| 编辑推荐: |
在文本中,主要讲解目前常用的四个自动化学习平台,auto-sklearn, TPOT,
auto_ml 和H2O,以及他们之间的性能比较。
本文来自于csdn,由火龙果软件Alice编辑、推荐。
|
|

摘要:
AutoML作为一个有效的工具可以帮助很多企业方便地实施和加速人工智能方面的应用落地。对于还不具备数据科学团队的公司来说,AutoML可以是全自动化的模型构建工具来使用,即便对于具备一定数据科学能力的公司,AutoML仍然可以帮助他们更加专注在人工智能落地中最为重要的事情上。在文本中,主要讲解目前常用的四个自动化学习平台,auto-sklearn,
TPOT, auto_ml 和H2O,以及他们之间的性能比较。
为什么需要AutoML?
机器学习建模是一个流程化的过程。首先我们需要拿到数据,其次就是数据的预处理、特征工程,接着要做模型的构建,并通过调参的方式来寻找最好的模型参数。如果效果不佳,我们经常需要回到特征工程,重新再走整个的流程。显然,在实际工程上,我们需要花费大量的精力在这些每个流程上的优化(包括特征选取,调参等等)。如果一个工具或者框架能够帮助我们把所有流程优化好,那会极大地提升工作效率。在这个情况下,我们只需要把输入数据传递给一个框架或者平台,则可以拿到最后已经训练好的模型。其实这就是AutoML所做的事情。
Auto_ml
设计的目标为帮助公司快速从数据中提取有价值的信息,它用来自动化机器学习系统构建中的大部分流程。不仅可以用来完成通常花费最长时间的特征工程,比如对于自然语言处理的if-idf特征构建,特征编码等,还可以对于维度非常高的数据尝试降维操作。
Auto_ml底层使用了Scikit-Learn, XGBoost,
TensorFlow, Keras, LightGBM等工具来确保运行时的高效。除了这些优点,Auto_ml也存在一些可扩展性缺点,而且对于多分类问题表现出(multi-class
classification)比较差的表现。
Auto-sklearn

顾名思义,Auto-sklearn是scikit-learn基础上搭建的自动化学习平台。它包含自动化特征工程部分,而且整个流程由Bayesian
search来优化并得到最好的模型。
Auto-sklearn的最大优势在于它建立在sklearn的生态上,所以具有更好的可扩展性以及兼容性,毕竟sklearn是目前为止最为流行的机器学习工具。
但相反,对于自然语言处理的数据,缺乏一些有效的工具。
TPOT
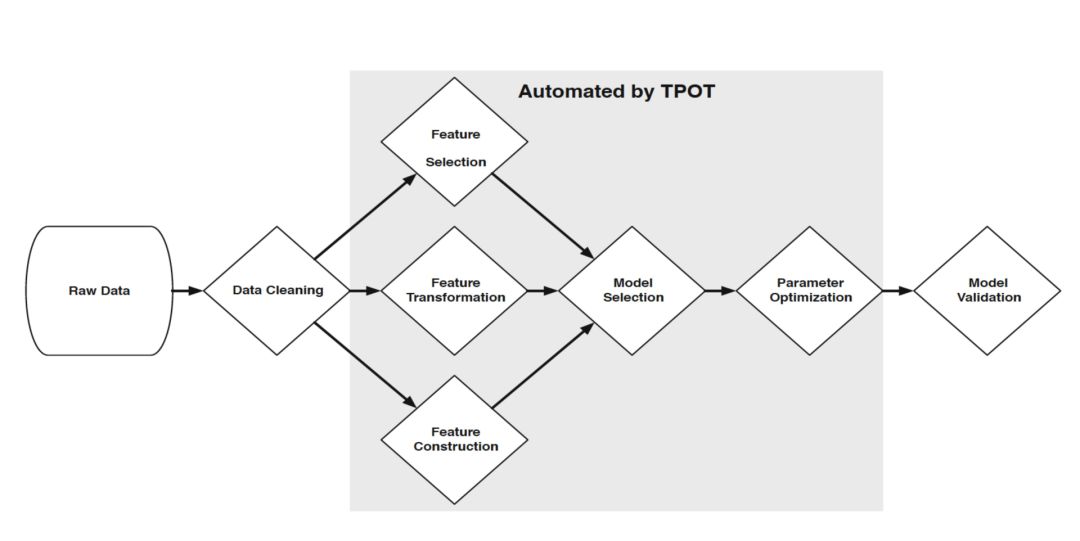
TPOT是基于树状的流程优化工具,它的核心基于遗传算法(genetic
algorithm)。它延伸了sklearn的框架,但基于自己的基础类。它的缺点也是对于自然语言数据的处理并不友好。
H20
H20是基于Java编写的框架,跟sklearn也比较类似。它包含常用的模型比如GLM、深度学习模型、GBM,
随机森林等。它支持多种类型的Grid search来找到最好的超参数(hyperparameter)。最后生成的模型是一个集成模型,结合了多个模型。
实验中利用的数据集
为了验证每个框架的性能,文本主要在OpenML的数据上做了测试,选取了57个用来分类的数据集,30个用来回归分析的收集。
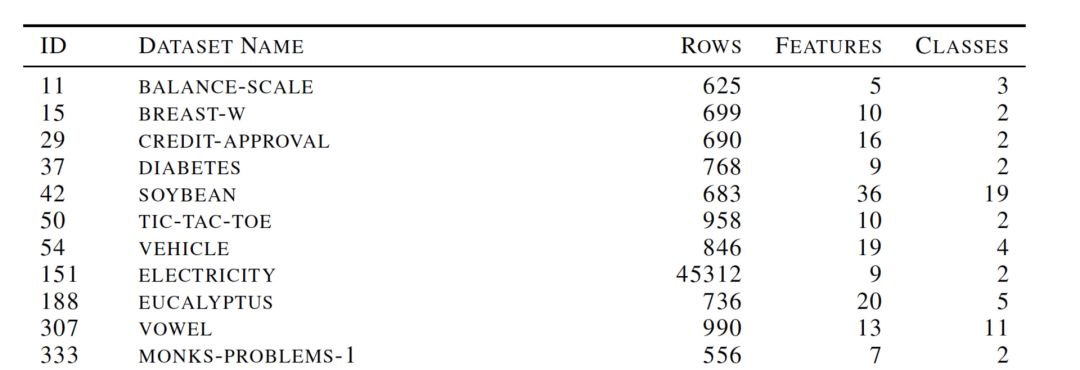
部分用于分类问题的数据集:
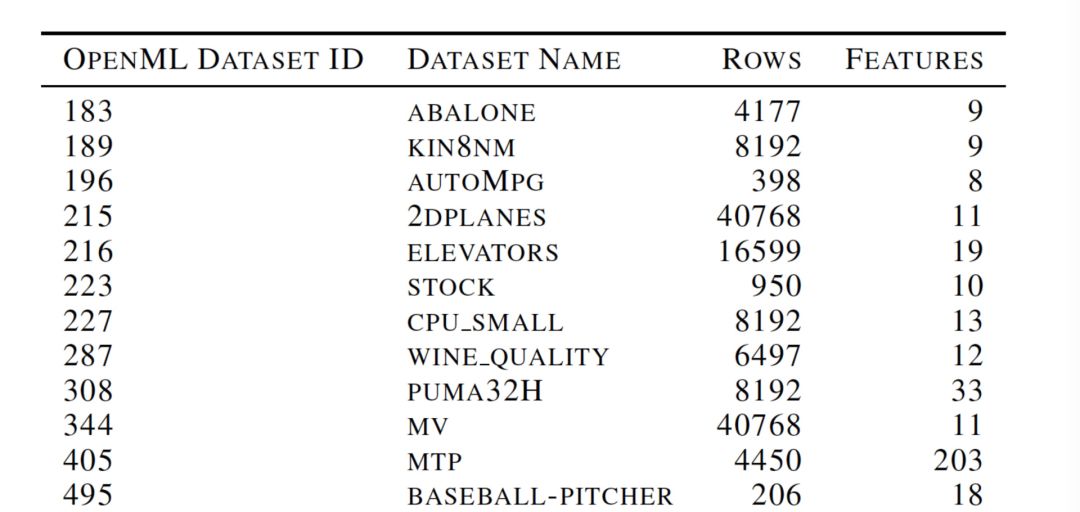
部分用于回归分析的数据集:
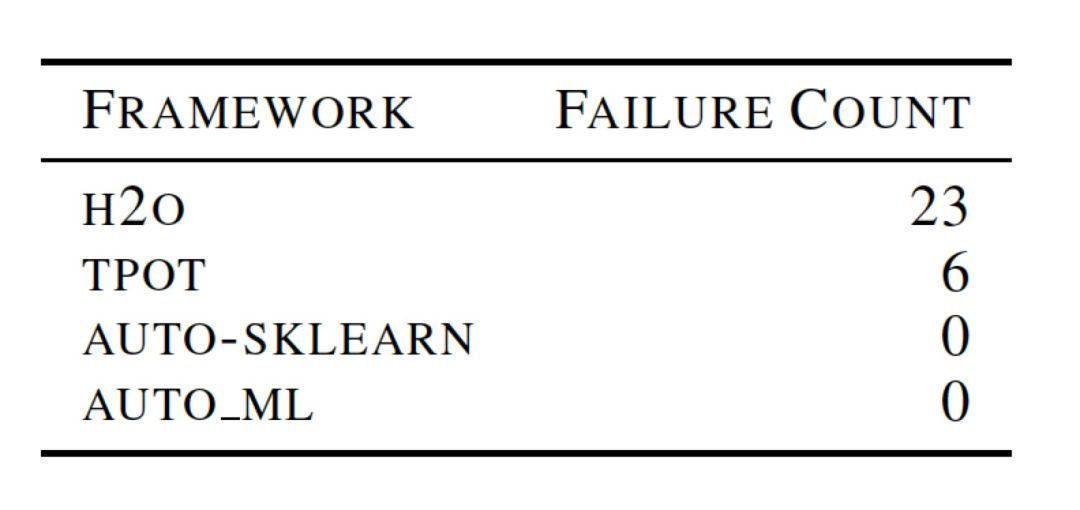
实验1: 对于发生异常情况的统计:
本文统计出了在进行实验过程中遇到的异常情况,如下表所示。同表中可以看出H20在异常次数上占据最高,这也证实了H20框架的一个缺点,就是对于资源管理的问题。
实验2: 对于预测准确率方面的统计
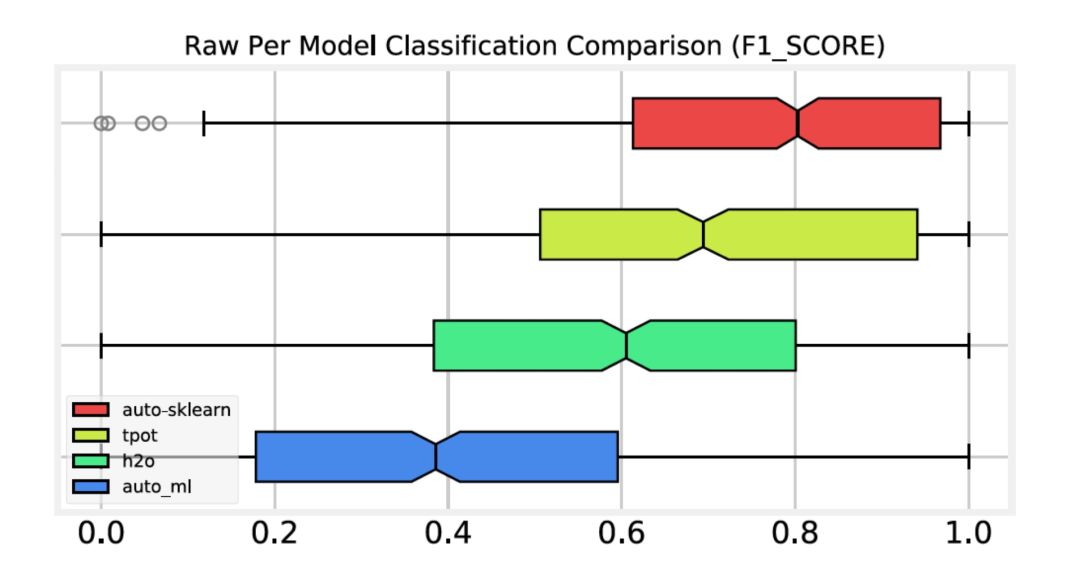
以下是针对分类和归回问题的预测统计。这个结果是基于所有数据集上的统计结果。从这个结果里可以看出,auto-sklearn在分类问题上要明显优于所有其他的框架。但在回归问题上,tpot要优于其他所有的框架。

|








