| БрМЭЦМі: |
БОЮФжївЊеыЖдздШЛгябдДІРэЃЈNLPЃЉЙ§ГЬжаЃЌживЊЛљДЁВПЗжГщШЁЮФБОФкШнЕФдЄДІРэЁЃЕквЛНкВЩгУКЫаФИХФюНВНтЕкЖўНкжЊЪЖРЉеЙВЙГфЁЃЕкШ§НкЕфаЭDOMEХфгадДДњТыЕкЫФНкВЮПМКЫаФЮФМўКЭTikaЙЄОпЕФJARАќЙВЯэ
ЁЃ
БОЮФРДздгкВЉПЭдАЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
еЊвЊЃКЪзЯШЮвУЧвЊвтЪЖЕНдЄДІРэЕФживЊадЁЃдкДѓЪ§ОнЕФБГОАЯТЃЌдНРДдНЖрЕФЗЧНсЙЙЛЏАыНсЙЙЛЏЮФБОЁЃШчКЮДгКЃСПЮФБОжаГщШЁЮвУЧашвЊЕФгаМлжЕЕФжЊЪЖЯдЕУгШЮЊживЊЁЃСэЭтЮФБОИёЪНГЃГЃВЛвЛЃЌжюШчЃКpdfЃЌwordЃЌexclЃЌxmlЃЌpptЃЌtxtЕШГЃМћЮФМўРраЭФуЛђаэОЙ§вЛЗЌжмелЛЙЪЧгаАьЗЈДІРэЕФЁЃЬШШєгіЕНdatabaseЃЌhtmlЃЌгЪМўЃЌRTF,ЭМЯёЃЌгявєЕШЮФМўЃЌФуЪЧЗёЫиЪжЮоВпСЫЁЃЛљгкДЫБОЮФзмНсApache
TikaФкШнГщШЁЙЄОпЃЌЦфЧПДѓжЎДІдкгкПЩвдДІРэИїжжЮФМўЃЌСэЭтНкдМФњИќЖрЕФЪБМфгУРДзіживЊЕФЪТЧщЁЃ
1 TikaНщЩм
TikaИХФю
TikaЪЧвЛИіФкШнЗжЮіЙЄОпЃЌздДјШЋУцЕФparserЙЄОпРрЃЌФмНтЮіЛљБОЫљгаГЃМћИёЪНЕФЮФМўЃЌЕУЕНЮФМўЕФmetadataЃЌcontentЕШФкШнЃЌЗЕЛиИёЪНЛЏаХЯЂЁЃзмЕФРДЫЕПЩвдзїЮЊвЛИіЭЈгУЕФНтЮіЙЄОпЁЃЬиБ№ЖдгкЫбЫїв§ЧцЕФЪ§ОнзЅШЅКЭДІРэВНжшгаживЊвтвхЁЃTikaЪЧApacheЕФLuceneЯюФПЯТУцЕФзгЯюФПЃЌдкluceneЕФгІгУжаПЩвдЪЙгУtikaЛёШЁДѓХњСПЮФЕЕжаЕФФкШнРДНЈСЂЫїв§ЃЌЗЧГЃЗНБуЃЌвВКмШнвзЪЙгУЁЃApache
Tika toolkitПЩвдздЖЏМьВтИїжжЮФЕЕ(Шчword,ppt,xml,csv,pptЕШ)ЕФРраЭВЂГщШЁЮФЕЕЕФдЊЪ§ОнКЭЮФБОФкШнЁЃTikaМЏГЩСЫЯжгаЕФЮФЕЕНтЮіПтЃЌВЂЬсЙЉЭГвЛЕФНгПкЃЌЪЙеыЖдВЛЭЌРраЭЕФЮФЕЕНјааНтЮіБфЕУИќМђЕЅЁЃTikaеыЖдЫбЫїв§ЧцЫїв§ЁЂФкШнЗжЮіЁЂзЊЛЏЕШЗЧГЃгагУЁЃ
TikaМмЙЙ
гІгУГЬађдБПЩвдКмШнвзЕидкЫћУЧЕФгІгУГЬађМЏГЩTikaЁЃTikaЬсЙЉСЫвЛИіУќСюааНчУцКЭЭМаЮгУЛЇНчУцЃЌЪЙЫќБШНЯШЫадЛЏЁЃдкБОеТжаЃЌЮвУЧНЋЬжТлЙЙГЩTikaМмЙЙЕФЫФИіживЊФЃПщЁЃЯТЭМЯдЪОСЫTikaЕФЫФИіФЃПщЕФЬхЯЕНсЙЙЃК
1.гябдМьВтЛњжЦЁЃ
2.MIMEМьВтЛњжЦЁЃ
3.ParserНгПкЁЃ
4.Tika Facade Рр.
гябдМьВтЛњжЦ
УПЕБвЛИіЮФБОЮФМўБЛДЋЕнЕНTikaЃЌЫќНЋМьВтдкЦфжаЕФгябдЁЃЫќНгЪмУЛгагябдЕФзЂЪЭЮФМўКЭЭЈЙ§МьВтИУгябдЬэМгдкИУЮФМўЕФдЊЪ§ОнаХЯЂЁЃжЇГжгябдЪЖБ№ЃЌTika
гавЛРрНазігябдБъЪЖЗћдкАќorg.apache.tika.languageМАгябдЪЖБ№зЪСЯПтРяУцАќКЌСЫгябдМьВтДгИјЖЈЮФБОЕФЫуЗЈЁЃTika
ФкВПЪЙгУN-gramЫуЗЈгябдМьВтЁЃ
MIMEМьВтЛњжЦ
TikaПЩвдИљОнMIMEБъзММьВтЮФЕЕРраЭЁЃTikaФЌШЯMIMEРраЭМьВтЪЧЪЙгУorg.apache.tika.mime.mimeTypesЁЃЫќЪЙгУorg.apache.tika.detect.Detector
НгПкДѓВПЗжФкШнРраЭМьВтЁЃФкВПTikaЪЙгУЖржжММЪѕЃЌШчЮФМўЦЅХфЬцЛЛЃЌФкШнРраЭЬсЪОЃЌФЇЪѕзжНкЃЌзжЗћБрТыЃЌвдМАЦфЫћвЛаЉММЪѕЁЃ
НтЮіЦїНгПк
org.apache.tika.parser НтЮіЦїНгПкЪЧTikaНтЮіЮФЕЕЕФжївЊНгПкЁЃИУНгПкДгЬсШЁЮФЕЕжаЕФЮФБОКЭдЊЪ§ОнЃЌВЂзмНсСЫЦфЖдЭтВПгУЛЇдИвтаДНтЮіЦїВхМўЁЃВЩгУВЛЭЌЕФОпЬхНтЮіЦїРрЃЌОпЬхЮЊИїИіЮФЕЕРраЭЃЌTika
жЇГжДѓСПЕФЮФМўИёЪНЁЃетаЉИёЪНЕФОпЬхРрВЛЭЌЕФЮФМўИёЪНЬсЙЉжЇГжЃЌЮоТлЪЧЭЈЙ§жБНгЪЕЯжТпМЗжЮіЦїЛђЪЙгУЭтВПНтЮіЦїПтЁЃ
Tika Facade Рр
ЪЙгУЕФTika facadeРрЪЧДгJavaЕїгУTikaЕФзюМђЕЅКЭжБНгЕФЗНЪНЃЌЖјЧввВбигУСЫЭтЙлЕФЩшМЦФЃЪНЁЃПЩвддк
Tika APIЕФorg.apache.tikaАќTika евЕНЭтЙлfacadeРрЁЃЭЈЙ§ЪЕЯжЛљБОгУР§ЃЌTikaзїЮЊfacadeЕФДњРэЁЃЫќГщЯѓСЫЕФTikaПтЕФЕзВуИДдгадЃЌР§ШчMIMEМьВтЛњжЦЃЌНтЮіЦїНгПкКЭгябдМьВтЛњжЦЃЌВЂЬсЙЉИјгУЛЇвЛИіМђЕЅЕФНгПкРДЪЙгУЁЃ
TikaЕФЬиЕу
ЭГвЛНтЮіЦїНгПкЃКTikaЗтзАдквЛИіЕЅвЛЕФНтЮіЦїНгПкЕФЕкШ§ЗННтЮіЦїПтЁЃгЩгкетИіЬиеїЃЌгУЛЇвнГіДгбЁдёКЯЪЪЕФНтЮіЦїПтЕФИКЕЃЃЌВЂЪЙгУЫќЃЌИљОнЫљгіЕНЕФЮФМўРраЭЁЃ
ЕЭФкДцеМгУЃКTikaвђДЫЯћКФИќЩйЕФФкДцзЪдДвВКмШнвзЧЖШыJavaгІгУГЬађЁЃвВПЩвдгУTikaЦНЬЈЯёвЦЖЏФЧбљPDAзЪдДЩйЃЌдЫааИУгІгУГЬађЁЃ
ПьЫйДІРэЃКДггІгУСЌНсФкШнМьВтКЭЬсШЁПЩвддЄЦкЕФЁЃ
СщЛюдЊЪ§ОнЃКTikaРэНтЫљгаетаЉЖМгУРДУшЪіЮФМўЕФдЊЪ§ОнФЃаЭЁЃ
НтЮіЦїМЏГЩЃКTikaПЩвдЪЙгУПЩдкЕЅвЛгІгУГЬађжаУПИіЮФМўРраЭЕФИїжжНтЮіЦїПтЁЃ
MIMEРраЭМьВтЃК TikaПЩвдМьВтВЂДгЫљгаАќРЈдкMIMEБъзМЕФУНЬхРраЭжаЬсШЁФкШнЁЃ
гябдМьВтЃК TikaАќРЈгябдЪЖБ№ЙІФмЃЌвђДЫПЩвддквЛИіЖргяжжЭјеОЛљгкгябдРраЭЕФЮФЕЕжаЪЙгУЁЃ
TikaЕФЙІФм
TikaжЇГжЖржжЙІФмЃК
1.ЮФЕЕРраЭМьВт
2.ФкШнЬсШЁ
3.дЊЪ§ОнЬсШЁ
4.гябдМьВт
ЮФМўРраЭМьВт
TikaЪЙгУВЛЭЌЕФМьВтММЪѕЃЌМьВтИјЫќЕФЮФМўЕФРраЭЁЃ

ФкШнЬсШЁ
TikaгавЛИіНтЮіЦїПтЃЌПЩвдЗжЮіИїжжЮФЕЕИёЪНЕФФкШнЃЌВЂЬсШЁЫќУЧЁЃШЛКѓМьВтЫљЪіЮФЕЕЕФРраЭЃЌЫќДгНтЮіЦїПтбЁдёЕФЪЪЕБЕФЗжЮіЦїЃЌВЂДЋЕнИУЮФЕЕЁЃВЛЭЌРрБ№ЕФTikaЗНЗЈРДНтЮіВЛЭЌЕФЮФМўИёЪНЁЃ

дЊЪ§ОнЬсШЁ
ЫцзХФкШнЃЌTikaЬсШЁОпгаЯрЭЌЕФГЬађЕФЮФМўЕФдЊЪ§ОнжаЕФФкШнЕФЬсШЁЁЃЖдгкФГаЉЮФМўРраЭЃЌTikaгаНгПкРрЬсШЁдЊЪ§ОнЁЃ

гябдМьВт
дкФкВПЃЌTikaШчЯТЯёвЛИіn-gramЫуЗЈРДМьВтЫљЪіФкШнЕФгябдЕФИјЖЈЮФЕЕжаЁЃTikaШЁОігкРрЃЌШчгябдЪЖБ№КЭProfilerЕФгябдЪЖБ№ЁЃ
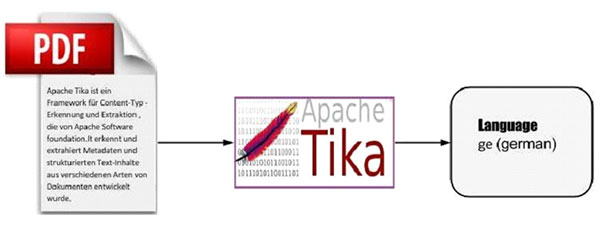
2 КЫаФжЊЪЖРЉеЙ
НтЮіЦїНгПк
org.apache.tika.parser.Parser НгПкЪЧ Apache Tika ЕФЙиМќзщМўЁЃЫќвўВиСЫВЛЭЌЮФМўИёЪНКЭНтЮіПтЕФИДдгадЃЌЖјЭЌЪБгжЮЊПЭЛЇгІгУГЬађДгИїжжВЛЭЌЕФЮФЕЕЬсШЁНсЙЙЛЏЕФЮФБОФкШнвдМАдЊЪ§ОнЬсЙЉСЫвЛИіМђЕЅЧвЙІФмЧПДѓЕФЛњжЦЁЃЫљгаетаЉЖМЪЧЭЈЙ§вЛИіМђЕЅЕФЗНЗЈЪЕЯжЕФЃК
| void parse(InputStream
stream, ContentHandler handler, Metadata metadata)
throws IOException, SAXException, TikaException; |
parse ЗНЗЈНгЪмвЊБЛНтЮіЕФЮФЕЕвдМАЯрЙиЕФдЊЪ§ОнзїЮЊЪфШыЃЌВЂЪфГі XHTML SAX ЪТМўвдМАЖюЭтЕФдЊЪ§ОнзїЮЊНсЙћЁЃЕМжТетвЛЩшМЦЕФжївЊЬѕМўШчБэ
1 ЫљЪОЁЃ
Бэ 1. Tika НтЮіЩшМЦЕФЬѕМў

етаЉЬѕМўдк parse ЗНЗЈЕФВЮЪ§ФкгаЫљЬхЯжЁЃ
Document InputStream
ЕквЛИіВЮЪ§ЪЧ InputStreamЃЌгУРДЖСШЁвЊБЛНтЮіЕФЮФЕЕЁЃ
ШчЙћДЫЮФЕЕСїВЛФмБЛЖСШЁЃЌНтЮіОЭЛсЭЃжЙВЂЧвХзГіЕФ IOException ОЭЛсБЛДЋЕнИјПЭЛЇгІгУГЬађЁЃШчЙћетИіСїПЩБЛЖСШЁЕЋВЛФмБЛНтЮіЃЈБШШчЮФЕЕБЛЦЦЛЕСЫЃЉЃЌНтЮіЦїОЭЛсХзГівЛИі
TikaExceptionЁЃДЫНтЮіЦїЪЕЯжНЋЛсЪЙгУетИіСїЃЌЕЋВЛЛсЙиБеЫќЁЃЙиБеСїЪЧгЩзюГѕДђПЊЫќЕФетИіПЭЛЇгІгУГЬађИКд№ЕФЁЃЧхЕЅ
1 ЯдЪОСЫгУ parse ЗНЗЈЪЙгУСїЕФНЈвщФЃЪНЁЃ
ЧхЕЅ 1. гУ parse ЗНЗЈЪЙгУСїЕФНЈвщФЃЪН
InputStream stream
= ...; // open the stream
try {
parser.parse(stream, ...); // parse the stream
} finally {
stream.close(); // close the stream
} |
XHTML SAX ЪТМў
ДЫЮФЕЕСїЕФБЛНтЮіФкШнБЛзїЮЊ XHTML SAX ЪТМўЕФвЛИіађСаЗЕЛиИјПЭЛЇгІгУГЬађЁЃXHTML гУРДБэДяДЫЮФЕЕЕФНсЙЙЛЏФкШнЃЌSAX
ЪТМўгУРДЦєгУСїЯпЛЏЕФДІРэЁЃЧызЂвтетРяЪЙгУСЫ XHTML ИёЪНЃЌНіНіЪЧЮЊСЫБэДяНсЙЙЛЏаХЯЂЃЌВЛЪЧЮЊСЫГЪЯжЮФЕЕвдЙЉфЏРРЁЃгЩДЫНтЮіЦїЪЕЯжЩњГЩЕФетаЉ
XHTML SAX ЪТМўБЛЗЂЫЭжСИјЕН parse ЗНЗЈЕФвЛИі ContentHandler ЪЕР§ЁЃШчЙћДЫФкШнДІРэГЬађДІРэвЛИіЪТМўЪЇАмЃЌНтЮіОЭЛсЭЃжЙВЂЧвЫљХзГіЕФ
SAXException ЛсБЛЗЂЫЭИјПЭЛЇгІгУГЬађЁЃЧхЕЅ 2 ЯдЪОСЫЫљЩњГЩЕФетИіЪТМўСїЕФећЬхНсЙЙЃЈВЂЧвЮЊСЫЧхЮњЃЌЛЙЬэМгСЫЫѕНјЃЉЁЃ
ЧхЕЅ 2. ЫљЩњГЩЕФетИіЪТМўСїЕФећЬхНсЙЙ
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>...</title>
</head>
<body>
...
</body>
</html> |
НтЮіЦїЪЕЯжЭЈГЃЛсЪЙгУ XHTMLContentHandler ЪЕгУЙЄОпРрРДЩњГЩ XHTML ЪфГіЁЃДІРэетаЉдЪМЕФ
SAX ЪТМўПЩФмЛсЗЧГЃИДдгЃЌЫљвд Apache TikaЃЈзд V0.2 ПЊЪМЃЉаЏДјСЫМИИіЪЕгУЙЄОпРрЃЌгУРДДІРэЪТМўСїВЂНЋЪТМўСїзЊЛЛЮЊЦфЫћЕФБэЪОЁЃ
БШШчЃЌBodyContentHandler РрПЩгУРДжЛЬсШЁ XHTML ЪфГіЕФжїЬхВПЗжВЂНЋЦфзїЮЊ
SAX ЪТМўЬсЙЉИјСэвЛИіФкШнДІРэГЬађЛђзїЮЊЗћКХЬсЙЉИјвЛИіЪфГіСїЁЂвЛИіБраДЦїЛђ вЛИізжЗћДЎЁЃШчЯТЕФДњТыЦЌЖЮНтЮіСЫРДздБъзМЪфШыСїЕФЮФЕЕВЂНЋЫљЬсШЁЕФЮФЕЕФкШнЪфГіЕНБъзМЪфГіЃК
ContentHandler
handler = new BodyContentHandler(System.out);
parser.parse(System.in, handler, ...); |
СэвЛИігагУЕФРрЪЧ ParsingReaderЃЌЫќЪЙгУСЫвЛИіКѓЬЈЯпГЬРДНтЮіДЫЮФЕЕВЂзїЮЊвЛИізжЗћСїЗЕЛиЫљЬсШЁЕФЮФБОФкШнЁЃ
ЧхЕЅ 3. ParsingReader ЕФР§зг
InputStream stream
= ...; // the document to be parsed
Reader reader = new ParsingReader(parser, stream,
...);
try {
...; // read the document text using the reader
} finally {
reader.close(); // the document stream is closed
automatically
} |
ЮФЕЕдЊЪ§Он
parse ЗНЗЈЕФзюКѓвЛИіВЮЪ§гУРДНЋЮФЕЕдЊЪ§ОнДЋЕнНј/ГіДЫНтЮіЦїЁЃЮФЕЕдЊЪ§ОнБЛБэЪіЮЊвЛИідЊЪ§ОнЖдЯѓЁЃБэ
2 СаГіСЫИќгаШЄЕФвЛаЉдЊЪ§ОнЪєадЁЃ
Бэ 2. дЊЪ§ОнЪєад

зЂвтЕНЃЌдЊЪ§ОнДІРэЛЙдк Apache Tika ПЊЗЂЭХЖгЕФЬжТлжЎжаЃЌЫљвддк Tika V1.0 жЎЧАЕФАцБОЃЌдкдЊЪ§ОнДІРэЗНУцгаПЩФмЛсгавЛаЉЃЈКѓЯђВЛМцШнЕФЃЉВювьЁЃ
НтЮіЦїЪЕЯж
Apache Tika здДјвЛаЉНтЮіЦїРрРДНтЮіИїжжЮФЕЕИёЪНЃЌШчБэ 3 ЫљЪОЁЃ
Бэ 3. Tika НтЮіЦїРр

ФњПЩвдЪЙгУФњздМКЕФНтЮіЦїРДРЉеЙ Apache TikaЃЌФњЖд Tika ЫљзіЕФШЮКЮЙБЯзЖМЪЧЪмЛЖгЕФЁЃTika
ЕФФПБъЪЧОЁПЩФмЕижигУЯжгаЕФНтЮіЦїПтЃЈБШШч Apache PDFBox Лђ Apache POIЃЉЃЌвђДЫ
Tika ФкЕФДѓЖрЪ§НтЮіЦїРрЖМЪЧЪЪгІгкетаЉЭтВППтЁЃApache Tika ЛЙАќКЌвЛаЉВЛеыЖдШЮКЮЬиЖЈЮФЕЕИёЪНЕФЭЈгУНтЮіЦїЪЕЯжЁЃЦфжазюжЕЕУвЛЬсЕФЪЧ
AutoDetectParser РрЃЌЫќНЋЫљгаЕФ Tika ЙІФмАќзАНјвЛИіФмДІРэШЮКЮЮФЕЕРраЭЕФНтЮіЦїЁЃетИіНтЮіЦїПЩздЖЏОіЖЈШыЯђЮФЕЕЕФРраЭЃЌШЛКѓЛсЯргІНтЮіДЫЮФЕЕЁЃЯждкЃЌЮвУЧПЩвдНјаавЛаЉЪЕМЪВйзїСЫЁЃШчЯТЕФетаЉРрЪЧЮвУЧдкећИіНЬГЬжавЊПЊЗЂЕФЃК
1.BudgetScrambleЁЊ ЯдЪОСЫШчКЮЪЙгУ Apache Tika
дЊЪ§ОнРДОіЖЈФФИіЮФЕЕзюНќБЛИќИФвдМАдкКЮЪБИќИФЁЃ
2.TikaMetadataЁЊ ЯдЪОСЫШчКЮЛёЕУФГИіЮФЕЕЕФЫљга Apache
Tika дЊЪ§ОнЃЌМДБуУЛгаЪ§ОнЃЈжЛЯдЪОЫљгаЕФдЊЪ§ОнРраЭЃЉЁЃ
3.TikaMimeTypeЁЊ ЯдЪОСЫШчКЮЪЙгУ Apache Tika
ЕФ mimetypes РДМьВтФГИіЬиЖЈЮФЕЕЕФ mimetypeЁЃ
4.TikaExtractTextЁЊ ЯдЪОСЫ Apache Tika
ЕФЮФМўЬсШЁЙІФмВЂНЋЫљЬсШЁЕФЮФБОБЃДцЮЊКЯЪЪЕФЮФМўЁЃ
5.LanguageDetector ЁЊ НщЩмСЫ Nutch гябдЕФЪЖБ№ЙІФмРДЪЖБ№ЬиЖЈФкШнЕФгябдЁЃ
6.Summary ЁЊ змНсСЫ Tika ЬиадЃЌБШШч MimeTypeЁЂФкШн
charset МьВтКЭдЊЪ§ОнЁЃДЫЭтЃЌЫќЛЙв§ШыСЫ cpdetector ЙІФмРДОіЖЈвЛИіЮФМўЕФ charset
БрТыЁЃзюКѓЃЌЫќЯдЪОСЫ Nutch гябдЪЖБ№ЕФЪЕМЪЪЙгУЁЃ
3 TikaЮФБОГщШЁЪЕР§ЗжЮі
TikaжївЊЭЈЙ§5ИіВПЗжЭъГЩГЃЙцЪ§ОнГщШЁЃК
1ЁЂInputStream input=new FileInputStream(new
File("./myfile/Active Learning.pdf")); //ЙЙНЈInputStreamРДЖСШЁЪ§ОнЃЌПЩвдаДЮФМўТЗОЖЃЌpdfЃЌwordЃЌhtmlЕШ
2ЁЂBodyContentHandler textHandler=new
BodyContentHandler(); //ЛёШЁФкШн
3ЁЂMetadata matadata=new Metadata();//MetadataЖдЯѓБЃДцСЫзїепЃЌБъЬтЕШдЊЪ§Он
4ЁЂPDFParser ParseContext context=new
ParseContext(); //етРяParserНтЮіЦїИљОнВЛЭЌЮФМўВЩгУВЛЭЌНтЮіЦї
5ЁЂParser parser=new AutoDetectParser();//ЕБЕїгУparserЃЌAutoDetectParserЛсздЖЏЙРМЦЮФЕЕMIMEРраЭЃЌДЫДІЪфШыpdfЮФМўЃЌвђДЫПЩвдЪЙгУ
6ЁЂparser.parse(input, textHandler,
matadata, context);//жДааНтЮіЙ§ГЬ
дДТыЃК
/**
* Tika AutoDetectParserРрРДЪЖБ№КЭГщШЁФкШн
* @throws TikaException
* @throws SAXException
* @throws IOException
*/
public static void getTextFronPDF() throws IOException,
SAXException, TikaException{
//ЙЙНЈInputStreamРДЖСШЁЪ§Он
InputStream input=new FileInputStream(new File("./myfile/Active
Learning.pdf"));//ПЩвдаДЮФМўТЗОЖЃЌpdfЃЌwordЃЌhtmlЕШ
BodyContentHandler textHandler=new BodyContentHandler();
Metadata matadata=new Metadata();//MetadataЖдЯѓБЃДцСЫзїепЃЌБъЬтЕШдЊЪ§Он
Parser parser=new AutoDetectParser();//ЕБЕїгУparserЃЌAutoDetectParserЛсздЖЏЙРМЦЮФЕЕMIMEРраЭЃЌДЫДІЪфШыpdfЮФМўЃЌвђДЫПЩвдЪЙгУPDFParser
ParseContext context=new ParseContext();
parser.parse(input, textHandler, matadata, context);//жДааНтЮіЙ§ГЬ
input.close();
System.out.println("Title: "+matadata.get(Metadata.TITLE));
System.out.println("Type: "+matadata.get(Metadata.TYPE));
System.out.println("Body: "+textHandler.toString());//ДгtextHandlerДђгЁе§ЮФ
} |
дЫааНсЙћЃК

|








