| БрМЭЦМі: |
БОЮФжївЊбЇЯАШчКЮЪЙгУ OpenCV ЖдЭМЯёНјааИЕРявЖБфЛЛ, ЪЙгУФЃАхЦЅХфдквЛЗљЭМЯёжаВщевФПБъЃЌдквЛеХЭМЦЌжаМьВтжБЯпЃЌЪЙгУЗжЫЎСыЫуЗЈЛљгкбкФЃЕФЭМЯёЗжИювдМАGrabCut
ЫуЗЈдРэЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкВЉПЭдАЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
23 ЭМЯёБфЛЛ
23.1 ИЕРявЖБфЛЛ
ФПБъ
БОаЁНкЮвУЧНЋвЊбЇЯАЃК
ЪЙгУ OpenCV ЖдЭМЯёНјааИЕРявЖБфЛЛ
ЪЙгУ Numpy жа FFTЃЈПьЫйИЕРявЖБфЛЛЃЉКЏЪ§
ИЕРявЖБфЛЛЕФвЛаЉгУДІ
ЮвУЧНЋвЊбЇЯАЕФКЏЪ§гаЃКcv2.dft()ЃЌcv2.idft() ЕШ
дРэ
ИЕРявЖБфЛЛОГЃБЛгУРДЗжЮіВЛЭЌТЫВЈЦїЕФЦЕТЪЬиадЁЃЮвУЧПЩвдЪЙгУ 2D
РыЩЂИЕРявЖБфЛЛ (DFT) ЗжЮіЭМЯёЕФЦЕгђЬиадЁЃЪЕЯж DFT ЕФвЛИіПьЫйЫуЗЈБЛГЦЮЊПьЫйИЕРявЖБфЛЛЃЈFFTЃЉЁЃЙигкИЕРявЖБфЛЛЕФЯИНкжЊЪЖПЩвддкШЮвтвЛБОЭМЯёДІРэЛђаХКХДІРэЕФЪщжаевЕНЁЃЧыВщПДБОаЁНкжаИќЖрзЪдДВПЗжЁЃ
ЖдгквЛИіе§ЯваХКХЃКx(t) = Asin(2Іаft), ЫќЕФЦЕТЪЮЊ fЃЌШчЙћАбетИіаХКХзЊЕНЫќЕФЦЕгђБэЪОЃЌЮвУЧЛсдкЦЕТЪ
f жаПДЕНвЛИіЗхжЕЁЃШчЙћЮвУЧЕФаХКХЪЧгЩВЩбљВњЩњЕФРыЩЂаХКХКУзщГЩЃЌЮвУЧЛсЕУЕНРрЫЦЕФЦЕЦзЭМЃЌжЛВЛЙ§ЧАУцЪЧСЌајЕФЃЌЯждкЪЧРыЩЂЁЃФуПЩвдАбЭМЯёЯыЯѓГЩбизХСНИіЗНЯђВЩМЏЕФаХКХЁЃЫљвдЖдЭМЯёЭЌЪБНјаа
X ЗНЯђКЭ Y ЗНЯђЕФИЕРявЖБфЛЛЃЌЮвУЧОЭЛсЕУЕНетЗљЭМЯёЕФЦЕгђБэЪОЃЈЦЕЦзЭМЃЉЁЃ
ИќжБЙлвЛЕуЃЌЖдгквЛИіе§ЯваХКХЃЌШчЙћЫќЕФЗљЖШБфЛЏЗЧГЃПьЃЌЮвУЧПЩвдЫЕЫћЪЧИпЦЕаХКХЃЌШчЙћБфЛЏЗЧГЃТ§ЃЌЮвУЧГЦжЎЮЊЕЭЦЕаХКХЁЃФуПЩвдАбетжжЯыЗЈгІгУЕНЭМЯёжаЃЌЭМЯёФЧРяЕФЗљЖШБфЛЏЗЧГЃДѓФиЃПБпНчЕуЛђепдыЩљЁЃЫљвдЮвУЧЫЕБпНчКЭдыЩљЪЧЭМЯёжаЕФИпЦЕЗжСПЃЈзЂвтетРяЕФИпЦЕЪЧжИБфЛЏЗЧГЃПьЃЌЖјЗЧГіЯжЕФДЮЪ§ЖрЃЉЁЃШчЙћУЛгаШчДЫДѓЕФЗљЖШБфЛЏЮвУЧГЦжЎЮЊЕЭЦЕЗжСПЁЃ
ЯждкЮвУЧПДПДдѕбљНјааИЕРявЖБфЛЛЁЃ
23.1.1 Numpy жаЕФИЕРявЖБфЛЛ
ЪзЯШЮвУЧПДПДШчКЮЪЙгУ Numpy НјааИЕРявЖБфЛЛЁЃNumpy жаЕФ
FFT АќПЩвдАяжњЮвУЧЪЕЯжПьЫйИЕРявЖБфЛЛЁЃКЏЪ§ np.fft.fft2() ПЩвдЖдаХКХНјааЦЕТЪзЊЛЛЃЌЪфГіНсЙћЪЧвЛИіИДдгЕФЪ§зщЁЃБОКЏЪ§ЕФЕквЛИіВЮЪ§ЪЧЪфШыЭМЯёЃЌвЊЧѓЪЧЛвЖШИёЪНЁЃЕкЖўИіВЮЪ§ЪЧПЩбЁЕФ,
ОіЖЈЪфГіЪ§зщЕФДѓаЁЁЃЪфГіЪ§зщЕФДѓаЁКЭЪфШыЭМЯёДѓаЁвЛбљЁЃШчЙћЪфГіНсЙћБШЪфШыЭМЯёДѓЃЌЪфШыЭМЯёОЭашвЊдкНјаа
FFT ЧАВЙ0ЁЃШчЙћЪфГіНсЙћБШЪфШыЭМЯёаЁЕФЛАЃЌЪфШыЭМЯёОЭЛсБЛЧаИюЁЃ
ЯждкЮвУЧЕУЕНСЫНсЙћЃЌЦЕТЪЮЊ 0 ЕФВПЗжЃЈжБСїЗжСПЃЉдкЪфГіЭМЯёЕФзѓЩЯНЧЁЃШчЙћЯыШУЫќЃЈжБСїЗжСПЃЉдкЪфГіЭМЯёЕФжааФЃЌЮвУЧЛЙашвЊНЋНсЙћбиСНИіЗНЯђЦНвЦ
ЁЃКЏЪ§ np.fft.fftshift() ПЩвдАяжњЮвУЧЪЕЯжетвЛВНЁЃЃЈетбљИќШнвзЗжЮіЃЉЁЃ
НјааЭъЦЕТЪБфЛЛжЎКѓЃЌЮвУЧОЭПЩвдЙЙНЈеёЗљЦзСЫЁЃ
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('messi5.jpg',0)
f = np.fft.fft2(img)
fshift = np.fft.fftshift(f)
# етРяЙЙНЈеёЗљЭМЕФЙЋЪНУЛбЇЙ§
magnitude_spectrum = 20*np.log(np.abs(fshift))
plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(magnitude_spectrum,
cmap = 'gray')
plt.title('Magnitude Spectrum'), plt.xticks([]),
plt.yticks([])
plt.show() |
НсЙћШчЯТЃК

ЮвУЧПЩвдПДЕНЪфГіНсЙћЕФжааФВПЗжИќАзЃЈССЃЉЃЌетЫЕУїЕЭЦЕЗжСПИќЖрЁЃ
ЯждкЮвУЧПЩвдНјааЦЕгђБфЛЛСЫЃЌЮвУЧОЭПЩвддкЦЕгђЖдЭМЯёНјаавЛаЉВйзїСЫЃЌР§ШчИпЭЈТЫВЈКЭжиНЈЭМЯёЃЈDFT ЕФФцБфЛЛЃЉЁЃБШШчЮвУЧПЩвдЪЙгУвЛИі60x60
ЕФОиаЮДАПкЖдЭМЯёНјаабкФЃВйзїДгЖјШЅГ§ЕЭЦЕЗжСПЁЃШЛКѓдйЪЙгУКЏЪ§np.fft.ifftshift() НјааФцЦНвЦВйзїЃЌЫљвдЯждкжБСїЗжСПгжЛиЕНзѓЩЯНЧСЫЃЌзѓКѓЪЙгУКЏЪ§
np.ifft2() Нјаа FFT ФцБфЛЛЁЃЭЌбљгжЕУЕНвЛЖбИДдгЕФЪ§зжЃЌЮвУЧПЩвдЖдЫћУЧШЁОјЖджЕЃК
rows, cols =
img.shape
crow,ccol = rows/2 , cols/2
fshift[crow-30:crow+30, ccol-30:ccol+30] = 0
f_ishift = np.fft.ifftshift(fshift)
img_back = np.fft.ifft2(f_ishift)
img_back = np.abs(img_back)
plt.subplot(131),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(132),plt.imshow(img_back, cmap =
'gray')
plt.title('Image after HPF'), plt.xticks([]),
plt.yticks([])
plt.subplot(133),plt.imshow(img_back)
plt.title('Result in JET'), plt.xticks([]),
plt.yticks([])
plt.show() |
НсЙћШчЯТЃК

ЩЯЭМЕФНсЙћЯдЪОИпЭЈТЫВЈЦфЪЕЪЧвЛжжБпНчМьВтВйзїЁЃетОЭЪЧЮвУЧдкЧАУцЭМЯёЬнЖШФЧвЛеТПДЕНЕФЁЃЭЌЪБЮвУЧЛЙЗЂЯжЭМЯёжаЕФДѓВПЗжЪ§ОнМЏжадкЦЕЦзЭМЕФЕЭЦЕЧјгђЁЃЮвУЧЯждквбОжЊЕРШчКЮЪЙгУ
Numpy Нјаа DFT КЭ IDFT СЫЃЌНгзХЮвУЧРДПДПДШчКЮЪЙгУ OpenCV НјааетаЉВйзїЁЃ
ШчЙћФуЙлВьзаЯИЕФЛАЃЌгШЦфЪЧзюКѓвЛеТ JET беЩЋЕФЭМЯёЃЌФуЛсПДЕНвЛаЉВЛздШЛЕФЖЋЮїЃЈШчЮвгУКьЩЋМ§ЭЗБъГіЕФЧјгђЃЉЁЃПДЩЯЭМФЧРягааЉЬѕДјзАЕФНсЙЙЃЌетБЛГЩЮЊеёСхаЇгІЁЃетЪЧгЩгкЮвУЧЪЙгУОиаЮДАПкзібкФЃдьГЩЕФЁЃетИібкФЃБЛзЊЛЛГЩе§ЯваЮзДЪБОЭЛсГіЯжетИіЮЪЬтЁЃЫљвдвЛАуЮвУЧВЛЪЪгУОиаЮДАПкТЫВЈЁЃзюКУЕФбЁдёЪЧИпЫЙДАПкЁЃ
23.1.2 OpenCV жаЕФИЕРявЖБфЛЛ
OpenCV жаЯргІЕФКЏЪ§ЪЧ cv2.dft() КЭ cv2.idft()ЁЃКЭЧАУцЪфГіЕФНсЙћвЛбљЃЌЕЋЪЧЪЧЫЋЭЈЕРЕФЁЃЕквЛИіЭЈЕРЪЧНсЙћЕФЪЕЪ§ВПЗжЃЌЕкЖўИіЭЈЕРЪЧНсЙћЕФащЪ§ВПЗжЁЃЪфШыЭМЯёвЊЪзЯШзЊЛЛГЩ
np.float32 ИёЪНЁЃЮвУЧРДПДПДШчКЮВйзїЁЃ
import numpy
as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('messi5.jpg',0)
dft = cv2.dft(np.float32(img),flags = cv2.DFT_COMPLEX_OUTPUT)
dft_shift = np.fft.fftshift(dft)
magnitude_spectrum = 20*np.log(cv2.magnitude(dft_shift[:,:,0],
dft_shift[:,:,1]))
plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(magnitude_spectrum,
cmap = 'gray')
plt.title('Magnitude Spectrum'), plt.xticks([]),
plt.yticks([])
plt.show() |
зЂвтЃКФуПЩвдЪЙгУКЏЪ§ cv2.cartToPolar()ЃЌЫќЛсЭЌЪБЗЕЛиЗљЖШКЭЯрЮЛЁЃ
ЯждкЮвУЧРДзіФц DFTЁЃдкЧАУцЕФВПЗжЮвУЧЪЕЯжСЫвЛИі HPFЃЈИпЭЈТЫВЈЃЉЃЌЯждкЮвУЧРДзі LPFЃЈЕЭЭЈТЫВЈЃЉНЋИпЦЕВПЗжШЅГ§ЁЃЦфЪЕОЭЪЧЖдЭМЯёНјааФЃК§ВйзїЁЃЪзЯШЮвУЧашвЊЙЙНЈвЛИібкФЃЃЌгыЕЭЦЕЧјгђЖдгІЕФЕиЗНЩшжУЮЊ
1, гыИпЦЕЧјгђЖдгІЕФЕиЗНЩшжУЮЊ 0ЁЃ
rows, cols =
img.shape
crow,ccol = rows/2 , cols/2
# create a mask first, center square is 1,
remaining all zeros
mask = np.zeros((rows,cols,2),np.uint8)
mask[crow-30:crow+30, ccol-30:ccol+30] = 1
# apply mask and inverse DFT
fshift = dft_shift*mask
f_ishift = np.fft.ifftshift(fshift)
img_back = cv2.idft(f_ishift)
img_back = cv2.magnitude(img_back[:,:,0],img_back[:,:,1])
plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(img_back, cmap =
'gray')
plt.title('Magnitude Spectrum'), plt.xticks([]),
plt.yticks([])
plt.show() |
НсЙћШчЯТЃК

зЂвтЃКOpenCV жаЕФКЏЪ§ cv2.dft() КЭ cv2.idft() вЊБШ Numpy ПьЁЃЕЋЪЧNumpy
КЏЪ§ИќМггУЛЇгбКУЁЃЙигкадФмЕФУшЪіЃЌЧыПДЯТУцЕФеТНкЁЃ
23.1.3 DFT ЕФадФмгХЛЏ
ЕБЪ§зщЕФДѓаЁЮЊФГаЉжЕЪБ DFT ЕФадФмЛсИќКУЁЃЕБЪ§зщЕФДѓаЁЪЧ 2
ЕФжИЪ§ЪБ DFT аЇТЪзюИпЁЃЕБЪ§зщЕФДѓаЁЪЧ 2ЃЌ3ЃЌ5 ЕФБЖЪ§ЪБаЇТЪвВЛсКмИпЁЃЫљвдШчЙћФуЯыЬсИпДњТыЕФдЫаааЇТЪЪБЃЌФуПЩвдаоИФЪфШыЭМЯёЕФДѓаЁЃЈВЙ
0ЃЉЁЃЖдгкOpenCV ФуБиаыздМКЪжЖЏВЙ 0ЁЃЕЋЪЧ NumpyЃЌФужЛашвЊжИЖЈ FFT дЫЫуЕФДѓаЁЃЌЫќЛсздЖЏВЙ
0ЁЃ
ФЧЮвУЧдѕбљШЗЖЈзюМбДѓаЁФиЃПOpenCV ЬсЙЉСЫвЛИіКЏЪ§:cv2.getOptimalDFTSize()ЁЃ
ЫќПЩвдЭЌЪББЛ cv2.dft() КЭ np.fft.fft2() ЪЙгУЁЃШУЮвУЧвЛЦ№ЪЙгУ IPythonЕФФЇЗЈУќСю%timeit
РДВтЪдвЛЯТАЩЁЃ
In [16]: img
= cv2.imread('messi5.jpg',0)
In [17]: rows,cols = img.shape
In [18]: print rows,cols
548
In [19]: nrows = cv2.getOptimalDFTSize(rows)
In [20]: ncols = cv2.getOptimalDFTSize(cols)
In [21]: print nrows, ncols
576 |
ПДЕНСЫАЩЃЌЪ§зщЕФДѓаЁДгЃЈ342ЃЌ548ЃЉБфГЩСЫЃЈ360ЃЌ576ЃЉЁЃЯждкЮвУЧЮЊЫќВЙ 0ЃЌШЛКѓПДПДадФмгаУЛгаЬсЩ§ЁЃФуПЩвдДДНЈвЛИіДѓЕФ
0 Ъ§зщЃЌШЛКѓАбЮвУЧЕФЪ§ОнПНБДЙ§ШЅЃЌЛђепЪЙгУКЏЪ§ cv2.copyMakeBoder()ЁЃ
nimg = np.zeros((nrows,ncols))
nimg[:rows,:cols] = img |
ЛђепЃК
right = ncols
- cols
bottom = nrows - rows
#just to avoid line breakup in PDF file
bordertype = cv2.BORDER_CONSTANT
nimg = cv2.copyMakeBorder(img,0,bottom,0,right,bordertype,
value = 0) |
ЯждкЮвУЧПДПД Numpy ЕФБэЯжЃК
In [22]: %timeit
fft1 = np.fft.fft2(img)
10 loops, best of 3: 40.9 ms per loop
In [23]: %timeit fft2 = np.fft.fft2(img,[nrows,ncols])
100 loops, best of 3: 10.4 ms per loop |
ЫйЖШЬсИпСЫ 4 БЖЁЃЮвУЧдйПДПД OpenCV ЕФБэЯжЃК
In [24]: %timeit
dft1= cv2.dft(np.float32(img),flags=cv2.DFT_COMPLEX_OUTPUT)
100 loops, best of 3: 13.5 ms per loop
In [27]: %timeit dft2= cv2.dft(np.float32(nimg),flags=cv2.DFT_COMPLEX_OUTPUT)
100 loops, best of 3: 3.11 ms per loop |
вВЬсИпСЫ 4 БЖЃЌЭЌЪБЮвУЧвВЛсЗЂЯж OpenCV ЕФЫйЖШЪЧ Numpy ЕФ 3 БЖЁЃ
ФувВПЩвдВтЪдвЛЯТФц FFT ЕФБэЯжЁЃ
23.1.4 ЮЊЪВУДРЦеРЫЙЫузгЪЧИпЭЈТЫВЈЦїЃП
ЮвдкТлЬГжагіЕНСЫвЛИіРрЫЦЕФЮЪЬтЁЃЮЊЪВУДРЦеРЫЙЫузгЪЧИпЭЈТЫВЈЦїЃП
ЮЊЪВУД Sobel ЪЧ HPFЃПЕШЕШЁЃЖдгкЕквЛИіЮЪЬтЕФД№АИЮвУЧвдИЕРявЖБфЛЛЕФаЮЪНИјГіЁЃЮвУЧвЛЦ№РДЖдВЛЭЌЕФЫузгНјааИЕРявЖБфЛЛВЂЗжЮіЫќУЧЃК
import cv2
import numpy as np
from matplotlib import pyplot as plt
# simple averaging filter without scaling parameter
mean_filter = np.ones((3,3))
# creating a guassian filter
x = cv2.getGaussianKernel(5,10)
#x.T ЮЊОиеѓзЊжУ
gaussian = x*x.T
# different edge detecting filters
# scharr in x-direction
scharr = np.array([[-3, 0, 3],
[-10,0,10],
[-3, 0, 3]])
# sobel in x direction
sobel_x= np.array([[-1, 0, 1],
[-2, 0, 2],
[-1, 0, 1]])
# sobel in y direction
sobel_y= np.array([[-1,-2,-1],
[0, 0, 0],
[1, 2, 1]])
# laplacian
laplacian=np.array([[0, 1, 0],
[1,-4, 1],
[0, 1, 0]])
filters = [mean_filter, gaussian, laplacian, sobel_x,
sobel_y, scharr]
filter_name = ['mean_filter', 'gaussian','laplacian',
'sobel_x', \
'sobel_y', 'scharr_x']
fft_filters = [np.fft.fft2(x) for x in filters]
fft_shift = [np.fft.fftshift(y) for y in fft_filters]
mag_spectrum = [np.log(np.abs(z)+1) for z in fft_shift]
for i in xrange(6):
plt.subplot(2,3,i+1),plt.imshow(mag_spectrum[i],cmap
= 'gray')
plt.title(filter_name[i]), plt.xticks([]), plt.yticks([])
plt.show() |
НсЙћЃК

ДгЭМЯёжаЮвУЧОЭПЩвдПДГіУПвЛИіЫузгдЪаэЭЈЙ§ФЧаЉаХКХЁЃДгетаЉаХЯЂжаЮв
УЧОЭПЩвджЊЕРФЧаЉЪЧ HPF ФЧЪЧ LPFЁЃ
ИќЖрзЪдД
1. An Intuitive Explanation of Fourier Theoryby Steven
Lehar
2. Fourier Transformat HIPR
3. What does frequency domain denote in case of images?
СЗЯА
24 ФЃАхЦЅХф
ФПБъ
дкБОНкЮвУЧвЊбЇЯАЃК
1. ЪЙгУФЃАхЦЅХфдквЛЗљЭМЯёжаВщевФПБъ
2. КЏЪ§ЃКcv2.matchTemplate()ЃЌcv2.minMaxLoc()
дРэ
ФЃАхЦЅХфЪЧгУРДдквЛИБДѓЭМжаЫббАВщевФЃАцЭМЯёЮЛжУЕФЗНЗЈЁЃOpenCV
ЮЊЮвУЧЬсЙЉСЫКЏЪ§ЃКcv2.matchTemplate()ЁЃКЭ 2D ОэЛ§вЛбљЃЌЫќвВЪЧгУФЃАхЭМЯёдкЪфШыЭМЯёЃЈДѓЭМЃЉЩЯЛЌЖЏЃЌВЂдкУПвЛИіЮЛжУЖдФЃАхЭМЯёКЭгыЦфЖдгІЕФЪфШыЭМЯёЕФзгЧјгђНјааБШНЯЁЃOpenCV
ЬсЙЉСЫМИжжВЛЭЌЕФБШНЯЗНЗЈЃЈЯИНкЧыПДЮФЕЕЃЉЁЃЗЕЛиЕФНсЙћЪЧвЛИіЛвЖШЭМЯёЃЌУПвЛИіЯёЫижЕБэЪОСЫДЫЧјгђгыФЃАхЕФЦЅХфГЬЖШЁЃ
ШчЙћЪфШыЭМЯёЕФДѓаЁЪЧЃЈWxHЃЉЃЌФЃАхЕФДѓаЁЪЧЃЈwxhЃЉЃЌЪфГіЕФНсЙћЕФДѓаЁОЭЪЧЃЈW-w+1ЃЌH-h+1ЃЉЁЃЕБФуЕУЕНетЗљЭМжЎКѓЃЌОЭПЩвдЪЙгУКЏЪ§cv2.minMaxLoc()
РДевЕНЦфжаЕФзюаЁжЕКЭзюДѓжЕЕФЮЛжУСЫЁЃЕквЛИіжЕЮЊОиаЮзѓЩЯНЧЕФЕуЃЈЮЛжУЃЉЃЌЃЈwЃЌhЃЉЮЊ moban ФЃАхОиаЮЕФПэКЭИпЁЃетИіОиаЮОЭЪЧевЕНЕФФЃАхЧјгђСЫЁЃ
зЂвтЃКШчЙћФуЪЙгУЕФБШНЯЗНЗЈЪЧ cv2.TM_SQDIFFЃЌзюаЁжЕЖдгІЕФЮЛжУВХЪЧЦЅХфЕФЧјгђЁЃ
24.1 OpenCV жаЕФФЃАхЦЅХф
ЮвУЧетРягавЛИіР§згЃКЮвУЧдкУЗЮїЕФееЦЌжаЫбЫїУЗЮїЕФУцВПЁЃЫљвдЮвУЧвЊжЦзїЯТУцетбљвЛИіФЃАхЃК

ЮвУЧЛсГЂЪдЪЙгУВЛЭЌЕФБШНЯЗНЗЈЃЌетбљЮвУЧОЭПЩвдБШНЯвЛЯТЫќУЧЕФаЇЙћСЫЁЃ
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('messi5.jpg',0)
img2 = img.copy()
template = cv2.imread('messi_face.jpg',0)
w, h = template.shape[::-1]
# All the 6 methods for comparison in a list
methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED',
'cv2.TM_CCORR',
'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']
for meth in methods:
img = img2.copy()
#exec гяОфгУРДжДааДЂДцдкзжЗћДЎЛђЮФМўжаЕФ Python гяОфЁЃ
# Р§ШчЃЌЮвУЧПЩвддкдЫааЪБЩњГЩвЛИіАќКЌ Python ДњТыЕФзжЗћДЎЃЌШЛКѓЪЙгУ exec гяОфжДааетаЉгяОфЁЃ
#eval гяОфгУРДМЦЫуДцДЂдкзжЗћДЎжаЕФгааЇ Python БэДяЪН
method = eval(meth)
# Apply template Matching
res = cv2.matchTemplate(img,template,method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# ЪЙгУВЛЭЌЕФБШНЯЗНЗЈЃЌЖдНсЙћЕФНтЪЭВЛЭЌ
# If the method is TM_SQDIFF or TM_SQDIFF_NORMED,
take minimum
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] +
h)
cv2.rectangle(img,top_left, bottom_right, 255,
2)
plt.subplot(121),plt.imshow(res,cmap = 'gray')
plt.title('Matching Result'), plt.xticks([]),
plt.yticks([])
plt.subplot(122),plt.imshow(img,cmap = 'gray')
plt.title('Detected Point'), plt.xticks([]), plt.yticks([])
plt.suptitle(meth)
plt.show() |
НсЙћШчЯТЃК






ЮвУЧПДЕН cv2.TM_CCORR ЕФаЇЙћВЛЯыЮвУЧЯыЕФФЧУДКУЁЃ
24.2 ЖрЖдЯѓЕФФЃАхЦЅХф
дкЧАУцЕФВПЗжЃЌЮвУЧдкЭМЦЌжаЫбЫиУЗЮїЕФСГЃЌЖјЧвУЗЮїжЛдкЭМЦЌжаГіЯжСЫвЛДЮЁЃМйШчФуЕФФПБъЖдЯѓжЛдкЭМЯёжаГіЯжСЫКмЖрДЮдѕУДАьФиЃПКЏЪ§cv.imMaxLoc()
жЛЛсИјГізюДѓжЕКЭзюаЁжЕЁЃДЫЪБЃЌЮвУЧОЭвЊЪЙгУуажЕСЫЁЃ
дкЯТУцЕФР§згжаЮвУЧвЊОЕфгЮЯЗ Mario ЕФвЛеХНиЦСЭМЦЌжаевЕНЦфжаЕФгВБвЁЃ
import cv2
import numpy as np
from matplotlib import pyplot as plt
img_rgb = cv2.imread('mario.png')
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
template = cv2.imread('mario_coin.png',0)
w, h = template.shape[::-1]
res = cv2.matchTemplate(img_gray,template,
cv2.TM_CCOEFF_NORMED)
threshold = 0.8
loc = np.where( res >= threshold)
for pt in zip(*loc[::-1]):
cv2.rectangle(img_rgb, pt, (pt[0] + w, pt[1]
+ h), (0,0,255), 2)
cv2.imwrite('res.png',img_rgb) |
НсЙћЃК
25 Hough жБЯпБфЛЛ
ФПБъ
РэНтЛєЗђБфЛЛЕФИХФю
бЇЯАШчКЮдквЛеХЭМЦЌжаМьВтжБЯп
бЇЯАКЏЪ§ЃКcv2.HoughLines()ЃЌcv2.HoughLinesP()
дРэ
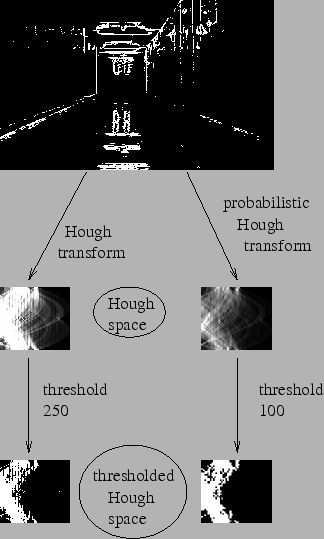
ЛєЗђБфЛЛдкМьВтИїжжаЮзДЕФЕФММЪѕжаЗЧГЃСїааЃЌШчЙћФувЊМьВтЕФаЮзДПЩвдгУЪ§бЇБэДяЪНаДГіЃЌФуОЭПЩвдЪЧЪЙгУЛєЗђБфЛЛМьВтЫќЁЃМАЪБвЊМьВтЕФаЮзДДцдквЛЕуЦЦЛЕЛђепХЄЧњвВПЩвдЪЙгУЁЃЮвУЧЯТУцОЭПДПДШчКЮЪЙгУЛєЗђБфЛЛМьВтжБЯпЁЃвЛЬѕжБЯпПЩвдгУЪ§бЇБэДяЪН
y = mx + c Лђеп Іб = xcosІШ + y sinІШ БэЪОЁЃ
Іб ЪЧДгдЕуЕНжБЯпЕФДЙжБОрРыЃЌІШ ЪЧжБЯпЕФДЙЯпгыКсжсЫГЪБеыЗНЯђЕФМаНЧЃЈШчЙћФуЪЙгУЕФзјБъЯЕВЛЭЌЗНЯђвВПЩФмВЛЭЌЃЌЮвЪЧАД
OpenCV ЪЙгУЕФзјБъЯЕУшЪіЕФЃЉЁЃШчЯТЭМЫљЪОЃК
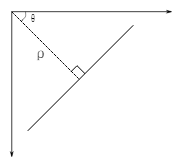
ЫљвдШчЙћвЛЬѕЯпдкдЕуЯТЗНОЙ§ЃЌІб ЕФжЕОЭгІИУДѓгк 0ЃЌНЧЖШаЁгк 180ЁЃЕЋЪЧШчЙћДгдЕуЩЯЗНОЙ§ЕФЛАЃЌНЧЖШВЛЪЧДѓгк
180ЃЌвВЪЧаЁгк 180ЃЌЕЋ Іб ЕФжЕаЁгк 0ЁЃДЙжБЕФЯпНЧЖШЮЊ 0 ЖШЃЌЫЎЦНЯпЕФНЧЖШЮЊ 90 ЖШЁЃШУЮвУЧРДПДПДЛєЗђБфЛЛЪЧШчКЮЙЄзїЕФЁЃУПвЛЬѕжБЯпЖМПЩвдгУ
(Іб,ІШ) БэЪОЁЃ
ЫљвдЪзЯШДДНЈвЛИі 2D Ъ§зщЃЈРлМгЦїЃЉЃЌГѕЪМЛЏРлМгЦїЃЌЫљгаЕФжЕЖМЮЊ 0ЁЃааБэЪО ІбЃЌСаБэЪО ІШЁЃетИіЪ§зщЕФДѓаЁОіЖЈСЫзюКѓНсЙћЕФзМШЗадЁЃШчЙћФуЯЃЭћНЧЖШОЋШЗЕН
1 ЖШЃЌФуОЭашвЊ 180 СаЁЃЖдгк ІбЃЌзюДѓжЕЮЊЭМЦЌЖдНЧЯпЕФОрРыЁЃЫљвдШчЙћОЋШЗЖШвЊДяЕНвЛИіЯёЫиЕФМЖБ№ЃЌааЪ§ОЭгІИУгыЭМЯёЖдНЧЯпЕФОрРыЯрЕШЁЃ
ЯыЯѓвЛЯТЮвУЧгавЛИіДѓаЁЮЊ 100x100 ЕФжБЯпЮЛгкЭМЯёЕФжабыЁЃШЁжБЯпЩЯЕФЕквЛИіЕуЃЌЮвУЧжЊЕРДЫДІЕФЃЈxЃЌyЃЉжЕЁЃАб
x КЭ y ДјШыЩЯБпЕФЗНГЬзщЃЌШЛКѓБщРњ ІШ ЕФШЁжЕЃК0ЃЌ1ЃЌ2ЃЌ3ЃЌ...ЃЌ180ЁЃЗжБ№ЧѓГігыЦфЖдгІЕФ
Іб ЕФжЕЃЌетбљЮвУЧОЭЕУЕНвЛЯЕСаЃЈІб,ІШЃЉЕФЪ§жЕЖдЃЌШчЙћетИіЪ§жЕЖддкРлМгЦїжавВДцдкЯргІЕФЮЛжУЃЌОЭдкетИіЮЛжУЩЯМг
1ЁЃЫљвдЯждкРлМгЦїжаЕФЃЈ50ЃЌ90ЃЉ=1ЁЃЃЈвЛИіЕуПЩФмДцдкгыЖрЬѕжБЯпжаЃЌЫљвдЖдгкжБЯпЩЯЕФУПвЛИіЕуПЩФмЪЧРлМгЦїжаЕФЖрИіжЕЭЌЪБМг
1ЃЉЁЃ
ЯждкШЁжБЯпЩЯЕФЕкЖўИіЕуЁЃжиИДЩЯБпЕФЙ§ГЬЁЃИќаТРлМгЦїжаЕФжЕЁЃЯждкРлМгЦїжаЃЈ50,90ЃЉЕФжЕЮЊ 2ЁЃФуУПДЮзіЕФОЭЪЧИќаТРлМгЦїжаЕФжЕЁЃЖджБЯпЩЯЕФУПИіЕуЖМжДааЩЯБпЕФВйзїЃЌУПДЮВйзїЭъГЩжЎКѓЃЌРлМгЦїжаЕФжЕОЭМг
1ЃЌЕЋЦфЫћЕиЗНгаЪБЛсМг 1, гаЪБВЛЛсЁЃАДееетжжЗНЪНЯТШЅЃЌЕНзюКѓРлМгЦїжаЃЈ50,90ЃЉЕФжЕПЯЖЈЪЧзюДѓЕФЁЃШчЙћФуЫбЫїРлМгЦїжаЕФзюДѓжЕЃЌВЂевЕНЦфЮЛжУЃЈ50,90ЃЉЃЌетОЭЫЕУїЭМЯёжагавЛЬѕжБЯпЃЌетЬѕжБЯпЕНдЕуЕФОрРыЮЊ
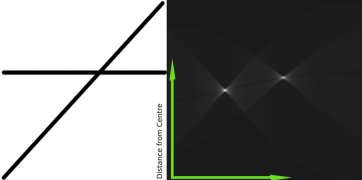
50ЃЌЫќЕФДЙЯпгыКсжсЕФМаНЧЮЊ 90 ЖШЁЃЯТУцЕФЖЏЛКмКУЕФбнЪОСЫетИіЙ§ГЬЃЈImage Courtesy:
AmosStorkey ЃЉЁЃ
етОЭЪЧЛєЗђжБЯпБфЛЛЙЄзїЕФЗНЪНЁЃКмМђЕЅЃЌвВаэФуздМКОЭПЩвдЪЙгУ NumpyИуЖЈЫќЁЃЯТЭМЯдЪОСЫвЛИіРлМгЦїЁЃЦфжазюССЕФСНИіЕуДњБэСЫЭМЯёжаСНЬѕжБЯпЕФВЮЪ§ЁЃЃЈImage
courtesy: WikipediaЃЉЁЃ
25.1 OpenCV жаЕФЛєЗђБфЛЛ
ЩЯУцНщЩмЕФећИіЙ§ГЬдк OpenCV жаЖМБЛЗтзАНјСЫвЛИіКЏЪ§ЃКcv2.HoughLines()ЁЃ
ЗЕЛижЕОЭЪЧЃЈІб,ІШЃЉЁЃІб ЕФЕЅЮЛЪЧЯёЫиЃЌІШ ЕФЕЅЮЛЪЧЛЁЖШЁЃетИіКЏЪ§ЕФЕквЛИіВЮЪ§ЪЧвЛИіЖўжЕЛЏЭМЯёЃЌЫљвддкНјааЛєЗђБфЛЛжЎЧАвЊЪзЯШНјааЖўжЕЛЏЃЌЛђепНјааCanny
БпдЕМьВтЁЃЕкЖўКЭЕкШ§ИіжЕЗжБ№ДњБэ Іб КЭ ІШ ЕФОЋШЗЖШЁЃЕкЫФИіВЮЪ§ЪЧуажЕЃЌжЛгаРлМгЦфжаЕФжЕИпгкуажЕЪБВХБЛШЯЮЊЪЧвЛЬѕжБЯпЃЌвВПЩвдАбЫќПДГЩФмМьВтЕНЕФжБЯпЕФзюЖЬГЄЖШЃЈвдЯёЫиЕуЮЊЕЅЮЛЃЉЁЃ
import cv2
import numpy as np
img = cv2.imread('dave.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray,50,150,apertureSize =
3)
lines = cv2.HoughLines(edges,1,np.pi/180,200)
for rho,theta in lines[0]:
a = np.cos(theta)
b = np.sin(theta)
x0 = a*rho
y0 = b*rho
x1 = int(x0 + 1000*(-b))
y1 = int(y0 + 1000*(a))
x2 = int(x0 - 1000*(-b))
y2 = int(y0 - 1000*(a))
cv2.line(img,(x1,y1),(x2,y2),(0,0,255),2)
cv2.imwrite('houghlines3.jpg',img) |
НсЙћШчЯТЃК
25.2 Probabilistic Hough Transform
ДгЩЯБпЕФЙ§ГЬЮвУЧПЩвдЗЂЯжЃКНіНіЪЧвЛЬѕжБЯпЖМашвЊСНИіВЮЪ§ЃЌеташвЊДѓСПЕФМЦЫуЁЃProbabilistic_Hough_Transform
ЪЧЖдЛєЗђБфЛЛЕФвЛжжгХЛЏЁЃЫќВЛЛсЖдУПвЛИіЕуЖМНјааМЦЫуЃЌЖјЪЧДгвЛЗљЭМЯёжаЫцЛњбЁШЁЃЈЪЧВЛЪЧвВПЩвдЪЙгУЭМЯёН№зжЫўФиЃПЃЉвЛИіЕуМЏНјааМЦЫуЃЌЖдгкжБЯпМьВтРДЫЕетвбОзуЙЛСЫЁЃЕЋЪЧЪЙгУетжжБфЛЛЮвУЧБиаывЊНЕЕЭуажЕЃЈзмЕФЕуЪ§ЖМЩйСЫЃЌуажЕПЯЖЈвВвЊаЁбНЃЁЃЉЁЃ
ЯТЭМЪЧЖдСНжжЗНЗЈЕФЖдБШЁЃЃЈImage Courtesy : Franck BettingerЁЏs homepageЃЉ
OpenCV жаЪЙгУЕФ Matas, J. ЃЌGalambos, C. КЭ Kittler, J.V.
ЬсГіЕФProgressive Probabilistic Hough TransformЁЃетИіКЏЪ§ЪЧ
cv2.HoughLinesP()ЁЃ
ЫќгаСНИіВЮЪ§ЁЃ
1.minLineLength - ЯпЕФзюЖЬГЄЖШЁЃБШетИіЖЬЕФЯпЖМЛсБЛКіТдЁЃ
2.MaxLineGap - СНЬѕЯпЖЮжЎМфЕФзюДѓМфИєЃЌШчЙћаЁгкДЫжЕЃЌетСНЬѕжБЯпОЭБЛПДГЩЪЧвЛЬѕжБЯпЁЃ
ИќМгИјСІЕФЪЧЃЌетИіКЏЪ§ЕФЗЕЛижЕОЭЪЧжБЯпЕФЦ№ЕуКЭжеЕуЁЃЖјдкЧАУцЕФР§згжаЃЌЮвУЧжЛЕУЕНСЫжБЯпЕФВЮЪ§ЃЌЖјЧвФуБиаывЊевЕНЫљгаЕФжБЯпЁЃЖјдкетРявЛЧаЖМКмжБНгКмМђЕЅЁЃ
import cv2
import numpy as np
img = cv2.imread('dave.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray,50,150,apertureSize =
3)
minLineLength = 100
maxLineGap = 10
lines = cv2.HoughLinesP(edges,1,np.pi/180,100,
minLineLength,maxLineGap)
for x1,y1,x2,y2 in lines[0]:
cv2.line(img,(x1,y1),(x2,y2),(0,255,0),2)
cv2.imwrite('houghlines5.jpg',img) |
НсЙћШчЯТЃК

26 Hough дВЛЗБфЛЛ
ФПБъ
1.бЇЯАЪЙгУЛєЗђБфЛЛдкЭМЯёжаевдВаЮЃЈЛЗЃЉЁЃ
2.бЇЯАКЏЪ§ЃКcv2.HoughCircles()ЁЃ
дРэ
дВаЮЕФЪ§бЇБэДяЪНЮЊ (x ? x center ) 2 +(y ?
y center ) 2 = r 2 ЃЌЦфжаЃЈx center ,y center ЃЉЮЊдВаФЕФзјБъЃЌr
ЮЊдВЕФжБОЖЁЃДгетИіЕШЪНжаЮвУЧПЩвдПДГіЃКвЛИідВЛЗашвЊ 3ИіВЮЪ§РДШЗЖЈЁЃЫљвдНјаадВЛЗЛєЗђБфЛЛЕФРлМгЦїБиаыЪЧ
3 ЮЌЕФЃЌетбљЕФЛАаЇТЪОЭЛсКмЕЭЁЃЫљвд OpenCV гУРДвЛИіБШНЯЧЩУюЕФАьЗЈЃЌЛєЗђЬнЖШЗЈЃЌЫќПЩвдЪЙгУБпНчЕФЬнЖШаХЯЂЁЃ
ЮвУЧвЊЪЙгУЕФКЏЪ§ЮЊ cv2.HoughCircles()ЁЃЮФЕЕжаЖдЫќЕФВЮЪ§гаЯъЯИЕФНтЪЭЁЃетРяЮвУЧОЭжБНгПДДњТыАЩЁЃ
import cv2
import numpy as np
img = cv2.imread('opencv_logo.png',0)
img = cv2.medianBlur(img,5)
cimg = cv2.cvtColor(img,cv2.COLOR_GRAY2BGR)
circles = cv2.HoughCircles(img,cv2.HOUGH_GRADIENT,1,20,
param1=50,param2=30,minRadius=0,maxRadius=0)
circles = np.uint16(np.around(circles))
for i in circles[0,:]:
# draw the outer circle
cv2.circle(cimg,(i[0],i[1]),i[2],(0,255,0),2)
# draw the center of the circle
cv2.circle(cimg,(i[0],i[1]),2,(0,0,255),3)
cv2.imshow('detected circles',cimg)
cv2.waitKey(0)
cv2.destroyAllWindows()
#Python: cv2.HoughCircles(image, method, dp, minDist,
circles, param1, param2, minRadius, maxRadius)
#Parameters:
#image ЈC 8-bit, single-channel, grayscale input
image.
# ЗЕЛиНсЙћЮЊ Output vector of found circles. Each vector
is encoded as a
#3-element floating-point vector (x, y, radius)
.
#circle_storage ЈC In C function this is a memory
storage that will contain
#the output sequence of found circles.
#method ЈC Detection method to use. Currently,
the only implemented method is
#CV_HOUGH_GRADIENT , which is basically 21HT ,
described in [Yuen90].
#dp ЈC Inverse ratio of the accumulator resolution
to the image resolution.
#For example, if dp=1 , the accumulator has the
same resolution as the input image.
#If dp=2 , the accumulator has half as big width
and height.
#minDist ЈC Minimum distance between the centers
of the detected circles.
#If the parameter is too small, multiple neighbor
circles may be falsely
#detected in addition to a true one. If it is
too large, some circles may be missed.
#param1 ЈC First method-specific parameter. In
case of CV_HOUGH_GRADIENT ,
#it is the higher threshold of the two passed
to the Canny() edge detector
# (the lower one is twice smaller).
#param2 ЈC Second method-specific parameter. In
case of CV_HOUGH_GRADIENT ,
# it is the accumulator threshold for the circle
centers at the detection stage.
#The smaller it is, the more false circles may
be detected. Circles,
# corresponding to the larger accumulator values,
will be returned first.
#minRadius ЈC Minimum circle radius.
#maxRadius ЈC Maximum circle radius. |
НсЙћШчЯТЃК

ИќЖрзЪдД
СЗЯА
27 ЗжЫЎСыЫуЗЈЭМЯёЗжИю
ФПБъ
БОНкЮвУЧНЋвЊбЇЯА
1.ЪЙгУЗжЫЎСыЫуЗЈЛљгкбкФЃЕФЭМЯёЗжИю
2.КЏЪ§ЃКcv2.watershed()
дРэ
ШЮКЮвЛИБЛвЖШЭМЯёЖМПЩвдБЛПДГЩЭиЦЫЦНУцЃЌЛвЖШжЕИпЕФЧјгђПЩвдБЛПДГЩЪЧЩНЗхЃЌЛвЖШжЕЕЭЕФЧјгђПЩвдБЛПДГЩЪЧЩНЙШЁЃЮвУЧЯђУПвЛИіЩНЙШжаЙрВЛЭЌбеЩЋЕФЫЎЁЃЫцзХЫЎЕФЮЛЕФЩ§ИпЃЌВЛЭЌЩНЙШЕФЫЎОЭЛсЯргіЛуКЯЃЌЮЊСЫЗРжЙВЛЭЌЩНЙШЕФЫЎЛуКЯЃЌЮвУЧашвЊдкЫЎЛуКЯЕФЕиЗНЙЙНЈЦ№ЕЬАгЁЃВЛЭЃЕФЙрЫЎЃЌВЛЭЃЕФЙЙНЈЕЬАгжЊЕРЫљгаЕФЩНЗхЖМБЛЫЎбЭУЛЁЃЮвУЧЙЙНЈКУЕФЕЬАгОЭЪЧЖдЭМЯёЕФЗжИюЁЃетОЭЪЧЗжЫЎСыЫуЗЈЕФБГКѓемРэЁЃФуПЩвдЭЈЙ§ЗУЮЪЭјеОCMM
webpage on watershedРДМгЩюздМКЕФРэНтЁЃ
ЕЋЪЧетжжЗНЗЈЭЈГЃЖМЛсЕУЕНЙ§ЖШЗжИюЕФНсЙћЃЌетЪЧгЩдыЩљЛђепЭМЯёжаЦфЫћВЛЙцТЩЕФвђЫидьГЩЕФЁЃЮЊСЫМѕЩйетжжгАЯьЃЌOpenCV
ВЩгУСЫЛљгкбкФЃЕФЗжЫЎСыЫуЗЈЃЌдкетжжЫуЗЈжаЮвУЧвЊЩшжУФЧаЉЩНЙШЕуЛсЛуКЯЃЌФЧаЉВЛЛсЁЃетЪЧвЛжжНЛЛЅЪНЕФЭМЯёЗжИюЁЃЮвУЧвЊзіЕФОЭЪЧИјЮвУЧвбжЊЕФЖдЯѓДђЩЯВЛЭЌЕФБъЧЉЁЃШчЙћФГИіЧјгђПЯЖЈЪЧЧАОАЛђЖдЯѓЃЌОЭЪЙгУФГИібеЩЋЃЈЛђЛвЖШжЕЃЉБъЧЉБъМЧЫќЁЃШчЙћФГИіЧјгђПЯЖЈВЛЪЧЖдЯѓЖјЪЧБГОАОЭЪЙгУСэЭтвЛИібеЩЋБъЧЉБъМЧЁЃЖјЪЃЯТЕФВЛФмШЗЖЈЪЧЧАОАЛЙЪЧБГОАЕФЧјгђОЭгУ
0 БъМЧЁЃетОЭЪЧЮвУЧЕФБъЧЉЁЃШЛКѓЪЕЪЉЗжЫЎСыЫуЗЈЁЃУПвЛДЮЙрЫЎЃЌЮвУЧЕФБъЧЉОЭЛсБЛИќаТЃЌЕБСНИіВЛЭЌбеЩЋЕФБъЧЉЯргіЪБОЭЙЙНЈЕЬАгЃЌжБЕННЋЫљгаЩНЗхбЭУЛЃЌзюКѓЮвУЧЕУЕНЕФБпНчЖдЯѓЃЈЕЬАгЃЉЕФжЕЮЊ
-1ЁЃ
27.1 ДњТы
ЯТУцЕФР§згжаЮвУЧНЋОЭКЭОрРыБфЛЛКЭЗжЫЎСыЫуЗЈЖдНєАЄдквЛЦ№ЕФЖдЯѓНјааЗжИюЁЃ
ШчЯТЭМЫљЪОЃЌетаЉгВБвНєАЄдквЛЦ№ЁЃОЭЫуФуЪЙгУуажЕВйзїЃЌЫќУЧШЮШЛЪЧНєАЄзХЕФЁЃ

ЮвУЧДгевЕНгВБвЕФНќЫЦЙРМЦПЊЪМЁЃЮвУЧПЩвдЪЙгУ Otsu's ЖўжЕЛЏЁЃ
import numpy
as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('coins.png')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray,0,255,cv2.
THRESH_BINARY_INV+cv2.THRESH_OTSU) |
НсЙћ

ЯждкЮвУЧвЊШЅГ§ЭМЯёжаЕФЫљгаЕФАздыЩљЁЃетОЭашвЊЪЙгУаЮЬЌбЇжаЕФПЊдЫЫуЁЃ
ЮЊСЫШЅГ§ЖдЯѓЩЯаЁЕФПеЖДЮвУЧашвЊЪЙгУаЮЬЌбЇБедЫЫуЁЃЫљвдЮвУЧЯждкжЊЕРППНќЖдЯѓжааФЕФЧјгђПЯЖЈЪЧЧАОАЃЌЖјдЖРыЖдЯѓжааФЕФЧјгђПЯЖЈЪЧБГОАЁЃЖјВЛФмШЗЖЈЕФЧјгђОЭЪЧгВБвжЎМфЕФБпНчЁЃ
ЫљвдЮвУЧвЊЬсШЁПЯЖЈЪЧгВБвЕФЧјгђЁЃИЏЪДВйзїПЩвдШЅГ§БпдЕЯёЫиЁЃЪЃЯТОЭПЩвдПЯЖЈЪЧгВБвСЫЁЃЕБгВБвжЎМфУЛгаНгДЅЪБЃЌетжжВйзїЪЧгааЇЕФЁЃЕЋЪЧгЩгкгВБвжЎМфЪЧЯрЛЅНгДЅЕФЃЌЮвУЧОЭгаСЫСэЭтвЛИіИќКУЕФбЁдёЃКОрРыБфЛЛдйМгЩЯКЯЪЪЕФуажЕЁЃНгЯТРДЮвУЧвЊевЕНПЯЖЈВЛЪЧгВБвЕФЧјгђЁЃетЪЧОЭашвЊНјааХђеЭВйзїСЫЁЃХђеЭПЩвдНЋЖдЯѓЕФБпНчбгЩьЕНБГОАжаШЅЁЃетбљгЩгкБпНчЧјгђБЛШЅДІРэЃЌЮвУЧОЭПЩвджЊЕРФЧаЉЧјгђПЯЖЈЪЧЧАОАЃЌФЧаЉПЯЖЈЪЧБГОАЁЃШчЯТЭМЫљЪОЁЃ
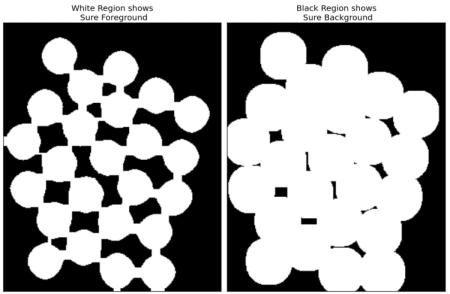
ЪЃЯТЕФЧјгђОЭЪЧЮвУЧВЛжЊЕРИУШчКЮЧјЗжЕФСЫЁЃетОЭЪЧЗжЫЎСыЫуЗЈвЊзіЕФЁЃ
етаЉЧјгђЭЈГЃЪЧЧАОАгыБГОАЕФНЛНчДІЃЈЛђепСНИіЧАОАЕФНЛНчЃЉЁЃЮвУЧГЦжЎЮЊБпНчЁЃДгПЯЖЈЪЧВЛЪЧБГОАЕФЧјгђжаМѕШЅПЯЖЈЪЧЧАОАЕФЧјгђОЭЕУЕНСЫБпНчЧјгђЁЃ
# noise removal
kernel = np.ones((3,3),np.uint8)
opening = cv2.morphologyEx(thresh,cv2.MORPH_OPEN,kernel,
iterations = 2)
# sure background area
sure_bg = cv2.dilate(opening,kernel,iterations=3)
# Finding sure foreground area
# ОрРыБфЛЛЕФЛљБОКЌвхЪЧМЦЫувЛИіЭМЯёжаЗЧ
СуЯёЫиЕуЕНзюНќЕФСуЯёЫиЕуЕФОрРыЃЌвВОЭЪЧ
ЕНСуЯёЫиЕуЕФзюЖЬОрРы
# ИізюГЃМћЕФОрРыБфЛЛЫуЗЈОЭЪЧЭЈЙ§СЌајЕФ
ИЏЪДВйзїРДЪЕЯжЃЌИЏЪДВйзїЕФЭЃжЙЬѕМўЪЧЫљ
гаЧАОАЯёЫиЖМБЛЭъШЋ
# ИЏЪДЁЃетбљИљОнИЏЪДЕФЯШКѓЫГађЃЌЮвУЧОЭ
ЕУЕНИїИіЧАОАЯёЫиЕуЕНЧАОАжааФ??ЯёЫиЕуЕФ
# ОрРыЁЃИљОнИїИіЯёЫиЕуЕФОрРыжЕЃЌЩшжУЮЊ
ВЛЭЌЕФЛвЖШжЕЁЃетбљОЭЭъГЩСЫЖўжЕЭМЯёЕФОрРыБфЛЛ
#cv2.distanceTransform(src, distanceType, maskSize)
# ЕкЖўИіВЮЪ§ 0,1,2 ЗжБ№БэЪО CV_DIST_L1, CV_DIST_L2 , CV_DIST_C
dist_transform = cv2.distanceTransform(opening,1,5)
ret, sure_fg = cv2.threshold(dist_transform,0.7*dist_transform.
max(),255,0)
# Finding unknown region
sure_fg = np.uint8(sure_fg)
unknown = cv2.subtract(sure_bg,sure_fg) |
ШчНсЙћЫљЪОЃЌдкуажЕЛЏжЎКѓЕФЭМЯёжаЃЌЮвУЧЕУЕНСЫПЯЖЈЪЧгВБвЕФЧјгђЃЌЖјЧвгВБвжЎМфвВБЛЗжИюПЊСЫЁЃЃЈгааЉЧщПіЯТФуПЩФмжЛашвЊЖдЧАОАНјааЗжИюЃЌЖјВЛашвЊНЋНєАЄдквЛЦ№ЕФЖдЯѓЗжПЊЃЌДЫЪБОЭУЛгаБивЊЪЙгУОрРыБфЛЛСЫЃЌИЏЪДОЭзуЙЛСЫЁЃЕБШЛИЏЪДвВПЩвдгУРДЬсШЁПЯЖЈЪЧЧАОАЕФЧјгђЁЃЃЉ

ЯждкжЊЕРСЫФЧаЉЪЧБГОАФЧаЉЪЧгВБвСЫЁЃФЧЮвУЧОЭПЩвдДДНЈБъЧЉЃЈвЛИігыдЭМЯёДѓаЁЯрЭЌЃЌЪ§ОнРраЭЮЊ in32
ЕФЪ§зщЃЉЃЌВЂБъМЧЦфжаЕФЧјгђСЫЁЃЖдЮвУЧвбОШЗЖЈЗжРрЕФЧјгђЃЈЮоТлЪЧЧАОАЛЙЪЧБГОАЃЉЪЙгУВЛЭЌЕФе§ећЪ§БъМЧЃЌЖдЮвУЧВЛШЗЖЈЕФЧјгђЪЙгУ
0 БъМЧЁЃЮвУЧПЩвдЪЙгУКЏЪ§ cv2.connectedComponents()РДзіетМўЪТЁЃЫќЛсАбНЋБГОАБъМЧЮЊ
0ЃЌЦфЫћЕФЖдЯѓЪЙгУДг 1 ПЊЪМЕФе§ећЪ§БъМЧЁЃ
ЕЋЪЧЃЌЮвУЧжЊЕРШчЙћБГОАБъМЧЮЊ 0ЃЌФЧЗжЫЎСыЫуЗЈОЭЛсАбЫќЕБГЩЮДжЊЧјгђСЫЁЃЫљвдЮвУЧЯыЪЙгУВЛЭЌЕФећЪ§БъМЧЫќУЧЁЃЖјЖдВЛШЗЖЈЕФЧјгђЃЈКЏЪ§cv2.connectedComponents
ЪфГіЕФНсЙћжаЪЙгУ unknown ЖЈвхЮДжЊЧјгђЃЉБъМЧЮЊ 0ЁЃ
# Marker labelling
ret, markers1 = cv2.connectedComponents(sure_fg)
# Add one to all labels so that sure background
is not 0, but 1
markers = markers1+1
# Now, mark the region of unknown with zero
markers[unknown==255] = 0
|
НсЙћЪЙгУ JET беЩЋЕиЭМБэЪОЁЃЩюРЖЩЋЧјгђЮЊЮДжЊЧјгђЁЃПЯЖЈЪЧгВБвЕФЧјгђЪЙгУВЛЭЌЕФбеЩЋБъМЧЁЃЦфгрЧјгђОЭЪЧгУЧГРЖЩЋБъМЧЕФБГОАСЫЁЃ
ЯждкБъЧЉзМБИКУСЫЁЃЕНзюКѓвЛВНЃКЪЕЪЉЗжЫЎСыЫуЗЈСЫЁЃБъЧЉЭМЯёНЋЛсБЛаоИФЃЌБпНчЧјгђЕФБъМЧНЋБфЮЊ -1.
markers3 = cv2.watershed(img,markers)
img[markers3 == -1] = [255,0,0] |
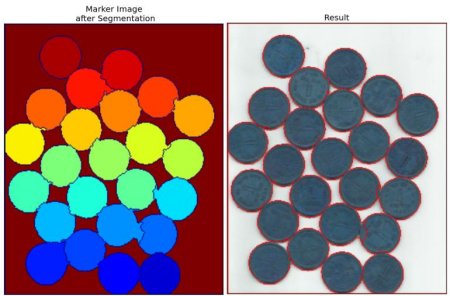
НсЙћШчЯТЁЃгааЉгВБвЕФБпНчБЛЗжИюЕФКмКУЃЌвВгавЛаЉгВБвжЎМфЕФБпНчЗжИюЕФВЛКУЁЃ

Now our marker is ready. It is time
for final step, apply watershed . Then marker image
will be modified . The boundary region will be marked
with -1.
markers = cv2.watershed(img,markers)
img[markers == -1] = [255,0,0] |
See the result below. For some coins,
the region where they touch are segmented properly
and for some, they are not.
СЗЯА
1. OpenCV здДјЕФЪОР§жагавЛИіНЛЛЅЪНЗжЫЎСыЗжИюГЬађЃКwatershed.pyЁЃ
здМКЭцЭцАЩЁЃ
28 ЪЙгУ GrabCut ЫуЗЈНјааНЛЛЅЪНЧАОАЬсШЁ
ФПБъ
дкБОНкжаЮвУЧНЋвЊбЇЯАЃК
1.GrabCut ЫуЗЈдРэЃЌЪЙгУ GrabCut ЫуЗЈЬсШЁЭМЯёЕФЧАОА
2. ДДНЈвЛИіНЛЛЅЪЧГЬађЭъГЩЧАОАЬсШЁ
дРэ
GrabCut ЫуЗЈЪЧгЩЮЂШэНЃЧХбаОПдКЕФ Carsten_RotherЃЌVladimir_KolmogorovКЭ
Andrew_Blake дкЮФеТЁЖGrabCutЁБ: interactive foreground
extraction using iterated graph cutsЁЗжаЙВЭЌЬсГіЕФЁЃДЫЫуЗЈдкЬсШЁЧАОАЕФВйзїЙ§ГЬжаашвЊКмЩйЕФШЫЛњНЛЛЅЃЌНсЙћЗЧГЃКУЁЃ
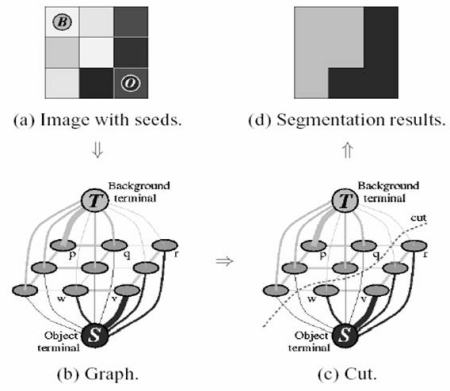
ДггУЛЇЕФНЧЖШРДПДЫќЕНЕзЪЧШчКЮЙЄзїЕФФиЃППЊЪМЪБгУЛЇашвЊгУвЛИіОиаЮНЋЧАОАЧјгђПђзЁЃЈЧАОАЧјгђгІИУЭъШЋБЛАќРЈдкОиаЮПђФкВПЃЉЁЃШЛКѓЫуЗЈНјааЕќДњЪНЗжИюжБДяДяЕНзюКУНсЙћЁЃЕЋЪЧгаЪБЗжИюЕФНсЙћВЛЙЛРэЯыЃЌБШШчАбЧАОАЕБГЩСЫБГОАЃЌЛђепАбБГОАЕБГЩСЫЧАОАЁЃдкетжжЧщПіЯТЃЌОЭашвЊгУЛЇРДНјаааоИФСЫЁЃгУЛЇжЛашвЊдкВЛРэЯыЕФВПЮЛЛвЛБЪЃЈЕувЛЯТЪѓБъЃЉОЭПЩвдСЫЁЃЛвЛБЪОЭЕШгкдкИцЫпМЦЫуЛњЃКЁАрЫЃЌРЯажЃЌФуАбетРяХЊЗДСЫЃЌЯТДЮЕќДњЕФЪБКђМЧЕУИФЙ§РДбНЃЁЁБЁЃШЛКѓЃЌдкЯТвЛТжЕќДњЕФЪБКђФуОЭЛсЕУЕНвЛИіИќКУЕФНсЙћСЫЁЃ
ШчЯТЭМЫљЪОЁЃдЫЖЏдБКЭзуЧђБЛРЖЩЋОиаЮАќЮЇдквЛЦ№ЁЃЦфжагаЮвзіЕФМИИіаое§ЃЌАзЩЋЛБЪБэУїетРяЪЧЧАОАЃЌКкЩЋЛБЪБэУїетРяЪЧБГОАЁЃзюКѓЮвЕУЕНСЫвЛИіКмКУЕФНсЙћЁЃ

дкећИіЙ§ГЬжаЕНЕзЗЂЩњСЫЪВУДФиЃП
1.гУЛЇЪфШывЛИіОиаЮЁЃОиаЮЭтЕФЫљгаЧјгђПЯЖЈЖМЪЧБГОАЃЈЮвУЧдкЧАУцвбОЬсЕНЃЌЫљгаЕФЖдЯѓЖМвЊАќКЌдкОиаЮПђФкЃЉЁЃОиаЮПђФкЕФЖЋЮїЪЧЮДжЊЕФЁЃЭЌбљгУЛЇШЗЖЈЧАОАКЭБГОАЕФШЮКЮВйзїЖМВЛЛсБЛГЬађИФБфЁЃ
2.МЦЫуЛњЛсЖдЮвУЧЕФЪфШыЭМЯёзівЛИіГѕЪМЛЏБъМЧЁЃЫќЛсБъМЧЧАОАКЭБГОАЯёЫиЁЃ
3.ЪЙгУвЛИіИпЫЙЛьКЯФЃаЭЃЈGMMЃЉЖдЧАОАКЭБГОАНЈФЃЁЃ
4.ИљОнЮвУЧЕФЪфШыЃЌGMM ЛсбЇЯАВЂДДНЈаТЕФЯёЫиЗжВМЁЃЖдФЧаЉЗжРрЮДжЊЕФЯёЫиЃЈПЩФмЪЧЧАОАвВПЩФмЪЧБГОАЃЉЃЌПЩвдИљОнЫќУЧгывбжЊЗжРрЃЈШчБГОАЃЉЕФЯёЫиЕФЙиЯЕРДНјааЗжРрЃЈОЭЯёЪЧдкзіОлРрВйзїЃЉЁЃ
5.етбљОЭЛсИљОнЯёЫиЕФЗжВМДДНЈвЛИБЭМЁЃЭМжаЕФНкЕуОЭЪЧЯёЫиЕуЁЃГ§СЫЯёЫиЕузіНкЕужЎЭтЛЙгаСНИіНкЕуЃКSource_node
КЭ Sink_nodeЁЃЫљгаЕФЧАОАЯёЫиЖМКЭ Source_node ЯрСЌЁЃЫљгаЕФБГОАЯёЫиЖМКЭ Sink_node
ЯрСЌЁЃ
6.НЋЯёЫиСЌНгЕН Source_node/end_node ЕФЃЈБпЃЉЕФШЈжигЩЫќУЧЪєгкЭЌвЛРрЃЈЭЌЪЧЧАОАЛђЭЌЪЧБГОАЃЉЕФИХТЪРДОіЖЈЁЃСНИіЯёЫижЎМфЕФШЈжигЩБпЕФаХЯЂЛђепСНИіЯёЫиЕФЯрЫЦадРДОіЖЈЁЃШчЙћСНИіЯёЫиЕФбеЩЋгаКмДѓЕФВЛЭЌЃЌФЧУДЫќУЧжЎМфЕФБпЕФШЈжиОЭЛсКмаЁЁЃ
7.ЪЙгУ mincut ЫуЗЈЖдЩЯУцЕУЕНЕФЭМНјааЗжИюЁЃЫќЛсИљОнзюЕЭГЩБОЗНГЬНЋЭМЗжЮЊ
Source_node КЭ Sink_nodeЁЃГЩБОЗНГЬОЭЪЧБЛМєЕєЕФЫљгаБпЕФШЈжижЎКЭЁЃдкВУМєжЎКѓЃЌЫљгаСЌНгЕН
Source_node ЕФЯёЫиБЛШЯЮЊЪЧЧАОАЃЌЫљгаСЌНгЕН Sink_node ЕФЯёЫиБЛШЯЮЊЪЧБГОАЁЃ
8.МЬајетИіЙ§ГЬжБЕНЗжРрЪеСВЁЃ
ЯТЭМбнЪОСЫетИіЙ§ГЬЃЈImage Courtesy:
28.1 бнЪО
ЯждкЮвУЧНјШы OpenCV жаЕФ grabcut ЫуЗЈЁЃOpenCV
ЬсЙЉСЫКЏЪ§ЃК
cv2.grabCut()ЁЃЮвУЧРДЯШПДПДЫќЕФВЮЪ§ЃК
img - ЪфШыЭМЯё
mask-бкФЃЭМЯёЃЌгУРДШЗЖЈФЧаЉЧјгђЪЧБГОАЃЌЧАОАЃЌПЩФмЪЧЧАОА/БГОАЕШЁЃПЩвдЩшжУЮЊЃКcv2.GC_BGD,cv2.GC_FGD,cv2.GC_PR_BGD,cv2.GC_PR_FGDЃЌЛђепжБНгЪфШы
0,1,2,3 вВааЁЃ
rect - АќКЌЧАОАЕФОиаЮЃЌИёЪНЮЊ (x,y,w,h)
bdgModel, fgdModel - ЫуЗЈФкВПЪЙгУЕФЪ§зщ. ФужЛашвЊДДНЈСНИіДѓаЁЮЊ
(1,65)ЃЌЪ§ОнРраЭЮЊ np.float64 ЕФЪ§зщЁЃ
iterCount - ЫуЗЈЕФЕќДњДЮЪ§
mode ПЩвдЩшжУЮЊ cv2.GC_INIT_WITH_RECT
Лђ cv2.GC_INIT_WITH_MASKЃЌ
вВПЩвдСЊКЯЪЙгУЁЃетЪЧгУРДШЗЖЈЮвУЧНјаааоИФЕФЗНЪНЃЌОиаЮФЃЪНЛђепбкФЃФЃЪНЁЃ
ЪзЯШЃЌЮвУЧРДПДЪЙгУОиаЮФЃЪНЁЃМгдиЭМЦЌЃЌДДНЈбкФЃЭМЯёЃЌЙЙНЈ bdgModelКЭ fgdModelЁЃДЋШыОиаЮВЮЪ§ЁЃЖМЪЧетУДжБНгЁЃШУЫуЗЈЕќДњ
5 ДЮЁЃгЩгкЮвУЧдкЪЙгУОиаЮФЃЪНЫљвдаоИФФЃЪНЩшжУЮЊ cv2.GC_INIT_WITH_RECTЁЃдЫааgrabcutЁЃЫуЗЈЛсаоИФбкФЃЭМЯёЃЌдкаТЕФбкФЃЭМЯёжаЃЌЫљгаЕФЯёЫиБЛЗжЮЊЫФРрЃК
БГОАЃЌЧАОАЃЌПЩФмЪЧБГОА/ЧАОАЪЙгУ 4 ИіВЛЭЌЕФБъЧЉБъМЧЃЈЧАУцВЮЪ§жаЬсЕНЙ§ЃЉЁЃ
ШЛКѓЮвУЧРДаоИФбкФЃЭМЯёЃЌЫљгаЕФ 0 ЯёЫиКЭ 1 ЯёЫиЖМБЛЙщЮЊ 0ЃЈР§ШчБГОАЃЉЃЌЫљгаЕФ 1 ЯёЫиКЭ 3
ЯёЫиЖМБЛЙщЮЊ 1ЃЈЧАОАЃЉЁЃЮвУЧзюжеЕФбкФЃЭМЯёОЭетбљзМБИКУСЫЁЃгУЫќКЭЪфШыЭМЯёЯрГЫОЭЕУЕНСЫЗжИюКУЕФЭМЯёЁЃ
import numpy
as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('messi5.jpg')
mask = np.zeros(img.shape[:2],np.uint8)
bgdModel = np.zeros((1,65),np.float64)
fgdModel = np.zeros((1,65),np.float64)
rect = (50,50,450,290)
# КЏЪ§ЕФЗЕЛижЕЪЧИќаТЕФ mask, bgdModel, fgdModel
cv2.grabCut(img,mask,rect,bgdModel,
fgdModel,5,cv2.GC_INIT_WITH_RECT)
mask2 = np.where((mask==2)|(mask==0),0,1).astype('uint8')
img = img*mask2[:,:,np.newaxis]
plt.imshow(img),plt.colorbar(),plt.show() |
НсЙћШчЯТЃК

АЅбНЃЌУЗЮїЕФЭЗЗЂБЛЮвУЧХЊУЛСЫЃЁШУЮвУЧРДАяЫћевЛиЭЗЗЂЁЃЫљвдЮвУЧвЊдкФЧРяЛвЛБЪЃЈЩшжУЯёЫиЮЊ
1ЃЌПЯЖЈЪЧЧАОАЃЉЁЃЭЌЪБЛЙгавЛаЉЮвУЧВЂВЛашвЊЕФВнЕиЁЃЮвУЧашвЊШЅГ§ЫќУЧЃЌЮвУЧдйдкетИіЧјгђЛвЛБЪЃЈЩшжУЯёЫиЮЊ
0ЃЌПЯЖЈЪЧБГОАЃЉЁЃЯждкПЩвдЯѓЧАУцЬсЕНЕФФЧбљРДаоИФбкФЃЭМЯёСЫЁЃ
ЪЕМЪЩЯЮвЪЧдѕУДзіЕФФиЃПЮвУЧЪЙгУЭМЯёБрМШэМўДђПЊЪфШыЭМЯёЃЌЬэМгвЛИіЭМВуЃЌЪЙгУБЪЫЂЙЄОпдкашвЊЕФЕиЗНЪЙгУАзЩЋЛцжЦЃЈБШШчЭЗЗЂЃЌаЌзгЃЌЧђЕШЃЉЃЛЪЙгУКкЩЋБЪЫЂдкВЛашвЊЕФЕиЗНЛцжЦЃЈБШШчЃЌlogoЃЌВнЕиЕШЃЉЁЃШЛКѓНЋЦфЫћЕиЗНгУЛвЩЋЬюГфЃЌБЃДцГЩаТЕФбкТыЭМЯёЁЃдк
OpenCV жаЕМШыетИібкФЃЭМЯёЃЌИљОнаТЕФбкТыЭМЯёЖддРДЕФбкФЃЭМЯёНјааБрМЁЃ
# newmask is
the mask image I manually labelled
newmask = cv2.imread('newmask.png',0)
# whereever it is marked white (sure foreground),
change mask=1
# whereever it is marked black (sure background),
change mask=0
mask[newmask == 0] = 0
mask[newmask == 255] = 1
mask, bgdModel, fgdModel = cv2.grabCut(img,mask,None,bgdModel,fgdModel,5,
cv2.GC_INIT_WITH_MASK)
mask = np.where((mask==2)|(mask==0),0,1).astype('uint8')
img = img*mask[:,:,np.newaxis]
plt.imshow(img),plt.colorbar(),plt.show() |
НсЙћШчЯТЃК

ОЭЪЧетбљЁЃФувВПЩвдВЛЪЙгУОиаЮГѕЪМЛЏЃЌжБНгНјШыбкТыЭМЯёФЃЪНЁЃЪЙгУ 2ЯёЫиКЭ 3 ЯёЫиЃЈПЩФмЪЧБГОА/ЧАОАЃЉЖдОиаЮЧјгђЕФЯёЫиНјааБъМЧЁЃШЛКѓЯѓЮвУЧдкЕкЖўИіР§згжаФЧбљЖдПЯЖЈЪЧЧАОАЕФЯёЫиБъМЧЮЊ
1 ЯёЫиЁЃШЛКѓжБНгдкбкФЃЭМЯёФЃЪНЯТЪЙгУ grabCut КЏЪ§ЁЃ |








