ИіаТЕФЯђСПЃКQ(Query)ЁЂK(Key)ЁЂV(Value) Q(Query)ЁЂK(Key)ЁЂV(Value)Q(Query)ЁЂK(Key)ЁЂV(Value)ЃЌЦфжаQuery QueryQueryЯђСПБэЪОЮЊСЫБрТыЕБЧАДЪашвЊШЅзЂвт(attend to)ЕФЦфЫћДЪ(АќРЈЕБЧАДЪгяБОЩэ)ЃЌKey KeyKeyЯђСПБэЪОЕБЧАДЪгУгкБЛМьЫїЕФЙиМќаХЯЂЃЌЖјValue ValueValueЯђСПЪЧеце§ЕФФкШнЁЃШ§ИіЯђСПЖМЪЧвдЕБЧАДЪЕФEmbeddingЯђСПЮЊЪфШыЃЌОЙ§ВЛЭЌЕФЯпадВуБфЛЛЕУЕНЕФЁЃ
ЯТУцвдОпЬхЪЕР§РДРэНтSelf-AttentionЛњжЦЁЃБШШчЕБЮвУЧЕФЪфШыЮЊthinkingКЭmachinesЪБЃЌЪзЯШЮвУЧашвЊЖдЫќУЧзіWord EmbeddingЃЌЕУЕНЖдгІЕФДЪЯђСПБэЪОx1,x2 x_{1},x_{2}x
1
,x
2
ЃЌдйНЋЖдгІЕФДЪЯђСПЗжБ№ЭЈЙ§Ш§ИіВЛЭЌЕФОиеѓНјааЯпадБфЛЛЃЌЕУЕНЖдгІЕФЯђСПq1,k1,v1 q_{1},k_{1},v_{1}q
1
,k
1
,v
1
КЭq2,k2,v2 q_{2},k_{2},v_{2}q
2
,k
2
,v
2
ЁЃЮЊСЫЪЙЕУQuery QueryQueryКЭKey KeyKeyЯђСПФмЙЛзіФкЛ§ЃЌФЃаЭвЊЧѓWKЁЂWQ W^{K}ЁЂW^{Q}W
K
ЁЂW
Q
ЕФДѓаЁЪЧвЛбљЕФЃЌЖјЖдWV W^{V}W
V
ЕФДѓаЁВЂУЛгавЊЧѓЁЃ


ЭМжаИјГіСЫЩЯЪіЙ§ГЬЕФПЩЪгЛЏЃЌдкЕУЕНЫљгаЕФЪфШыЖдгІЕФqiЁЂkiЁЂvi q_{i}ЁЂk_{i}ЁЂv_{i}q
i
ЁЂk
i
ЁЂv
i
ЯђСПКѓЃЌОЭПЩвдНјааSelf-AttentionЯђСПЕФМЦЫуСЫЁЃШчЯТЭМЫљЪОЃЌЕБЮвУЧашвЊМЦЫуthinkingЖдгІЕФattentionЯђСПЪБЃЌЪзЯШНЋq1 q_{1}q
1
КЭЫљгаЪфШыЖдгІЕФki k_{i}k
i
зіЕуЛ§ЃЌЗжБ№ЕУЕНВЛЭЌЕФScore ScoreScoreЃК


ШчЯТЭМЫљЪОЃЌдйЖдScore ScoreScoreжЕзіscale scalescaleВйзїЃЌЭЈЙ§Г§вд8dk**ЁЬ 8\sqrt{d_{k}}8
d
k
НЋscore scorescoreжЕЫѕаЁЃЌетбљФмЪЙЕУscore scorescoreжЕИќЦНЛЌЃЌдкзіЬнЖШЯТНЕЪБИќЮШЖЈЃЌгаРћгкФЃаЭЕФбЕСЗЁЃдйЖдЕУЕНЕФаТЕФScore ScoreScoreжЕзіSoftmax SoftmaxSoftmaxЃЌРћгУ$ SoftmaxВйзїЕУЕНЕФИХТЪЗжВМЖдЫљгаЕФ ВйзїЕУЕНЕФИХТЪЗжВМЖдЫљгаЕФВйзїЕУЕНЕФИХТЪЗжВМЖдЫљгаЕФv_{i}НјааМгШЈЦНОљЃЌЕУЕНЕБЧАДЪгяЕФзюжеБэЪО НјааМгШЈЦНОљЃЌЕУЕНЕБЧАДЪгяЕФзюжеБэЪОНјааМгШЈЦНОљЃЌЕУЕНЕБЧАДЪгяЕФзюжеБэЪОz_{1}$ЁЃЖдmachinesЕФБрТыКЭЩЯЪіЙ§ГЬвЛбљЁЃ


ШчЙћЮвУЧвдЯђСПаЮЪНбЛЗЪфШыЫљгаДЪгяЕФEmbeddingЯђСПЕУЕНЫќУЧЕФзюжеБрТыЃЌетжжЗНЪНвРШЛЪЧДЎааЕФЃЌЖјШчЙћЮвУЧАбЩЯУцЕФЯђСПМЦЫуБфЮЊОиеѓЕФдЫЫуЃЌдђПЩвдЪЕЯжвЛДЮМЦЫуГіЫљгаДЪгяЖдгІЕФзюжеБрТыЃЌетбљЕФОиеѓдЫЫуПЩвдГфЗжЕФРћгУЕчФдЕФгВМўКЭШэМўзЪдДЃЌДгЖјЪЙГЬађИќИпаЇЕФжДааЁЃ
ЯТЭМЫљЪОЮЊОиеѓдЫЫуЕФаЮЪНЁЃЦфжаX XXЮЊЪфШыЖдгІЕФДЪЯђСПОиеѓЃЌWQЁЂWKЁЂWV W^{Q}ЁЂW^{K}ЁЂW^{V}W
Q
ЁЂW
K
ЁЂW
V
ЮЊЯргІЕФЯпадБфЛЛОиеѓЃЌQЁЂKЁЂV QЁЂKЁЂVQЁЂKЁЂVЮЊX XXОЙ§ЯпадБфЛЛЕУЕНЕФQuery QueryQueryЯђСПОиеѓЁЂKey KeyKeyЯђСПОиеѓКЭValue ValueValueЯђСПОиеѓ


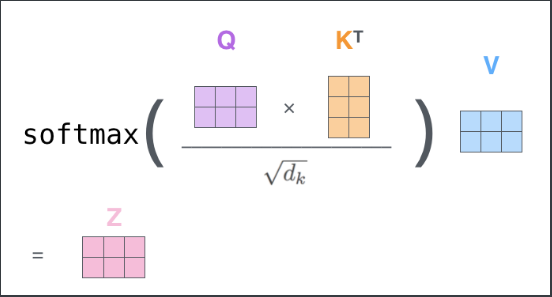
2.3 Scaled Dot-Production Attetntion
__Scaled Dot-Product Attention__ЦфЪЕЪЧдкЩЯвЛНкЕФattentionЕФЛљДЁЩЯМгШыСЫ__scale__КЭ__mask__ВйзїНјаагХЛЏЃЌОпЬхНсЙЙШчЯТЭМЫљЪОЁЃЪзЯШЖдгк__scale__ВйзїЃЌЫѕЗХвђзгЕФМгШыЪЧПМТЧЕНQ*K Q*KQ*KЕФНсЙћОиеѓжаЕФжЕПЩФмЛсКмДѓЃЌГ§вдвЛИіЫѕЗХвђзгПЩвдЪЙжЕБфаЁЃЌетбљФЃаЭдкзіЬнЖШЯТНЕЪБПЩвдИќМгЮШЖЈЁЃ__mask__ВйзїжївЊЪЧЮЊСЫЦСБЮЕєЪфШыжаУЛгавтвхЕФВПЗж(padding mask)КЭеыЖдЬиЖЈШЮЮёашвЊЦСБЮЕФВПЗж(sequence mask)ЃЌДгЖјНЕЕЭЦфЖдзюКѓНсЙћЕФгАЯьЁЃетСНжжВЛЭЌЕФmaskЗНЗЈдкКѓУцЛсЯъЯИЫЕУїЁЃ



ЩЯЭМИјГіСЫдкВЛЭЌheadжаЕФattentionВйзїЃЌгЩЭМжаПЩжЊЃЌУПИіheadжаЖМДцдквЛзщWQi,WKi,WVi W_{i}^{Q}, W_{i}^{K}, W_{i}^{V}W
i
Q
*
,W
i
K
*
,W
i
V
*
ЃЌЭЈЙ§гыЪфШыНјааОиеѓЯрГЫдЫЫуЃЌПЩвдЕУЕНвЛзщЖдгІЕФ(Qi,Ki,Vi) (Q_{i}, K_{i}, V_{i})(Q
i
*
,K
i
*
,V
i
*
)ЃЌВЂгЩДЫЕУЕНheadЕФЪфГіzi z_{i}z
i
*
ЁЃдкЕЅИіheadжаНјааЕФattentionВйзїЃЌгыЩЯвЛНкЫљНВЕФЭъШЋЯрЭЌЁЃзюКѓЖрИіheadЕУЕНЕФНсЙћШчЯТЭМЫљЪОЁЃ

ЖјзюКѓЮвУЧЫљашвЊЕФЪфГіВЛЪЧЖрИіОиеѓЃЌЖјЪЧЕЅИіОиеѓЃЌЫљвдзюКѓЖрИіheadЕФЪфГіЖМдкОиеѓЕФзюКѓвЛИіЮЌЖШЩЯНјааЦДНгЃЌдйНЋЕУЕНЕФОиеѓгывЛИіОиеѓWO W^{O}W
O
ЯрГЫЃЌетвЛДЮЯпадБфЛЛЕФФПЕФЪЧЖдЦДНгЕУЕНЕФОиеѓНјаабЙЫѕЃЌвдЕУЕНзюРэЯыЕФЪфГіОиеѓЁЃ

ЯТЭМЫљЪОЃЌЮЊЭъећЕФMulti-head AttentionЙ§ГЬЃЌ

ФЧУДЮвУЧШчКЮРДРэНтЖрИіheadЗжБ№зЂвтЕНЕФФкШнФиЃПЯТУцИјГіСНИіЭМРДОйР§ЫЕУїЁЃЕквЛИіЭМИјГіСЫдкЗвыitЪБСНИіheadЗжБ№зЂвтЕНЕФФкШнЃЌДгжаПЩвдКмУїЯдЕФПДЕНЃЌЕквЛИіheadзЂвтЕНСЫanimalЃЌЖјЕкЖўИіheadзЂвтЕНСЫtiredЃЌетОЭБЃжЄСЫЗвыЕФе§ШЗадЁЃ

ЕкЖўИіЭМжаИјГіСЫЫљвдheadЗжБ№зЂвтЕНЕФФкШнЃЌетЪБКђattentionОПОЙФмЗёзЅШЁЕНзюашвЊБЛЛёШЁЕФаХЯЂБфЕУВЛдйФЧУДжБЙлЁЃ

3. The Residual Connection ВаВюСЌНг
дкTransformerжаЃЌУПИіMulti-Head AttentionВуКЭFeed
ForwardВуЖМЛсгавЛИіВаВюСЌНгЃЌШЛКѓдйНгвЛИіLayer NormВуЁЃВаВюСЌНгдкEncoderКЭDecoderжаЖМДцдкЃЌЧвНсЙЙЭъШЋЯрЭЌЁЃШчЯТЭМЫљЪОЃЌвЛИіEncoderжаSelf-AttentionВуЕФЪфГіz1,z2
КЭЪфШы(x1,x2) ЯрМгЃЌзїЮЊLayerNormВуЕФЪфШыЁЃВаВюСЌНгБОЩэгаКмЖрКУДІЃЌЕЋВЂВЛЪЧTransformerНсЙЙЕФжиЕуЃЌетРяВЛзіЯъЪіЁЃ

4. Positional Encoding
ЮвУЧдкTransformerжаЪЙгУSelf-AttentionЕФФПЕФЪЧгУЫќРДДњЬцRNNЁЃRNNжЛФмЙизЂЕНЙ§ШЅЕФаХЯЂЃЌЖјSelf-AttentionЭЈЙ§ОиеѓдЫЫуПЩвдЭЌЪБЙизЂЕНЕБЧАЪБПЬЕФЩЯЯТЮФжаЫљгаЕФаХЯЂЃЌетЪЙЕУЦфПЩвдЪЕЯжКЭRNNЕШМлЩѕжСИќКУЕФаЇЙћЁЃЭЌЪБЃЌRNNзїЮЊвЛжжДЎааЕФађСаФЃаЭЛЙгавЛИіКмживЊЕФЬиеїЃЌОЭЪЧЫќФмЙЛПМТЧЕНЕЅДЪЕФЫГађ(ЮЛжУ)ЙиЯЕЁЃдкЭЌвЛИіОфзгжаЃЌМДЪЙЫљгаЕФДЪЖМЯрЭЌЕЋДЪађЕФБфЛЏвВПЩФмЕМжТОфзгЕФгявхЭъШЋВЛЭЌЃЌБШШчЁБББОЉЕНЩЯКЃЕФЛњЦБЁБгыЁБЩЯКЃЕНББОЉЕФЛњЦБЁБЃЌЫќУЧЕФгявхОЭгаКмДѓЕФВюБ№ЁЃЖјSelf-AttentionНсЙЙЪЧВЛПМТЧДЪЕФЫГађЕФЃЌШчЙћВЛв§ШыЮЛжУаХЯЂЃЌЧАвЛИіР§згСНОфЛАжажаЕФ"ББОЉ"ЛсБЛБрТыГЩЯрЭЌЕФЯђСПЃЌЕЋЪЕМЪЩЯЮвУЧЯЃЭћСНепЕФБрТыЯђСПЪЧВЛЭЌЕФЃЌЧАвЛОфжаЕФ"ББОЉ"ашвЊБрТыГіЗЂГЧЪаЕФгявхЃЌЖјКѓвЛОфжаЕФ"ББОЉ"дђЮЊФПЕФГЧЪаЁЃЛЛбджЎЃЌШчЙћУЛгаЮЛжУаХЯЂЃЌSelf-AttentionжЛЪЧвЛИіНсЙЙИќИДдгЕФДЪДќФЃаЭЁЃЫљвдЃЌдкДЪЯђСПБрТыжав§ШыЮЛжУаХЯЂЪЧБивЊЕФЁЃ
ЮЊСЫНтОіетИіЮЪЬтЃЌЮвУЧашвЊв§ШыЮЛжУБрТыЃЌвВОЭЪЧtЪБПЬЕФЪфШыЃЌГ§СЫEmbeddingжЎЭт(етЪЧгыЮЛжУЮоЙиЕФ)ЃЌЮвУЧЛЙв§ШывЛИіЯђСПЃЌетИіЯђСПЪЧгыtгаЙиЕФЃЌЮвУЧАбEmbeddingКЭЮЛжУБрТыЯђСПМгЦ№РДзїЮЊФЃаЭЕФЪфШыЁЃетбљЕФЛАШчЙћСНИіДЪдкВЛЭЌЕФЮЛжУГіЯжСЫЃЌЫфШЛЫќУЧЕФEmbeddingЪЧЯрЭЌЕФЃЌЕЋЪЧгЩгкЮЛжУБрТыВЛЭЌЃЌзюжеЕУЕНЕФЯђСПвВЪЧВЛЭЌЕФЁЃ
ЮЛжУБрТыгаКмЖрЗНЗЈЃЌЦфжаашвЊПМТЧЕФвЛИіживЊвђЫиОЭЪЧашвЊЫќБрТыЕФЪЧЯрЖдЮЛжУЕФЙиЯЕЁЃБШШчСНИіОфзгЃКЁБББОЉЕНЩЯКЃЕФЛњЦБЁБКЭЁБФуКУЃЌЮвУЧвЊвЛеХББОЉЕНЩЯКЃЕФЛњЦБЁБЁЃЯдШЛМгШыЮЛжУБрТыжЎКѓЃЌСНИіББОЉЕФЯђСПЪЧВЛЭЌЕФСЫЃЌСНИіЩЯКЃЕФЯђСПвВЪЧВЛЭЌЕФСЫЃЌЕЋЪЧЮвУЧЦкЭћQuery(ББОЉ1)*Key(ЩЯКЃ1) Query(ББОЉ1)*Key(ЩЯКЃ1)Query(ББОЉ1)*Key(ЩЯКЃ1)ШДЪЧЕШгкQuery(ББОЉ2)*Key(ЩЯКЃ2) Query(ББОЉ2)*Key(ЩЯКЃ2)Query(ББОЉ2)*Key(ЩЯКЃ2)ЕФЁЃ

гЩЩЯЭМПЩжЊЃЌЮЛжУБрТыЦфЪЕЪЧвдМгЗЈЕФаЮЪННЋДЪгяЕФEmbeddingЯђСПМгЩЯЦфЮЛжУЯђСПзїЮЊзюКѓЕФЪфГіЃЌетБЃжЄСЫЕБЭЌвЛИіДЪГіЯждкОфзгЕФВЛЭЌЮЛжУЪБЃЌЦфЖдгІЕФДЪЯђСПБэЪОЪЧВЛЭЌЕФЁЃдкTransformerжаЕФpositional
ОпЬхЪЕЯжЩЯЃЌЪзЯШвЊУїШЗЕФЪЧЃЌдкTransformerжаЕФЕФpositional encodingОиеѓЪЧЙЬЖЈЕФЃЌЕБУПИіЪфШыбљБОЕФДѓаЁЮЊmaxlen*dmodel maxlen*d_{model}maxlen*d
model
ЪБЃЌдђЮвУЧашвЊЕФpositional enccodingОиеѓЕФДѓаЁЭЌбљЮЊmaxlen*dmodel maxlen*d_{model}maxlen*d
model
ЧветИіЮЛжУБрТыОиеѓБЛгІгУгкКЭЫљгаЪфШыбљБОзіМгЗЈЃЌвдДЫНЋЮЛжУаХЯЂБрТыНјбљБОЕФДЪЯђСПБэЪОЁЃНгЯТРДЫЕвЛЯТШчКЮЕУЕНетИіpositional encodingОиеѓЁЃ
ЕБЮвУЧашвЊЕФpositional encodingОиеѓPE PEPEЕФДѓаЁЮЊmaxlen*dmodel maxlen*d_{model}maxlen*d
model
ЪБЃЌЪзЯШИљОнОиеѓжаУПИіЮЛжУЕФЯТБъ(i,j) (i,j)(i,j)АДЯТУцЕФЙЋЪНШЗЖЈИУЮЛжУЕФжЕЃК

НгзХЃЌдкХМЪ§ЮЛжУЃЌЪЙгУе§ЯвБрТыЃЌдкЦцЪ§ЮЛжУЃЌЪЙгУгрЯвБрТыЃК

ЮЊЪВУДетбљБрТыОЭФмв§ШыДЪгяЕФЮЛжУаХЯЂФиЃПШчЙћжЛАДееЕквЛИіЙЋЪНФЧбљИљОнЪфШыОиеѓЕФЯТБъжЕНјааБрТыЕФЛАЃЌЯдШЛБрТыЕФЪЧДЪЛуЕФОјЖдЮЛжУаХЯЂЃЌМД__ОјЖдЮЛжУБрТы__ЁЃЕЋДЪгяЕФЯрЖдЮЛжУвВЪЧЗЧГЃживЊЕФЃЌетвВЪЧTransformerжав§Шые§ЯвКЏЪ§ЕФдвђНјаа__ЯрЖдЮЛжУБрТы__ЕФдвђЁЃе§ЯвКЏЪ§ФмЙЛБэЪОДЪгяЕФЯрЖдЮЛжУаХЯЂЃЌжївЊЪЧЛљгквдЯТСНИіЙЋЪНЃЌетБэУїЮЛжУk+p k+pk+pЕФЮЛжУЯђСППЩвдБэЪОЮЊЮЛжУk kkЕФЬиеїЯђСПЕФЯпадБфЛЏЃЌетЮЊФЃаЭВЖзНЕЅДЪжЎМфЕФЯрЖдЮЛжУЙиЯЕЬсЙЉСЫЗЧГЃДѓЕФБуРћЁЃ

5. Layer Norm
МйЩшЮвУЧЕФЪфШыЪЧвЛИіЯђСПЃЌетИіЯђСПжаЕФУПИідЊЫиЖМДњБэСЫЪфШыЕФвЛИіВЛЭЌЬиеїЃЌЖјLayerNormвЊзіЕФОЭЪЧЖдвЛИібљБОЯђСПЕФЫљгаЬиеїНјааNormalizationЃЌетвВБэУїLayNormЕФЪфШыПЩвджЛгавЛИібљБОЁЃ
МйЩшвЛИібљБОЯђСПЮЊX=x1,x2,Ё,xn X={x_{1},x_{2},Ё, x_{n}}X=x
1
,x
2
,Ё,x
n
ЃЌдђЖдЦфзіLayer NormalizationЕФЙ§ГЬШчЯТЫљЪОЁЃЯШЧѓВЛЭЌЬиеїЕФОљжЕКЭЗНВюЃЌдйРћгУОљжЕКЭЗНВюЖдбљБОЕФИїИіЬиеїжЕНјааNormalizationВйзїЁЃ

ЯТЭМИјГівЛИіЖдВЛЭЌбљБОзіLayer NormalizationЕФЪЕР§ЁЃ

Layer NormalizationЕФЗНЗЈПЩвдКЭBatch NormalizationЖдБШзХНјааРэНтЃЌвђЮЊBatch NormalizationВЛЪЧTransformerжаЕФНсЙЙЃЌетРяВЛзіЯъНтЁЃ
6. Mask
MaskЃЌЙЫУћЫМвхОЭЪЧбкТыЃЌПЩвдРэНтЮЊЖдЪфШыЕФЯђСПЛђепОиеѓжаЕФвЛаЉЬиеїжЕНјаабкИЧЃЌЪЙЦфВЛЗЂЛгзїгУЃЌетаЉБЛбкИЧЕФЬиеїжЕПЩФмЪЧБОЩэВЂУЛгавтвх(БШШчЮЊСЫЖдЦыЖјЬюГфЕФЁЏ0ЁЏ)ЛђепЪЧеыЖдЕБЧАШЮЮёЮЊСЫзіЬиЪтДІРэЖјЬивтНјаабкИЧЁЃ
дкTransformerжагаСНжжmaskЗНЗЈЃЌЗжБ№ЮЊ__padding mask__КЭ__sequence mask__ЃЌетСНжжmaskЗНЗЈдкTransformerжаЕФзїгУВЂВЛвЛбљЁЃ__padding mask__дкEncoderКЭDecoderжаЖМЛсгУЕНЃЌЖј__sequence mask__жЛдкDecoderжаЪЙгУЁЃ
6.1 padding mask
дкздШЛгябдДІРэЕФЯрЙиШЮЮёжаЃЌЪфШыбљБОвЛАуЮЊОфзгЃЌЖјВЛЭЌЕФОфзгжаАќКЌЕФДЪЛуЪ§ФПБфЛЏКмДѓЃЌЕЋЛњЦїбЇЯАФЃаЭвЛАувЊЧѓЪфШыЕФДѓаЁЪЧвЛжТЕФЃЌвЛАуНтОіетИіЮЪЬтЕФЗНЗЈЪЧЖдЪфШыЕФЕЅДЪађСаИљОнзюДѓГЄЖШНјаа__ЖдЦы__ЃЌМДдкГЄЖШаЁгкзюДѓГЄЖШЕФЪфШыКѓУцЬюЁЏ0ЁЏЁЃОйИіР§згЃЌЕБmaxlen=20 maxlen=20maxlen=20ЃЌЖјЮвУЧЪфШыЕФОиеѓДѓаЁЮЊ12*dmodel 12*d_{model}12*d
model
ЪБЃЌетЪЧЮвУЧЖдЪфШыНјааЖдЦыЃЌОЭашвЊдкЪфШыЕФКѓУцЦДНгвЛИіДѓаЁЮЊ8*dmodel 8*d_{model}8*d
model
ЕФСуОиеѓЃЌЪЙЪфШыЕФДѓаЁБфЮЊmaxlen*dmodel maxlen*d_{model}maxlen*d
model
ЁЃЕЋЯдШЛЃЌетаЉЬюГфЕФЁЏ0ЁЏВЂУЛгавтвхЃЌЫќЕФзїгУжЛЪЧЪЕЯжЪфШыЕФЖдЦыЁЃдкзіattentionЪБЃЌЮЊСЫЪЙattentionЯђСПВЛНЋзЂвтСІЗХдкетаЉУЛгавтвхЕФжЕЩЯЃЌЮвУЧашвЊЖдетаЉжЕзі__padding mask__ЁЃ
ОпЬхРДЫЕЃЌзі__padding mask__ЕФЗНЗЈЪЧЃЌНЋетаЉУЛгавтвхЕФЮЛжУЩЯЕФжЕжУЮЊвЛИіКмаЁЕФЪ§ЃЌетбљдкзіsoftmax softmaxsoftmaxЪБЃЌетаЉЮЛжУЩЯЖдгІЕФИХТЪжЕЛсЗЧГЃаЁНгНќгк0ЃЌЦфЖдзюжеНсЙћЕФгАЯьвВЛсНЕЕЭЕНзюаЁЁЃ
6.2 sequence mask
ЧАУцвбОЫЕЙ§ЃЌдкTransformerжаЃЌ__sequence mask__жЛгУдкDecoderжаЃЌЫќЕФзїгУЪЧЪЙЕУDecoderдкНјааНтТыЪБВЛФмПДЕНЕБЧАЪБПЬжЎКѓЕФЕФаХЯЂЁЃвВОЭЪЧЫЕЃЌЖдгквЛИіЪфШыађСаЃЌЕБЮвУЧвЊЖдt ttЪБПЬНјааНтТыЪБЃЌЮвУЧжЛФмПМТЧ(1,2,Ё,t*1) (1,2,Ё,t-1)(1,2,Ё,t*1)ЪБПЬЕФаХЯЂЃЌЖјВЛФмПМТЧжЎКѓЕФ(t+1,Ё,n) (t+1,Ё, n)(t+1,Ё,n)ЪБПЬЕФаХЯЂЁЃ
ОпЬхзіЗЈЃЌЪЧВњЩњвЛИіЯТШ§НЧОиеѓЃЌетИіОиеѓЕФЩЯШ§НЧЕФжЕШЋЮЊ0ЃЌЯТШ§НЧЕФжЕШЋЮЊЪфШыОиеѓЖдгІЮЛжУЕФжЕЃЌетбљОЭЪЕЯжСЫдкУПИіЪБПЬЖдЮДРДаХЯЂЕФбкИЧЁЃ
7. Encoder and Decoder stacks
ЩЯУцМИНкжавбОНщЩмСЫTransformerЕФжївЊНсЙЙЃЌетвЛНкНЋдкДЫЛљДЁЩЯЃЌДгећЬхЩЯдйДЮРэНтвЛЯТTranformerЕФНсЙЙ

ШчЩЯЭМЫљЪОЃЌTransformerгЩ6ИіEncoderВуКЭ6ИіDecoderВузщГЩЃЌЦфжаИїИіEncoderВуЕФНсЙЙЭъШЋЯрЭЌЃЌИїИіDecoderВуЕФНсЙЙвВЪЧЭъШЋвЛбљЕФЁЃЖјDecoderВуКЭEncoderВужЎМфЕФВюБ№дкгкDecoderВужаЖрСЫвЛИіEncoder-Decoder AttentionзгВуКЭAdd & NormalizeзгВуЃЌетвЛВуЕФЪфШыЮЊDecoderВуЕФЩЯвЛИізгВуЕФЪфГіКЭEncoderВуЕФзюжеЪфГіЃЌЦфжаEncoderВуЕФзюжеЪфГізїЮЊK КЭV ЃЌDecoderВужаЩЯвЛИізгВуЕФЪфГізїЮЊQ ЁЃ
|





