| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫШчКЮбЇЯАШчКЮЖдЭМЯёНјаабеЩЋПеМфзЊЛЛвдМАМђЕЅуажЕЃЌздЪЪгІуажЕЃЌOtsuЁЏs
ЖўжЕЛЏЃЌ ЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкВЉПЭдАЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
13 беЩЋПеМфзЊЛЛ
ФПБъ
1.ФуНЋбЇЯАШчКЮЖдЭМЯёНјаабеЩЋПеМфзЊЛЛЃЌБШШчДг BGR ЕНЛвЖШЭМЃЌЛђепДгBGR
ЕН HSV ЕШЁЃ
2.ЮвУЛЛЙвЊДДНЈвЛИіГЬађгУРДДгвЛЗљЭМЯёжаЛёШЁФГИіЬиЖЈбеЩЋЕФЮяЬхЁЃ
3.ЮвУЧНЋвЊбЇЯАЕФКЏЪ§гаЃКcv2.cvtColor()ЃЌcv2.inRange()
ЕШЁЃ
13.1 зЊЛЛбеЩЋПеМф
дк OpenCV жагаГЌЙ§ 150 жаНјаабеЩЋПеМфзЊЛЛЕФЗНЗЈЁЃЕЋЪЧФувдКѓОЭЛсЁЂЗЂЯжЮвУЧОГЃгУЕНЕФвВОЭСНжжЃКBGR?Gray
КЭ BGR?HSVЁЃ
ЮвУЧвЊгУЕНЕФКЏЪ§ЪЧЃКcv2.cvtColor(input_image ЃЌflag)ЃЌЦфжа flagОЭЪЧзЊЛЛРраЭЁЃ
Ждгк BGR?Gray ЕФзЊЛЛЃЌЮвУЧвЊЪЙгУЕФ flag ОЭЪЧ cv2.COLOR_BGR2GRAYЁЃ
ЭЌбљЖдгк BGR?HSV ЕФзЊЛЛЃЌЮвУЧгУЕФ flag ОЭЪЧ cv2.COLOR_BGR2HSVЁЃ
ФуЛЙПЩвдЭЈЙ§ЯТУцЕФУќСюЕУЕНЫљгаПЩгУЕФ flagЁЃ
import cv2
flags=[i for in dir(cv2) if i startswith('COLOR_')]
print flags |
зЂвтЃКдк OpenCV ЕФ HSV ИёЪНжаЃЌHЃЈЩЋВЪ/ЩЋЖШЃЉЕФШЁжЕЗЖЮЇЪЧ [0ЃЌ179]ЃЌSЃЈБЅКЭЖШЃЉЕФШЁжЕЗЖЮЇ
[0ЃЌ255]ЃЌVЃЈССЖШЃЉЕФШЁжЕЗЖЮЇ [0ЃЌ255]ЁЃЕЋЪЧВЛЭЌЕФШэМўЪЙгУЕФжЕПЩФмВЛЭЌЁЃЫљвдЕБФуашвЊФУ
OpenCV ЕФ HSV жЕгыЦфЫћШэМўЕФ HSV жЕНјааЖдБШЪБЃЌвЛЖЈвЊМЧЕУЙщвЛЛЏЁЃ
13.2 ЮяЬхИњзй
ЯждкЮвУЧжЊЕРдѕбљНЋвЛЗљЭМЯёДг BGR зЊЛЛЕН HSV СЫЃЌЮвУЧПЩвдРћгУетвЛЕуРДЬсШЁДјгаФГИіЬиЖЈбеЩЋЕФЮяЬхЁЃдк
HSV беЩЋПеМфжавЊБШдк BGR ПеМфжаИќШнвзБэЪОвЛИіЬиЖЈбеЩЋЁЃдкЮвУЧЕФГЬађжаЃЌЮвУЧвЊЬсШЁЕФЪЧвЛИіРЖЩЋЕФЮяЬхЁЃЯТУцОЭЪЧОЭЪЧЮвУЧвЊзіЕФМИВНЃК
1.ДгЪгЦЕжаЛёШЁУПвЛжЁЭМЯё
2.НЋЭМЯёзЊЛЛЕН HSV ПеМф
3.ЩшжУ HSV уажЕЕНРЖЩЋЗЖЮЇЁЃ
4.ЛёШЁРЖЩЋЮяЬхЃЌЕБШЛЮвУЧЛЙПЩвдзіЦфЫћШЮКЮЮвУЧЯызіЕФЪТЃЌБШШчЃКдкРЖЩЋЮяЬхжмЮЇЛвЛИіШІЁЃ
ЯТУцОЭЪЧЮвУЧЕФДњТыЃК
import cv2
import numpy as np
cap = cv2.VideoCapture(r'ФуЕФЪгЦЕЮФМў')
while(1):
# Take each frame
_, frame = cap.read()
# Convert BGR to HSV
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
# define range of blue color in HSV
lower_blue = np.array([110,50,50])
upper_blue = np.array([130,255,255])
# Threshold the HSV image to get only blue
colors
mask = cv2.inRange(hsv, lower_blue, upper_blue)
# Bitwise-AND mask and original image
res = cv2.bitwise_and(frame,frame, mask= mask)
cv2.imshow('frame',frame)
cv2.imshow('mask',mask)
cv2.imshow('res',res)
k = cv2.waitKey(5) & 0xFF
if k == 27:
break
cv2.destroyAllWindows() |
зЂвтЃКетЪЧЮяЬхИњзйжазюМђЕЅЕФЗНЗЈЁЃЕБФубЇЯАСЫТжРЊжЎКѓЃЌФуОЭЛсбЇЕНИќЖрЯрЙижЊЪЖЃЌФЧЪЧФуОЭПЩвдевЕНЮяЬхЕФжиаФЃЌВЂИљОнжиаФРДИњзйЮяЬхЃЌНіНідкЩуЯёЭЗЧАЛгЛгЪжОЭПЩвдЛГіЭЌЕФЭМаЮЃЌЛђепЦфЫћИќгаШЄЕФЪТЁЃ

13.3 дѕбљевЕНвЊИњзйЖдЯѓЕФ HSV жЕЃП
етЪЧЮвдкstackoverflow.comЩЯгіЕНЕФзюЦеБщЕФЮЪЬтЁЃЦфЪЕетецЕФКмМђЕЅЃЌКЏЪ§
cv2.cvtColor() вВПЩвдгУЕНетРяЁЃЕЋЪЧЯждкФувЊДЋШыЕФВЮЪ§ЪЧЃЈФуЯывЊЕФЃЉBGR жЕЖјВЛЪЧвЛИБЭМЁЃР§ШчЃЌЮвУЧвЊевЕНТЬЩЋЕФ
HSV жЕЃЌЮвУЧжЛашдкжеЖЫЪфШывдЯТУќСюЃК
import cv2
import numpy as np
green=np.uint8([0,255,0])
hsv_green=cv2.cvtColor(green,cv2.COLOR_BGR2HSV)
error: /builddir/build/BUILD/opencv-2.4.6.1/
modules/imgproc/src/color.cpp:3541:
error: (-215) (scn == 3 || scn == 4) &&
(depth == CV_8U || depth == CV_32F)
in function cvtColor
#scn (the number of channels of the source),
#i.e. self.img.channels(), is neither 3 nor 4.
#
#depth (of the source),
#i.e. self.img.depth(), is neither CV_8U nor CV_32F.
# ЫљвдВЛФмгУ [0,255,0] ЃЌЖјвЊгУ [[[0,255,0]]]
# етРяЕФШ§ВуРЈКХгІИУЗжБ№ЖдгІгк cvArray ЃЌ cvMat ЃЌ IplImage
green=np.uint8([[[0,255,0]]])
hsv_green=cv2.cvtColor(green,cv2.COLOR_BGR2HSV)
print(hsv_green)
# [[[60 255 255]]] |
ЯждкФуПЩвдЗжБ№гУ [H-100ЃЌ100ЃЌ100] КЭ [H+100ЃЌ255ЃЌ255]
зіЩЯЯТуажЕЁЃГ§СЫетИіЗНЗЈжЎЭтЃЌФуПЩвдЪЙгУШЮКЮЦфЫћЭМЯёБрМШэМўЃЈР§Шч GIMPЃЉЛђепдкЯпзЊЛЛШэМўевЕНЯргІЕФ
HSV жЕЃЌЕЋЪЧзюКѓБ№ЭќСЫЕїНк HSV ЕФЗЖЮЇЁЃ
СЗЯА
1. ГЂЪдЭЌЪБЬсШЁЖрИіВЛЭЌЕФбеЩЋЮяЬхЃЌБШШчЭЌЪБЬсШЁКьЃЌРЖЃЌТЬШ§ИіВЛЭЌбеЩЋЕФЮяЬхЁЃ
14 МИКЮБфЛЛ
ФПБъ
1.бЇЯАЖдЭМЯёНјааИїжжМИИіБфЛЛЃЌР§ШчвЦЖЏЃЌа§зЊЃЌЗТЩфБфЛЛЕШЁЃ
2.НЋвЊбЇЕНЕФКЏЪ§гаЃКcv2.getPerspectiveTransformЁЃ
БфЛЛ
OpenCV ЬсЙЉСЫСНИіБфЛЛКЏЪ§ЃЌcv2.warpAffine КЭ cv2.warpPerspectiveЃЌЪЙгУетСНИіКЏЪ§ФуПЩвдЪЕЯжЫљгаРраЭЕФБфЛЛЁЃcv2.warpAffine
НгЪеЕФВЮЪ§ЪЧ2 ЁС 3 ЕФБфЛЛОиеѓЃЌЖј cv2.warpPerspective НгЪеЕФВЮЪ§ЪЧ 3 ЁС
3 ЕФБфЛЛОиеѓЁЃ
14.1 РЉеЙЫѕЗХ
РЉеЙЫѕЗХжЛЪЧИФБфЭМЯёЕФГпДчДѓаЁЁЃOpenCV ЬсЙЉЕФКЏЪ§ cv2.resize()ПЩвдЪЕЯжетИіЙІФмЁЃЭМЯёЕФГпДчПЩвдздМКЪжЖЏЩшжУЃЌФувВПЩвджИЖЈЫѕЗХвђзгЁЃЮвУЧПЩвдбЁдёЪЙгУВЛЭЌЕФВхжЕЗНЗЈЁЃдкЫѕЗХЪБЮвУЧЭЦМіЪЙгУ
cv2.INTER_AREAЃЌдкРЉеЙЪБЮвУЧЭЦМіЪЙгУ v2.INTER_CUBICЃЈТ§) КЭ v2.INTER_LINEARЁЃФЌШЯЧщПіЯТЫљгаИФБфЭМЯёГпДчДѓаЁЕФВйзїЪЙгУЕФВхжЕЗНЗЈЖМЪЧ
cv2.INTER_LINEARЁЃФуПЩвдЪЙгУЯТУцШЮвтвЛжжЗНЗЈИФБфЭМЯёЕФГпДчЃК
import cv2
import numpy as np
img=cv2.imread('messi5.jpg')
# ЯТУцЕФ None БОгІИУЪЧЪфГіЭМЯёЕФГпДчЃЌ
ЕЋЪЧвђЮЊКѓБпЮвУЧЩшжУСЫЫѕЗХвђзг
# вђДЫетРяЮЊ None
res=cv2.resize(img,None,fx=2,fy=2,
interpolation=cv2.INTER_CUBIC)
#OR
# етРяФиЃЌЮвУЧжБНгЩшжУЪфГіЭМЯёЕФГпДчЃЌ
ЫљвдВЛгУЩшжУЫѕЗХвђзг
height,width=img.shape[:2]
res=cv2.resize(img,(2*width,2*height),
interpolation=cv2.INTER_CUBIC)
while(1):
cv2.imshow('res',res)
cv2.imshow('img',img)
if cv2.waitKey(1) & 0xFF == 27:
break
cv2.destroyAllWindows()
# Resize(src, dst, interpolation=CV_INTER_LINEAR)
|
14.2 ЦНвЦ
ЦНвЦОЭЪЧНЋЖдЯѓЛЛвЛИіЮЛжУЁЃШчЙћФувЊбиЃЈxЃЌyЃЉЗНЯђвЦЖЏЃЌвЦЖЏЕФОрРыЪЧЃЈt
x ЃЌt y ЃЉЃЌФуПЩвдвдЯТУцЕФЗНЪНЙЙНЈвЦЖЏОиеѓЃК
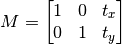
ФуПЩвдЪЙгУ Numpy Ъ§зщЙЙНЈетИіОиеѓЃЈЪ§ОнРраЭЪЧ np.float32ЃЉЃЌШЛКѓАбЫќДЋИјКЏЪ§ cv2.warpAffine()ЁЃПДПДЯТУцетИіР§згАЩЃЌЫќБЛвЦЖЏСЫЃЈ100,50ЃЉИіЯёЫиЁЃ
import cv2
import numpy as np
img = cv2.imread('messi5.jpg',0)
rows,cols = img.shape
M = np.float32([[1,0,100],[0,1,50]])
dst = cv2.warpAffine(img,M,(cols,rows))
cv2.imshow('img',dst)
cv2.waitKey(0)
cv2.destroyAllWindows() |

ОЏИцЃККЏЪ§ cv2.warpAffine() ЕФЕкШ§ИіВЮЪ§ЕФЪЧЪфГіЭМЯёЕФДѓаЁЃЌЫќЕФИёЪНгІИУЪЧЭМЯёЕФЃЈПэЃЌИпЃЉЁЃгІИУМЧзЁЕФЪЧЭМЯёЕФПэЖдгІЕФЪЧСаЪ§ЃЌИпЖдгІЕФЪЧааЪ§ЁЃ
ЯТУцОЭЪЧНсЙћЃК
14.3 а§зЊ
ЖдвЛИіЭМЯёа§зЊНЧЖШ ІШ, ашвЊЪЙгУЕНЯТУцаЮЪНЕФа§зЊОиеѓЁЃ
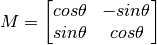
ЕЋЪЧ OpenCV дЪаэФудкШЮвтЕиЗННјааа§зЊЃЌЕЋЪЧа§зЊОиеѓЕФаЮЪНгІИУао
ИФЮЊ
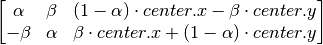
ЦфжаЃК
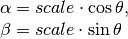
ЮЊСЫЙЙНЈетИіа§зЊОиеѓЃЌOpenCV ЬсЙЉСЫвЛИіКЏЪ§ЃКcv2.getRotationMatrix2DЁЃ
ЯТУцЕФР§згЪЧдкВЛЫѕЗХЕФЧщПіЯТНЋЭМЯёа§зЊ 90 ЖШЁЃ
import cv2
import numpy as np
img=cv2.imread('messi5.jpg',0)
rows,cols=img.shape
# етРяЕФЕквЛИіВЮЪ§ЮЊа§зЊжааФЃЌЕкЖўИіЮЊа§зЊНЧЖШЃЌЕкШ§ИіЮЊа§зЊКѓЕФЫѕЗХвђзг
# ПЩвдЭЈЙ§ЩшжУа§зЊжааФЃЌЫѕЗХвђзгЃЌвдМАДАПкДѓаЁРДЗРжЙа§зЊКѓГЌГіБпНчЕФЮЪЬт
M=cv2.getRotationMatrix2D((cols/2,rows/2),45,0.6)
# ЕкШ§ИіВЮЪ§ЪЧЪфГіЭМЯёЕФГпДчжааФ
dst=cv2.warpAffine(img,M,(2*cols,2*rows))
while(1):
cv2.imshow('img',dst)
if cv2.waitKey(1)&0xFF==27:
break
cv2.destroyAllWindows() |
ЯТУцЪЧНсЙћ:

14.4 ЗТЩфБфЛЛ
ЁЁЁЁдкЗТЩфБфЛЛжаЃЌдЭМжаЫљгаЕФЦНааЯпдкНсЙћЭМЯёжаЭЌбљЦНааЁЃЮЊСЫДДНЈетИіОиеѓЮвУЧашвЊДгдЭМЯёжаевЕНШ§ИіЕувдМАЫћУЧдкЪфГіЭМЯёжаЕФЮЛжУЁЃШЛКѓcv2.getAffineTransform
ЛсДДНЈвЛИі 2x3 ЕФОиеѓЃЌзюКѓетИіОиеѓЛсБЛДЋИјКЏЪ§ cv2.warpAffineЁЃ
РДПДПДЯТУцЕФР§згЃЌвдМАЮвбЁдёЕФЕуЃЈБЛБъМЧЮЊТЬЩЋЕФЕуЃЉ
img = cv2.imread('drawing.png')
rows,cols,ch = img.shape
pts1 = np.float32([[50,50],[200,50],[50,200]])
pts2 = np.float32([[10,100],[200,50],[100,250]])
M = cv2.getAffineTransform(pts1,pts2)
dst = cv2.warpAffine(img,M,(cols,rows))
plt.subplot(121),plt.imshow(img),plt.title('Input')
plt.subplot(122),plt.imshow(dst),plt.title('Output')
plt.show() |
ЯТУцЪЧНсЙћЃК
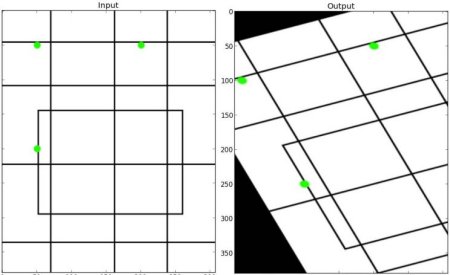
14.5 ЭИЪгБфЛЛ
ЖдгкЪгНЧБфЛЛЃЌЮвУЧашвЊвЛИі 3x3 БфЛЛОиеѓЁЃдкБфЛЛЧАКѓжБЯпЛЙЪЧжБЯпЁЃвЊЙЙНЈетИіБфЛЛОиеѓЃЌФуашвЊдкЪфШыЭМЯёЩЯев
4 ИіЕуЃЌвдМАЫћУЧдкЪфГіЭМЯёЩЯЖдгІЕФЮЛжУЁЃетЫФИіЕужаЕФШЮвтШ§ИіЖМВЛФмЙВЯпЁЃетИіБфЛЛОиеѓПЩвдгаКЏЪ§ cv2.getPerspectiveTransform()
ЙЙНЈЁЃШЛКѓАбетИіОиеѓДЋИјКЏЪ§cv2.warpPerspectiveЁЃ
ДњТыШчЯТЃК
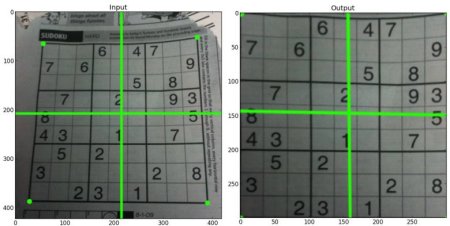
img = cv2.imread('sudokusmall.png')
rows,cols,ch = img.shape
pts1 = np.float32([[56,65],[368,52],[28,387],[389,390]])
pts2 = np.float32([[0,0],[300,0],[0,300],[300,300]]
M = cv2.getPerspectiveTransform(pts1,pts2
dst = cv2.warpPerspective(img,M,(300,300))
plt.subplot(121),plt.imshow(img),plt.title('Input')
plt.subplot(122),plt.imshow(dst),plt.title('Output')
plt.show() |
НсЙћШчЯТЃК
15 ЭМЯёуажЕ
ФПБъ
1.БОНкФуНЋбЇЕНМђЕЅуажЕЃЌздЪЪгІуажЕЃЌOtsuЁЏs ЖўжЕЛЏЕШ
2.НЋвЊбЇЯАЕФКЏЪ§га cv2.thresholdЃЌcv2.adaptiveThreshold
ЕШЁЃ
15.1 МђЕЅуажЕ
гыУћзжвЛбљЃЌетжжЗНЗЈЗЧГЃМђЕЅЁЃЕЋЯёЫижЕИпгкуажЕЪБЃЌЮвУЧИјетИіЯёЫиИГгшвЛИіаТжЕЃЈПЩФмЪЧАзЩЋЃЉЃЌЗёдђЮвУЧИјЫќИГгшСэЭтвЛжжбеЩЋЃЈвВаэЪЧКкЩЋЃЉЁЃетИіКЏЪ§ОЭЪЧ
cv2.threshhold()ЁЃетИіКЏЪ§ЕФЕквЛИіВЮЪ§ОЭЪЧдЭМЯёЃЌдЭМЯёгІИУЪЧЛвЖШЭМЁЃЕкЖўИіВЮЪ§ОЭЪЧгУРДЖдЯёЫижЕНјааЗжРрЕФуажЕЁЃЕкШ§ИіВЮЪ§ОЭЪЧЕБЯёЫижЕИпгкЃЈгаЪБЪЧаЁгкЃЉуажЕЪБгІИУБЛИГгшЕФаТЕФЯёЫижЕЁЃOpenCVЬсЙЉСЫЖржжВЛЭЌЕФуажЕЗНЗЈЃЌетЪЧгаЕкЫФИіВЮЪ§РДОіЖЈЕФЁЃетаЉЗНЗЈАќРЈЃК
1.cv2.THRESH_BINARY
2.cv2.THRESH_BINARY_INV
3.cv2.THRESH_TRUNC
4.cv2.THRESH_TOZERO
5.cv2.THRESH_TOZERO_INV
ЩЯЭМеЊбЁздЁЖбЇЯА OpenCVЁЗжаЮФАцЃЌЦфЪЕетаЉдкЮФЕЕжаЖМгаЯъЯИНщЩмСЫЃЌФувВПЩвджБНгВщПДЮФЕЕЁЃ
етИіКЏЪ§гаСНИіЗЕЛижЕЃЌЕквЛИіЮЊ retValЃЌЮвУЧКѓУцЛсНтЪЭЁЃЕкЖўИіОЭЪЧуажЕЛЏжЎКѓЕФНсЙћЭМЯёСЫЁЃ
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('gradient.png',0)
ret,thresh1 = cv2.threshold(img,127,255,cv2.
THRESH_BINARY)
ret,thresh2 = cv2.threshold(img,127,255,cv2.
THRESH_BINARY_INV)
ret,thresh3 = cv2.threshold(img,127,255,cv2.
THRESH_TRUNC)
ret,thresh4 = cv2.threshold(img,127,255,cv2.
THRESH_TOZERO)
ret,thresh5 = cv2.threshold(img,127,255,cv2.THRESH_TOZERO_INV)
titles = ['Original Image','BINARY','BINARY_INV','TRUNC','TOZERO','
TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4,
thresh5]
for i in xrange(6):
plt.subplot(2,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show() |
зЂвтЃКЮЊСЫЭЌЪБдквЛИіДАПкжаЯдЪОЖрИіЭМЯёЃЌЮвУЧЪЙгУКЏЪ§ plt.subplot()ЁЃФуПЩвдЭЈЙ§ВщПД Matplotlib
ЕФЮФЕЕЛёЕУИќЖрЯъЯИаХЯЂЁЃ
НсЙћШчЯТЃК

15.2 здЪЪгІуажЕ
дкЧАУцЕФВПЗжЮвУЧЪЙгУЪЧШЋОжуажЕЃЌећЗљЭМЯёВЩгУЭЌвЛИіЪ§зїЮЊуажЕЁЃЕБЪБетжжЗНЗЈВЂВЛЪЪгІгыЫљгаЧщПіЃЌгШЦфЪЧЕБЭЌвЛЗљЭМЯёЩЯЕФВЛЭЌВПЗжЕФОпгаВЛЭЌССЖШЪБЁЃетжжЧщПіЯТЮвУЧашвЊВЩгУздЪЪгІуажЕЁЃДЫЪБЕФуажЕЪЧИљОнЭМЯёЩЯЕФУПвЛИіаЁЧјгђМЦЫугыЦфЖдгІЕФуажЕЁЃвђДЫдкЭЌвЛЗљЭМЯёЩЯЕФВЛЭЌЧјгђВЩгУЕФЪЧВЛЭЌЕФуажЕЃЌДгЖјЪЙЮвУЧФмдкССЖШВЛЭЌЕФЧщПіЯТЕУЕНИќКУЕФНсЙћЁЃ
етжжЗНЗЈашвЊЮвУЧжИЖЈШ§ИіВЮЪ§ЃЌЗЕЛижЕжЛгавЛИіЁЃ
Adaptive Method- жИЖЈМЦЫууажЕЕФЗНЗЈЁЃ
ЈC cv2.ADPTIVE_THRESH_MEAN_CЃКуажЕШЁздЯрСкЧјгђЕФЦНОљжЕ
ЈC cv2.ADPTIVE_THRESH_GAUSSIAN_CЃКуажЕШЁжЕЯрСкЧјгђЕФМгШЈКЭЃЌШЈжиЮЊвЛИіИпЫЙДАПкЁЃ
Block Size - СкгђДѓаЁЃЈгУРДМЦЫууажЕЕФЧјгђДѓаЁЃЉЁЃ
C - етОЭЪЧЪЧвЛИіГЃЪ§ЃЌуажЕОЭЕШгкЕФЦНОљжЕЛђепМгШЈЦНОљжЕМѕШЅетИіГЃЪ§ЁЃ
ЮвУЧЪЙгУЯТУцЕФДњТыРДеЙЪОМђЕЅуажЕгыздЪЪгІуажЕЕФВюБ№ЃК
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('dave.jpg',0)
img = cv2.medianBlur(img,5)
ret,th1 = cv2.threshold(img,127,255,cv2.THRESH_BINARY)
th2 = cv2.adaptiveThreshold(img,255,cv2.ADAPTIVE_
THRESH_MEAN_C,\
cv2.THRESH_BINARY,11,2)
th3 = cv2.adaptiveThreshold(img,255,cv2.ADAPTIVE_
THRESH_GAUSSIAN_C,\
cv2.THRESH_BINARY,11,2)
titles = ['Original Image',
'Global Thresholding
(v = 127)',
'Adaptive Mean Thresholding', 'Adaptive Gaussian
Thresholding']
images = [img, th1, th2, th3]
for i in xrange(4):
plt.subplot(2,2,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show() |
НсЙћЃК

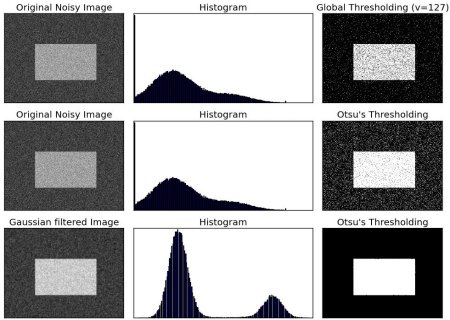
15.3 OtsuЁЏ ЁЏs ЖўжЕЛЏ
дкЕквЛВПЗжжаЮвУЧЬсЕНЙ§ retValЃЌЕБЮвУЧЪЙгУ Otsu ЖўжЕЛЏЪБЛсгУЕНЫќЁЃФЧУДЫќЕНЕзЪЧЪВУДФиЃП
дкЪЙгУШЋОжуажЕЪБЃЌЮвУЧОЭЪЧЫцБуИјСЫвЛИіЪ§РДзіуажЕЃЌФЧЮвУЧдѕУДжЊЕРЮвУЧбЁШЁЕФетИіЪ§ЕФКУЛЕФиЃПД№АИОЭЪЧВЛЭЃЕФГЂЪдЁЃШчЙћЪЧвЛИБЫЋЗхЭМЯёЃЈМђЕЅРДЫЕЫЋЗхЭМЯёЪЧжИЭМЯёжБЗНЭМжаДцдкСНИіЗхЃЉФиЃПЮвУЧЦёВЛЪЧгІИУдкСНИіЗхжЎМфЕФЗхЙШбЁвЛИіжЕзїЮЊуажЕЃПетОЭЪЧ
Otsu ЖўжЕЛЏвЊзіЕФЁЃМђЕЅРДЫЕОЭЪЧЖдвЛИБЫЋЗхЭМЯёздЖЏИљОнЦфжБЗНЭММЦЫуГівЛИіуажЕЁЃЃЈЖдгкЗЧЫЋЗхЭМЯёЃЌетжжЗНЗЈЕУЕНЕФНсЙћПЩФмЛсВЛРэЯыЃЉЁЃ
етРягУЕНЕНЕФКЏЪ§ЛЙЪЧ cv2.threshold()ЃЌЕЋЪЧашвЊЖрДЋШывЛИіВЮЪ§ЃЈflagЃЉЃКcv2.THRESH_OTSUЁЃетЪБвЊАбуажЕЩшЮЊ
0ЁЃШЛКѓЫуЗЈЛсевЕНзюгХуажЕЃЌетИізюгХуажЕОЭЪЧЗЕЛижЕ retValЁЃШчЙћВЛЪЙгУ Otsu ЖўжЕЛЏЃЌЗЕЛиЕФretVal
жЕгыЩшЖЈЕФуажЕЯрЕШЁЃ
ЯТУцЕФР§згжаЃЌЪфШыЭМЯёЪЧвЛИБДјгадыЩљЕФЭМЯёЁЃЕквЛжжЗНЗЈЃЌЮвУЧЩш127
ЮЊШЋОжуажЕЁЃЕкЖўжжЗНЗЈЃЌЮвУЧжБНгЪЙгУ Otsu ЖўжЕЛЏЁЃЕкШ§жжЗНЗЈЃЌЮвУЧЪзЯШЪЙгУвЛИі 5x5 ЕФИпЫЙКЫГ§ШЅдывєЃЌШЛКѓдйЪЙгУ
Otsu ЖўжЕЛЏЁЃПДПДдывєШЅГ§ЖдНсЙћЕФгАЯьгаЖрДѓАЩЁЃ
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('noisy2.png',0)
# global thresholding
ret1,th1 = cv2.threshold(img,127,255,cv2.
THRESH_BINARY)
# Otsu's thresholding
ret2,th2 = cv2.threshold(img,0,255,cv2.
THRESH_BINARY+cv2.
THRESH_OTSU)
# Otsu's thresholding after Gaussian filtering
blur = cv2.GaussianBlur(img,(5,5),0)
ret3,th3 = cv2.threshold(blur,0,255,cv2.
THRESH_BINARY+cv2.
THRESH_OTSU)
# plot all the images and their histograms
images = [img, 0, th1,
img, 0, th2,
blur, 0, th3]
titles = ['Original Noisy Image','Histogram','
Global
Thresholding (v=127)',
'Original Noisy Image','Histogram',"Otsu's
Thresholding",
'Gaussian filtered Image','Histogram',"Otsu's
Thresholding"]
for i in xrange(3):
plt.subplot(3,3,i*3+1),plt.imshow(images[i*3],'gray')
plt.title(titles[i*3]), plt.xticks([]), plt.yticks([])
plt.subplot(3,3,i*3+2),plt.hist(images[i*3].ravel(),256)
plt.title(titles[i*3+1]), plt.xticks([]), plt.yticks([])
plt.subplot(3,3,i*3+3),plt.imshow(images[i*3+2],'gray')
plt.title(titles[i*3+2]), plt.xticks([]), plt.yticks([])
plt.show() |
15.4 OtsuЁЏ ЁЏs ЖўжЕЛЏЪЧШчКЮЙЄзїЕФЃП
дкетвЛВПЗжЮвУЧЛсбнЪОдѕбљЪЙгУ Python РДЪЕЯж Otsu ЖўжЕЛЏЫуЗЈЃЌДгЖјИцЫпДѓМвЫќЪЧШчКЮЙЄзїЕФЁЃШчЙћФуВЛИааЫШЄЕФЛАПЩвдЬјЙ§етвЛНкЁЃвђЮЊЪЧЫЋЗхЭМЃЌOtsu
ЫуЗЈОЭЪЧвЊевЕНвЛИіуажЕЃЈtЃЉ, ЪЙЕУЭЌвЛРрМгШЈЗНВюзюаЁЃЌашвЊТњзуЯТСаЙиЯЕЪНЃК
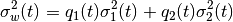
ЦфжаЃК
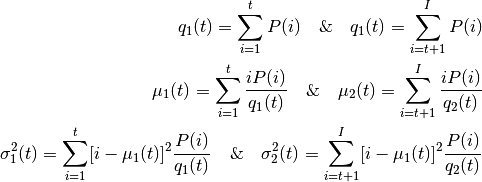
ЦфЪЕОЭЪЧдкСНИіЗхжЎМфевЕНвЛИіуажЕ tЃЌНЋетСНИіЗхЗжПЊЃЌВЂЧвЪЙУПвЛИіЗхФкЕФЗНВюзюаЁЁЃЪЕЯжетИіЫуЗЈЕФ Python
ДњТыШчЯТЃК
img = cv2.imread('noisy2.png',0)
blur = cv2.GaussianBlur(img,(5,5),0)
# find normalized_histogram, and its cumulative
distribution function
hist = cv2.calcHist([blur],[0],None,
[256],[0,256])
hist_norm = hist.ravel()/hist.max()
Q = hist_norm.cumsum()
bins = np.arange(256)
fn_min = np.inf
thresh = -1
for i in xrange(1,256):
p1,p2 = np.hsplit(hist_norm,[i]) # probabilities
q1,q2 = Q[i],Q[255]-Q[i] # cum sum of classes
b1,b2 = np.hsplit(bins,[i]) # weights
# finding means and variances
m1,m2 = np.sum(p1*b1)/q1, np.sum(p2*b2)/q2
v1,v2 = np.sum(((b1-m1)**2)*p1)/q1,np.sum(((b2-m2)**2)*p2)/q2
# calculates the minimization function
fn = v1*q1 + v2*q2
if fn < fn_min:
fn_min = fn
thresh = i
# find otsu's threshold value with OpenCV function
ret, otsu = cv2.threshold(blur,0,255,cv2.
THRESH_BINARY+cv2.
THRESH_OTSU)
prin(thresh,ret) |
|








