| 编辑推荐: |
本文将使用Hyperopt库演示梯度提升机(Gradient Boosting
Machine,GBM) 的贝叶斯超参数调整的完整示例。
本文来自于csdn,由火龙果软件Alice编辑、推荐。
|
|
一、Python实现自动贝叶斯调整超参数
【导读】机器学习中,调参是一项繁琐但至关重要的任务,因为它很大程度上影响了算法的性能。手动调参十分耗时,网格和随机搜索不需要人力,但需要很长的运行时间。因此,诞生了许多自动调整超参数的方法。贝叶斯优化是一种用模型找到函数最小值方法,已经应用于机器学习问题中的超参数搜索,这种方法性能好,同时比随机搜索省时。此外,现在有许多Python库可以实现贝叶斯超参数调整。文章由贝叶斯优化方法、优化问题的四个部分、目标函数、域空间、优化过程、及结果展示几个部分组成。
贝叶斯优化方法
贝叶斯优化通过基于目标函数的过去评估结果建立替代函数(概率模型),来找到最小化目标函数的值。贝叶斯方法与随机或网格搜索的不同之处在于,它在尝试下一组超参数时,会参考之前的评估结果,因此可以省去很多无用功。
超参数的评估代价很大,因为它要求使用待评估的超参数训练一遍模型,而许多深度学习模型动则几个小时几天才能完成训练,并评估模型,因此耗费巨大。贝叶斯调参发使用不断更新的概率模型,通过推断过去的结果来“集中”有希望的超参数。
Python中的选择
Python中有几个贝叶斯优化库,它们目标函数的替代函数不一样。在本文中,我们将使用Hyperopt,它使用Tree
Parzen Estimator(TPE)。其他Python库包括Spearmint(高斯过程代理)和SMAC(随机森林回归)。
优化问题的四个部分
贝叶斯优化问题有四个部分:
目标函数:我们想要最小化的内容,在这里,目标函数是机器学习模型使用该组超参数在验证集上的损失。
域空间:要搜索的超参数的取值范围
优化算法:构造替代函数并选择下一个超参数值进行评估的方法。
结果历史记录:来自目标函数评估的存储结果,包括超参数和验证集上的损失。
数据集
在本例中,我们将使用Caravan Insurance数据集,其目标是预测客户是否购买保险单。 这是一个有监督分类问题,训练集和测试集的大小分别为5800和4000。评估性能的指标是AUC(曲线下面积)评估准则和ROC(receiver
operating characteristic,以真阳率和假阳率为坐标轴的曲线图)曲线,ROC AUC越高表示模型越好。
数据集如下所示:

为Hyperopt最小化目标函数,我们的目标函数返回1-ROC AUC,从而提高ROC AUC。
梯度提升模型
梯度提升机(GBM)是一种基于使用弱学习器(如决策树)组合成强学习器的模型。 GBM中有许多超参数控制整个集合和单个决策树,如决策树数量,决策树深度等。简单了解了GBM,接下来我们介绍这个问题对应的优化模型的四个部分
目标函数
目标函数是需要我们最小化的。 它的输入为一组超参数,输出需要最小化的值(交叉验证损失)。Hyperopt将目标函数视为黑盒,只考虑它的输入和输出。
在这里,目标函数定义为:
def objective(hyperparameters):
'''Returns validation score from hyperparameters'''
model = Classifier(hyperparameters)
validation_loss = cross_validation(model, training_data)
return validation_loss |
我们评估的是超参数在验证集上的表现,但我们不将数据集划分成固定的验证集和训练集,而是使用K折交叉验证。使用10倍交叉验证和提前停止的梯度提升机的完整目标函数如下所示。
import lightgbm
as lgb
from hyperopt import STATUS_OK
N_FOLDS = 10
# Create the dataset
train_set = lgb.Dataset(train_features, train_labels)
def objective(params, n_folds=N_FOLDS):
'''Objective function for Gradient Boosting
Machine Hyperparameter Tuning'''
# Perform n_fold cross validation with hyperparameters
# Use early stopping and evalute based on ROC
AUC
cv_results = lgb.cv(params, train_set, nfold=n_folds,
num_boost_round=10000,
early_stopping_rounds=100, metrics='auc', seed=50)
# Extract the best score
best_score = max(cv_results['auc-mean'])
# Loss must be minimized
loss = 1 - best_score
# Dictionary with information for evaluation
return {'loss': loss, 'params': params, 'status':
STATUS_OK} |
关键点是cvresults = lgb.cv(...)。为了实现提前停止的交叉验证,我们使用LightGBM函数cv,它输入为超参数,训练集,用于交叉验证的折数等。我们将迭代次数(numboostround)设置为10000,但实际上不会达到这个数字,因为我们使用earlystopping_rounds来停止训练,当连续100轮迭代效果都没有提升时,则提前停止,并选择模型。因此,迭代次数并不是我们需要设置的超参数。
一旦交叉验证完成,我们就会得到最好的分数(ROC AUC),然后,因为我们最小化目标函数,所以计算1-
ROC AUC,然后返回这个值。
域空间
域空间表示我们要为每个超参数计算的值的范围。在搜索的每次迭代中,贝叶斯优化算法将从域空间为每个超参数选择一个值。当我们进行随机或网格搜索时,域空间是一个网格。在贝叶斯优化中,想法是一样的,但是不是按照顺序(网格)或者随机选择一个超参数,而是按照每个超参数的概率分布选择。
而确定域空间是最困难的。如果我们有机器学习方法的经验,我们可以通过在我们认为最佳值的位置放置更大的概率来使用它来告知我们对超参数分布的选择。然而,不同数据集之间最佳模型不一样,并且具有高维度问题(许多超参数),超参数之间也会互相影响。在我们不确定最佳值的情况下,我们可以将范围设定的大一点,让贝叶斯算法为我们做推理。
首先,我们看看GBM中的所有超参数:
import lgb
# Default gradient boosting machine classifier
model = lgb.LGBMClassifier()
model
LGBMClassifier(boosting_type='gbdt', n_estimators=100,
class_weight=None, colsample_bytree=1.0,
learning_rate=0.1, max_depth=-1,
min_child_samples=20,
min_child_weight=0.001, min_split_gain=0.0,
n_jobs=-1, num_leaves=31, objective=None,
random_state=None, reg_alpha=0.0, reg_lambda=0.0,
silent=True, subsample=1.0,
subsample_for_bin=200000, subsample_freq=1) |
其中一些我们不需要调整(例如objective和randomstate),我们将使用提前停止来找到最好的n_estimators。
但是,我们还有10个超参数要优化! 首次调整模型时,我通常会创建一个以默认值为中心的宽域空间,然后在后续搜索中对其进行细化。
例如,让我们在Hyperopt中定义一个简单的域,这是GBM中每棵树中叶子数量的离散均匀分布:
from hyperopt
import hp
# Discrete uniform distribution
num_leaves = {'num_leaves': hp.quniform('num_leaves',
30, 150, 1)} |
这里选择离散的均匀分布,因为叶子的数量必须是整数(离散),并且域中的每个值都可能(均匀)。
另一种分布选择是对数均匀,它在对数标度上均匀分布值。 我们将使用对数统一(从0.005到0.2)来获得学习率,因为它在几个数量级上变化:
# Learning rate
log uniform distribution
learning_rate = {'learning_rate': hp.loguniform('learning_rate',
np.log(0.005),
np.log(0.2)} |
下面分别绘制了均匀分布和对数均匀分布的图。 这些是核密度估计图,因此y轴是密度而不是计数!
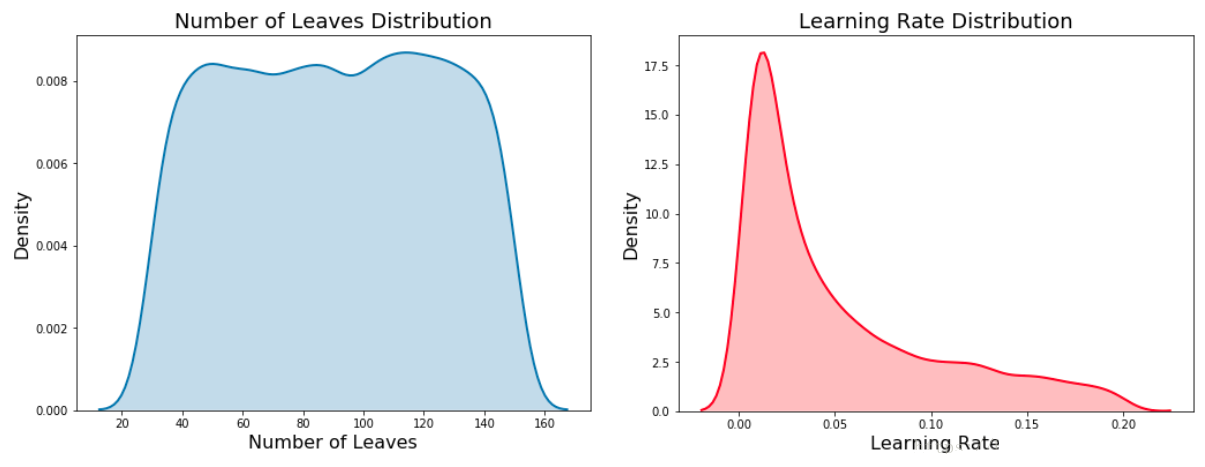
现在,让我们定义整个域:
# Define the
search space
space = {
'class_weight': hp.choice('class_weight', [None,
'balanced']),
'boosting_type': hp.choice('boosting_type',
[{'boosting_type': 'gbdt',
'subsample': hp.uniform('gdbt_subsample', 0.5,
1)},
{'boosting_type': 'dart',
'subsample': hp.uniform('dart_subsample', 0.5,
1)},
{'boosting_type': 'goss'}]),
'num_leaves': hp.quniform('num_leaves', 30, 150,
1),
'learning_rate': hp.loguniform('learning_rate',
np.log(0.01), np.log(0.2)),
'subsample_for_bin': hp.quniform('subsample_for_bin',
20000, 300000, 20000),
'min_child_samples': hp.quniform('min_child_samples',
20, 500, 5),
'reg_alpha': hp.uniform('reg_alpha', 0.0, 1.0),
'reg_lambda': hp.uniform('reg_lambda', 0.0, 1.0),
'colsample_bytree': hp.uniform('colsample_by_tree',
0.6, 1.0)
} |
这里我们使用了许多不同的域分发类型:
choice:类别变量
quniform:离散均匀(整数间隔均匀)
uniform:连续均匀(间隔为一个浮点数)
loguniform:连续对数均匀(对数下均匀分布)
# boosting type
domain
boosting_type = {'boosting_type': hp.choice('boosting_type',
[{'boosting_type': 'gbdt',
'subsample': hp.uniform('subsample', 0.5, 1)},
{'boosting_type': 'dart',
'subsample': hp.uniform('subsample', 0.5, 1)},
{'boosting_type': 'goss',
'subsample': 1.0}])} |
这里我们使用条件域,这意味着一个超参数的值取决于另一个超参数的值。 对于提升类型“goss”,gbm不能使用子采样(仅选择训练观察的子样本部分以在每次迭代时使用)。
因此,如果提升类型是“goss”,则子采样率设置为1.0(无子采样),否则为0.5-1.0。 这是使用嵌套域实现的
定义域空间之后,我们可以从中采样查看样本。
# Sample from
the full space
example = sample(space)
# Dictionary get method with default
subsample = example['boosting_type'].get('subsample',
1.0)
# Assign top-level keys
example['boosting_type'] = example['boosting_type']['boosting_type']
example['subsample'] = subsample
example
{'boosting_type': 'gbdt',
'class_weight': 'balanced',
'colsample_bytree': 0.8111305579351727,
'learning_rate': 0.16186471096789776,
'min_child_samples': 470.0,
'num_leaves': 88.0,
'reg_alpha': 0.6338327001528129,
'reg_lambda': 0.8554826167886239,
'subsample_for_bin': 280000.0,
'subsample': 0.6318665053932255} |
优化算法
虽然这是贝叶斯优化中概念上最难的部分,但在Hyperopt中创建优化算法只需一行。 要使用Tree
Parzen Estimator,代码为:
from hyperopt
import tpe
# Algorithm
tpe_algorithm = tpe.suggest |
在优化时,TPE算法根据过去的结果构建概率模型,并通过最大化预期的改进来决定下一组超参数以在目标函数中进行评估。
结果历史
跟踪结果并不是绝对必要的,因为Hyperopt将在内部为算法执行此操作。 但是,如果我们想知道幕后发生了什么,我们可以使用Trials对象来存储基本的训练信息,还可以使用从目标函数返回的字典(包括损失和范围)。
制创建Trials对象也只要一行代码:
from hyperopt
import Trials
# Trials object to track progress
bayes_trials = Trials() |
为了监控训练运行进度,可以将结果历史写入csv文件,防止程序意外中断导致评估结果消失。
import csv
# File to save first results
out_file = 'gbm_trials.csv'
of_connection = open(out_file, 'w')
writer = csv.writer(of_connection)
# Write the headers to the file
writer.writerow(['loss', 'params', 'iteration',
'estimators', 'train_time'])
of_connection.close() |
然后在目标函数中我们可以在每次迭代时添加行写入csv:
# Write to the
csv file ('a' means append)
of_connection = open(out_file, 'a')
writer = csv.writer(of_connection)
writer.writerow([loss, params, iteration, n_estimators,
run_time])
of_connection.close() |
优化:
一旦我们定义好了上述部分,就可以用fmin运行优化:
from hyperopt
import fmin
MAX_EVALS = 500
# Optimize
best = fmin(fn = objective, space = space, algo
= tpe.suggest,
max_evals = MAX_EVALS, trials = bayes_trials) |
在每次迭代时,算法从代理函数中选择新的超参数值,该代理函数基于先前的结果构建并在目标函数中评估这些值。
这继续用于目标函数的MAX_EVALS评估,其中代理函数随每个新结果不断更新。
结果:
从fmin返回的最佳对象包含在目标函数上产生最低损失的超参数:
{'boosting_type':
'gbdt',
'class_weight': 'balanced',
'colsample_bytree': 0.7125187075392453,
'learning_rate': 0.022592570862044956,
'min_child_samples': 250,
'num_leaves': 49,
'reg_alpha': 0.2035211643104735,
'reg_lambda': 0.6455131715928091,
'subsample': 0.983566228071919,
'subsample_for_bin': 200000} |
一旦我们有了这些超参数,我们就可以使用它们来训练完整训练数据的模型,然后评估测试数据。 最终结果如下:
The best model
scores 0.72506 AUC ROC on the test set.
The best cross validation score was 0.77101 AUC
ROC.
This was achieved after 413 search iterations. |
作为参考,500次随机搜索迭代返回了一个模型,该模型在测试集上评分为0.7232 ROC AUC,在交叉验证中评分为0.76850。没有优化的默认模型在测试集上评分为0.7143
ROC AUC。
在查看结果时,请记住一些重要的注意事项:
最佳超参数是那些在交叉验证方面表现最佳的参数,而不一定是那些在测试数据上做得最好的参数。当我们使用交叉验证时,我们希望这些结果可以推广到测试数据。
即使使用10倍交叉验证,超参数调整也会过度拟合训练数据。交叉验证的最佳分数显著高于测试数据。
随机搜索可以通过纯粹的运气返回更好的超参数(重新运行笔记本可以改变结果)。贝叶斯优化不能保证找到更好的超参数,并且可能陷入目标函数的局部最小值。
另一个重点是超参数优化的效果将随数据集的不同而不同。相对较小的数据集(训练集大小为6000),调整超参数,最终得到的模型的提升并不大,但数据集更大时,效果会很明显。
因此,通过贝叶斯概率来优化超参数,我们可以:在测试集上得到更好的性能;调整超参数的迭代次数减少.
可视化结果:
绘制结果图表是一种直观的方式,可以了解超参数搜索过程中发生的情况。此外,通过将贝叶斯优化与随机搜索进行比较,可以看出方法的不同之处。
首先,我们可以制作随机搜索和贝叶斯优化中采样的learning_rate的核密度估计图。作为参考,我们还可以显示采样分布。垂直虚线表示学习率的最佳值(根据交叉验证)。
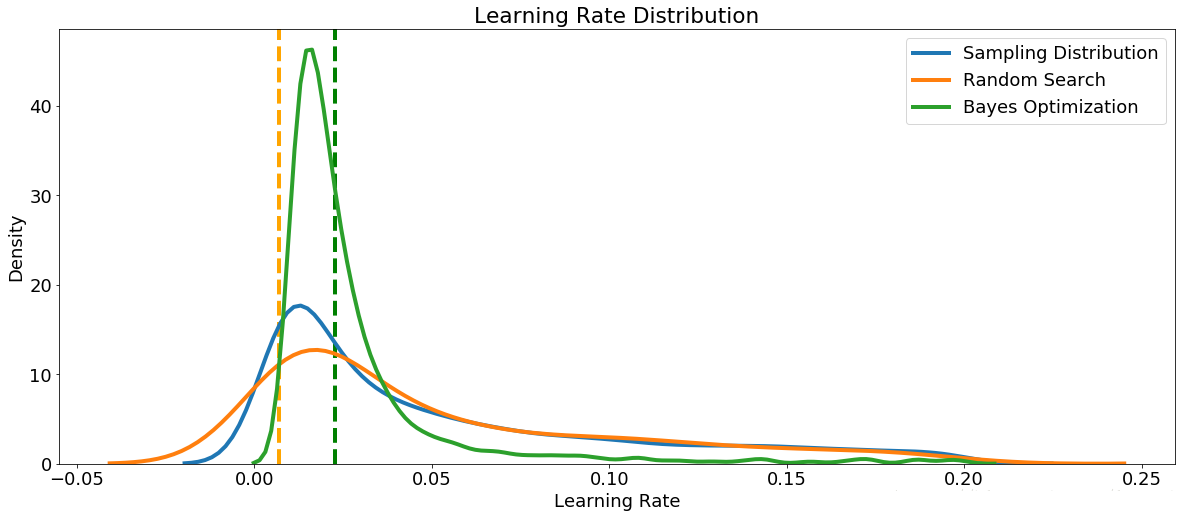
我们将学习率定义为0.005到0.2之间的对数正态,贝叶斯优化结果看起来与采样分布类似。 这告诉我们,我们定义的分布看起来适合于任务,尽管最佳值比我们放置最大概率的值略高。
这可用于告诉域进一步搜索。
另一个超参数是增强类型,在随机搜索和贝叶斯优化期间评估每种类型的条形图。 由于随机搜索不关注过去的结果,我们预计每种增强类型的使用次数大致相同。
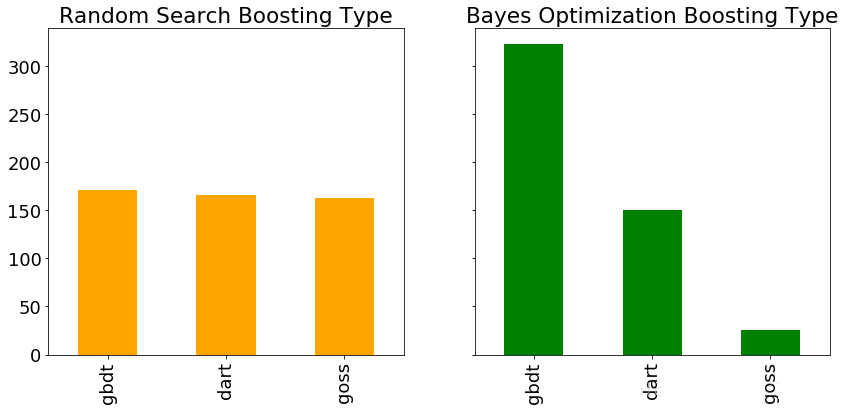
根据贝叶斯算法,gdbt提升模型比dart或goss更有前途。 同样,这可以帮助进一步搜索,贝叶斯方法或网格搜索。
如果我们想要进行更明智的网格搜索,我们可以使用这些结果来定义围绕超参数最有希望的值的较小网格。
我们再看下其他参数的分布,随机搜索和贝叶斯优化中的所有数字超参数。 垂直线再次表示每次搜索的超参数的最佳值:
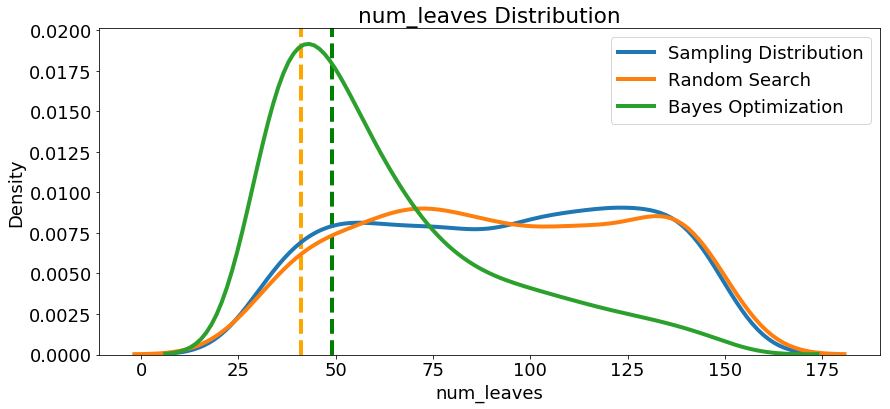
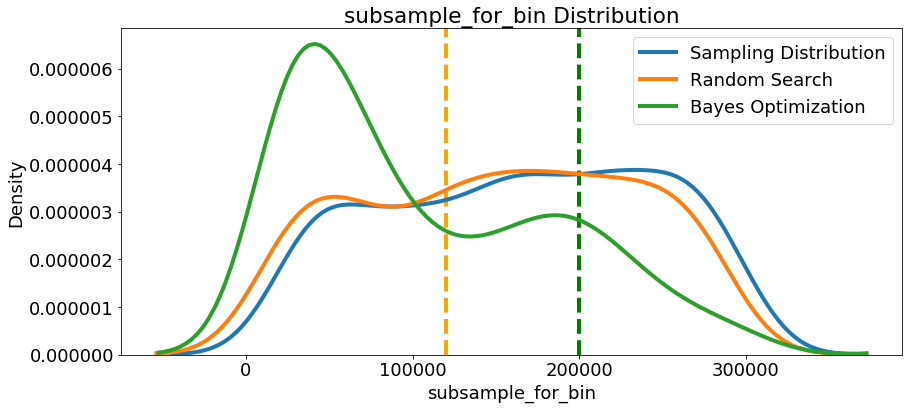
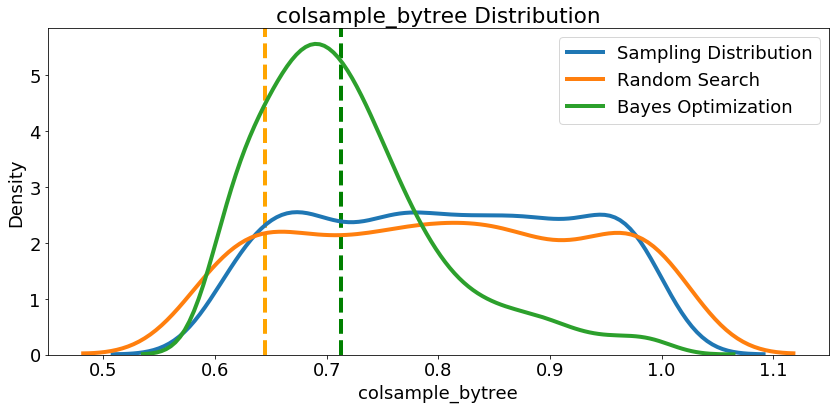
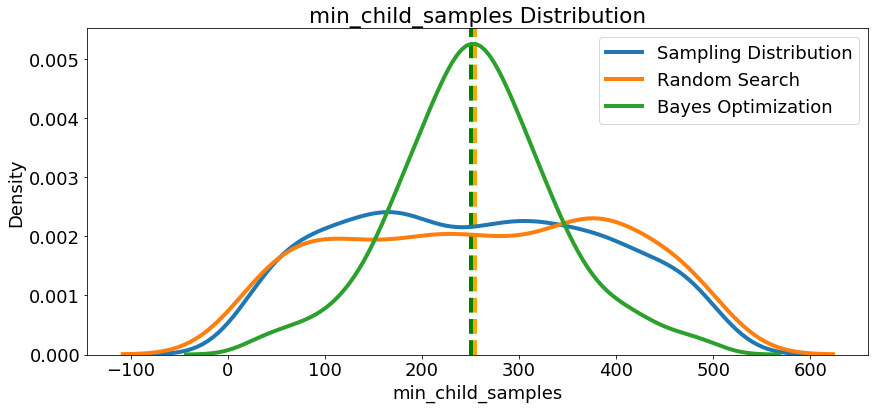
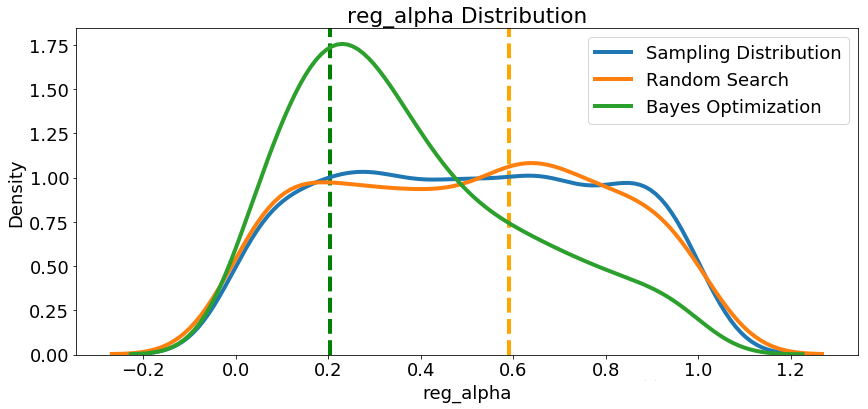
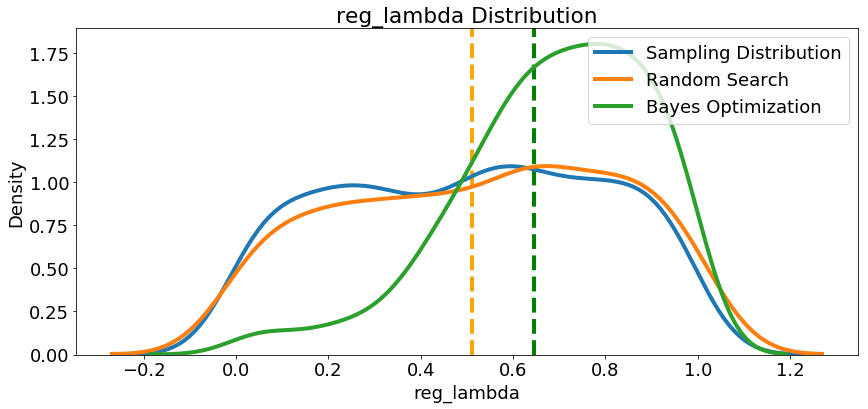
在大多数情况下(subsampleforbin除外),贝叶斯优化搜索倾向于在超参数值附近集中(放置更多概率),从而产生交叉验证中的最低损失。这显示了使用贝叶斯方法进行超参数调整的基本思想:花费更多时间来评估有希望的超参数值。
此处还有一些有趣的结果可能会帮助我们在将来定义要搜索的域空间时。仅举一个例子,看起来regalpha和reglambda应该相互补充:如果一个是高(接近1.0),另一个应该更低。不能保证这会解决问题,但通过研究结果,我们可以获得可能适用于未来机器学习问题的见解!
搜索的演变
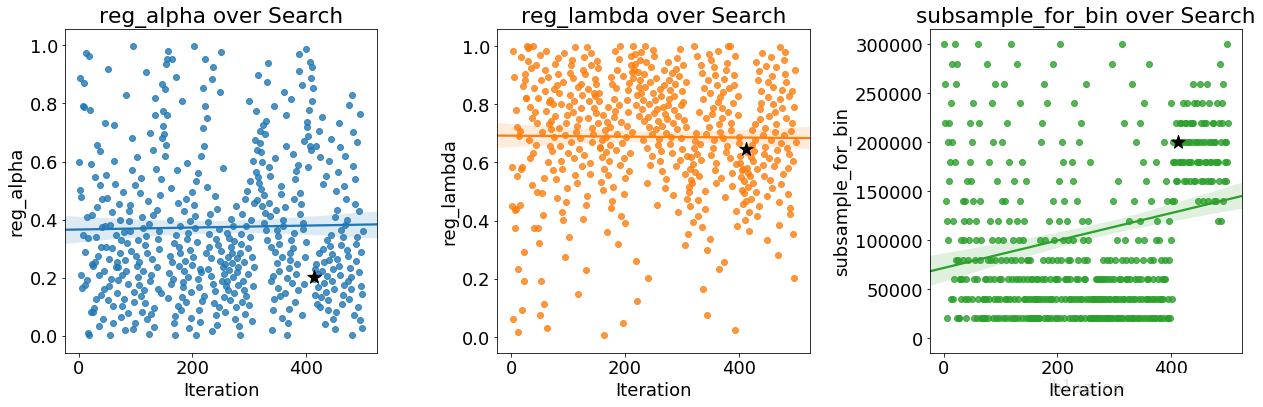
随着优化的进展,我们期望贝叶斯方法关注超参数的更有希望的值:那些在交叉验证中产生最低误差的值。我们可以绘制超参数与迭代的值,以查看是否存在明显的趋势。
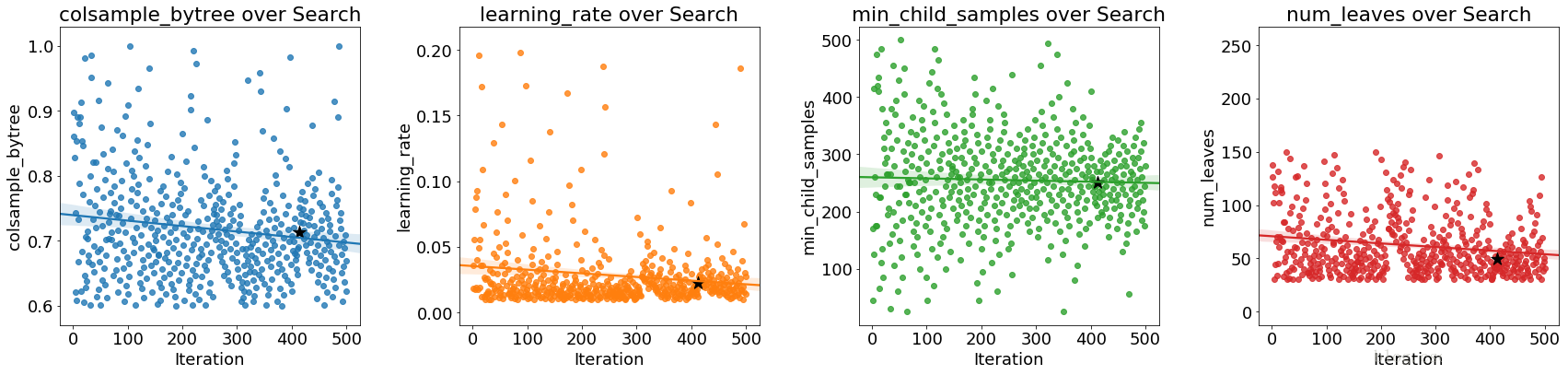
黑星表示最佳值。 colsamplebytree和learningrate会随着时间的推移而减少,这可能会指导我们未来的搜索。
最后,如果贝叶斯优化工作正常,我们预计平均验证分数会随着时间的推移而增加(相反,损失减少):
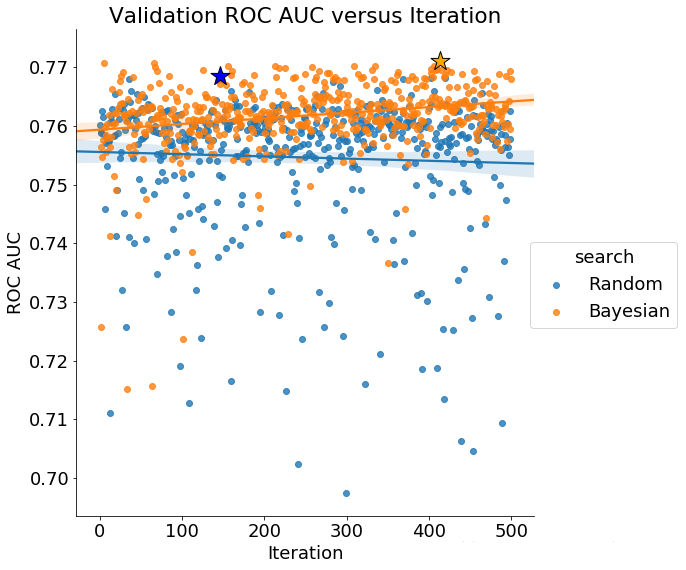
来自贝叶斯超参数优化的验证集上的分数随着时间的推移而增加,表明该方法正在尝试“更好”的超参数值(应该注意,仅根据验证集上的表现更好)。随机搜索没有显示迭代的改进。
继续搜索
如果我们对模型的性能不满意,我们可以继续使用Hyperopt进行搜索。我们只需要传入相同的试验对象,算法将继续搜索。
随着算法的进展,它会进行更多的挖掘 - 挑选过去表现良好的价值 , 而不是探索 - 挑选新价值。因此,开始完全不同的搜索可能是一个好主意,而不是从搜索停止的地方继续开始。如果来自第一次搜索的最佳超参数确实是“最优的”,我们希望后续搜索专注于相同的值。
经过另外500次训练后,最终模型在测试集上得分为0.72736 ROC AUC。 (我们实际上不应该评估测试集上的第一个模型,而只依赖于验证分数。理想情况下,测试集应该只使用一次,以便在部署到新数据时获得算法性能的度量)。同样,由于数据集的小尺寸,这个问题可能导致进一步超参数优化的收益递减,并且最终会出现验证错误的平台(由于隐藏变量导致数据集上任何模型的性能存在固有限制未测量和噪声数据,称为贝叶斯误差
结论
可以使用贝叶斯优化来完成机器学习模型的超参数自动调整。与随机或网格搜索相比,贝叶斯优化对目标函数的评估较少,测试集上的更好的泛化性能。
除了网格和随机搜索之外,我们还能够提高梯度增强机的测试集性能,尽管我们需要谨慎对待训练数据的过度拟合。此外,我们通过可视化结果表看到随机搜索与贝叶斯优化的不同之处,这些图表显示贝叶斯方法对超参数值的概率更大,导致交叉验证损失更低。
使用优化问题的四个部分,我们可以使用Hyperopt来解决各种各样的问题。贝叶斯优化的基本部分也适用于Python中实现不同算法的许多库。从手动切换到随机或网格搜索只是一小步,但要将机器学习提升到新的水平,需要一些自动形式的超参数调整。贝叶斯优化是一种易于在Python中使用的方法,并且可以比随机搜索返回更好的结果。 |








