| БрМЭЦМі: |
БОЮФжївЊИјДѓМвЗжЯэСЫЩюЖШбЇЯАЕФгІгУЃЌвдМАдкЫМПМзівЛИіЩюЖШбЇЯАЦНЬЈжЎКѓЃЌЮвУЧЕФПМТЧКЭМмЙЙЩшМЦЃЌЯЃЭћФмИјДѓМвДјРДвЛаЉАяжњЁЃ
БОЮФРДздгкМђЪщЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
еЊвЊ
ЩюЖШбЇЯАЕФИХФюдДгкШЫЙЄЩёОЭјТчЕФбаОПЃЌКЌЖрвўВуЕФЖрВуИажЊЦїОЭЪЧвЛжжЩюЖШбЇЯАНсЙЙЁЃЩюЖШбЇЯАЭЈЙ§зщКЯЕЭВуЬиеїаЮГЩИќМгГщЯѓЕФИпВуБэЪОЪєадРрБ№ЛђЬиеїЃЌвдЗЂЯжЪ§ОнЕФЗжВМЪНЬиеїБэЪОЁЃ
ЛњЦїбЇЯАгыЩюЖШбЇЯАгІгУ
ЛњЦїбЇЯАЪЧЭЈЙ§ЛњЦїНјаазджїбЇЯАЪ§ОнЖјЗЧвдБрТыЕФЗНЪНЃЛЩюЖШбЇЯАЪЧЛњЦїбЇЯАЕФвЛИіЗжжЇЃЌжївЊАќРЈЫФжжзюЛљБОЕФЭјТчНсЙЙЁЃ
CNNЪЧОэЛ§ЩёОЭјТчЁЃЭЈЙ§ОэЛ§ЭјТчЕФФЃаЭЃЌПЩвдИпаЇЕиДІРэЭМЯёЗжРрЛђШЫСГЪЖБ№ЕШгІгУЁЃ
MLPЪЧЖрВуИажЊЛњЃЌвВОЭЪЧДЋЭГЕФЩёОЭјТчЁЃвбОБЛGoogleДѓСПгІгУдкYoutubeЪгЦЕЭЦМіКЭAPPЭЦМіЩЯЁЃ
RNNФЃаЭЪЧдкЩёОдЊРяМгШыДјМЧвфЕФЩёОдЊНсЙЙЃЌПЩвдДІРэКЭЪБМфађСагаЙиЕФЮЪЬтЁЃ
RLЪЧAlphagoгУЕНЕФдіЧПбЇЯАЃЌЫќЕФЕзВувВгУЕНвЛаЉЩюЖШбЇЯАММЪѕЁЃ
CaseStudyЃКImage Classification
МйШчгавЛИігІгУвЊЭЈЙ§ДѓСПЭМЦЌбЕСЗЗжБцГіУЈКЭЙЗЕФЭМЦЌЁЃШчЙћАДееДЋЭГЕФЗНЗЈЃЌГЬађдБздМКаДгІгУРДЧјБ№УЈЙЗЭМЦЌЃЌПЩФмашвЊКмЖрЙцдђКЭЭМаЮДІРэММЧЩЃЌБиаыЪЧвЛИіЭМЯёзЈМвЁЃ
ЕЋЯждкгаСЫЩёОЭјТчЃЌЪфШыжЛЪЧЪ§ОнЃЌжЛвЊЖЈвхвЛИіМђЕЅЕФЩёОЭјТчЃЌАбгІгУаДКУКѓЭЈЙ§Ъ§ОнбЕСЗЃЌОЭФмЪЕЯжвЛИіаЇЙћВЛДэЕФЭМЯёЗжРргІгУЁЃ

GoogleвбОПЊдДСЫInceptionЕФФЃаЭЃЌЪЧВуЪ§БШНЯИпЕФвЛИіЖрВуЩёОЭјТчЁЃетИіЭјТчгааЉИДдгЃЌгУGPUЛњЦїПЩФмвЊбЕСЗСНЕНШ§жмВХФмЪЕЯжЁЃгаСЫTensorflowетбљЕФЙЄОпКѓЃЌПЩвддкGithubЕижЗЩЯжБНгЯТдиЫќЕФФЃаЭЁЃ
CaseStudyЃКGame AI
GameAIЪЧгЮЯЗШЫЙЄжЧФмЃЌЭЈЙ§ЭМЯёЕФНсЙћгУдіЧПбЇЯАКЭQlearningЕФЫуЗЈЃЌОЭПЩвдЪЕЯжЫќздЖЏзюДѓЛЏЕиЕУЕНЗжЪ§ЁЃ

Introduce Tensorflow
TensorflowЪЧGoogleПЊдДЕФвЛИіDeep Learning LibraryЃЌЬсЙЉСЫC++КЭPythonНгПкЃЌжЇГжЪЙгУGPUКЭCPUНјаабЕСЗЃЌвВжЇГжЗжВМЪНДѓЙцФЃбЕСЗЁЃ
дкЪЙгУTensorflowЕФЪБКђЃЌжЛаДвЛИіОВЬЌДПЮФБОЕФЮФМўЃЌЭЈЙ§PythonНтЪЭЦїШЅдЫааЃЌЫљвдTensorflowБОжЪЩЯжЛЪЧвЛИіDeep
Learning LibraryЁЃ
Summary Of?Tensorflow
TensorflowетИіLibraryашвЊШЫЙЄАВзАЃЌНХБОашвЊЪжЖЏдЫааЃЌЛЗОГашвЊЪжЖЏХфжУЁЃЗжВМЪНЕФTensorflowвЊАбвЛИіНХБОПНБДЕНЖрЬЈЛњЦїЩЯЃЌЪжЖЏХфжУЁЃвЊНјааДњТыЕїгХашвЊЪжЖЏRunКЭTuneЁЃ
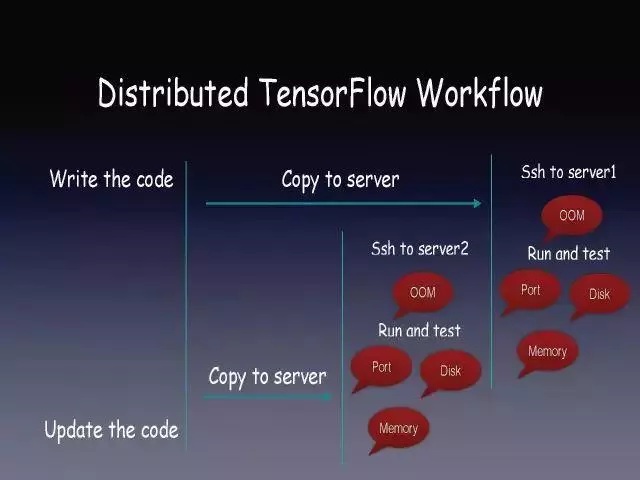
ЮвУЧЯызіTensorflowФЃаЭЕїгХЃЌЕЋЗўЮёЦїПЩФмГіЯжOOMЁЂПЩФмЪЙгУЕФЖЫПкБЛБ№ШЫеМгУЁЂвВПЩФмДХХЬГіЯжЙЪеЯЃЌЗўЮёЦїЛЗОГБфГЩгІгУПЊЗЂепЕФИКЕЃЁЃ

ЗжВМЪНTensorflowЭЌбљашвЊАбДњТыПНБДЕНЗжВМЪНЕФИїЬЈЛњЦїЩЯЃЌЧвВЛТлTensorflowЕФадФмЪЧЗёЫцзХНкЕуЪ§дНЖрЖјдіЧПЃЌЗўЮёЦїЮЌЛЄГЩБОвбГЪЯпаддіМгСЫЁЃ
ЫфШЛGoogleПЊдДСЫвЛИіЗЧГЃКУЕФЩюЖШбЇЯАЙЄОпЃЌЕЋЫќВЂУЛгаНтОіЩюЖШбЇЯАгІгУВПЪ№КЭЕїЖШЕФЮЪЬтЁЃ
гаШЫЫЕЙ§ЃЌШЮКЮИДдгЕФЮЪЬтЖМФмЭЈЙ§ГщЯѓРДНтОіЁЃЮвУЧдкжаМфв§ШывЛИіЗжВМЪНЕФЙмРэЯЕЭГЃЌШУЩЯВувЕЮёгІгУВЛашвЊжБНгЙмРэЕзВузЪдДЃЌгЩЭГвЛЕФЕїЖШЯЕЭГШЅЪЕЯжЁЃ
ЩюЖШбЇЯАЦНЬЈМмЙЙгыЩшМЦ
Cloud-MLЃКThe Principles
ЮвУЧЯЃЭћетЪЧвЛИідЦМЦЫуЃЌЖјВЛЪЧЬсЙЉТуЛњЕФЗўЮёЁЃгУЛЇжЛашаДКУгІгУДњТыЬсНЛЃЌВЛгУЭЈЙ§SshЛђЕЧТМЕНЗўЮёЦїЩЯгУНХБОдЫааЁЃ
ЮвУЧЯыАбФЃаЭЕФбЕСЗКЭЗўЮёНјааМЏГЩЁЃвЛИіФЃаЭбЕСЗЭъГЩКѓЛсЕУЕНвЛаЉФЃаЭЮФМўЃЌПЩвджБНгАбетаЉФЃаЭЮФМўгІгУЦ№РДЁЃ
ЮвУЧЯЃЭћетИіЦНЬЈЪЧИпПЩгУЕФЃЌМДЪЙгУЛЇЕФШЮЮёбЕСЗЪЇАмЃЌвВФмжиаТИјгУЛЇзівЛИіЕїЖШЁЃ
гУЛЇжЎМфЕФШЮЮёЪЧашвЊзізЪдДИєРыКЭЖЏЬЌЕїЖШЁЃ
ЮвУЧЯЃЭћФмжЇГжВЂЗЂЕФбЕСЗЁЃ
ЭЈЙ§Automatically TuningЦНЬЈЃЌгУЛЇПЩвдвЛДЮЬсНЛЖрИіГЌВЮЪ§зщКЯЃЌШУЫќВЂаабЕСЗЃЌЕШбЕСЗНсЪјПЩвджБНгПДЕНаЇЙћЁЃ
Cloud-MLЃКAll-In-One Platform

ФПЧАетИіЦНЬЈвбОЮЊгУЛЇЬсЙЉЩюЖШбЇЯАПђМмЕФПЊЗЂЛЗОГЃЌПЊЗЂЭъжЎКѓПЩвдАбДњТыЬсНЛЩЯШЅЃЌШЛКѓОЭПЩвдбЕСЗЃЌбЕСЗНсЙћЛсжБНгБЃДцдкЮвУЧздМКЕФЗжВМЪНДцДЂРяЁЃгУЛЇПЩвдЭЈЙ§етИіЦНЬЈЦ№вЛИіRPCЗўЮёЃЌЫћЕФЪжЛњЛђвЕЮёЗўЮёЦїФмЙЛжБНгЕїгУетИіЗўЮёЁЃЮвУЧЛЙЬсЙЉСЫModel
ZooвдМАRPCПЭЛЇЖЫЕФвЛаЉЙІФмЁЃ
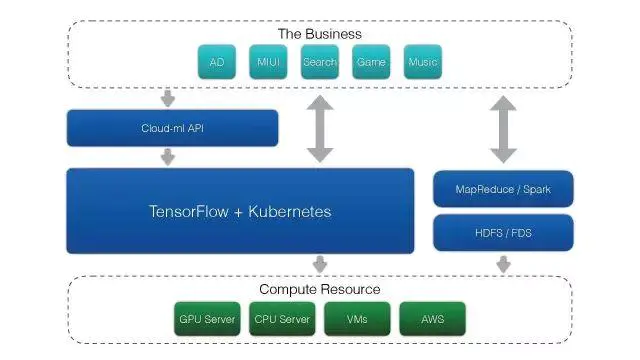
етЪЧЩюЖШбЇЯАЦНЬЈЕФЛљБОМмЙЙЁЃ
зюЩЯВуЪЧгУЛЇвЕЮёЃЌгаЙуИцЁЂЫбЫїЁЂгЮЯЗЕШЃЌЖМгаздМКЕФвЕЮёГЁОАЃЌПЩвдИљОнздМКЕФЪ§ОнИёЪНБраДвЛаЉTensorflowЁЂЩюЖШбЇЯАЕФНХБОЁЃЭЈЙ§Cloud-MlЕФAPIАбШЮЮёЬсНЛЕНЗўЮёЖЫЃЌгЩЗўЮёЖЫДДНЈвЛИіШнЦїЃЌАбЫќЕїгУЕНеце§ЕФЮяРэЛњМЦЫузЪдДЩЯЁЃ
етећИіДѓЦНЬЈжївЊЪЧгЩTensorflowКЭKubermetesЪЕЯжЕФЁЃгЩетИіЦНЬЈЙмРэЕзВуЮЌЛЄЕФCPUЗўЮёЦїКЭGPUЗўЮёЦїЁЂащФтЛњвдМАAWSЕФЛњЦїЁЃ
Cloud-MLЃКKubernetes Inside
KubermetesЪЧвЛИіШнЦїЕФМЏШКЙмРэЯЕЭГЃЌЫќЛсвРРЕвЛИіЖрНкЕуЕФEtcdМЏШКЃЌгавЛИіЛђЖрИіMasterШЅЙмРэKubeletНкЕуЁЃУПИіЮяРэЛњЛсВПЪ№вЛИіKubeletКЭDockerНјГЬЃЌдкЩЯУцЛсдЫааЖрИіDockerЕФContainerЁЃ
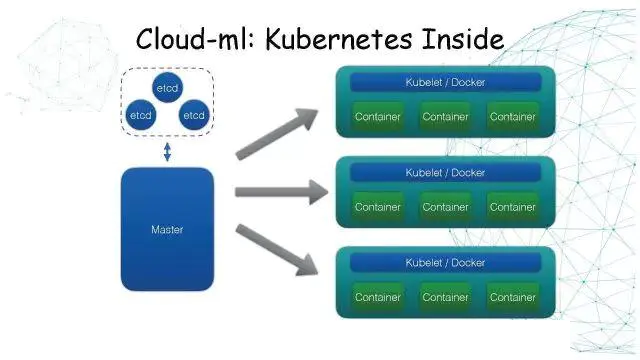
ЮвУЧетИіЦНЬЈЗтзАСЫвЛИіKubeletЃЌШУгУЛЇАбвЕЮёДњТыЬсНЛЩЯРДЃЌзщГЩвЛИіDockerШнЦїЕФИёЪНЃЌШЛКѓгЩKubeletШЅЕїЖШЁЃ
Cloud-MLЃКThe Architecture
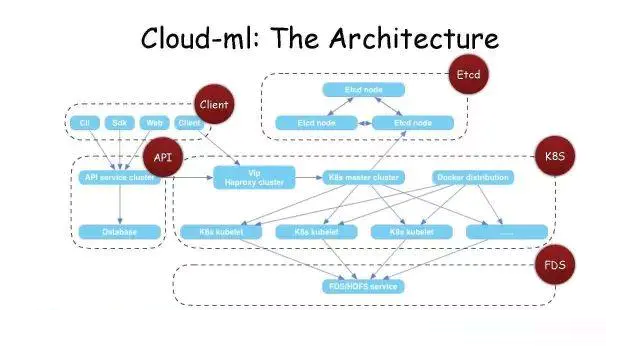
етЪЧвЛИіЗжВуКЭНтёюЕФЛљБОМмЙЙЃЌКУДІОЭЪЧAPIЗўЮёжЛашвЊИКд№ЪкШЈШЯжЄЁЂШЮЮёЙмРэЃЌЕїЖШЭЈЙ§KubermetesШЅзіЃЌKubermetesЕФдЊЪ§ОнЖМЭЈЙ§EtcdШЅДцДЂЃЌУПвЛВПЗжЖМРћгУAPIНјааЧыЧѓЁЃетбљОЭФмАбећИіЯЕЭГЕФзщМўНтёюЁЃ
Cloud-MLЃКTrain Job

гаСЫЩюЖШбЇЯАЦНЬЈжЎКѓЃЌЭЈЙ§вбОжЇГжЕФAPIЩљУїЬсНЛШЮЮёЕФУћГЦЃЌБраДКУPythonДњТыЕФЕижЗЁЃдЫааДњТыЕФВЮЪ§ЭЈЙ§PostЧыЧѓЙ§РДЁЃ
ЮвУЧвВЬсЙЉSDKЖдAPIзіСЫЗтзАЁЃ
УќСюааЙЄОпCommandФмЙЛжБНгАбаДКУЕФНХБОЬсНЛЕНдЦЦНЬЈНјаабЕСЗЁЃЛЙгаФкВПМЏГЩЕФWeb
ConsoleЁЃ
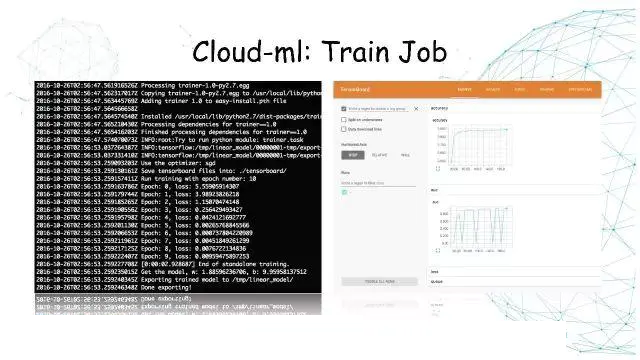
бЕСЗШЮЮёЬсНЛжЎКѓЃЌдкУќСюааПЩвдПДЕНШЮЮёбЕСЗШежОЁЃ
TensorboardПЩвдПДЖЈвхЕФФЃаЭНсЙЙЁЃ
Cloud-MLЃКModel Service
бЕСЗШЮЮёНсЪјКѓПЩвджБНгЦ№вЛИіModel ServiceЁЃвђЮЊЮФМўвбОБЃДцдкдЦДцДЂРяСЫЃЌжЛвЊдйЗЂвЛИіAPIЧыЧѓЃЌдкКѓЖЫвВЗтзАСЫвЛИіDocker
ImageЁЃ
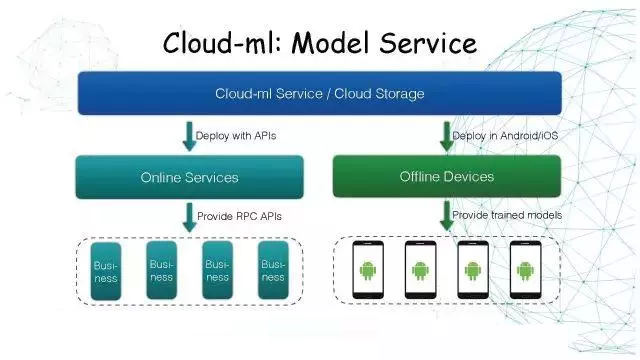
ЕзВуЪЧвРРЕGoogleвбОПЊдДЕФTensorflow ServingжБНгМгдиФЃаЭЮФМўЁЃ
зѓБпЪЧOnline ServicesЃЌгУЛЇАбФЃаЭбЕСЗЭъБЃДцдкетРяЃЌЦ№вЛИіШнЦїЃЌЖдЭтЬсЙЉИпадФмЕФRPCЗўЮёЁЃ
Cloud-MLЃКPredict Client

дкЯпЗўЮёжЇГжGrpcКЭHTTPНгПкЃЌРэТлЩЯжЇГжДѓВПЗжБрГЬгябдЁЃПЩвдЪЙгУJavaПЭЛЇЖЫЁЂC++ПЭЛЇЖЫЁЂGoПЭЛЇЖЫКЭPythonПЭЛЇЖЫЃЌЛђжБНгдкAndriodЧыЧѓФЃаЭЗўЮёЁЃ
ЭЈЙ§вЛИіЭГвЛЕФНгПкЖдЭтЬсЙЉЭМЯёЯрЙиЕФAPIЃЌЕзВуЪЧгЩKubermetesНјааЕїЖШКЭзЪдДИєРыЁЃ
гвБпЪЧPythonЕФGrpcПЭЛЇЖЫЃЌЕБФЃаЭЦ№РДвдКѓЃЌгУЛЇжЛашвЊБраДЖўЪЎМИааPythonДњТыЃЌАбФЃаЭЕФЪфШызМБИКУЃЌОЭПЩвдЧыЧѓЗўЮёЁЃ
Cloud-MLЃКWrap-Up
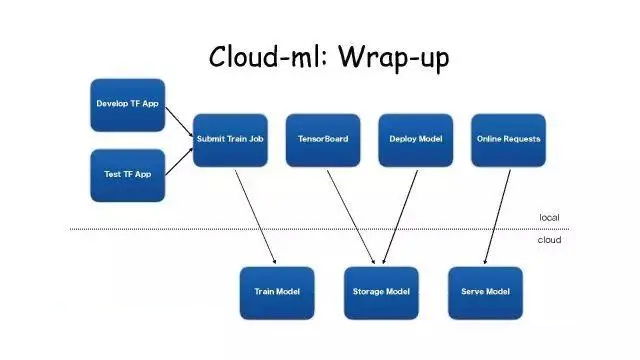
дкгаЩюЖШбЇЯАЦНЬЈвдКѓЃЌЙЄзїСїЪЧетбљЕФЁЃЩЯУцЪЧЙЄзїЛЗОГЃЌдЦЖЫгаЗўЮёЦїКЭЛљДЁМмЙЙЮЌЛЄЕФЗўЮёЁЃгУЛЇдкБОЕиЛЗОГБраДздМКЕФTensorflowгІгУЃЌдкБОЕибщжЄетИігІгУФмЗёХмЦ№РДЁЃ
ЭЈЙ§Submit Train JobЕФAPIАбШЮЮёЬсНЛЕНдЦЖЫЃЌеце§гУGPUЛђCPUбЕСЗЕФДњТыОЭдкдЦЖЫдЫааЁЃдЫааЭъжЎКѓЛсАбФЃаЭБЃДцЕНЗжВМЪНДцДЂРяУцЁЃ
гУЛЇПЩвдгУЙйЗНЬсЙЉЕФTest TF APPШЅПДФЃаЭбЕСЗЕФаЇЙћШчКЮЃЌШчЙћУЛЮЪЬтЃЌдкгУЛЇздМКЕФЛЗОГЕїгУDeploy
ModelЕФAPIЃЌетбљОЭЛсАбModelФУГіРДЦ№вЛИіШнЦїЃЌЖдЭтЬсЙЉRPCЗўЮёЁЃ
гУЛЇОЭПЩвдбЁдёздМКЯВЛЖЕФПЭЛЇЖЫЃЌгУRPCЕФЗНЪНЧыЧѓФЃаЭЗўЮёЁЃ
ЩюЖШбЇЯАЦНЬЈЪЕМљгыгІгУ
PracticeЃКDistributed Training

жЇГжЗжВМЪНбЕСЗЁЃгУЛЇдкPythonНХБОРяЖЈвхСЫвЛЯЕСаВЮЪ§ЃЌАбетИіНХБОПНБДЕНИїЬЈЛњЦїЩЯШЅдЫааЁЃ
ЮвУЧШУгУЛЇАбЗжВМЪННкЕуИіЪ§КЭЕБЧАНјГЬНЧЩЋЭЈЙ§ЛЗОГБфСПЖЈвхЃЌЛЗОГБфСПУћЪЧЙЬЖЈЕФЁЃетбљЫќжЛашвЊвЛИіЛЗОГБфСПОЭПЩвдЖЈвхНјГЬдкЗжВМЪНбЕСЗРяЕФНЧЩЋЁЃ
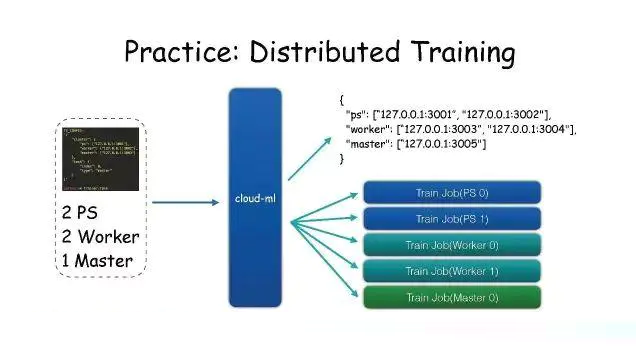
ЮвУЧАбгУЛЇЕФНХБОФУГіРДвдКѓЃЌВЛашвЊЫќШЅЙмРэЗўЮёЦїЕФЛЗОГЃЌжЛашвЊЩљУїетИіМЏШКгаЖрЩйИіPSЁЂWorkerКЭMasterЃЌАбетаЉВЮЪ§ЬсНЛИјCloud-MlЕФAPIЗўЮёЃЌгЩЫќРДЩъЧыПЩгУЕФIPКЭЖЫПкЁЃ
PracticeЃКStorage Integration

ЮвУЧЖдДцДЂЯЕЭГзіСЫМЏГЩЁЃПЊдДЕФTensorflowФПЧАжЛжЇГжБОЕиДцДЂЃЌвђЮЊЮвУЧдкдЦЖЫбЕСЗЃЌШЮЮёгЩЮвУЧЕїЖШЕНЬиЖЈЕФЛњЦїЃЌгУЛЇВЛПЩФмжБНгАббЕСЗЪ§ОнЗХЕНБОЕиЁЃ
ЮвУЧЯЃЭћгУЛЇФмжБНгЗУЮЪЮвУЧЕФЗжВМЪНДцДЂЃЌЫљвдЖдTensorflowдДТызіСЫаоИФЁЃЬсНЛШЮЮёЕФЪБКђПЩвджБНгжИЖЈвЛИіFDSЕФТЗОЖЃЌЯЕЭГОЭФмИљОнгУЛЇЕФШЈЯожБНгЖСШЁбЕСЗЪ§ОнЁЃ
ЖдGoogleЙйЗНЕФTensorflowзіСЫЭиеЙЁЃбЕСЗЭъжЎКѓЪ§ОнШЋВПЗХдкЗжВМЪНДцДЂРяЃЌгУTensorflowжИЖЈFDSТЗОЖЁЃ
бЕСЗЭъАбФЃаЭЕМГіЕНFDSвдКѓЃЌЭЈЙ§Cloud-MlЕФAPIДДНЈвЛИіЗўЮёЃЌМгдиЫќЕФФЃаЭЮФМўЁЃ
еыЖдВЛЭЌЕФФЃаЭЩљУїВЛЭЌЕФЧыЧѓЪ§ОнЃЌЪфШыРраЭКЭЪфШыЕФжЕЭЈЙ§JsonЖЈвхЃЌОЭПЩвдЧыЧѓФЃаЭЗўЮёСЫЁЃ
PracticeЃКSupport HPAT
HPATЪЧЩёОЭјТчРяЕФГЌВЮЪ§здЖЏЕїгХЃЌМЋДѓЫѕЖЬСЫПЦбаШЫдБКЭзЈзЂзіЫуЗЈФЃаЭШЫдБЕФЪБМфЁЃ

PracticeЃКDependency Management

ШУгУЛЇЬсНЛДњТыЕФЪБКђЬсНЛвЛИіБъзМЕФPython PackageЁЃ
PracticeЃКBringYour Own Image

ШУгУЛЇЕФDockerжБНгЬсНЛЕНKubermetesМЏШКРяЃЌеце§ГЙЕзНтОігУЛЇвРРЕЕФЮЪЬтЁЃ
PracticeЃКModelZoo
ЮвУЧАбModelЮФМўЗХЕНДцДЂжаЃЌЭЈЙ§APIАбPaperЪЕЯжСЫЃЌВЛЭЌЕФModelЖМПЩвдВПЪ№ЕНетИіЦНЬЈЩЯЃЌетбљОЭПЩвдЭЈЙ§RPCРДжБНгЗУЮЪетИіЗўЮёСЫЁЃ
змНс
ЮвУЧвВЯраХдЦМЦЫуДѓЪ§ОнЪБДњвбОЕНРДЃЌЯТвЛИіЪБДњНЋЛсЪЧЩюЖШбЇЯАЃЌВЂЧвЮДРДЛсМЬајЭљдЦЩюЖШбЇЯАЗЂеЙЁЃаЛаЛДѓМвЃЁ
|





